【Sqoop基础】Sqoop定位:关系型数据库与Hadoop生态间的高效数据桥梁
目录
1 大数据集成挑战与Sqoop的诞生
2 Sqoop架构深度解析
2.1 核心架构组件
2.2 数据传输流程
3 Sqoop核心特性解析
3.1 高效并行传输
3.2 全量与增量传输模式
3.3 多目标系统支持
4 Sqoop与同类工具对比
4.1 Sqoop vs Flume
4.2 Sqoop vs Kafka Connect
4.3 Sqoop适用场景判断
5 Sqoop示例
5.1 性能优化策略
5.2 数据一致性保障
5.3元数据管理
6 总结
1 大数据集成挑战与Sqoop的诞生
在大数据时代,企业面临着 结构化数据与非结构化数据融合的核心挑战。传统关系型数据库(如MySQL、Oracle、SQL Server)存储着企业80%以上的关键业务数据,而Hadoop生态系统则以其强大的分布式存储和计算能力成为大数据处理的事实标准。这两大系统间的 数据孤岛问题严重制约了数据分析的完整性和时效性。
Sqoop(SQL-to-Hadoop)应运而生,作为Apache顶级项目,它专门设计用于在关系型数据库与Hadoop生态组件(如HDFS、Hive、HBase)之间建立高效、可靠的数据传输通道。Sqoop名称源自"SQL"和"Hadoop"的组合,形象地表达了其作为两者间桥梁的定位。
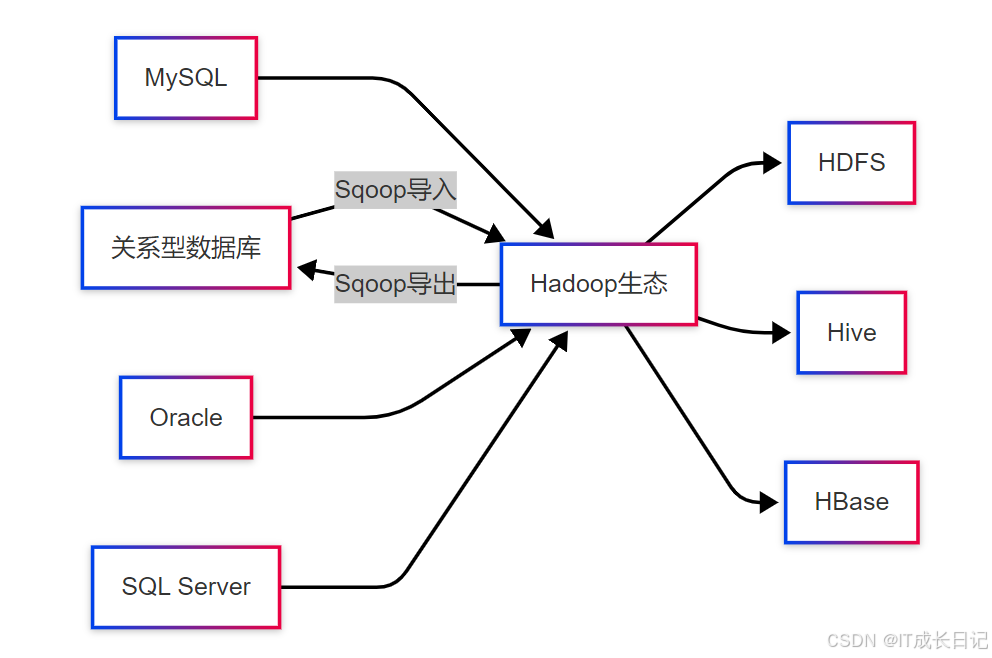
Sqoop的核心功能定位——在传统数据库系统与Hadoop生态系统间建立双向数据通道。这种桥梁作用解决了大数据环境下的几个关键问题:
- 数据迁移:将历史业务数据从关系数据库迁移到Hadoop进行长期存储和分析
- 数据同步:定期将增量数据从OLTP系统同步到大数据平台
- 结果回写:将Hadoop处理的分析结果导回业务系统供应用程序使用
2 Sqoop架构深度解析
理解Sqoop的架构设计是掌握其高效传输机制的关键。Sqoop采用 客户端-连接器架构,具有高度可扩展性和灵活性。
2.1 核心架构组件
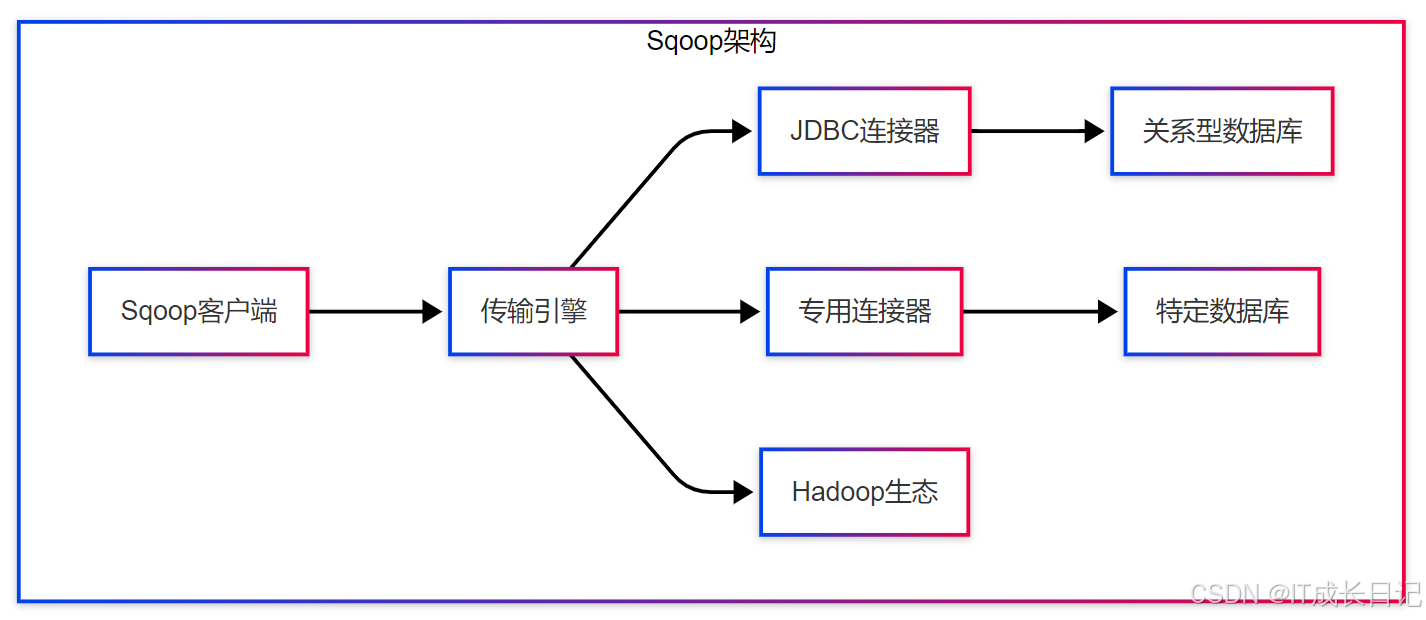
架构组件详解:
- Sqoop客户端:用户交互入口,接受命令行参数并触发数据传输作业
- 传输引擎:核心执行引擎,负责任务分解、并行控制和容错处理
- 连接器(Connector):数据库特定的适配器,分为两类:
- JDBC通用连接器:通过标准JDBC接口访问各种关系数据库
- 专用连接器:为特定数据库(如MySQL、Oracle)优化的高性能连接器
- 元数据存储:记录任务执行状态和元数据信息(部分版本支持)
2.2 数据传输流程
Sqoop的数据传输过程经过精心设计以确保效率和可靠性:

- 任务并行化:Sqoop将大表拆分为多个数据分片(基于主键或指定列),每个分片由一个Map任务处理
- 批处理优化:采用批量插入/导出策略减少网络往返
- 容错机制:任务失败自动重试,可配置重试次数
- 类型映射:自动处理关系数据库与Hadoop数据类型间的转换
3 Sqoop核心特性解析
Sqoop之所以能成为数据库与Hadoop间的首选桥梁工具,得益于其一系列强大的核心特性。
3.1 高效并行传输
Sqoop的并行传输机制是其性能优势的关键:

并行策略:
- 默认基于表的主键进行范围划分(需指定--split-by参数)
- 每个分片由一个独立的Map任务处理
- 并行度通过-m或--num-mappers参数控制(建议设置为集群可用核数的1/4到1/2)
3.2 全量与增量传输模式
针对不同场景,Sqoop提供灵活的传输策略:
| 模式 | 命令选项 | 适用场景 | 示例 |
| 全量导入 | 无特殊选项 | 初始数据迁移 | sqoop import --table employees |
| 增量追加 | --incremental append | 新增记录同步 | sqoop import --table sales --incremental append --check-column sale_date --last-value '2025-05-26' |
| 增量更新 | --incremental lastmodified | 记录更新同步 | sqoop import --table products --incremental lastmodified --check-column update_time --last-value '2025-05-26' |
3.3 多目标系统支持
Sqoop不仅支持HDFS,还能直接导入到Hadoop生态的其他组件:
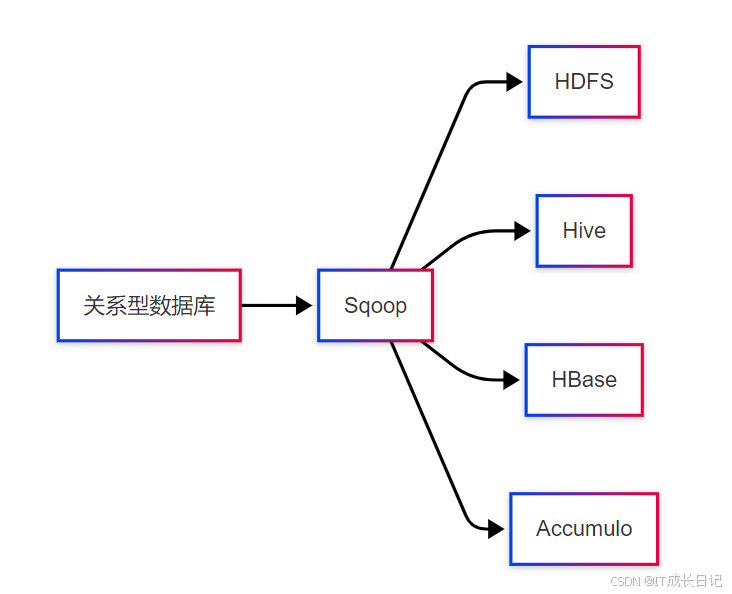
- Hive集成示例:
sqoop import \--connect jdbc:mysql://192.168.28.92/mydb \--table transactions \--hive-import \--create-hive-table \--hive-table sales.transactions4 Sqoop与同类工具对比
4.1 Sqoop vs Flume
| 维度 | Sqoop | Flume |
| 数据源 | 关系型数据库 | 日志/事件数据流 |
| 传输方向 | 双向传输 | 单向采集 |
| 数据特性 | 结构化数据 | 半/非结构化数据 |
| 传输模式 | 批量传输 | 流式传输 |
| 典型场景 | 数据库-Hadoop集成 | 日志收集到HDFS |
4.2 Sqoop vs Kafka Connect
| 维度 | Sqoop | Kafka Connect |
| 架构模式 | 批处理 | 流式/批处理 |
| 延迟性 | 高(分钟级) | 低(秒级) |
| 数据转换 | 有限 | 丰富(支持单消息转换) |
| 状态管理 | 简单 | 完善(offset跟踪) |
| 适用场景 | 批量数据迁移 | 实时数据管道 |
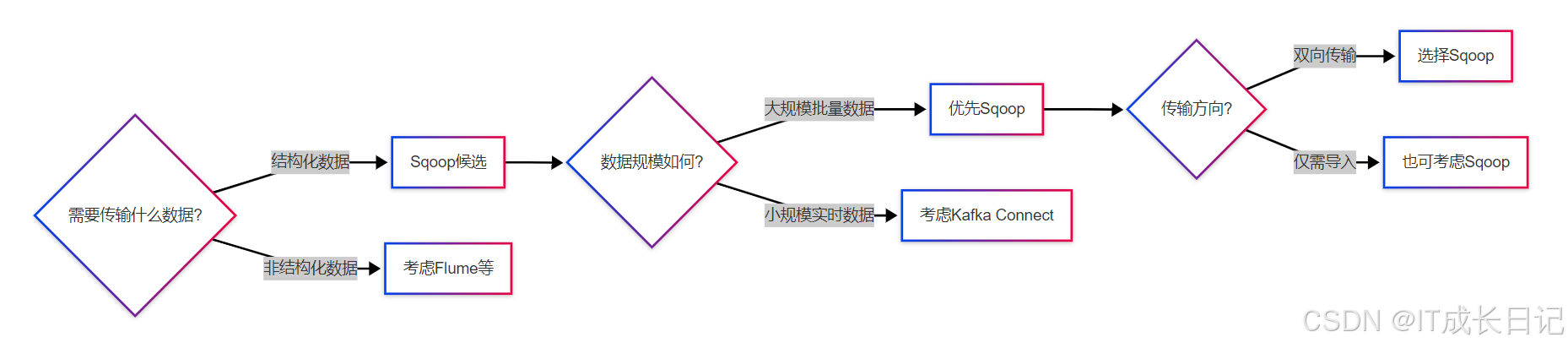
4.3 Sqoop适用场景判断
5 Sqoop示例
5.1 性能优化策略
连接器选择:
- 优先使用数据库专用连接器(如mysql-connector-java)
- 对于Teradata等大型数据仓库,考虑使用厂商提供的Sqoop连接器
- 并行度调优:
# 根据数据量和集群资源合理设置mapper数量
sqoop import \--connect jdbc:oracle:thin:@//dbserver:1521/ORCL \--username scott \--password tiger \--table SALES \--num-mappers 8 \--split-by SALE_ID- 批量参数配置:
# 调整批量大小减少网络开销
sqoop import \--connect jdbc:mysql://192.168.28.92/retail \--table customers \--batch \--fetch-size 10005.2 数据一致性保障
事务控制:
- 导出时使用--staging-table参数实现中间暂存
- 对于关键数据,启用--clear-staging-table确保一致性
- 示例:
sqoop export \--connect jdbc:mysql://192.168.28.92/warehouse \--table sales_summary \--export-dir /user/hive/warehouse/sales_summary \--staging-table sales_summary_stage \--clear-staging-table5.3元数据管理
- 利用--update-key实现记录级更新:
sqoop export \--connect jdbc:mysql://192.168.28.92/hr \--table employee \--export-dir /data/employee_updates \--update-key emp_id \--update-mode allowinsert6 总结
Sqoop作为关系型数据库与Hadoop生态间的 高效数据桥梁,在大数据技术栈中占据着不可替代的位置。其核心价值体现在:
- 专业定位:专注于结构化数据的批量传输,不做多而做精
- 高效稳定:基于MapReduce的并行传输机制,确保大规模数据传输的可靠性
- 生态融合:深度集成HDFS、Hive、HBase等Hadoop组件,形成完整解决方案
- 简单易用:命令行接口简单直观,学习成本低
随着企业数据架构的演进,Sqoop可能不会永远是大数据集成的唯一选择,但在当前阶段,它仍然是解决数据库与Hadoop间批量数据传输问题的最成熟、最可靠的解决方案。