深度学习入门(十三):加深网络
首先要认识一点,深度学习是加深了层的深度神经网络。
加深网络
首先回顾前面,我们了解了构成神经网络的各种层、学习时的有效方法、对图像特别有效的CNN、参数的最优化方法等。这些都是深度学习中的重要技术。
更深层的网络
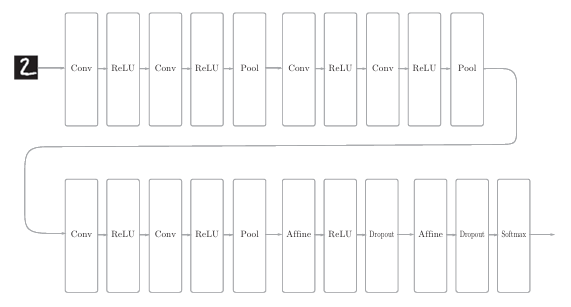
如图所示的是一个CNN,但是它比之前的所有网络都要深。这里使用的卷积层是3X3的小型滤波器,特点是随着层的加深,通道数变大。此外,插入了池化层,以逐渐减小中间数据的空间大小;并且后面的全连接层中使用了Dropout层。
这个网络使用He初始值作为权重的初始值,使用Adam更新权重参数。因此总共具有以下特点:
• 基于3×3的小型滤波器的卷积层。
• 激活函数是ReLU。
• 全连接层的后面使用Dropout层。
• 基于Adam的最优化。
• 使用He初始值作为权重初始值。
所以可以说这是一个加深的神经网络,使用了多个之前提到的技术。这个网络的识别精度高达99%,只有在极其严苛的情况下才会识别失败,连人眼也无法识别出。也就是说,这样经过训练的神经网络可以达到和人眼识别近似一样的效果,因此可以说存在巨大的可能性。
进一步提高识别精度
对于MNIST数据集,层不用特别深就获得了(目前)最高的识别精度。一般认为,这是因为对于手写数字识别这样一个比较简单的任务,没有必要将网络的表现力提高到那么高的程度。因此,可以说加深层的好处并不大。
集成学习、学习率衰减、Data Augmentation(数据扩充)等都有助于提高识别精度。尤其是数据扩充,方法简单而效果显著。
Data Augmentation基于算法“人为地”扩充输入图像(训练图像)。具体地说,如图所示,对于输入图像,通过施加旋转、垂直或水平方向上的移动等微小变化,增加图像的数量。这在数据集图像数量有限时尤其有效。
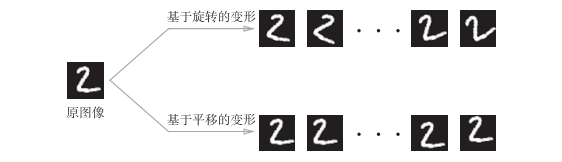
除了如图所示的变形之外,Data Augmentation还可以通过其他各种方法扩充图像,比如裁剪图像的 “crop处理”、将图像左右翻转的“flip 处理”(只在不需要考虑图像对称性的情况下有效)等。
对于一般的图像,施加亮度等外观上的变化、放大缩小等尺度上的变化也是有效的。
加深层的动机
加深层的重要性理论研究还不够透彻。但是有几点可以从过往的研究和实验中得以解释(虽然有一些直观)。
首先,从以ILSVRC为代表的大规模图像识别的比赛结果中可以看出加深层的重要性,因为从前几名看,他们的方法多是基于深度学习的,并且有逐渐加深网络的层的趋势。也就是说,可以看到层越深,识别性能也越好。
加深层的一个好处是可以减少网络的参数数量。与没有加深层的网络相比,加深了层的网络可以用更少的参数达到同等水平(或者更强)的表现力。
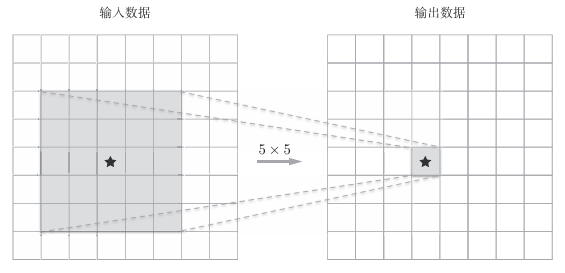
如图示是5X5卷积的例子
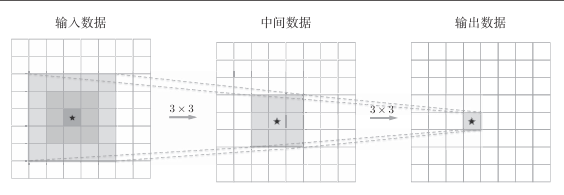
如图是两次重复3X3卷积的例子。
明显可以看到:一次5×5的卷积运算的区域可以由两次3×3的卷积运算抵充。并且,相对于前者的参数数量25(5×5),后者一共是18(2×3×3),通过叠加卷积层,参数数量减少了。而且,这个参数数量之差会随着层的加深而变大。
加深层的另一个好处就是使学习更加高效。与没有加深层的网络相比,通过加深层,可以减少学习数据,从而高效地进行学习。具体地说,在前面的卷积层中,神经元会对边缘等简单的形状有响应,随着层的加深,开始对纹理、物体部件等更加复杂的东西有响应。
通过加深网络,就可以分层次地分解需要学习的问题。因此,各层需要学习的问题就变成了更简单的问题。
通过加深层,可以分层次地传递信息,这一点也很重要。
这里需要注意的是,近几年的深层化是由大数据、计算能力等即便加深层也能正确地进行学习的新技术和环境支撑的。