单向循环链表与双向链表
单向循环链表的原理与应用
思考:对于单向链表而言,想要遍历链表,则必须从链表的首结点开始进行遍历,请问有没有更简单的方案实现链表中的数据的增删改查?
回答:是有的,可以使用单向循环的链表进行设计,单向循环的链表的使用规则和普通的单向链表没有较大的区别,需要注意:单向循环链表的尾结点的指针域中必须指向链表的首结点的地址,由于带头结点的单向循环链表更加容易进行管理,所以教学以带头结点的为例:
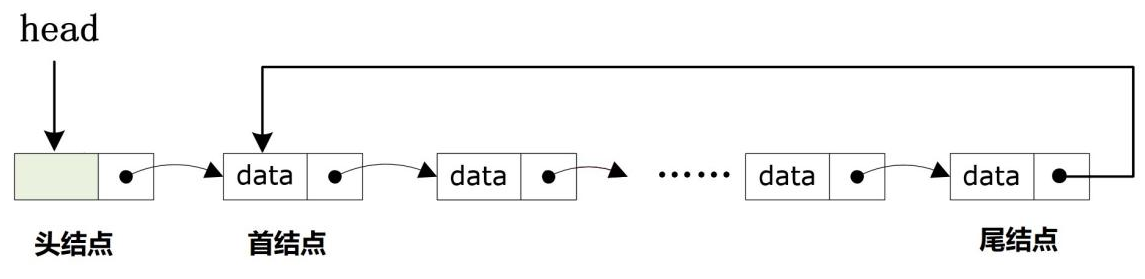
上图所示的就是一个典型的单向循环链表的结构,可以发现单向循环链表的结构属于环形结构,链表中的最后一个结点的指针域中存储的是链表的第一个结点的地址。
为了管理单向循环链表,需要构造头结点的数据类型以及构造有效结点的数据类型,如下:
//指的是单向循环链表中的结点有效数据类型,用户可以根据需要进行修改
typedef int DataType_t;//构造单向循环链表的结点,链表中所有结点的数据类型应该是相同的
typedef struct CircularLinkedList
{DataType_t data; //结点的数据域struct LinkedList *next; //结点的指针域}CircLList_t;创建一个空链表,由于是使用头结点,所以就需要申请头结点的堆内存并初始化即可!
//创建一个空单向循环链表,空链表应该有一个头结点,对链表进行初始化
CircLList_t * CircLList_Create(void)
{//1.创建一个头结点并对头结点申请内存CircLList_t *Head = (CircLList_t *)calloc(1,sizeof(CircLList_t));if (NULL == Head){perror("Calloc memory for Head is Failed");exit(-1);}//2.对头结点进行初始化,头结点是不存储数据域,指针域指向自身,体现“循环”思想Head->next = Head;//3.把头结点的地址返回即可return Head;
}
创建新结点,为新结点申请堆内存并对新结点的数据域和指针域进行初始化,操作如下:
//创建新的结点,并对新结点进行初始化(数据域 + 指针域)
CircLList_t * CircLList_NewNode(DataType_t data)
{//1.创建一个新结点并对新结点申请内存CircLList_t *New = (CircLList_t *)calloc(1,sizeof(CircLList_t));if (NULL == New){perror("Calloc memory for NewNode is Failed");return NULL;}//2.对新结点的数据域和指针域进行初始化New->data = data;New->next = NULL;return New;
}遍历整个链表
//遍历链表
bool CircLList_Print(CircLList_t *Head)
{//对单向循环链表的头结点的地址进行备份CircLList_t *Phead = Head;//判断当前链表是否为空,为空则直接退出if (Head->next == Head){printf("current linkeflist is empty!\n");return false;}//从首结点开始遍历while(Phead->next){//把头结点的直接后继作为新的头结点Phead = Phead->next;//输出头结点的直接后继的数据域printf("data = %d\n",Phead->data);//判断是否到达尾结点,尾结点的next指针是指向首结点的地址if (Phead->next == Head->next){break;} }return true;
}根据情况把新结点插入到链表中,此时可以分为尾部插入、头部插入、指定位置插入:
头插
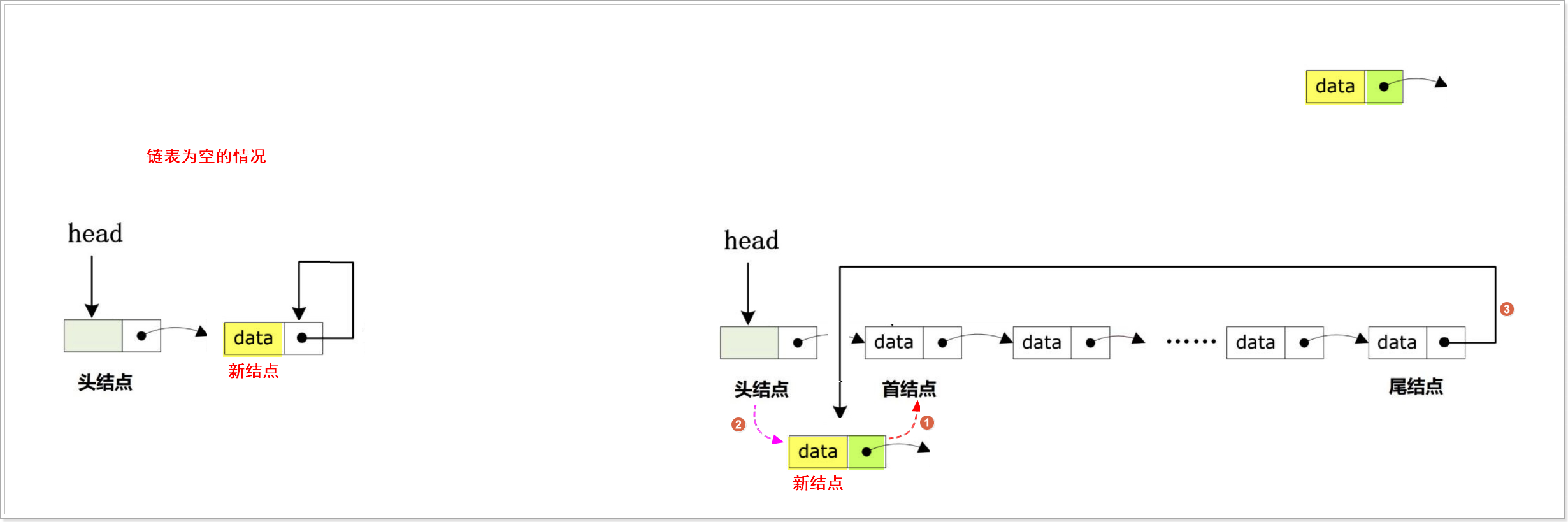
bool CircLList_HeadInsert(CircLList_t *Head, DataType_t data)
{CircLList_t *Phead = Head; //备份头结点的地址//1.创建新的结点,并对新结点进行初始化CircLList_t *New = CircLList_NewNode(data);if (NULL == New){printf("can not insert new node\n");return false;}//2.判断链表是否为空,如果为空,则把新结点作为首结点,体现“循环”if (Head->next == Head){Head->next = New;New->next = New;return true;}//3.如果链表是非空的,则需要对尾结点的next指针进行处理,指向首结点while(Phead->next){Phead = Phead->next;if ( Phead->next == Head->next ){break;}}Phead->next = New; //尾结点的next指针指向新的首结点New->next = Head->next; //新结点的next指针指向原本的首结点Head->next = New; //更新首结点地址,让头结点的next指针指向新结点return true;
}尾插
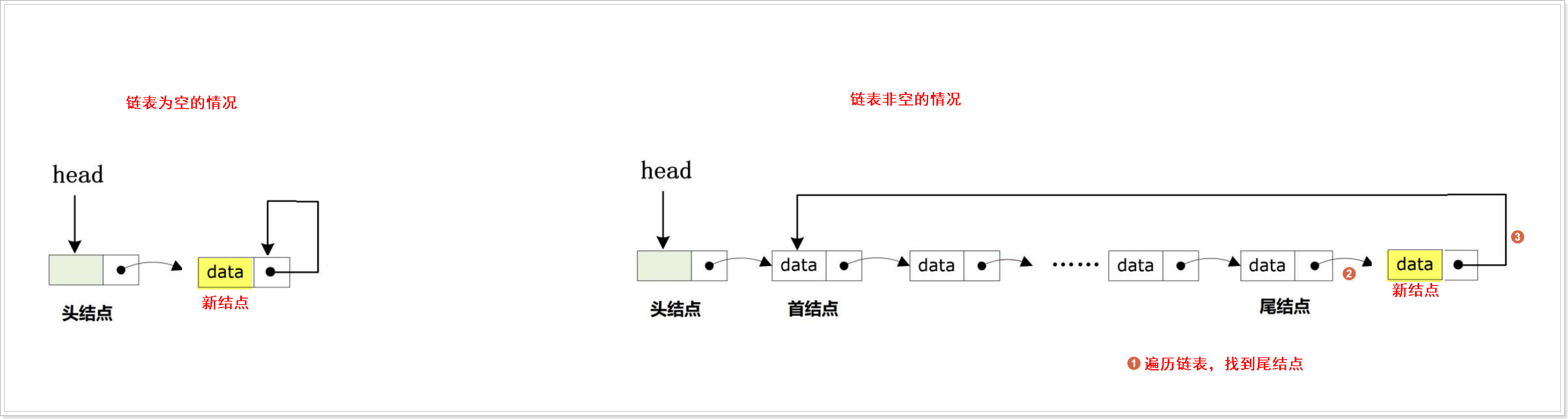
bool CircLList_TailInsert(CircLList_t *Head, DataType_t data)
{CircLList_t *Phead = Head; //备份头结点的地址//1.创建新的结点,并对新结点进行初始化CircLList_t *New = CircLList_NewNode(data);if (NULL == New){printf("can not insert new node\n");return false;}//2.判断链表是否为空,如果为空,则把新结点作为首结点,体现“循环”if (Head->next == Head){Head->next = New;New->next = New;return true;}//3.如果链表是非空的,则需要对尾结点的next指针进行处理,指向首结点while(Phead->next){Phead = Phead->next;if ( Phead->next == Head->next ){break;}}Phead->next = New; //旧的尾结点的next指针指向新结点New->next = Head->next; //新结点的next指针指向首结点地址return true;
}指定位置后插入
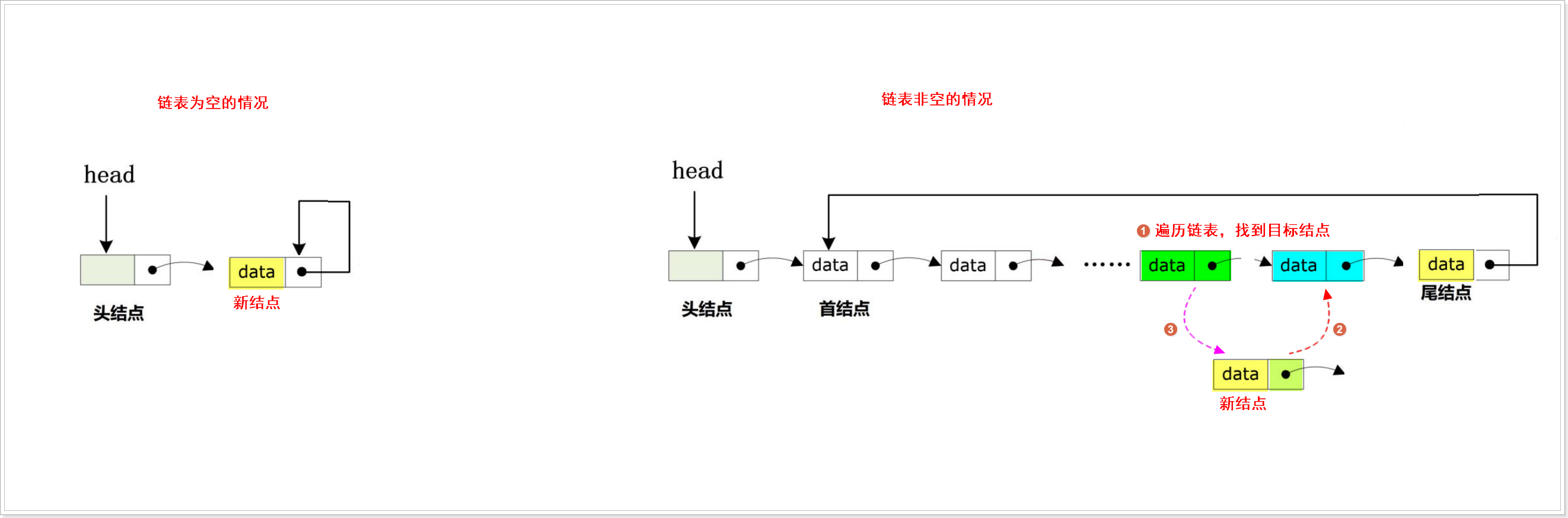
bool CircLList_TailInsert(CircLList_t *Head, DataType_t data)
{CircLList_t *Phead = Head; //备份头结点的地址//1.创建新的结点,并对新结点进行初始化CircLList_t *New = CircLList_NewNode(data);if (NULL == New){printf("can not insert new node\n");return false;}//2.判断链表是否为空,如果为空,则把新结点作为首结点,体现“循环”if (Head->next == Head){Head->next = New;New->next = New;return true;}//3.如果链表是非空的,则需要对指定位置结点的指针进行处理while (Phead->next){if (Phead->data == Data) {New->next = Phead->next;Phead->next = New;return true;}Phead = Phead->nextif(Phead == Head->next)break;Phead = Phead->next;}
}根据情况可以从链表中删除某结点,此时可以分为尾部删除、头部删除、指定元素删除:
头删

//头删
bool LList_HeadDel(LList_t *Head)
{//对单向循环链表的头结点的地址进行备份CircLList_t *Phead = Head;//对单向循环链表的首结点的地址进行备份CircLList_t *Temp = Head->next;//2.判断链表是否为空,如果为空,则退出if (Head->next == Head){printf("Linkedlist is Empty\n");return false;}//3.判断链表中是否只有首结点if ( Head->next == Head->next->next ){Temp->next = NULL; //首结点的next指针指向NULLHead->next = Head; //头结点的next指针指向头结点,体现“循环”free(Temp); //释放结点内存return true;} //4.如果链表是非空的,则需要对尾结点的next指针进行处理,指向新的首结点while(Phead->next){Phead = Phead->next;if ( Phead->next == Temp ) //遍历到尾结点{break;}}Phead->next = Temp->next ; //让尾结点的next指针指向新的首结点Head->next = Phead->next; //更新首结点,让头结点的next指针指向新的首结点Temp->next = NULL; //旧的首结点的next指针指向NULL,从链表中断开free(Temp); //释放待删除结点的内存return true;
}尾删
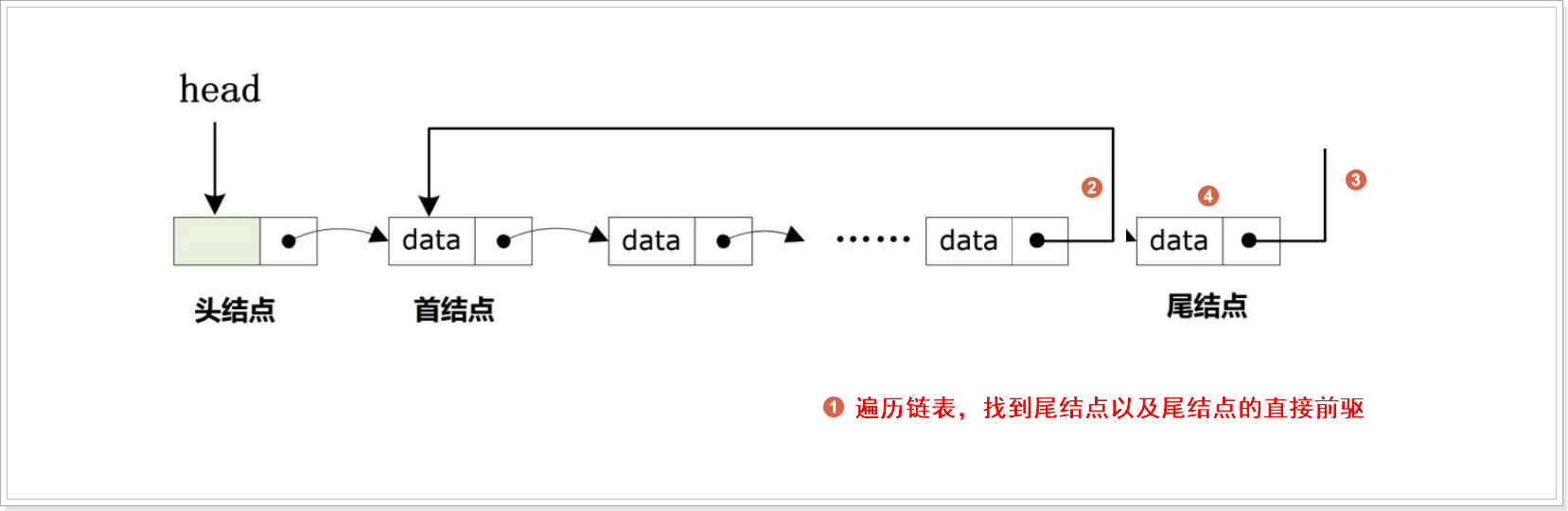
//头删
bool LList_HeadDel(LList_t *Head)
{//对单向循环链表的头结点的地址进行备份CircLList_t *Phead = Head;//对单向循环链表的首结点的地址进行备份CircLList_t *Temp = Head->next;//2.判断链表是否为空,如果为空,则退出if (Head->next == Head){printf("Linkedlist is Empty\n");return false;}//3.判断链表中是否只有尾结点if ( Head->next == Head->next->next ){Temp->next = NULL; //首结点的next指针指向NULLHead->next = Head; //头结点的next指针指向头结点,体现“循环”free(Temp); //释放结点内存return true;} //4.如果链表是非空的,则需要对尾结点的next指针进行处理,指向新的首结点while(Phead->next){Phead_prv = Phead //保存尾结点直接前驱的地址Phead = Phead->next;if ( Phead->next == Temp ) //遍历到尾结点{break;}}Phead_prv->next = Temp ; //让尾结点的直接前驱指向首节点Phead->next = NULL; //尾结点的next指针指向NULL,从链表中断开free(Phead); //释放待删除结点的内存return true;
}指定删
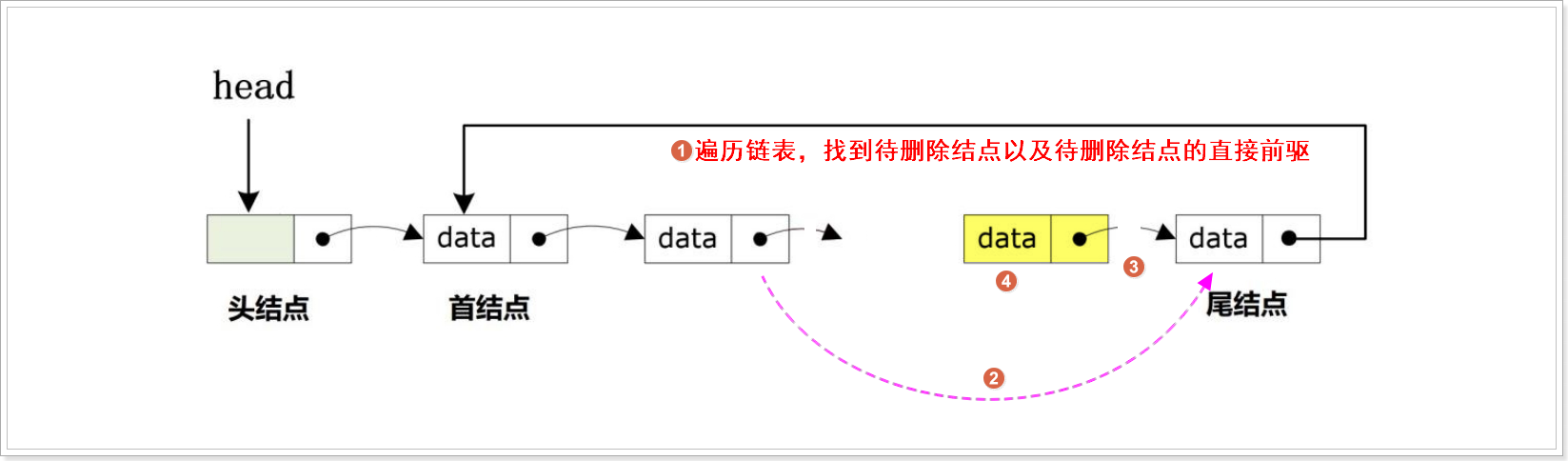
双向链表的原理与应用
如果想要提高单向链表或者单向循环链表的访问速度,则可以在链表中的结点中再添加一个指针域,让新添加的指针域指向当前结点的直接前驱的地址,也就意味着一个结点中有两个指针域(prev + next),也被称为双向链表(Double Linked List)。
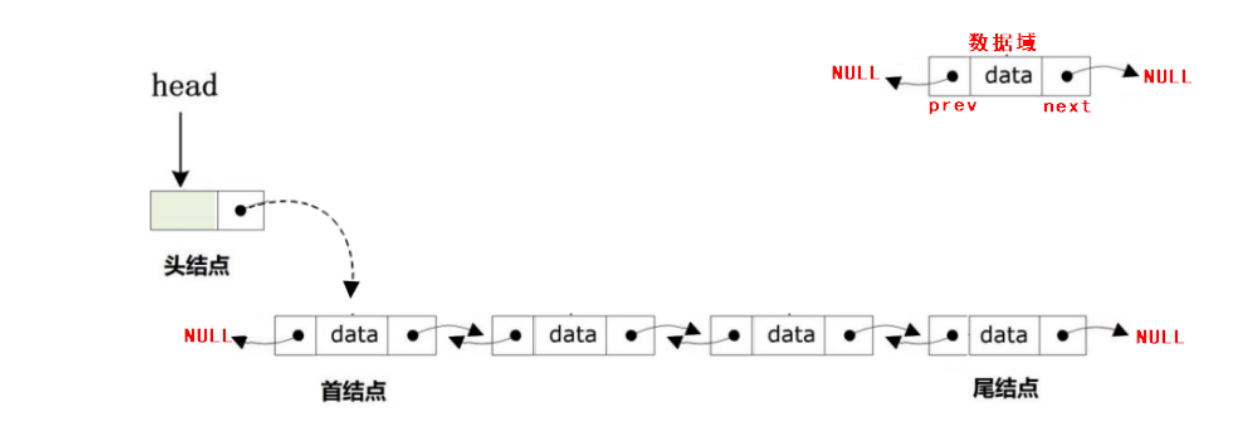
由于带头结点更加方便用户进行数据访问,所以本次创建一条带头结点的双向不循环的链表。
//指的是双向链表中的结点有效数据类型,用户可以根据需要进行修改
typedef int DataType_t;//构造双向链表的结点,链表中所有结点的数据类型应该是相同的
typedef struct DoubleLinkedList
{DataType_t data; //结点的数据域struct DoubleLinkedList *prev; //直接前驱的指针域struct DoubleLinkedList *next; //直接后继的指针域}DoubleLList_t;创建一个空链表,由于是使用头结点,所以就需要申请头结点的堆内存并初始化即可!
//创建一个空双向链表,空链表应该有一个头结点,对链表进行初始化
DoubleLList_t * DoubleLList_Create(void)
{//1.创建一个头结点并对头结点申请内存DoubleLList_t *Head = (DoubleLList_t *)calloc(1,sizeof(DoubleLList_t));if (NULL == Head){perror("Calloc memory for Head is Failed");exit(-1);}//2.对头结点进行初始化,头结点是不存储数据域,指针域指向NULLHead->prev = NULL;Head->next = NULL;//3.把头结点的地址返回即可return Head;
}创建新结点,为新结点申请堆内存并对新结点的数据域和指针域进行初始化,操作如下:
DoubleLList_t * DoubleLList_NewNode(DataType_t data)
{//1.创建一个新结点并对新结点申请内存DoubleLList_t *New = (DoubleLList_t *)calloc(1,sizeof(DoubleLList_t));if (NULL == New){perror("Calloc memory for NewNode is Failed");return NULL;}//2.对新结点的数据域和指针域(2个)进行初始化New->data = data;New->prev = NULL;New->next = NULL;return New;
}根据情况可以从链表中插入新结点,此时可以分为尾部插入、头部插入、指定位置插入:
头插
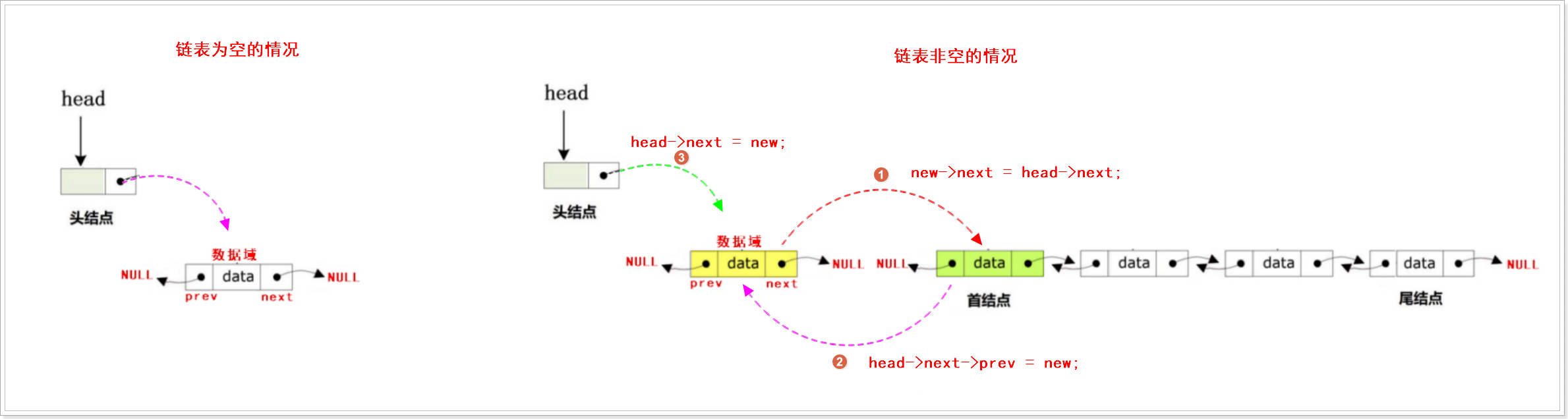
//头插
bool DoubleList_HeadInsert(DoubleList_t * Head, DataType_t data)
{//1.创建新结点并对新结点进行初始化DoubleList_t * New = DoubleList_NewNode(data);if (NULL == New){printf("can not insert new node\n");return false;}//2.判断双向链表是否为空,如果为空,则直接插入到头结点之后if (NULL == Head->next){Head->next = New; //让头结点的next指针指向新结点return true;}//3.如果双向链表为非空,则把新结点插入到链表的头部New->next = Head->next; //新结点的next指针指向原本的首结点地址Head->next->prev = New; //原本的首结点的prev指针指向新结点的地址Head->next = New; //更新头结点的next指针,让next指针指向新结点的地址return true;
}尾插
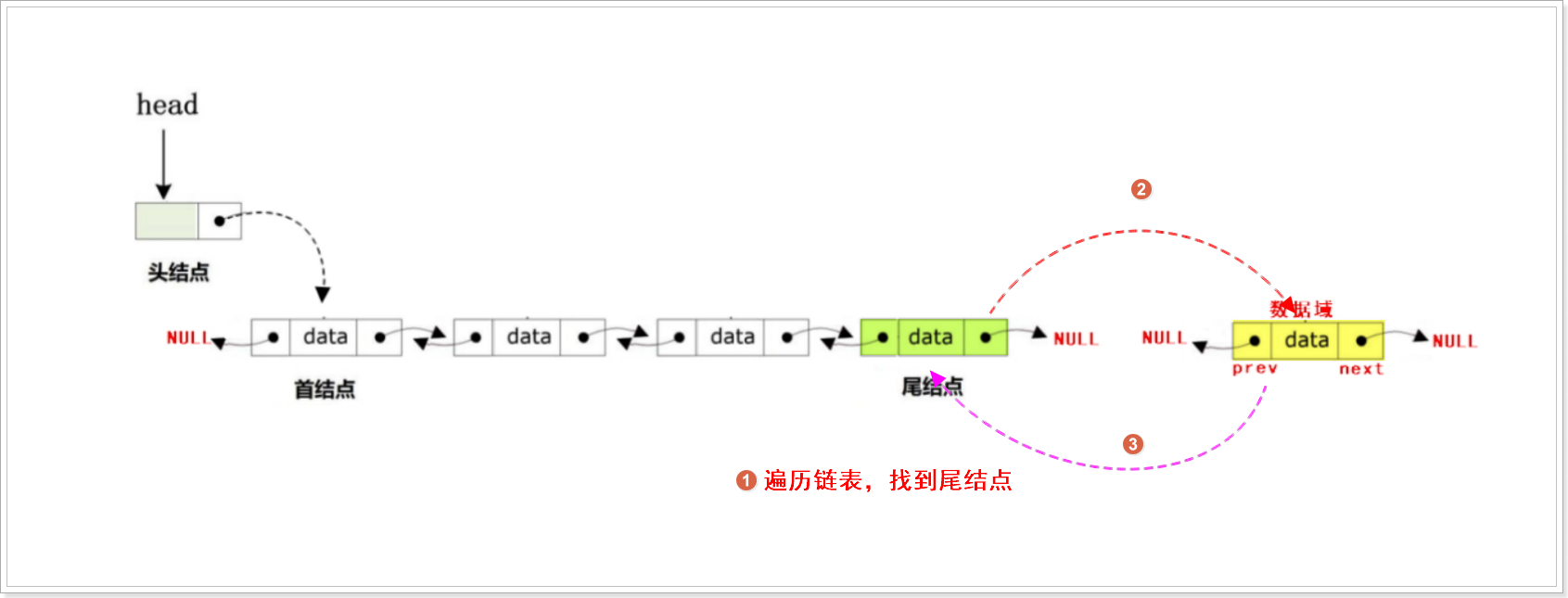
//尾插
bool DoubleList_TailInsert(DoubleList_t * Head, DataType_t data)
{DoubleList_t * Phead = Head; //备份头结点地址,防止头结点丢失//1.创建新结点并对新结点进行初始化DoubleList_t * New = DoubleList_NewNode(data);if (NULL == New){printf("can not insert new node\n");return false;}//2.判断双向链表是否为空,如果为空,则直接插入到头结点之后if (NULL == Head->next){Head->next = New; //让头结点的next指针指向新结点return true;}//3.如果双向链表为非空,则把新结点插入到链表的尾部while(Phead->next){Phead = Phead->next;}Phead->next = New; //尾结点的next指针指向新结点地址New->prev = Phead; //新结点的prev指针指向原本的尾结点地址return true;
}指定插
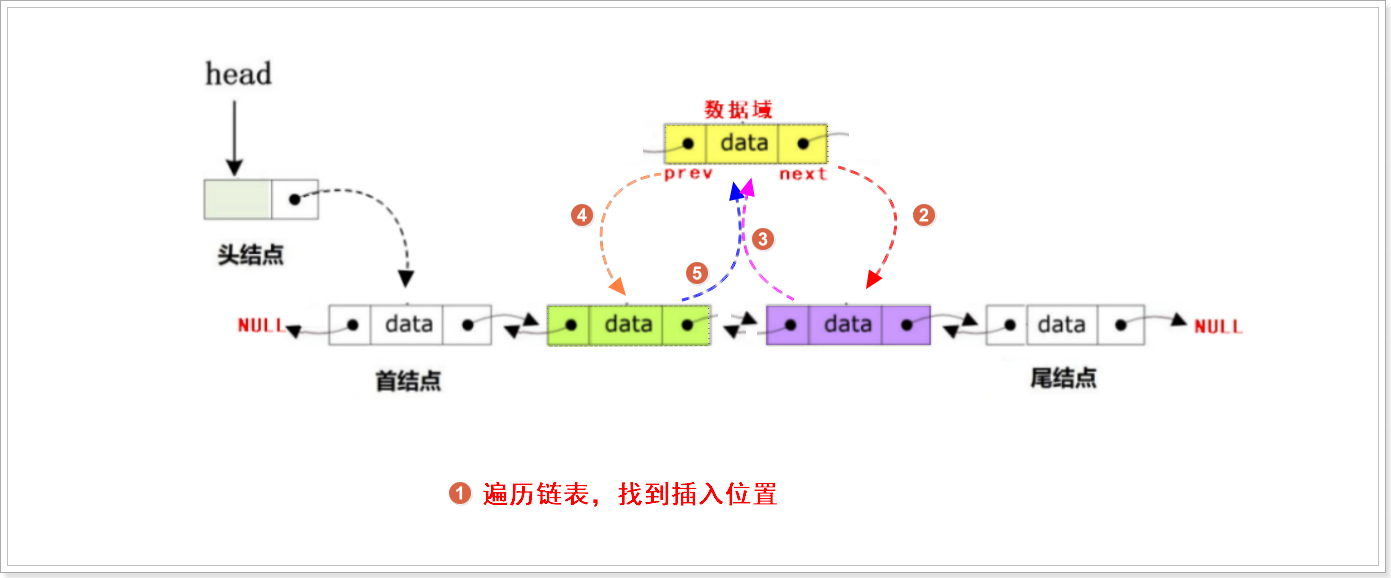
根据情况可以从链表中删除某结点,此时可以分为尾部删除、头部删除、指定结点删除:
//指定位置插入 插入目标结点之后
bool DoubleList_DestInsert(DoubleList_t *Head, DataType_t destval, DataType_t data)
{DoubleList_t * Phead = Head; //备份头结点地址,防止头结点丢失//1.创建新结点并对新结点进行初始化DoubleList_t * New = DoubleList_NewNode(data);if (NULL == New){printf("can not insert new node\n");return false;}//2.判断双向链表是否为空,如果为空,则直接插入到头结点之后if (NULL == Head->next){Head->next = New; //让头结点的next指针指向新结点return true;}//3.如果双向链表为非空,此时分为3种情况(尾部 or 中间)while(Phead->next){Phead = Phead->next;if (Phead->data == destval){break;}}//如果遍历链表之后发现没有目标结点,则退出即可if (Phead->next == NULL && Phead->data != destval){printf("dest node is not found\n");return false;}//如果遍历链表找到目标结点,则分为(尾部 or 中间)if(Phead->next == NULL) //尾插{New->prev = Phead; //新结点的prev指针指向尾结点的地址Phead->next = New; //尾结点的next指针指向新结点}else //中间{New->next = Phead->next; // 新结点的next指针指向目标结点的直接后继结点New->prev = Phead; // 新结点的prev指针指向目标结点的地址Phead->next->prev = New; // 目标结点的直接后继结点的prev指针指向新结点Phead->next = New; // 目标结点的next指针指向新结点}return true;
}头删
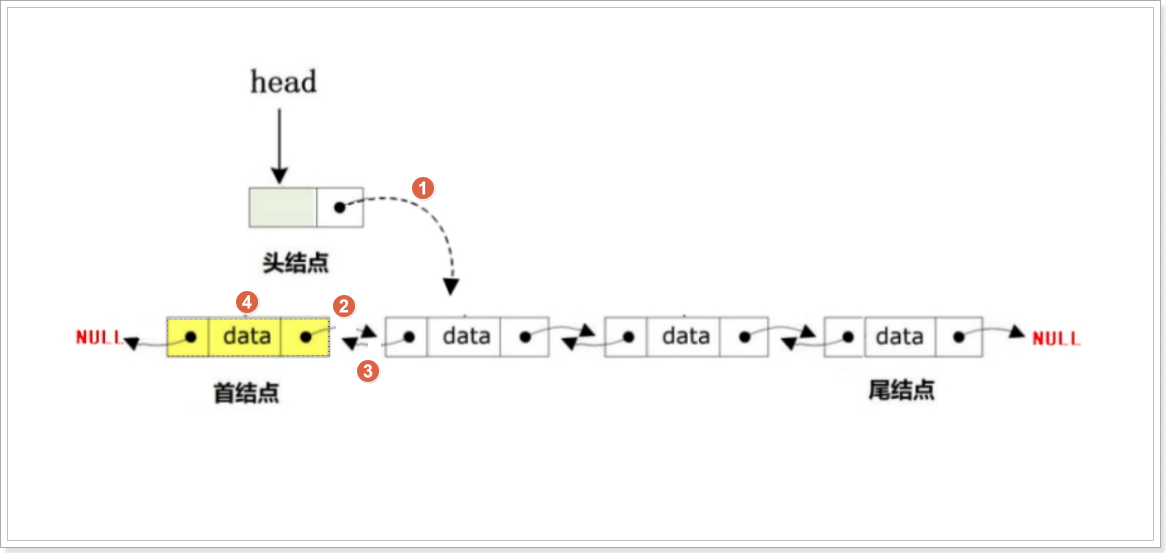
//头删
bool DoubleList_HeadDel(DoubleList_t *Head)
{//对双向链表的首结点的地址进行备份DoubleList_t *Temp = Head->next;//2.判断链表是否为空,如果为空,则退出if (Head->next == NULL){printf("DoubleList is Empty\n");return false;}//3.判断链表中是否只有首结点if (Temp->next != NULL) // 如果链表不止一个节点{ Temp->next->prev = NULL; // 新首节点的prev置为NULL}//4.如果链表是非空的,则需要对头结点的next指针进行处理,指向新的首结点Head->next = Temp->next; //头结点的next指针进行处理,指向新的首结点Temp->next = NULL; //旧的首节点next指向NULLfree(Temp); //释放待删除结点的内存return true;
}如果没有 if (Thead->next != NULL) 这个条件判断,直接写 Thead->next->prev = NULL ,会产生以下严重后果:当只有一个结点时, Thead->next 的值为 NULL 。因为尾节点的 next 指针指向 NULL ,表示链表结束。如果直接执行Thead->next->prev = NULL ,就相当于对一个空指针进行解引用操作,去访问它的成员 prev 。在 C 语言中,这是不允许的,会导致程序崩溃,抛出类似 “Segmentation fault(段错误)” 这样的运行时错误。
尾删
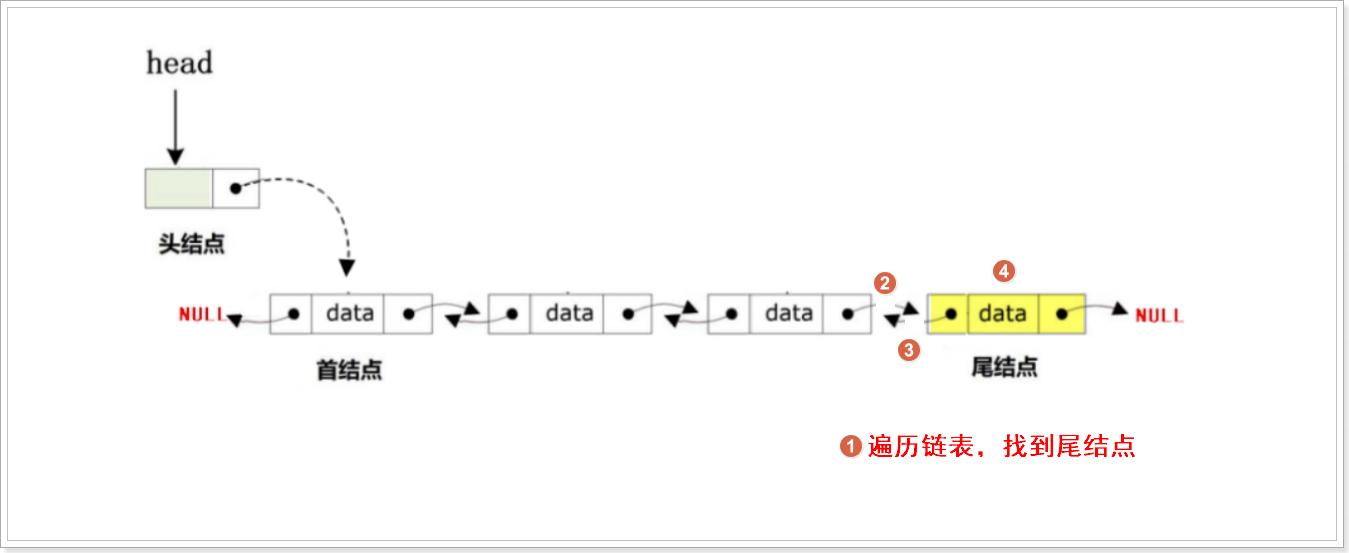
// 尾删
bool DoubleList_TailDel(DoubleList_t *Head)
{// 备份头结点的地址DoubleList_t *Phead = Head;// 判断链表是否为空,如果为空则退出if (Head->next == NULL){printf("DoubleList is Empty\n");return false;}// 遍历到尾结点while (Phead->next != NULL){Phead = Phead->next;}// 获取尾结点的前驱结点DoubleList_t *Prev = Phead->prev;// 如果存在前驱结点(即链表不止一个节点)if (Prev != NULL){Prev->next = NULL; // 前驱结点的next指向NULL}else{Head->next = NULL; // 如果无前驱,说明删除后链表为空}// 释放尾结点内存free(Phead);return true;
}指定删
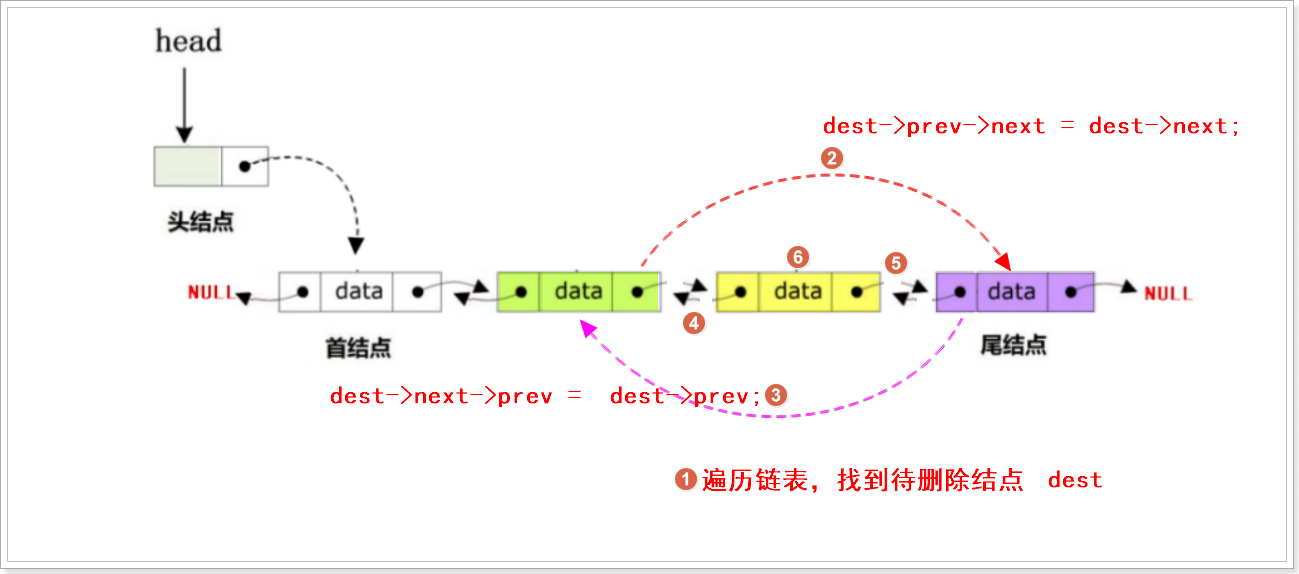
//指定删除
bool DoubleList_DestDel(DoubleList_t * Head, DataType_t destval)
{DoubleList_t * Phead = Head; //备份头结点地址,防止头结点丢失//1.判断双向链表是否为空,如果为空,则删除失败if (NULL == Head->next){printf("linked list is empty\n");return false;}//2.如果双向链表为非空,此时遍历链表查找没有目标结点while(Phead->next){Phead = Phead->next;if (Phead->data == destval){break;}}//如果链表中没有目标结点,此时直接退出即可if (Phead->next == NULL && Phead->data != destval){printf("dest node is not found\n");return false;}//如果链表中发现目标结点,此时分为(头部 or 尾部 or 中间)if(Phead == Head->next) //头部{Head->next = Phead->next; //更新头结点,让头结点的next指针指向首结点的直接后继if (Phead->next != NULL) //如果待删除节点的下一个节点存在,则将其 prev 置为 NULL,确保新头节点的前驱正确。{Phead->next->prev = NULL;}Phead->next = NULL;free(Phead); //释放待删除结点内存}else if(Phead->next == NULL) //尾部{Phead->prev->next = NULL; //尾结点的直接前驱结点的next指针指向NULLPhead->prev = NULL; //尾结点的prev指针指向NULLfree(Phead); //释放待删除结点内存}else //中间{Phead->prev->next = Phead->next; //让待删除结点的直接前驱结点的next指针指向待删除结点的直接后继Phead->next->prev = Phead->prev; //让待删除结点的直接后继结点的prev指针指向待删除结点的直接前驱地址Phead->next = NULL; //让待删除结点的next指针指向NULLPhead->prev = NULL; //让待删除结点的prev指针指向NULLfree(Phead); //释放待删除结点内存}return true;
}练习题

A :双链表在插入和删除时,需要同时调整前驱和后继指针,操作并不比单链表简单,所以 A 选项错误。
B:单链表和双链表都不支持随机访问
C:双链表无论是表头指针还是表尾指针都很重要,都不能省略,因为双链表的遍历、插入和删除等操作往往需要借助表头指针或表尾指针来进行定位起始位置等操作\
D:单链表中每个结点只有一个指向后继的指针,若要访问前驱结点,只能从头开始遍历链表。而双链表的每个结点既有指向后继的指针,又有指向前驱的指针 ,可以方便灵活地访问前后相邻结点,所以 D 选项正确。

A:p->next=q; 这一步执行后,p 原来的后继结点就丢失了,后续再执行 q->next=p->next; 无法正确设置 q 的后继
B:操作顺序符合上述在双向链表中 p 结点后插入 q 结点的步骤,要记住插入动作要先连接在断开
C:同 A
D:同 A

A:p->prior=q; 这一步直接改变 p 的前驱,后续 p->prior->next=q; 操作时,由于 p 的前驱已经改变,会导致逻辑错误
B:p->prior=q->next; 这里逻辑混乱,q->next 指向的是 p ,将其赋给 p->prior 不符合在 p 前插入 q 的指针调整逻辑
C:q->next=p; p->next=q; 这两步操作错误,在双向链表中在 p 前插入 q ,不应该改变 p 的后继,且后续指针调整逻辑也混乱
D:对

A:对
B:p->prior = p->prior->prior; 这一步将 p 的前驱指向了 p 前驱的前驱,逻辑混乱;p->prior->prior = p; 也不符合双向链表删除结点的指针调整规则,会导致链表结构错误
C:p->next->prior = p; 这一步错误地将 p 后继的前驱又指向了 p ,没有达到删除 p 的目的;p->next = p->next->next; 也不能正确调整指针
D:p->next = p->prior->prior; 和 p->prior = p->prior->prior; 这两步操作不符合双向链表删除结点时调整指针的逻辑,会使链表结构出错

A:顺序表:它可以通过数组下标直接随机存取任一指定序号的元素,时间复杂度为O(1) 。在顺序表最后进行插入和删除运算时,若不涉及扩容等操作 ,插入和删除的时间复杂度也较低,插入平均时间复杂度为 O(1)(不考虑扩容) ,删除平均时间复杂度为 O(1)(不考虑元素移动后的整理等额外操作),所以顺序表能满足最常用操作的高效需求。
B:双链表:双链表不支持随机存取,要存取指定序号的元素,需要从表头或表尾开始遍历,时间复杂度为 O(n)
C:双循环链表:和双链表类似,不支持随机存取,存取指定序号元素需遍历,时间复杂度为 O(n)
D:单循环链表:同样不支持随机存取,存取指定序号元素要遍历链表,时间复杂度为 O(n)

A:单链表:在单链表中,在最后一个元素之后插入元素,需要遍历整个链表找到尾节点,时间复杂度为 O(n) ;删除第一个元素,虽然时间复杂度为 O(1),但插入操作效率低,不满足最常用操作高效的要求。
B:不带头结点的单循环链表:插入最后一个元素需要遍历链表找尾节点,时间复杂度 O(n) ;删除第一个元素时,因为没有头结点辅助,还需要先找到尾节点使其 next 指向第二个节点,操作相对复杂,时间复杂度也较高,整体不满足要求。
C:双链表:在双链表中,删除第一个元素时间复杂度为 O(1),但在最后一个元素之后插入元素,需要遍历链表找到尾节点(虽然可以从表头或表尾双向遍历,但仍需一定时间),时间复杂度为 O(n) ,不是最节省时间的。
D:不带头结点且有尾指针的单循环链表:有尾指针,在最后一个元素之后插入元素时,可直接利用尾指针,时间复杂度为 O(1);删除第一个元素时,可通过尾指针找到第一个元素(尾指针的 next 指向第一个元素),然后调整指针完成删除,时间复杂度也为 O(1) ,能高效满足最常用的两种操作,最节省运算时间。

A:在顺序表中,由于元素是连续存储的,可通过数组下标直接访问第i个元素,时间复杂度为O(1)。
B:效率一样
C:效率一样
D:效率一样