大模型的开发应用(四):深度学习模型量化与QLoRA微调
大模型量化与QLoRA微调
- 1 深度学习模型量化
- 1.1 量化的目的与原因
- 1.2 对称量化(Symmetric quantization)与非对称量化 (Asymmetric quantization)
- 1.3 量化粒度
- 1.4 神经网络中的量化与反量化
- 2 训练后量化与量化感知训练
- 2.1 根据阶段对量化分类
- 2.2 三种量化分类对比
- 3 量化分类总结
- 4 QLoRA量化
- 4.1 分位数量化与NF4量化
- 4.2 QLoRA中的量化过程
- 4.3 QLoRA的参数配置经验
- 5 LLM.int8(): 大规模语言模型的无损8比特量化
- 5.1 问题背景:传统量化的局限性
- 5.2 核心原理
- **(1) 动态异常值分离**
- **(2) 矩阵乘法的混合精度计算**
- 5.3 关键优势
- 5.4 实验数据
- 5.5 使用场景与代码示例
- 适用场景
- 代码实现(Hugging Face集成)
- 局限性
- 总结
- 6 使用LLaMA Factory进行量化训练与导出
- 6.1 QLoRA训练
- 6.2 量化导出
- 6.3 关于 LLaMAFactory 导出量化模型或者QLoRA训练时的环境问题
- 7 关于 Bitsandbytes(了解即可,不重要)
- 7.1 `bitsandbytes` 是一个库
- 7.2 `bitsandbytes` 包含的量化算法
- 7.3 与 `HQQ` 和 `EETQ` 的区别
- 总结
1 深度学习模型量化
1.1 量化的目的与原因
简单来说,就是压缩模型,节约显存,一个权重数据类型为FP32的模型,假设占用了8G的显存,如果把权重量化为int8,那么显存占用量只有2G,如果量化为int4,那么显存只占用1G。另一方面,显卡处理低精度的数据会快于高精度的数据,因此,量化还能加快推理速度。
量化不但用于权重,还用于激活值。
1.2 对称量化(Symmetric quantization)与非对称量化 (Asymmetric quantization)
这里我们以最常用的 int8 量化为例,介绍对称量化与非对称量化。int8 类型的数据,因为只有8位,因此它的取值范围是 [-128, 127],这里只有256个值,量化要做的事情,就是把FP32类型的向量、矩阵、张量映射到这个范围中,把原来无数种取值情况,降低到只有256种取值情况。
假设 r r r 是模型某一层的权重矩阵, ∣ r ∣ |r| ∣r∣是其绝对值值, ∣ r ∣ m a x |r|_{max} ∣r∣max是最大的绝对值, r m a x r_{max} rmax 是其最大值, r m i n r_{min} rmin 是其最小值。
若矩阵 r r r 中每个元素都除以 ∣ r ∣ m a x |r|_{max} ∣r∣max,那么矩阵 r 就被压缩到了 [-1, 1] 这个区间,然后乘以127并取整,就能把原来的数据映射到 [-127, 127]之间,公式如下:
q = r o u n d ( r ∣ r ∣ m a x ⋅ ( 2 7 − 1 ) ) q=round(\frac{r}{|r|_{max}}\cdot(2^7-1)) q=round(∣r∣maxr⋅(27−1))
round 是四舍五入的取整函数,假设 n 是量化的位数,那么上式可以表示成:
q = r o u n d ( r ∣ r ∣ m a x ( 2 n − 1 ) ) = r o u n d ( r S ) q=round(\frac{r}{|r|_{max}}(2^n-1))=round(\frac {r}{S}) q=round(∣r∣maxr(2n−1))=round(Sr)
这里面 S = ∣ r ∣ m a x 2 n − 1 S=\frac {|r|_{max}}{2^n-1} S=2n−1∣r∣max ,被称为缩放系数,这种量化方法被称为对称量化。
若对矩阵 r r r 按以下方式处理,则为非对称量化:
q = r o u n d ( r − r m i n r m a x − r m i n ⋅ ( 2 7 − 1 ) ) = r o u n d ( ( 2 n − 1 − 1 ) ⋅ r r m a x − r m i n − ( 2 n − 1 − 1 ) ⋅ r m i n r m a x − r m i n ) = r o u n d ( r S + Z ) q=round(\frac{r-r_{min}}{r_{max}-r_{min}}\cdot (2^7-1))=round(\frac{(2^{n-1}-1) \cdot r}{r_{max}-r_{min}}-\frac{(2^{n-1}-1) \cdot r_{min}}{r_{max}-r_{min}})=round(\frac {r}{S} + Z) q=round(rmax−rminr−rmin⋅(27−1))=round(rmax−rmin(2n−1−1)⋅r−rmax−rmin(2n−1−1)⋅rmin)=round(Sr+Z)
上式的过程,是先把 r 缩放到 [0, 1] 区间,然后再缩放到 [0, 127],缩放系数为 S = r m a x − r m i n 2 n − 1 − 1 S=\frac{r_{max}-r_{min}}{2^{n-1}-1} S=2n−1−1rmax−rmin,Z是零点(即量化前值为0的点), Z = − ( 2 n − 1 − 1 ) ⋅ r m i n r m a x − r m i n Z=-\frac{(2^{n-1}-1) \cdot r_{min}}{r_{max}-r_{min}} Z=−rmax−rmin(2n−1−1)⋅rmin。
我们可以调节零点和缩放系数,把 r 先缩放到 [0, 255],然后偏移到 [-127, 127] 区间,让 int8 的各个位数都得到利用:
q = r o u n d ( r − r m i n r m a x − r m i n ⋅ ( 2 8 − 1 ) − 2 7 ) = r o u n d ( ( 2 n − 1 ) ⋅ r r m a x − r m i n − ( 2 n − 1 ) ⋅ r m i n r m a x − r m i n − 2 n − 1 ) = r o u n d ( r S + Z ) q=round(\frac{r-r_{min}}{r_{max}-r_{min}}\cdot (2^8-1)-2^7)=round(\frac{(2^n-1) \cdot r}{r_{max}-r_{min}}- \frac{(2^n-1)\cdot r_{min}}{r_{max}-r_{min}}-2^{n-1})=round(\frac {r}{S} + Z) q=round(rmax−rminr−rmin⋅(28−1)−27)=round(rmax−rmin(2n−1)⋅r−rmax−rmin(2n−1)⋅rmin−2n−1)=round(Sr+Z)
其中:
S = r m a x − r m i n 2 n − 1 Z = − ( 2 n − 1 ) ⋅ r m i n r m a x − r m i n − 2 n − 1 \begin{aligned} & S=\frac{r_{max}-r_{min}}{2^{n}-1} \\ & Z=- \frac{(2^n-1)\cdot r_{min}}{r_{max}-r_{min}}-2^{n-1} \end{aligned} S=2n−1rmax−rminZ=−rmax−rmin(2n−1)⋅rmin−2n−1
为了方便使用 int8 量化后的数据进行计算,一半情况下会对 Z 进行取整(稍后就能看见取整的作用了),即:
Z = r o u n d ( − ( 2 n − 1 ) ⋅ r m i n r m a x − r m i n − 2 n − 1 ) Z=round(- \frac{(2^n-1)\cdot r_{min}}{r_{max}-r_{min}}-2^{n-1}) Z=round(−rmax−rmin(2n−1)⋅rmin−2n−1)
上面的推导过程比较繁琐,只需要记住,对称量化的公式为 q = r o u n d ( r S ) q=round(\frac {r}{S}) q=round(Sr),非对称量化为 q = r o u n d ( r S + Z ) q=round(\frac {r}{S}+Z) q=round(Sr+Z),其中S是缩放系数,Z为零点,就够了。
缩放系数和零点被统称为量化参数,对称量化没有零点,因此只有一个量化参数,而非对称量化则有两个量化参数。
对称量化与非对称量化的示意图如下:
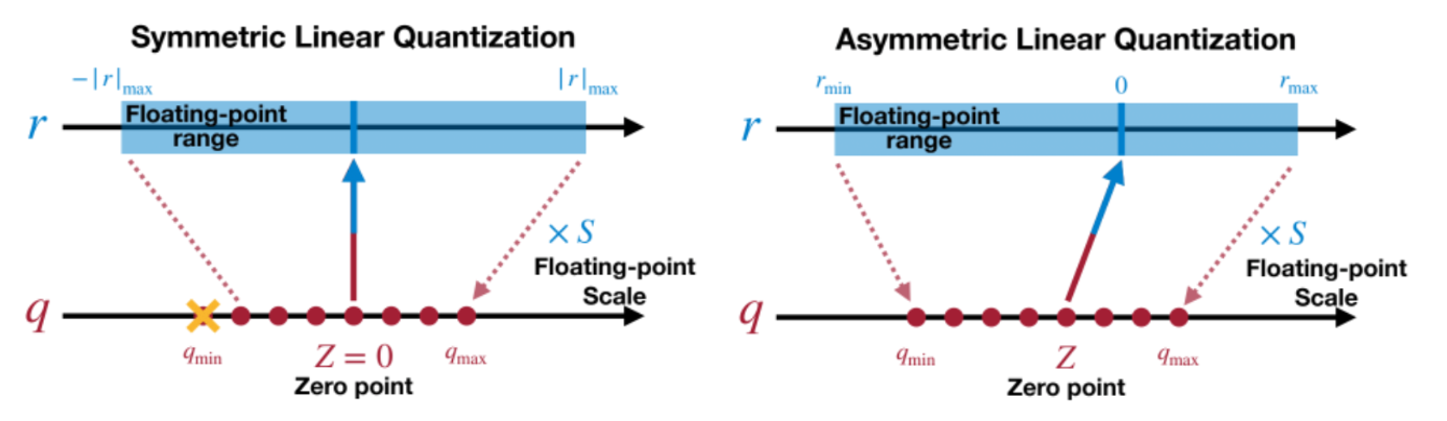
对称量化比较简单一些,只有一个量化参数,但不太适合用于激活值量化,因为神经网络中大量使用ReLU函数,这会使得激活值只有正数没有负数,此时若使用对称量化,那么量化空间中负数部分被浪费,正数部分过于拥挤,从而影响精度。
量化是为了节约显存,计算完成之后往往需要反量化,反量化公式如下:
r = S ( q − Z ) r=S(q-Z) r=S(q−Z)
若是对称量化,上式的 Z 为0。
计算的时候,先对权重和输入数据进行量化,再用量化后的值进行计算,计算完成再反量化为原始精度。例如,输入值和权重做一次矩阵运算,可以表示成如下形式:
X f W f = ( S x ∗ ( X q − Z x ) ) @ ( S w ∗ ( W q − Z w ) ) = S x ∗ S w ( X q W q − X q Z w − W q Z x + Z x Z w ) ) \begin{aligned} X_{f} W_{f} & =(S_{x} * (X_{q}-Z_{x})) @ (S_{w} * (W_{q}-Z_{w})) \\ & =S_{x} * S_{w}(X_{q} W_{q}-X_{q} Z_{w}-W_{q} Z_{x}+Z_{x} Z_{w})) \end{aligned} XfWf=(Sx∗(Xq−Zx))@(Sw∗(Wq−Zw))=Sx∗Sw(XqWq−XqZw−WqZx+ZxZw))
上面的式子中,下标 f 表示 FP32 浮点数,q 表示量化后的 int8 量化后的结果。由于 Z 已经取整了,因此 X q W q − X q Z w − W q Z x + Z x Z w X_{q} W_{q}-X_{q} Z_{w}-W_{q} Z_{x}+Z_{x} Z_{w} XqWq−XqZw−WqZx+ZxZw 是 int8 类型的矩阵运算,这部分算完之后,整型转浮点型(例如 5 -> 5.0),然后乘以缩放系数得到结果。通过量化操作,我们实现了将 FP32 类型的数据乘法转化为了 int8 类型数据的乘法,由于大多数显卡对于 int8 数据的计算速度比 FP32 快很多,所以也实现了加速的功能。
无论是对称量化,还是非对称量化,因为存在取整的操作,因此反量化后得到的 FP32 数据和原始数据会有差异。虽然存在差异,但对神经网络的整体预测结果影响有限,以分类网络为例,由于最后的 softmax 层的存在,同一个输入样本,原来最大的神经元,量化后大概率还是最大。模型层数多的时候,误差累积,使得量化后的模型相比原始模型有可能会下降1-2个点,这是很正常的,总体而言影响不大。
1.3 量化粒度
量化粒度决定精度转换的细致程度,常见方案包括:
- 全网络统一量化,权重和偏置分别只需要一套参数,优点是实现简单,适合通用硬件,缺点是无法适应各层差异(如激活值分布差异)
- 逐层量化(Layer-wise Quantization),为每层独立计算缩放因子和零点,每层的权重搞一套参数,偏置搞一套参数,这是平衡精度与实现复杂度的主流方案;
- 逐通道量化(Channel-wise Quantization),按输出通道分别量化(常用于卷积层),每个输出通道对应于一个卷积核,实际上是对每个卷积核单独量化,因此各自都有一套量化参数,所以相比于逐层量化,量化参数显著增加;
- 分块量化(Block-wise Quantization),将矩阵均匀切分为固定大小的块,每块单独量化,同样会使量化参数显著增加,过程如下图所示:
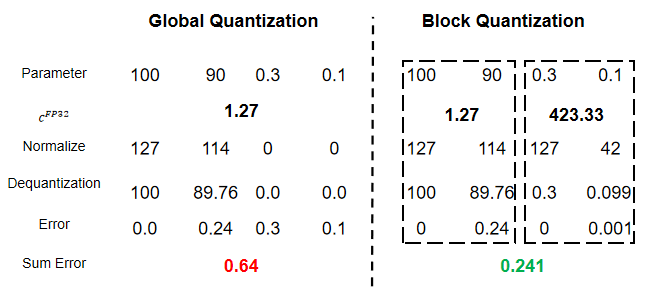
- 混合量化(Hybrid Quantization),对模型的不同部分使用不同的量化粒度。
1.4 神经网络中的量化与反量化
神经网络训练完成后,可以对其权重进行量化,这里假设使用 int8 对称量化,且使用逐层量化。量化后在推理的时候,过程如下图所示:
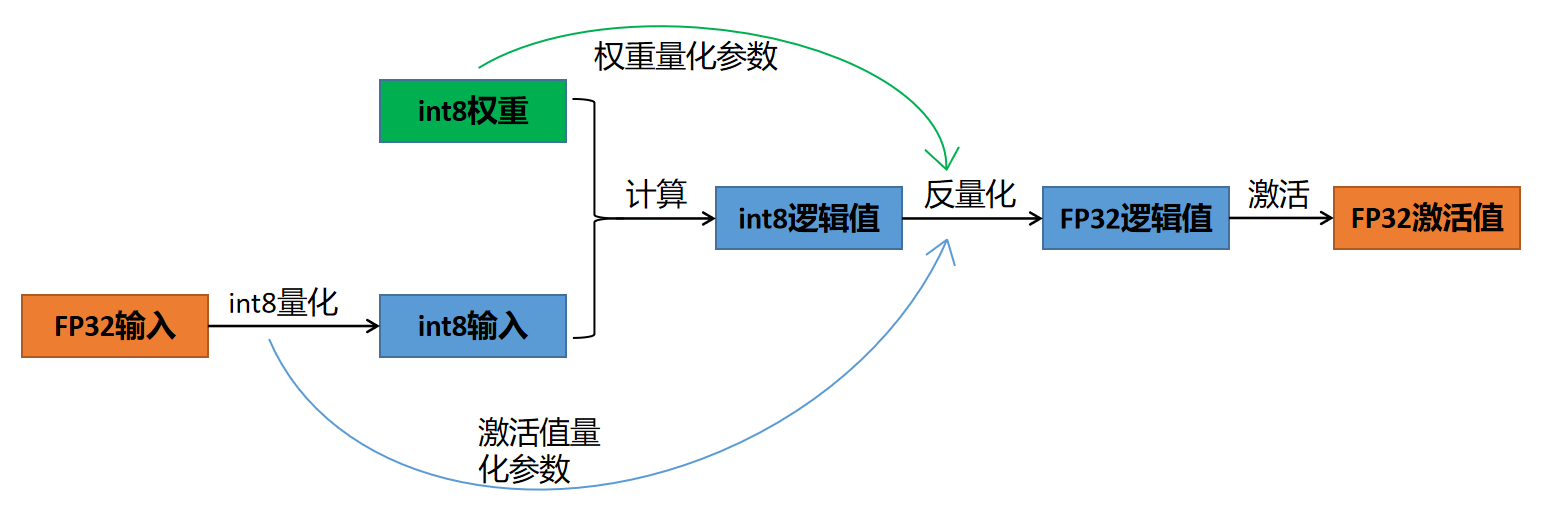
上图中,FP32输入,其实就是上一层的FP32激活值。
2 训练后量化与量化感知训练
2.1 根据阶段对量化分类
对于训练好的神经网络,量化是一次性完成,但激活值量化就有点麻烦了,因为不同的输入有不同的激活值,对应的量化参数也会不一样。根据不同的输入样本是否使用同一套激活值,可以分为训练后动态量化(Post-Training Dynamic Quantization, PTDQ)与训练后静态量化(Post-Training Static Quantization, PTSQ)。另外,对于权重的量化也可以在训练的过程中,这种情况被称为量化感知训练(Quantization-Aware Training, QAT)。
训练后的模型在推理时,每个输入样本单独量化和反量化,即每个输入样本自己有一套量化参数,这个就是动态量化,动态指的是量化参数是动态的。
若训练后的模型,在正式推理之前,用一组有代表性的数据跑一遍整个网络,并把激活值的量化参数存下来,这组数据称为校准数据,存下来的量化参数可以是校准数据的平均值,也可以是移动平均(因为校准数据也是一个个batch喂进模型的)。在正式推理的时候,使用校准数据的量化参数对输入样本进行量化和反量化,这个就是静态量化,静态指的是量化参数是固定的。正式推理时,因为量化参数并不来自于本次输入数据,有可能导致量化后超出量化范围,比如 int8 量化时,某个数被量化成130,超过了[-128, 127]的范围,这个时候需要裁剪,用上边界127替代130。
量化感知训练则是在训练的时候进行量化,并且是模型权重和激活值同时量化。在模型搭建的时候,为模型添加伪量化模块(QuantStub/DeQuantStub)模拟量化操作,这个模块有两个参数S和Z,该模块在正向传播的时候起的是量化功能,在反向传播的时候是恒等函数(直通估计器),以便能传递梯度。传统的QAT,量化参数不可训练,它由动态统计,训练的时候,是通过调整伪量化模块之前的模型权重参数,从而影响激活值及其量化参数。也有些QAT算法,量化参数也是可以训练的,例如LSQ(Learned Step Size Quantization)算法。
2.2 三种量化分类对比
训练后动态量化,由于在推理时实时计算激活值的缩放因子和零点,每次推理的激活值范围可能不同,导致量化参数不稳定,容易被噪声干扰。例如,若某层激活值的真实范围为[-1, 1],但某个样本的瞬时激活值出现异常值[-5, 5],动态量化会将缩放因子适配到[-5, 5],正常值[-1, 1]被压缩到更小的整数范围,导致分辨率降低。
而训练后静态量化,由于校准阶段通过统计输入数据分布固定量化参数,使得量化参数基于有代表性的校准数据(如最小/最大值或KL散度),更贴合真实输入分布,稳定性高,不易受噪声干扰。
相比于训练后量化,量化感知训练精度最高,因为它通过训练补偿了量化误差。
精度:训练后动态量化 < 训练后静态量化 < 量化感知训练
在推理速度方面,同样是训练后动态量化最差,因为需要临时计算量化参数:训练后动态量化 < 训练后静态量化 ≈ 量化感知训练
对于 RNN/LSTM/Transformer 等模型,不同句子的词向量差异大,导致量化参数频繁跳变,激活值动态变化范围大,推荐使用训练后动态量化;对于 CNN 等激活分布稳定的模型,则推荐使用训练后静态量化;对精度要求苛刻且允许重新训练的场景,如自动驾驶、医学影像分析、高精度人脸识别等,推荐使用量化感知训练。
3 量化分类总结
根据量化映射是否为线性映射,可以分为线性量化和非线性量化,其中线性量化可以分为对称量化和非对称量化,后文讲的NF4量化则是非线性量化的一种。
根据量化阶段分,则可以分为训练后量化和量化感知训练,前者又可以分为训练后动态量化和训练后静态量化。
根据量化粒度分,可以分为全网络统一量化、逐层量化、逐通道量化和逐块量化。
我们主要关注大模型的量化,关于常规量化方式,只需要知道概念,不需要懂实操。
4 QLoRA量化
4.1 分位数量化与NF4量化
深度学习模型权重大致服从标准正态分布,那么量化的时候可以根据累计概率密度对分布范围(从负无穷到正无穷)划分区间,假如我用4位量化,那就分16个区间( 2 4 = 16 2^4=16 24=16),每个区间的累积概率相同,当权重的值落在这个区间时,我就用这个区间的中点来表示,那么权重从原来的无数种可能的值,变成了只有16种有限可能的值。
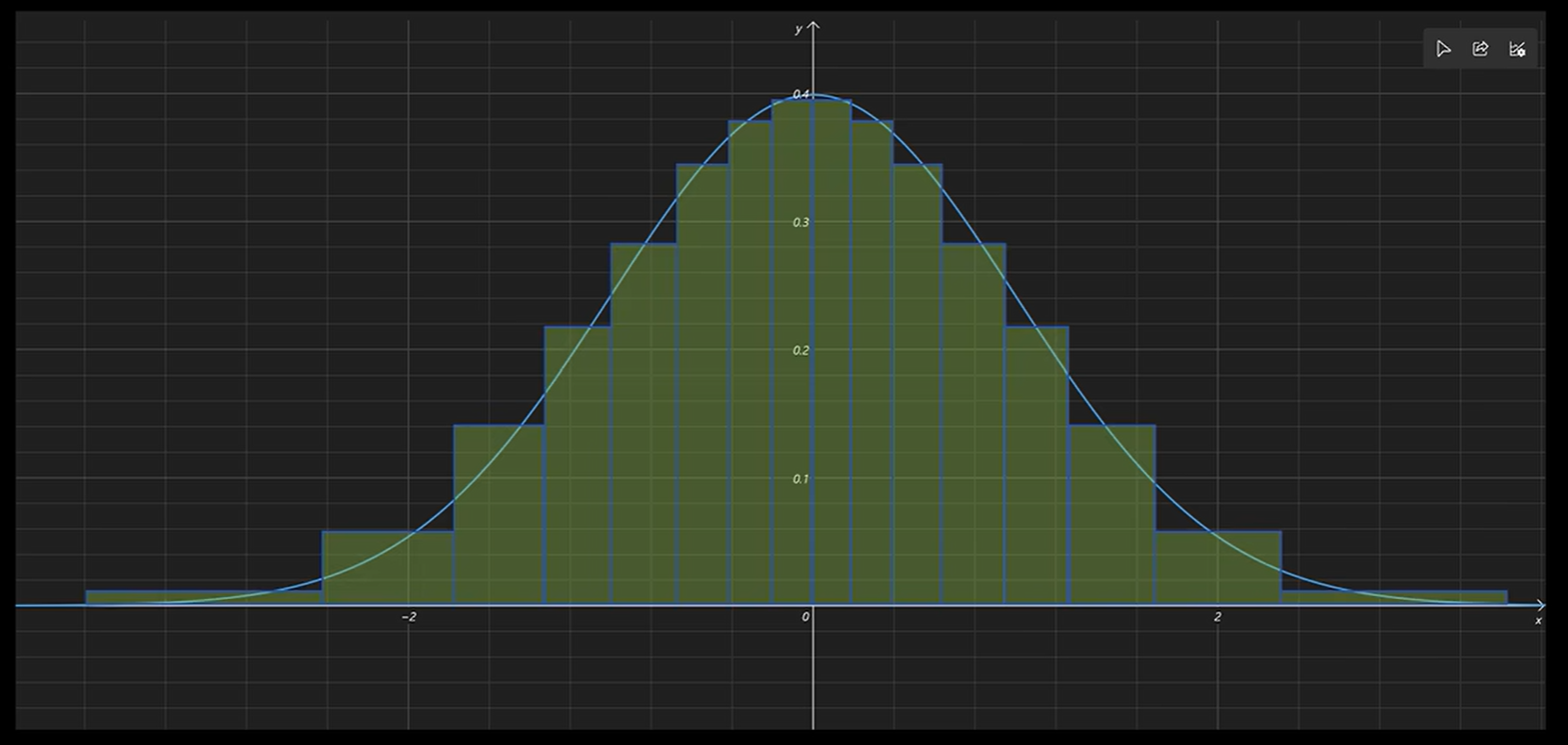
当然,因为数轴是无限的,最左边的区间和最右边的区间,区间中点求不出来,解决办法就是做一个截断,然后再按累积概率重新划分区间并求区间中点,如下图所示:
存储的时候,并不是存储这16个区间中点,而是存储区间编号,比如说,某个值落在了第5个区间,那就存储5,那么模型就从FP16被量化为了一个4位整数,反量化的时候,才是把区间编号转化为区间中点,这一步可以查表获得。
以上就是分位数量化的核心思想,简而言之,就是在分布密集区域(如靠近0的区域)分配更多量化级别,稀疏区域分配更少,从而降低整体量化误差。
NF4量化属于分位数量化的一种,但实现过程和上面有点差别:
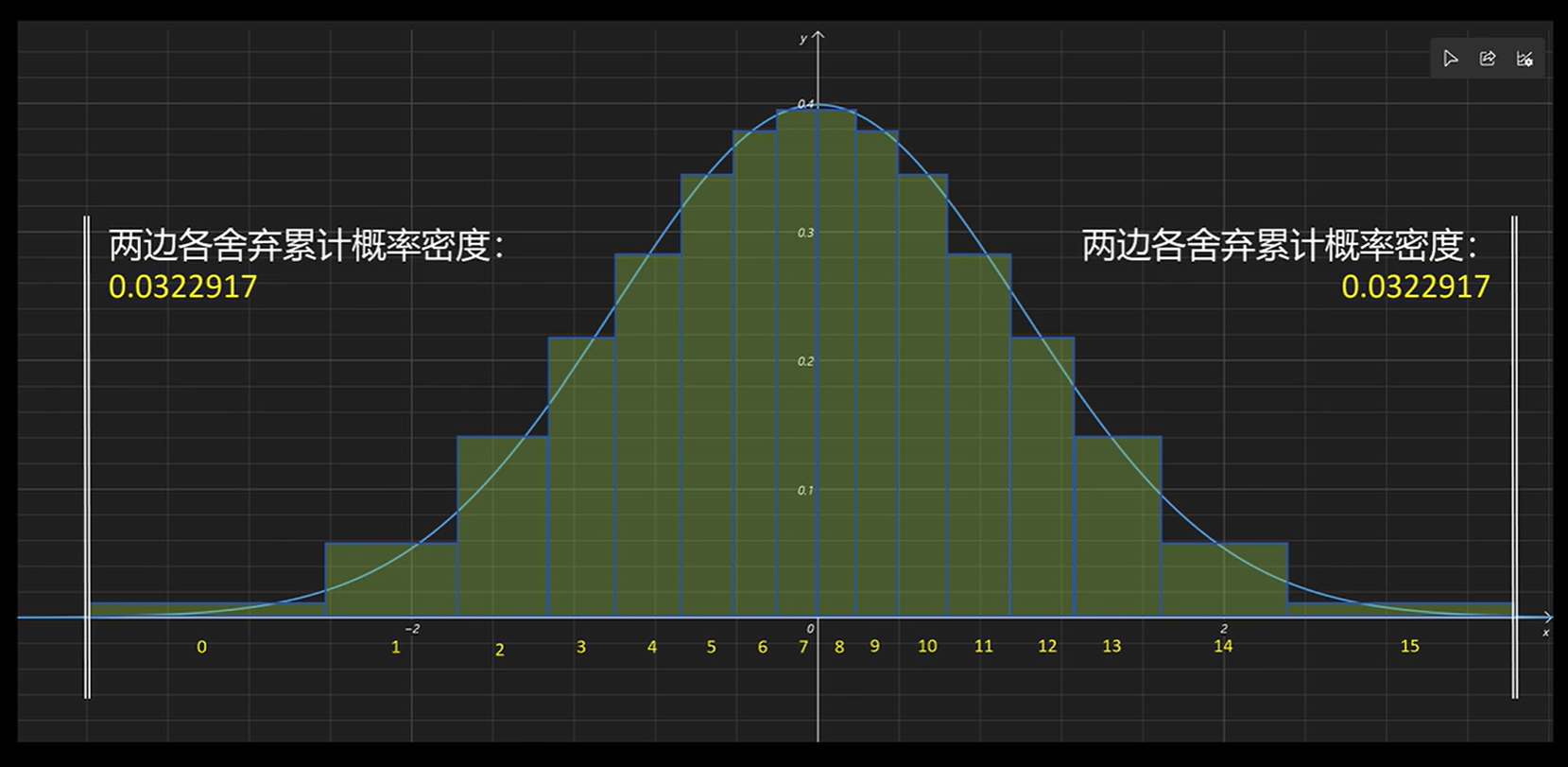
(1)首先在正态分布的两边各舍弃0.0322917的概率。
(2)将数轴的负数部分按照概率密度等分为7个区间,从而可以得到8个累计概率分位数,将数轴的正数部分按照概率密度等分为8个区间,从而可以得到9个累计概率分位数,两个合起来去掉一个0就生成全部的16个分位数,将这16个分位数归一化(除以最大绝对值),即缩放到 [ − 1 , 1 ] [-1, 1] [−1,1] 区间。这里之所以负数和整数的区间数量不一样,主要原因是要把0单独拿出来占用一个量化后的映射值,那么只剩15个映射值,那么0的两边必然不可能相同,第(4)步中会进一步介绍。
(3)模型权重归一化,即除以最大的绝对值 abs_max_weight,把权重缩放到 [ − 1 , 1 ] [-1, 1] [−1,1] 区间,获取分位数的代码如下:
import torch
from scipy.stats import norm# 数轴两端要舍弃的概率
discard_probability = 0.0322917# 将(0.0322917, 0.5)区间7等分,获得8个等分点,这是概率等分点
negative_quantiles_probability = torch.linspace(discard_probability, 0.5, 8)# 根据概率等分点,获取标准正态分布负半轴的分位数,获得的分位数列表,最后一个分位数是0
negative_quantiles = norm.ppf(negative_quantiles_probability).tolist()# 将(0.5, 0.9677083)区间8等分,获得9个等分点,这是概率等分点
positive_quantiles_probability = torch.linspace(0.5, 1-discard_probability, 9)# 根据概率等分点,获取标准正态分布正半轴的分位数,获得的分位数列表,第一个分位数是0
positive_quantiles = norm.ppf(positive_quantiles_probability).tolist()# 将正半轴和负半轴的分位数合并
quantiles = negative_quantiles[:-1] + positive_quantiles
# print(quantiles)# 分位数转Torch张量
quantiles = torch.tensor(quantiles)# 将分位数归一化
abs_max_quantiles = torch.abs(quantiles).max()
quantiles_norm = quantiles / abs_max_quantiles
print(quantiles_norm)输出:
tensor([-1.0000, -0.6962, -0.5251, -0.3949, -0.2844, -0.1848, -0.0910, 0.0000,0.0796, 0.1609, 0.2461, 0.3379, 0.4407, 0.5626, 0.7230, 1.0000])
(4)对模型权重中的每个元素,从16个分位数中找到与其最接近的,并存储其索引,比如权重中某个值为0.99,那么与其最接近的分位数为1.0,它是第15个分位数(从0开始计数),那么就把这个15存下来,也就是说,权重从FP16的0.99被量化为了4位整型15;这里有一个需要注意:若权重归一化后为0.0142,在0和0.0796之间,按理应该舍入到0,但只能舍入到0.0796,因为0具有特殊含义,对于ReLU函数这种,0和非0梯度是不一样的,只有权重是0,才能量化到0,在0的左右两个区间中,都不能舍入为0。即这套量化方案,要保证0、负数、正数,量化之后仍然为0、负数、正数。
(5)反量化时,查表获得分位数索引对应的FP16的浮点数(分位数),然后再乘以 abs_max_weight,例如,4位整型15 对应的 FP16浮点数 为1.0,再乘以 abs_max_weight。
上面的第一步我一直没想明白,既然不是用区间中点作为量化值,那么为啥还要像无限区间取中点的方式舍弃一部分概率?原因我也不知道,不过不重要了。
4.2 QLoRA中的量化过程
在进行LoRA训练时,主模型的权重张量被划分为多个连续的小块(block),每个块的大小通常为 64 或 256,每个块单独使用NF4量化,然后冻结主模型的权重,随后对NF4量化时产生的参数(abs_max_weight)进行再次量化。主模型的激活值、LORA分支上的权重和激活值都不参与量化,因为梯度更新需要较高的精度,而低位量化会导致梯度信息丢失,影响模型收敛,需要保持精度以捕我细做变化。
NF4量化后的权重常驻显存,正向/反向传播到这一层,需要用到权重的时候,才反量化为FP16/BF16浮点数,这是临时恢复,并不常驻显存,计算完成后立即释放。而纯LoRA则是所有层的 FP16/BF16 权重常驻显存,因此QLoRA的显存占用低于纯LoRA。反量化时,NF4量化后的权重通过查表就能获得 FP16/BF16 浮点数,现代GPU可以快速完成。
QLoRA还使用了分页优化器Paged Optimizer,在GPU显存不足的时候可以把optimizer转移到内存中,在需要更新optimizer状态时再加载回来,以此来减少GPU显存的峰值占用。当然,这个属于硬件层面的优化,我们不做深入。
简单来说,就是块量化、NF4量化、二次量化。第一次量化是先对模型权重的每个矩阵分块,然后在各块内对模型权重进行NF4量化;第二次是对NF4量化时的权重参数进行量化,在NF4量化时,由于把权重缩放到了 [ − 1 , 1 ] [-1, 1] [−1,1] 区间,产生了 abs_max_weight,第二次量化就是使用 int8 对这个量化参数进行量化。分块降低了全局归一化的计算成本,并隔离异常值(如梯度爆炸时的离群值),之所以需要二次量化,是因为在NF4量化时,采用了细粒度量化(分块量化),导致量化参数数量庞大(如70B模型需数万个参数),占用显存不可忽略。
4.3 QLoRA的参数配置经验
在QLoRA中,秩(rank)的设置是一个关键的调参环节,直接影响模型的适应能力和计算效率。以下是秩设置的综合建议及分析:
1 理解秩的作用
- 低秩分解原理:QLoRA通过低秩矩阵(维度为 d×r 和 r×d)近似全参数微调,其中 r 是秩。秩越大,近似能力越强,但参数量和计算量也会增加(参数量为 2×d×r)。
- 量化影响:QLoRA结合4-bit量化,显著降低了内存占用,可能允许使用更大的秩而不显著增加资源消耗。
2 秩设置的考量因素
- 任务复杂度:复杂任务(如逻辑推理、多轮对话)通常需要更高的秩(如64或以上),简单任务(如分类)可能只需较小秩(如8-32)。
- 数据集规模:大数据集可支持更高秩(减少过拟合风险),小数据集建议从较低秩(如32)开始,必要时配合正则化。
- 模型规模:大模型(如LLaMA-70B)通常需要更高秩(如64-128),小模型(如7B)可能8-32足够。
- 资源限制:量化虽降低内存压力,但训练时间仍随秩增长线性增加。需在效果和效率间权衡。
3 实践经验与推荐值
- 常见默认值:QLoRA官方示例和社区实践(如Hugging Face PEFT库)常使用 r=64 作为起点,尤其在7B-13B模型中表现稳健。
- 实验策略:
- 初始尝试:从 r=64 开始,若效果不佳,逐步增加至128或降低至32。
- 极端情况:极大数据集或复杂任务可测试 r=128;资源紧张或简单任务尝试 r=32。
- 分层次设置:可对关键层(如注意力模块)分配更高秩,但会引入调参复杂性,通常建议统一设置。
4 过拟合与稳定性
- 小数据集:若秩过高(如>64)导致过拟合,可降低秩或增加Dropout、权重衰减。
- 量化补偿:量化可能损失部分信息,适当提高秩(如从32→64)可能补偿性能,但需验证。
5 实验验证步骤
- 基线测试:使用 r=64 训练,观察验证集损失和任务指标。
- 调整方向:
- 若欠拟合:逐步提高秩(如64→128)或检查数据质量。
- 若过拟合:降低秩(如64→32)或增加正则化。
- 资源评估:监控GPU内存和训练时间,确保秩增加在可接受范围内。
6 参考文献与示例
- QLoRA论文:建议在7B-65B模型中使用 r=64,结合4-bit量化和双阶段训练策略。
- 开源项目:Hugging Face的https://github.com/huggingface/peft提供QLoRA示例,默认配置常为 r=64。
7 总结建议
- 推荐起点:r=64(尤其7B-13B模型)。
- 调参优先级:任务复杂度 > 数据集规模 > 模型大小 > 资源限制。
- 实验必要:最终值需通过A/B测试确定,结合验证集性能和资源消耗综合选择。
通过合理平衡这些因素,可以高效地设置QLoRA的秩,优化模型性能与资源消耗。
5 LLM.int8(): 大规模语言模型的无损8比特量化
5.1 问题背景:传统量化的局限性
传统量化方法在大型语言模型(LLM)中面临两大挑战:
-
离群值特征(Outlier Features)
大模型的中间激活(如注意力层输出)存在极端异常值(绝对值远超其他值),当然,说它是异常值并不准确,因为有可能是从输入中获得的重要特征,这种特征确实明显大于其他特征。由于这种极端离群值的存在,若使用传统量化方式,在量化的时候会使得其他特征被压缩到0附近,导致在反量化后与原始特征有较大差异,进而导致精度下降。
-
误差放大效应
低精度(INT8)无法准确表示离群值,导致矩阵乘法中的误差被指数级放大,破坏模型输出质量。
5.2 核心原理
(1) 动态异常值分离
- 逐向量检测:对每个输入向量计算绝对值最大值。
- 阈值判定:若某特征的绝对值超过预设阈值(一般阈值设为6),标记为离群值向量。
- 分离存储:离群值保留为FP16/FP32,常规值量化为INT8。
- 记录位置:需要专门有一套参数去记录异常值在原矩阵中的位置。
(2) 矩阵乘法的混合精度计算
将原始计算分解为两部分:
W X = W int8 X int8 ⏟ 低精度高效计算 + W fp16 X fp16 ⏟ 高精度保精度 WX = \underbrace{W_{\text{int8}}X_{\text{int8}}}_{\text{低精度高效计算}} + \underbrace{W_{\text{fp16}}X_{\text{fp16}}}_{\text{高精度保精度}} WX=低精度高效计算 Wint8Xint8+高精度保精度 Wfp16Xfp16
- INT8 计算:对常规值部分使用高效的 INT8 矩阵乘法(占用显存极低),当然,算完之后还需要反量化为FP16/FP32。
- FP16/FP32 计算:对异常值部分保留高精度计算(确保精度不丢失)。
5.3 关键优势
| 特性 | 说明 |
|---|---|
| 显存节省 | 权重显存降低50%(FP16→INT8) |
| 零精度损失 | 在BLOOM-176B等模型上,困惑度(Perplexity)与FP16基线完全一致 |
| 计算效率 | INT8计算速度接近FP16,异常值计算占比通常<1% |
| 模型兼容性 | 支持所有Transformer架构(GPT-3、T5、LLaMA等) |
下图中,绿线是未量化的大模型在 zero-shot (未给参考示例的情况下让模型判断,就称为 zero-shot)的精度,即原始精度,橙色线是使用8位传统量化的精度,蓝线是使用 LLM.int8() 量化后的精度:
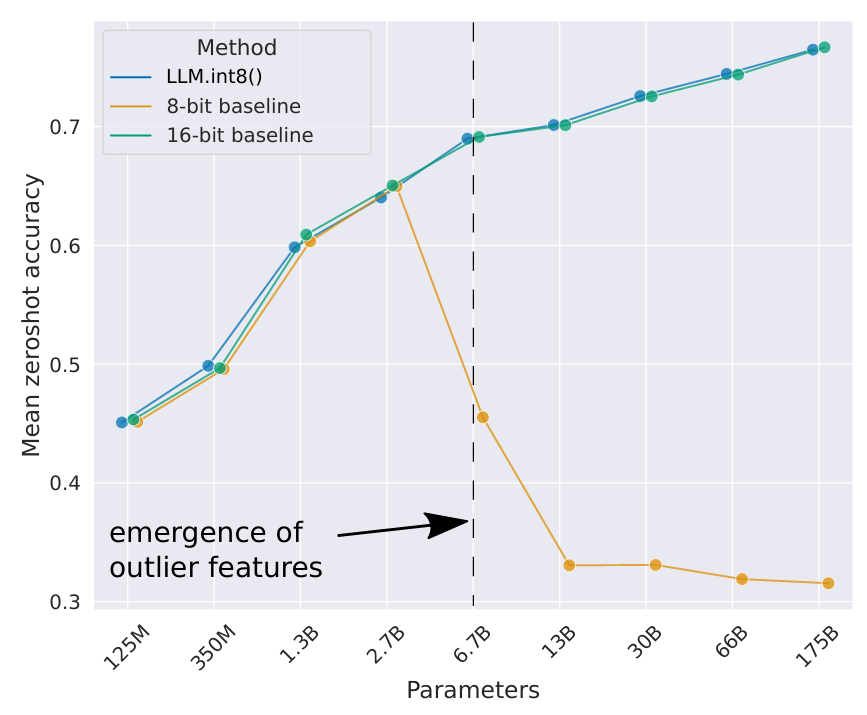
随着模型参数的扩大,离群特征的数量也在急剧增加,当增加到一定程度后,使用传统的8位量化会使精度暴跌。而如果使用LLM.int8()量化,则量化后的模型精度始终与原始精度相当。
5.4 实验数据
- 显存占用
FP16下175B模型需350GB显存 → LLM.int8()仅需175GB。 - 推理速度
INT8计算速度达FP16的90-95%,整体延迟增加约10-15%。 - 精度验证
在WikiText、C4等数据集上,量化后困惑度与原始模型误差<0.1%。
5.5 使用场景与代码示例
适用场景
- 单卡推理:在24GB显存的RTX 4090上运行13B-20B参数模型。
- 边缘部署:资源受限设备运行大模型。
代码实现(Hugging Face集成)
from transformers import AutoModelForCausalLM# 加载模型时启用 LLM.int8() 量化
model = AutoModelForCausalLM.from_pretrained("facebook/opt-6.7b",load_in_8bit=True, # 启用 8 比特量化device_map="auto" # 自动分配 GPU/CPU 资源
)# 正常执行推理
input_text = "Hello, I am"
outputs = model.generate(input_text, max_length=50)
print(outputs)
局限性
离群值计算开销:如果离群值占比过高(某些特殊模型结构),高精度计算部分可能拖慢速度。
训练支持有限:当前 LLM.int8() 主要针对推理优化,训练支持仍在完善中。
总结
LLM.int8() 通过 动态分离离群值 + 混合精度计算,首次实现了大语言模型的无损 8 比特量化,是资源受限场景下运行大模型的革命性技术。其设计思想(针对模型特性动态调整量化策略)也为其他领域的模型压缩提供了重要启发,是Bitsandbytes库的默认算法。
6 使用LLaMA Factory进行量化训练与导出
6.1 QLoRA训练
打开LLaMA Factory的 UI 界面:
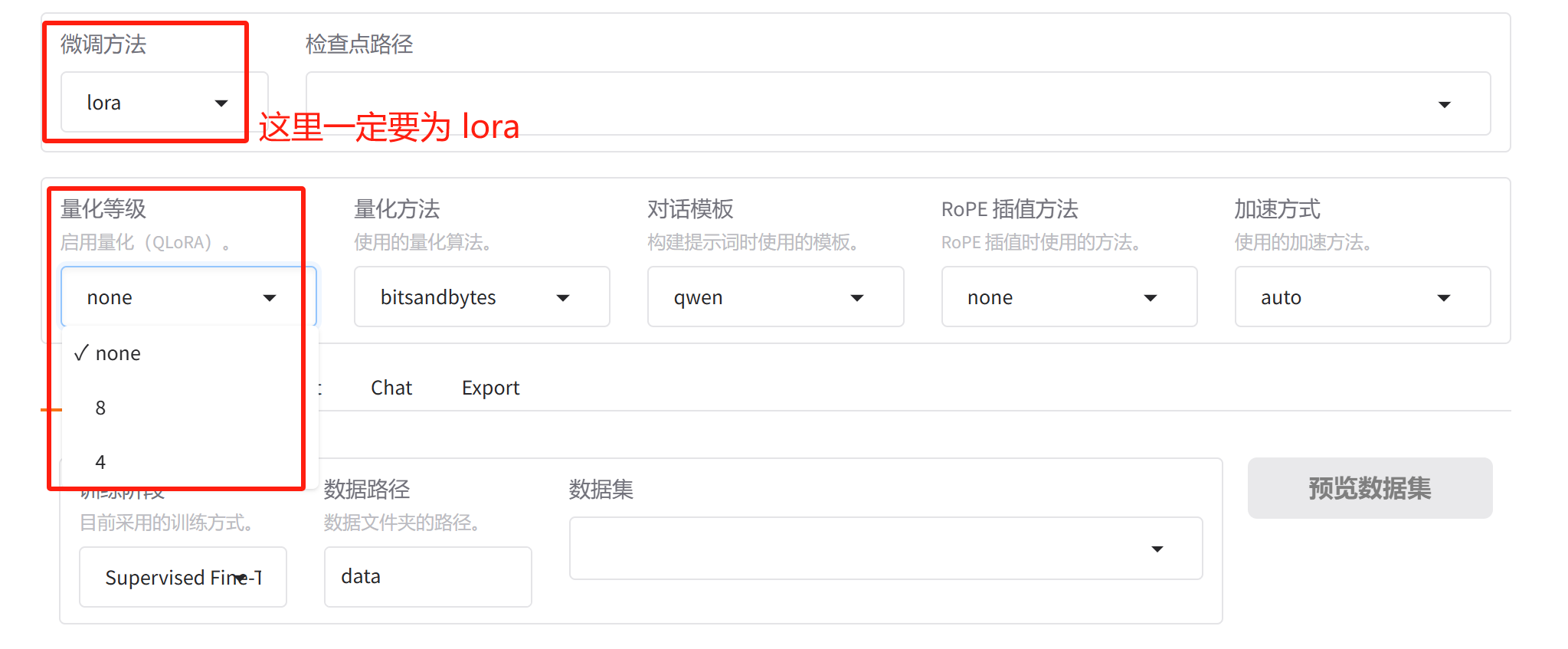
微调方法选择lora,此时,如果量化等级选择 None,则是纯 LoRA 微调;如果量化等级选择 4,则是主模型的量化方法是 NF4 量化,这是最正宗的 QLoRA 微调;如果量化等级选择 8,则主模型为 LLM.int8()量化,不会分块,也不会二次量化。
QLoRA微调完成之后,检查点保存的是 LoRA 分支(即低秩适配器),这是 FP16/BF16 的数据类型,合并导出的时候,主模型是同样是 FP16/BF16,也就是说,QLoRA的量化仅仅发生在训练期间。
6.2 量化导出
在导出前需要先加载模型,加载的时候其实也可以选择量化加载,它其实是对主模型加载后做了个量化,这个过程和微调时一致(因为QLoRA微调时,也仅仅是量化主模型,且主模型参数冻结):
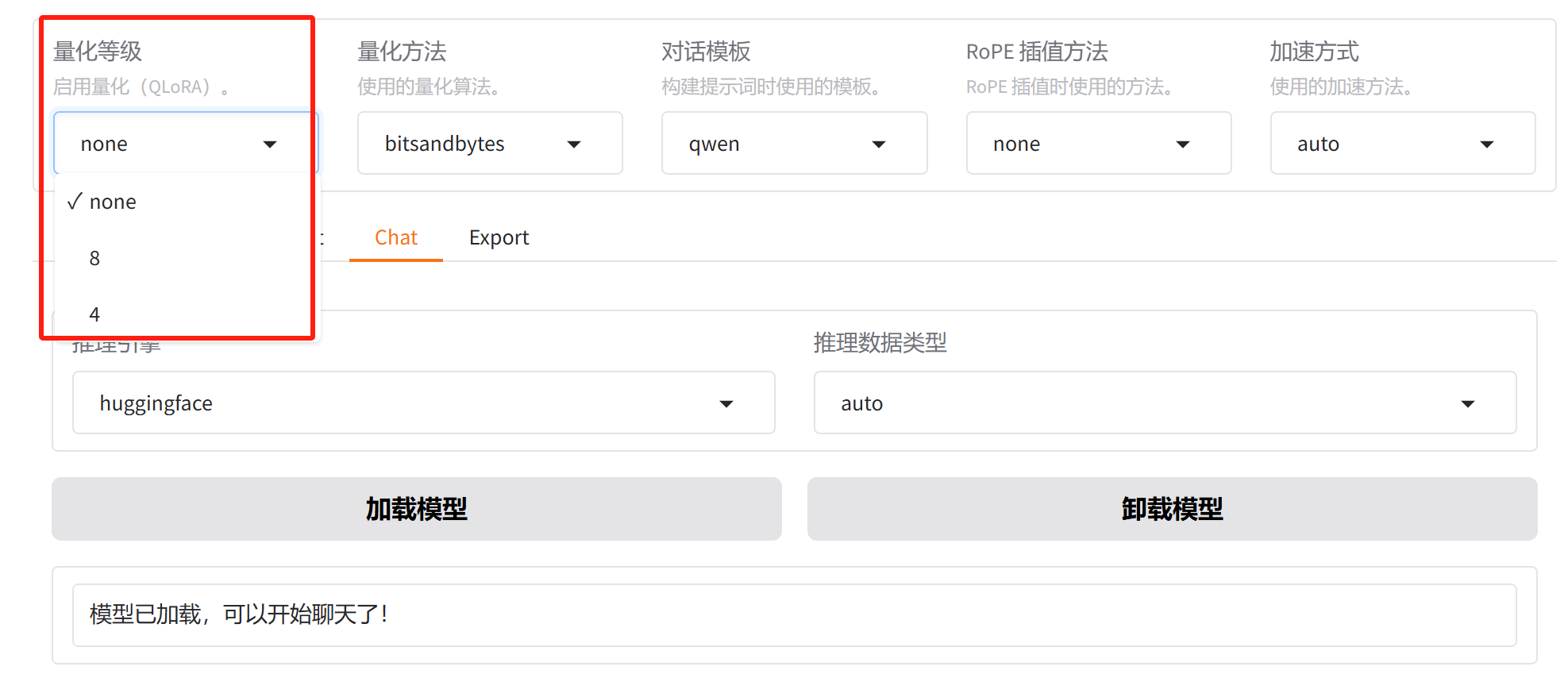
选8就是 LLM.int8() 量化,选4就是NF4量化。
QLoRA微调结束之后,需要先普通导出,其实就是用原始主模型(没有量化)和LoRA分支进行合并,就是我们上节课介绍的方式,即先加载,后导出。
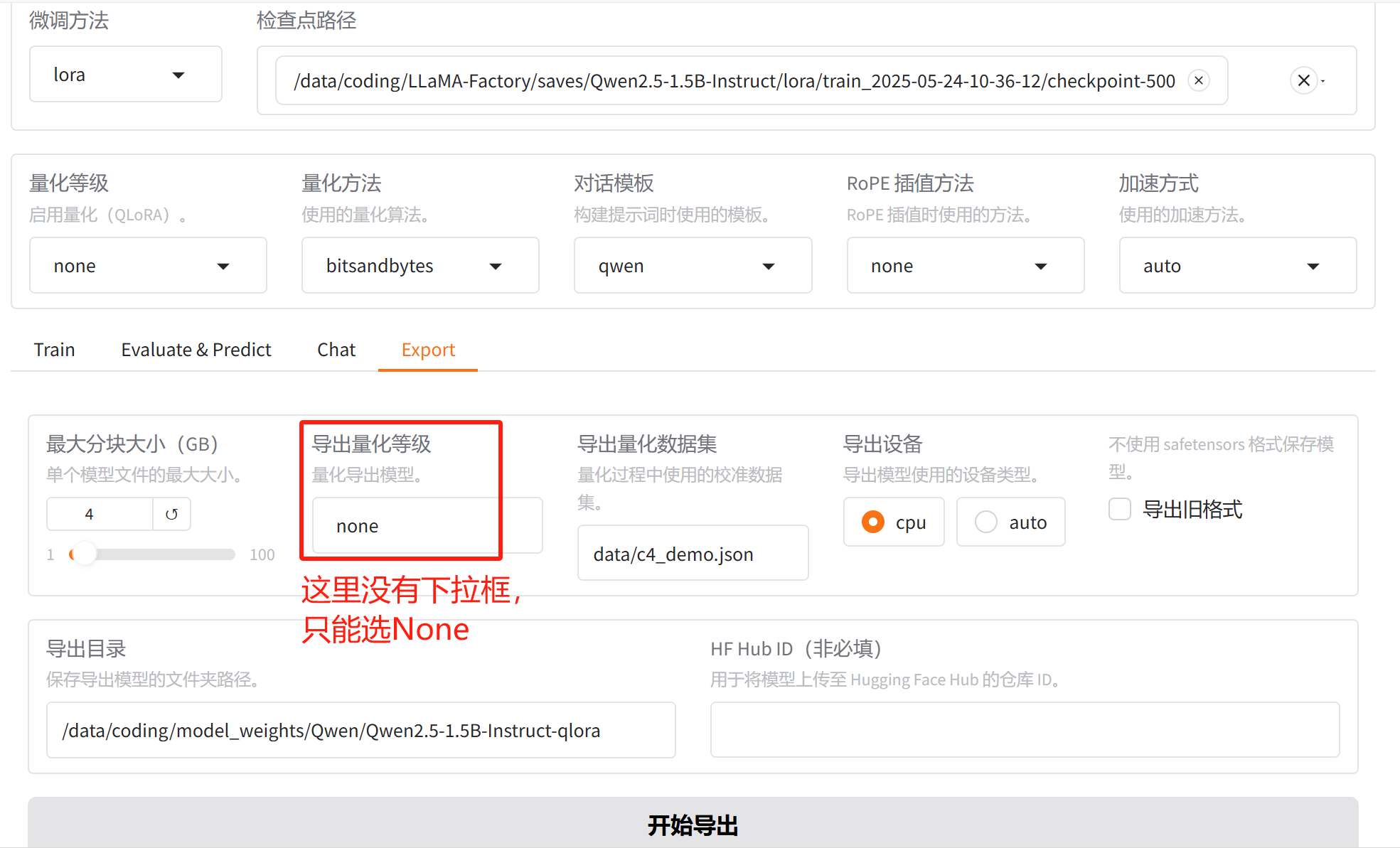
普通导出完成后,把导出的模型再加载进来,然后才能量化导出。加载导出的模型可以按下面截图 1 2 3的顺序:
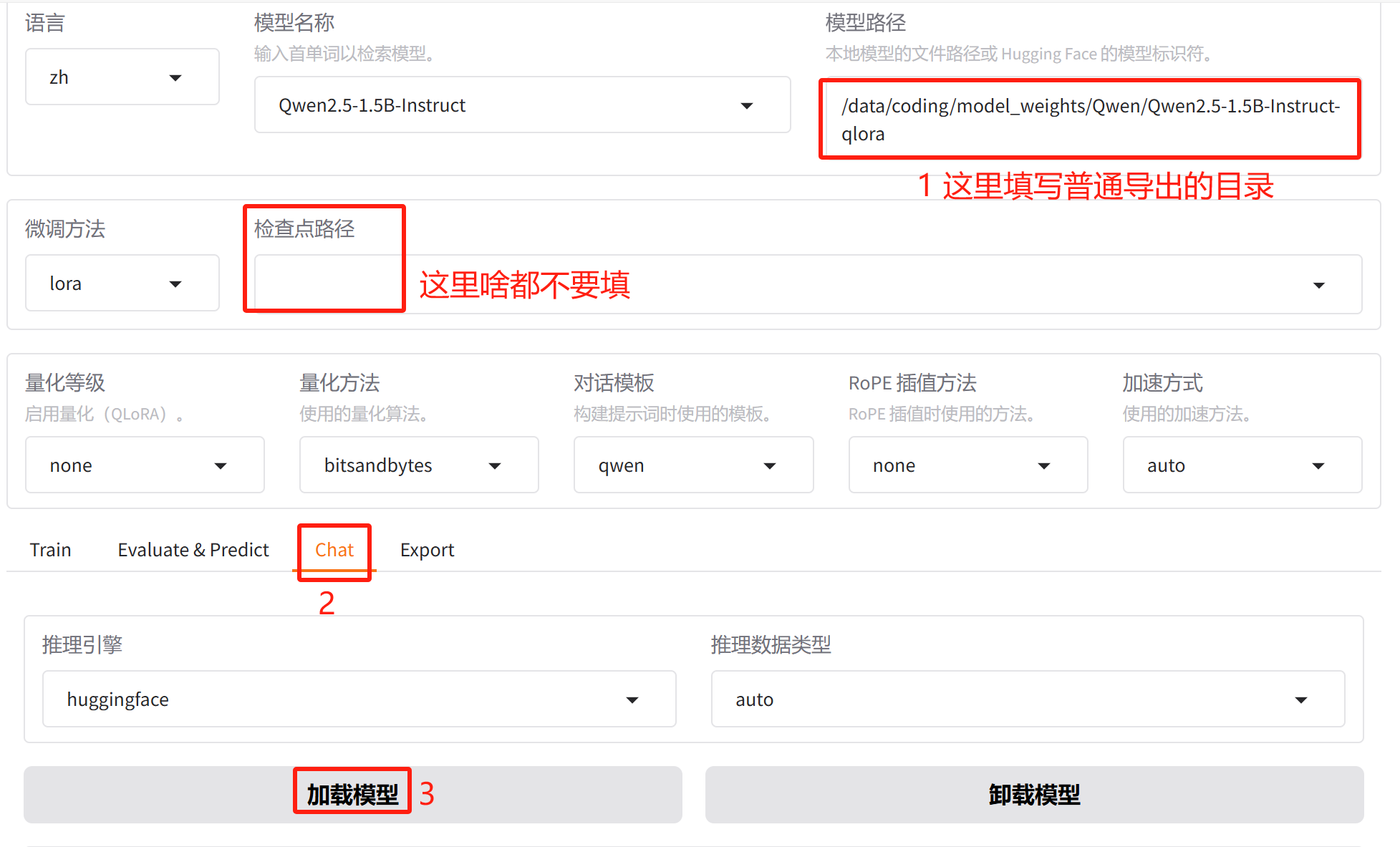
接下来按下面的方式量化导出:
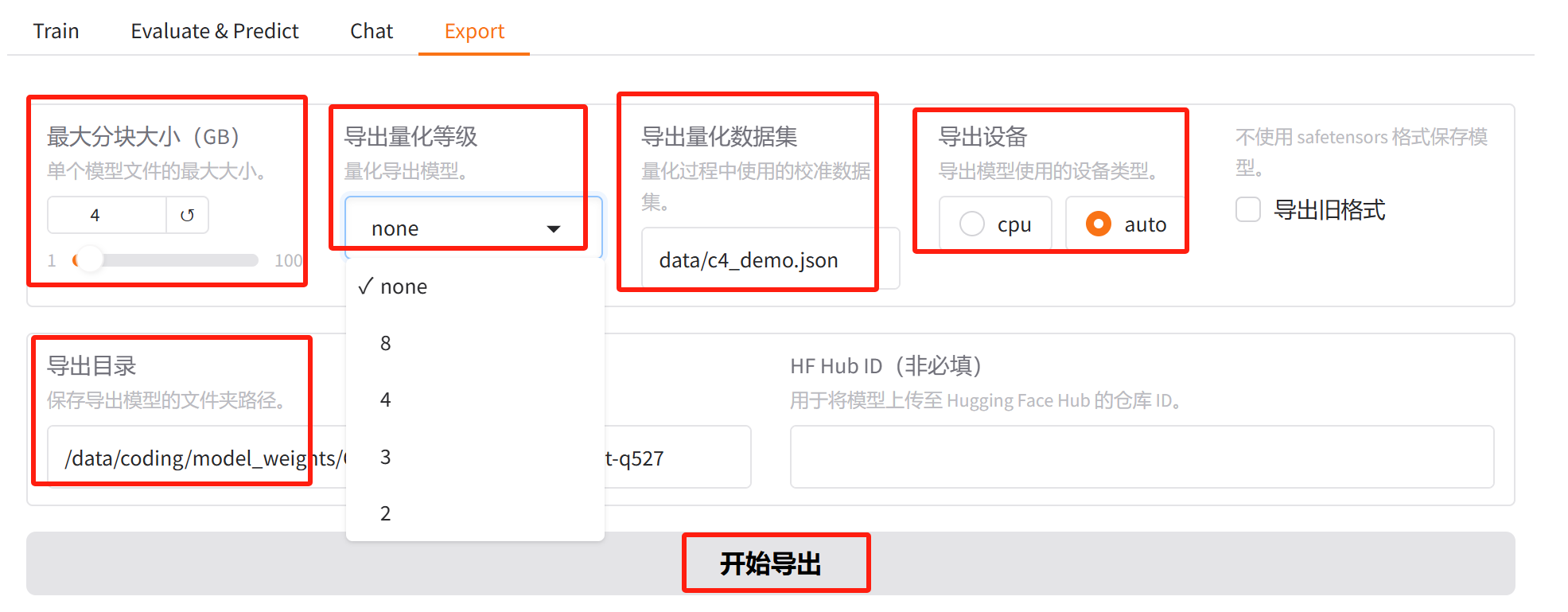
量化导出时,用的算法是GPTQ,它是一种训练后量化的算法,我们不去细究具体原理,这里需要提前安装optimum>=1.17和auto_gptq两个包。量化导出一般是选择 8 比特;导出量化数据集其实就是校准数据集,这个一般选择默认的 c4_demo.json 就可以;导出设备默认是cpu,导出的时候需要把 LoRA 分支合并到主模型,如果有 GPU 可用,那么可以选择 auto,量化导出还是比较花时间的,因为需要用校准数据集跑一遍模型,并计算出量化参数,建议导出设备选择 auto。
我们可以对比普通导出的模型和量化导出的模型的显存占用情况。
下面是普通导出的模型的显存占用(将导出的模型在 Chat 选项卡加载进来,然后新开一个终端,输入 nvitop):
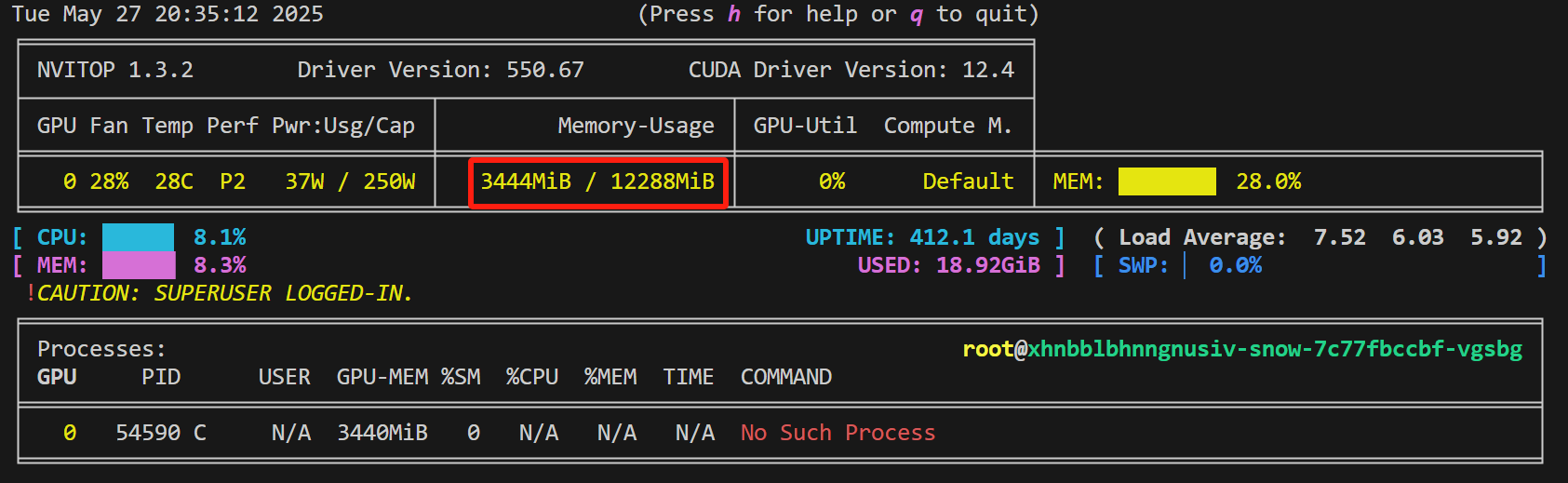
下面是普通导出的模型的显存占用(加载方式和前面一样,但加载量化模型非常耗时):
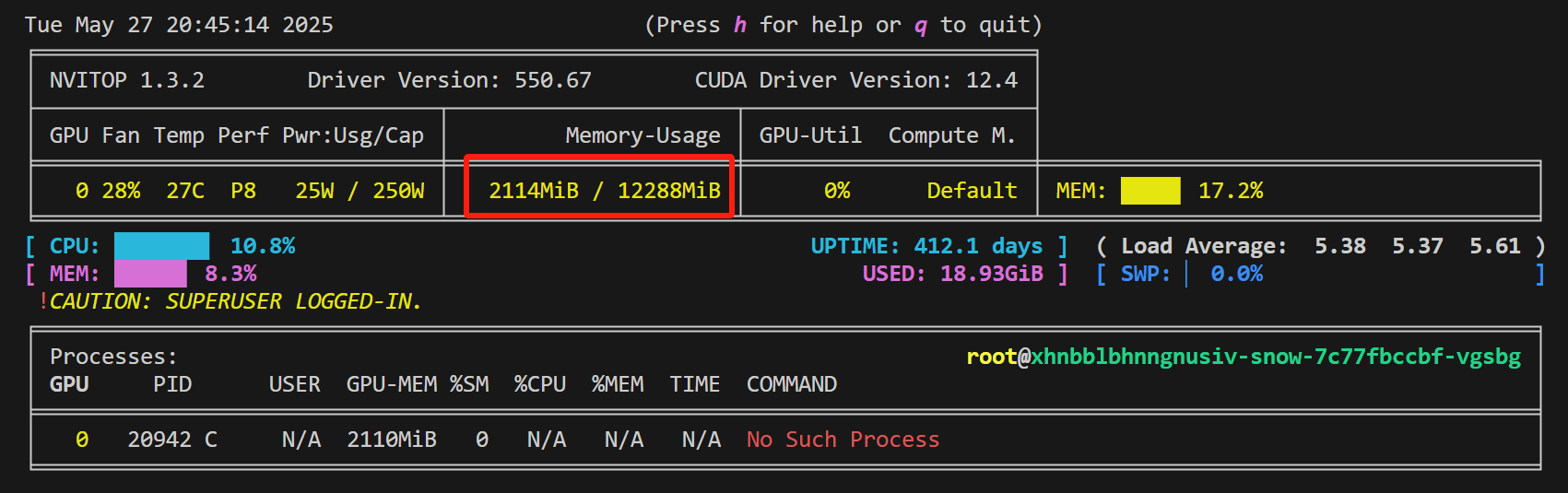
可以看到,量化导出的模型,显存占用只有普通导出的模型(即没有量化的模型)的三分之二。理论上,量化后的模型,显存占用只有原来的一半,这里除了模型之外,估计还有其他程序占用了显存。
6.3 关于 LLaMAFactory 导出量化模型或者QLoRA训练时的环境问题
如果在新建环境后,马上安装 LLaMAFactory,那么会自动安装它的依赖环境,并且依赖包都是最新的,包括PyTorch,我的设备上,自动安装的是PyTorch 2.7。
此时使用 LLaMAFactory 导出量化模型,可能会报下面的错误:
importlib.metadata.PackageNotfoundError: No package metadata was found for The 'bitsandbytes>=0.37.8' distribution was not found and is required by this application
此时,如果你pip install bitsandbytes==0.37.8,则有可能报下面的错误:
raise RuntimeError(
RuntimeError: Failed to import transformers.integrations.bitsandbytes because of the following error (look up to see its traceback):CUDA Setup failed despite GPU being available. Inspect the CUDA SETUP outputs above to fix your environment!If you cannot find any issues and suspect a bug, please open an issue with detals about your environment:https://github.com/TimDettmers/bitsandbytes/issues
如果你pip install bitsandbytes==0.43.3,则有可能报下面的错误:
raise RuntimeError(
RuntimeError: Failed to import transformers.integrations.bitsandbytes because of the following error (look up to see its traceback):
No module named 'triton.ops'
其实,根本原因是高版本 PyTorch(如 2.6+)可能与 bitsandbytes 不兼容,导致依赖链异常。最好是新建一个conda环境,然后手动安装PyTorch 2.5 版本,随后安装 LLaMa Factory 以及 bitsandbytes:
pip install torch==2.5.1 torchvision==0.20.1 torchaudio==2.5.1 --index-url https://download.pytorch.org/whl/cu124
pip install e .
pip install pydantic==2.10.6
pip install bitsandbytes==0.43.3
7 关于 Bitsandbytes(了解即可,不重要)
bitsandbytes 是一个库,内部实现了多种 量化算法 和优化技术。这个库主要用于处理数值计算中的精度问题,并且特别关注于优化深度学习模型的训练和推理过程。它提供了多种工具和方法来实现数值稳定性和效率的提升,尤其是在使用低精度数据类型(如8位整数)进行模型量化时非常有用。通过利用bitsandbytes,开发者可以更高效地部署深度学习模型,同时减少计算资源的需求。
7.1 bitsandbytes 是一个库
-
功能定位:
bitsandbytes是一个专为 PyTorch 设计的库,旨在通过 低精度量化(如 8-bit、4-bit)和 优化器 来降低大型模型(如 LLM)的内存占用和计算需求。- 它提供了 API 和工具链,支持模型训练、推理、微调(如 QLoRA)等场景。
- 内部封装了多种量化算法和优化策略(如
LLM.int8()、4-bit 量化等)。
-
核心特性:
- 8-bit 优化器(如
Adam8bit):减少训练时优化器状态的内存占用。 - 模型量化:支持将模型权重量化为 8-bit、4-bit 等低精度格式,显著节省显存。
- 硬件兼容性:主要支持 NVIDIA GPU,未来可能扩展到其他硬件(如 CPU、AMD GPU)。
- 8-bit 优化器(如
-
使用方式:
通过安装库(pip install bitsandbytes)后,调用其 API 对模型进行量化或优化。例如:from transformers import AutoModelForCausalLM, BitsAndBytesConfig bnb_config = BitsAndBytesConfig(load_in_8bit=True) # 启用 8-bit 量化 model = AutoModelForCausalLM.from_pretrained("model_id", quantization_config=bnb_config)
7.2 bitsandbytes 包含的量化算法
库中实现了多种 量化算法,这些算法是其核心功能的一部分。例如:
-
LLM.int8():
- 针对大语言模型的 8-bit 量化方法,通过 离群值检测(outlier detection)处理异常值,避免量化误差累积。
- 将权重矩阵中 99.9% 的非离群值量化为 8-bit,离群值以 16-bit 浮点数处理,最终显存占用减少约 50%。
-
4-bit 量化:
- 支持
fp4和nf4数据类型(4-bit 浮点数),进一步压缩模型体积。 - 结合 双重量化(double quantization)和 分页优化器(paged optimizer)技术,适配 QLoRA 微调场景。
- 支持
-
动态量化:
- 不需要校准数据集(data-free),直接在模型加载时动态量化,适合快速部署。
7.3 与 HQQ 和 EETQ 的区别
bitsandbytes、HQQ、EETQ 都是量化技术,但各有特点:
-
bitsandbytes:- 以库的形式提供,功能全面,支持训练和推理,适合 PyTorch 生态。
- 量化算法(如
LLM.int8())注重 离群值处理 和 训练兼容性。
-
HQQ:- 专注于 低比特量化(4-bit 及以下),无需校准数据,推理速度极快。
- 通过 半二次优化(Half-Quadratic Optimization)减少量化误差,适合对精度要求高的场景。
-
EETQ:- 仅对权重进行三值量化(-1, 0, 1),简化计算逻辑,适合硬件加速。
- 无需激活值量化,实现简单且高效。
总结
bitsandbytes是一个库,提供量化算法、优化器等工具,简化低精度模型的开发和部署。- 其核心算法(如
LLM.int8()、4-bit 量化)是库的核心能力之一,但需要通过库的 API 调用。 - 如果你需要快速实现模型压缩并兼容 PyTorch 流程,
bitsandbytes是首选;如果需要更灵活的低比特量化(如 4-bit、3-bit),可结合HQQ或EETQ。