主流Agent Memory工具or框架对比(Mem0、LangMem、Letta)
Memory调研
一点前置知识
为什么记忆很重要
-
在对话中保持上下文连贯性
-
从过去的交互中学习
-
随着时间推移打造个性化体验
Short-Term Memory 短期记忆
人工智能系统中最基本的记忆形式保存着即时上下文——就像一个人记住在对话中刚刚说过的话。这包括:
-
对话历史记录:最近的消息及其顺序
-
工作记忆:临时变量和状态
-
注意力上下文:对话当前的焦点
Long-Term Memory 长期记忆
更复杂的人工智能应用程序会实现长期记忆,以便在不同对话中保留信息。这包括:
-
事实记忆:存储的有关用户、偏好和特定领域信息的知识
-
情景记忆:过往的交互与经历
-
语义记忆:对概念及其关系的理解
Mem0
开源的长期记忆管理框架,saas服务提供更强的能力和可视化管理等。
关键特性
记忆处理:使用大语言模型(LLMs)在保留完整上下文的同时,自动从对话中提取并存储重要信息
记忆管理:持续更新并解决存储信息中的矛盾,以保持准确性
双存储架构:结合用于内存存储的向量数据库和用于关系跟踪的图数据库
智能检索系统:采用语义搜索和图形查询,根据重要性和时效性查找相关记忆。
简单的API集成:提供易于使用的端点,用于添加(add)和检索(search)记忆
流程
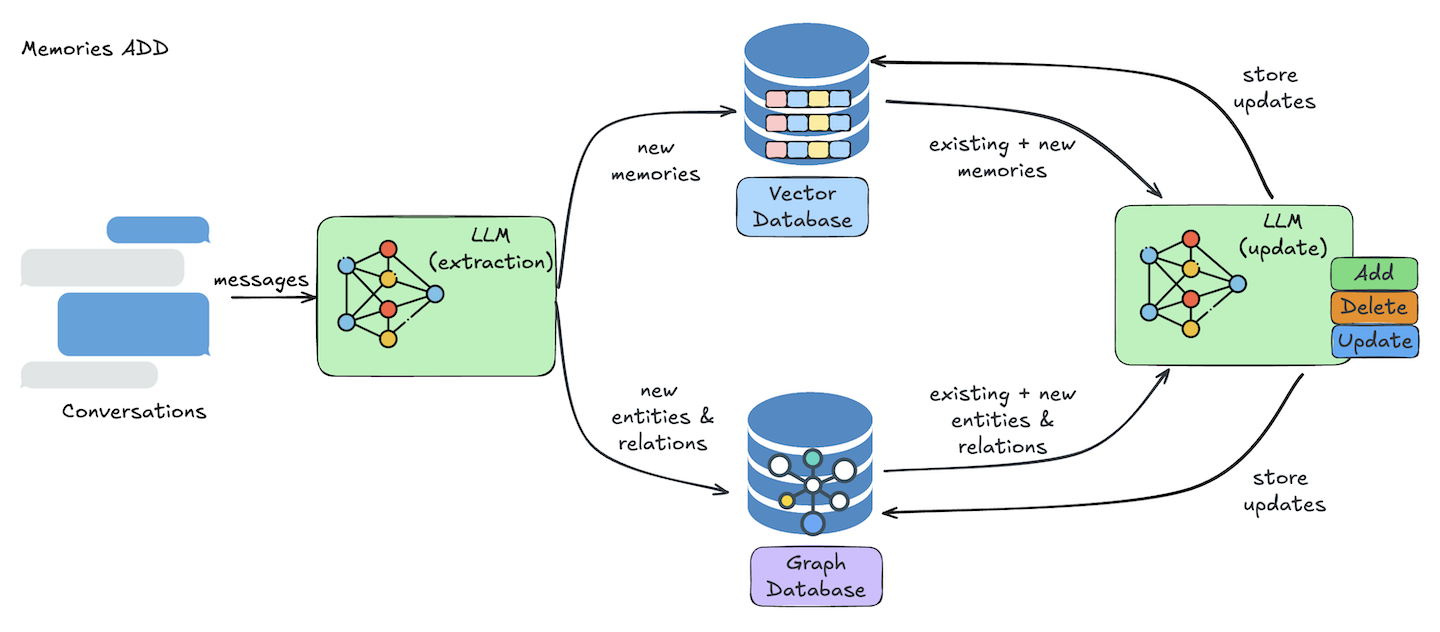
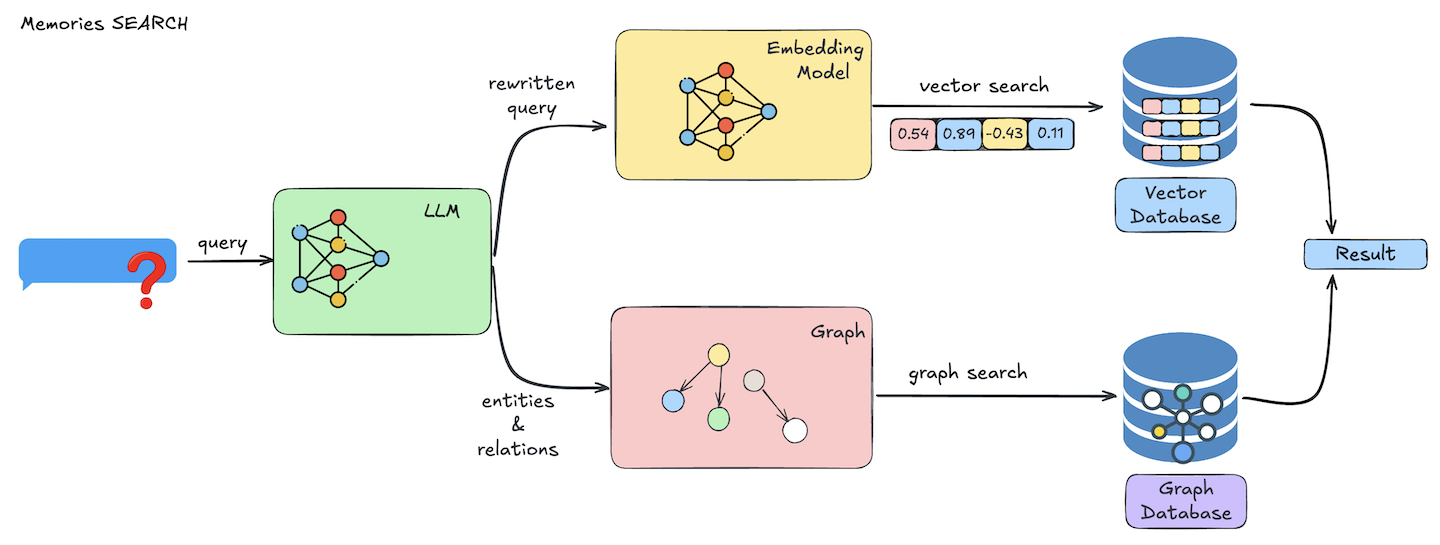
关键提示词
Fact Extraction
custom_fact_extraction_prompt = """
Please only extract entities containing customer support information, order details, and user information.
Here are some few shot examples:Input: Hi.
Output: {{"facts" : []}}Input: The weather is nice today.
Output: {{"facts" : []}}Input: My order #12345 hasn't arrived yet.
Output: {{"facts" : ["Order #12345 not received"]}}Input: I'm John Doe, and I'd like to return the shoes I bought last week.
Output: {{"facts" : ["Customer name: John Doe", "Wants to return shoes", "Purchase made last week"]}}Input: I ordered a red shirt, size medium, but received a blue one instead.
Output: {{"facts" : ["Ordered red shirt, size medium", "Received blue shirt instead"]}}Return the facts and customer information in a json format as shown above.
"""
Update Memory
UPDATE_MEMORY_PROMPT = """You are a smart memory manager which controls the memory of a system.
You can perform four operations: (1) add into the memory, (2) update the memory, (3) delete from the memory, and (4) no change.Based on the above four operations, the memory will change.Compare newly retrieved facts with the existing memory. For each new fact, decide whether to:
- ADD: Add it to the memory as a new element
- UPDATE: Update an existing memory element
- DELETE: Delete an existing memory element
- NONE: Make no change (if the fact is already present or irrelevant)There are specific guidelines to select which operation to perform:1. **Add**: If the retrieved facts contain new information not present in the memory, then you have to add it by generating a new ID in the id field.
- **Example**:- Old Memory:[{"id" : "0","text" : "User is a software engineer"}]- Retrieved facts: ["Name is John"]- New Memory:{"memory" : [{"id" : "0","text" : "User is a software engineer","event" : "NONE"},{"id" : "1","text" : "Name is John","event" : "ADD"}]}2. **Update**: If the retrieved facts contain information that is already present in the memory but the information is totally different, then you have to update it.
If the retrieved fact contains information that conveys the same thing as the elements present in the memory, then you have to keep the fact which has the most information.
Example (a) -- if the memory contains "User likes to play cricket" and the retrieved fact is "Loves to play cricket with friends", then update the memory with the retrieved facts.
Example (b) -- if the memory contains "Likes cheese pizza" and the retrieved fact is "Loves cheese pizza", then you do not need to update it because they convey the same information.
If the direction is to update the memory, then you have to update it.
Please keep in mind while updating you have to keep the same ID.
Please note to return the IDs in the output from the input IDs only and do not generate any new ID.
- **Example**:- Old Memory:[{"id" : "0","text" : "I really like cheese pizza"},{"id" : "1","text" : "User is a software engineer"},{"id" : "2","text" : "User likes to play cricket"}]- Retrieved facts: ["Loves chicken pizza", "Loves to play cricket with friends"]- New Memory:{"memory" : [{"id" : "0","text" : "Loves cheese and chicken pizza","event" : "UPDATE","old_memory" : "I really like cheese pizza"},{"id" : "1","text" : "User is a software engineer","event" : "NONE"},{"id" : "2","text" : "Loves to play cricket with friends","event" : "UPDATE","old_memory" : "User likes to play cricket"}]}3. **Delete**: If the retrieved facts contain information that contradicts the information present in the memory, then you have to delete it. Or if the direction is to delete the memory, then you have to delete it.
Please note to return the IDs in the output from the input IDs only and do not generate any new ID.
- **Example**:- Old Memory:[{"id" : "0","text" : "Name is John"},{"id" : "1","text" : "Loves cheese pizza"}]- Retrieved facts: ["Dislikes cheese pizza"]- New Memory:{"memory" : [{"id" : "0","text" : "Name is John","event" : "NONE"},{"id" : "1","text" : "Loves cheese pizza","event" : "DELETE"}]}4. **No Change**: If the retrieved facts contain information that is already present in the memory, then you do not need to make any changes.
- **Example**:- Old Memory:[{"id" : "0","text" : "Name is John"},{"id" : "1","text" : "Loves cheese pizza"}]- Retrieved facts: ["Name is John"]- New Memory:{"memory" : [{"id" : "0","text" : "Name is John","event" : "NONE"},{"id" : "1","text" : "Loves cheese pizza","event" : "NONE"}]}
"""
langgraph集成
def chatbot(state: State):messages = state["messages"]user_id = state["mem0_user_id"]# Retrieve relevant memoriesmemories = mem0.search(messages[-1].content, user_id=user_id)context = "Relevant information from previous conversations:\n"for memory in memories:context += f"- {memory['memory']}\n"system_message = SystemMessage(content=f"""You are a helpful customer support assistant. Use the provided context to personalize your responses and remember user preferences and past interactions.
{context}""")full_messages = [system_message] + messagesresponse = llm.invoke(full_messages)# Store the interaction in Mem0mem0.add(f"User: {messages[-1].content}\nAssistant: {response.content}", user_id=user_id)return {"messages": [response]}
LangMem
LangMem专为解决AI记忆管理难题而生,旨在实现与各类人工智能框架的无缝融合,为开发者提供一套强大的记忆管理解决方案,其核心特性极具亮点:
**主动记忆管理:**赋予AI主体动态掌控信息的能力,随时存储新知识、精准检索所需内容,还能根据实际情况及时更新信息,确保记忆鲜活且准确。
**共享内存机制:**搭建起一个共享知识库,多个人工智能主体都能自由访问、共同贡献,促进知识的流动与创新。
**命名空间组织:**通过按用户、项目或团队划分信息命名空间,让信息检索变得高效有序,如同给庞大的知识仓库设置了清晰的索引目录。
个性化与持续进化:借助持续更新与优化机制,推动AI实现个性化成长与终身学习,始终紧跟时代步伐,满足不断变化的用户需求。
在LangMem所设计的memory体系中, 定义了几种不同的Typical Storage Pattern:Collection 、 Profiles和Procedural
Collection
Collection 主要用于存储不受限制的知识,适用于需要长期积累和检索的信息。每条记忆被存储为独立的文档或记录,可以在需要时进行搜索和回忆;
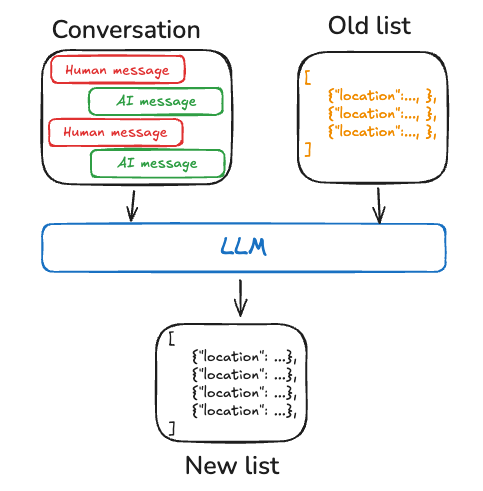
适用场景:记录用户的长期知识,例如用户的兴趣、职业背景、技能等
更新方式:需要合并新信息,避免重复或冲突
检索方式:通过语义搜索或关键词匹配来查找,结合记忆的重要性和使用频率来优化检索结果
Profiles
存储结构化的用户信息,例如用户的姓名、语言偏好、沟通风格等。与 Collection 不同,Profile 只存储最新的状态,而不是累积所有历史信息。Profile 作为单一文档存储,每次更新时都会覆盖旧数据
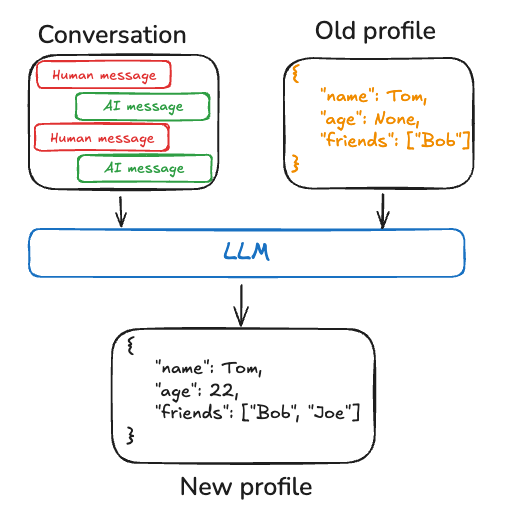
适用场景:适用于需要快速访问当前状态的应用,例如个性化推荐、用户设置;适用于需要严格定义数据结构的场景,例如用户档案、系统配置;
更新方式:不会创建新记录,而是直接更新现有的 Profile;适用于只关心最新状态的应用,而不是历史;
检索方式:直接查找用户的 Profile
Procedural Memory
类似于人类的工作记忆,用于存储如何执行任务的知识,主要体现在system prompts 和行为优化上
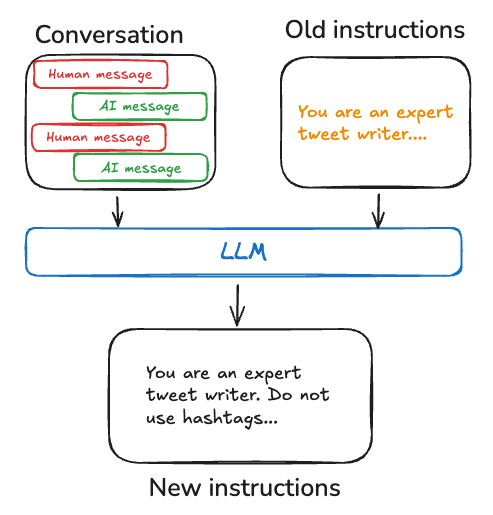
适用场景:需要长期优化 Agent行为和交互方式,少走弯路
Writing memories
提供了两种写入memory的方法:及时写入(适用于要求即时记忆反映的场景)和一段时间后的异步写入(适用于高效处理和存储大量信息的场景)
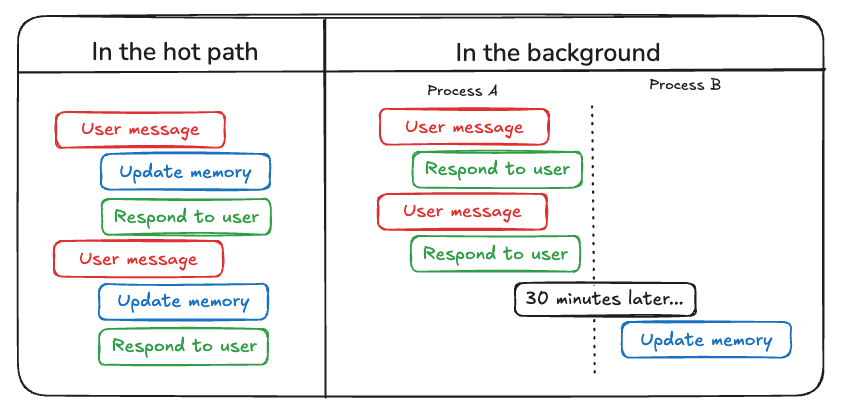
记忆管理时序图
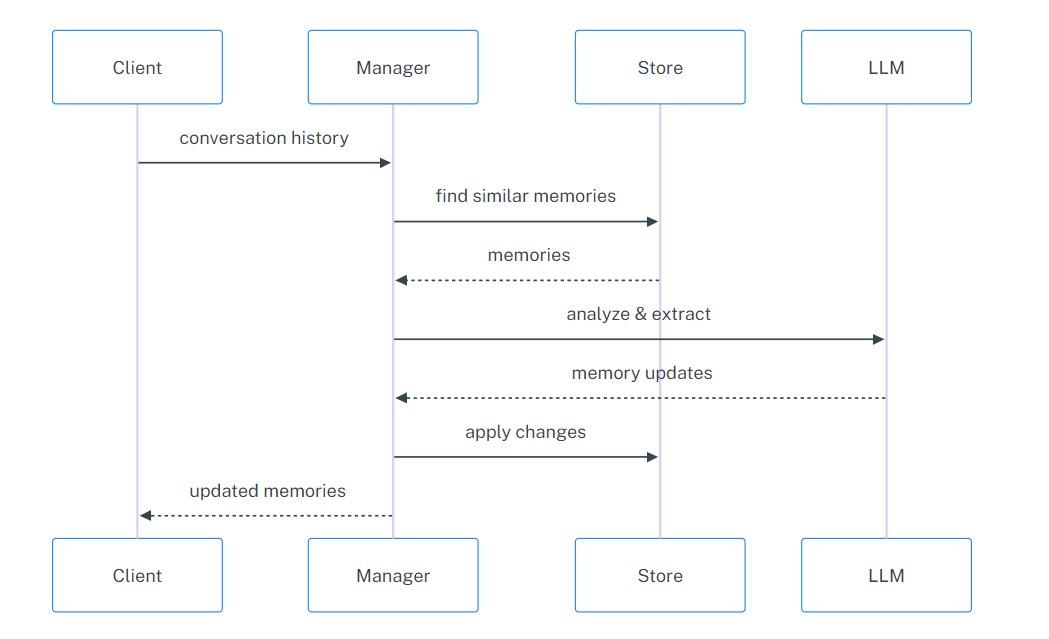
MemoryManager
++code++
-
用于管理记忆提取和处理的类
-
实现了异步和同步的调用方法
-
主要功能是根据给定的消息和已有记忆,提取、更新和删除记忆对象

如何提取记忆
大致流程:
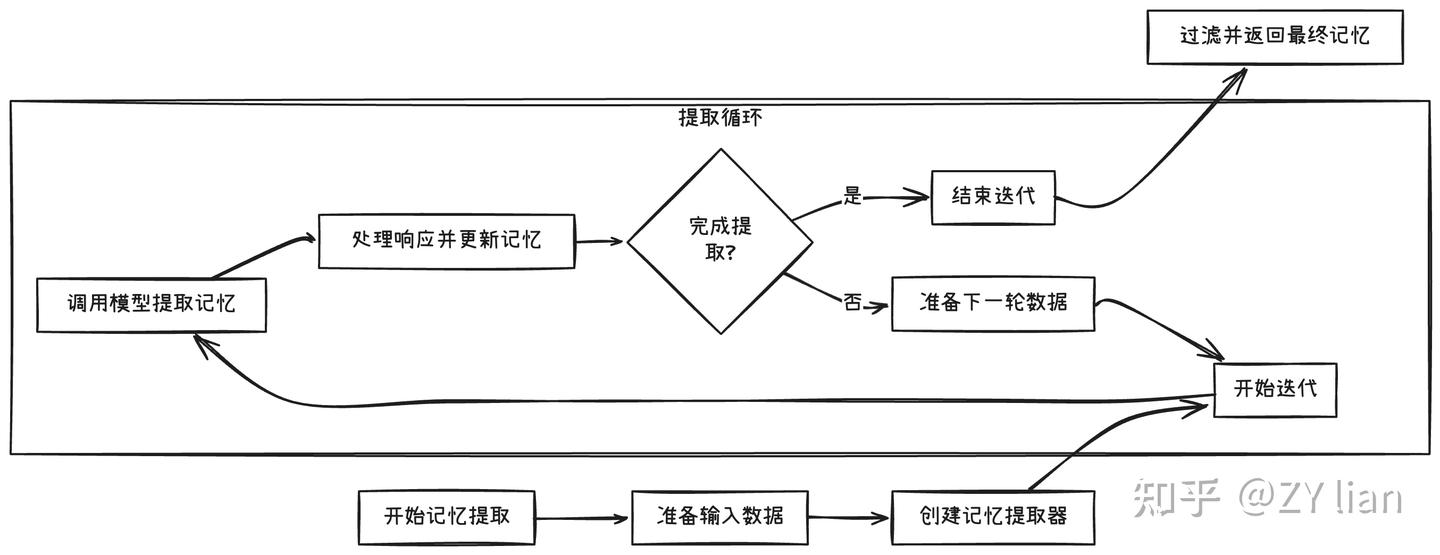
采用的prompt
_MEMORY_INSTRUCTIONS = “”"You are a long-term memory manager maintaining a core store of semantic, procedural, and episodic memory. These memories power a life-long learning agent’s core predictive model.
What should the agent learn from this interaction about the user, itself, or how it should act? Reflect on the input trajectory and current memories (if any).
Extract & Contextualize
Identify essential facts, relationships, preferences, reasoning procedures, and context
Caveat uncertain or suppositional information with confidence levels (p(x)) and reasoning
Quote supporting information when necessary
Compare & Update
Attend to novel information that deviates from existing memories and expectations.
Consolidate and compress redundant memories to maintain information-density; strengthen based on reliability and recency; maximize SNR by avoiding idle words.
Remove incorrect or redundant memories while maintaining internal consistency
Synthesize & Reason
What can you conclude about the user, agent (“I”), or environment using deduction, induction, and abduction?
What patterns, relationships, and principles emerge about optimal responses?
What generalizations can you make?
Qualify conclusions with probabilistic confidence and justification
As the agent, record memory content exactly as you’d want to recall it when predicting how to act or respond. Prioritize retention of surprising (pattern deviation) and persistent (frequently reinforced) information, ensuring nothing worth remembering is forgotten and nothing false is remembered. Prefer dense, complete memories over overlapping ones.“”"
使用方式python SDK。
**优点:**与langchain、langgraph同生态便于集成。
**缺点:**langmem仅做数据分析和处理,依赖langgraph存储逻辑。
langgraph接入方案:
InMemoryStore将内存保存在进程内存中——在重新启动时丢失。对于生产环境,使用AsyncPostgresStore或类似的数据库支持的存储来在服务器重启时持久化内存。
- 自定义的agent绑定工具
# Import core components (1)
from langgraph.prebuilt import create_react_agent
from langgraph.store.memory import InMemoryStore
from langmem import create_manage_memory_tool, create_search_memory_tool# Set up storage (2)
store = InMemoryStore(index={"dims": 1536,"embed": "openai:text-embedding-3-small",}
) # Create an agent with memory capabilities (3)
agent = create_react_agent("anthropic:claude-3-5-sonnet-latest",tools=[# Memory tools use LangGraph's BaseStore for persistence (4)create_manage_memory_tool(namespace=("memories",)),create_search_memory_tool(namespace=("memories",)),],store=store,
)#使用
# Store a new memory (1)
agent.invoke({"messages": [{"role": "user", "content": "Remember that I prefer dark mode."}]}
)# Retrieve the stored memory (2)
response = agent.invoke({"messages": [{"role": "user", "content": "What are my lighting preferences?"}]}
)
print(response["messages"][-1].content)
# Output: "You've told me that you prefer dark mode."
- 使用memory manager
import osfrom anthropic import AsyncAnthropic
from langchain_core.runnables import RunnableConfig
from langgraph.func import entrypoint
from langgraph.store.memory import InMemoryStorefrom langmem import create_memory_store_managerstore = InMemoryStore(index={"dims": 1536,"embed": "openai:text-embedding-3-small",}
)manager = create_memory_store_manager("anthropic:claude-3-5-sonnet-latest", namespace=("memories", "{langgraph_user_id}"))
client = AsyncAnthropic(api_key=os.getenv("ANTHROPIC_API_KEY"))@entrypoint(store=store)
async def my_agent(message: str, config: RunnableConfig):memories = await manager.asearch(query=message,config=config,)llm_response = await client.messages.create(model="claude-3-5-sonnet-latest",system="You are a helpful assistant.\n\n## Memories from the user:"f"\n<memories>\n{memories}\n</memories>",max_tokens=2048,messages=[{"role": "user", "content": message}],)response = {"role": "assistant", "content": llm_response.content[0].text}await manager.ainvoke({"messages": [{"role": "user", "content": message}, response]},)return response["content"]config = {"configurable": {"langgraph_user_id": "user123"}}
response_1 = await my_agent.ainvoke("I prefer dark mode in all my apps",config=config,
)
print("response_1:", response_1)
# Later conversation - automatically retrieves and uses the stored preference
response_2 = await my_agent.ainvoke("What theme do I prefer?",config=config,
)
print("response_2:", response_2)
# You can list over memories in the user's namespace manually:
print(manager.search(query="app preferences", config=config))
- 使用summarize_messages总结历史对话
from langgraph.graph import StateGraph, START, MessagesState
from langgraph.checkpoint.memory import InMemorySaver
from langmem.short_term import summarize_messages, RunningSummary
from langchain_openai import ChatOpenAI
from pydantic import SecretStr
model = ChatOpenAI(model="ep-20250415164829-89rqj",temperature=0.7,timeout=60,api_key=SecretStr("3feeff15-7053-4ad4-813a-2ee09d1e8983"),base_url="https://ark.cn-beijing.volces.com/api/v3",)
summarization_model = model.bind(max_tokens=128)class SummaryState(MessagesState):summary: RunningSummary | Nonedef call_model(state):summarization_result = summarize_messages(state["messages"],running_summary=state.get("summary"),model=summarization_model,max_tokens=30,max_tokens_before_summary=20,max_summary_tokens=20,)response = model.invoke(summarization_result.messages)state_update = {"messages": [response]}if summarization_result.running_summary:state_update["summary"] = summarization_result.running_summaryprint(response.content)return state_updatecheckpointer = InMemorySaver()
workflow = StateGraph(SummaryState)
workflow.add_node(call_model)
workflow.add_edge(START, "call_model")
graph = workflow.compile(checkpointer=checkpointer)config = {"configurable": {"thread_id": "1"}}
graph.invoke({"messages": "hi, my name is bob"}, config)
graph.invoke({"messages": "write a short poem about cats"}, config)
graph.invoke({"messages": "now do the same but for dogs"}, config)
graph.invoke({"messages": "what's my name?"}, config)
参考文档:
https://github.com/langchain-ai/langmem
https://langchain-ai.github.io/langmem/
Letta/MemGPT
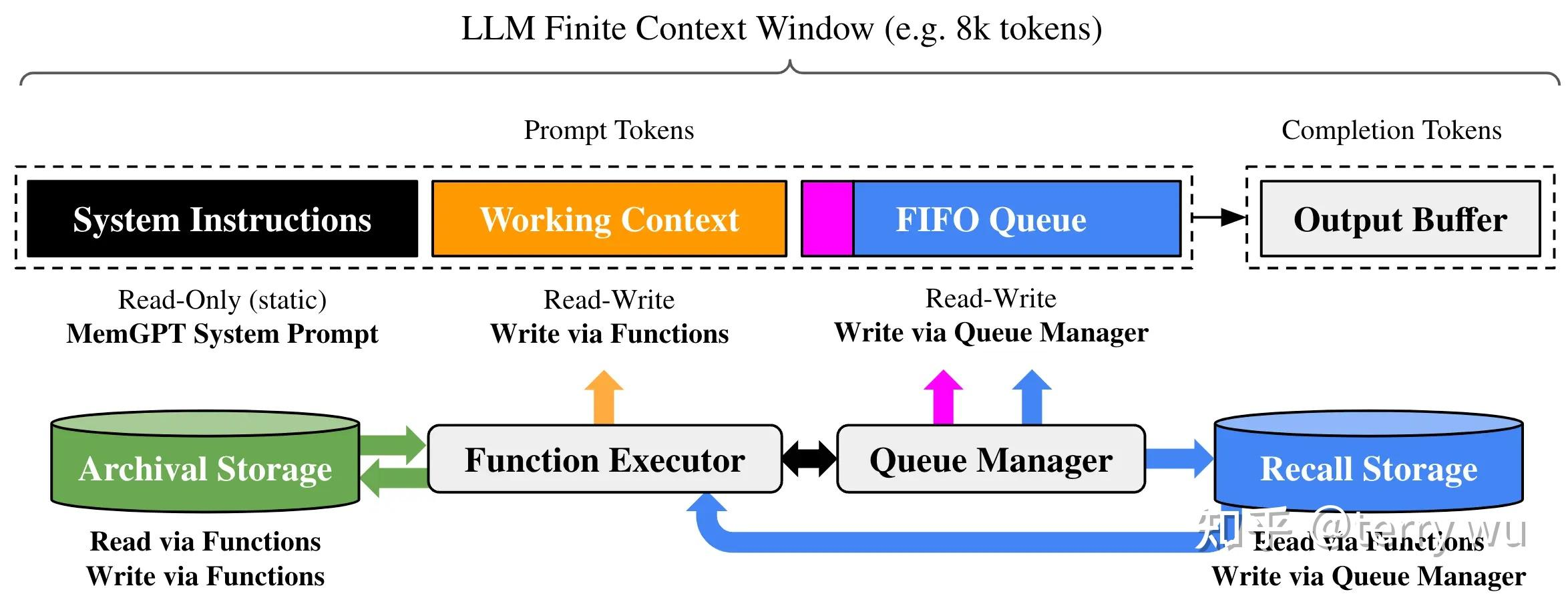
主要是借鉴了传统操作系统中虚拟内存(virtual memory)的管理机制,memgpt方案对LLM context窗口进行了详细的规划和分配(最大化发挥context窗口效用;对应OS中的物理内存),另外增加了archival memory和recall memory(通过数据库进行管理,作为context窗口的补充;对应OS中的磁盘空间)。
memgpt设计理念
通常情况下,标准LLM大模型提供的是一个无状态(stateless)api接口,”tokens in, tokens out”, LLM服务侧不会管理和保留任何信息,仅会根据用户侧单次发起请求中携带的context窗口信息进行应答和反馈;而用户侧应用则需要负责管理和提供所有信息(比如提供message history、rag方案会提供text chunk等)。
memgpt大致可以理解为是一个位于LLM大模型和用户应用之间的编排层(orchestration layer),其底层基础是LLM大模型,同时对外提供服务接口。在实际使用过程中,memgpt会创建一个agent,该agent可视作为一个状态机(stateful),负责管理(中转、编排、传递)某个用户应用与LLM之间的所有对话内容。
在对话过程中,mempgt agent会将关键数据留存在当前context窗口,将非关键数据保存在archival storage数据库,将所有历史对话message记录保存在recall storage数据库,并且随时根据需要从数据库中搜索和取回数据、再填充到context窗口中,从而确保LLM能够获得“某种形式的历史信息“或者”memory“。
注:memgpt还支持data source功能,可以将文档进行embedding,加载到archival memory,由agent进行搜索调用,这可以理解为一种极为简化的轻量级rag方案(主流RAG方案是需要采用更加精巧、完善的优化设计)。
memgpt memory层次结构
memgpt的memory长效记忆能力主要是由两个方面构成:
-
**memory的双层数据存储结构。**包含context window(第一层级),以及 archival memory和recall memory(第二层级)。借鉴操作系统的虚拟内存(virtual memory)管理机制,将需要频繁调用的关键数据留存在第一层级,将其它数据保存或备份在第二层级。
-
具备memory编辑管理能力的tool工具。基于LLM的function calling功能,通过预先设计定义的function、以及优化的prompt提示词,为tool工具能力提供了支撑保障。
Context window
最为重要的context窗口被分割为几个部分:
-
System Instruction:该部分内容相对固定,主要包含agent基本设定,memory编辑功能特性说明;介绍Core memory,Archival Storage,Recall Storage的用途、以及可以调用的tool工具。
-
Working Context:也称为Core Memory或In-Context memory,用于保存agent的memory block。在默认模式下(正常对话应用场景),agent会包含两个block,一个是human(保存用户基本信息),一个是persona(保存agent自身角色设定)。随着对话过程的展开,agent会根据自行判断或用户指令,持续补充、修改human和persona block中保存的内容。这部分内容就构成了agent对于用户、及自身情况的基本认知。
-
FIFO Queue:主要是包含最近的对话message记录。实际上,由于context窗口长度限制,定期会将一部分message记录保存到Recall Storage、并且会从context中删除这些记录;此时,memgpt会针对删除的message记录、以及原先的summary(如已存在),生成一个recursive memory。在context窗口中,这部分内容调整最为频繁。
context窗口内容由memgpt agent负责管理和编排,一并提交给底层LLM大模型进行处理;LLM返回的内容同样也会经由agent,agent根据流程处理完毕后再传递给用户。
【letta实际方案补充完善】
目前,letta框架实际方案中的context windows,相对于原memgpt论文进行了完善,单独新增列出了Tools descriptions和External Summary部分。
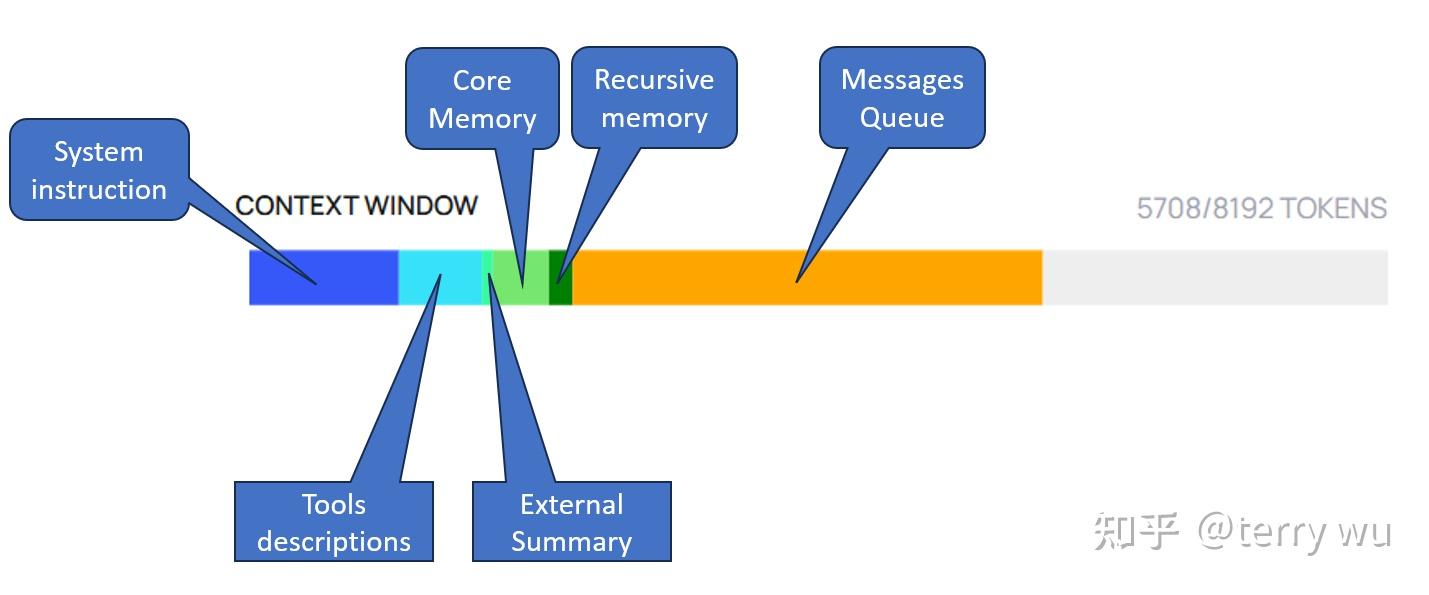
-
**Tools description:**包括系统默认memory编辑管理tool工具、以及其它自定义tool,将其转换为json schema形式进行保存。
-
External Summary:实际上就是Recall storage/memory,Archival storage/memory的当前统计数据。

Archival Storage和Recall Storage
- Archival Storage:Archival Storage可视作为Core memory的补充,提供了“无限空间“。根据system prompt默认模板设定,Archival Storage定位介于core memory和recall storage之间。个人理解通常是会保存一些相对比较抽象的信息,比如agent根据自己理解总结而获得的一些关于用户的行为习惯、或个人偏好等。
另外,当Core memory预留空间用完时,Archival Storage也可作为一个额外的存储空间。Archival Storage采用embedding向量搜索方式。
【Core memory定位】
Core memory provides essential, foundational context for keeping track of your persona and key details about user.
【Archival Storage定位】
A more structured and deep storage space for your reflections, insights, or any other data that doesn’t fit into the core memory but is essential enough not to be left only to the ‘recall memory’.
(以上摘自system prompt默认模板)
- Recall Storage:是将历史过往的message对话记录全部留存保存下来,以便agent随时进行检索调用。Recall Storage采用关键字搜索方式。
memory编辑管理工具
- Function Executor:即通过Function Executor来调用memory编辑管理工具。 agent默认包含5个memory编辑管理工具、和1个用户消息发送工具。
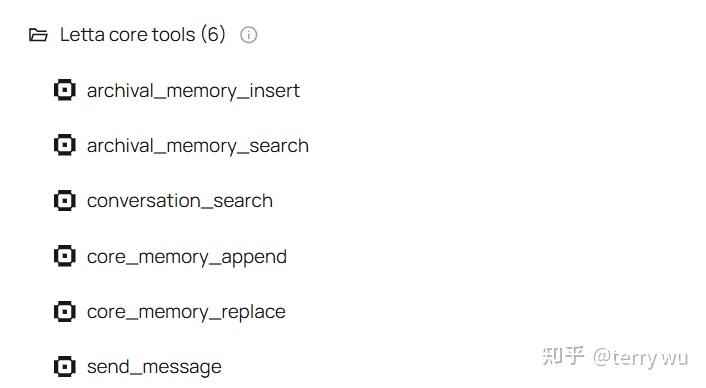
此外,还有一个Queue Manager,是内置的message queue管理工具。
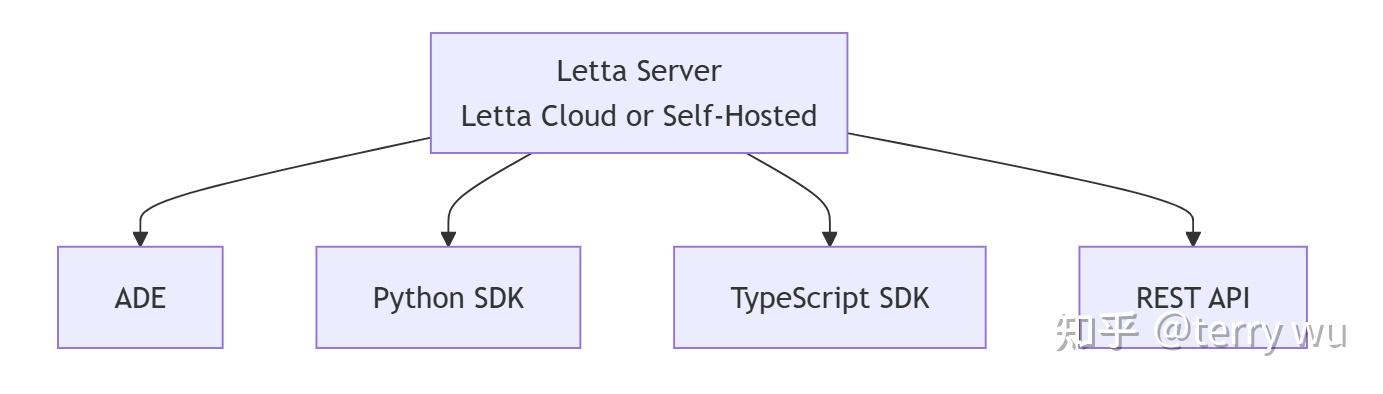
letta可以理解为是一个总体框架,内部包含memgpt agent;letta框架对外提供各种形式接口,方便用户调用memgpt agent。
letta框架中,支持多种agent调用方式,包括Python/TypeScript SDK,REST API 和ADE(Agent Development Environment )。
总结
**优点:**可docker 部署服务,服务版数据库使用postageSQL,易于数据迁移。
**缺点:**python SDK文档介绍的接口使用方法不详细
接入方案
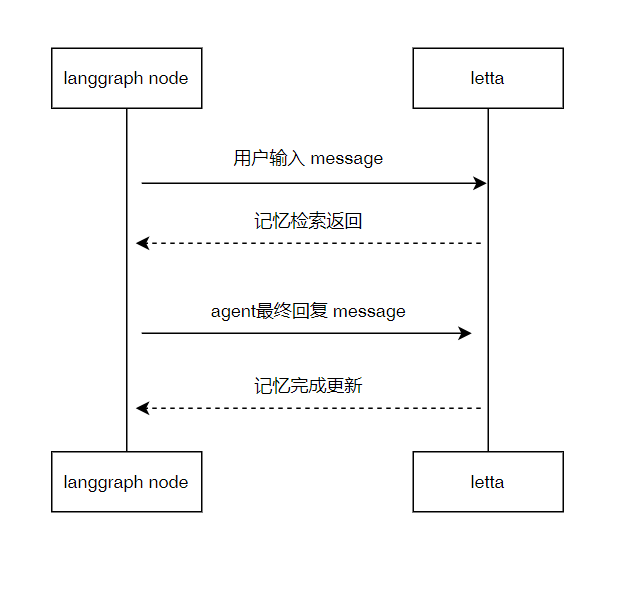
代码示例
from letta_client import Letta
# 链接服务器
client = Letta(base_url= "http://10.4.65.99:8283",# base_url= "http://localhost:8283",token="123456",
)#创建agent
llm_config = {"model": "gpt-4o","model_endpoint_type": "openai","model_endpoint": "string","provider_name": "string","provider_category": "base","model_wrapper": "string","context_window": 0,"put_inner_thoughts_in_kwargs": True,"handle": "string","temperature": 0.7,"max_tokens": 4096,"enable_reasoner": False,"reasoning_effort": "low","max_reasoning_tokens": 0}embedding_config = {"embedding_endpoint_type": "openai","embedding_endpoint": "string","embedding_model": "string","embedding_dim": 0,"embedding_chunk_size": 300,"handle": "string","azure_endpoint": "string","azure_version": "string","azure_deployment": "string"}client = Letta(base_url= "http://10.4.65.99:8283",# base_url= "http://localhost:8283",token="123456",
)
# 创建一个带记忆能力的agent
client.agents.create(name="Test", llm_config=llm_config, embedding_config=embedding_config)
处理用户消息,返回响应
from letta_client import Letta, MessageCreate, TextContentclient = Letta(token="YOUR_TOKEN",
)
client.agents.messages.create(agent_id="agent_id",messages=[MessageCreate(role="user",content=[TextContent(text="text",)],)],
)
参考文档:
https://docs.letta.com/api-reference/overview
https://github.com/letta-ai/letta-python/blob/main/reference.md
| 特性/系统 | Mem0 | LangMem | MemGPT |
|---|---|---|---|
| 核心目标 | 提供多层次、个性化的长期记忆支持 | 增强 LLM 的长期记忆能力,提升多轮对话表现 | 实现虚拟上下文管理,突破 LLM 上下文窗口限制 |
| 记忆架构 | 多层次记忆架构,涵盖用户、会话和 AI 代理记忆 | 采用向量数据库存储记忆,结合注意力机制进行检索 | 分层记忆管理,模拟操作系统的虚拟内存机制 |
| 记忆更新机制 | 支持动态更新和历史追踪,保留记忆的历史版本 | 通过交互持续优化,提升个性化服务 | 利用事件驱动控制流,自主编辑和检索记忆 |
| 适用场景 | 个性化学习助手、客户支持、医疗保健、虚拟伴侣等 | 多轮对话系统、个性化推荐、用户行为分析等 | 长文档分析、多轮对话、任务规划等需要扩展上下文的任务 |
| 部署方式 | 提供托管服务和开源包,支持私有云部署 | 提供开源代码,支持本地部署和定制化开发 | 提供开源代码,支持本地部署和定制化开发 |
| 开发者支持 | 提供简洁的 API,便于快速集成 | 提供灵活的 API 接口,支持多种集成方式 | 提供函数调用接口,支持事件驱动的控制流管理 |
| 开源地址 | GitHub - mem0ai/mem0 | GitHub - langmem/langmem | GitHub - memgpt/memgpt |