[论文品鉴] DeepSeek V3 最新论文 之 MTP
继续介绍DeepSeek最近发布的关于V3的论文【Insights into DeepSeek-V3: Scaling Challenges and Reflections on Hardware for AI Architectures】,且依然会结合年初的论文 【DeepSeek-V3 Technical Report】 一起。
下面DeepSeek-V3的这张架构图,前两篇文章已经分别介绍了 偏底层 的 MLA 和 MoE,剩下最后的一块内容就是 偏头部 的 MTP 了。
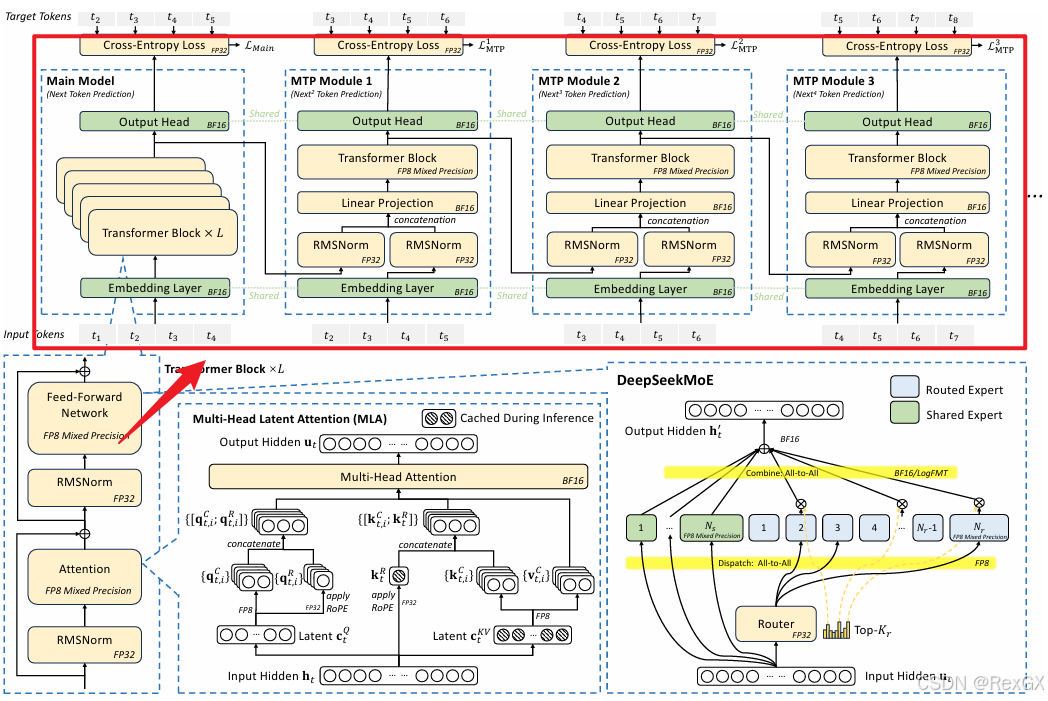
MTP
MTP(Multi-Token Prediction)多token预测,与之相对应的就是普通LLM的NTP(Next-Token Prediction),很显然MTP尝试解决的问题是一次性的预测多个token。
还是那就老话,“不是所有的牛奶都是特仑苏”,在深入 DeepSeek MTP 前,先来看看 普通的 MTP。
它的思想很简单,先看下 训练阶段,下面这张图从下往上看:
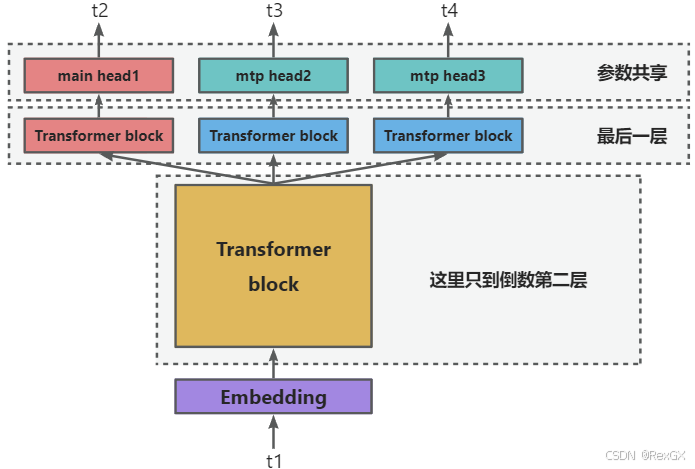
- 首先,input token t 1 t_1 t1 通过 embedding 后送入了 Transformer block,就和正常 LLM 的
NTP一样 - 但注意这里只到 倒数第二层,并非最终的输出层;且这一部分,所有输出头 共享
- 假设预测 next 3 个token
- 那么,首先会有一个 main head,它的定位和正常 LLM 的
NTP的输出头一样,输出 t 2 t_2 t2 下一个 token,也是准确率最高的 head - 同时,倒数第二层也会把数据传入 另外两个
MTP Head,去预测 t 3 、 t 4 t3、t4 t3、t4 - 这3个输出头,共享参数,在训练的时候都参与
loss计算,只不过 main head 的权重最大
再来看 推理阶段:
- 同样的,对于输入 “恒电的饭菜”,去预测下3个token
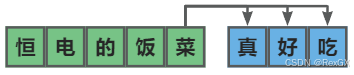
- 但由于预测的越远,预测的越不准,所以需要通过 验证 确保符合预期
- 首先, t 2 t2 t2 也就是下一个 token (“真”字)准确率最高,可以直接采纳
- 然后,看 t 3 t3 t3 的 token(“好”字),
 也可以采纳
也可以采纳 - 最后,看 t 4 t4 t4 的 token(“吃”字),
 ,个人表示完全无法接受 😃
,个人表示完全无法接受 😃 - 所以此时,虽然预测了next 3 token,但通过 验证 只采纳了 next 2 ,也就是输出为 “恒电的饭菜真好”
- 然后再作为输入,进入下一轮 MTP 递归,继续生成 next 3 token,继续 验证,直到 EOS
DeepSeek MTP
普通的 MTP 的主要问题在于:多头相互间是独立预测的,准确率低,严重依赖后期验证。
DeepSeek MTP 的解法是:给每个头传入额外的信息,帮助它们进行预测。
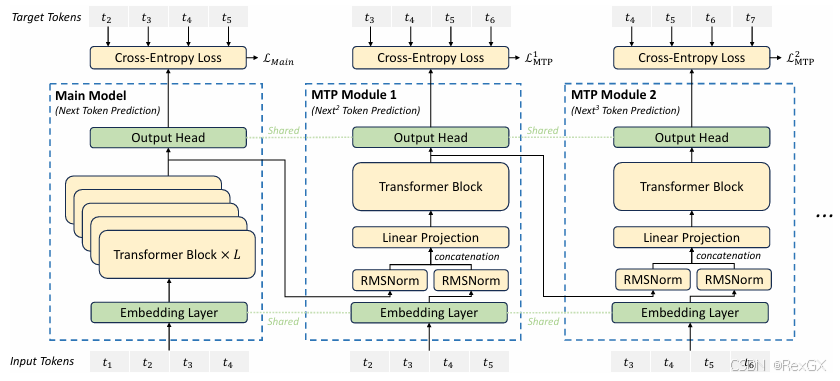
论文中的原图不太容易理解,可以看我的这张图(再和上面普通MTP对比着看):
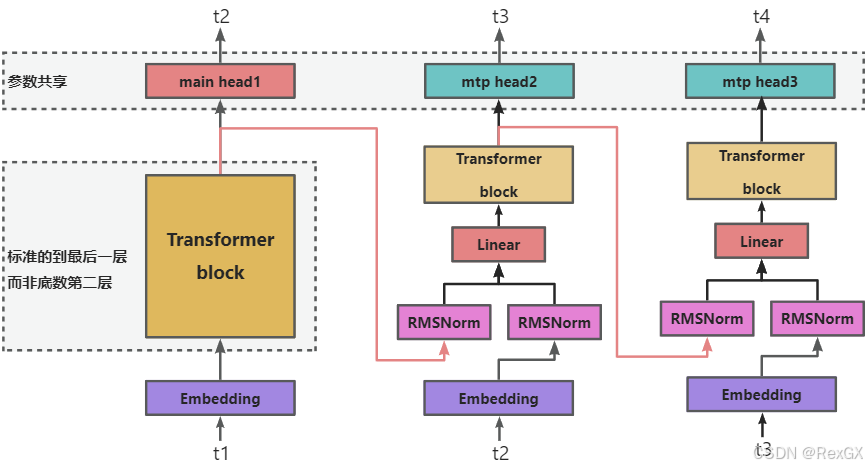
- 首先,和普通
MTP最大的不同是,input token t 1 t1 t1 会经过main head这个头的完整的 transformer block 输出 token t 2 t2 t2,而不是只到共享的 − 1 -1 −1 倒数第二层,再经过最后一层 - 经过完整 transformer block 输出 token t 2 t2 t2 的特征,会作为
mtp head的一分部输入 - 再结合 token t 2 t2 t2 本身经过 embedding 后 的输入
- 进入一个线性层,进行 降维,然后进入 这个
mtp head自己的 transformer block 进行 t 3 t3 t3 的预测 - 同样的,
MTP head的预测结果,也参与loss计算
所以,通过 传入上一个head用于预测的特征,可以 帮助下一个head去预测下一个token,预测的会更准确。
同时,对于 DeepSeek MTP 首先需要强调一点的是,DeepSeek MTP 只用于 训练阶段 去提高 main model 的性能,所以在 推理阶段,完全舍弃掉了 MTP。

以上,介绍了普通 MTP,以及 DeepSeek MTP ,下一篇继续介绍另外一块重要内容 FP8混合精度训练。