机器学习-模型选择与调优
模型选择和参数调优是为了更好的训练模型,提高效率。
一、交叉验证
1.1 保留交叉验证
保留交叉验证HoldOut Cross-validation(Train-Test-Split):就是我们经常用的模型选择库中的数据集划分方法。from sklearn.model_seletion import train_test_split
优点:很简单很容易执行。
缺点:
(1)不适用于分布不平衡的数据集:如果整个数据集前面70%都是一个分类结果,后面30%是另一个分类结果,此时模型并没有接触过后一个分类结果,它不能很好的训练数据集。
(2) 不适用于小数据集:小数据集本来就小,还要被分一些出来做训练集,可能会缺失一些特征,训练结果就不准确。
1.2 K-折交叉验证
我们将数据集划分为K个大小相同的部分,一个fold作为验证机,其余的fold作为训练集。让模型重复训练k次,让每一个fold都能作为验证集。
这样计算出来的模型准确率是通过取k个模型验证数据的平均准确率来计算。
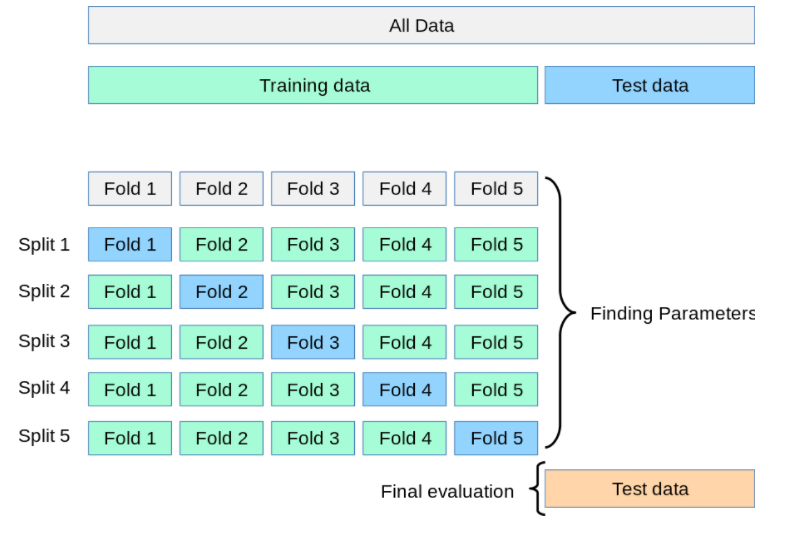
1.3 分层K-折交叉验证
分层K-折就是在K-折的基础之上,将每一折中都保持着原数据中各个类别的比例关系,避免分配不均导致的模型训练不稳定。
比如说:原始数据有3类,比例为1:2:1,采用3折分层交叉验证,那么划分的3折中,每一折中的数据类别保持着1:2:1的比例,这样的验证结果更加可信。
目的:保证数据划分更具体,不会出现像保留交叉验证一样,一个结果出现在训练集或测试集,分布不均,训练不准确。
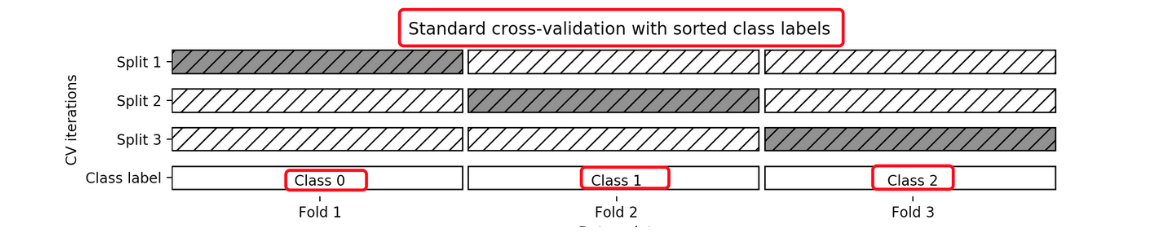
1.4 其他验证
留一交叉验证:k 折交叉验证的极端情况,k 等于样本总数 n,每次留 1 个样本作测试集,其余 n-1 个作训练集,重复 n 次。
蒙特卡罗交叉验证:多次随机划分数据集为训练集和测试集(如 100 次),每次按固定比例(如 80% 训练、20% 测试)随机抽样,最终取多次评估结果的平均值和方差。
时间序列交叉验证:针对具有时间顺序的数据(如股票价格、气温数据),严格遵循 “过去数据训练,未来数据测试” 的原则,避免数据泄露(即不允许用未来数据训练模型)。
1.5 api
from sklearn.model_selection import StratifiedKFold (分层k-折交叉验证)
from sklearn.model_seletion import KFold (k-折交叉验证)
参数:
n_splits:划分的折叠数目;
shuffle:拆分前是否需要打乱;
random_state:随机因子,确定后随机顺序固定。
注意:分层k-折的结果返回的是下标
indexs=strat_k_fold.split(X,y) :返回的是下标
1.6 示例
步骤:
(1)加载数据集
(2)划分数据集(利用KF,S-K-F)
(3)预估器(KNN分类)
(4)交叉验证
from sklearn.datasets import load_iris
from sklearn.model_selection import KFold
from sklearn.preprocessing import StandardScaler
from sklearn.neighbors import KNeighborsClassifier# 加载数据集
iris = load_iris()
X = iris.data
y = iris.target# 数据划分
kf = KFold(n_splits=5, shuffle=True, random_state=42)#创建预估器
knn = KNeighborsClassifier(n_neighbors=7)# 进行k-折交叉验证
accuracy = [] # 记录每次交叉验证的准确率
for train_index,test_index in kf.split(X,y):# print("train_index:") # 每次划分的训练集索引# print(train_index)# print("test_index:") # 每次划分的测试集索引# print(test_index)X_train,X_test = X[train_index],X[test_index]y_train,y_test = y[train_index],y[test_index]# 数据标准化scaler = StandardScaler()X_train_scaled = scaler.fit_transform(X_train)X_test_scaled = scaler.transform(X_test)# 训练模型knn.fit(X_train_scaled,y_train)# 预测y_pred = knn.predict(X_test_scaled)# 计算准确率current_accuracy = knn.score(X_test_scaled,y_test)accuracy.append(current_accuracy) # 记录每次交叉验证的准确率
print("y_pred:",y_pred)
print("mean_accuracy:",sum(accuracy)/len(accuracy)) #通过k-折交叉验证的准确率结果:
![]()
二、超参数搜索
2.1超参数的定义
一些算法或是api函数的参数需要人为设置,而且产生不一样的结果,需要调试。
简单来说就是可以人为设置的参数就是超参数。
超参数搜索也叫网格搜索,可以帮我们自动找到最好的超参数值。
2.2api
from sklearn.model_selection import GridSearchCV(estimator,param_grid)
参数介绍:
estimator:预估器实例,模型
param_grid:这是一个字典,键为参数名称(注意引号),值为超参数数值(用列表括起来)
属性(通过调用可以得到的一些属性信息):
最佳参数:best_params_
在训练集中的准确率:best_score_
最佳预估器:best_estimator_
交叉验证过程描述:cv_results_
最佳k在列表中的下标:best_index_
2.3案例
from sklearn.datasets import load_digits #数字数据集
from sklearn.model_selection import GridSearchCV
from sklearn.neighbors import KNeighborsClassifierdigits = load_digits()
x, y = digits.data, digits.target
print(x.shape, y.shape) #查看数据集大小
# print(x[0:1]) #查看1个数据
# print(digits.target_names) #查看标签名称
# print(digits.feature_names) #查看特征名称#定义模型
knn = KNeighborsClassifier()#定义参数
param_grid = {'n_neighbors':[1,2,3,4,5,6,7,8,9,10]}#定义搜索器
grid = GridSearchCV(knn, param_grid, cv=5) #cv=5表示交叉验证5次#训练
grid.fit(x,y)#查看结果
print('最佳参数:',grid.best_params_) #查看最佳参数
print('最佳得分:',grid.best_score_) #查看最佳得分
print('最佳模型:',grid.best_estimator_) #查看最佳模型
print('交叉验证结果:',grid.cv_results_) #查看交叉验证结果,交叉验证过程描述
print('最佳索引:',grid.best_index_) #查看最佳索引
print('预测:',grid.predict(x[0:1]))结果:
最佳参数: {'n_neighbors': 2}
最佳得分: 0.9671711544413494
最佳模型: KNeighborsClassifier(n_neighbors=2)
交叉验证结果: {'mean_fit_time': array([0.00099692, 0.00082879, 0.00125132, 0.00079823, 0.00099778,
0.00081935, 0.00099869, 0.00107026, 0.0007978 , 0.00060015]), 'std_fit_time': array([1.40323057e-06, 4.18653504e-04, 3.87689213e-04, 3.99112958e-04,
4.76837158e-07, 4.11639674e-04, 6.32486186e-04, 1.36887732e-04,
7.46301923e-04, 3.72818400e-04]), 'mean_score_time': array([0.04248996, 0.01425023, 0.01377449, 0.0166883 , 0.01630931,
0.01730285, 0.01649156, 0.01899719, 0.017243 , 0.01619835]), 'std_score_time': array([0.06054706, 0.00120909, 0.00088281, 0.00118273, 0.00053347,
0.0008768 , 0.00105914, 0.00304906, 0.00128587, 0.00093385]), 'param_n_neighbors': masked_array(data=[1, 2, 3, 4, 5, 6, 7, 8, 9, 10],
mask=[False, False, False, False, False, False, False, False,
False, False],
fill_value='?',
dtype=object), 'params': [{'n_neighbors': 1}, {'n_neighbors': 2}, {'n_neighbors': 3}, {'n_neighbors': 4}, {'n_neighbors': 5}, {'n_neighbors': 6}, {'n_neighbors': 7}, {'n_neighbors': 8}, {'n_neighbors': 9}, {'n_neighbors': 10}], 'split0_test_score': array([0.96111111, 0.96111111, 0.95555556, 0.94722222, 0.94722222,
0.94444444, 0.93611111, 0.93611111, 0.93055556, 0.93055556]), 'split1_test_score': array([0.95277778, 0.96666667, 0.95833333, 0.95833333, 0.95555556,
0.95833333, 0.96111111, 0.95833333, 0.95277778, 0.94722222]), 'split2_test_score': array([0.96657382, 0.96935933, 0.96657382, 0.96657382, 0.96657382,
0.96657382, 0.96935933, 0.96935933, 0.97214485, 0.96935933]), 'split3_test_score': array([0.98607242, 0.97771588, 0.98607242, 0.98050139, 0.98050139,
0.97493036, 0.98050139, 0.97771588, 0.97771588, 0.97771588]), 'split4_test_score': array([0.95543175, 0.96100279, 0.96657382, 0.96657382, 0.9637883 ,
0.95264624, 0.95264624, 0.94986072, 0.94986072, 0.94986072]), 'mean_test_score': array([0.96439338, 0.96717115, 0.96662179, 0.96384092, 0.96272826,
0.95938564, 0.95994584, 0.95827608, 0.95661096, 0.95494274]), 'std_test_score': array([0.01183842, 0.00618072, 0.01067232, 0.01094553, 0.01116854,
0.01061202, 0.01505909, 0.01457979, 0.01688705, 0.01677273]), 'rank_test_score': array([ 3, 1, 2, 4, 5, 7, 6, 8, 9, 10])}
最佳索引: 1
预测: [0]
三、鸢尾花分类案例
用KNN算法对鸢尾花进行分类,添加网格搜索和交叉验证
from sklearn.datasets import load_iris
from sklearn.model_selection import StratifiedKFold
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import GridSearchCV
from sklearn.neighbors import KNeighborsClassifier#加载数据
x,y = load_iris(return_X_y = True)#标准化
scaler = StandardScaler()
x = scaler.fit_transform(x)#创建交叉分类器实例
skf = StratifiedKFold(n_splits=5,shuffle=True,random_state=42)#创建模型
model = KNeighborsClassifier(n_neighbors=3)#创建参数
params = {'n_neighbors':[1,2,3,4,5,6,7,8,9,10]}#创建搜索器
grid = GridSearchCV(model,params)#训练
grid.fit(x,y)#得到结果
print('最佳参数:',grid.best_params_)
print('最佳下标:',grid.best_index_)
print('最佳模型:',grid.best_estimator_)
print('最佳得分:',grid.best_score_)
print('过程描述:',grid.cv_results_)
print('预测:',grid.predict([[2,8.9,0.9,3.2]]))结果:
最佳参数: {'n_neighbors': 6}
最佳下标: 5
最佳模型: KNeighborsClassifier(n_neighbors=6)
最佳得分: 0.9666666666666668
过程描述: {'mean_fit_time': array([0.0001071 , 0.00029998, 0.00051384, 0.00021391, 0.00050397,
0.00010757, 0.0004066 , 0.00040684, 0.00044508, 0.00078511]), 'std_fit_time': array([0.0002142 , 0.00039891, 0.00046208, 0.00026198, 0.00044436,
0.00021515, 0.00049815, 0.00049868, 0.00054933, 0.00065707]), 'mean_score_time': array([0.00198288, 0.00124302, 0.00198274, 0.00220242, 0.00080552,
0.00185204, 0.00122752, 0.00139542, 0.00163827, 0.00080972]), 'std_score_time': array([0.00058545, 0.00046171, 0.00091026, 0.00058962, 0.00040297,
0.00088482, 0.00045424, 0.00048509, 0.0006156 , 0.00049571]), 'param_n_neighbors': masked_array(data=[1, 2, 3, 4, 5, 6, 7, 8, 9, 10],
mask=[False, False, False, False, False, False, False, False,
False, False],
fill_value='?',
dtype=object), 'params': [{'n_neighbors': 1}, {'n_neighbors': 2}, {'n_neighbors': 3}, {'n_neighbors': 4}, {'n_neighbors': 5}, {'n_neighbors': 6}, {'n_neighbors': 7}, {'n_neighbors': 8}, {'n_neighbors': 9}, {'n_neighbors': 10}], 'split0_test_score': array([0.93333333, 0.96666667, 0.96666667, 0.96666667, 0.96666667,
0.96666667, 0.96666667, 0.96666667, 0.96666667, 0.96666667]), 'split1_test_score': array([0.96666667, 0.96666667, 0.96666667, 0.96666667, 0.96666667,
0.96666667, 0.96666667, 0.96666667, 0.96666667, 0.96666667]), 'split2_test_score': array([0.93333333, 0.9 , 0.93333333, 1. , 0.93333333,
1. , 0.93333333, 1. , 0.96666667, 0.96666667]), 'split3_test_score': array([0.9 , 0.9 , 0.9 , 0.86666667, 0.93333333,
0.9 , 0.9 , 0.93333333, 0.9 , 0.93333333]), 'split4_test_score': array([1. , 1. , 1. , 0.96666667, 1. ,
1. , 1. , 0.96666667, 1. , 0.96666667]), 'mean_test_score': array([0.94666667, 0.94666667, 0.95333333, 0.95333333, 0.96 ,
0.96666667, 0.95333333, 0.96666667, 0.96 , 0.96 ]), 'std_test_score': array([0.03399346, 0.04 , 0.03399346, 0.04521553, 0.02494438,
0.03651484, 0.03399346, 0.02108185, 0.03265986, 0.01333333]), 'rank_test_score': array([10, 9, 6, 6, 3, 1, 6, 1, 3, 3])}
预测: [2]
四、总结
本文写了机器学习中的一个小部分《模型选择与参数调优》,模型的选择,划分是由交叉验证决定,参数调优则是由超参数搜索相关api得到属性,查看属性后可以看的最优参数,超参数搜索的实现为我们节省了大量测试时间、提高了运行效率。