数据洪流下,如何让数据库管理不再成为效率瓶颈?
在大数据与云原生时代,开发者和数据工程师的日常常常被这些问题困扰:
-
面对百万级数据表,翻页卡顿、操作滞后,一个简单的查询竟要等上几分钟?
-
误删数据、误改字段,只因工具无法识别主键,恢复成本远超想象?
-
多库混杂、表结构复杂,找一张表如同大海捞针?
这些问题背后,本质上是传统数据库管理工具在高并发、高复杂度场景下的力不从心。本文将结合真实工作场景,分享如何用一套「更懂工程师」的解决方案,让数据管理回归高效与优雅。
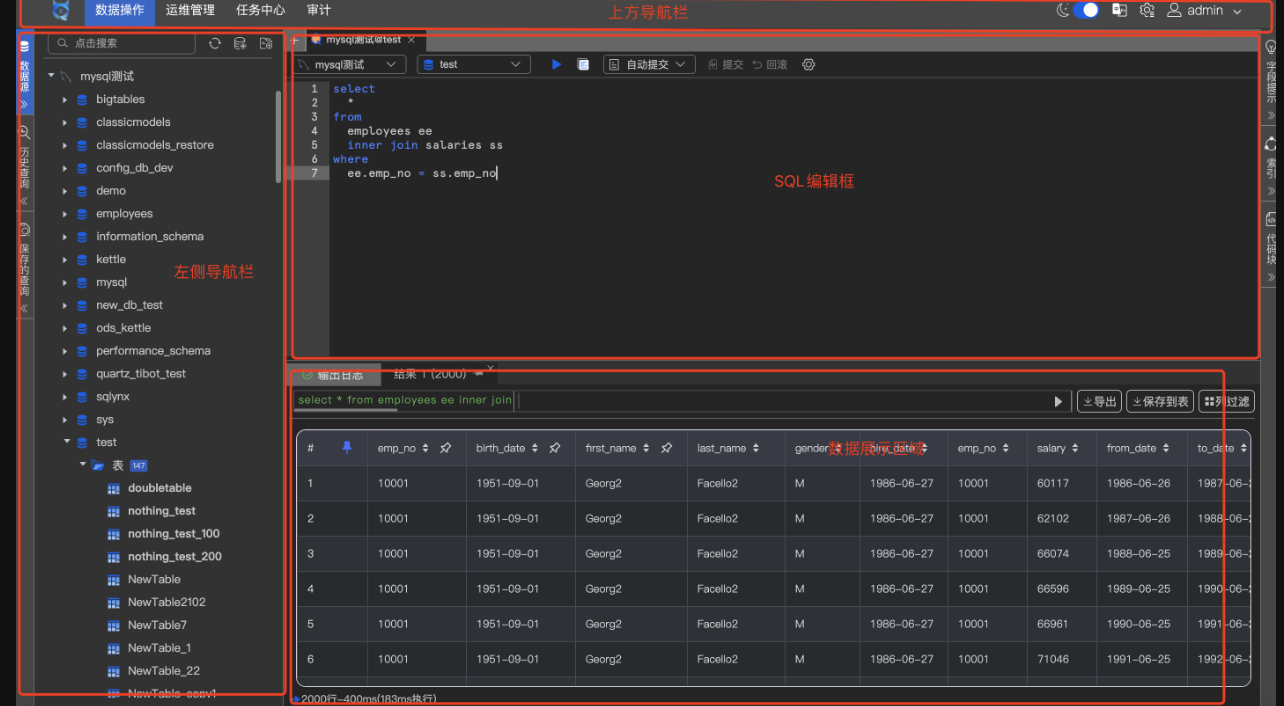
场景一:数据分析师的噩梦——百万级数据表操作
痛点:某电商平台的数据分析师小王,每天需要从包含千万条订单记录的表中筛选数据。传统工具的分页加载机制让他频繁等待,复制多行数据需手动点击,效率极低。
解法:
-
单页百万级流畅展示:无需分页跳转,直接滚动浏览全表,配合类 Excel 的拖选、批量复制粘贴功能,筛选效率提升 5 倍。
-
高亮标记关键行:快速标识异常数据,结合条件格式自定义颜色规则,让海量数据中的问题点“一目了然”。
场景二:运维工程师的焦虑——数据安全与精准操作
痛点:运维工程师老张在清理测试环境时,因工具未识别主键,误删了生产环境的用户表,导致服务中断 2 小时。
解法:
-
主键智能保护机制:默认基于主键执行更新/删除操作,若表无主键,自动识别数字或常规字符串字段作为替代,从源头降低误操作风险。
-
操作回滚与日志追溯:所有数据变更自动记录日志,支持一键回滚至任意版本,真正实现“操作可审计,风险可控制”。
场景三:开发者的效率瓶颈——复杂 SQL 与跨库查询
痛点:后端开发者小林负责优化一个跨库联合查询,但工具缺乏智能提示,频繁因语法错误或字段混淆导致执行失败。
解法:
-
上下文感知的 SQL 补全:根据当前输入位置动态推荐关键字、表名、字段名,甚至自动补全关联条件。
-
跨库联合查询可视化:直接在界面中拖拽多表生成 JOIN 语句,自动解析关联关系,避免手写错误。
场景四:架构师的新需求——物化视图与分布式优化
痛点:数据架构师团队引入 TiDB 分布式数据库后,原有工具无法解析物化视图,导致性能优化方案推进困难。
解法:
-
深度适配分布式特性:支持 TiDB 的物化视图与外表字段提示,自动识别分区键、索引分布,帮助开发者直观理解执行计划。
-
性能瓶颈可视化分析:通过图形化展示查询耗时与资源占用,快速定位慢 SQL 与锁冲突问题。
场景五:团队协作的混乱——多环境多库管理
痛点:某金融团队同时管理开发、测试、生产三套环境的 50+ 数据库,每次切换环境都要反复检索连接信息。
解法:
-
多维度数据库过滤:支持按名称、标签、类型等多条件组合筛选,一键切换不同环境的数据库集群。
-
团队级连接共享:管理员可统一配置并安全分发连接信息,避免敏感信息泄露。
工具背后:一场关于「开发者体验」的革新
上述场景的解决方案,均来自一款专注于「极致效率」的数据库管理工具。它没有铺天盖地的广告,却凭借几个核心设计理念,在开发者社群中悄然走红:
-
以操作直觉为核心
-
类 Excel 的数据网格交互
-
零学习成本的拖拽式 SQL 构建
-
-
为国产化而生
-
深度适配达梦、人大金仓、OceanBase 等国产数据库特性
-
支持麒麟、统信等国产操作系统
-
-
安全即基础能力
-
本地化加密存储 + 企业级权限管控
-
全链路操作审计与脱敏策略
-
-
性能不做妥协
-
单机支持 TB 级数据预览
-
分布式查询响应速度提升 40%
-
现在,轮到你了!
如果你厌倦了在工具限制与业务需求之间妥协,不妨体验这套「让数据管理回归简单」的解决方案。
立即访问官网下载最新版本,解锁以下能力:
✅ 百万级数据秒级加载
✅ 国产数据库开箱即用
✅ 团队协作无缝对接
官网地址:点击跳转至 SQLynx 下载页

为什么开发者都在推荐它?
“从 Navicat 切过来后,团队再也没人抱怨工具难用了。” —— 某跨境电商架构师
“对 TiDB 的深度支持,是我们选择它的关键。” —— 金融科技公司技术负责人
“终于找到一款既轻量又专业的国产替代工具!” —— 开源社区贡献者
工具的价值,终究要交给时间来证明。而你,只需给自己一次尝试的机会。