【第三十七周】SigLip:Sigmoid Loss for Language Image Pre-Training
SigLip
- 摘要
- Abstract
- 文章信息
- 引言
- 方法
- Softmax 损失
- Sigmoid 损失
- Siglip的分块收集策略
- 实验与结果
- 总结
摘要
SigLIP 是一种针对语言–图像预训练的新型方法,它用简单的成对 Sigmoid 损失取代传统的 Softmax(InfoNCE)损失,从而将批次大小与损失计算解耦,显著降低了跨设备通信与内存开销 。该方法首先将图像与文本分别通过独立编码器提取并归一化特征,再应用可学习的温度与偏置计算每对图文样本的点积 logits,最后对所有正负样本对执行二分类交叉熵损失,这种设计既保证了在小批次时训练的稳定性,也能高效扩展至高批次规模。关键技术还包括冻结视觉编码器的 Locked-image Tuning、对大批次进行分块(chunked)损失计算以便分布式训练。然而,由于缺少全局负样本归一化,SigLIP 在极端大批次下性能提升趋于饱和,可能无法充分利用全局负样本结构。
Abstract
SigLIP is a novel approach to vision–language pretraining that replaces the traditional Softmax (InfoNCE) loss with a simple pairwise Sigmoid loss, thereby decoupling batch size from loss computation and greatly reducing cross-device communication and memory overhead. The method first extracts and normalizes features from images and text using separate encoders, then applies learnable temperature and bias to compute the dot-product logits for each image–text pair, and finally applies a binary cross-entropy loss over all positive and negative pairs; this design ensures stable training at small batch sizes while allowing efficient scaling to very large batches. Key techniques also include Locked-image Tuning, which freezes the visual encoder, and a chunked loss computation strategy that enables distributed training with minimal memory footprint. However, because it lacks global normalization over negative samples, SigLIP’s performance improvements plateau at extreme batch sizes, potentially underutilizing the full structure of the negative sample distribution.
文章信息
Title:Sigmoid Loss for Language Image Pre-Training
Author:Xiaohua Zhai, Basil Mustafa, Alexander Kolesnikov, Lucas Beyer
Source:https://arxiv.org/abs/2303.15343
引言
OpenAI 提出 链接: CLIP 后,对比语言图像预训练获得显著发展。CLIP 使用图像-文本对和对比损失进行网络预训练。这种方法有多个优点:
(1) 通过爬取互联网来收集图像-文本对数据集相对便宜;
(2) 它支持零样本迁移到下游任务(例如,图像分类/检索);
(3) 它的性能随模型和数据集大小而变化,即更大的网络和数据集可实现更好的性能。
但 CLIP 需要较大的批大小,且需要在批次级别上两次应用基于 Softmax 的对比损失,分别对图像和文本的相似度分数进行归一化。
本文介绍的 SigLip 提出一种更简单的替代方案:Sigmoid 损失。它无需对整个批次进行任何操作,从而极大简化了分布式损失的实现并提升了效率;此外,它从概念上将批次大小与任务定义解耦。
方法
SigLip 是Sigmoid Loss for Language Image Pre -training 的缩写。SigLIP 的核心思想是使用 Sigmoid运算而不是Softmax运算。下面先分析在语言-图像预训练中的两种损失:
Softmax 损失
CLIP 使用 Softmax 函数,因此,给定正对(图像-文本)的损失取决于小批量内的每个负对。
 其中,其中 B \mathcal{B} B 表示批大小(正对的数量), x x x 表示图像特征, y y y 示文本特征, t t t是标量温度超参数,用于控制 softmax 输出的锐度/平滑度。此式中有两个关键细节:
其中,其中 B \mathcal{B} B 表示批大小(正对的数量), x x x 表示图像特征, y y y 示文本特征, t t t是标量温度超参数,用于控制 softmax 输出的锐度/平滑度。此式中有两个关键细节:
(1)CLIP(softmax)损失是不对称的,有两项,第一项为给定的查询图像找到最佳文本匹配,而第二项为给定的查询文本找到最佳图像匹配。
(2)CLIP(softmax)损失需要一个全局归一化因子(累加计算中的分母),这会引入二次内存复杂性——具体来说,是一个NxN成对相似性矩阵。
Sigmoid 损失
相比之下,SigLIP 既不对称,也不需要全局归一化因子。因此,每对(正数和负数)的损失都与小批量内的其他对无关。 z i j = { 1 , for positive pairs. − 1 , for negative pairs. z_{ij}= \begin{cases} \quad1, & \text{for positive pairs.} \\ -1, & \text{for negative pairs.} & \end{cases} zij={1,−1,for positive pairs.for negative pairs.值得注意的是,CLIP 和 SigLIP 都计算小批量中每对(正/负)之间的相似性。然而,每个损失的内存需求都存在细微差异。使用 CLIP,每个GPU 都会为所有成对相似性维护一个NxN矩阵,以便对正对进行规范化。使用 SigLIP,无需维护 NxN 矩阵,因为每个正/负对都是独立的。
z i j = { 1 , for positive pairs. − 1 , for negative pairs. z_{ij}= \begin{cases} \quad1, & \text{for positive pairs.} \\ -1, & \text{for negative pairs.} & \end{cases} zij={1,−1,for positive pairs.for negative pairs.值得注意的是,CLIP 和 SigLIP 都计算小批量中每对(正/负)之间的相似性。然而,每个损失的内存需求都存在细微差异。使用 CLIP,每个GPU 都会为所有成对相似性维护一个NxN矩阵,以便对正对进行规范化。使用 SigLIP,无需维护 NxN 矩阵,因为每个正/负对都是独立的。
了解 CLIP 和 SigLIP 之间差异的另一种方法是检查它们的问题表述。给定一个查询图像 I,CLIP 解决一个多类分类问题,并将图像 I 分配给其对应的正文本T ,该文本 T是小批量中所有其他负文本中的文本。而 SigLIP 解决二元分类问题,匹配对 ( I , T )为正标签,其他所有对为负标签。CLIP 计算全局归一化因子(等式 1 分母),而 SigLIP 不计算。
Siglip的分块收集策略
与 CLIP 相比,SigLIP 需要的 GPU 间通信更少。CLIP 在所有 GPU 之间传递图像和文本特征,以计算NxN归一化矩阵。这需要两次全收集操作。相比之下,SigLIP 仅在所有 GPU 之间传递文本特征,以计算所有成对相似性。这只需要一次全收集操作。
然而,全收集操作仍然很昂贵,因为所有 GPU 都处于空闲状态,等待接收所有特征后再计算损失(等式 2)。想象一个分布在 256 个 GPU 上的小批量;每个 GPU 都会等到它从所有其他 255 个 GPU 接收特征后再计算损失。这需要很长的等待时间!因此,本文提出了一种高效的“分块”实现,以完全避免全收集。

举个例子,如上图,一个大小为12的mini-batch分布在3个GPU上,有12对正样本对和132对负样本(非对角线)对。每个GPU计算其设备上的mini-batch(大小为4)的损失。然后,每个GPU将其文本特征传递给一个单一的兄弟GPU。
GPU(设备)1从GPU2接收文本特征,GPU2从GPU3接收,GPU3从GPU1接收。现在,每个GPU都有了一组新的负样本对:它自己的图像特征加上来自兄弟GPU的文本特征。因此,计算出新的损失并将其累积到之前计算的损失上。SigLIP重复这两个步骤(损失计算和特征通信),直到计算出整个mini-batch的总损失。
对于每个 GPU(设备),“分块”实现可以总结如下:
- 计算其自身文本和图像特征的损失。
- 从单个兄弟 GPU接收文本特征。
- 使用其自身的图像及其同级文本特征来计算新的损失。
- 将总损失增加新计算的损失。
- 从第二步开始重复,直至所有兄弟 GPU 都传递其文本特征。
实验与结果
在实验部分,作者对比了 SigLIP (sigmoid) 和 CLIP (softmax)。
论文比较了SigLIP 和 CLIP 在预训练期间使用 ImageNet 进行零样本性能测试 (y 轴) 时的不同批次大小 (x 轴),结果如下图:

主要发现包括:
(1) SigLIP 在小批次大小 (例如 4-8k) 下的性能优于 CLIP;
(2) 虽然相关文献声称大批次大小可以提高性能,但本文表明 SigLIP 和 CLIP 都在 32k 批次大小时达到饱和;
(3) 随着批次大小的增加,SigLIP 和 CLIP 之间的性能差距缩小。
另外,论文评估了哪种损失(CLIP vs SigLIP)对标签噪声更具鲁棒性。这个实验很重要,因为语言图像训练数据集通常是从互联网上抓取的。出于实际目的,假设每个图像查询都有一个文本匹配,反之亦然。这种假设通常是嘈杂且不完善的。虽然很难量化训练数据集中的噪声水平,但可以使用以下五种方法之一合成地破坏训练数据:
- 图像:以概率p用均匀随机噪声替换图像。
- 文本:以概率p,用随机采样的标记的新序列替换标记化的文本,最多可达某个(采样的)序列长度。
- 批次对齐:随机打乱批次中p %的顺序。
- 图像和文本:分别以概率p应用图像和文本方法。
- 图像、文本和批次:与图像和文本方法一起,还对对齐的分数p进行打乱。
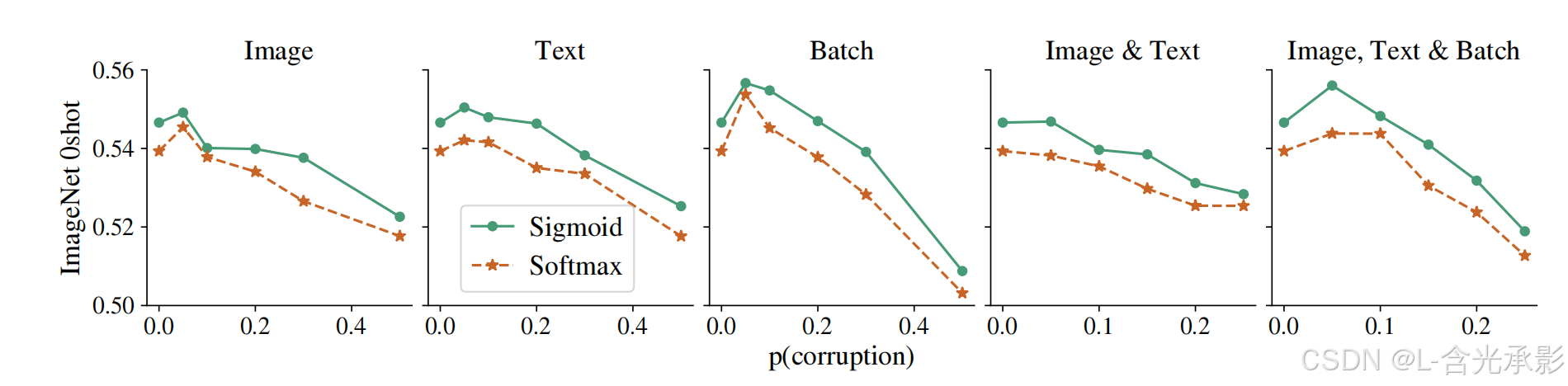
上图比较了当使用上述五种损坏方法之一损坏训练数据集时 CLIP (softmax) 与 SigLIP (sigmoid)。显然,SigLIP 对噪声标签的鲁棒性始终更高。
源码:https://github.com/google-research/big_vision
总结
SigLIP 提出了一种结构简洁、高效实用的图文预训练方法,其核心在于用成对 Sigmoid 损失替代传统对比学习中的 Softmax 损失,从而打破了批次大小与损失计算间的耦合。整个工作流程包括:将图像与文本分别通过独立编码器提取特征,进行归一化处理后,计算每一对图文的点积相似度并加上可学习温度与偏置,最终通过 Sigmoid 二分类损失对正负样本进行判别。该设计不仅显著减少了通信与内存开销,使得在小批次下更稳健、在大批次下更易扩展,还保留了良好的对齐能力和下游迁移性能。然而,SigLIP 也存在无法利用全局负样本分布、在极端大批次下性能提升趋于饱和等限制。未来研究可进一步探索更强的负样本建模策略、多模态自监督融合、以及适用于多语言与复杂场景下的通用对齐机制,以提升语义理解的精度与泛化能力。