Hadoop集群部署
目录
一、简介
二、知识点
三、环境准备
1. 规划节点
2. 基础准备
四、模块内容
4.1安装java环境(三台虚拟机均操作)
4.2配置免密登录
4.3修改时区并配置自动时间同步
4.4分布式安装Hadoop
4.5启动集群
4.6HDFS的应用
4.7 实例:wordcount示例程序
一、简介
Hadoop集群是一种基于Java开发的分布式计算框架,它允许用户在物理分布的大量数据中进行高速的数据处理。Hadoop集群的核心部分是HDFS(Hadoop Distributed File System),HDFS提供了高容错性和高并发访问的大数据存储。总的来说,Hadoop集群是一个强大的大数据处理工具,能够处理PB级别的数据。他是由一个node1和2个以上的slave节点组成。
二、知识点
- 安装java环境并验证
- 配置免密登录并验证
- 分布式安装Hadoop
- 启动Hadoop集群
三、环境准备
1. 规划节点
节点分配,配置,要求等
| 主机名称 | Ip | 说明 |
| node1 | 192.168.20.50 | 主节点 |
| node2 | 192.168.20.51 | 计算节点 |
| node3 | 192.168.20.52 | 计算节点2. |
2. 基础准备
- 本实验在CentOS-7-x86_64-DVD-1804.iso 环境下操作
- 本实验需要用到hadoop-3.3.4.tar.gz,jdk-8u361-linux-x64.tar.gz环境资源包
- 本次实训机器均为4核8g的机器(内存至少要在2g以上)硬盘80g
四、模块内容
4.1安装java环境(三台虚拟机均操作)
给三台虚拟主机修改名称,分别为node1 node2 node3
[root@localhost ~]# hostnamectl set-hostname node1
[root@localhost ~]# hostnamectl set-hostname node2
[root@localhost ~]# hostnamectl set-hostname node3配置映射文件
[root@node1 ~]# vi /etc/hosts
192.168.20.50 node1
192.168.20.51 node2
192.168.20.52 node3
关闭防火墙以及开放所有端口
[root@node1 ~]# systemctl disable firewalld && systemctl stop firewalld
Removed symlink /etc/systemd/system/multi-user.target.wants/firewalld.service.
Removed symlink /etc/systemd/system/dbus-org.fedoraproject.FirewallD1.service.
注册hadoop用户,密码为123456
[root@node1 ~]# useradd hadoop
passwd:123456将jdk-8u361-linux-x64.tar.gz软件包上传到root目录,并解压到/export/server,配置软连接
[root@node1~]# mkdir -p /export/server
[root@node1~]# tar xvf jdk-8u361-linux-x64.tar.gz -C /export/server/
[root@node1 ~]# ln -s /export/server/jdk1.8.0_361/ /export/server/jdk在 /etc/profile 下写入如下配置文件(写入末尾)
[root@node1 ~]# vi /etc/profile
export JAVA_HOME=/export/server/jdk
export PATH=$JAVA_HOME/bin:$PATH#使文件立即生效
[root@node1 ~]# source /etc/profile配置java执行程序的软连接
#删除系统自带的java程序
[root@node1 ~]# rm -f /usr/bin/java
#软链接我们自己安装的java程序
[root@node1 ~]# ln -s /export/server/jdk/bin/java /usr/bin/java验证java是否安装成功
[root@node1 ~]# java -version
[root@node1 ~]# javac -version4.2配置免密登录
在node1上面配置免密登录,使node1可以登录到node2 node3
(root用户和hadoop用户均配置)
[root@node1 ~]# ssh-keygen -t rsa
连续输入三次回车
[root@node1 ~]# ssh-copy-id node1
输入yes回车
密码为node2主机的密码(密码输入时候不显示)
/usr/bin/ssh-copy-id: INFO: 1 key(s) remain to be installed -- if you are prompted now it is to install the new keys
root@node2's password:
Number of key(s) added: 1Now try logging into the machine, with: "ssh 'node1"
and check to make sure that only the key(s) you wanted were added.
[root@node1 ~]# ssh-copy-id node2
输入yes回车
密码为node3主机的密码(密码输入时候不显示)
/usr/bin/ssh-copy-id: INFO: 1 key(s) remain to be installed -- if you are prompted now it is to install the new keys
root@node2's password: Number of key(s) added: 1Now try logging into the machine, with: "ssh 'node2'"
and check to make sure that only the key(s) you wanted were added.[root@node1 ~]# ssh-copy-id node3
输入yes回车
密码为node2主机的密码(密码输入时候不显示)
/usr/bin/ssh-copy-id: INFO: 1 key(s) remain to be installed -- if you are prompted now it is to install the new keys
root@node2's password: Number of key(s) added: 1Now try logging into the machine, with: "ssh 'node2'"
and check to make sure that only the key(s) you wanted were added.
验证免密登录是否配置成功
[root@node1 ~]# ssh node2
不需要输入密码直接登录进去node2就为配置成功
[root@node2 ~]# logout
Connection to node2 closed.
[root@node1 ~]# ssh node34.3修改时区并配置自动时间同步
安装ntp软件
#前提是已经配置yum源,我已配置完
[root@node1 ~]# yum install -y ntp更新时区
[root@node1 ~]# rm -f /etc/localtime;sudo ln -s /usr/share/zoneinfo/Asia/shanghai /etc/localtime同步时间
[root@node1 ~]# ntpdate -u ntp.aliyun.com开启ntp服务并设置开机自启
[root@node1 ~]# systemctl start ntpd
[root@node1 ~]# systemctl enable ntpd4.4分布式安装Hadoop
上传hadoop-3.3.4.tar.gz安装包到/root/,解压到/export/server/并构建软连接。(仅在node1节点执行)
[root@node1 ~]# tar xvf hadoop-3.3.4.tar.gz -C /export/server/
[root@node1 ~]# cd /export/server/
[root@node1 server]# ln -s /export/server/hadoop-3.3.4 hadoop
[root@node1 server]# cd hadoop创建环境目录并添加环境变量,依次写入如下文件
[root@node1 ~]# mkdir -p /data/nn
[root@node1 ~]# mkdir /data/dn
[root@node2 ~]# mkdir -p /data/dn
[root@node2 ~]# mkdir -p /data/dn
[root@node1 ~]# mkdir /data/nm-local
[root@node1 ~]# mkdir /data/nm-log
[root@node2 ~]# mkdir /data/nm-local
[root@node2 ~]# mkdir /data/nm-log
[root@node3 ~]# mkdir /data/nm-local
[root@node3 ~]# mkdir /data/nm-log#进入Hadoop目录依次配置环境变量
[root@node1 ~]# cd /export/server/hadoop/etc/hadoop/
[root@node1 hadoop]#
[root@node1 hadoop]# vi hadoop-env.sh
export JAVA_HOME=/export/server/jdk
export HADOOP_HOME=/export/server/hadoop
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export HADOOP_LOG_DIR=$HADOOP_HOME/logs解析:
- JAVA HOME,指明JDK环境的位置在哪
- HADOOP HOME,指明Hadoop安装位置
- HADOOP CONF DIR,指明Hadoop配置文件目录位置
- HADOOP LOG DIR,指明Hadoop运行日志目录位置。通过记录这些环境变量,来指明上述运行时的重要信息
在node1里面编写hadoop-env.sh、core-site.xml、hdfs- site.xml和workers配置文件
编写core-site.xml
[root@node1 hadoop]# vi core-site.xml
<configuration><property><name>fs.defaultFS</name><value>hdfs://node1:8020</value> </property><property><name>io.file.buffer.size</name><value>131072</value></property>
</configuration>编写hdfs-site.xml
[root@node1 hadoop]# vi hdfs-site.xml
<configuration><property><name>dfs.datanode.data.dir.perm</name><value>700</value></property><property><name>dfs.namenode.name.dir</name><value>/data/nn</value></property><property><name>dfs.namenode.hosts</name><value>node1,node2,node3</value></property><property><name>dfs.blocksize</name><value>268435456</value></property><property><name>dfs.namenode.handler.count</name><value>100</value></property><property><name>dfs.datanode.data.dir</name><value>/data/dn</value></property>
</configuration>配置Hadoop工作目录
[root@node1 hadoop]# vi workers
#localhost
node1
node2
node3配置mapred-env.sh配置文件
[hadoop@node1 hadoop]$ cat mapred-env.sh
#设置JDK路径...
export JAVA_HOME=/export/server/jdk
export HADOOP_JOB_HISTORYSERVER_HEAPSIZE=1000
export HADOOP_MAPRED_ROOT_LOGGER=INFO,RFA配置mapred-site.xml配置文件
[hadoop@node1 hadoop]$ cat mapred-site.xml
<configuration><property><name>mapreduce.framework.name</name><value>yarn</value><description>MapReduce的运行框架设置为YARN</description></property><property><name>mapreduce.jobhistory.address</name><value>node1:10020</value><description>历史服务器通讯端口为node1:10020</description></property><property><name>mapreduce.jobhistory.webapp.address</name><value>node1:19888</value><description>历史服务器web端口为node1的19888</description></property><property><name>mapreduce.jobhistory.intermediate-done-dir</name><value>/data/mr-history/tmp</value><description>历史信息在HDFS的记录临时路径</description></property><property><name>mapreduce.jobhistory.done-dir</name><value>/data/mr-history/done</value><description>历史信息在HDFS的记录路径</description></property><property><name>yarn.app.mapreduce.am.env</name><value>HADOOP_MAPRED_HOME=$HADOOP_HOME</value><description>MapReduce HOME 设置为HADOOP_HOME</description></property><property><name>mapreduce.map.env</name><value>HADOOP_MAPRED_HOME=$HADOOP_HOME</value><description>MapReduce HOME 设置为HADOOP_HOME</description></property><property><name>mapreduce.reduce.env</name><value>HADOOP_MAPRED_HOME=$HADOOP_HOME</value><description>MapReduce HOME 设置为HADOOP_HOME</description></property>
</configuration>配置yarn-env.sh配置文件
[hadoop@node1 hadoop]$ cat yarn-env.sh
#设置JDK路径的环境变量
export JAVA_HOME=/export/server/jdk
#设置HADOOP HOME的环境变量
export HADOOP_HOME=/export/server/hadoop
#设置配置文件路径的环境变量
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
#设置日志文件路径的环境变量
export HADOOP_LOG_DIR=$HADOOP_HOME/logs配置yarn-site.xml配置文件
[hadoop@node1 hadoop]$ cat yarn-site.xml
<configuration><!-- Site specific YARN configuration properties -->
<property><name>yarn.resourcemanager.hostname</name><value>node1</value><description>ResourceManager设置在node1节点</description>
</property><property><name>yarn.nodemanager.local-dirs</name><value>/data/nm-local</value><description>NodeManager中间数据本地存储路径</description>
</property><property><name>yarn.nodemanager.log-dirs</name><value>/data/nm-log</value><description>NodeManager数据日志本地存储路径</description>
</property><property><name>yarn.nodemanager.aux-services</name><value>mapreduce_shuffle</value><description>为MapReduce程序开启Shuffle服务</description>
</property><property><name>yarn.log.server.url</name><value>http://node1:19888/jobhistory/logs</value><description>历史服务器URL</description>
</property><property><name>yarn.web-proxy.address</name><value>node1:8089</value><description>代理服务器主机和端口</description>
</property><property><name>yarn.log-aggregation-enable</name><value>true</value><description>开启日志聚合</description>
</property><property><name>yarn.nodemanager.remote-app-log-dir</name><value>/tmp/logs</value><description>程序日志HDFS的存储路径</description>
</property><property><name>yarn.resourcemanager.scheduler.class</name><value>org.apache.hadoop.yarn.server.resourcemanager.scheduler.fair.FairScheduler</value><description>选择公平调度器</description>
</property>
</configuration>4.5启动集群
将node1文件分发到node2 node3
#回到/root目录执行下面命令分发文件到node2 node3
root@node1 hadoop]# cd /root
[root@node1 ~]# scp -r /export/server/hadoop-3.3.4/ node2:/export/server/
[root@node1 ~]# scp -r /export/server/hadoop-3.3.4/ node3:/export/server/
[root@node2 ~]# cd /export/server/
#设置node2和node3的软连接
[root@node2 server]# ln -s /export/server/hadoop-3.3.4 hadoop
[root@node3 ~]# cd /export/server/
[root@node3 server]# ln -s /export/server/hadoop-3.3.4 hadoop分发完成后需/etc/profile配置环境变量操作如下,三台虚拟机均操作
[root@node1 ~]# vi /etc/profile
export HADOOP_HOME=/export/server/hadoop
export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH使文件立即生效
[root@node1 ~]# source /etc/profile以root身份,在node1,node2,node3三台服务器上均执行如下命令
[root@node1 ~]# chown -R hadoop:hadoop /data
[root@node1 ~]# chown -R hadoop:hadoop /export初始化和启动Hadoop,hdfs服务
[root@node1 ~]# su - hadoop
#格式化namenode
[root@node1 ~]# hdfs namenode -format
这里我们输入Y
………….
2024-02-01 23:54:42,653 INFO namenode.FSImage: FSImageSaver clean checkpoint: txid = 0 when meet shutdown.
2024-02-01 23:54:42,654 INFO namenode.NameNode: SHUTDOWN_MSG:
/************************************************************
SHUTDOWN_MSG: Shutting down NameNode at node1/192.168.20.50
************************************************************/
#一键启动hdfs集群、yarn集群
[root@node1 ~]# start-dfs.sh
[root@node1 ~]# start-yarn.sh验证Hadoop以及hdfs
#node1节点
[hadoop@node1 hadoop]$ jps
31509 ResourceManager
31637 NodeManager
32568 Jps
53116 SecondaryNameNode
16349 DataNode
16207 NameNode
4044 NodeManager
#node2节点:
[root@node2 ~]# jps
81265 NodeManager
54017 DataNode
54406 Jps
#node3节点:
[root@node3 ~]# jps
8126 NodeManager
6221 DataNode
6224 Jps
#添加历史服务器
[hadoop@node1 ~]$ mapred --daemon start historyserver
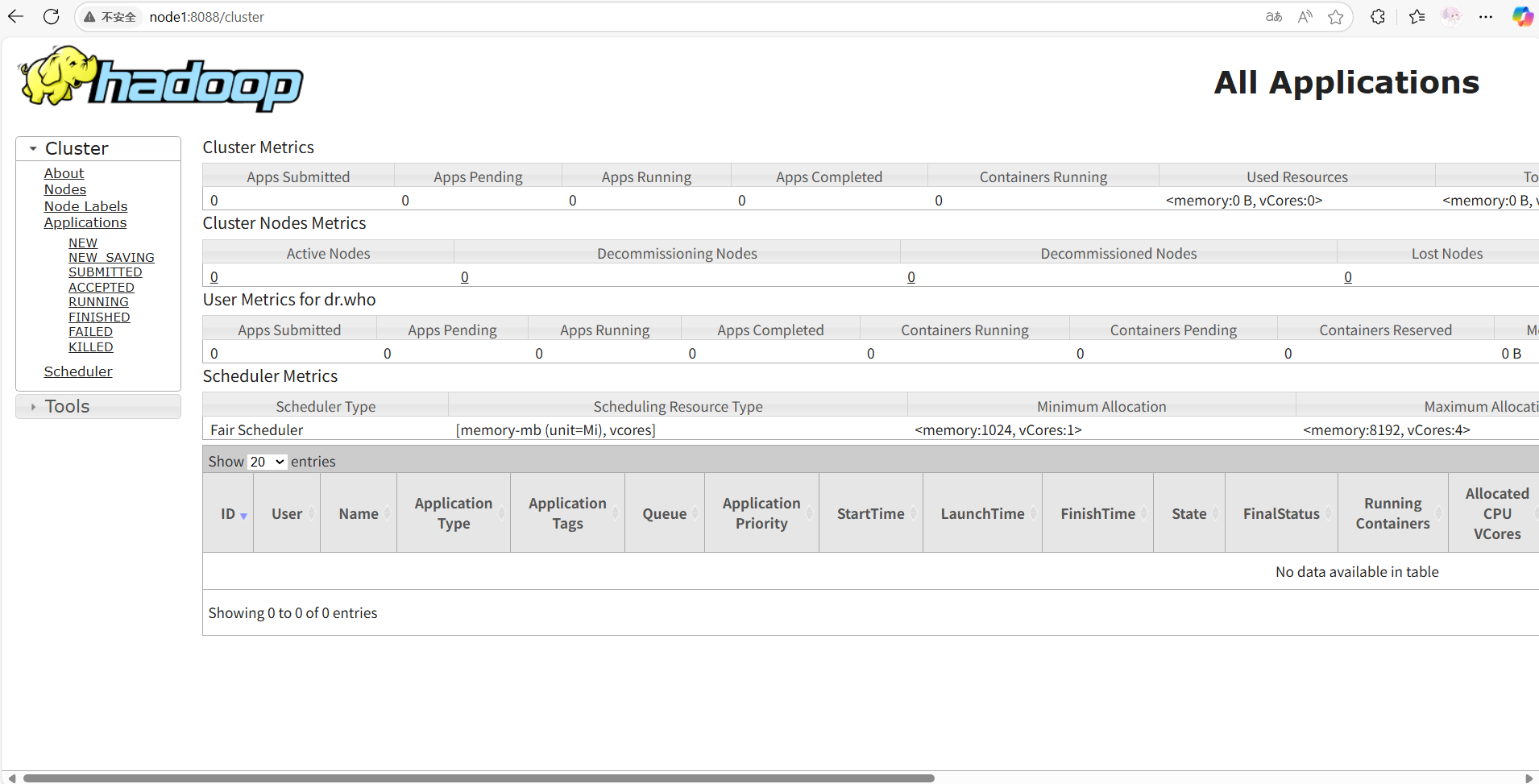
WARNING: HADOOP_MAPRED_ROOT_LOGGER has been replaced by HADOOP_ROOT_LOGGER. Using value of HADOOP_MAPRED_ROOT_LOGGER.查看YARN的WEB UI页面
打开 http://node1:8088 即可看到YARN集群的监控页面(ResourceManager的WEB UI)
4.6HDFS的应用
登入HDFS
在4.4启动的Hadoop集群基础上,通过浏览器进入hdfs网页端http://IP:9870(端口号默认、node1节点IP)。结果如图1-5-1。
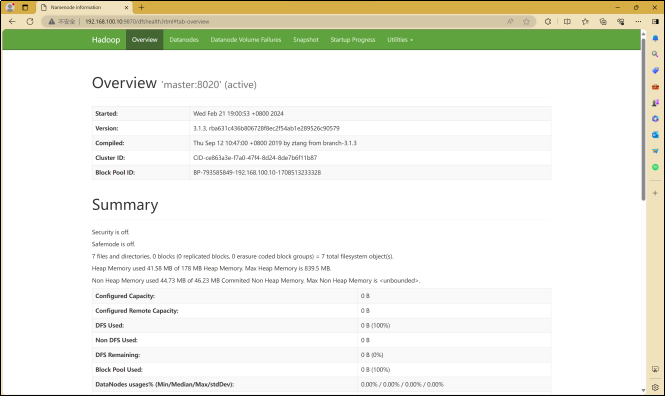
图1-5-1
查看目录
在node1节点下查看HDFS根目录下的内容。命令如下,结果如图1-5-2。
[root@node1 ~]# hdfs dfs -ls /
Found 1 items
drwxrwx--- - root supergroup 0 2024-02-21 06:04 /tmp
[root@node1 ~]# hdfs dfs -mkdir /tmp
[root@node1 ~]# hdfs dfs -mkdir /data
图1-5-2
创建目录
在node1节点的HDFS根目录下创建内容。命令如下。
[root@node1 ~]# hdfs dfs -mkdir /tmp
[root@node1 ~]# hdfs dfs -mkdir /data4.7 实例:wordcount示例程序
提交wordcount示例程序
单词计数示例程序:
- 给定数据输入的路径(HDFS)、给定结果输出的路径(HDFS)
- 将输入路径内的数据中的单词进行计数,将结果写到输出路径
我们可以准备一份数据文件,并上传到HDFS中。
[root@node1 server]# vi words.txt
itheima itcast itheima itcast
hadoop hdfs hadoop hdfs
hadoop mapreduce hadoop yarn
itheima hadoop itcast hadoop
itheima itcast hadoop yarn mapreduce将words.txt文件上传到HDFS
[root@node1 server]# hadoop fs -mkdir -p /input/wordcount
[root@node1 server]# hadoop fs -mkdir /output
[root@node1 server]# hadoop fs -put words.txt /input/wordcount/执行如下命令,提交示例MapReduce程序WordCount到YARN中执行
[root@node1 server]# hadoop jar $HADOOP HOME/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.1.jar wordcount hdfs://node1:8020/input/wordcount/ hdfs://node1:8020/output/wc1
注意:
- 参数wordcount,表示运行jar包中的单词计数程序(Javaclass)
- 参数1是数据输入路径(hdfs://node1:8020/input/wordcount/)
- 参数2是结果输出路径(hdfs://node1:8020/output/wc1),需要确保输出的文件夹不存在
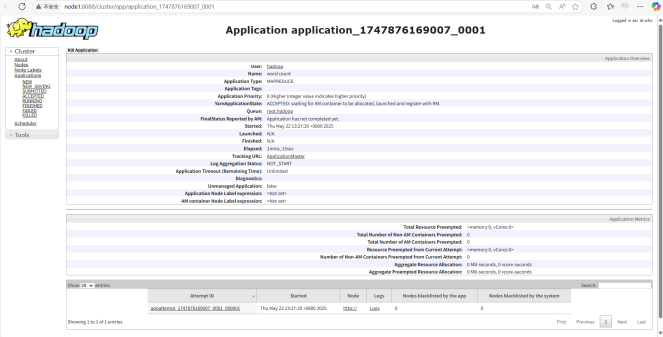
验证
点击http://node1:8088/cluster/app/application_1747876169007_0001访问web页面