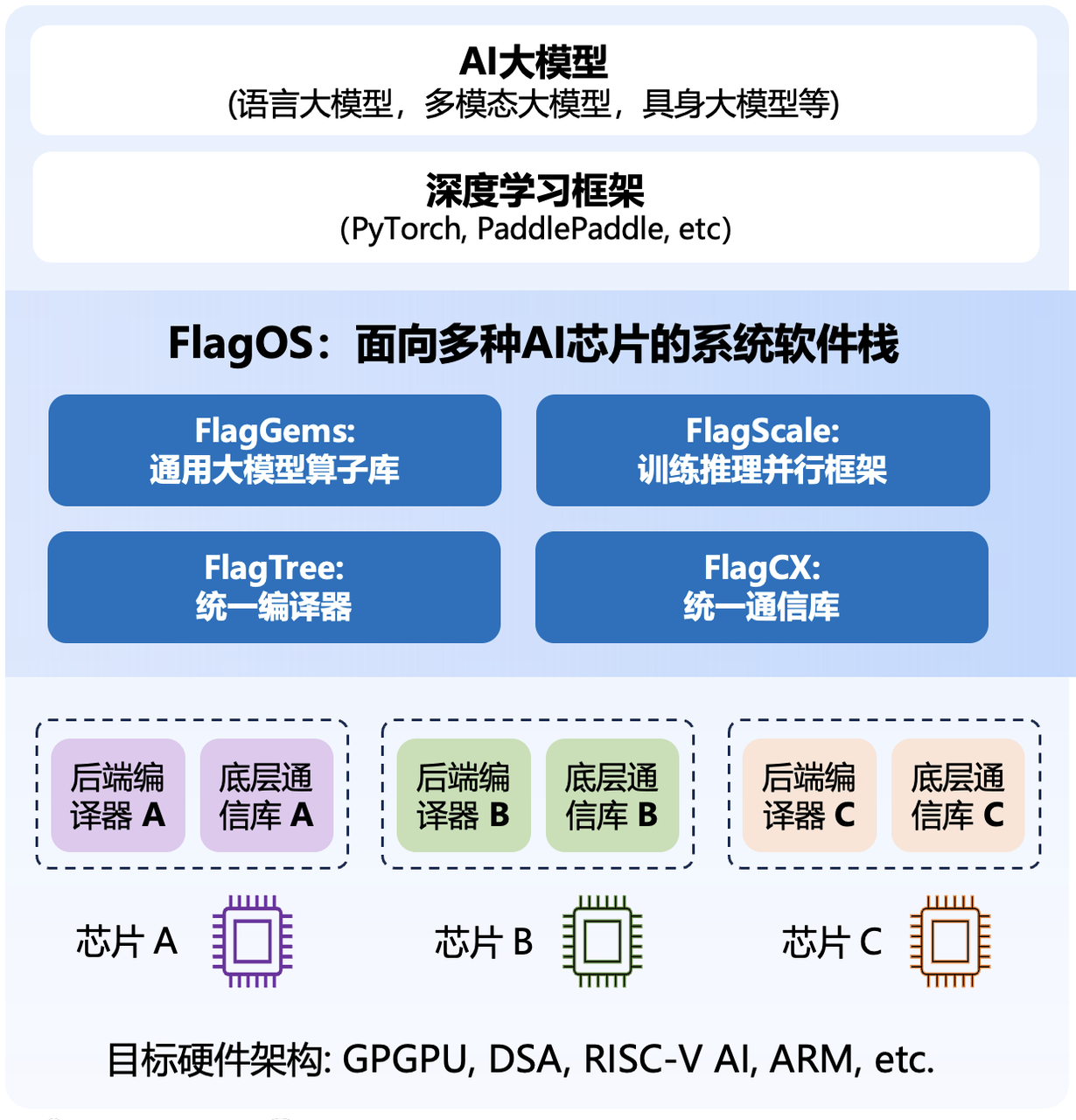
FlagOS 新里程:开源面向多种硬件架构的统一AI 编译器 FlagTree
为了推动不同架构 AI 硬件系统的创新和落地,打造开源、统一的 AI 系统软件生态,智源研究院联合多家机构开源了 AI 编译器 FlagTree。FlagTree 的开源,是开源、统一 AI 系统软件生态 FlagOS 发展进程中又一个重要的里程碑事件。至此,FlagOS 已经形成了具备高性能通用 AI 算子库FlagGems/FlagAttention、统一 AI 编译器 FlagTree、大模型训推一体框架 FlagScale 和统一通信库 FlagCX 的较为完整的系统软件技术栈。
1 FlagTree:基于 Triton 语言的开源统一AI编译器
FlagTree 开源社区希望通过开放合作的方式,打造一个支持Triton语言,面向多种 AI 硬件架构、增强对AI硬件特性支持能力的开源、统一 AI 编译器。从而为开发者提供更多选择,推动各种AI系统创新技术的普及和多元发展。
统一 AI 编译器 FlagTree 的发展,离不开社区生态参与机构的合作共建,为了推动 FlagTree 的开源合作和技术发展,FlagOS 生态社区为 FlagTree 开源社区成立了开源治理委员会、技术指导委员会、项目管理委员会、社区秘书处等多个组织,对 FlagTree 的发展形成强有力的保障。到目前为止,已经有十多家机构加入 FlagTree 开源社区,并按计划、有节奏地召开技术委员会会议,为 FlagTree 新版本的发布、后续版本的技术方案和研发路线进行重要的探讨。
1.1 FlagTree v0.1:支持多芯片后端,为上层用户提供统一的AI编译器版本
当前发布的 FlagTree v0.1版本能够兼容现有的 Triton 适配方案,实现了 Triton 语言的单版本多后端支持。目前,FlagTree 为支持多后端的编译器构建统一代码仓库;同时,FlagTree 统一承担对 Triton语言上游社区快速更迭的跟进任务,拉齐各芯片后端适配 Triton 的版本,为顺畅适配 Triton 语言的算子库铺平道路。
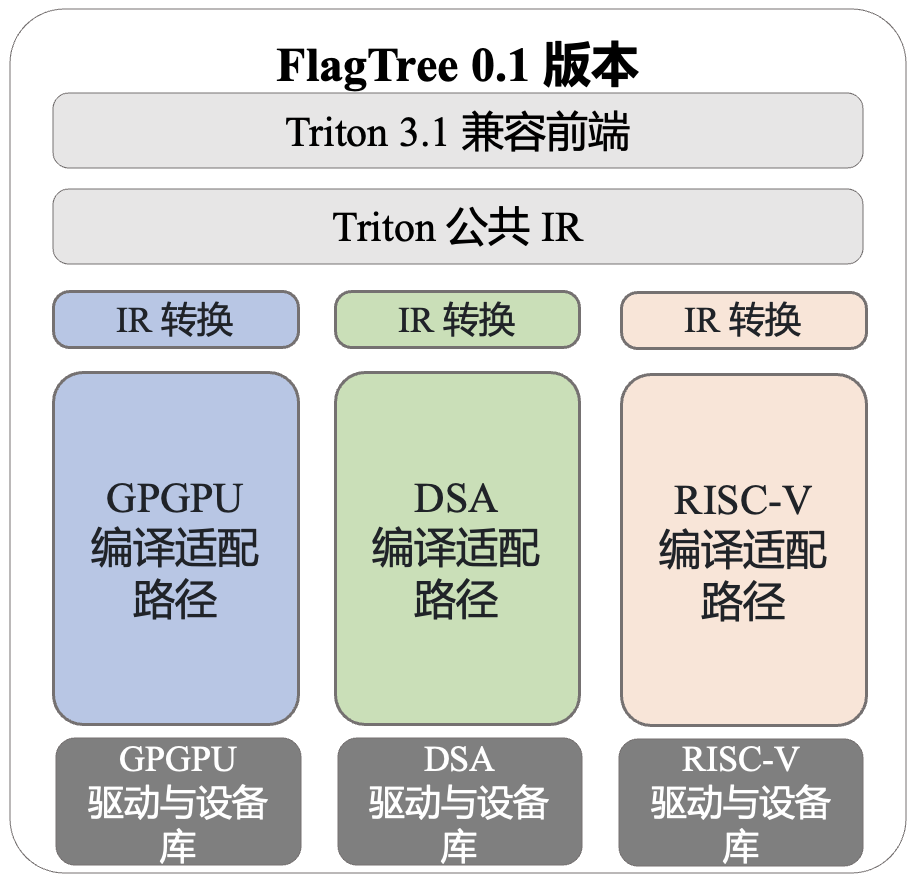
重要特性:
兼容现有两种主流编译路径:技术路线上,FlagTree 兼容 TritonGPU Dialect、Linalg Dialect 向下编译的两条编译路径,未来会充分收集各芯片平台的编译诉求,对中间层 IR 做统一设计。
接入形式灵活:源码、动态库
支持多种AI硬件后端:英伟达、摩尔线程等五家厂商
架构插件化设计:支持高差异度模块,相关的芯片平台可自行维护这部分模块的代码仓库
跨平台编译与快速验证能力
CI/CD:构建完备CI/CD,覆盖多元 AI 芯片
维护 Triton 官方版本升级,减少重复投入
FlagGems 和 FlagTree 联动,统一算子库与编译器
安全合规:由于本代码库有来自多个团队的贡献,我们使用专业工具保障项目代码的安全合规
1.2 FlagTree下一版本:集成更多硬件后端,增强硬件相关特性优化
下一个 FlagTree 版本将在以下方面进行重要更新。
-
在现有多种芯片后端的支持基础上,继续扩展更多后端的支持,包括在近期已经正式加入FlagTree开源社区的华为、清微智能和ARM中国等。
-
升级 Triton 新版本特性,包括3.2.x、3.3.x。
-
对非 GPGPU 后端提供多种接入范式,如新增 FLIR 仓库支持基于 Linalg Dialect 扩展
-
GPGPU 后端代码整合,规范接入标准
-
针对不同的硬件特性提供编程接口及编译支撑,从而在非侵入式修改语言层的前提下通过指导信息提升性能,如支持 DMA、Shared Memory 的硬件感知提示
-
FlagGems 和 FlagTree 联动,统一算子库与编译器,包括版本适配、后端适配、推理芯片适配等
2 关于统一 AI 编译器的一些思考
最近,LLVM 的创始人Chris Lattner发表了关于“Democratizing AI Compute”的系列文章,在中文社区受到广泛关注。Chris 曾在Apple、Google等著名团队供职多年,并创立和主导开发了 LLVM、Swift、XLA、MLIR等重要的语言和编译器项目。在文章中,他讨论了 CUDA 和 Triton 各自的优势和不足,也刨析了多年来各家企业和开源组织针对 AI 硬件的统一生态所做的各种尝试,包括 OpenCL、OneAPI 等,尤其深入讨论了 MLIR 的发展历程。FlagTree 这个开源项目,正是针对 Triton 语言和 Triton 原生编译器进行增强的多后端统一 AI 编译器,所以也在此分享一下我们对打造 FlagTree 统一 AI 编译器的思考。
2.1 为什么要打造 FlagTree ?
在过去两年,OpenAI 的Triton 语言已经成为了业界公认的继 CUDA C语言后,第二大流行的 AI 算子开发语言,其目前在 Github 上的开源项目使用量达到 CUDA C 的十分之一。虽然离 CUDA C 的流行度还有距离,但由于它的编译器生态开源开放,被多个 AI 芯片厂商所支持,具备较好的跨平台潜能。且 Triton 提供的类 Python 的编程风格,专为高效的 GPU 编程设计(特别是针对 AI 和高性能计算场景),大大提高了算子开发者的开发效率。所以在支持 AI 算法开发中,Triton 语言的受欢迎程度快速上升。它的主要优势体现在以下几个方面:
-
类Python语法:Triton 的语法类似 Python,降低了传统 GPU 编程(如CUDA)的复杂性,无需深入掌握架构细节即可编写高性能内核。
-
自动并行化:开发者无需手动管理线程块(thread blocks)或共享内存,Triton 会自动处理并行化策略。
-
灵活的矩阵分块(Tiling):支持自动和手动分块策略,优化内存访问模式(如避免 GPU 全局内存的 bank conflicts)。
-
与 PyTorch 深度集成:可直接在 PyTorch 模型中使用 Triton 编写的内核,无缝调用 GPU 资源。
Triton 已经开始被广泛使用,尤其是被研究人员用于开发新模型和特殊的算法。但也有如下明显的弱势:
-
开发效率与性能的权衡:Triton 的 Pythonic 语法和自动优化虽提升开发效率,但牺牲了手写 CUDA C++ 的极致性能(如寄存器分配、指令级优化)。
-
跨芯片的可移植性和性能不足:对非 GPGPU 架构芯片的支持不完善,依赖开发者自行适配,并且 Triton 对非 GPGPU 架构芯片未深度优化,硬件特性利用不充分,性能不及预期。
-
治理与生态局限性: 开源治理依赖 OpenAI 主导,社区参与度不足,非 OpenAI 优先的需求(如小众硬件支持)进展缓慢。
所以,在研发 FlagOS 技术栈来为产业提供开源、统一的系统软件生态时,我们越来越意识到,需要面向 Triton 语言,基于已有的 Triton 编译器能力,构建一个可以真正面向多种 AI 芯片架构的增强型统一编译器 FlagTree 。
通过构建 FlagTree 开源社区,我们力图扩展 Triton 语言的上下游生态,重点解决当前 Triton 不足之处,更好地提升Triton语言在各种不同硬件架构上的性能,赋能人工智能技术开发者。
-
增强编译技术,提升性能:DSL 采用分层优化设计,基础层保留现有高级语法,满足大多数场景;专家层暴露底层硬件控制接口(如共享内存布局、Tensor Core 指令),允许开发者手动优化关键路径。硬件感知优化,针对硬件特性生成专用指令。
-
标准化硬件抽象层,提升多后端能力:定义统一的硬件中间表示(计算单元、内存层次、原子操作),隔离硬件差异。
-
加强社区治理与驱动力:通过治理委员会和社区技术委员会,引入多方代表(如硬件平台、深度学习框架平台、科研机构)共同决策技术路线,实现社区贡献的快速迭代。
2.2 从 OpenCL、OpenXLA、MLIR 到 FlagTree,我们需要吸取哪些经验和教训?
在 Chris 的文章中,他总结了 AI 产业界几次试图构建统一开源、面向多种硬件架构的技术尝试,包括OpenCL、TVM、OpenXLA、OneAPI、MLIR等。通过对这些项目的分析,我们认为以下几点十分重要。
-
需要有“诚意”的开源:跨硬件架构的系统软件技术难度大,对各方的开源合作要求较高。如果这类开源项目只包含了技术规范、或只把非核心部分开源出来(如OpenCL和OpenXLA在后期出现了类似情况),社区其他合作者会觉得主导方“有所保留”,整个社区也不会全力以赴。此外,如果企业总是拿自己的内部版本和开源版本来竞争,以证明内部版本优于开源版本,也会不利于开源社区的发展。智源研究院作为一个中立的、非营利的机构牵头 FlagTree 的开源建设,一定程度保证了开源项目的“诚意”属性,能够保证开源版本的领先性。
-
有一个稳定的团队来保障项目的愿景和执行。要支持多种AI硬件的开源项目,除了本身要克服“通用性“和”专用极致优化”之间的技术矛盾,更为挑战的是,如何协调多硬件厂商之间的合作共建。从 MLIR 的例子看到,如果没有一个团队来保证整个项目的发展方向、来对最后的可用性和领先性负责,完全靠社区自治,是很容易走向碎片化和技术分叉,甚至再次走入困境。智源团队有着从大模型算法、到训推框架、到算子库和编译器多层次的经验,一直秉承开源合作、创新突破、发展社区的理念。智源团队在 FlagTree 中很高兴能承担此重任,与各生态成员单位一同前行、合作共赢。
-
避免技术的碎片化:我们看到无论是 OpenCL、TVM 还是 MLIR ,经过一段时间的发展后,项目都容易分裂成多个互不兼容的分支。虽然在一开始是希望由统一的代码来支持多种硬件架构,但最终还是分裂为不同代码仓库,支持不同硬件平台。如今,我们看到在 Triton 的上游社区也出现了这种情况,各机构平台为了支持 Triton ,各自不得已 fork 了自己的版本仓库。上层用户一方面无法获得一站式的代码,另一方面因为各个 fork 分支版本不一样,导致许多前后兼容的问题无法避免。所以,FlagTree 从编译器软件架构层面就开始支持多种硬件后端,通过统一的集成和测试,保障同一个代码版本可以在多种硬件上稳定支持。
当然,在平衡“通用统一“和“极致优化“这两个技术目标上,我们很难同时做到最好,这也是 FlagTree 这个项目的重要技术挑战。如何通过好的编译器架构设计、接口设计、优化策略和算法创新,让这两大目标之间的 trade-off 代价最小,是需要 FlagTree 开源社区成员单位不断突破,不断协同创新。
关于 FlagTree 开源社区
FlagTree 开源社区是由芯片硬件平台、深度学习框架平台、非营利性组织、科研机构等十多家国内外机构共同发起并创立的。2025年3月,FlagTree 开源社区正式建立并开启运营工作。项目治理委员会(GB)、技术指导委员会(TSC)和项目管理委员会(PMC)的相继成立,对 FlagTree 的技术发展将形成强有力的组织保障。
FlagTree 开源社区希望以开放合作的方式,打造一个面向多种芯片的开源、统一 AI 编译器,扩展 Triton 语言的上下游生态,赋能大模型技术开发者。通过统一多后端的编译器,FlagTree 社区能够建立起一个支持多种芯片硬件架构(GPGPU、DSA、RISC-V AI等)的生态,从而实现跨硬件平台运行,为开发者提供更多选择,推动 AI 技术的普及和多元发展。
FlagTree 开源地址:
https://gitee.com/flagtree/flagtree
https://github.com/FlagTree/flagtree
