探究Azure devops 流水线缓存
流水线缓存可以通过重用先前运行中下载的依赖项来帮助缩短构建时间,避免重新创建或重新下载相同的文件。这在每次运行开始时重复下载相同依赖项的场景中尤其有用。这通常是一个耗时的过程,涉及数百或数千次网络调用。
当恢复和保存缓存所需的时间少于重新生成文件所需的时间时,缓存最有效。然而,在某些情况下,缓存可能不会带来性能优势,甚至可能对构建时间产生负面影响。评估您的具体场景以确定缓存是否是合适的方法至关重要。
缓存任务:工作原理
通过将缓存任务添加到作业的步骤部分,即可将缓存添加到流水线中。
在流水线执行过程中,当遇到缓存步骤时,任务会尝试根据提供的输入恢复缓存。如果未找到缓存,则该步骤完成,并执行作业中的下一步。
作业中的所有步骤都成功运行后,系统会自动添加一个特殊的“作业后:缓存”步骤,并针对每个未跳过的“恢复缓存”步骤触发该步骤。此步骤负责保存缓存。
启用依赖项缓存的步骤
- 定义缓存:指定缓存键和依赖项的路径。
- 恢复缓存:使用构建早期阶段的缓存机制恢复已缓存的依赖项。
- 保存缓存:构建完成后,将任何新的或更新的依赖项保存回缓存。
Cache@2 任务
此任务有 3 个输入参数 -
- key(必填):用于标识缓存的唯一键
- path(必填):要缓存的文件夹或文件的路径
- restoreKeys(可选):如果 key 失效,则将使用此选项来查找缓存
缓存NuGet包的例子
要缓存 NuGet 包,请定义一个管道变量,该变量指向运行管道的代理上包的位置。
在下面的示例中,packages.lock.json 的内容经过哈希处理,生成一个动态缓存键。这确保每当文件发生更改时,都会创建一个新的缓存键。
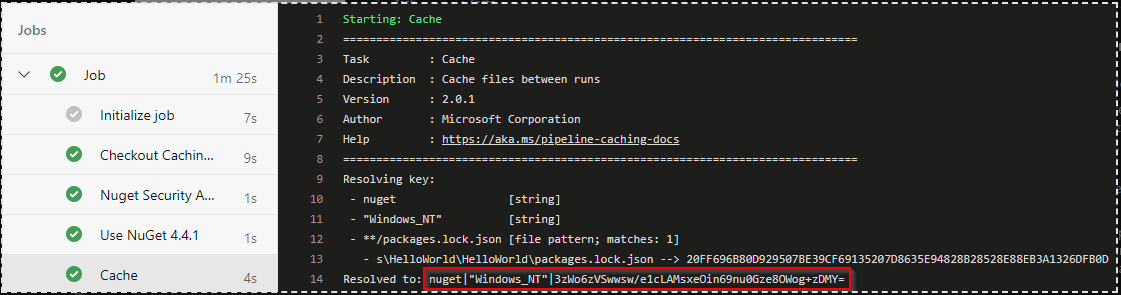
variables:NUGET_PACKAGES: $(Pipeline.Workspace)/.nuget/packages- task: Cache@2displayName: Cache v2 task inputs:key: 'nuget | "$(Agent.OS)" | **/packages.lock.json,!**/bin/**,!**/obj/**'restoreKeys: |nuget | "$(Agent.OS)"nugetpath: '$(NUGET_PACKAGES)'cacheHitVar: 'CACHE_RESTORED'pipeline解读
变量:: 此部分定义可在整个流水线中重复使用的变量。
- NUGET_PACKAGES:: 此部分定义一个名为 NUGET_PACKAGES 的变量。
- $(Pipeline.Workspace)/.nuget/packages:此部分将 NUGET_PACKAGES 的值设置为流水线工作区中用于存储 NuGet 包的特定路径。$(Pipeline.Workspace) 是一个预定义变量,指向流水线的临时目录,而 .nuget/packages 是 NuGet 包的通用目录结构。
task: Cache@2:这表示您正在 Azure DevOps 中使用版本 2 的缓存任务。
- displayName:Cache v2 任务:这是任务的可读名称,将显示在 Azure DevOps UI 中。
- inputs:: 此部分包含缓存任务的具体输入。
- key:: 这指定了缓存的键。
- 'nuget | "$(Agent.OS)" | **/packages.lock.json,!**/bin/**,!**/obj/**':
该键是唯一的,由多个部分组成:
- nuget:标识缓存的类型(适用于 NuGet 包)。
- $(Agent.OS):使用构建代理的操作系统(例如 Windows、Linux),确保缓存特定于操作系统。
- **/packages.lock.json:表示如果 packages.lock.json 文件发生更改,缓存键也应更改,这对于确保缓存的新鲜度至关重要。 !**/bin/** 和 !**/obj/**:这些排除模式确保缓存不包含 bin 或 obj 目录中的任何文件,从而避免不必要的文件膨胀。
- restoreKeys:: 此部分指定主缓存键未命中时使用的回退键。
nuget | "$(Agent.OS)":添加特定于操作系统的回退,以尝试检索缓存。
nuget:更通用的回退,不依赖于操作系统。
- path:: 此部分指定缓存路径。
'$(NUGET_PACKAGES)':此部分使用先前定义的指向 NuGet 包目录的变量。
- cacheHitVar:: 此部分指定一个变量,如果缓存成功恢复,该变量将被设置为 true。
' CACHE_RESTORED':此变量可在管道的后续部分用于检查缓存是否命中并采取相应的操作(例如,如果包是从缓存中恢复的,则跳过 dotnet restore)。
恢复缓存
以下任务仅在 CACHE_RESTORED 变量为 false 时运行。这意味着,如果缓存命中(包已在缓存中),则会跳过恢复步骤以节省时间和资源。如果未找到缓存,则会运行恢复命令来下载必要的依赖项。
- task: NuGetCommand@2condition: ne(variables.CACHE_RESTORED, true)inputs:command: 'restore'restoreSolution: '**/*.sln'性能对比
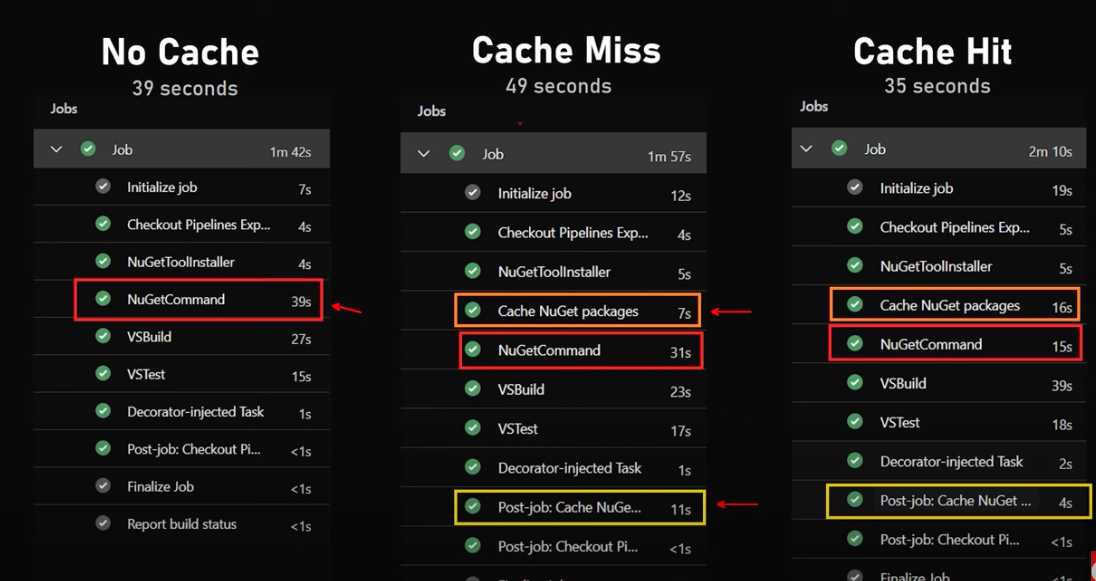
流水线缓存显著减少了恢复依赖项所需的时间,从而加快了构建速度。以下对比展示了缓存对两种不同流水线执行时间的影响:
- 未使用缓存(左图):恢复任务大约耗时 39 秒。
- 为命中缓存(中图):由于第一次运行启用cache的pipeline,缓存没有命中,恢复时间加上保存时间,一共49秒。
- 命中缓存(右图):缓存命中,恢复时间减少到15秒,保存时间也减少到4秒,一共35秒。
下面的图看起来更加直观
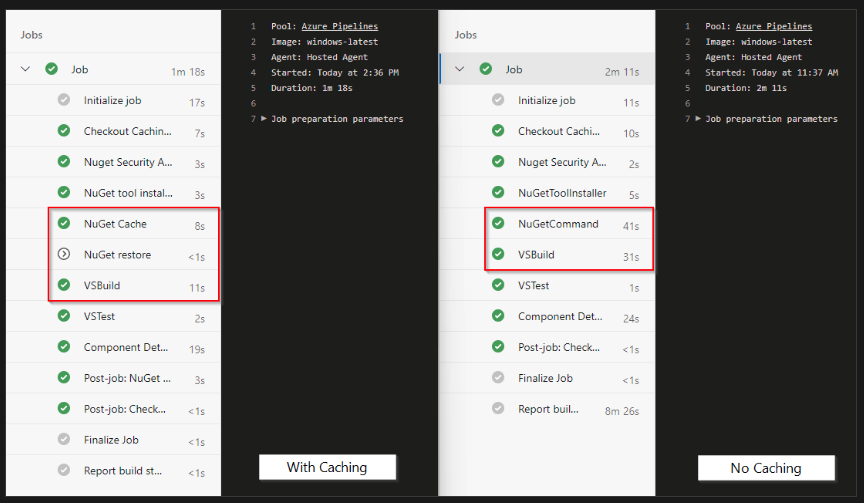
下面是完整的pipeline代码
pool:vmImage: 'windows-latest'variables:solution: '**/*.sln'buildPlatform: 'Any CPU'buildConfiguration: 'Release'NUGET_PACKAGES: $(Pipeline.Workspace)/.nuget/packagessteps:
- task: NuGetToolInstaller@1displayName: 'NuGet tool installer'- task: Cache@2displayName: 'NuGet Cache'inputs:key: 'nuget | "$(Agent.OS)" | **/packages.lock.json,!**/bin/**,!**/obj/**'restoreKeys: |nuget | "$(Agent.OS)"nugetpath: '$(NUGET_PACKAGES)'cacheHitVar: 'CACHE_RESTORED'- task: NuGetCommand@2displayName: 'NuGet restore'condition: ne(variables.CACHE_RESTORED, true)inputs:command: 'restore'restoreSolution: '$(solution)'- task: VSBuild@1displayName: 'Visual Studio Build'inputs:solution: '$(solution)'platform: '$(buildPlatform)'configuration: '$(buildConfiguration)'常见问题
问题 1
缓存不工作?或者没有缓存命中?
确保您的构建已通过。如果构建失败,缓存将不起作用,作业后缓存步骤虽然“通过”,但没有任何反应(没有日志就说明构建失败)。
问题 2
缓存命中/恢复仍然没有发生?检查在作业后缓存步骤中是否看到此警告。
警告]给定的缓存键在恢复和保存步骤之间已更改其解析值;
如果是,请确保在缓存和作业后缓存步骤之间的任何构建步骤均未更改缓存键值。
例如,我们在 NPM 示例中使用以下值作为缓存键。
npm | $(Agent.OS) | ${{parameters.WORKING_DIR}}/package-lock.json
假设构建中有一个 npm 发布步骤,它会更改 package-lock.json 的值。在这种情况下,您将永远不会获得缓存命中,因为 package-lock.json(哈希值)是唯一缓存键的一部分。
有两种解决方法 - 删除导致更改的步骤或从键中删除 package-lock.json。
问题3
文档指出使用 ${Pipeline.Workspace} 在托管构建代理上定义相对路径。
但是,托管构建代理上并非所有文件夹都通过默认变量公开。因此,有时您可能需要指定绝对路径,例如上面的代码片段 - /home/vsts/.npm。
问题4
缓存在项目、流水线和分支级别具有限制范围。
示例:假设您在开发分支上为流水线 A 添加了缓存。现在,如果您创建一个名为 feature/A 的新分支并针对开发分支发起拉取请求。由于这是一个新分支,因此该分支的第一次流水线运行将出现“缓存未命中”。
因此,缓存在用于短期功能分支时作用不大。
*文档中提到了这一点,但可能会被忽略。
问题 5
在 Windows 上,当缓存大小超过某个阈值时,构建代理的缓存似乎会非常慢。这违背了缓存的初衷,因为您添加缓存是为了加快构建速度,而不是相反。