Python 字符串相似度计算:方法、应用与实践
1. 字符串相似度计算方法概述
1.1 基于编辑距离的方法
编辑距离是衡量两个字符串相似度的一种经典方法,它定义为将一个字符串转换为另一个字符串所需的最少单字符编辑操作次数,这些操作包括插入、删除和替换字符。Levenshtein 距离是最常用的编辑距离算法。
-
算法原理:Levenshtein 距离通过动态规划计算两个字符串之间的最短编辑路径。对于长度分别为 (m) 和 (n) 的字符串 (s) 和 (t),其距离 (d(s,t)) 可以通过递归公式计算:

该算法的时间复杂度为 O(m×n),空间复杂度同样为 O(m×n)。
-
Python 实现:在 Python 中,可以使用
difflib模块中的SequenceMatcher类来计算两个字符串的相似度,其基于编辑距离进行计算。例如:import difflib s1 = "kitten" s2 = "sitting" matcher = difflib.SequenceMatcher(None, s1, s2) similarity = matcher.ratio() print(f"Similarity: {similarity:.2f}")输出的相似度值在 0 到 1 之间,值越接近 1 表示字符串越相似。
-
应用场景:编辑距离广泛应用于拼写检查、文本编辑、生物信息学等领域。例如,在拼写检查工具中,通过计算用户输入的单词与字典中单词的编辑距离,可以快速找出最接近的正确单词,并提示用户进行更正。在生物信息学中,编辑距离可用于比较 DNA 序列的相似性,帮助研究人员分析基因变异和进化关系。
2. 编辑距离算法
2.1 Levenshtein 距离定义
Levenshtein 距离是衡量两个字符串相似度的一种量化方法,它表示将一个字符串转换为另一个字符串所需的最少单字符编辑操作次数。这些操作包括插入、删除和替换字符。例如,将字符串 “kitten” 转换为 “sitting”,可以通过以下步骤实现:
- 将 “k” 替换为 “s”。
- 在末尾插入 “g”。
因此,Levenshtein 距离为 3。Levenshtein 距离越小,说明两个字符串越相似。它在拼写检查、文本编辑、生物信息学等领域有着广泛的应用,例如在拼写检查工具中,通过计算用户输入的单词与字典中单词的 Levenshtein 距离,可以快速找出最接近的正确单词,并提示用户进行更正。在生物信息学中,Levenshtein 距离可用于比较 DNA 序列的相似性,帮助研究人员分析基因变异和进化关系。
2.2 Levenshtein 距离计算公式
Levenshtein 距离通过动态规划计算两个字符串之间的最短编辑路径。对于长度分别为 ( m ) 和 ( n ) 的字符串 ( s ) 和 ( t ),其距离 ( d(s,t) ) 可以通过以下递归公式计算:

该算法的时间复杂度为 ( O(m \times n) ),空间复杂度同样为 ( O(m \times n) )。具体实现时,可以使用一个二维数组 ( dp ) 来存储中间结果,其中 ( dp[i][j] ) 表示字符串 ( s ) 的前 ( i ) 个字符和字符串 ( t ) 的前 ( j ) 个字符之间的 Levenshtein 距离。通过填充这个二维数组,最终 ( dp[m][n] ) 就是两个字符串的 Levenshtein 距离。
3. Python 实现编辑距离计算
3.1 使用动态规划实现
在 Python 中,可以使用动态规划来实现 Levenshtein 距离的计算。以下是具体的实现代码:
def levenshtein_distance(s1, s2):m, n = len(s1), len(s2)dp = [[0] * (n + 1) for _ in range(m + 1)]# 初始化边界条件for i in range(m + 1):dp[i][0] = ifor j in range(n + 1):dp[0][j] = j# 填充动态规划表for i in range(1, m + 1):for j in range(1, n + 1):if s1[i - 1] == s2[j - 1]:dp[i][j] = dp[i - 1][j - 1]else:dp[i][j] = 1 + min(dp[i - 1][j], dp[i][j - 1], dp[i - 1][j - 1])return dp[m][n]# 示例
s1 = "kitten"
s2 = "sitting"
distance = levenshtein_distance(s1, s2)
print(f"Levenshtein Distance: {distance}")
- 代码解析:
dp[i][j]表示字符串s1的前i个字符和字符串s2的前j个字符之间的 Levenshtein 距离。- 初始化时,
dp[i][0]和dp[0][j]分别表示将一个字符串转换为空字符串所需的编辑操作次数,即插入或删除操作的次数。 - 在填充动态规划表时,如果当前字符相同,则直接继承上一个状态的值;否则,取三种操作(插入、删除、替换)的最小值加 1。
- 性能分析:
- 时间复杂度为 (O(m \times n)),其中 (m) 和 (n) 分别为两个字符串的长度。
- 空间复杂度为 (O(m \times n)),可以通过优化将空间复杂度降低到 (O(\min(m, n))),例如使用滚动数组。
3.2 使用 difflib 模块
Python 的 difflib 模块提供了一个简单的方法来计算字符串的相似度,它基于编辑距离进行计算。以下是使用 difflib 模块的示例代码:
import difflibdef calculate_similarity(s1, s2):matcher = difflib.SequenceMatcher(None, s1, s2)similarity = matcher.ratio()return similarity# 示例
s1 = "kitten"
s2 = "sitting"
similarity = calculate_similarity(s1, s2)
print(f"Similarity: {similarity:.2f}")
- 代码解析:
difflib.SequenceMatcher是一个用于比较两个序列的类,其中None表示不使用自定义的匹配函数。ratio()方法返回两个序列的相似度,值在 0 到 1 之间,越接近 1 表示越相似。
- 性能分析:
difflib.SequenceMatcher内部使用了动态规划算法来计算编辑距离,因此其时间复杂度和空间复杂度与手动实现的动态规划方法相同,均为 (O(m \times n))。- 优点是代码简洁,易于使用,适合快速实现字符串相似度计算。
4. 其他相似度计算方法
4.1 Jaccard 相似度
Jaccard 相似度是一种衡量两个集合相似度的方法,它定义为两个集合交集的大小与并集的大小之比。在字符串相似度计算中,可以通过将字符串分割成字符集合或 n-gram 集合来应用 Jaccard 相似度。
- 算法原理:对于两个字符串 ( s_1 ) 和 ( s_2 ),将其分别分割成字符集合 ( A ) 和 ( B ),则 Jaccard 相似度 ( J(A, B) ) 可以表示为:
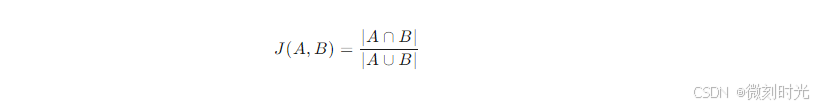
其中,∣A∩B∣ 表示集合 A 和 B 的交集大小,∣A∪B∣ 表示集合 A 和 B 的并集大小。Jaccard 相似度的值在 0 到 1 之间,越接近 1 表示两个字符串越相似。
- Python 实现:以下是使用 Jaccard 相似度计算字符串相似度的 Python 实现:
def jaccard_similarity(s1, s2):set1 = set(s1)set2 = set(s2)intersection = set1.intersection(set2)union = set1.union(set2)similarity = len(intersection) / len(union)return similarity# 示例 s1 = "kitten" s2 = "sitting" similarity = jaccard_similarity(s1, s2) print(f"Jaccard Similarity: {similarity:.2f}") - 应用场景:Jaccard 相似度在文本分类、信息检索、生物信息学等领域有广泛应用。例如,在文本分类中,可以通过计算文档之间的 Jaccard 相似度来判断它们是否属于同一类别;在生物信息学中,可以用于比较蛋白质序列或基因序列的相似性。
- 性能分析:Jaccard 相似度的计算时间复杂度主要取决于集合操作的时间复杂度,通常为 (O(m + n)),其中 (m) 和 (n) 分别为两个字符串的长度。空间复杂度主要取决于集合的大小,通常为 (O(m + n))。
4.2 余弦相似度
余弦相似度是通过计算两个向量之间的夹角余弦值来衡量它们的相似度。在字符串相似度计算中,可以将字符串表示为向量,例如通过词袋模型或 TF-IDF 模型将字符串转换为向量,然后计算它们的余弦相似度。
-
算法原理:对于两个向量 ( \mathbf{A} ) 和 ( \mathbf{B} ),它们的余弦相似度 ( \cos(\theta) ) 可以表示为:
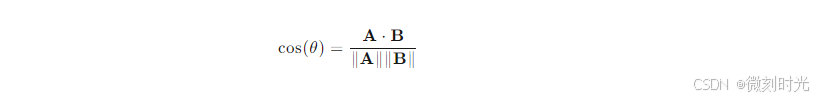
其中,A⋅B 表示向量 A 和 B 的点积,∥A∥ 和 ∥B∥ 分别表示向量 A 和 B 的模。余弦相似度的值在 -1 到 1 之间,越接近 1 表示两个向量越相似。
-
Python 实现:以下是使用余弦相似度计算字符串相似度的 Python 实现:
from sklearn.feature_extraction.text import CountVectorizer from sklearn.metrics.pairwise import cosine_similaritydef cosine_text_similarity(s1, s2):vectorizer = CountVectorizer().fit_transform([s1, s2])vectors = vectorizer.toarray()similarity = cosine_similarity(vectors[0].reshape(1, -1), vectors[1].reshape(1, -1))[0][0]return similarity# 示例 s1 = "kitten" s2 = "sitting" similarity = cosine_text_similarity(s1, s2) print(f"Cosine Similarity: {similarity:.2f}") -
应用场景:余弦相似度在文本挖掘、信息检索、推荐系统等领域有广泛应用。例如,在信息检索中,可以通过计算查询向量与文档向量之间的余弦相似度来判断文档与查询的相关性;在推荐系统中,可以用于计算用户兴趣向量与物品特征向量之间的相似度。
-
性能分析:余弦相似度的计算时间复杂度主要取决于向量的维度和向量操作的时间复杂度,通常为 (O(d)),其中 (d) 为向量的维度。空间复杂度主要取决于向量的存储空间,通常为 (O(d))。
5. Python 中的相似度计算库
5.1 difflib 模块功能
difflib 是 Python 标准库中的一个模块,主要用于比较序列,包括字符串和列表等。它提供了多种方法来计算字符串的相似度,其中最常用的是 SequenceMatcher 类。
SequenceMatcher类:该类可以比较两个序列的相似度,其ratio()方法返回一个介于 0 和 1 之间的浮点数,表示两个序列的相似度。例如,对于字符串 “kitten” 和 “sitting”,SequenceMatcher的ratio()方法返回的相似度约为 0.667。SequenceMatcher内部使用了动态规划算法来计算编辑距离,因此其时间复杂度和空间复杂度与手动实现的动态规划方法相同,均为 (O(m \times n))。get_close_matches方法:该方法用于从一个单词列表中找出与目标单词最相似的单词。例如,get_close_matches("apple", ["appel", "aple", "bpple", "bpple"])返回的结果是['appel', 'aple']。这个方法在拼写检查等场景中非常有用,可以帮助用户快速找到最接近的正确单词。unified_diff方法:该方法用于生成两个序列的统一差异格式,通常用于比较文本文件的差异。例如,比较两个字符串 “kitten” 和 “sitting” 的差异,unified_diff方法会输出类似
--- a
+++ b
@@ -1,1 +1,1 @@
-kitten
+sitting
的结果,直观地展示了两个字符串的差异。
5.2 fuzzywuzzy 库
fuzzywuzzy 是一个基于 Python 的字符串相似度计算库,它使用 Levenshtein 距离来计算字符串之间的相似度,并提供了更简洁易用的接口。
ratio方法:该方法计算两个字符串的相似度,返回一个介于 0 和 100 之间的整数,表示两个字符串的相似度百分比。例如,对于字符串 “kitten” 和 “sitting”,fuzzywuzzy.ratio("kitten", "sitting")返回的结果是 66。与difflib的SequenceMatcher类相比,fuzzywuzzy的ratio方法返回的相似度值范围不同,但其计算原理相同,都是基于编辑距离。partial_ratio方法:该方法计算两个字符串的部分相似度,适用于一个字符串是另一个字符串子集的情况。例如,对于字符串 “kitten” 和 “kitten sitting”,fuzzywuzzy.partial_ratio("kitten", "kitten sitting")返回的结果是 100,表示 “kitten” 是 “kitten sitting” 的子集,相似度为 100%。这个方法在处理部分匹配的场景中非常有用,例如在搜索框中输入部分关键词时,可以快速找到最匹配的结果。token_sort_ratio方法:该方法先对字符串进行分词并排序,然后计算排序后的字符串的相似度。例如,对于字符串 “kitten sitting” 和 “sitting kitten”,fuzzywuzzy.token_sort_ratio("kitten sitting", "sitting kitten")返回的结果是 100,表示两个字符串在分词排序后完全相同。这个方法适用于单词顺序不固定的情况,例如在处理用户输入的自然语言时,可以忽略单词的顺序差异。token_set_ratio方法:该方法先对字符串进行分词并去重,然后计算去重后的字符串的相似度。例如,对于字符串 “kitten sitting” 和 “kitten sitting sitting”,fuzzywuzzy.token_set_ratio("kitten sitting", "kitten sitting sitting")返回的结果是 100,表示两个字符串在分词去重后完全相同。这个方法适用于字符串中包含重复单词的情况,可以忽略重复单词对相似度的影响。
6. 实际应用场景
6.1 文本校对
字符串相似度计算在文本校对领域有着广泛的应用。通过比较用户输入的文本与标准文本之间的相似度,可以快速发现拼写错误、语法错误以及内容偏差等问题。
- 拼写检查:利用编辑距离算法,如 Levenshtein 距离,可以计算用户输入的单词与字典中单词的相似度。当相似度低于某个阈值时,系统可以提示用户可能的拼写错误,并提供相似的正确单词作为建议。例如,当用户输入 “teh” 时,系统可以通过计算其与 “the” 的编辑距离,发现编辑距离为 1,从而提示用户 “teh” 可能是 “the” 的拼写错误。
- 文本比对:在文档校对中,可以使用 Jaccard 相似度或余弦相似度等方法来比较两份文本的相似度。如果相似度较低,说明两份文本存在较大的内容差异,可能存在错误或篡改。例如,在学术论文校对中,通过比较提交的论文与原始稿件之间的相似度,可以检测出是否存在抄袭或内容篡改等问题。
- 语法纠错:一些高级的文本校对工具不仅能够检测拼写错误,还能通过分析句子结构和语法规则来发现语法错误。这些工具通常会将句子分解为单词序列,然后计算每个单词与上下文的语义相似度,从而判断句子的语法是否正确。例如,当用户输入 “He go to school” 时,系统可以通过计算 “go” 与上下文的语义相似度,发现其与正确的 “goes” 存在较大差异,从而提示用户语法错误。
6.2 搜索引擎优化
在搜索引擎优化(SEO)中,字符串相似度计算可以帮助优化关键词匹配、内容相关性分析以及搜索结果排序等环节。
- 关键词匹配:搜索引擎会根据用户输入的关键词与网页内容之间的相似度来判断网页的相关性。通过使用编辑距离或余弦相似度等算法,可以更准确地计算关键词与网页内容的匹配程度。例如,当用户搜索 “Python 编程” 时,搜索引擎可以通过计算 “Python 编程” 与网页标题和内容的相似度,将最相关的网页排在搜索结果的前面。
- 内容相关性分析:搜索引擎需要判断网页内容是否与用户查询的主题相关。通过将网页内容表示为向量,并使用余弦相似度等算法计算网页内容向量与用户查询向量之间的相似度,可以更准确地评估网页的相关性。例如,对于一篇关于 Python 编程的教程网页,其内容向量与用户查询 “Python 编程” 的向量之间的余弦相似度较高,说明该网页与用户查询主题高度相关。
- 搜索结果排序:搜索引擎根据网页的相关性、权威性等多个因素对搜索结果进行排序。字符串相似度计算可以作为相关性评估的一个重要指标。例如,对于用户输入的查询 “人工智能应用”,搜索引擎会计算每个网页与该查询的相似度,并结合其他因素(如网页的链接数量、访问量等)对搜索结果进行综合排序,将最相关且权威的网页排在前面,提高用户的搜索体验。# 7. 总结
在本篇研究报告中,我们深入探讨了 Python 中计算两个字符串相似度的多种方法及其应用。从基于编辑距离的经典算法到利用集合和向量的相似度度量,再到 Python 中的实用库,我们全面分析了不同方法的原理、实现和性能特点。
通过编辑距离算法,如 Levenshtein 距离,我们能够精确地衡量两个字符串之间的差异,并通过动态规划实现高效计算。这种方法在拼写检查、文本编辑和生物信息学等领域具有重要应用,能够为用户提供直观的相似度评估和编辑建议。
Jaccard 相似度和余弦相似度则从集合和向量的角度出发,为字符串相似度计算提供了新的视角。Jaccard 相似度通过集合的交集和并集来衡量相似度,适用于文本分类和生物信息学中的序列比较。余弦相似度则通过向量的夹角余弦值来评估相似度,在文本挖掘和推荐系统中表现出色,能够处理大规模文本数据并提供高效的相似度计算。
Python 中的 difflib 和 fuzzywuzzy 等库进一步简化了字符串相似度计算的过程。difflib 提供了基于编辑距离的相似度计算和差异分析功能,而 fuzzywuzzy 则通过更简洁的接口和多种相似度计算方法,为开发者提供了灵活的工具,适用于各种实际应用场景。
在实际应用中,字符串相似度计算广泛应用于文本校对、搜索引擎优化和信息检索等领域。通过拼写检查、文本比对和语法纠错等功能,文本校对工具能够帮助用户快速发现并纠正文本中的错误。在搜索引擎优化中,相似度计算能够提高关键词匹配的准确性、增强内容相关性分析的效果,并优化搜索结果的排序,从而提升用户体验。
综上所述,Python 提供了多种强大的工具和方法来计算字符串的相似度,这些方法各具优势,适用于不同的应用场景。开发者可以根据具体需求选择合适的算法或库,以实现高效、准确的字符串相似度计算,为各种文本处理任务提供有力支持。