TPAMI 2025 | CEM:使用因果效应图解释底层视觉模型

底层视觉可解释性专题:https://x-lowlevel-vision.github.io/
论文:https://arxiv.org/abs/2407.19789
代码:https://github.com/J-FHu/CEM
动机
在底层视觉领域,深度学习模型虽极大提升了任务性能,但其内部运行机制宛如黑盒,行为逻辑模糊不清。深度剖析这些模型,对优化网络架构、强化实际应用可靠性至关重要。为攻克这一难题,我们引入因果推理理论用以阐释底层视觉模型,并推出解释工具 —— 因果效应图(Causal Effect Map, CEM)。CEM具有良好的通用性,能适用于各类底层视觉任务及不同的网络结构。借助CEM,我们能够直观量化输入与输出之间的正、负效应关系,为底层视觉模型的解释开辟了全新视角。
通用性
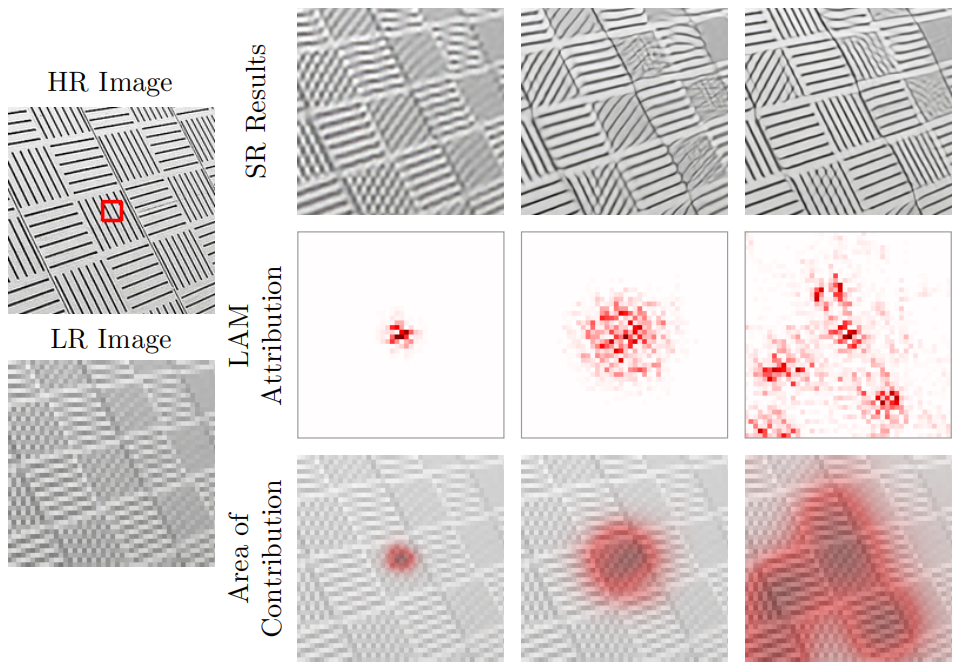
在过往研究中,Gu等人提出的 Local Attribution Map(LAM)[1],运用积分梯度方法,揭示了超分辨率网络里输入图像的不同区域与特定区域超分结果间的相关性。LAM 这一成果,为超分辨率领域的研究提供了关键的结论,如下图所示,使用LAM可以发现不同超分网络对输入图像的利用差异,这极大增进了我们对超分网络的理解。但 LAM 的计算基于图像超分,这就决定了它只适用于超分辨率网络,在其他底层视觉任务中无法应用 。
因果性
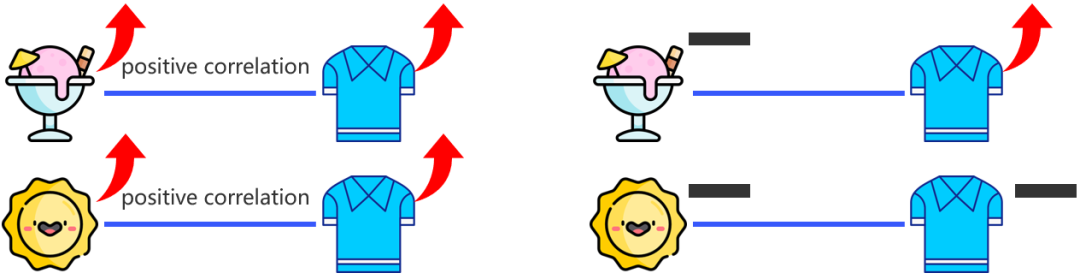
为了追寻对神经网络更科学更严谨的理解,我们希望从相关性分析深入为因果性分析。仅仅观察到两个事件或变量之间存在相关性,并不能就此认定它们存在因果关系 [2]。如下图左所示例子,如果我们统计冰淇淋和T恤销量会发现这两者呈现正相关性,同时温度和T恤销量也是正相关性。但从本质逻辑判断,冰淇淋销量的增长并非引发 T 恤销量上升的原因。这清晰地表明,相关性与因果性之间不能简单划等号。do 算子是因果推理中一个用于实现干预(Intervention)的重要算子。通过干预我们才能判断出变量间的因果性。如下图右所示,若对冰淇淋销量实施干预措施,使其每日销量维持恒定,即执行 do (冰淇淋销量 = 常数) 操作,此时可观测到 T 恤销量并不会随之趋于平稳;而当对温度进行干预,使每日温度保持一致,即 do (温度 = 常数),则 T 恤销量将不会产生显著波动。通过系统地观察与分析一个变量在另一变量接受干预前后的变化,我们得以准确判断变量间的因果关系,为深入理解神经网络的内在机制提供了关键方法与全新视角。
底层视觉中的干预
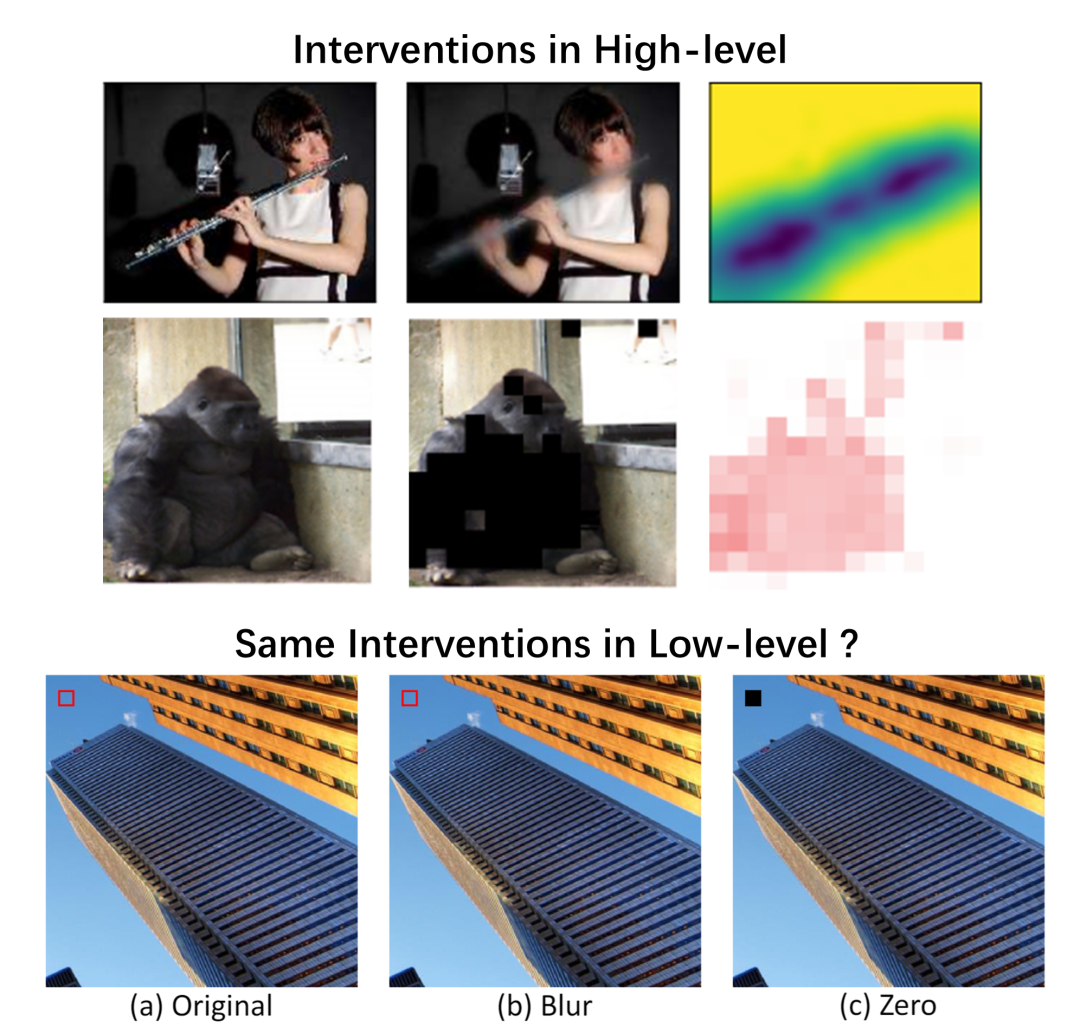
既然明确了通过干预操作能够判断变量间的因果性,接下来我们就要思考如何在底层视觉任务中实施干预。以图像识别为代表的高层视觉任务,其干预方式如下图所示,常见做法包括模糊处理或者采用 zero mask(零掩码)。通过抹除图像不同位置的语义信息,观察该位置对网络预测结果产生的影响,进而推断出因果效应。然而这样的方式无法直接使用在底层视觉任务中,例如下图所示,模糊操作没有带来有意义的干预,而zero mask操作则太过强烈的破坏了像素信息。鉴于此,我们认为在底层视觉任务中实施干预应遵循两项基本原则:其一,干预必须具备实际意义,能够切实带来图像内容上的实质性改变;其二,干预过程应确保无害,不能使图像严重偏离自然图像分布。另外,底层视觉模型大多与图像的退化(Degradation)相关,若干预行为改变了输入图像中的退化类型及程度,网络行为极有可能受到这些不一致的退化因素干扰。因此,我们进一步提出,底层视觉任务中的有效干预应保证不改变原有的退化分布,以此保障底层视觉模型的稳定运行与准确分析。
基于上述分析,我们决定从自然图像库获取干预图像块,并通过多次干预计算期望。这一方法得出的结果,在一定程度上反映了该区域在平均情况下对重建的基础作用。选择自然图像库中的图像块,可确保干预不会过度偏离自然图像的分布。同时,多次干预能够有效消除单次干预可能产生的偏差,使结果更具可靠性与代表性。
最终我们因果效应图(Causal Effect Map,CEM)的整体计算流程如下图所示:
1.原始输入图像 I 经由模型 F 处理后,运用图像质量评价指标 M_R (在本文中为 PSNR)来测算绿色框选的感兴趣区域 ROI 的重建效果。
2.我们从自然图像库 N 中随机选取干预图像块 x_t ,用以替换输入图像 I 中的区域 p_i 。随后,对干预后的图像经模型 F 输出的 ROI 重建结果进行量化。通过执行 T 次干预操作,计算干预效果的期望值。
3.通过计算干预前图像 I 与干预后图像 I’ 的输出图像差异,从而得到区域 p_i 所对应的因果效应。当因果效应大于 0 时,表明原始的 p_i 相较于平均结果产生了正向贡献;而当因果效应小于 0 时,则意味着原始的 p_i 相较于平均结果造成了负向贡献。
一些有趣的发现
机制诊断
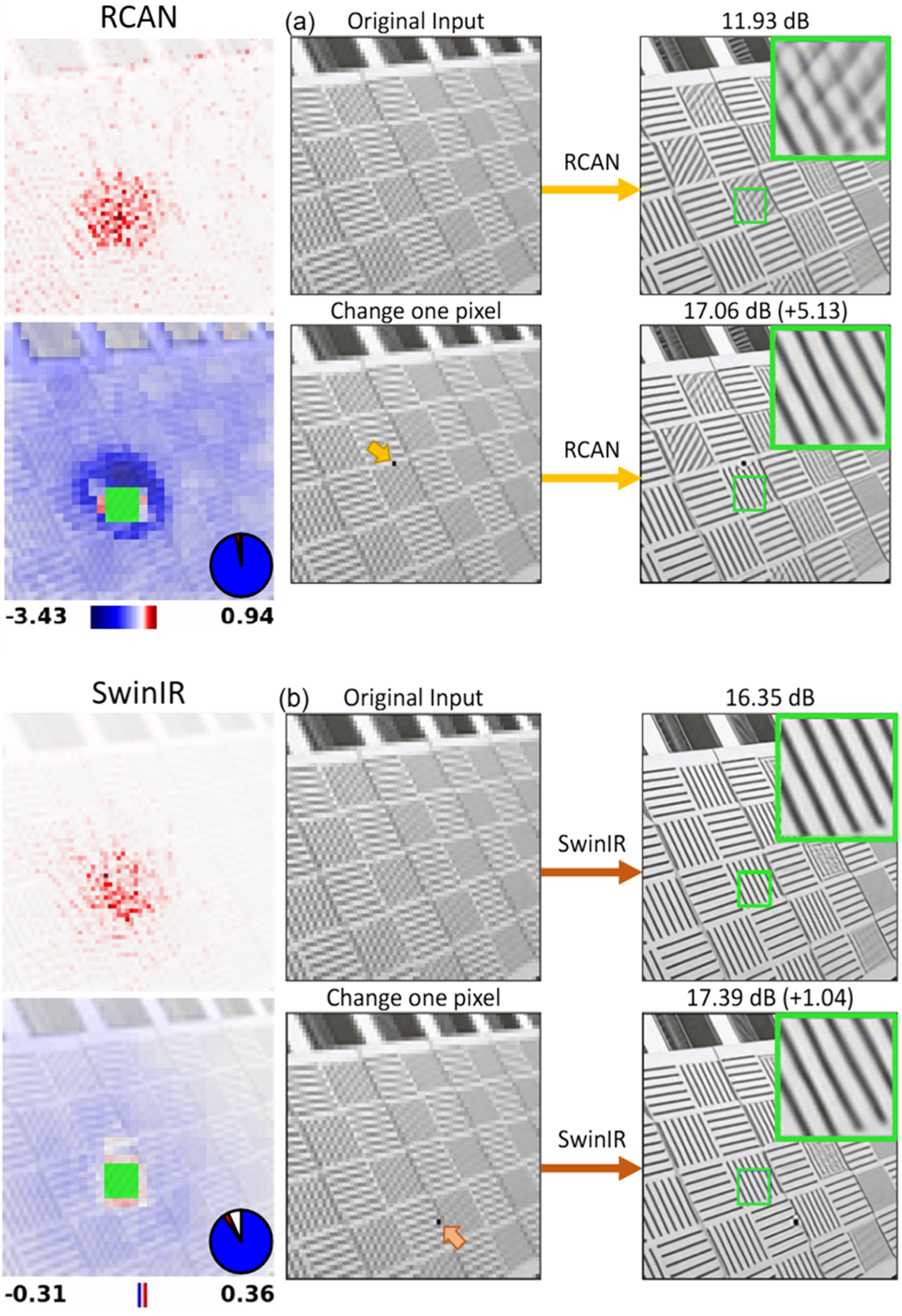
如下图所示,通过对比RCAN [3]和SwinIR [4]的LAM结果,我们注意到在 RCAN 模型中,与ROI重建相关的区域数量更多。依据先前研究的结论,模型若能利用更多的区域信息,通常应当会取得更为理想的效果。然而,令人费解的是,为何在 RCAN 的结果中却出现了纹理错误的情况呢?
如下图通过CEM 进行深入剖析,谜团得以解开:原来在 RCAN 中,大部分的输入区域对 ROI 的重建产生了显著的负向影响,而且这种影响的程度相当大,最大的负向效应达到了 3.43 dB。相较之下,SwinIR 的表现则相对稳定,其输入图像中的区域不会给 ROI 的重建带来过于严重的干扰。此外,我们还进行了这样的实验:当改变 RCAN 模型中产生最负向贡献区域内的一个像素值时,惊喜地发现 ROI 的重建效果最多可提升 5.13 dB,同时错误的纹理也能够得到有效的纠正。而对于 SwinIR 模型,在改变其产生最负向贡献区域内的一个像素值后,ROI 的重建效果最多仅能提升 1.04 dB。
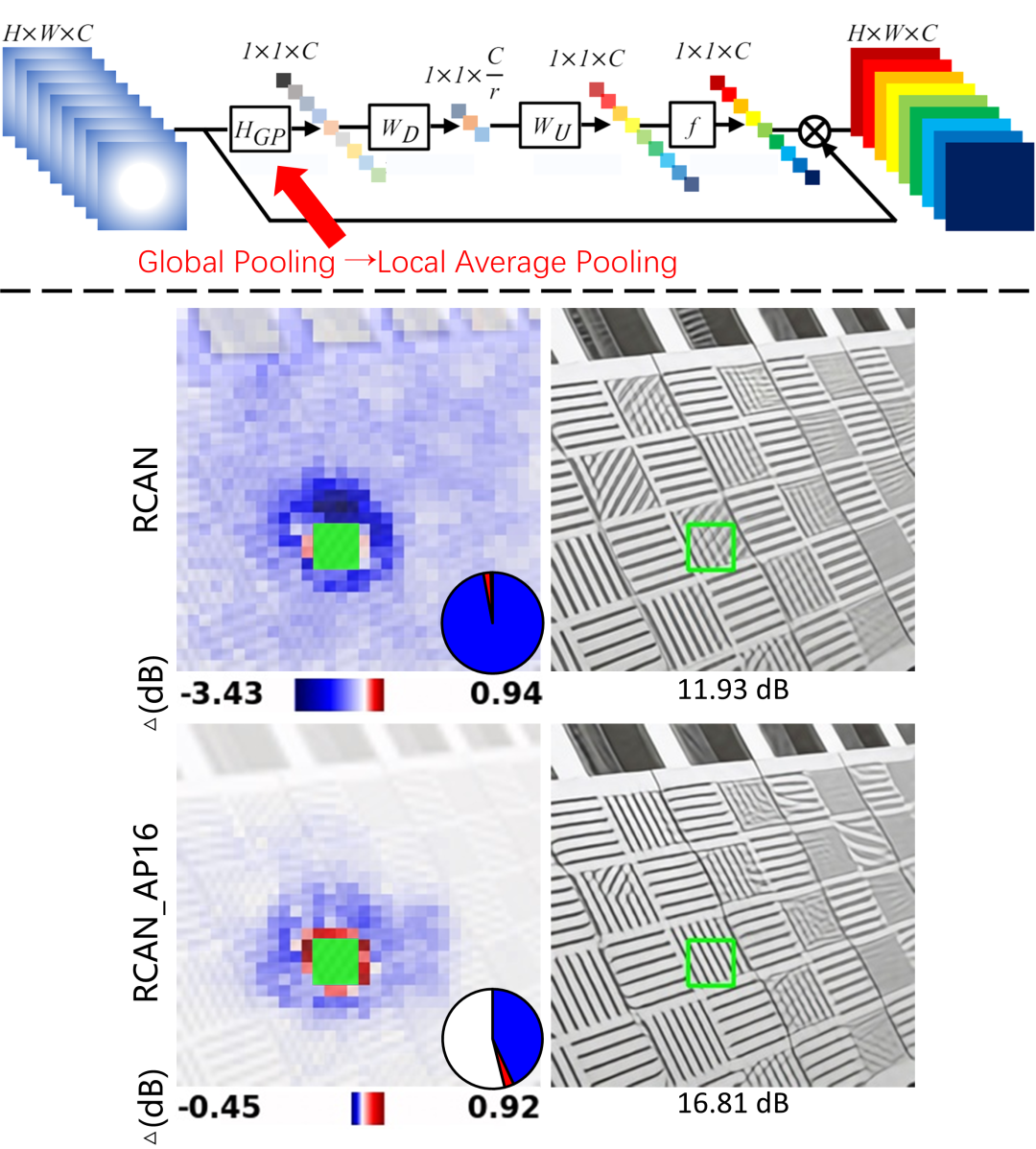
为了深入探究 RCAN 模型出现问题的根源,我们开展了进一步的研究。RCAN 模型的众多层级中都集成了通道注意力机制,而在这一机制的运算过程中,存在着全局池化(Global Pooling)这一关键步骤。该步骤会将维度为 H×W×C 的特征图在空间维度上进行压缩,最终得到维度为 1×1×C 的向量。我们推测,这一过程中的信息压缩程度可能过高,对于像素级的图像超分辨率任务而言,这种过度的信息压缩或许是不利的。
基于以上推测,我们对 RCAN 模型进行了改进,将通道注意力机制中的全局池化操作替换为核大小为 16 的区域平均池化,由此得到了改进后的模型 RCAN_AP16。随后,我们在这一改进模型上再次进行了因果效应图(CEM)的计算。结果正如下图所示,改进后的模型中,最具负向影响的图像块所产生的因果效应显著减弱,同时, ROI在重建过程中也不再出现错误的纹理现象。
不同任务的差异
以往,底层视觉领域的可解释性工具大多仅适用于图像超分辨率任务,而针对其他任务的可解释性研究则相对匮乏。然而,借助因果效应图(CEM),我们能够对同一网络在处理不同任务时的行为差异展开深入分析。
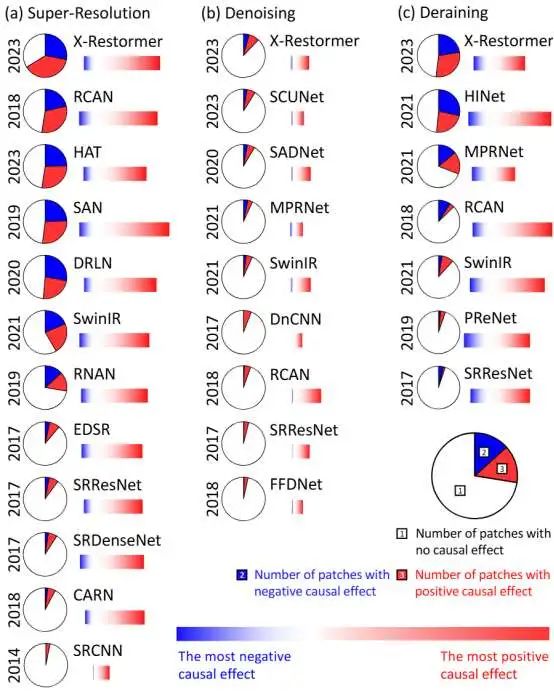
如下图所示,我们挑选了四个具有代表性的网络结构,分别是 SRResNet [5]、RCAN、SwinIR 以及 X-Restormer [6]。通过观察这些网络在超分辨率(SR)、去噪(DN)、去雨(DR)任务中的 CEM 结果,我们发现:在超分辨率任务中,网络结构的合理设计确实能够使其利用到更为广泛的区域信息;而在去噪任务中,尽管这些网络具备拥有大范围甚至全局感受野的能力,但实际上,真正发挥作用的区域仍然相对局限于局部范围。

我们在测试集上统计不同任务不同模型的CEM情况,可以发现一些有趣的结论。如下图所示,在超分辨率任务发展过程中,模型利用到的信息量发生了显著变化。模型在去噪任务的发展则没有体现出同样的变化,去噪模型所关注的区域仅仅占据了整幅图像的一小部分,而且这些区域对于ROI的重建所产生的因果效应也并不突出。至于在去雨任务中,网络所展现出的行为特征则处于超分辨率任务和去噪任务两者之间的状态。
多任务模型分析
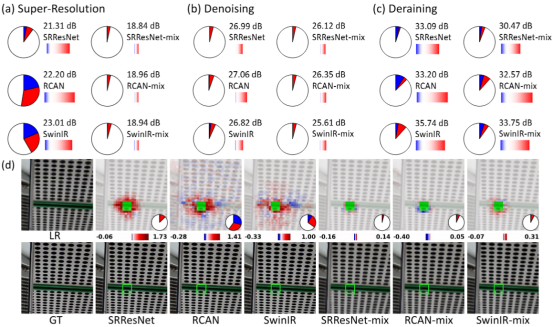
在先前的实验里,我们所考量的均是通过单一任务训练而得的网络模型,并对这些模型在该单个任务上的行为表现进行观察。然而,因果效应图(CEM)同样能够对经由多任务训练所产出的通用模型开展分析工作。我们将低分辨率图像、噪声图像以及雨图同时作为训练数据,把超分辨率、去噪和去雨这三种任务混合起来对模型进行训练,由此获得了三个具有代表性的网络,分别是 SRResNet-mix、RCAN-mix 以及 SwinIR-mix。将它们与各自的单任务训练版本进行对比后,我们也能够观察到如下图所示的 CEM 结果。一个显著的变化在于,经过混合任务训练的模型在超分辨率任务上所利用到的区域数量大幅减少,同时其性能也出现了明显的下降,即便 RCAN 和 SwinIR 在单任务训练版本中已然展现出了对长程信息的利用能力。不过,对于去噪和去雨任务而言,这些模型的行为表现以及性能并没有发生太大的改变。这一现象揭示出,在多任务训练的过程中,如果对不同任务采取一视同仁的混合方式,很可能会致使模型仅仅聚焦于部分任务,进而使得模型无法培养出处理全局信息的能力。这或许揭示了我们在训练通用模型时,针对不同任务的难度、比例以及训练顺序等方面,或许都需要进行精心的调试 [7],以避免模型的潜力无法得到充分的挖掘。
总结
本工作提出了一种名为 CEM 的通用方法来解释底层视觉模型。首次将因果关系引入底层视觉的可解释性中。通过该方法,我们实现了对输入图像区域与模型性能之间因果效应的可视化呈现。通过将 CEM 广泛应用于各类不同的底层视觉模型,我们得以从一个全新且独特的视角出发,对底层视觉领域的发展进行深入思考。期待未来的研究人员基于 CEM 进一步理解和探索底层视觉模型。最终推动整个领域朝着更智能、更可靠的方向发展。