机器学习k近邻,高斯朴素贝叶斯分类器
1、k近邻分类
# 2-14 k近邻分类
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from scipy import stats # 导入stats# 参数设置
knn_k_max = 20 # k近邻中的最大k值
folds = 4 # k份交叉验证的份数k
# 读入轮椅数据集
df = pd.read_csv('wheelchair_dataset.csv')
data = np.array(df)
m_all = np.shape(data)[0] # 样本总数
d = np.shape(data)[1] - 1 # 输入特征的维数
classes = np.amax(data[:, d]) # 类别数量
m_test = m_all // folds # 测试数据集中样本的数量
m_train = m_test * (folds - 1) # 训练数据集中样本的数量
# 构造随机种子为指定值的随机数生成器,并对数据集中样本随机排序
rng = np.random.default_rng(1)
rng.shuffle(data)
# 对所有样本的输入特征进行归一化(因取值范围已知)
data = data.astype(float)
data[:, 0:d - 1] = (data[:, 0:d - 1] - 0) / (1023 - 0) # 归一化压力传感器读数
data[:, d - 1] = (data[:, d - 1] - 0) / (50 - 0) # 归一化超声波传感器的读数
# 用于保存分类错误的数量
train_errors = np.zeros(knn_k_max)
test_errors = np.zeros(knn_k_max)
# 对k份交叉验证的k个不同数据集划分进行循环
for kfold_k in range(folds):test_start = kfold_k * m_test # 测试数据集中第一个样本的索引# 划分数据集X_test = data[test_start:test_start + m_test, 0:d]Y_test = data[test_start:test_start + m_test, d]X_train_p1 = data[0:test_start, 0:d] # 训练数据集输入特征的前一部分X_train_p2 = data[test_start + m_test:, 0:d] # 训练数据集输入特征的后一部分X_train = np.concatenate((X_train_p1, X_train_p2), axis=0) # 连接训练数据集输入特征数组Y_train_p1 = data[0:test_start, d] # 训练数据集标注的前一部分Y_train_p2 = data[test_start + m_test:, d] # 训练数据集标注的后一部分Y_train = np.concatenate((Y_train_p1, Y_train_p2), axis=0) # 连接训练数据集输入特征数组# 对k近邻中的k进行循环for knn_k in range(1, knn_k_max + 1): # 对测试数据集中的每个样本for i in range(m_test):X = X_test[i, :].reshape((1, -1)) # 当前样本的总输入特征Y = Y_test[i] # 当前样本的标注diff = X - X_train # 当前样本与训练数据集中所有样本的输入特征之差dist = np.sum(diff * diff, axis=1) # 计算距离的平方sorted_index = np.argsort(dist) # 对距离排序并得到排序后的索引k_index = sorted_index[0:knn_k] # 前k个训练样本的索引k_label = Y_train[k_index] # 前k个训练样本的标注Y_hat = stats.mode(k_label, keepdims=True).mode[0] # 把前k个训练样本标注的众数作为预测类别值# 累加测试数据集上的分类错误数量if(Y_hat !=Y):test_errors[knn_k-1]=test_errors[knn_k-1]+1# 对训练数据集中每一个样本for i in range(m_train):X = X_train[i, :].reshape((1, -1)) # 当前样本的总输入特征Y = Y_train[i] # 当前样本的标注diff = X - X_train # 当前样本与训练数据集中所有样本的输入特征之差dist = np.sum(diff * diff, axis=1) # 计算距离的平方sorted_index = np.argsort(dist) # 对距离排序并得到排序后的索引k_index = sorted_index[0:knn_k] # 前k个训练样本的索引k_label = Y_train[k_index] # 前k个训练样本的标注Y_hat = stats.mode(k_label, keepdims=True).mode[0] # 把前k个训练样本标注的众数作为预测类别值# 累加训练数据集上的分类错误数量if(Y_hat !=Y):train_errors[knn_k-1]=train_errors[knn_k-1]+1
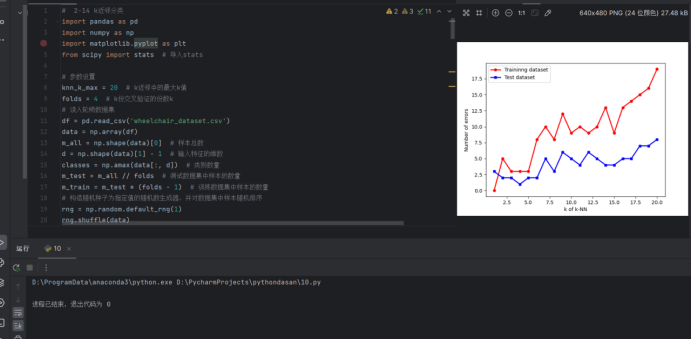
# 画出两个数据集上的分类错误线
plt.plot(np.arange(1, knn_k_max + 1), train_errors, 'r-o', linewidth=2, markersize=5)
plt.plot(np.arange(1, knn_k_max + 1), test_errors, 'b-s', linewidth=2, markersize=5)
plt.ylabel('Number of errors')
plt.xlabel('k of k-NN')
plt.legend(['Traininng dataset', 'Test dataset'])
plt.show()
结果图
2、高斯朴素贝叶斯分类器
# 2-16 高斯朴素贝叶斯分类器
import pandas
import numpy as np# 参数设置
m_train = 200 # 训练样本数量
# 读入轮椅数据
df = pandas.read_csv('wheelchair_dataset.csv')
data = np.array(df)
m_all = np.shape(data)[0] # 样本数量
d = np.shape(data)[1] - 1 # 输入特征维数
m_test = m_all - m_train # 测试样本的数量# 构造随机种子为指定值的随机数生成器,并对数据集中的样本随机排序
rng = np.random.default_rng(1)
rng.shuffle(data)# 划分数据集
X_train = data[0:m_train, 0:d]
y_train = data[0:m_train, d]
X_test = data[m_train:, 0:d]
y_test = data[m_train:, d]# 用于保存混淆矩阵
test_conf_mat = np.zeros((classes, classes)) # 测试数据集混淆矩阵
train_conf_mat = np.zeros((classes, classes)) # 训练数据集混淆矩阵# 用于保存高斯朴素贝叶斯分类器的参数
gnb_priors = np.zeros(classes).reshape((-1, 1)) # 各个类别的先验概率
gnb_means = np.zeros((classes, d)) # 均值
gnb_stds = np.zeros((classes, d)) # 标准差# 训练(估算参数)
for c in range(classes): # 对于每一个类别x_class_c = np.compress(y_train == c + 1, X_train, axis=0) # 从训练数据集中抽取该类别训练样本的输入特征gnb_priors[c, 0] = np.shape(x_class_c)[0] / m_train # 估算该类别的先验概率gnb_means[c, :] = np.mean(x_class_c, axis=0) # 估算该类别训练样本各维输入特征的均值gnb_stds[c, :] = np.std(x_class_c, axis=0, ddof=1) # 估算该类别训练样本各维输入特征的标准差# 预测(测试数据集)
for i in range(m_test): # 对测试数据集中每一个样本x = X_test[i, :].reshape((1, -1)) # 样本的输入特征std_x = (x - gnb_means) / gnb_stds # 标准化输入特征p_class = np.log(gnb_priors) - np.sum(0.5 * std_x * std_x + np.log(gnb_stds), axis=1).reshape((-1, 1)) # 该输入特征对应为各个类别的可能性y_hat = np.argmax(p_class) + 1 # 预测:样本对应为可能性最大的类别# 累加测试数据集上的混淆矩阵y = y_test[i]test_conf_mat[y_hat - 1, y - 1] = test_conf_mat[y_hat - 1, y - 1] + 1# 预测(训练数据集)
for i in range(m_train): # 对训练数据集中每一个样本x = X_train[i, :].reshape((1, -1)) # 样本的输入特征std_x = (x - gnb_means) / gnb_stds # 标准化输入特征p_class = np.log(gnb_priors) - np.sum(0.5 * std_x * std_x + np.log(gnb_stds), axis=1).reshape((-1, 1)) # 该输入特征对应为各个类别的可能性y_hat = np.argmax(p_class) + 1 # 预测:样本对应为可能性最大的类别# 累加训练数据集上的混淆矩阵y = y_train[i]train_conf_mat[y_hat - 1, y - 1] = train_conf_mat[y_hat - 1, y - 1] + 1# 清零累加变量
F1_acc_test, F1_acc_train = 0, 0# 累加测试数据集和训练数据集上各个类别的F1值
for c in range(classes):precision_test = test_conf_mat[c, c] / np.sum(test_conf_mat[c, :])recall_test = test_conf_mat[c, c] / np.sum(test_conf_mat[:, c])F1_acc_test = F1_acc_test + 2 * precision_test * recall_test / (precision_test + recall_test)precision_train = train_conf_mat[c, c] / np.sum(train_conf_mat[c, :])recall_train = train_conf_mat[c, c] / np.sum(train_conf_mat[:, c])F1_acc_train = F1_acc_train + 2 * precision_train * recall_train / (precision_train + recall_train)# 计算宏平均F1值
test_macro_F1 = F1_acc_test / classes
train_macro_F1 = F1_acc_train / classes# 计算训练数据集和测试数据集上的马修斯相关系数
test_MCC_a = np.sum(test_conf_mat)
test_MCC_s = np.trace(test_conf_mat)
test_MCC_h = np.sum(test_conf_mat, axis=1)
test_MCC_l = np.sum(test_conf_mat, axis=0)
test_MCC = (test_MCC_a * test_MCC_s - np.dot(test_MCC_h, test_MCC_l)) / np.sqrt((test_MCC_a * test_MCC_a - np.dot(test_MCC_h, test_MCC_h)) * (test_MCC_a * test_MCC_a - np.dot(test_MCC_l, test_MCC_l)))
train_MCC_a = np.sum(train_conf_mat)
train_MCC_s = np.trace(train_conf_mat)
train_MCC_h = np.sum(train_conf_mat, axis=1)
train_MCC_l = np.sum(train_conf_mat, axis=0)
train_MCC = (train_MCC_a * train_MCC_s - np.dot(train_MCC_h, train_MCC_l)) / np.sqrt((train_MCC_a * train_MCC_a - np.dot(train_MCC_h, train_MCC_h)) * (train_MCC_a * train_MCC_a - np.dot(train_MCC_l, train_MCC_l)))# 打印结果
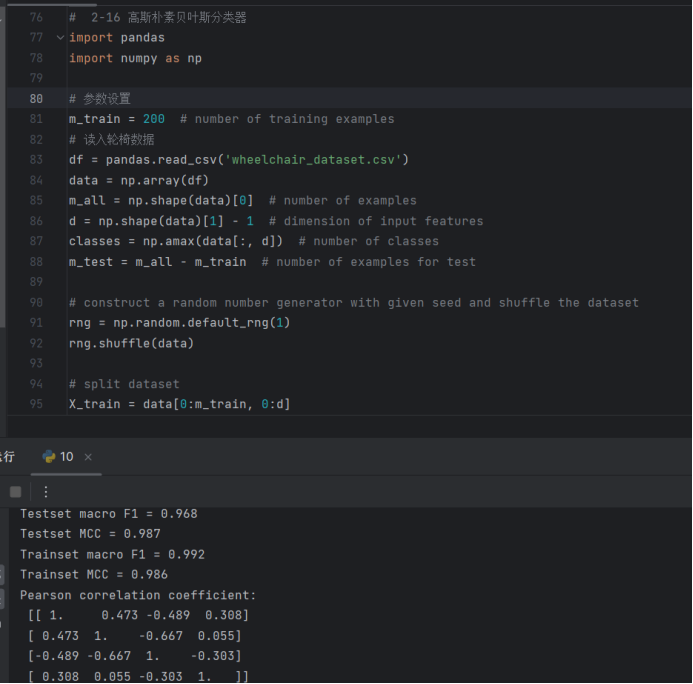
print(f'Testset macro F1 = {test_macro_F1:.3f}')
print(f'Testset MCC = {test_MCC:.3f}')
print(f'Trainset macro F1 = {train_macro_F1:.3f}')
print(f'Trainset MCC = {train_MCC:.3f}')
结果图