并发编程艺术--AQS底层源码解析(二)
上一章讲完了独占非中断获取锁的源码,本章我们来讲一讲共享锁以及中断获取锁的源码。
源码:
共享获取锁:
首先我们要了解什么是共享锁,共享式获取与独占式获取最主要的区别在于同一时刻能否有多个线程同时获取到同步的状态。以读写锁为例,在数据库中的读锁则是共享锁,可以允许多个线程同时访问这个资源,但是写锁则为独占锁也就是说只能允许一个线程在一个时间段访问这个资源。并且读锁和写锁是互斥的,也就是共享锁和独占锁是互斥的
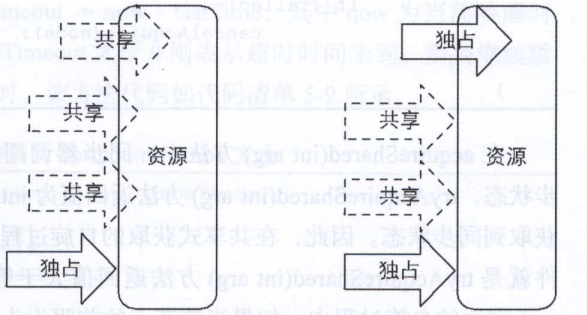
上图可以看出对于共享锁可以允许多个线程访问当持有共享锁的时候独占线程后续则不能持有独占锁,同样的当独占锁持有锁的同时不允许共享锁持有。我们看一下ReentrantReadWriteLock锁源码
public class ReentrantReadWriteLock implements ReadWriteLock, Serializable {private static final long serialVersionUID = -6992448646407690164L;private final ReadLock readerLock;private final WriteLock writerLock;final Sync sync;
}
可以看出ReentrantReadWriteLock内部含有三个内部类一个是readerLock(读锁),一个是writerLock(写锁),一个是Sync(AQS子类)。那么其实readerLock与writerLock的api调用还是基于Sync的方法来实现的。
那么公用一个Sync 当进行读写锁的获取的时候如何达到读写互斥呢,原理就在于AQS的state变量,对于这个变量是int类型的,那么就将其分为两部分,高16位表示高 16 位表示读锁计数,低 16 位表示写锁重入次数,基于此可以区分当前锁是否有读锁和写锁,当进行读锁或者写锁获取判断的时候只需要看高16位和低16位值是否大于0就知道当前锁对象中是否含有读锁或者写锁,基于此来实现了读写互斥。
读写互斥我们说完了那么我们就来讲讲读锁也就是共享锁获取的源码解析:
public void lock() {this.sync.acquireShared(1);}可以看出读锁的lock获取是基于AQS的acquireShared方法来实现的。其中的参数与独占锁表示的一样也是获取同步资源的个数。
public final void acquireShared(int var1) {if (this.tryAcquireShared(var1) < 0) {this.doAcquireShared(var1);}}其中tryAcquireShared表示尝试获取锁,其中会返回当前锁的state值表示资源的剩余量,如果小于0则表示获取锁失败,会进入doAcquireShared方法中,并且tryAcquireShared也是交给子类去实现的
private void doAcquireShared(int var1) {Node var2 = this.addWaiter(AbstractQueuedSynchronizer.Node.SHARED);boolean var3 = true;try {boolean var4 = false;while(true) {Node var5 = var2.predecessor();if (var5 == this.head) {int var6 = this.tryAcquireShared(var1);if (var6 >= 0) {this.setHeadAndPropagate(var2, var6);var5.next = null;if (var4) {selfInterrupt();}var3 = false;return;}}if (shouldParkAfterFailedAcquire(var5, var2) && this.parkAndCheckInterrupt()) {var4 = true;}}} finally {if (var3) {this.cancelAcquire(var2);}}}
分析上述源码,首先与独占锁一样先得到Node节点调用addWaiter方法进行初始化初始化方法的逻辑与独占锁初始化的一样上一章已经讲过,这里就不加赘述了。然后我们看与独占锁一样进入了一个死循环中,并且逻辑也几乎一样首先判断前驱节点是否为head节点,如果不是则不会尝试获取锁,是则获取锁。由此可见:几乎每个节点都不会与其他节点进行通信的,都是通过比较头节点来选择是否进行锁抢占。那么与独占锁的区别在于尝试获取锁的时候返回值不再是Boolean类型而是int类型原因是读锁是共享锁可以多个线程访问资源,而这里控制线程访问数量则是通过state的值来进行控制的。后续的逻辑与独占锁基本相同,如果返回的值大于0表明还有资源可以获取此时则会进行head头的设置,注意这里的head头设置采用了CAS锁的方式进行设置与独占锁不同,原因可能多个线程同时设置head头,而独占锁肯定只有一个线程来设置head头。而如果不是head头则会进行shouldParkAfterFailedAcquire方法的阻塞校验设置以及调用parkAndCheckInterrupt进入阻塞状态减少cpu资源的消耗。
我们可以看出共享锁与独占锁获取锁的方式大差不差区别点在于尝试获取锁的时候返回类型以及head头设置的时候需要加上CAS锁保证同步,并且同样的var4表示线程的中断状态但是并没有实质性的作用,因此这个方法也是无法进行中断的。接下来我们将讲述可以中断的获取锁的方法。
独占超时获取锁:
我们直接从ReentrantLock源码的tryLock来进行源码分析
public boolean tryLock(long var1, TimeUnit var3) throws InterruptedException {return this.sync.tryAcquireNanos(1, var3.toNanos(var1));}
这里的参数多了一个TimeUnit类型的表示超时时间,也就是说这个获取锁是有一个时间限制的如果超时之后将会直接返回当前锁获取结果。我们可以看出其核心代码还是依赖于AQS的tryAcquireNanos方法
public final boolean tryAcquireNanos(int var1, long var2) throws InterruptedException {if (Thread.interrupted()) {throw new InterruptedException();} else {return this.tryAcquire(var1) || this.doAcquireNanos(var1, var2);}}可以看出首先就进行了线程中断的判断,如果中断标志为打开那么就会抛出异常来终止方法的进行。如果中断标志位为false则会进入以下两个方法tryAcquire和doAcquireNanos。其中tryAcquire则是交给子类去实现的方法。doAcquireNanos则是进入等待队列的方法。
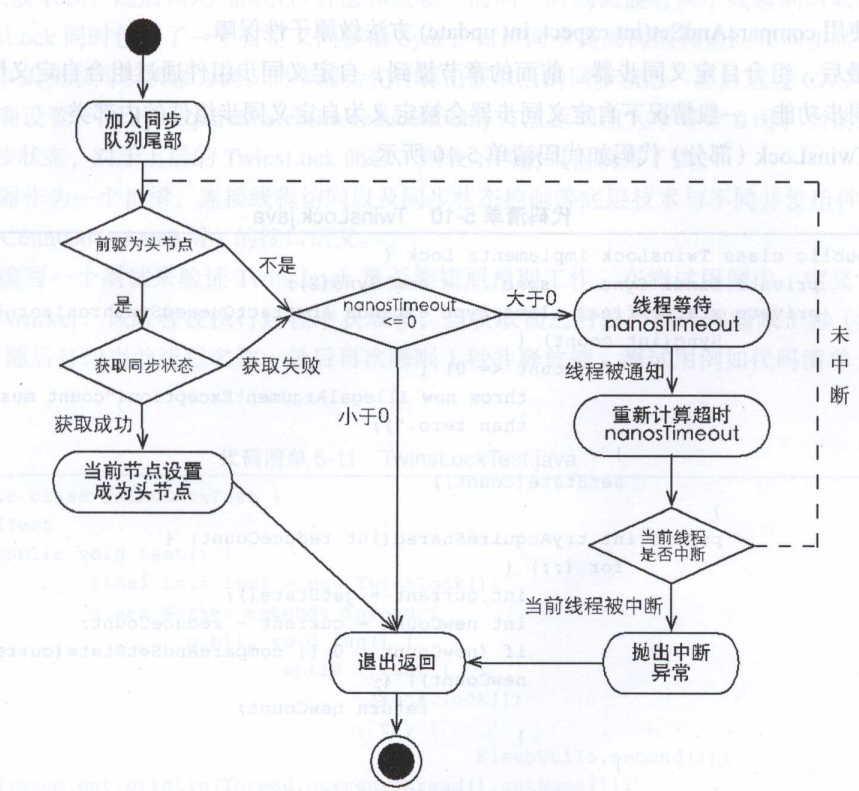
private boolean doAcquireNanos(int var1, long var2) throws InterruptedException {if (var2 <= 0L) {return false;} else {long var4 = System.nanoTime() + var2;Node var6 = this.addWaiter(AbstractQueuedSynchronizer.Node.EXCLUSIVE);boolean var7 = true;while(true) {boolean var9;try {Node var8 = var6.predecessor();if (var8 == this.head && this.tryAcquire(var1)) {this.setHead(var6);var8.next = null;var7 = false;var9 = true;return var9;}var2 = var4 - System.nanoTime();if (var2 > 0L) {if (shouldParkAfterFailedAcquire(var8, var6) && var2 > 1000L) {LockSupport.parkNanos(this, var2);}if (Thread.interrupted()) {throw new InterruptedException();}continue;}var9 = false;} finally {if (var7) {this.cancelAcquire(var6);}}return var9;}}}进入方法之后首先判断是否当前时间小于0,小于则直接返回false。然后判断head是否为前驱节点并且尝试获取锁,如果都为true则会将head进行重新设置。此时设置head不需要CAS因为是独占锁。如果head头既不是前驱节点那么就会计算当前时间还剩余多少。如果剩余时间小于0那么则证明时间过期直接设置返回false,表示方法执行结束。如果时间还有那么就会进行阻塞判断,判断逻辑与独占非中断锁几乎一样都是先查看当前前驱节点的状态是否符合标准如果不符合则会重新选择前驱节点(将前驱节点剔除),同时判断所剩时间是否过于小,如果都符合的话则会进入阻塞,这里的阻塞与非中断阻塞不同,这里的阻塞设置了阻塞时间。
public static void parkNanos(Object var0, long var1) {if (var1 > 0L) {Thread var3 = Thread.currentThread();setBlocker(var3, var0);UNSAFE.park(false, var1);setBlocker(var3, (Object)null);}}其中park方法则是阻塞方法,Unsafe.park则是阻塞方法。当出来之后也会判断当前线程是否中断标志为true,如果为true则会抛出异常。
if (Thread.interrupted()) {throw new InterruptedException();}后续的方法则与不可中断的获取锁方法逻辑一样。
至此我们来总结一下可中断的超时获取锁与普通的获取锁的区别在哪里
1. 几乎每个方法都会先判断当前线程的中断标志位,并且做出对应的处理,这里与普通获取锁不同,普通获取锁只会记录而不会做出对应的逻辑处理
2.同时设置超时时间会在循环中进行时间判断如果时间剩余小于0则会直接返回当前的获取锁的结果值
至此独占,共享,可中断,含有超时时间的获取锁的方法源码解析都已经解析完毕。接下来我们讲一讲可重入锁的源码分析。