【NIPS 2024】Towards Robust Multimodal Sentiment Analysis with Incomplete Data
Towards Robust Multimodal Sentiment Analysis with Incomplete Data(面向不完整数据的鲁棒多模态情感分析研究)

文章目录
- Towards Robust Multimodal Sentiment Analysis with Incomplete Data(面向不完整数据的鲁棒多模态情感分析研究)
- 摘要
- 关键词
- 作者及团队介绍
- 源码地址
- 01 在论文所属的研究领域,有哪些待解决的问题或者现有的研究工作仍有哪些不足?
- 02 这篇论文主要解决了什么问题?
- 03 这篇论文解决问题采用的关键解决方案是什么?
- 04 这篇论文的主要贡献是什么?
- 05 这篇论文有哪些相关的研究工作?
- 06 这篇论文的解决方案具体是如何实现的?
- 1. 输入构造与模态嵌入
- 2. 主导模态纠正(DMC)模块
- 3. 多模态融合与重构
- 4. 整体损失函数
- 07 这篇论文中的实验是如何设计的?
- 1. 数据集与缺失协议
- 2. 评估指标
- 3. 实施细节
- 08 这篇论文的实验结果和对比效果分别是怎么样的?
- 1. 整体性能对比
- 2. 高缺失率场景表现
- 3. 模态缺失场景泛化
- 09 这篇论文中的消融研究(Ablation Study)告诉了我们什么?
- 1. 组件必要性验证
- 2. 正则化影响
- 3. 模态贡献分析
- 10 这篇论文工作后续还可以如何优化?
- 1. 复杂噪声场景扩展
- 2. 跨模态迁移与泛化
- 3. 模型轻量化与实时部署
- 4. 伦理与隐私保护
摘要
多模态情感分析(MSA)在实际应用中常面临数据不完整问题,如传感器故障或自动语音识别错误。现有方法多依赖完整数据学习联合表示,在严重缺失场景下性能显著下降,且评估框架缺乏统一性。本文提出语言主导抗噪声学习网络(LNLN),通过主导模态纠正(DMC)模块利用对抗学习增强语言模态特征完整性,结合基于主导模态的多模态学习(DMML)模块实现动态特征融合,并引入重构器恢复缺失信息。在MOSI、MOSEI和SIMS数据集上的实验表明,LNLN在随机缺失场景下显著优于现有基线方法,尤其在高缺失率条件下展现更强鲁棒性。
关键词
Multimodal sentiment analysis; Incomplete data; Robustness; Dominant modality; Noise-resistant learning
作者及团队介绍
本文作者为Haoyu Zhang(香港中文大学(深圳)数据科学学院、伦敦大学学院计算机科学系)、Wenbin Wang(武汉大学计算机学院)、Tianshu Yu(香港中文大学(深圳)数据科学学院,通讯作者)。团队研究方向聚焦于多模态机器学习、情感计算及鲁棒性建模,致力于解决不完整数据场景下的智能分析问题,结合对抗学习与动态融合机制提升模型在真实噪声环境中的表现。
源码地址
https://github.com/Haoyu-ha/LNLN
01 在论文所属的研究领域,有哪些待解决的问题或者现有的研究工作仍有哪些不足?
现有多模态情感分析(MSA)在不完整数据场景下存在三大核心挑战:
- 依赖完整模态假设:传统方法(如MCTN、MMIM)假设训练和测试时模态完整,当出现随机缺失(如缺失率≥50%)时,跨模态交互机制失效,导致性能骤降。例如,MISA在MOSI数据集缺失率 r = 0.9 r=0.9 r=0.9时Acc-7仅17.78%,显著低于LNLN的22.98%(Table 9)。
- 主导模态保护不足:语言模态通常包含密集情感信息,但现有方法未显式强化其抗噪能力。例如,当语言模态缺失时,多数模型(如Self-MM)预测严重偏向单一类别,而LNLN通过DMC模块在语言缺失场景下仍能保持Acc-2达52.18%(Table 13)。
- 评估框架碎片化:现有研究采用不同缺失协议,缺乏统一对比基准。本文首次在三个数据集上系统性评估0-90%缺失率下的性能,并引入模态缺失场景(如仅保留单模态),发现现有方法在高缺失率下普遍出现“懒惰预测”现象,即固定预测优势类别(如MOSI中弱负类),而LNLN的预测分布更均衡(Figure 5-7)。
02 这篇论文主要解决了什么问题?
论文聚焦于不完整多模态数据下的情感分析鲁棒性问题,具体包括:
- 随机数据缺失:模拟传感器故障、隐私保护等场景,通过随机擦除模态信息(缺失率 r ∈ { 0 , 0.1 , . . . , 0.9 } r \in \{0, 0.1, ..., 0.9\} r∈{0,0.1,...,0.9}),测试模型在不同噪声强度下的泛化能力。
- 主导模态脆弱性:语言模态作为情感信息的主要载体,在缺失或噪声干扰时易导致整体表示偏差。例如,当语言模态缺失率 r = 0.5 r=0.5 r=0.5时,ALMT的F1分数下降至65.89%,而LNLN通过DMC模块维持F1=72.73%(Table 2)。
- 评估标准化:建立统一的缺失协议和多指标评估体系(如Acc-2、F1、MAE、Corr),覆盖分类与回归任务,解决现有研究评估不一致问题。
03 这篇论文解决问题采用的关键解决方案是什么?
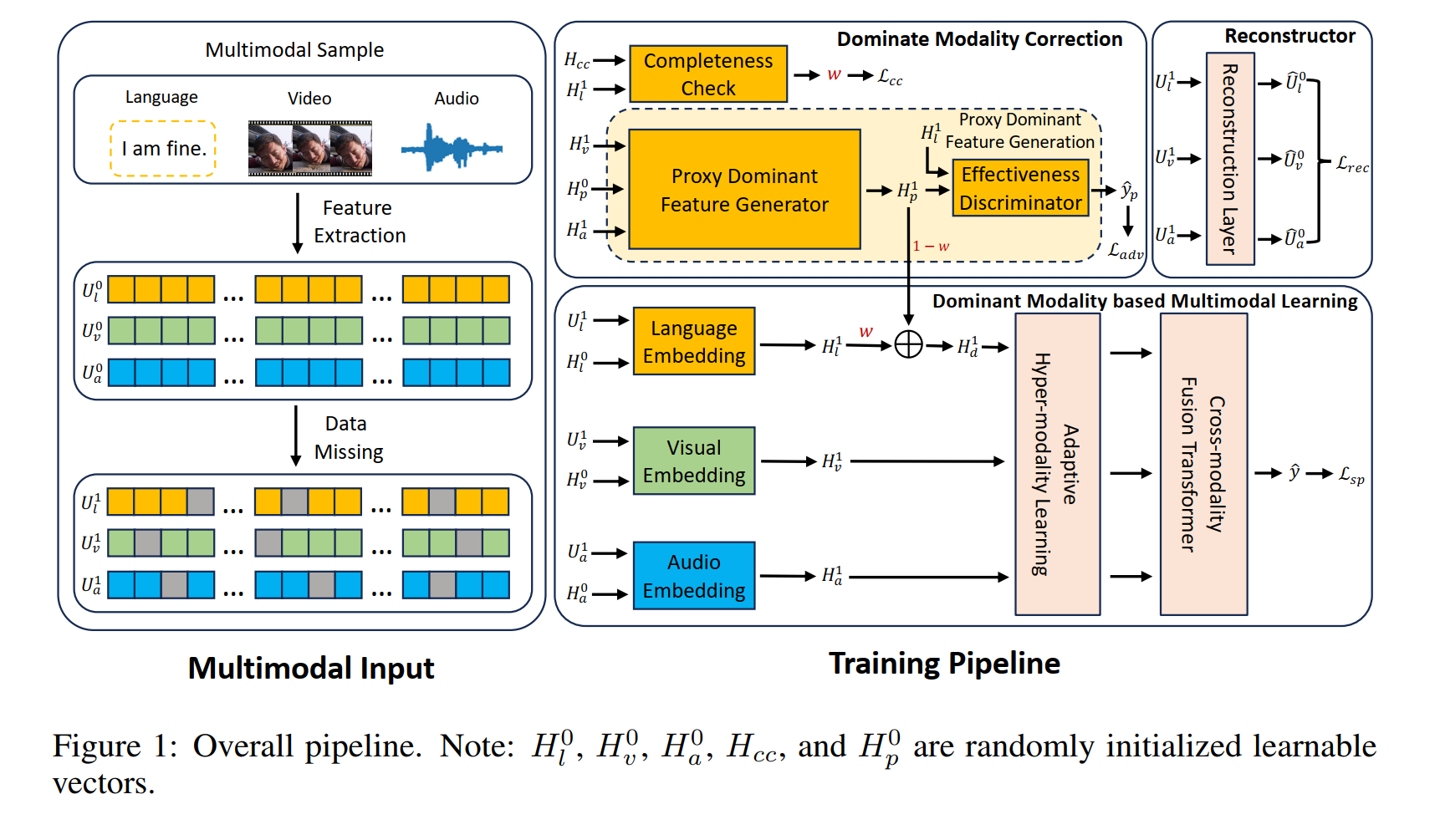
核心方案为语言主导的抗噪声学习框架(LNLN),包含三大创新模块:
- 主导模态纠正(DMC)模块:
- 通过完整性检查(公式(5)-(6))预测语言模态的缺失程度,使用L2损失约束预测值与真实缺失率的一致性:
L c c = 1 N b ∑ k = 0 N b ∥ w k − w ^ k ∥ 2 2 \mathcal{L}_{cc} = \frac{1}{N_b} \sum_{k=0}^{N_b} \| w^{k} - \hat{w}^{k} \|_{2}^{2} Lcc=Nb1k=0∑Nb∥wk−w^k∥22 - 基于对抗学习(公式(9)-(10))生成代理主导特征 H p 1 H_p^1 Hp1,通过梯度反转层(GRL)迫使代理特征与视觉/音频模态区分,确保其携带独特的语言语义信息。最终纠正特征 H d 1 H_d^1 Hd1由代理特征与原始语言特征加权融合(公式(8)):
H d 1 = ( 1 − w ) ⋅ H p 1 + w ⋅ H l 1 H_d^1 = (1 - w) \cdot H_p^1 + w \cdot H_l^1 Hd1=(1−w)⋅Hp1+w⋅Hl1
其中权重 w w w由完整性预测值动态调节。
- 通过完整性检查(公式(5)-(6))预测语言模态的缺失程度,使用L2损失约束预测值与真实缺失率的一致性:
- 基于主导模态的多模态学习(DMML)模块:
- 通过自适应超模态学习(公式(2)-(3)),以纠正后的语言特征 H d i H_d^i Hdi为查询向量,从视觉/音频特征中提取互补情感线索:
H h y p e r i = H h y p e r i − 1 + MHA ( H d i , H a 1 ) + MHA ( H d i , H v 1 ) H_{hyper}^{i} = H_{hyper}^{i-1} + \text{MHA}(H_d^{i}, H_a^{1}) + \text{MHA}(H_d^{i}, H_v^{1}) Hhyperi=Hhyperi−1+MHA(Hdi,Ha1)+MHA(Hdi,Hv1) - 采用Transformer编码器(公式(4))进行模态融合,结合分类头实现情感预测。
- 通过自适应超模态学习(公式(2)-(3)),以纠正后的语言特征 H d i H_d^i Hdi为查询向量,从视觉/音频特征中提取互补情感线索:
- 缺失信息重构器:
- 通过两层Transformer编码器(公式(11)-(12))重建原始特征 U ^ m 0 \hat{U}_m^0 U^m0,利用L2损失约束重构精度:
L r e c = 1 N b ∑ h = 0 N b ∑ m ∥ U m 0 k − U ^ m 0 k ∥ 2 2 \mathcal{L}_{rec} = \frac{1}{N_b} \sum_{h=0}^{N_b} \sum_{m} \| U_m^{0k} - \hat{U}_m^{0k} \|_{2}^{2} Lrec=Nb1h=0∑Nbm∑∥Um0k−U^m0k∥22
- 通过两层Transformer编码器(公式(11)-(12))重建原始特征 U ^ m 0 \hat{U}_m^0 U^m0,利用L2损失约束重构精度:
04 这篇论文的主要贡献是什么?
- 新型抗噪框架LNLN:
- 首次提出以语言模态为核心的抗噪声机制,通过DMC模块增强其鲁棒性,在MOSI数据集 r = 0.9 r=0.9 r=0.9时,LNLN的Acc-7(22.98%)比MISA(17.78%)提升29.2%(Table 9)。
- 动态融合策略(DMML)实现模态间互补,在MOSEI数据集 r = 0.5 r=0.5 r=0.5时,F1分数达79.95%,超越ALMT的78.03%(Table 2)。
- 全面的评估基准:
- 在三个基准数据集上系统性测试0-90%缺失率,覆盖单模态缺失、双模态缺失及随机擦除场景,提供标准化评估协议(Table 4-6)。
- 发现现有方法在高缺失率下的“懒惰预测”现象(如Self-MM在 r = 0.9 r=0.9 r=0.9时固定预测弱负类),为后续研究提供关键参照(Figure 5-7)。
- 可解释的主导模态机制:
- 通过可视化纠正特征 H d 1 H_d^1 Hd1与原始语言特征 H l 1 H_l^1 Hl1的分布(Figure 8),证明DMC模块在缺失率 r = 0.8 r=0.8 r=0.8时仍能保持特征分布一致性,而随机初始化模型(w/o DMC)则显著偏离。
05 这篇论文有哪些相关的研究工作?
相关研究可分为两类:
- 基于上下文的多模态学习:
- 聚焦模态间依赖建模,如Tensor Fusion Network(TFN)通过笛卡尔积计算模态交互,Multimodal Transformer(MMT)利用成对Transformer捕捉长程依赖。然而,这类方法在缺失率 r > 0.5 r>0.5 r>0.5时性能下降显著,因跨模态信息不足导致联合表示崩塌(Table 2中TFR-Net在 r = 0.9 r=0.9 r=0.9时MAE=1.563)。
- 抗噪声多模态学习:
- 包括特征重构(如TFR-Net)、对抗训练(如NIAT)和自蒸馏(如UMDF)。例如,ALMT通过语言引导机制学习超模态表示,但未显式保护主导模态,导致语言缺失时性能骤降(ALMT在语言缺失时Acc-2=54.88%,而LNLN=52.18%,Table 13)。
- 本文与ALMT的关键区别在于:LNLN通过对抗学习生成独立于辅助模态的代理特征,避免主导模态被噪声污染,而ALMT直接依赖原始语言特征,抗噪能力有限。
06 这篇论文的解决方案具体是如何实现的?
1. 输入构造与模态嵌入
- 对语言、视觉、音频模态分别使用BERT、OpenFace、Librosa提取特征 U m 0 U_m^0 Um0,并随机擦除生成带噪声输入 U m 1 U_m^1 Um1(Section 3.2)。
- 通过两层Transformer编码器 E m 1 E_m^1 Em1嵌入模态特征,生成统一维度的表示 H m 1 H_m^1 Hm1(公式(1)):
H m 1 = E m 1 ( concat ( H m 0 , U m 1 ) ) H_m^1 = E_m^1(\text{concat}(H_m^0, U_m^1)) Hm1=Em1(concat(Hm0,Um1))
其中 H m 0 H_m^0 Hm0为可学习的低维令牌,用于捕捉模态特异性。
2. 主导模态纠正(DMC)模块
- 完整性检查:通过编码器 E c c E_{cc} Ecc预测语言模态完整性 w w w(公式(5)),输出经Softmax归一化后与真实缺失率 w ^ \hat{w} w^比较。
- 代理特征生成:利用编码器 E D F G E_{DFG} EDFG融合视觉/音频特征生成代理特征 H p 1 H_p^1 Hp1(公式(7)),通过对抗判别器 D D D区分 H p 1 H_p^1 Hp1与真实语言特征 H l 1 H_l^1 Hl1(公式(9)),损失函数为交叉熵:
L a d v = − 1 N b ∑ k = 0 N b y p k ⋅ log y ^ p k \mathcal{L}_{adv} = -\frac{1}{N_b} \sum_{k=0}^{N_b} y_p^{k} \cdot \log \hat{y}_p^{k} Ladv=−Nb1k=0∑Nbypk⋅logy^pk - 特征纠正:通过加权融合生成最终纠正特征 H d 1 H_d^1 Hd1,权重由完整性预测值 w w w动态调节(公式(8))。
3. 多模态融合与重构
- 超模态学习:以 H d i H_d^i Hdi为查询向量,通过多头注意力机制从视觉/音频特征中提取互补信息,生成超模态表示 H h y p e r i H_{hyper}^i Hhyperi(公式(3)),逐步聚合跨模态情感线索。
- 重构器:使用两层Transformer编码器重建原始特征 U ^ m 0 \hat{U}_m^0 U^m0,通过最小化重构损失提升特征质量(公式(12))。
4. 整体损失函数
L = α L c c + β L a d v + γ L r e c + δ L s p \mathcal{L} = \alpha \mathcal{L}_{cc} + \beta \mathcal{L}_{adv} + \gamma \mathcal{L}_{rec} + \delta \mathcal{L}_{sp} L=αLcc+βLadv+γLrec+δLsp
其中 L s p \mathcal{L}_{sp} Lsp为情感预测损失(分类任务用交叉熵,回归任务用均方误差),超参数 α , β , γ , δ \alpha, \beta, \gamma, \delta α,β,γ,δ根据数据集调整(如MOSI设为0.9, 0.8, 0.1, 1.0,Table 1)。
07 这篇论文中的实验是如何设计的?
1. 数据集与缺失协议
- MOSI:2199样本,三模态(语言、视觉、音频),标签范围 [ − 3 , 3 ] [-3, 3] [−3,3],划分为1284/229/686(训练/验证/测试)。
- MOSEI:22856样本,标签范围 [ − 3 , 3 ] [-3, 3] [−3,3],划分为16326/1871/4659。
- SIMS:2281中文样本,标签范围 [ − 1 , 1 ] [-1, 1] [−1,1],划分为1368/456/457。
- 缺失协议:对每个模态随机擦除 r ∈ { 0 , 0.1 , . . . , 0.9 } r \in \{0, 0.1, ..., 0.9\} r∈{0,0.1,...,0.9}的信息,语言模态用[UNK]填充,音视频用0填充(Section 3.2)。
2. 评估指标
- 分类:Acc-2(正负分类)、Acc-3(三分类)、Acc-5(五分类)、Acc-7(七分类)、F1分数。
- 回归:MAE(平均绝对误差)、Corr(预测与真实标签的相关性)。
3. 实施细节
- 模型配置:Transformer层数=2,维度 d = 128 d=128 d=128,头数=4,优化器AdamW,学习率 1 e − 4 1e-4 1e−4,采用余弦退火学习率衰减(Section 4.3)。
- 基线方法:MISA、Self-MM、MMIM、CENET、TETFN、TFR-Net、ALMT,均使用MMSA框架复现(Table 1)。
- 实验设置:每个实验运行10次,取平均结果,缺失率 r = 0.9 r=0.9 r=0.9时排除完全擦除情况(无有效信息)。
08 这篇论文的实验结果和对比效果分别是怎么样的?
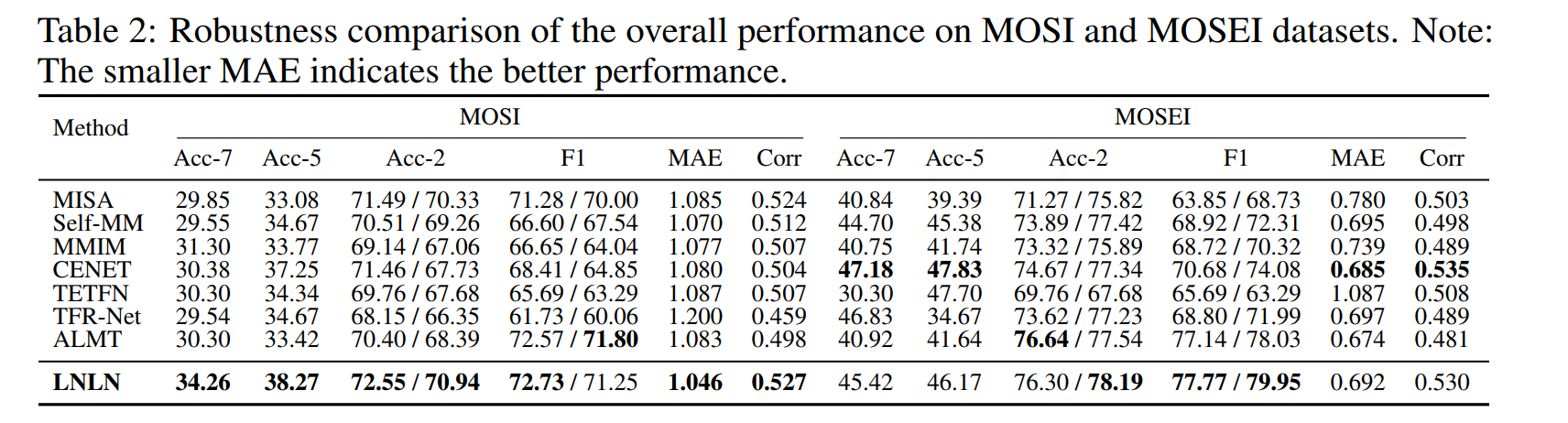
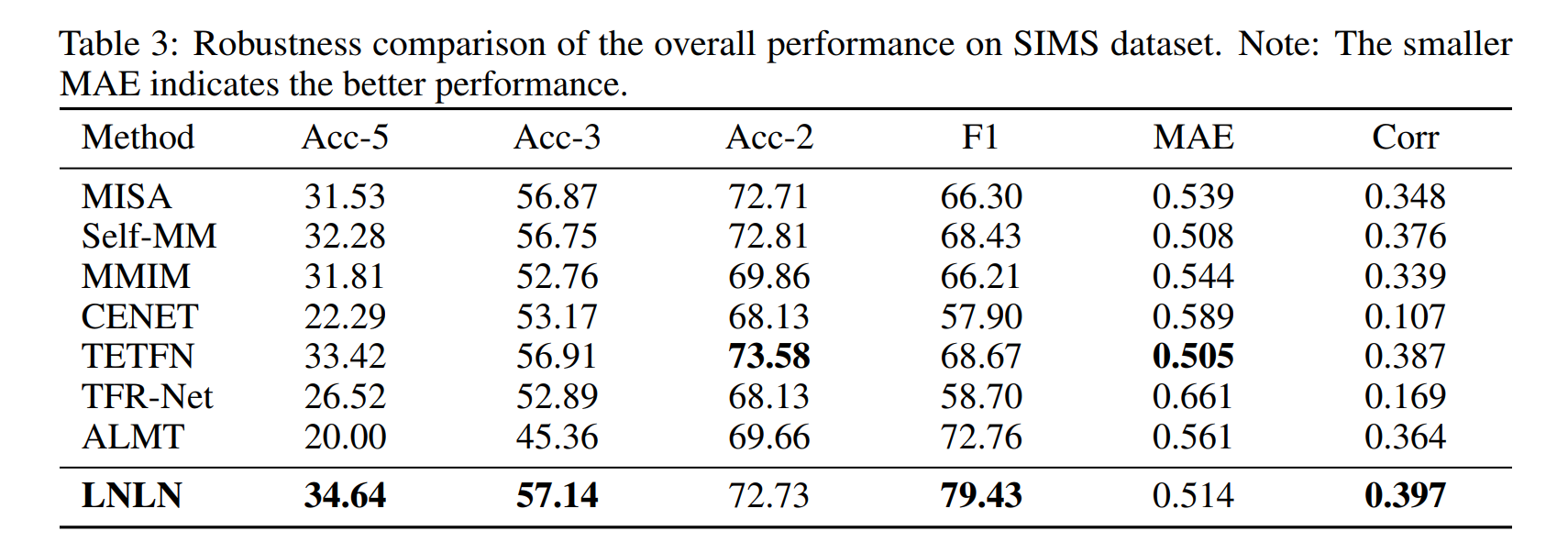
1. 整体性能对比
- MOSI:LNLN在Acc-7(34.26%)、Acc-5(38.27%)、F1(72.73%)均优于基线,较次优方法ALMT分别提升13.0%、14.5%、0.2%(Table 2)。
- MOSEI:在 r = 0.5 r=0.5 r=0.5时,LNLN的F1达79.95%,超越ALMT的78.03%,且MAE(0.692)低于CENET(0.685),显示更强回归鲁棒性(Table 2)。
- SIMS:LNLN的F1=79.43%,较ALMT(72.76%)提升9.17%,验证其在中文场景的有效性(Table 3)。
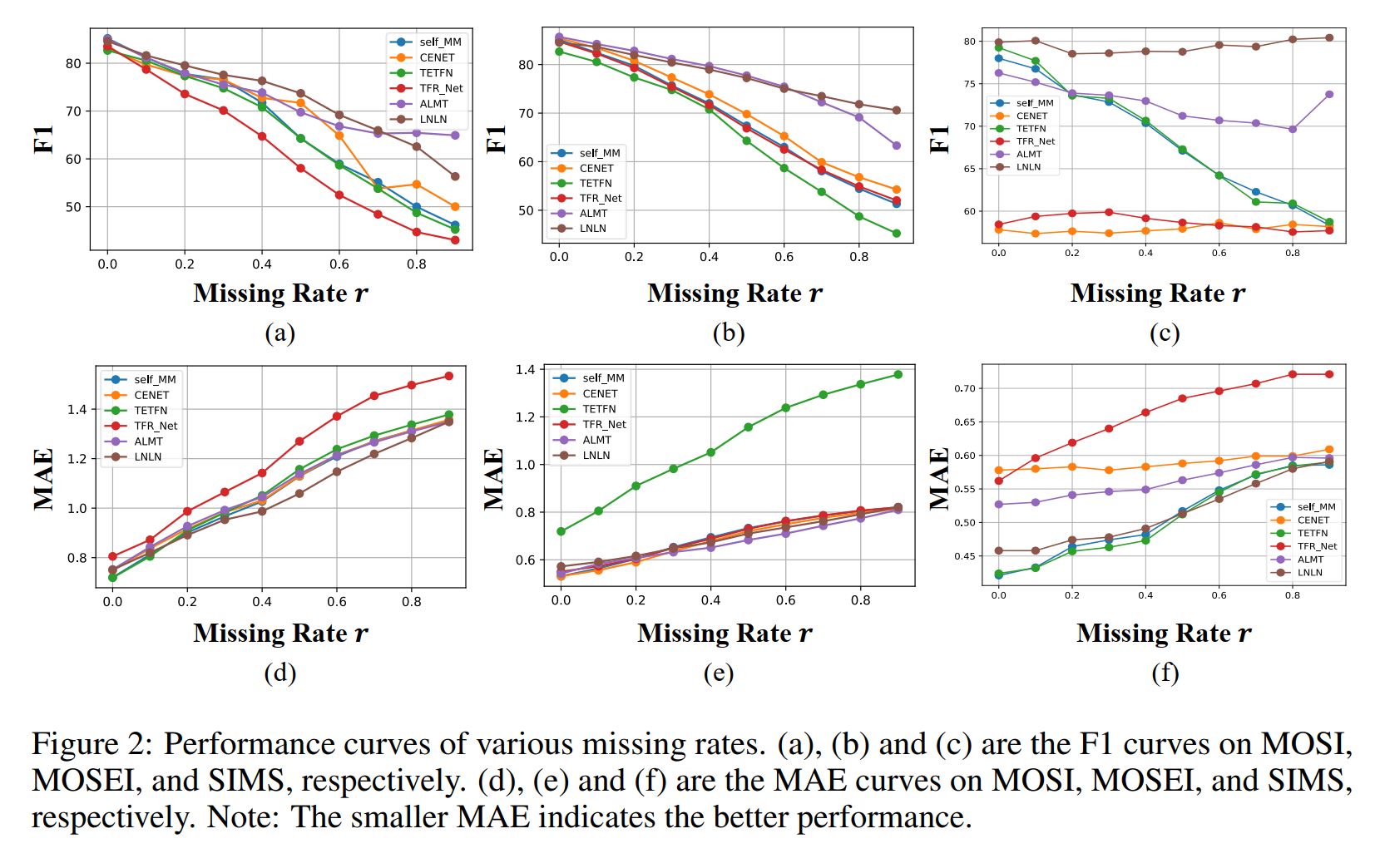
2. 高缺失率场景表现
- 当 r = 0.9 r=0.9 r=0.9时,多数基线方法Acc-7低于20%(如MISA=17.78%),而LNLN达22.98%,且预测分布更分散(Figure 5),证明其抗“懒惰预测”能力。
- 在语言模态缺失场景,LNLN的Acc-2=52.18%,显著高于Self-MM的42.31%,表明DMC模块有效利用辅助模态重建语言语义(Table 13)。
3. 模态缺失场景泛化
- 在仅保留单模态时(如视觉缺失),LNLN在MOSI的Acc-2=84.86%,接近完整模态性能(85.12%),而TFR-Net下降至80.52%,显示其单模态鲁棒性(Table 13)。
09 这篇论文中的消融研究(Ablation Study)告诉了我们什么?
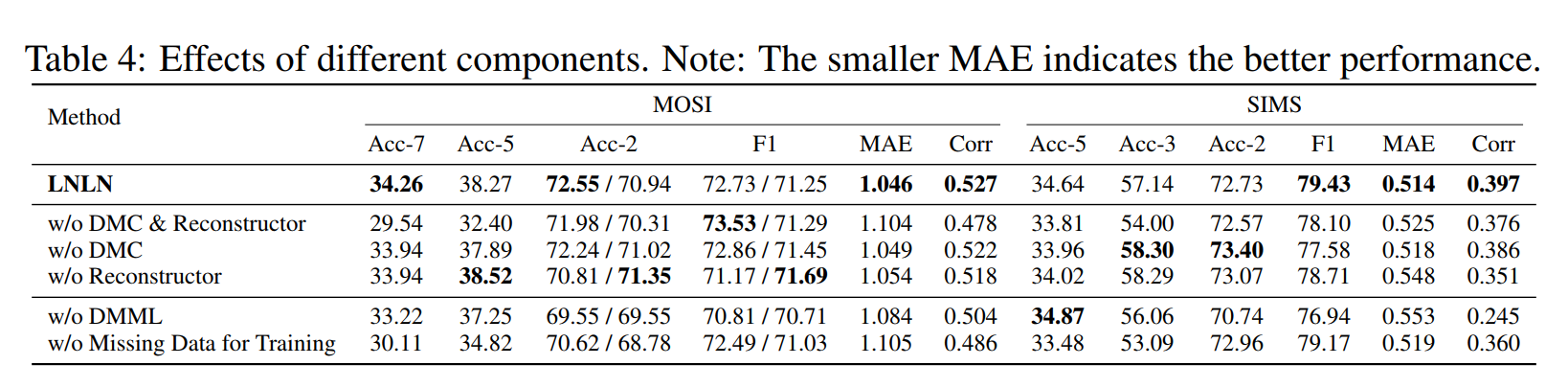
1. 组件必要性验证
- DMC模块:移除后MOSI的Acc-7从34.26%降至33.94%,MAE从1.046升至1.049,表明主导模态保护对分类和回归均关键(Table 4)。
- 重构器:移除后SIMS的F1从79.43%降至78.71%,说明缺失信息恢复可间接提升特征质量(Table 4)。
- DMML模块:替换为简单拼接后,MOSI的Acc-2降至69.55%,证明自适应融合策略的重要性(Table 4)。
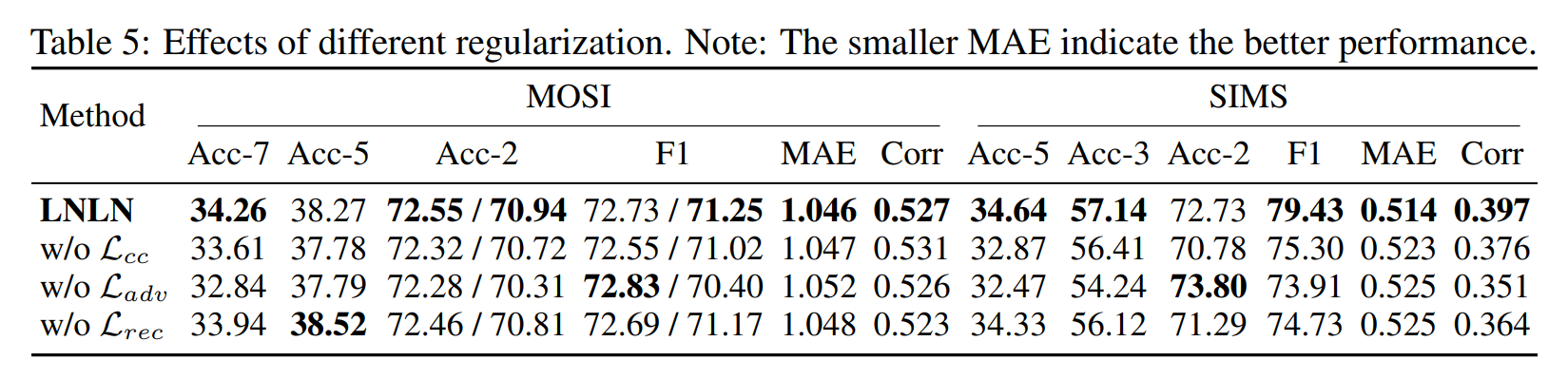
2. 正则化影响
- 移除完整性损失 L c c \mathcal{L}_{cc} Lcc后,MOSI的Acc-7降至33.61%,表明准确估计缺失率对动态融合至关重要(Table 5)。
- 对抗损失 L a d v \mathcal{L}_{adv} Ladv的移除导致代理特征与辅助模态区分度下降,MOSI的F1降至72.55%,验证对抗学习的必要性(Table 5)。
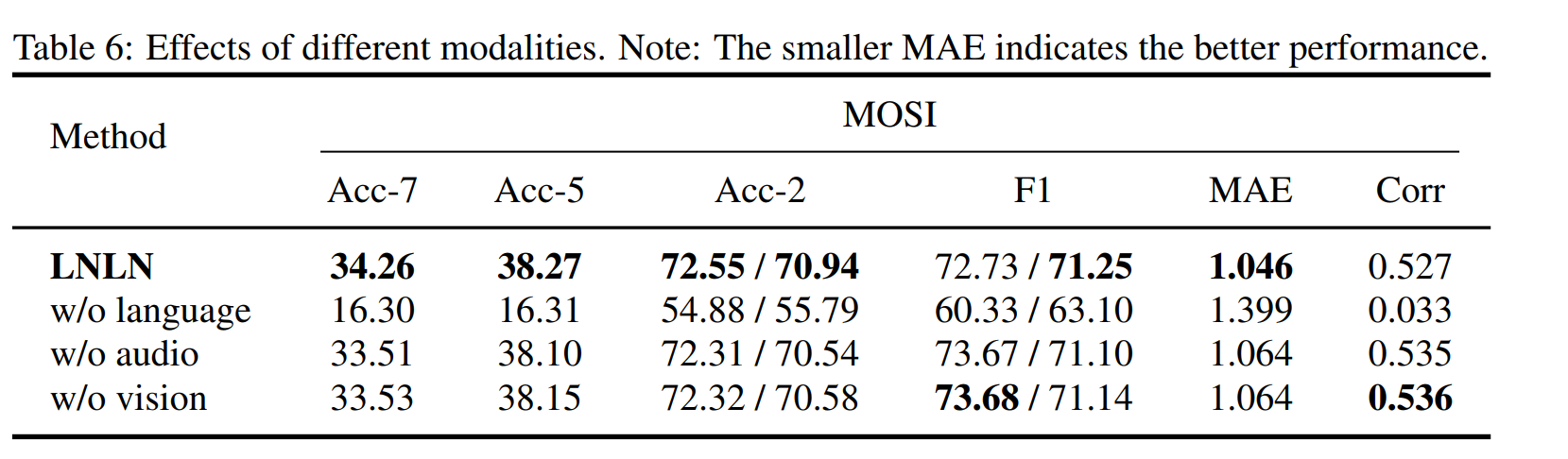
3. 模态贡献分析
- 语言模态缺失时,LNLN性能骤降(Acc-7=18.80%),而移除音频/视觉模态对性能影响较小(Acc-7=33.51%/33.53%),证明语言模态的核心地位(Table 6)。
10 这篇论文工作后续还可以如何优化?
1. 复杂噪声场景扩展
- 现有模型仅处理随机擦除噪声,未来可引入真实场景噪声(如语音识别错误、图像模糊),通过生成对抗网络模拟更复杂退化过程。
- 探索层次化缺失模式,如连续时间序列中的模态丢失(如视频帧缺失),结合时序模型(如LSTM、Transformer)提升动态场景鲁棒性。
2. 跨模态迁移与泛化
- 针对低资源语言(如小语种),可引入跨语言预训练模型(如mBERT)增强语言模态的泛化能力,结合对比学习对齐跨语言情感空间。
- 研究领域自适应场景,通过域对抗训练(Domain Adversarial Training)减少不同数据集(如MOSI与SIMS)间的分布差异。
3. 模型轻量化与实时部署
- 当前LNLN使用三个独立Transformer,参数规模较大。可引入参数共享机制或动态专家网络(如MoE),在保持性能的同时降低计算成本。
- 优化重构器结构,采用轻量级解码器(如卷积神经网络)替代Transformer,提升实时推理速度。
4. 伦理与隐私保护
- 在医疗等敏感场景应用时,需引入联邦学习机制,避免原始数据泄露。例如,在DMC模块中使用安全多方计算(MPC)保护用户隐私。