图论学习笔记 5 - 最小树形图
我们不废话,直接进入正题:最小树形图,一个名字看起来很高级的东西。
声明:为了便于理解,可能图片数量会有亿点点多。图片尺寸可能有的较大。
概念
最小树形图的英文是 Directed Minimum Spanning Tree。
相信懂英文的同学都知道,Minimum Spanning Tree 这依托东西的英文就是 MST,也就是最小生成树。
前面有一个 Directed(有向 的意思)就是最小生成树的一个有向的版本(所以说这个“最小树形图”的名字感觉很诈骗)。显然任意树形图的边数一定是点数 − 1 -1 −1。
最小生成树的内容是属于基础图论,但最小树形图属于高级图论,其间肯定有什么东西使得这两个东西差别巨大:
-
首先,最小树形图相对于最小生成树的边从无向变成了有向。则最小树形图除了连通性问题其他的都应该和最小生成树的标准一样。
-
其次,一棵有向树并不是只需要满足弱连通就是树形图,ta 需要满足从一个根结点都可以通过走有向边到达所有的点(如图一)。 或者是 一个根结点都可以通过走有向边被所有的点到达(如图二)。(显然自己可以到达自己)
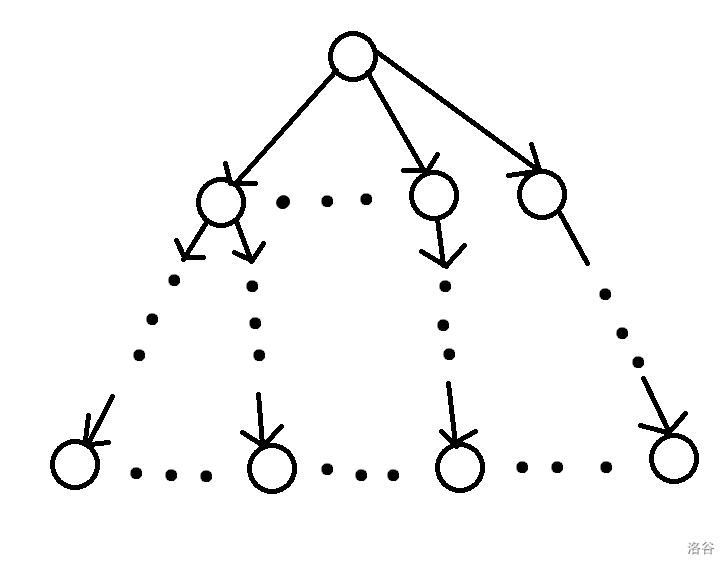
上面的就是一个树形图。
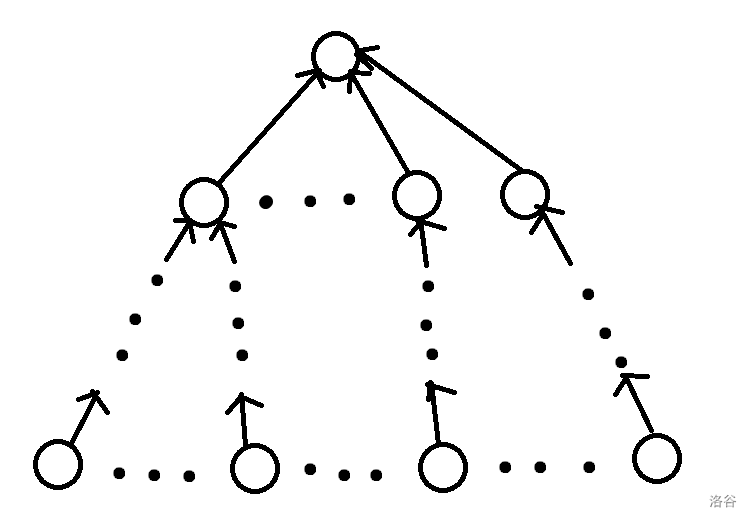
上面的也是一个树形图。可以发现,树形图无非就这两种情况。
很容易发现,最小树形图相比最小生成树难度飙升的一个点就是边的方向有了限制。
最小生成树求解的时候,使用了并查集判断连通性,而且还证明了贪心方法是正确的。
但是最小树形图显然不能使用并查集,而且贪心方法我们目前也不知道是否正确(可能选了一条边后面就甚至不会产生最小树形图)。乍一看就复杂了许多。
所以最小树形图和最小生成树的求解方法没有多大相同点。
求解 - 朱刘算法
在前面有两个是一棵有向树成为树形图的条件,显然后面一个条件就是前面那个条件的反着来。
所以当得到了求满足第一个条件的最小树形图的方法的时候,将图的边全部反向就可以使用同样的方法求出满足第二个条件的最小树形图。
感觉这个算法涉及到的结论真的有点多教练讲这个东西的时候我都快被绕死了。 数了数有三个比较重要的结论,构成了朱刘算法。
这个时候就要请出我们的主角——朱 - 刘算法(Chu - Liu Algorithm)。其可以求满足从一个根结点都可以通过走有向边到达所有的点的最小树形图。
考虑观察最小树形图的形状(就是我给出来的第一张图),发现根结点的入度为 0 0 0,而其他的结点的入度为 1 1 1,即恰有一条入边。这是我们对最小树形图的结构的一个比较重要的把握。
所以,就对于每一个点,可以记录它的入边列表。然后对于每一个点,就可以从入边列表里面选择一条入边,选择 n − 1 n-1 n−1 条入边,使这 n − 1 n-1 n−1 条入边的权值和最小,而且在中间无环就可以构成一个满足条件的树形图。
至于为什么 n − 1 n-1 n−1 个点选择一条入边,而且不构成环就是一个满足条件的树形图,可以自己尝试证明,感觉比较显然:
前面就已经保证了有 n − 1 n-1 n−1 条边,而且每一个点入度为 1 1 1。只要满足后面的不构成环的条件,就可以确定此时的点数也是 n n n,就可以说明这是一个树形图。
假设我们目前已经得到了 n − 1 n-1 n−1 条权值和最小的入边,但是不知道有没有环。
考虑结束条件,不难发现:
-
如果没有环,就直接结束,选用这些边。
-
如果存在某一个点没有入边,就可以直接结束,很容易发现这种情况下不会存在最小树形图。
那么如果这个时候没有结束,就说明肯定答案存在,只不过是我们现在还没有找到而已。
继续考虑挖掘性质。不难发现此时得出来的有环树形图的根结点形成树,其他连通块里面是内向基环树。
这太突然了,why?
口胡证明:首先考虑根的位置,很容易发现有且仅有根没有入边,也就是边数比点数少一个 1 1 1,因为这是一个连通块,没有多余的边来形成环。
对于其他的连通块,很容易发现有多少点就有多少边,根据图论基础知识可得这些连通块构成了一个外向基环树森林。
注意: 此时所讲的外向基环树和前面的内向基环树有出入。实际上入度都为 1 1 1 的树是外向基环树,但是待会我们要换边(因为此时得出来的树形图有环)的时候记录的却是到达一个点的结点,所以可以看成把边反向变成有一条出边,也可以就看作内向基环树。在后面处理答案的前面会先将图的边的顺序反向。且在后面为了便于表述,把外向基环树看作是内向基环树。
既然已经发现根结点的弱连通块形成的是一棵树,那么就不管它了。考虑其他的内向基环树森林。
此时又有一个很重要的结论,直接就把题目给解决了:
- 对于某一个大小为 n n n 的环,如果其最小入边方案(即每一个点的入边选最小的)恰好构成了环(也就是不能这么选),那么其最小可行的方案一定是保留其中 n − 1 n-1 n−1 条边,某一个点放弃其环上入边,并改选环外来源入边。
很显然上面加粗的部分会使答案增大,所以可以依靠贪心思想来使增大的部分最小。
如果还是带有环的话,将其缩成一个点(这个环已经不会再产生贡献了),然后继续重复这个过程。复杂度为 O ( n m ) O(nm) O(nm)。
于是就可以了,朱刘算法就这么诞生了。
朱刘算法实现
#include <bits/stdc++.h>
#define int long long
using namespace std;
int n, m, r;
const int N = 210;struct edge {int f, val;
};
vector<edge> v[N];
int mn[N], fr[N], fa[N], cnt;int find(int x) {//并查集(查询所属结点,也是用来判断有没有被缩点)if (x == fa[x])return x;return fa[x] = find(fa[x]);
}int chuliu(int rt) {cnt = n;for (int i = 1; i <= n; i++)fa[i] = i;//初始化int in = 0;//缩点中选择的环边bool f = 0;//有没有找到环while (1) {//一直循环找环int sum = 0;for (int i = 1; i <= cnt; i++)//选取每一个结点最小的入边,并判断是否无解if (fa[i] == i && i != rt) {mn[i] = 1e16;for (auto [x, y] : v[i])if (find(i) != find(x) && y < mn[i])mn[i] = y, fr[i] = find(x);//fr[i]记录i在内向基环树里面的后继if (mn[i] == 1e16)//找不到一条入边,无解return -1;sum += mn[i];}bool vis[N] = {0}, stk[N] = {0};//是否访问,当前是否在栈里面vis[rt] = 1, f = 0;//要避免根被访问(要不然就废了)for (int i = 1; i <= cnt && !f; i++)//这里我们使用循环来简化搜索if (fa[i] == i && !vis[i]) {//如果没有被访问到for (int x = i; !vis[x] && !f; x = fr[x]) {//搜索vis[x] = stk[x] = 1;if (stk[fr[x]]) {//找到了一个环,说明这个时候要考虑换边cnt++, fa[cnt] = cnt;//增加一个点(实际上是一个环)for (int j = x; j != x || find(j) != cnt; j = fr[j]) {//对环进行了循环,即找到环里面的所有点fa[j] = cnt, in += mn[j];//缩点for (int k = 0; k < v[j].size(); k++)v[cnt].push_back({v[j][k].f, v[j][k].val - mn[j]});//计算权值(这时候要换边)}f = 1;}}for (int x = i; stk[x]; x = fr[x])stk[x] = 0;//取消stk标记}if (!f)return sum + in;//缩点已经形成的环内点的值 + 此时的树边的值}
}signed main() {cin >> n >> m >> r;for (int i = 1; i <= m; i++) {int x, y, z;cin >> x >> y >> z;v[y].push_back({x, z});//为了跑朱刘算法,要存反边}cout << chuliu(r) << endl;return 0;
}可合并堆 - 左偏树
| 数据结构 | 查找最值top() | 删除最值pop() | 插入push() | 修改关键字modify() | 合并merge |
|---|---|---|---|---|---|
| 二叉堆(优先队列) | Θ ( 1 ) \Theta(1) Θ(1) | Θ ( log n ) \Theta(\log n) Θ(logn) | Θ ( log n ) \Theta(\log n) Θ(logn) | Θ ( log n ) \Theta(\log n) Θ(logn) | Θ ( n ) \Theta(n) Θ(n) |
| 左偏树 | Θ ( 1 ) \Theta(1) Θ(1) | Θ ( log n ) \Theta(\log n) Θ(logn) | Θ ( log n ) \Theta(\log n) Θ(logn) | Θ ( log n ) \Theta(\log n) Θ(logn) | Θ ( log n ) \Theta(\log n) Θ(logn) |
| 二项堆 | Θ ( 1 ) \Theta(1) Θ(1) | Θ ( log n ) \Theta(\log n) Θ(logn) | Θ ( 1 ) \Theta(1) Θ(1) | Θ ( log n ) \Theta(\log n) Θ(logn) | Θ ( log n ) \Theta(\log n) Θ(logn) |
| 斜二项堆 | Θ ( 1 ) \Theta(1) Θ(1) | Θ ( log n ) \Theta(\log n) Θ(logn) | Θ ( 1 ) \Theta(1) Θ(1) | Θ ( log n ) \Theta(\log n) Θ(logn) | Θ ( log n ) \Theta(\log n) Θ(logn) |
| 配对堆 | Θ ( 1 ) \Theta(1) Θ(1) | Θ ( log n ) \Theta(\log n) Θ(logn) | Θ ( 1 ) \Theta(1) Θ(1) | Θ ( log n ) \Theta(\log n) Θ(logn) | Θ ( 1 ) \Theta(1) Θ(1) |
| 带秩配对堆 | Θ ( 1 ) \Theta(1) Θ(1) | Θ ( log n ) \Theta(\log n) Θ(logn) | Θ ( 1 ) \Theta(1) Θ(1) | Θ ( 1 ) \Theta(1) Θ(1) | Θ ( 1 ) \Theta(1) Θ(1) |
| 斐波那契堆 | Θ ( 1 ) \Theta(1) Θ(1) | Θ ( log n ) \Theta(\log n) Θ(logn) | Θ ( 1 ) \Theta(1) Θ(1) | Θ ( 1 ) \Theta(1) Θ(1) | Θ ( 1 ) \Theta(1) Θ(1) |
| 严格斐波那契堆 | Θ ( 1 ) \Theta(1) Θ(1) | Θ ( log n ) \Theta(\log n) Θ(logn) | Θ ( 1 ) \Theta(1) Θ(1) | Θ ( 1 ) \Theta(1) Θ(1) | Θ ( 1 ) \Theta(1) Θ(1) |
| 布罗达尔堆 | Θ ( 1 ) \Theta(1) Θ(1) | Θ ( log n ) \Theta(\log n) Θ(logn) | Θ ( 1 ) \Theta(1) Θ(1) | Θ ( 1 ) \Theta(1) Θ(1) | Θ ( 1 ) \Theta(1) Θ(1) |
| 2–3 堆 | Θ ( log n ) \Theta(\log n) Θ(logn) | Θ ( log n ) \Theta(\log n) Θ(logn) | Θ ( log n ) \Theta(\log n) Θ(logn) | Θ ( 1 ) \Theta(1) Θ(1) | 无 无 无 |
注释:“布罗达尔堆”的英文是 Brodal,在国内未找到合适的翻译,所以就音译了一下。
可能有人会问修改关键字是什么意思。意思就是把一个非根结点的结点来修改了,也就是modify()。
左偏树英文是 Leftist Heap / Tree。Heap 是堆的意思,所以左偏树是一种高级的堆,或者说是可合并堆。
众所周知直接对堆合并并不容易,所以可以在左偏树上面合并。
左偏树,整体来看就是像一种偏向左边的树,很容易想到完全二叉树也是一种左偏树,但是左偏树是
先来明晰一下比较基础的概念。
内部结点:指有两个子结点的点。
外部结点:指只有少于两个子结点的点。
首先,左偏树是一棵二叉树,而且是一棵二叉堆。这里记点 x x x 到最近的外部结点的距离为 d x d_x dx(很奇怪的定义),左子结点 l x l_x lx,右子结点 r x r_x rx。
将 d x d_x dx 的值称为 x x x 的深度(这里的深度不是以前的深度了)。
为了使左偏树是“左偏”的,我们要求 l x l_x lx 的深度应该 ≥ \ge ≥ r x r_x rx 的深度(如果某一个子结点不存在的话视为其深度为 0 0 0)。这是很奇怪的,但是后面就会体会到这样的用意了。
注意,一棵左偏树的子树也一定是一棵左偏树。简单归纳就可以得到。
左偏树的性质很奇妙,但是在这之前,先来看看左偏树是长什么样的。
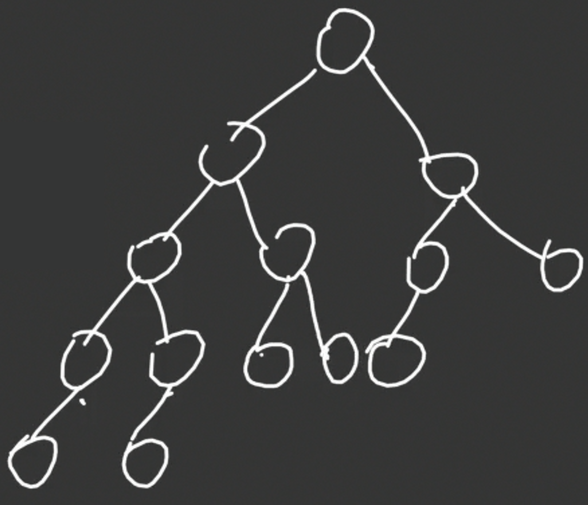
很容易标出每一个点的 d d d 值:
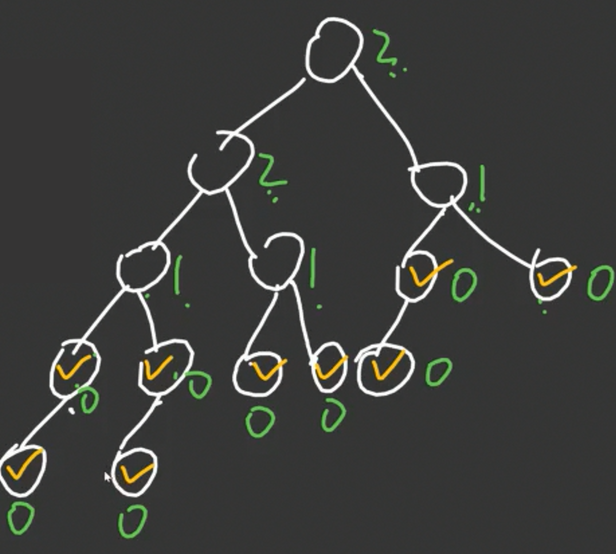
很容易发现,这是一棵左偏树,因为对于每一个点,其左儿子的深度都是大于等于右儿子的深度的。
设 r t rt rt 为左偏树的根结点。很容易发现, n ≥ 2 d r t + 1 − 1 n \ge 2^{d_{rt}+1}-1 n≥2drt+1−1,为什么呢?
因为很容易注意到左偏树的前 d r t + 1 d_{rt}+1 drt+1 层一定是一个满二叉树。因为根结点至少要走 d r t d_{rt} drt 步才能到达一个外部结点,所以每一个外部结点的深度都一定大于等于 d r t d_{rt} drt,而在此之前一定是一棵满二叉树。
也就很容易地出来这个式子了。
那么这个式子有什么用呢?很大的用处就是可以把它反过来,变成 d r t = O ( log n ) d_{rt} = O(\log n) drt=O(logn) 的级别,也就是说整棵树的深度不会太多。
其次,很容易发现 d x = d r x + 1 d_{x} = d_{r_x} + 1 dx=drx+1。
因为原本按照树形 dp 的思路来是 d x = min ( d l x , d r x ) + 1 d_x = \min(d_{l_x},d_{r_x})+1 dx=min(dlx,drx)+1,但是因为 min \min min 函数里面的前者大于后者,所以就可以把前者舍去,变成第一句话提到的式子。
一些比较浅显的东西讲完之后,接下来就到了重头戏——如何合并两个左偏树。
堆的合并需要选择某一个子树进行保留,而将另一个子树和对方的整个堆进行合并,而把对方的根结点视为我方根结点的新右子结点。而对于左偏树中一个根结点的子树,很容易发现一定是将右边的结点取合并,保留左边的结点,因为右边的子树大小比左边的子树大小要小。
而且,一个根结点最多往右走 d r t d_{rt} drt 次,所以这样就可以确定合并复杂度是 O ( log n ) O(\log n) O(logn)。
但是,我们需要保证一个左偏树和另一个左偏树合并之后还是一个左偏树,要不然下次就没法合并了。
这个很简单。当你发现两个左偏树合并之后某一个左子树的深度小于右子树,就直接交换一下左右儿子就可以了。
这就是左偏树的得天独厚的条件:很容易就可以把自己调整成一个新的左偏树。最终的合并复杂度也是 O ( log n ) O(\log n) O(logn)。
讲了这么多左偏树的好处,还没有将左偏树的增删方法(也可以说是构造方法)说了。
删除根结点:这里的方法很妙,直接合并左子树和右子树即可。注意如果不是删除根结点的话,请看下文。
加入:可以把要加入的结点看成一个树,然后把它合并到要加入的左偏树里面。
查询堆顶端的权值:可以使用类似并查集的方法来维护。(并查集立大功)
容易发现,这个时候的左偏树担任了大多数操作的主角,很多操作都可以转换为合并的问题。
左偏树实现
这是一个树状结构,至于怎么实现,还是需要好好想想。
首先,很容易想到多个堆一定要把结点存储在同一个数组里。
为什么呢?因为如果每一个左偏树都开一个结点数组,在合并的时候如果还要把每一个结点加入到对方,这样就已经达到了线性复杂度,所以不可以。而如果共享一个数组的话,每一次合并就只需要修改一下两个根结点之间的关系即可。
这里就给一个模板代码,写了我知道的所有左偏树的操作,想要 A 题直接拿这个模板改改就可以了。
模板题:P3377 【模板】左偏树/可并堆
#include <bits/stdc++.h>
#define int long long // 使用long long类型
using namespace std;// 结点结构体,存储堆中的值
struct node {int x;node() {x = 1e16; // 默认构造为极大值,表示空结点}node(int a) {x = a; // 初始化结点值为a}
} e;// 重载<运算符,实现小根堆的比较逻辑(实际比较方向相反)
bool operator<(node x, node y) {return x.x > y.x; // 注意:此处实际按x的值降序排列,用于维护小根堆
}// 左偏树(可并堆)结构体
struct lefttree {int sz = 0; // 当前结点数量(包括已删除结点)vector<int> l, r; // 左右子结点下标vector<int> d; // 结点到空结点的距离(npl)vector<int> fa; // 并查集父结点(用于快速查找根)vector<node> val; // 结点存储的值vector<bool> f; // 标记结点是否存在(是否被删除)// 并查集查找(带路径压缩)int find(int x) {return x == fa[x] ? x : fa[x] = find(fa[x]);}// 合并以x和y为根的两个堆,返回新根int merge(int x, int y) {if (!x || !y)return x + y; // 任一为空则返回非空者if (val[x] < val[y])swap(x, y); // 保证x为较小值的根(维护小根堆)fa[y] = x; // y的父结点指向xr[x] = merge(r[x], y); // 递归合并x的右子树和y// 维护左偏性质:左子树的深度不小于右子树的深度if (d[l[x]] < d[r[x]])swap(l[x], r[x]);d[x] = min(d[l[x]], d[r[x]]) + 1; // 更新当前结点的深度return x;}// 删除x所在堆的根结点void pop(int x) {int rt = find(x); // 找到根结点int nw = merge(l[rt], r[rt]); // 合并左右子树f[rt] = false; // 标记原根结点已删除fa[rt] = fa[nw] = nw; // 更新并查集父结点}// 插入新元素x,创建一个新结点void push(int x) {sz++;l.push_back(0);r.push_back(0); // 初始化左右子结点为0(空)d.push_back(0); // 初始npl为0fa.push_back(sz); // 父结点指向自己val.push_back(node(x)); // 存储结点值f.push_back(true); // 标记为存在}// 初始化左偏树void init() {sz = 0;// 清空所有数组,并添加一个占位元素(下标从1开始)l = r = d = fa = vector<int>(1);val = vector<node>(1, e); // 默认构造占位结点f = vector<bool>(1, false);}
} st;signed main() {int n, m;cin >> n >> m;st.init(); // 初始化左偏树for (int i = 1; i <= n; i++) {int x;cin >> x;st.push(x); // 插入初始元素}while (m--) {int op;cin >> op;if (op == 1) { // 合并操作int x, y;cin >> x >> y;// 若两结点均存在且不在同一堆中,则合并if (st.f[x] && st.f[y] && st.find(x) != st.find(y))st.merge(st.find(x), st.find(y));} else { // 查询并删除堆顶int x;cin >> x;if (st.f[x]) { // 若结点存在cout << st.val[st.find(x)].x << endl; // 输出堆顶值st.pop(x); // 删除堆顶} else {cout << "-1" << endl; // 堆已空}}}return 0;
}
左偏树修改关键字
前面我们提到了一个东西叫做“修改关键字”,也就是那个叫做 modify() 的函数。但是上面的空间实在不够了,所以就新开一个。
发现修改有三种:增加,删除,和修改上面的值。
增加很简单,直接就新建一棵树,然后合并到要加入的左偏树里面即可。
修改上面的值也很简单,只需要先删除在重新增加即可。问题在于如何删除任意结点。
很容易发现,如果需要 modify() 的话可以从要删除的结点合并一下左右子结点,然后从这个结点一直走祖先,每一次检查一下是否左子树的 d d d 值小于右子树的 d d d 值,如果小于就交换左右子树即可。合并一次左右子结点是 O ( log n ) O(\log n) O(logn) 的,但是从一个点一直走祖先是 O ( n ) O(n) O(n) 的。
但是我们前面提到的时间复杂度是 Θ ( log n ) \Theta(\log n) Θ(logn) 的,这就说明这种暴力的方法不是最好的。
但是,这种暴力是可以看出如何优化的痕迹的。 很容易发现,从这个要删除的结点合并左右子树之后,一定会有一段祖先的 d d d 值被影响。而且,当一个祖先的 d d d 值在操作后没有变化的话,更加上面的祖先也不会有变化。
为什么呢?因为一个点 x x x 的 d d d 值只关乎于 d l x d_{l_x} dlx 和 d r x d_{r_x} drx 这两个东西,当两个东西都没有变的时候, d x d_x dx 显然也不会改变。
所以,我们只需要走 删除结点之后 d d d 值改变 的路径即可。但是我们并不知道这条路径是多长的,还需要深度思考。
很容易发现一个事实:一个删除的点的祖先的 d d d 值一定不会增加。 这是显然的。因为这个删除的点没了,其祖先到外部点的距离很有可能会减少。
设 x x x 是删除的点的祖先,其父亲为 y y y,而且在删除结点之后 x x x 和 y y y 的 d d d 值均有改变。考虑分类讨论 x x x 相对于 y y y 的关系:
-
如果 x x x 本来就是 y y y 的右子结点。而 d x d_x dx 不会增加,所以在调整完左右子树的次序之后一定还是在右子结点。
-
如果 x x x 是 y y y 的左子结点。因为 d y = min ( d r y , d l y ) + 1 d_y = \min(d_{r_y},d_{l_y}) + 1 dy=min(dry,dly)+1 而 x = l y x = l_y x=ly,而且在 d r y d_{r_y} dry 没有发生改变的时候 d y d_y dy 发生改变了。很显然这意味着新的 d x < d r y d_{x} < d_{r_y} dx<dry 了,也就是说这个时候 x x x 应该被换到右子结点。
所以发现,在对于所有 d d d 值改变的点调整左右子树之后,最终一定是这样子的:
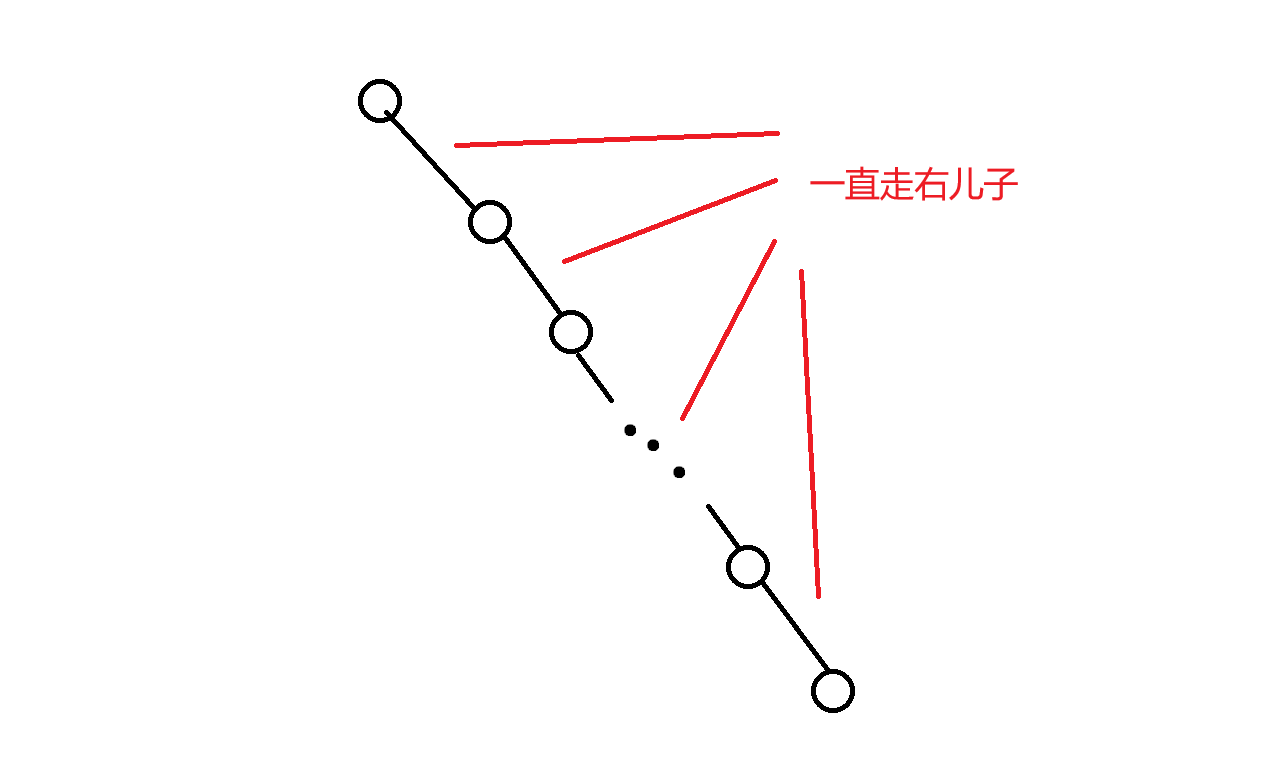
很容易发现这条链不会超过 d r t d_{rt} drt,其中 r t rt rt 表示左偏树的根结点。根据前文退出来的结论,很容易发现 d r t ≈ O ( log n ) d_{rt} \approx O(\log n) drt≈O(logn),所以链的长度不超过 log n \log n logn。所以最终的复杂度也是 O ( log n ) O(\log n) O(logn),就结束了。
P4331 [BalticOI 2004] Sequence 数字序列
妙妙 + 结论 + trick 题。
发现需要 b 1 < b 2 < ⋯ < b n b_1 < b_2 < \cdots < b_n b1<b2<⋯<bn,但是小于号实在不好处理,怎么办呢?
这里有一个常见的思路,就不讲推理过程了: ∀ 1 ≤ i ≤ n , a i − i → a i , b i − i → b i \forall 1\le i\le n,a_i-i\to a_i,b_i - i \to b_i ∀1≤i≤n,ai−i→ai,bi−i→bi,也就是每一个数组都减去一个公差为 1 1 1 的等差数列。
这样就可以把条件变为 b 1 ≤ b 2 ≤ ⋯ ≤ b n b_1 \le b_2 \le \cdots \le b_n b1≤b2≤⋯≤bn。因为同加同减差不变,在之后求出来的答案也是对的,只需要把求出来的 b i b_i bi 都按照 b i + i b_i+i bi+i 输出即可。
事实证明,把 < < < 变成 ≤ \le ≤ 有大用。这是第一步。
但是即便这样这个题目依旧很复杂,先来考虑解决一种序列:
a 1 ≥ a 2 ≥ ⋯ ≥ a n a_1 \ge a_2 \ge \cdots \ge a_n a1≥a2≥⋯≥an,可以选择 ∀ 1 ≤ i ≤ n , b i = a ⌊ n + 1 2 ⌋ \forall 1 \le i \le n,b_i = a_{\lfloor \frac{n+1}{2}\rfloor} ∀1≤i≤n,bi=a⌊2n+1⌋,也就是所有的 b i b_i bi 都等于 a a a 的中位数,也必须要使 b b b 值都相同。
这个东西是为什么,画一个图即可,发现此时的方案是众多方案中最小的方案之一。但是到了后面我们还要把各个不增或不减序列拼接起来,显然这时候的最大值是最小的,在之后肯定最优。
这是第二步。
已经解决了一种特殊的东西,就可以从这一种序列拓展到一般的序列了。
显然,一个序列是从不减的序列首尾拼接而成的。 所以可以将这一种序列诞生的 b b b 序列考虑拼接起来。
但是这个时候还会有一个问题,在单独 b b b 序列中满足单调不减,但是在 b b b 序列之间就并不一定可以满足单调不减,所以需要调整。
这时候又引出了一个结论:
对于相邻的两个 a a a 值下降区间 X , Y X,Y X,Y, X X X 在 Y Y Y 的左边,如果其产生的 b b b 值各自为 x , y x,y x,y 而且 x > y x > y x>y,则两区间的 b b b 最优应该统一为 z z z, y ≤ z ≤ x y \le z\le x y≤z≤x。
显然只有 x > y x>y x>y 的时候需要调整。发现如果 z > x z>x z>x 的话显然不优,而 z < y z<y z<y 的话也不优。画图可以知道。
而且在统一之后还需要使得最大值最小,可以把两段下降区间合并,然后取中位数即可。很容易想象这是最优的,而且最大值最小。
这是第三步。
显然我们需要合并两个区间,并求出其中位数。
很显然想到这个东西可以使用堆来做。堆只需要维护 $sz /2 $ 个数即可,其中 s z sz sz 表示区间的长度,而堆顶就是中位数。
在合并的时候,可以先将两个堆合并到一起,然后再删除堆顶直到元素个数 = s z / 2 = sz/2 =sz/2。
可合并堆可以使用左偏树来实现。
左偏树整体修改
有时候,左偏树要做一个整体修改,也就是把一个子树的结点全部加上一个值。
这个时候我们可以效仿隔壁线段树,把加上的值作为一个 tag 弄在修改的子树根上面,然后修改子树的根。这个思想是挺简单的。
但是我们还要想办法让它支持左偏树原本的操作。
因为左偏树是一种可合并堆,所以需要支持合并。
至于合并,我们可以对某一个有 tag 的结点进行类似一个 pushdown 的操作,消除这个 tag,并下传到子结点,也对子结点进行修改。合并的时候,我们就还是可以像原来一样比对根的大小并合并。
很显然这个 tag 维护的东西不能乱设,根据线段树的 lazytag 来讲,左偏树的 tag 也需要满足结合律,也就是相同类型的东西不同的运算顺序得出来的结果一样。
而且,在打上 tag 之后,堆的形态不能发生改变。这就有一个很好的例子,就是取模。你不能保证两个数取模之后还保持原来的大小关系。
朱刘算法的另一种写法
显然我们现在这是要讲左偏树优化朱刘算法了。
但是原本我们实现的方法很难优化,所以先来看一下另一种写法。
先来看看这个外向基环树。
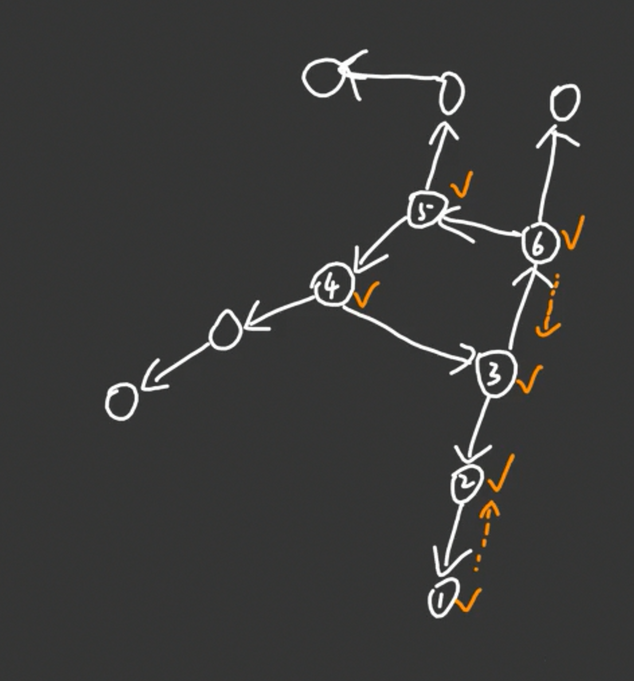
因为我们找环的时候是沿着入边搜回去的,所以也可以看成是一个内向基环树。
很容易发现,我们在执行普通的朱刘算法的时候,是从 1 → 2 → 3 → 4 → 5 → 6 1 \to 2 \to 3 \to 4 \to 5\to 6 1→2→3→4→5→6 的。
然而这个时候找到了环 { 3 , 4 , 5 , 6 } \{3,4,5,6\} {3,4,5,6},所以要将其缩点为 7 7 7。
目前,我们先开一个栈,存储所有被访问的结点。则这个栈现在是: 1 , 2 , 3 , 4 , 5 , 6 1,2,3,4,5,6 1,2,3,4,5,6。
上面的过程是原本的朱刘算法的实现思路,但是这样我们并不满足。因为一次循环只会找到一个环,缩完点就直接再来一遍,很浪费时间。所以考虑一次找到多个环。
我们会想:为什么搜到 7 7 7 这个环就要重新搜一遍呢?我们可以直接把栈里面的 3 , 4 , 5 , 6 3,4,5,6 3,4,5,6 去掉并加上 7 7 7,从 7 7 7 继续开始搜不就完了!注意再找到 7 7 7 这个环时候,构成这个环的 3 , 4 , 5 , 6 3,4,5,6 3,4,5,6 都在栈的顶端位置,所以可以直接弹出并替换。
所以思路就成型了。