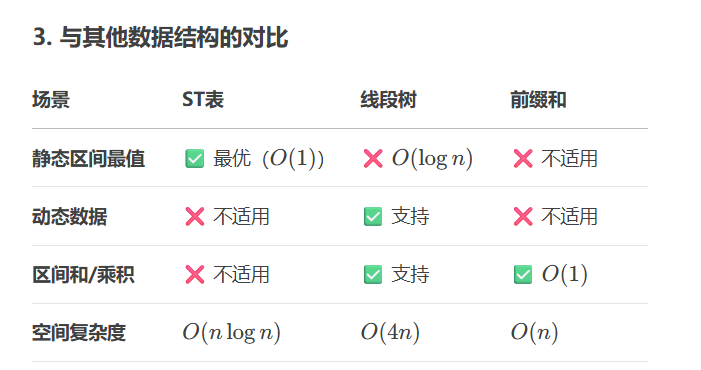
ST表——算法的优化
定义

ST表,又名稀疏表,是一种基于倍增思想,用于解决可重复贡献问题的数据结构

(了解)倍增思想:倍增思想是一种通过逐步翻倍的方式,将复杂问题分解为多个可重复利用的子问题,从而高效解决特定类型问题的算法设计策略。其核心在于利用二进制分解或幂次跳跃,将线性步骤压缩为对数级别,广泛应用于预处理、查询优化和动态规划等场景。
1. 适用场景
(1)静态数据
-
数据不可修改:ST表适用于数据固定、无频繁更新的场景(如离线查询)。
-
多次查询:若需要多次区间查询(如 105 次查询),ST表的 O(1) 查询效率优势显著。
(2)可重复贡献问题
-
操作满足结合律且可重叠计算:
ST表要求区间操作的结果可以通过重叠的子区间推导得出。典型操作包括:-
最大值/最小值(RMQ)
-
最大公约数(GCD)
-
按位与(Bitwise AND)、按位或(Bitwise OR)
-
区间覆盖(如“区间内是否存在特定值”)
-
(3)空间复杂度可接受
-
预处理需要 O(nlogn)的空间,适用于数据规模中等的情况(如 n≤106n≤106)。
2. 不适用场景
(1)动态数据
-
若数据需要频繁修改(如单点更新、区间更新),需选择线段树或树状数组。
(2)不可重复贡献的操作
-
依赖非重叠区间的操作无法使用ST表,例如:
-
区间和、区间乘积(需用前缀和)
-
区间众数、中位数
-
统计类操作(如不同元素数量)
-
(3)对空间敏感的场景
-
若数据规模极大(如 n≥107),ST表的 O(nlogn) 空间可能超出内存限制。
通俗一点来讲就是ST表适合用于给定数据的查询,给定的数据不能改变 ,否则就不能使用ST表,而是选择线段树。
ST表的优缺点(可不看)
ST表的优点
1. 极快的查询速度
-
时间复杂度:每次查询仅需 O(1) 时间。
通过预处理不同长度的区间块,任意查询区间可被拆分为两个预处理的块,合并结果即可得到答案。 -
适用场景:适合高并发查询(如 105次查询),显著优于线段树的 O(logn) 查询。
2. 实现简单
-
预处理逻辑清晰:仅需两层循环即可完成预处理。
-
代码简洁:相比线段树的递归或迭代实现,ST表更易编写和调试。
3. 支持可重复贡献操作
-
适用操作:最大值、最小值、GCD、按位与/或等。
max(a,max(b,c))=max(max(a,b),c)
这些操作的结果可通过重叠区间推导,满足结合律,例如:
4. 预处理时间可接受
-
时间复杂度:O(nlogn)。
对于 n≤106,预处理时间通常在合理范围内(如 106×20≈2×107 次操作)。
ST表的缺点
1. 不支持动态更新
-
静态数据限制:若数据发生修改(如单点更新),需重新预处理,时间复杂度为 O(nlogn)。
动态场景下应选择线段树(O(logn)更新)或树状数组。
2. 空间开销较高
-
空间复杂度:O(nlogn)。
例如 n=106时,需存储 106×20≈2×107个值(约80MB)。
相比之下,前缀和仅需 O(n)空间。
3. 适用范围有限
-
仅支持可重复贡献操作:
无法处理区间和、区间乘积等非可重复贡献操作(结果依赖非重叠区间)。
此类问题需改用前缀和或线段树。
4. 预处理常数较大
-
内存访问模式:二维数组的跳跃访问可能导致缓存不友好,实际运行时间可能略高于理论值。
ST表的基本模板:
# define MAX0 16+1 //log(n)+1
int a[100006][MAX0]; //ST表
int Log[100006]; //方便查询,避免多次判断区间距离是2的几次方
初始化Log: (其实这个可以不要,只是在查询的时候方便一点)
//初始化Log
void Chulog() {Log[1] = 0;//个数为1时,在数组的第1行,及a[][0]Log[2] = 1;//个数为2时,在数组的第2行,及a[][1]for (int i = 3; i <= n;i++){Log[i] = Log[i>>1] + 1;/*Logn[i] = Logn[i / 2] + 1 的 加1 是为了将 i 的二进制位数(或对数值)与其半数 i / 2 的对应值关联起来确保正确计算每个 i 的最大满足 2 ^ k ≤ i 的整数 k *///不懂的时候可以举几个数看看(只可意会不可言说)}
}初始化ST表 :
//初始化ST表
void ChuST() {//st[i][j]表示的是以i为起点,长度为2^j的区间的最值//外层循环遍历的是长度的指数,内层循环遍历的是起点 for (int i = 1; i<=Log[n]; i++) {//结束点n最大的倍数for (int j = 1; j + (1 << i) - 1 <= n; j++) {//结束点是 j + (1 << i) - 1 <= n,就是区间的最右端不能超过na[j][i] = max(a[j][i - 1], a[j + (1 << (i - 1))][i - 1]);//取两个 2^n-1倍 的max比较得2^n倍的max}}
}查询:
int l,r;for (int i = 1; i <= m; i++) {cin >> l >> r;int j = Log[r - l + 1];printf("%d\n", max(a[l][j], a[r - (1 << j) + 1][j]));//l - l+i<<j区间 和 r - (1 << j) + 1] - r区间取最大值}例题:
A - ST 表 && RMQ 问题(基本)
背景
这是一道 ST 表经典题——静态区间最大值
请注意最大数据时限只有 0.8s,数据强度不低,请务必保证你的每次查询复杂度为 O(1)O(1)。若使用更高时间复杂度算法不保证能通过。
如果您认为您的代码时间复杂度正确但是 TLE,可以尝试使用快速读入:
inline int read()
{int x=0,f=1;char ch=getchar();while (ch<'0'||ch>'9'){if (ch=='-') f=-1;ch=getchar();}while (ch>='0'&&ch<='9'){x=x*10+ch-48;ch=getchar();}return x*f;
}
函数返回值为读入的第一个整数。
快速读入作用仅为加快读入,并非强制使用。
描述
给定一个长度为 N 的数列,和 M 次询问,求出每一次询问的区间内数字的最大值。
输入
第一行包含两个整数 N,M,分别表示数列的长度和询问的个数。
第二行包含 N 个整数(记为 aiai),依次表示数列的第 ii 项。
接下来 MM 行,每行包含两个整数 li,ri,表示查询的区间为 [li,ri]。
输出
输出包含 M 行,每行一个整数,依次表示每一次询问的结果。
样本 1
| 输入复制 | 输出复制 |
|---|---|
8 8
9 3 1 7 5 6 0 8
1 6
1 5
2 7
2 6
1 8
4 8
3 7
1 8 | 9
9
7
7
9
8
7
9 |
提示
对于 30%30% 的数据,满足 1≤N,M≤10。
对于 70%70% 的数据,满足 1≤N,M≤105。
对于 100%100% 的数据,满足 1≤N≤105,1≤M≤2×106,ai∈[0,109],1≤li≤ri≤N。
思路:十分板正的一个ST表板题,就是去求区间内的一个最大值
#define _CRT_SECURE_NO_WARNINGS
#include<stdio.h>
#include<iostream>
#include<bits/stdc++.h>
using namespace std;
# define MAX0 16+1 //log(n)+1
int a[100006][MAX0]; //ST表
int Log[100006]; //方便查询,避免多次判断区间距离是2的几次方
int n, m;
//初始化Log
void Chulog() {Log[1] = 0;//个数为1时,在数组的第1行,及a[][0]Log[2] = 1;//个数为2时,在数组的第2行,及a[][1]for (int i = 3; i <= n;i++){Log[i] = Log[i>>1] + 1;/*Logn[i] = Logn[i / 2] + 1 的 加1 是为了将 i 的二进制位数(或对数值)与其半数 i / 2 的对应值关联起来确保正确计算每个 i 的最大满足 2 ^ k ≤ i 的整数 k *///不懂的时候可以举几个数看看(只可意会不可言说)}
}
//初始化ST表
void ChuST() {//st[i][j]表示的是以i为起点,长度为2^j的区间的最值//外层循环遍历的是长度的指数,内层循环遍历的是起点 for (int i = 1; i<=Log[n]; i++) {//结束点n最大的倍数for (int j = 1; j + (1 << i) - 1 <= n; j++) {//结束点是 j + (1 << i) - 1 <= n,就是区间的最右端不能超过na[j][i] = max(a[j][i - 1], a[j + (1 << (i - 1))][i - 1]);//取两个 2^n-1倍 的max比较得2^n倍的max}}
}
inline int read(){int x = 0, f = 1; char ch = getchar();while (ch < '0' || ch>'9') { if (ch == '-') f = -1; ch = getchar(); }while (ch >= '0' && ch <= '9') { x = x * 10 + ch - 48; ch = getchar(); }return x * f;
}
int main(){ios::sync_with_stdio(false); // 禁用同步cin.tie(nullptr); // 解除cin与cout绑定int j = 0;int p = 1;n = read();m = read();Chulog();for (int i = 1; i <= n; i++) {a[i][0]=read();}ChuST();int x, y;for (int i = 1; i <= m; i++) {x = read();y = read();int j = Log[y - x + 1];printf("%d\n", max(a[x][j], a[y - (1 << j) + 1][j]));}return 0;
}B - Balanced Lineup G
题目描述
A 国正在开展一项伟大的计划 —— 国旗计划。这项计划的内容是边防战士手举国旗环绕边境线奔袭一圈。这项计划需要多名边防战士以接力的形式共同完成,为此,国土安全局已经挑选了 N 名优秀的边防战士作为这项计划的候选人。
A 国幅员辽阔,边境线上设有 M 个边防站,顺时针编号 1 至 M。每名边防战士常驻两个边防站,并且善于在这两个边防站之间长途奔袭,我们称这两个边防站之间的路程是这个边防战士的奔袭区间。N 名边防战士都是精心挑选的,身体素质极佳,所以每名边防战士的奔袭区间都不会被其他边防战士的奔袭区间所包含。
现在,国土安全局局长希望知道,至少需要多少名边防战士,才能使得他们的奔袭区间覆盖全部的边境线,从而顺利地完成国旗计划。不仅如此,安全局局长还希望知道更详细的信息:对于每一名边防战士,在他必须参加国旗计划的前提下,至少需要多少名边防战士才能覆盖全部边境线,从而顺利地完成国旗计划。
输入格式
第一行,包含两个正整数 N,M,分别表示边防战士数量和边防站数量。
随后 N 行,每行包含两个正整数。其中第 i 行包含的两个正整数 Ci、Di 分别表示 i 号边防战士常驻的两个边防站编号,Ci 号边防站沿顺时针方向至 Di 号边防站力他的奔袭区间。数据保证整个边境线都是可被覆盖的。
输出格式
输出数据仅 1 行,需要包含 N 个正整数。其中,第 j 个正整数表示 j 号边防战士必须参加的前提下至少需要多少名边防战士才能顺利地完成国旗计划。
输入输出样例
输入 #1复制
4 8 2 5 4 7 6 1 7 3
输出 #1复制
3 3 4 3
说明/提示
N⩽2×105,M<109,1⩽Ci,Di⩽M。
思路:
就是使用两个ST表,一个min,一个max然后相减得结果
#define _CRT_SECURE_NO_WARNINGS
#include<stdio.h>
#include<iostream>
#include<bits/stdc++.h>
using namespace std;
# define MAX0 16+1
int a[100006][MAX0];
int Log[100006];
int n, m;
void Chulog() {Log[1] = 0;Log[2] = 1;for (int i = 3; i <= n; i++) {Log[i] = Log[i >> 1] + 1;}
}
void ChuST() {for (int i = 1; i <= Log[n]; i++) {for (int j = 1; j + (1 << i) - 1 <= n; j++) {a[j][i] = min(a[j][i - 1], a[j + (1 << (i - 1))][i - 1]);}}
}
int main() {ios::sync_with_stdio(false); // 禁用同步cin.tie(nullptr); // 解除cin与cout绑定int j = 0;int p = 1;cin >> n >> m;Chulog();for (int i = 1; i <= n; i++) {cin >> a[i][0];}ChuST();int x, y;for (int i = 1; i+m-1 <= n; i++) {int x = i, y = i + m - 1;int j = Log[y - x + 1];cout << min(a[x][j], a[y - (1 << j) + 1][j]) << endl;}return 0;
}C - 质量检测
Description
为了检测生产流水线上总共 N 件产品的质量,我们首先给每一件产品打一个分数 A 表示其品质,然后统计前 MM 件产品中质量最差的产品的分值 Q[m]=min{A1,A2,...Am},以及第 2 至第 M+1件的 Q[m+1],Q[m+2]… 最后统计第 N−M+1 至第 N 件的 Q[n]。根据 Q 再做进一步评估。
请你尽快求出 Q 序列。
Input
输入共两行。
第一行共两个数 N、M,由空格隔开。含义如前述。
第二行共 NN 个数,表示 N件产品的质量。
Output
输出共 N−M+1 行。
第 1 至 N−M+1行每行一个数,第 ii 行的数 Q[i+M−1]。含义如前述。
Sample 1
| Inputcopy | Outputcopy |
|---|---|
10 4 16 5 6 9 5 13 14 20 8 12 | 5 5 5 5 5 8 8 |
Hint
[数据范围]
对于 30%30% 的数据,N≤1000。
对于 100%100% 的数据,M≤N≤100000,Ai≤1000000。
思路:这题是ST表思路可以做,可能有人和我想的一样用单调队列来做,但好像会超时O(n^2)
#define _CRT_SECURE_NO_WARNINGS
#include<stdio.h>
#include<iostream>
#include<bits/stdc++.h>
using namespace std;
# define MAX0 16+1
int a[100006][MAX0];
int Log[100006];
int n, m;
void Chulog() {Log[1] = 0;Log[2] = 1;for (int i = 3; i <= n; i++) {Log[i] = Log[i >> 1] + 1;}
}
void ChuST() {for (int i = 1; i <= Log[n]; i++) {for (int j = 1; j + (1 << i) - 1 <= n; j++) {a[j][i] = min(a[j][i - 1], a[j + (1 << (i - 1))][i - 1]);}}
}
int main() {ios::sync_with_stdio(false); // 禁用同步cin.tie(nullptr); // 解除cin与cout绑定int j = 0;int p = 1;cin >> n >> m;Chulog();for (int i = 1; i <= n; i++) {cin >> a[i][0];}ChuST();int x, y;for (int i = 1; i+m-1 <= n; i++) {int x = i, y = i + m - 1;int j = Log[y - x + 1];cout << min(a[x][j], a[y - (1 << j) + 1][j]) << endl;}return 0;
}