康佳Java开发面试题及参考答案
面向对象三大特性是什么?请举例说明多态。
面向对象编程(OOP)的三大核心特性是封装、继承和多态。封装是将数据和操作数据的方法绑定在一起,并隐藏对象的内部实现细节;继承允许一个类继承另一个类的属性和方法,从而实现代码复用和层次化设计;而多态则是指对象在运行时能够表现出不同形态的能力。
多态的实现依赖于方法重写和接口实现。在 Java 中,多态主要通过两种方式体现:继承多态和接口多态。继承多态是指子类可以重写父类的方法,而接口多态则是指实现类可以实现接口中定义的方法。通过多态,我们可以编写更加灵活、可扩展的代码,提高系统的可维护性。
例如,有一个抽象类Shape定义了计算面积的抽象方法calculateArea(),并派生出Circle和Rectangle两个子类。每个子类都重写了calculateArea()方法以实现自己的计算逻辑。当我们通过父类引用指向子类对象时,调用calculateArea()方法会根据实际对象类型动态调用相应的实现。
abstract class Shape {abstract double calculateArea();
}class Circle extends Shape {private double radius;public Circle(double radius) {this.radius = radius;}@Overridedouble calculateArea() {return Math.PI * radius * radius;}
}class Rectangle extends Shape {private double width;private double height;public Rectangle(double width, double height) {this.width = width;this.height = height;}@Overridedouble calculateArea() {return width * height;}
}public class PolymorphismExample {public static void main(String[] args) {Shape circle = new Circle(5.0);Shape rectangle = new Rectangle(4.0, 6.0);System.out.println("Circle Area: " + circle.calculateArea());System.out.println("Rectangle Area: " + rectangle.calculateArea());}
}
在这个例子中,circle和rectangle都是Shape类型的引用,但实际指向的是不同的子类对象。当调用calculateArea()方法时,Java 虚拟机(JVM)会根据对象的实际类型来决定执行哪个子类的方法实现,这就是多态的核心体现。
多态的优势在于可以编写通用的代码处理不同类型的对象,提高代码的灵活性和可扩展性。例如,我们可以创建一个Shape数组,存储不同类型的形状对象,然后统一调用calculateArea()方法,无需关心具体对象的类型。
Shape[] shapes = new Shape[2];
shapes[0] = new Circle(5.0);
shapes[1] = new Rectangle(4.0, 6.0);for (Shape shape : shapes) {System.out.println("Area: " + shape.calculateArea());
}
这种方式使得代码更加简洁、通用,同时也符合开闭原则 —— 对扩展开放,对修改关闭。
extends 和 implement 的区别是什么?
在 Java 中,extends和implement是用于实现继承和接口的两个关键字,它们在语法和功能上有明显的区别。
extends关键字用于类与类之间的继承关系,允许一个子类继承父类的属性和方法。Java 只支持单继承,即一个类只能直接继承自一个父类。通过继承,子类可以复用父类的代码,并可以重写父类的方法以实现自己的特定行为。父类可以是具体类或抽象类,但不能是接口。
implement关键字用于类与接口之间的实现关系,允许一个类实现一个或多个接口。接口是一种特殊的抽象类型,只包含方法签名而不包含实现。类实现接口时,必须实现接口中定义的所有方法。Java 支持多实现,即一个类可以同时实现多个接口,从而弥补了单继承的局限性。
下面通过一个示例来说明两者的区别:
// 定义一个父类
class Animal {public void eat() {System.out.println("Animal is eating");}
}// 定义一个接口
interface Flyable {void fly();
}// Bird类继承自Animal并实现Flyable接口
class Bird extends Animal implements Flyable {@Overridepublic void fly() {System.out.println("Bird is flying");}@Overridepublic void eat() {System.out.println("Bird is eating seeds");}
}// 另一个接口
interface Swimmable {void swim();
}// Duck类继承自Bird并实现Swimmable接口
class Duck extends Bird implements Swimmable {@Overridepublic void swim() {System.out.println("Duck is swimming");}
}
在这个例子中,Bird类通过extends关键字继承了Animal类的eat()方法,并通过implement关键字实现了Flyable接口的fly()方法。Duck类进一步继承了Bird类,并实现了Swimmable接口,展示了多重实现的能力。
从使用场景来看,extends主要用于创建具有层次结构的类体系,实现代码复用和行为扩展;而implement则用于定义对象的行为契约,实现不同类之间的行为统一。接口更适合用于定义通用的行为标准,而继承则更适合用于表示 "is-a" 的关系。
需要注意的是,抽象类和接口在 Java 8 之后的区别变得更加模糊,因为接口可以包含默认方法和静态方法。但总体来说,抽象类更适合作为相关类的基类,而接口更适合作为独立的行为模块。
final 关键字的作用及使用场景?
在 Java 中,final关键字用于限制事物的可变性,它可以应用于类、方法和变量,分别表示不同的含义和使用场景。
当final用于修饰类时,表示该类不能被继承,即不能有子类。这种设计通常用于确保类的实现不会被修改,例如 Java 中的String类就是一个final类,它的不可变性确保了字符串在多线程环境下的安全性。
final class FinalClass {// 类的实现
}// 错误:无法继承final类
// class SubClass extends FinalClass {}
当final用于修饰方法时,表示该方法不能被子类重写。这通常用于确保方法的实现逻辑不被改变,例如在父类中定义了一个核心业务方法,不希望子类修改它。
class Parent {public final void display() {System.out.println("This is a final method.");}
}class Child extends Parent {// 错误:无法重写final方法// public void display() {}
}
当final用于修饰变量时,表示该变量一旦被赋值就不能再被修改,即成为常量。对于基本数据类型,final使其值不可变;对于引用类型,final使其引用不可变,但引用的对象内容可以改变。
class FinalVariableExample {final int NUMBER = 10; // 基本数据类型常量final StringBuilder builder = new StringBuilder("Hello"); // 引用类型常量public void modifyVariables() {// NUMBER = 20; // 错误:无法修改final变量builder.append(" World"); // 可以修改引用对象的内容// builder = new StringBuilder("Hi"); // 错误:无法修改final引用}
}
final变量必须在声明时或构造函数中初始化,否则会导致编译错误。此外,final还可以用于修饰方法参数,确保在方法内部不能修改该参数的值。
public void calculate(final int value) {// value = value + 10; // 错误:无法修改final参数
}
final关键字的使用场景包括:
- 常量定义:使用
final修饰的静态变量(static final)是 Java 中定义常量的标准方式,例如public static final double PI = 3.14159;。 - 安全性考虑:通过
final类和方法防止代码被恶意修改,提高系统安全性。 - 性能优化:
final方法在编译时会被内联优化,提高方法调用效率。 - 线程安全:
final变量在多线程环境下不需要额外的同步机制,因为它们不可变。
在设计类和方法时,合理使用final关键字可以提高代码的健壮性和可维护性,但过度使用可能会限制代码的灵活性,因此需要根据具体场景权衡使用。
static 关键字的作用及使用场景?
在 Java 中,static关键字用于表示属于类本身而不是类的实例的成员。它可以应用于变量、方法、代码块和内部类,改变这些成员的生命周期和访问方式。
static变量(静态变量)属于类而不是类的实例,所有实例共享同一个静态变量。静态变量在类加载时初始化,存储在方法区,其生命周期与类相同。静态变量通常用于表示类级别的全局变量,例如计数器或配置参数。
class Counter {static int count = 0; // 静态变量,所有实例共享public Counter() {count++; // 每次创建实例时计数器加1}public static int getCount() { // 静态方法return count;}
}public class StaticVariableExample {public static void main(String[] args) {Counter c1 = new Counter();Counter c2 = new Counter();System.out.println(Counter.getCount()); // 输出2}
}
static方法(静态方法)属于类而不是类的实例,可以直接通过类名调用,无需创建对象。静态方法只能访问静态成员(静态变量和静态方法),不能访问实例成员,因为静态方法在类加载时就存在,而实例成员需要创建对象后才能存在。
class MathUtils {public static int add(int a, int b) { // 静态方法return a + b;}
}public class StaticMethodExample {public static void main(String[] args) {int result = MathUtils.add(5, 3); // 直接通过类名调用静态方法System.out.println(result); // 输出8}
}
static代码块(静态代码块)在类加载时执行一次,用于初始化静态变量或执行类级别的初始化操作。静态代码块按照在类中出现的顺序依次执行。
class StaticBlockExample {static int value;static { // 静态代码块value = 10;System.out.println("Static block executed");}public static void main(String[] args) {System.out.println("Value: " + value);}
}
static内部类(静态内部类)是定义在另一个类内部的静态类,它不依赖于外部类的实例,可以直接创建。静态内部类只能访问外部类的静态成员。
class Outer {static int x = 10;static class Inner {public void display() {System.out.println("Outer x: " + x);}}
}public class StaticNestedClassExample {public static void main(String[] args) {Outer.Inner inner = new Outer.Inner(); // 直接创建静态内部类实例inner.display(); // 输出10}
}
static关键字的使用场景包括:
- 工具类:将常用的工具方法定义为静态方法,例如
java.lang.Math类中的所有方法都是静态的。 - 单例模式:使用静态变量保存类的唯一实例,例如饿汉式单例。
- 全局常量:使用
static final修饰的变量定义全局常量,例如public static final String DEFAULT_NAME = "John";。 - 初始化资源:在静态代码块中初始化数据库连接、加载配置文件等操作。
需要注意的是,过度使用static会导致代码的可测试性和可维护性下降,因为静态成员难以被继承和重写,也不利于依赖注入。因此,应谨慎使用static关键字,遵循面向对象设计原则。
Java 的异常体系结构是怎样的?

Java 的异常体系结构是一个基于继承的层次结构,所有异常类最终都继承自java.lang.Throwable类。Throwable类有两个主要子类:Error和Exception,分别表示错误和异常。
Error类表示系统级错误和资源耗尽的情况,例如OutOfMemoryError、StackOverflowError和VirtualMachineError等。这类错误通常是不可恢复的,应用程序不应该尝试捕获或处理它们。
Exception类表示程序可以捕获和处理的异常情况。Exception又分为两个主要分支:受检查异常(Checked Exception)和运行时异常(RuntimeException)。
受检查异常是指继承自Exception但不继承自RuntimeException的异常类。这类异常在编译时被检查,必须在方法签名中声明或使用try-catch块捕获。例如,IOException、SQLException和ClassNotFoundException等。
运行时异常是指继承自RuntimeException的异常类。这类异常在编译时不被检查,可以不声明或捕获。常见的运行时异常包括NullPointerException、ArrayIndexOutOfBoundsException、IllegalArgumentException和ArithmeticException等。
Java 异常处理机制的核心是try-catch-finally语句和throws声明。通过try块包裹可能抛出异常的代码,使用catch块捕获并处理异常,使用finally块执行无论是否发生异常都必须执行的代码。throws声明用于方法签名中,表示该方法可能抛出的异常。
import java.io.File;
import java.io.FileReader;
import java.io.IOException;public class ExceptionHandlingExample {public static void main(String[] args) {try {readFile("nonexistent.txt");} catch (IOException e) {System.out.println("Error reading file: " + e.getMessage());}}public static void readFile(String fileName) throws IOException {File file = new File(fileName);FileReader reader = new FileReader(file);// 读取文件内容reader.close();}
}
在这个例子中,readFile方法声明可能抛出IOException,调用者必须处理这个受检查异常。如果文件不存在,会抛出FileNotFoundException(IOException的子类),被catch块捕获并处理。
Java 7 引入了try-with-resources语句,用于自动关闭实现了AutoCloseable接口的资源,简化了资源管理代码。
import java.io.File;
import java.io.FileReader;
import java.io.IOException;public class TryWithResourcesExample {public static void main(String[] args) {try (FileReader reader = new FileReader("example.txt")) {// 读取文件内容int data;while ((data = reader.read()) != -1) {System.out.print((char) data);}} catch (IOException e) {System.out.println("Error reading file: " + e.getMessage());}}
}
在这个例子中,FileReader实现了AutoCloseable接口,try-with-resources语句会自动关闭资源,无需显式调用close()方法。
Java 异常体系的设计遵循以下原则:
- 受检查异常用于表示可预测的异常情况,强制开发者处理这些异常,提高程序的健壮性。
- 运行时异常用于表示编程错误,如空指针引用或数组越界,这类异常应该通过代码审查和测试来避免。
- 错误表示系统级问题,应用程序通常无法处理。
合理使用 Java 的异常机制可以使代码更加健壮、清晰,同时也便于调试和维护。在设计应用程序时,应根据异常的类型和业务需求选择合适的处理方式,避免捕获不必要的异常或忽略重要的异常信息。
String 类型中 CHAR 和 VARCHAR 的区别及使用场景?
在数据库领域,CHAR和VARCHAR是两种常用的字符串数据类型,它们在存储方式、长度特性和适用场景上存在显著差异。理解这些差异对于数据库设计和性能优化至关重要。
CHAR是固定长度的字符串类型,在定义时需要指定长度,无论实际存储的字符串长度是多少,都会占用固定的存储空间。例如,定义一个CHAR(10)的字段,如果存储的字符串长度小于 10 个字符,剩余的空间会用空格填充。这种特性使得CHAR在处理定长数据时效率较高,因为数据库可以精确计算每个记录的位置。
VARCHAR则是可变长度的字符串类型,同样需要在定义时指定最大长度,但实际存储空间只占用字符串实际长度加 1 或 2 个字节(用于存储字符串长度)。例如,定义一个VARCHAR(10)的字段,存储长度为 5 的字符串时,实际只占用 6 或 7 个字节。这种灵活性使得VARCHAR在处理长度变化较大的数据时更为节省空间。
两者的主要区别可以归纳为以下几点:
| 特性 | CHAR | VARCHAR |
|---|---|---|
| 存储方式 | 固定长度,不足补空格 | 可变长度,存储实际长度 + 标记 |
| 空间效率 | 可能浪费空间(填充空格) | 更节省空间(按需分配) |
| 访问速度 | 略快(无需计算长度) | 稍慢(需读取长度标记) |
| 适用场景 | 定长数据(如身份证号、邮编) | 变长数据(如姓名、地址) |
在实际应用中,CHAR适用于存储长度固定的数据,如性别('M'/'F')、国家代码(如 'CN'、'US')等。由于其长度固定,检索效率较高,尤其在需要频繁比较的场景中表现出色。例如,存储 UUID 时使用CHAR(36)可以避免因长度变化带来的额外开销。
VARCHAR则更适合存储长度不确定的数据,如用户输入的文本、文章内容等。使用VARCHAR可以有效节省存储空间,特别是在处理大量数据时,这种优势更为明显。但需要注意的是,若定义的最大长度过大,可能会导致索引效率下降,因为索引通常需要存储完整的字段长度信息。
在性能方面,CHAR的固定长度特性使其在排序和比较操作中略占优势,因为不需要额外处理长度信息。而VARCHAR由于其动态特性,在插入和更新时可能需要额外的内存分配和移动操作。
在选择使用CHAR还是VARCHAR时,需要综合考虑数据的特性、存储空间成本和查询性能。对于长度变化不大且经常参与比较操作的数据,优先使用CHAR;对于长度变化较大且对存储空间敏感的数据,则应选择VARCHAR。此外,还应根据具体数据库系统的实现特点进行调整,不同数据库对这两种类型的处理可能存在细微差异。
ArrayList 的底层数据结构是什么?扩容机制如何?时间复杂度如何?
ArrayList是 Java 集合框架中常用的动态数组实现,它继承自AbstractList类并实现了List接口。其底层数据结构是一个动态扩容的数组,这使得ArrayList能够像普通数组一样通过索引快速访问元素,同时具备动态调整大小的能力。
在ArrayList内部,使用一个Object[]数组来存储元素。当创建ArrayList对象时,默认会初始化一个空数组(JDK 1.8 及以后),直到第一次添加元素时才会分配默认容量(10)的数组。这种延迟初始化策略可以减少内存浪费。
ArrayList的扩容机制是其核心特性之一。当向ArrayList中添加元素时,如果当前数组已满,就需要进行扩容操作。扩容过程如下:
- 计算新的容量:默认情况下,新容量是原容量的 1.5 倍(即
oldCapacity + (oldCapacity >> 1))。 - 创建一个新的数组,大小为计算出的新容量。
- 将原数组中的所有元素复制到新数组中。
- 使用新数组替换原数组,并丢弃原数组。
这种扩容机制确保了ArrayList能够动态增长以容纳更多元素,但频繁的扩容操作会导致性能开销,因为涉及到数组的复制。为了避免这种情况,可以在创建ArrayList时通过构造函数指定初始容量,或者使用ensureCapacity方法预先分配足够的空间。
以下是ArrayList扩容机制的示例代码:
import java.util.ArrayList;public class ArrayListExample {public static void main(String[] args) {ArrayList<Integer> list = new ArrayList<>(5); // 初始容量为5// 添加6个元素,触发扩容for (int i = 0; i < 6; i++) {list.add(i);}System.out.println("List size: " + list.size()); // 输出6System.out.println("List capacity: " + getCapacity(list)); // 输出7(5*1.5=7.5,取整为7)}// 通过反射获取ArrayList的容量private static int getCapacity(ArrayList<?> list) {try {java.lang.reflect.Field field = ArrayList.class.getDeclaredField("elementData");field.setAccessible(true);return ((Object[]) field.get(list)).length;} catch (Exception e) {return -1;}}
}
ArrayList的时间复杂度分析如下:
- 随机访问:通过索引访问元素的时间复杂度为 O (1),因为数组的内存地址是连续的,可以直接计算出元素的位置。
- 添加元素:在列表末尾添加元素的平均时间复杂度为 O (1),但在数组满时需要扩容,此时时间复杂度为 O (n)。如果预先知道元素数量并设置合适的初始容量,可以避免扩容开销。
- 插入元素:在指定位置插入元素的时间复杂度为 O (n),因为需要将后续元素向后移动。
- 删除元素:删除指定位置元素的时间复杂度为 O (n),因为需要将后续元素向前移动。
- 遍历元素:使用迭代器或 for-each 循环遍历元素的时间复杂度为 O (n),因为需要访问每个元素一次。
HashMap 的底层实现原理是什么?JDK 1.8 前后有哪些区别?
HashMap是 Java 中最常用的数据结构之一,用于存储键值对(key-value pairs)。其核心设计目标是提供高效的插入、查询和删除操作。理解HashMap的底层实现原理以及 JDK 1.8 前后的变化,对于优化代码性能和避免潜在问题至关重要。
在 JDK 1.8 之前,HashMap的底层实现是数组 + 链表的结构,也称为哈希桶(Hash Bucket)。具体实现如下:
- 哈希表数组:
HashMap内部维护一个数组,每个数组元素称为一个桶(Bucket),用于存储键值对。 - 链表处理哈希冲突:当不同的键通过哈希函数计算出相同的索引位置时,这些键值对会以链表的形式存储在同一个桶中。
- 哈希函数:通过键的
hashCode()方法计算哈希值,再经过扰动函数处理后映射到数组索引。 - 插入与查找:插入和查找时,先通过哈希值找到对应的桶,再在链表中遍历查找或插入元素。
JDK 1.8 对HashMap的实现进行了重大优化,引入了红黑树结构,形成了数组 + 链表 + 红黑树的复合结构。当链表长度超过阈值(默认为 8)且数组长度大于 64 时,链表会转换为红黑树;当树节点数量小于 6 时,红黑树会退化为链表。这种优化主要是为了解决哈希冲突严重时链表查询效率低下的问题(链表查询时间复杂度为 O (n),而红黑树为 O (log n))。
JDK 1.8 前后的主要区别如下:
| 特性 | JDK 1.7 及以前 | JDK 1.8 及以后 |
|---|---|---|
| 数据结构 | 数组 + 链表 | 数组 + 链表 + 红黑树 |
| 插入方式 | 头插法(新节点插入链表头部) | 尾插法(新节点插入链表尾部) |
| 哈希函数复杂度 | 扰动函数进行 4 次位运算 + 5 次异或 | 扰动函数进行 1 次位运算 + 1 次异或 |
| 扩容机制 | 全部元素重新计算哈希值和索引 | 仅判断原索引或原索引 + 旧容量 |
| 线程安全性 | 非线程安全,多线程可能导致死循环 | 非线程安全,多线程可能导致数据不一致 |
以下是 JDK 1.8 中HashMap的关键代码片段,展示了链表转红黑树的逻辑:
// 链表节点类
static class Node<K,V> implements Map.Entry<K,V> {final int hash;final K key;V value;Node<K,V> next;// 省略构造方法和其他方法
}// 红黑树节点类
static final class TreeNode<K,V> extends LinkedHashMap.Entry<K,V> {TreeNode<K,V> parent; // red-black tree linksTreeNode<K,V> left;TreeNode<K,V> right;TreeNode<K,V> prev; // needed to unlink next upon deletionboolean red;// 省略构造方法和其他方法
}// 插入元素的方法
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,boolean evict) {Node<K,V>[] tab; Node<K,V> p; int n, i;if ((tab = table) == null || (n = tab.length) == 0)n = (tab = resize()).length;if ((p = tab[i = (n - 1) & hash]) == null)tab[i] = newNode(hash, key, value, null);else {Node<K,V> e; K k;if (p.hash == hash &&((k = p.key) == key || (key != null && key.equals(k))))e = p;else if (p instanceof TreeNode)e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);else {for (int binCount = 0; ; ++binCount) {if ((e = p.next) == null) {p.next = newNode(hash, key, value, null);if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1sttreeifyBin(tab, hash); // 链表转红黑树break;}if (e.hash == hash &&((k = e.key) == key || (key != null && key.equals(k))))break;p = e;}}// 省略后续代码}// 省略后续代码
}
在 JDK 1.8 中,HashMap的扩容机制也得到了优化。当数组扩容时,元素的位置要么保持不变,要么移动到原位置 + 旧容量的位置。这种设计避免了重新计算哈希值,提高了扩容效率。
需要注意的是,HashMap是非线程安全的。在多线程环境下,推荐使用ConcurrentHashMap代替。JDK 1.7 及以前的HashMap在多线程扩容时可能会导致死循环,而 JDK 1.8 虽然修复了这个问题,但仍不保证线程安全。
进程和线程的区别是什么?
进程和线程是操作系统中两个重要的概念,它们都是实现多任务处理的方式,但在设计理念、资源占用和调度方式上存在本质区别。
进程(Process) 是程序在操作系统中的一次执行实例,是系统进行资源分配和调度的基本单位。每个进程都有自己独立的内存空间、文件描述符、数据栈等系统资源。进程之间相互独立,一个进程的崩溃不会影响其他进程。操作系统通过进程控制块(PCB)来管理进程,包括进程的状态、优先级、程序计数器等信息。
线程(Thread) 是进程中的一个执行单元,是 CPU 调度和分派的基本单位。一个进程可以包含多个线程,这些线程共享进程的资源,如内存空间、文件句柄等,但每个线程有自己独立的程序计数器、栈和寄存器。线程之间的通信比进程更高效,因为它们可以直接访问共享数据。
进程和线程的主要区别可以从以下几个方面进行对比:
| 特性 | 进程 | 线程 |
|---|---|---|
| 资源分配 | 拥有独立的内存空间和系统资源 | 共享所属进程的资源,仅拥有自己的栈和寄存器 |
| 调度单位 | 是操作系统调度的基本单位 | 是 CPU 调度的基本单位 |
| 创建和销毁开销 | 开销大,需要分配和释放资源 | 开销小,只需保存和恢复少量寄存器状态 |
| 通信方式 | 进程间通信(IPC)需要复杂机制 | 直接访问共享内存,通信效率高 |
| 并发能力 | 适合多核 CPU 并行处理 | 适合 IO 密集型任务,提高吞吐量 |
| 健壮性 | 一个进程崩溃不影响其他进程 | 一个线程崩溃可能导致整个进程崩溃 |
| 上下文切换 | 切换开销大,涉及内存空间和 CPU 环境的切换 | 切换开销小,主要保存和恢复寄存器状态 |
进程间通信(IPC)通常通过管道、消息队列、共享内存、套接字等方式实现,而线程间通信可以直接通过共享变量进行。由于线程共享内存空间,它们之间的通信速度更快,但也更容易引发竞态条件(Race Condition)和死锁等问题,需要使用同步机制(如锁、信号量)来保证线程安全。
进程和线程的使用场景也有所不同。进程适合需要隔离性和稳定性的场景,如不同应用程序之间的隔离;而线程适合需要提高并发性能和资源利用率的场景,如多任务处理、网络服务器等。
在现代操作系统中,通常采用多进程和多线程混合的方式来实现高效的并发处理。例如,Web 服务器通常使用多进程模型来处理多个客户端请求,每个进程内部再使用多线程来处理并发的连接。这种设计既保证了系统的稳定性,又提高了资源利用率和响应速度。
线程如何维护自己的私有变量?
在多线程编程中,有时需要为每个线程维护一份独立的变量副本,以避免线程间的数据竞争和保证线程安全。Java 提供了几种机制来实现线程私有变量,其中最常用的是ThreadLocal类和线程局部存储(Thread-Local Storage, TLS)。
ThreadLocal 类 是 Java 提供的一种特殊机制,它为每个使用该变量的线程都提供一个独立的变量副本,每个线程都可以独立地改变自己的副本,而不会影响其他线程的副本。ThreadLocal内部维护一个ThreadLocalMap,其中键是ThreadLocal实例本身,值是每个线程的变量副本。
以下是ThreadLocal的基本用法示例:
public class ThreadLocalExample {// 创建一个ThreadLocal实例,初始值为0private static final ThreadLocal<Integer> threadLocal = ThreadLocal.withInitial(() -> 0);public static void main(String[] args) {// 创建两个线程Thread t1 = new Thread(() -> {for (int i = 0; i < 5; i++) {// 获取当前线程的变量副本并递增int value = threadLocal.get();threadLocal.set(value + 1);System.out.println(Thread.currentThread().getName() + ": " + threadLocal.get());try {Thread.sleep(100);} catch (InterruptedException e) {e.printStackTrace();}}}, "Thread-1");Thread t2 = new Thread(() -> {for (int i = 0; i < 5; i++) {// 获取当前线程的变量副本并递增int value = threadLocal.get();threadLocal.set(value + 2);System.out.println(Thread.currentThread().getName() + ": " + threadLocal.get());try {Thread.sleep(100);} catch (InterruptedException e) {e.printStackTrace();}}}, "Thread-2");// 启动线程t1.start();t2.start();// 等待线程执行完毕try {t1.join();t2.join();} catch (InterruptedException e) {e.printStackTrace();}// 清理ThreadLocalthreadLocal.remove();}
}
在这个例子中,ThreadLocal为每个线程维护了一个独立的计数器。Thread-1每次将计数器加 1,而Thread-2每次将计数器加 2。由于每个线程都有自己的副本,它们之间的操作互不影响。
ThreadLocal的实现原理是,每个Thread对象都包含一个ThreadLocalMap,当调用ThreadLocal的get()或set()方法时,会先获取当前线程的ThreadLocalMap,然后以ThreadLocal实例为键查找或存储值。这种设计使得每个线程都能独立地访问自己的变量副本。
InheritableThreadLocal 类 是ThreadLocal的子类,它允许子线程继承父线程的ThreadLocal变量值。当一个线程创建子线程时,子线程会复制父线程的InheritableThreadLocal变量副本。
以下是InheritableThreadLocal的示例:
public class InheritableThreadLocalExample {private static final InheritableThreadLocal<Integer> inheritableThreadLocal = new InheritableThreadLocal<>();public static void main(String[] args) {// 在主线程中设置值inheritableThreadLocal.set(10);// 创建子线程Thread childThread = new Thread(() -> {// 子线程可以访问父线程设置的值System.out.println("Child thread value: " + inheritableThreadLocal.get());// 子线程修改自己的副本inheritableThreadLocal.set(20);System.out.println("Child thread updated value: " + inheritableThreadLocal.get());});// 启动子线程childThread.start();// 主线程继续使用自己的副本System.out.println("Main thread value: " + inheritableThreadLocal.get());try {childThread.join();} catch (InterruptedException e) {e.printStackTrace();}// 清理inheritableThreadLocal.remove();}
}
除了ThreadLocal,还可以通过以下方式实现线程私有变量:
- 局部变量:方法内部的局部变量是线程私有的,每个线程执行该方法时都会创建自己的局部变量副本。
- 线程封闭:将对象限制在单个线程中使用,避免多线程访问共享资源。
- 栈封闭:通过方法调用栈来保证变量的线程私有性,如将对象作为方法参数传递,不在多个线程间共享。
使用ThreadLocal时需要注意内存泄漏问题。由于ThreadLocalMap中的键是弱引用(WeakReference),当ThreadLocal实例被垃圾回收后,键会变为null,但值仍然是强引用,可能导致内存泄漏。因此,在不再使用ThreadLocal时,应调用remove()方法清理数据。
在多线程环境中,合理使用线程私有变量可以简化并发编程模型,避免使用复杂的同步机制,提高代码的可维护性和性能。
ThreadLocal 的实现原理是什么?存在哪些内存泄漏问题?如何解决?
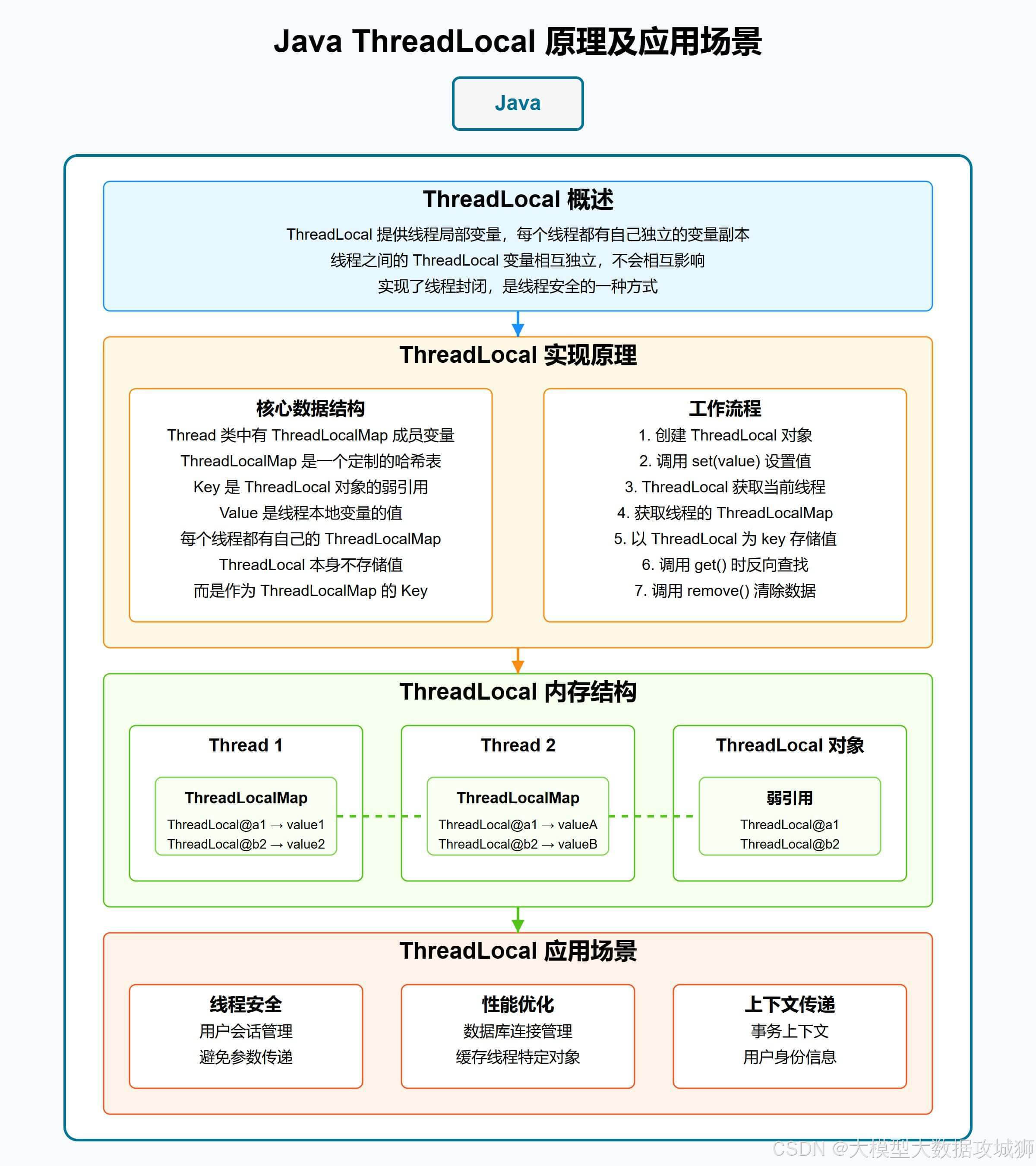
ThreadLocal 是 Java 中用于实现线程局部变量的类,它为每个使用该变量的线程都提供一个独立的变量副本,每个线程都可以独立地改变自己的副本,而不会影响其他线程所对应的副本。其核心设计是为了解决多线程环境下的变量隔离问题,避免线程间的数据竞争。
ThreadLocal 的实现原理基于每个线程内部都有一个 ThreadLocalMap 实例,该实例存储了与该线程相关的所有 ThreadLocal 变量及其对应的值。ThreadLocalMap 是 ThreadLocal 的一个静态内部类,其键为 ThreadLocal 实例(弱引用),值为用户设置的对象。当线程调用 ThreadLocal 的 get()、set() 或 remove() 方法时,实际上是通过当前线程获取其内部的 ThreadLocalMap,然后以 ThreadLocal 实例为键进行操作。
以下是 ThreadLocal 的关键代码片段,展示了其实现原理:
public class ThreadLocal<T> {// 获取当前线程的变量值public T get() {Thread t = Thread.currentThread();ThreadLocalMap map = getMap(t);if (map != null) {ThreadLocalMap.Entry e = map.getEntry(this);if (e != null) {@SuppressWarnings("unchecked")T result = (T)e.value;return result;}}return setInitialValue();}// 设置当前线程的变量值public void set(T value) {Thread t = Thread.currentThread();ThreadLocalMap map = getMap(t);if (map != null)map.set(this, value);elsecreateMap(t, value);}// 获取当前线程的ThreadLocalMapThreadLocalMap getMap(Thread t) {return t.threadLocals;}// 静态内部类ThreadLocalMapstatic class ThreadLocalMap {static class Entry extends WeakReference<ThreadLocal<?>> {/** The value associated with this ThreadLocal. */Object value;Entry(ThreadLocal<?> k, Object v) {super(k);value = v;}}// 省略其他实现}
}
ThreadLocal 的内存泄漏问题主要源于其内部的 ThreadLocalMap 设计。ThreadLocalMap 中的键是 ThreadLocal 实例的弱引用(WeakReference),而值是强引用。当外部对 ThreadLocal 的强引用被释放后,ThreadLocal 实例会被垃圾回收(因为弱引用无法阻止 GC),但此时 ThreadLocalMap 中的键变为 null,而值仍然保持强引用。如果线程一直存活(如线程池中的线程),这些 null 键对应的 value 就无法被回收,从而导致内存泄漏。
解决 ThreadLocal 内存泄漏问题的关键在于及时清理不再需要的 ThreadLocal 变量。具体措施包括:
- 使用后调用
remove()方法:在不需要ThreadLocal变量时,显式调用remove()方法删除对应的键值对。 - 在
finally块中调用remove():对于需要确保资源释放的场景,建议在finally块中调用remove(),保证无论是否发生异常都能清理资源。 - 避免使用静态的
ThreadLocal:静态的ThreadLocal可能导致其生命周期与应用程序相同,增加内存泄漏的风险。 - 使用线程池时特别注意:由于线程池中的线程会被复用,
ThreadLocal变量可能会在不同的任务间共享,因此在任务执行前后都应进行清理。
以下是正确使用 ThreadLocal 的示例:
public class ThreadLocalExample {private static final ThreadLocal<Integer> threadLocal = ThreadLocal.withInitial(() -> 0);public static void main(String[] args) {try {// 设置线程局部变量threadLocal.set(10);// 使用线程局部变量System.out.println("Current value: " + threadLocal.get());} finally {// 确保清理线程局部变量,避免内存泄漏threadLocal.remove();}}
}
通过合理使用 remove() 方法,可以有效避免 ThreadLocal 导致的内存泄漏问题。此外,Java 8 引入的 ThreadLocal.withInitial() 方法提供了更简洁的初始化方式,同时也建议在使用 ThreadLocal 时遵循良好的编程实践,确保变量的生命周期得到正确管理。
synchronized 的实现原理是什么?涉及 JVM 的哪一部分?
synchronized 是 Java 中用于实现线程同步的关键字,它可以保证在同一时刻只有一个线程能够访问被同步的代码块或方法。其实现原理基于 Java 对象头中的 Mark Word 和 JVM 内置的 Monitor(监视器)机制。
在 JVM 中,每个对象都有一个对象头(Object Header),其中包含了 Mark Word 信息。Mark Word 是一个动态数据结构,根据对象的状态不同而存储不同的信息。当对象被用作锁时,Mark Word 会存储锁的相关信息,如锁状态、偏向线程 ID、锁记录指针等。
synchronized 的实现分为两种形式:同步方法和同步代码块。对于同步方法,JVM 通过方法表中的 ACC_SYNCHRONIZED 标志来实现同步;对于同步代码块,JVM 则使用 monitorenter 和 monitorexit 指令来实现。
以下是同步代码块的字节码示例:
public class SynchronizedExample {private final Object lock = new Object();public void synchronizedMethod() {synchronized (lock) {// 同步代码块System.out.println("Inside synchronized block");}}
}
对应的字节码片段:
monitorenter // 进入监视器,获取锁
getstatic // 其他指令
invokevirtual // 其他指令
monitorexit // 正常退出监视器,释放锁
astore_1 // 异常处理
monitorexit // 异常退出监视器,释放锁
athrow // 抛出异常
从字节码可以看出,同步代码块使用 monitorenter 和 monitorexit 指令来实现锁的获取和释放。每个对象都关联一个 Monitor(监视器),当线程执行 monitorenter 指令时,会尝试获取对象的 Monitor。如果 Monitor 未被占用,则该线程获得 Monitor 并继续执行;如果 Monitor 已被其他线程占用,则该线程会被阻塞,直到 Monitor 被释放。
Monitor 是 JVM 实现的一种锁机制,它是一个对象级别的同步原语。在 HotSpot JVM 中,Monitor 由 ObjectMonitor 类实现,其主要数据结构包括:
- _owner:指向持有 Monitor 的线程
- _WaitSet:存储处于等待状态的线程队列
- _EntryList:存储处于阻塞状态的线程队列
当线程进入同步代码块时,会尝试获取对象的 Monitor:
- 如果 Monitor 的 _owner 为 null,表示没有线程持有锁,当前线程可以直接获取锁并将 _owner 设置为自己。
- 如果 Monitor 的 _owner 指向当前线程,表示当前线程已经持有锁,可以直接重入(synchronized 支持重入锁)。
- 如果 Monitor 的 _owner 指向其他线程,当前线程会被放入 _EntryList 队列中阻塞等待。
当线程退出同步代码块时,会释放 Monitor:
- 将 _owner 设置为 null
- 唤醒 _EntryList 中的一个等待线程
synchronized 涉及 JVM 的多个部分:
- 对象头:存储锁状态和相关信息
- 字节码:通过
ACC_SYNCHRONIZED标志和monitorenter/monitorexit指令实现同步逻辑 - 运行时:Monitor 机制由 JVM 运行时系统实现
- 内存模型:synchronized 保证了可见性和有序性,涉及 JVM 的内存屏障和 Happens-Before 规则
在 JDK 1.6 之后,synchronized 进行了大量优化,引入了偏向锁、轻量级锁、锁粗化、锁消除等机制,大大提高了其性能。这些优化使得 synchronized 在大多数情况下不再是性能瓶颈,成为了 Java 中最常用的同步机制之一。
如何对 synchronized 进行锁优化?
在 JDK 1.6 之前,synchronized 是一个重量级锁,性能较低,因为每次获取锁都需要进行用户态和内核态的切换。JDK 1.6 对 synchronized 进行了重大优化,引入了偏向锁、轻量级锁、锁粗化、锁消除等技术,显著提高了其性能。以下是几种主要的锁优化方式:
偏向锁(Biased Locking):偏向锁是为了在没有竞争的情况下减少锁获取的开销而引入的。当一个线程第一次获取锁时,锁对象的 Mark Word 会记录该线程的 ID,称为偏向线程 ID。此后,该线程再次获取锁时,无需进行任何同步操作,直接获得锁,从而节省了大量的锁获取时间。只有当其他线程尝试竞争该锁时,偏向锁才会被撤销并升级为轻量级锁。
轻量级锁(Lightweight Locking):轻量级锁是为了在竞争不激烈的情况下避免重量级锁的性能开销而设计的。当线程获取锁时,如果锁对象处于无锁状态(Mark Word 中存储的是对象的哈希码等信息),JVM 会在当前线程的栈帧中创建一个锁记录(Lock Record),并通过 CAS(Compare-And-Swap)操作将锁对象的 Mark Word 复制到锁记录中,同时将 Mark Word 指向锁记录的指针。如果 CAS 操作成功,线程获得轻量级锁;如果失败,表示有其他线程竞争锁,锁会升级为重量级锁。
锁粗化(Lock Coarsening):锁粗化是指将多个连续的加锁、解锁操作合并为一次加锁、解锁操作,以减少锁的获取和释放次数。例如,在循环中频繁加锁解锁的代码,JVM 会将锁的范围扩展到循环外部,避免多次获取和释放锁。
// 优化前
for (int i = 0; i < 100; i++) {synchronized (this) {// 业务逻辑}
}// 优化后(锁粗化)
synchronized (this) {for (int i = 0; i < 100; i++) {// 业务逻辑}
}
锁消除(Lock Elimination):锁消除是指 JVM 在编译时通过逃逸分析技术,发现某些代码中使用的锁对象不会被其他线程访问,从而将这些锁操作消除。例如,在方法内部创建的局部对象作为锁,并且该对象不会逃逸到方法外部,JVM 会消除对该对象的锁操作。
public void method() {Object lock = new Object();synchronized (lock) {// 业务逻辑,lock对象不会逃逸到方法外部}
}// JVM可能会优化为
public void method() {// 业务逻辑
}
锁升级(Lock Inflation):锁升级是指锁状态随着竞争情况逐渐升级的过程。锁的状态从无锁状态开始,依次经历偏向锁、轻量级锁,最终升级为重量级锁。这种设计使得锁能够根据实际竞争情况动态调整,在不同场景下都能提供较好的性能。
自旋锁(Spin Lock):自旋锁是指当线程尝试获取锁失败时,不会立即进入阻塞状态,而是进行一段时间的自旋(循环等待),看锁是否会被释放。如果在自旋期间锁被释放,线程可以立即获得锁,避免了线程切换的开销。自旋锁适用于锁持有时间较短的场景。JDK 1.6 引入了自适应自旋锁,根据以往的自旋成功率、时间等因素自动调整自旋的时间。
在实际开发中,可以通过以下方式进一步优化 synchronized 的使用:
- 减小锁的粒度:将大的同步块拆分为多个小的同步块,减少锁的持有时间,从而降低锁竞争的可能性。
- 使用替代方案:在某些场景下,可以使用更细粒度的锁(如
ReentrantLock)或原子类(如AtomicInteger)来替代synchronized,以获得更好的性能。 - 避免锁的嵌套:锁的嵌套会增加死锁的风险,同时也会降低性能。
- 优化代码逻辑:减少同步代码块中的耗时操作,如 IO 操作、网络请求等。
通过合理使用这些锁优化技术,可以显著提高 synchronized 的性能,使其在大多数场景下不再成为性能瓶颈。
CAS(Compare-And-Swap)存在哪些问题?
CAS(Compare-And-Swap)是一种无锁算法,用于实现多线程环境下的原子操作。它通过比较内存中的值与预期值是否相等,如果相等则将内存中的值更新为新值,整个操作是原子性的。CAS 是 Java 中原子类(如 AtomicInteger、AtomicLong)和并发工具(如 ReentrantLock)的基础实现机制。然而,CAS 虽然避免了锁的使用,但也存在一些问题和局限性。
ABA 问题:CAS 操作需要检查内存中的值是否与预期值相同,如果相同则更新。但如果内存中的值从 A 变为 B,再从 B 变回 A,CAS 操作会认为值没有发生变化,从而成功更新。这种情况下,虽然 CAS 操作成功,但实际上值已经经历了变化,可能会导致一些潜在的问题。例如,在链表操作中,ABA 问题可能会导致链表结构被破坏。
解决 ABA 问题的方法是引入版本号或时间戳,每次值发生变化时增加版本号。Java 中的 AtomicStampedReference 和 AtomicMarkableReference 就是为了解决 ABA 问题而设计的。AtomicStampedReference 维护一个版本号,CAS 操作不仅检查值是否相等,还检查版本号是否一致。
import java.util.concurrent.atomic.AtomicStampedReference;public class ABADemo {private static AtomicStampedReference<Integer> atomicStampedRef = new AtomicStampedReference<>(100, 0);public static void main(String[] args) {Thread t1 = new Thread(() -> {try {int stamp = atomicStampedRef.getStamp();System.out.println("Thread-1 stamp: " + stamp);Thread.sleep(1000); // 等待t2完成ABA操作boolean success = atomicStampedRef.compareAndSet(100, 101, stamp, stamp + 1);System.out.println("Thread-1 CAS: " + success);} catch (InterruptedException e) {e.printStackTrace();}});Thread t2 = new Thread(() -> {int stamp = atomicStampedRef.getStamp();System.out.println("Thread-2 stamp: " + stamp);atomicStampedRef.compareAndSet(100, 101, stamp, stamp + 1);System.out.println("Thread-2 stamp after first CAS: " + atomicStampedRef.getStamp());stamp = atomicStampedRef.getStamp();atomicStampedRef.compareAndSet(101, 100, stamp, stamp + 1);System.out.println("Thread-2 stamp after second CAS: " + atomicStampedRef.getStamp());});t1.start();t2.start();}
}
循环时间长开销大:CAS 通常是通过循环(自旋)来实现的,如果长时间自旋仍无法成功获取锁,会给 CPU 带来较大的开销。特别是在竞争激烈的情况下,大量线程不断进行 CAS 操作但始终失败,会导致 CPU 使用率飙升,系统性能下降。
为了避免这种情况,可以设置自旋的最大次数或最长时间,超过阈值后放弃自旋,进入阻塞状态。JDK 中的 ReentrantLock 就是采用了这种方式,在公平锁模式下,当线程无法获取锁时会进入队列等待,而不是无限自旋。
只能保证一个共享变量的原子操作:CAS 操作只能对单个内存地址进行原子性的比较和交换。如果需要同时保证多个共享变量的原子性,CAS 就无法直接实现。在这种情况下,可以考虑以下几种解决方案:
- 将多个变量合并为一个对象,使用
AtomicReference来保证对象的原子性。 - 使用锁(如
synchronized或ReentrantLock)来保证多个变量的原子性操作。 - 使用
StampedLock提供的乐观读锁机制,在某些场景下可以提高并发性能。
缓存行伪共享(False Sharing):在多核心 CPU 中,每个核心都有自己的缓存行(Cache Line)。当多个线程同时操作不同的变量,但这些变量位于同一个缓存行中时,会导致缓存行伪共享问题。一个线程对缓存行的修改会导致其他核心的缓存行失效,需要重新从主内存加载数据,从而降低性能。
解决缓存行伪共享问题的方法是进行缓存行填充(Padding),使每个变量单独占用一个缓存行。Java 8 引入了 @Contended 注解来自动进行缓存行填充,也可以通过手动添加无用字段的方式来实现。
// 使用@Contended注解避免伪共享
@sun.misc.Contended
public class ContendedExample {public volatile long value1 = 0L;public volatile long value2 = 0L;
}// 手动填充实现
public class PaddingExample {public volatile long p1, p2, p3, p4, p5, p6, p7; // 填充前public volatile long value1 = 0L;public volatile long p8, p9, p10, p11, p12, p13, p14; // 填充后public volatile long value2 = 0L;
}
虽然 CAS 存在这些问题,但在合适的场景下,它仍然是一种高效的并发控制机制。与锁相比,CAS 具有更低的开销和更好的可扩展性,特别适合在竞争不激烈、操作简单的场景下使用。在实际开发中,应根据具体业务场景选择合适的并发控制方式。
线程池的核心组件有哪些?(corePoolSize 核心线程数、maximumPoolSize 最大线程数、keepAliveTime 非核心线程超时时间、workQueue 任务队列、threadFactory 线程工厂、handler 拒绝策略)
线程池是 Java 中用于管理和复用线程的机制,通过预先创建一定数量的线程,避免了频繁创建和销毁线程带来的性能开销。Java 中的线程池由 ThreadPoolExecutor 类实现,其核心组件包括以下六个部分:
corePoolSize(核心线程数):线程池的基本大小,当提交的任务数小于 corePoolSize 时,线程池会创建新的线程来执行任务,即使其他核心线程处于空闲状态。核心线程创建后不会被销毁,除非设置了 allowCoreThreadTimeOut 为 true,此时核心线程在空闲时间超过 keepAliveTime 后也会被销毁。
maximumPoolSize(最大线程数):线程池允许创建的最大线程数。当提交的任务数超过 corePoolSize 且任务队列已满时,线程池会创建新的线程,直到线程数达到 maximumPoolSize。如果任务数继续增加,超过 maximumPoolSize,则会触发拒绝策略。
keepAliveTime(非核心线程超时时间):当线程池中的线程数量超过 corePoolSize 时,多余的线程(非核心线程)在空闲时间超过 keepAliveTime 后会被销毁。如果设置了 allowCoreThreadTimeOut 为 true,则该参数也适用于核心线程。
workQueue(任务队列):用于存储等待执行的任务的阻塞队列。当提交的任务数超过 corePoolSize 时,新任务会被放入任务队列中等待执行。Java 提供了多种阻塞队列实现,常见的有:
- ArrayBlockingQueue:基于数组的有界阻塞队列,需要指定队列大小。
- LinkedBlockingQueue:基于链表的阻塞队列,可以是有界或无界的。Executors.newFixedThreadPool () 使用的是无界的 LinkedBlockingQueue。
- SynchronousQueue:不存储元素的阻塞队列,每个插入操作必须等待另一个线程的移除操作,反之亦然。Executors.newCachedThreadPool () 使用的是 SynchronousQueue。
- PriorityBlockingQueue:基于优先级的无界阻塞队列,元素需要实现 Comparable 接口。
threadFactory(线程工厂):用于创建线程的工厂类,通过线程工厂可以自定义线程的名称、优先级、是否为守护线程等属性。默认情况下,线程池使用 Executors.defaultThreadFactory() 创建线程。在实际应用中,建议自定义线程工厂,以便于线程的管理和监控。
import java.util.concurrent.*;public class CustomThreadFactory implements ThreadFactory {private final String namePrefix;private final AtomicInteger threadNumber = new AtomicInteger(1);public CustomThreadFactory(String poolName) {this.namePrefix = poolName + "-thread-";}@Overridepublic Thread newThread(Runnable r) {Thread t = new Thread(r, namePrefix + threadNumber.getAndIncrement());if (t.isDaemon()) {t.setDaemon(false);}if (t.getPriority() != Thread.NORM_PRIORITY) {t.setPriority(Thread.NORM_PRIORITY);}return t;}
}
handler(拒绝策略):当线程池中的线程数量达到 maximumPoolSize 且任务队列已满时,新提交的任务会触发拒绝策略。Java 提供了四种内置的拒绝策略:
- AbortPolicy(默认):直接抛出
RejectedExecutionException异常,阻止系统正常运行。 - CallerRunsPolicy:由调用线程(提交任务的线程)直接执行该任务,从而降低新任务的提交速度。
- DiscardPolicy:默默丢弃无法处理的任务,不做任何处理。
- DiscardOldestPolicy:丢弃任务队列中最老的任务(即队列头部的任务),然后尝试重新提交新任务。
除了内置的拒绝策略,还可以通过实现 RejectedExecutionHandler 接口来自定义拒绝策略。
线程池的工作流程可以概括为:
- 提交任务时,线程池首先检查核心线程数是否已满,如果未满则创建新线程执行任务。
- 如果核心线程数已满,则将任务放入任务队列。
- 如果任务队列已满,且线程数未达到 maximumPoolSize,则创建新线程执行任务。
- 如果线程数已达到 maximumPoolSize,则触发拒绝策略。
合理配置线程池的核心组件对于系统性能至关重要。例如,对于 CPU 密集型任务,应设置较小的核心线程数(如 CPU 核心数 + 1);对于 IO 密集型任务,可设置较大的核心线程数(如 CPU 核心数 * 2)。任务队列的选择也需要根据业务场景进行调整,避免使用无界队列导致内存溢出。
任务提交到线程池后执行流程是怎样的?
任务提交到线程池后的执行流程是一个多阶段的决策过程,涉及线程池的核心线程、任务队列和最大线程数等组件的协同工作。理解这一流程对于合理配置线程池参数和优化系统性能至关重要。
当一个任务通过 execute() 或 submit() 方法提交到线程池时,线程池会按照以下步骤进行处理:
首先检查线程池的核心线程数是否已满。如果核心线程数小于 corePoolSize,即使此时有空闲的核心线程,线程池也会创建一个新的线程来执行该任务。这一策略确保了核心线程能够被充分利用。
若核心线程数已满,线程池会将任务放入任务队列(workQueue)中等待执行。任务队列的类型和容量决定了后续的处理逻辑。例如,使用有界队列(如 ArrayBlockingQueue)时,队列可能会被填满;而使用无界队列(如 LinkedBlockingQueue)时,队列几乎不会被填满,但可能导致系统资源耗尽。
若任务队列已满,线程池会检查当前线程数是否达到 maximumPoolSize。如果未达到,线程池会创建一个新的非核心线程来执行该任务。这些非核心线程在空闲时间超过 keepAliveTime 后会被销毁,以节省资源。
若线程数已达到 maximumPoolSize,线程池会触发拒绝策略(handler)来处理无法执行的任务。内置的拒绝策略包括抛出异常(AbortPolicy)、由调用线程执行(CallerRunsPolicy)、丢弃任务(DiscardPolicy)或丢弃最老的任务(DiscardOldestPolicy)。
这一流程可以用以下伪代码表示:
if (线程数 < corePoolSize) {创建新线程执行任务
} else if (任务队列未满) {将任务放入队列
} else if (线程数 < maximumPoolSize) {创建新线程执行任务
} else {执行拒绝策略
}
值得注意的是,线程池的状态也会影响任务的执行。例如,当线程池被关闭(shutdown 或 shutdownNow)后,新提交的任务会被拒绝。此外,如果任务执行过程中抛出异常,线程会被销毁,但线程池会创建一个新的线程来替代它。
在实际应用中,合理配置线程池参数至关重要。例如,对于 CPU 密集型任务,应避免设置过大的线程数,以免增加上下文切换开销;对于 IO 密集型任务,可以设置较多的线程数以提高并发度。通过理解任务提交后的执行流程,可以更有针对性地调整线程池配置,优化系统性能。
如何设置核心线程数与最大线程数?为什么设置核心线程数要参考 CPU 核数?
设置线程池的核心线程数(corePoolSize)和最大线程数(maximumPoolSize)需要综合考虑任务类型、系统资源和性能需求。合理的配置可以充分利用系统资源,避免线程过多导致的上下文切换开销或线程过少导致的资源浪费。
对于 CPU 密集型任务,核心线程数应接近或等于 CPU 核心数。这是因为 CPU 密集型任务几乎不等待 IO 操作,线程一直占用 CPU 资源。如果线程数过多,会导致频繁的上下文切换,增加系统开销。例如,对于一个 8 核的 CPU,设置核心线程数为 8 或 9(考虑到可能的额外开销)是比较合适的。计算公式可表示为:corePoolSize = CPU 核心数 + 1。
对于 IO 密集型任务,核心线程数可以设置得较大,因为 IO 操作会使线程长时间处于等待状态,CPU 资源利用率较低。此时增加线程数可以提高并发度,充分利用 CPU 资源。一般来说,IO 密集型任务的核心线程数可以设置为 CPU 核心数的两倍左右,计算公式为:corePoolSize = 2 * CPU 核心数。更精确的计算可以基于任务的等待时间与计算时间的比例:corePoolSize = CPU 核心数 * (1 + 等待时间/计算时间)。
最大线程数(maximumPoolSize)的设置需要结合任务队列的类型。如果使用无界队列(如 LinkedBlockingQueue),则最大线程数参数无效,因为任务会不断进入队列等待,不会触发创建新线程的条件。此时应谨慎使用无界队列,避免系统资源耗尽。如果使用有界队列(如 ArrayBlockingQueue),最大线程数应根据系统能够承受的最大并发量来设置,防止过多线程导致系统崩溃。
设置核心线程数参考 CPU 核数的主要原因是为了避免 CPU 资源的浪费或过度竞争。当线程数接近 CPU 核心数时,每个 CPU 核心可以被充分利用,减少空闲时间。而当线程数远大于 CPU 核心数时,会导致多个线程竞争同一个 CPU 核心,增加上下文切换的频率,降低系统性能。上下文切换需要保存和恢复线程的状态,消耗 CPU 时间,过多的上下文切换会使系统吞吐量下降。
此外,还应考虑系统的其他资源限制,如内存、网络带宽等。如果线程数过多,每个线程占用的内存资源会累积,可能导致内存溢出。因此,在设置线程数时,需要综合考虑任务特性、CPU 核心数、内存容量等因素,通过性能测试不断调整,找到最优配置。
常见的线程池类型有哪些?(如 CachedThreadPool、SingleThreadPool、ScheduledThreadPool、FixedThreadPool)
Java 提供了多种预定义的线程池类型,每种类型都针对特定的场景进行了优化。这些线程池可以通过 Executors 工厂类快速创建,也可以手动配置 ThreadPoolExecutor 来实现更灵活的控制。
CachedThreadPool:可缓存的线程池,通过 Executors.newCachedThreadPool() 创建。它的核心线程数为 0,最大线程数为 Integer.MAX_VALUE,使用 SynchronousQueue 作为任务队列。这种线程池的特点是线程可以无限扩展,适合处理大量短时间的异步任务。当有新任务提交时,如果没有空闲线程,会立即创建一个新线程;如果线程空闲时间超过 60 秒,会被自动回收。由于线程数可以无限增长,使用时需要注意控制任务数量,避免系统资源耗尽。
SingleThreadPool:单线程的线程池,通过 Executors.newSingleThreadExecutor() 创建。它的核心线程数和最大线程数都为 1,使用无界的 LinkedBlockingQueue 作为任务队列。这种线程池确保所有任务按照提交顺序依次执行,适合需要保证任务顺序执行的场景。即使任务抛出异常,线程池也会创建一个新线程继续执行后续任务。
ScheduledThreadPool:定时任务线程池,通过 Executors.newScheduledThreadPool(int corePoolSize) 创建。它的核心线程数由用户指定,最大线程数为 Integer.MAX_VALUE,使用 DelayedWorkQueue 作为任务队列。这种线程池适用于需要定时执行或周期性执行的任务,支持延迟执行和固定频率执行。例如,可以使用 scheduleAtFixedRate() 方法按固定频率执行任务,或使用 scheduleWithFixedDelay() 方法在任务执行完成后延迟固定时间再执行。
FixedThreadPool:固定大小的线程池,通过 Executors.newFixedThreadPool(int nThreads) 创建。它的核心线程数和最大线程数都为用户指定的值,使用无界的 LinkedBlockingQueue 作为任务队列。这种线程池适用于需要控制并发线程数的场景,线程数固定,不会创建过多线程导致系统资源耗尽。当所有线程都在执行任务时,新任务会在队列中等待。
WorkStealingPool(Java 8 引入):工作窃取线程池,通过 Executors.newWorkStealingPool() 创建。它基于 ForkJoinPool 实现,使用多个工作队列,不同线程可以从其他线程的队列中窃取任务执行。这种线程池适合处理分治型任务,能够充分利用多核 CPU 的并行能力,提高系统吞吐量。
这些预定义的线程池虽然使用方便,但在实际生产环境中可能存在一些风险。例如,CachedThreadPool 和 ScheduledThreadPool 的最大线程数为 Integer.MAX_VALUE,可能导致创建过多线程耗尽系统资源;SingleThreadPool 和 FixedThreadPool 使用无界队列,可能导致任务堆积引发内存溢出。因此,建议手动配置 ThreadPoolExecutor,根据实际需求设置合理的参数,如核心线程数、最大线程数、任务队列类型和拒绝策略等。
JVM 内存分布是怎样的?
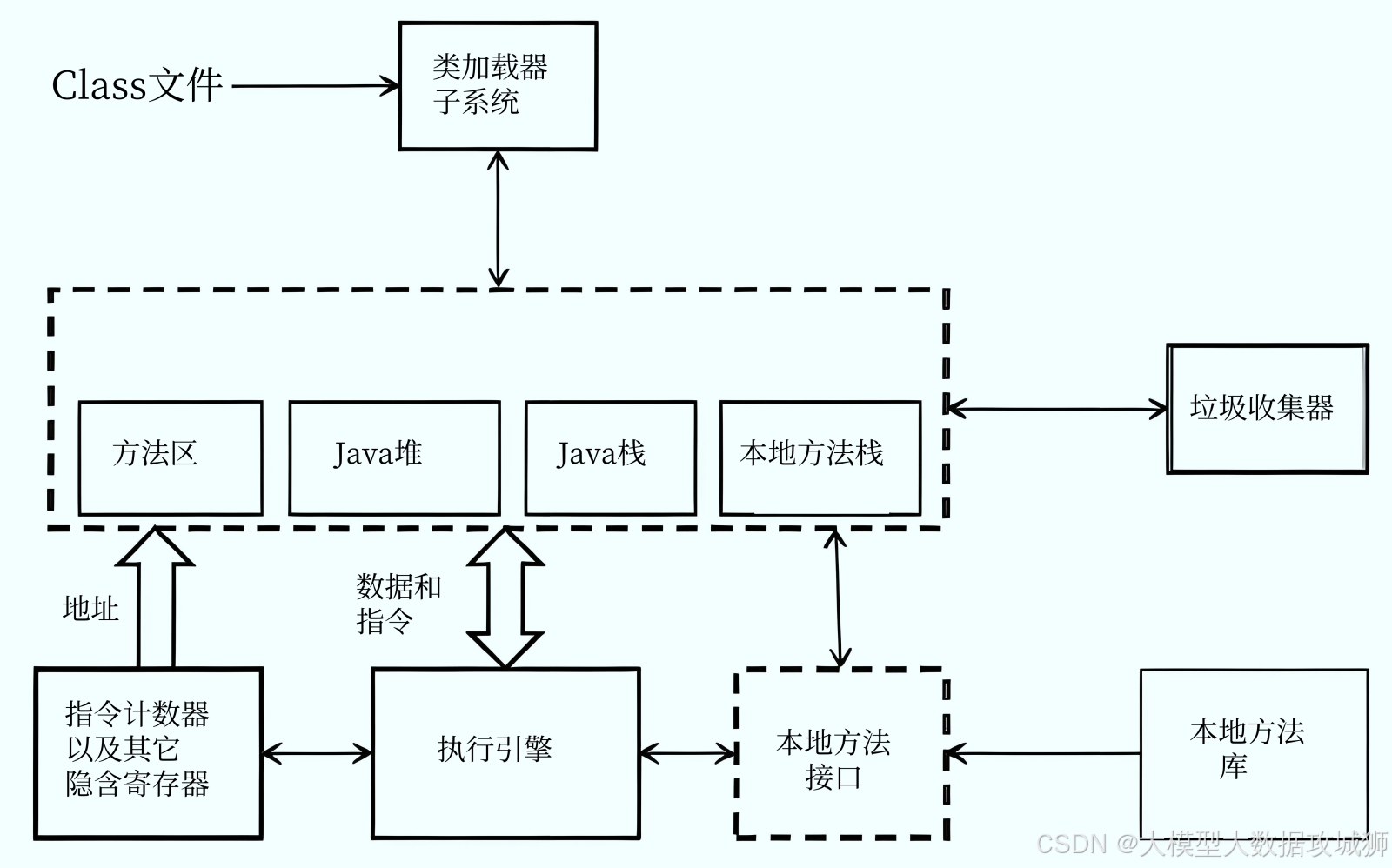
JVM 内存分布是指 Java 虚拟机在运行时将内存划分为不同的区域,每个区域有不同的用途和生命周期。理解 JVM 内存分布对于优化 Java 应用性能、排查内存泄漏和解决 OutOfMemoryError 等问题至关重要。
堆(Heap):Java 堆是 JVM 管理的最大一块内存区域,所有对象实例和数组都在堆上分配。堆是线程共享的,在 JVM 启动时创建。堆内存又分为新生代和老年代,新生代进一步分为 Eden 区和两个 Survivor 区(From 和 To)。堆的大小可以通过 -Xms 和 -Xmx 参数设置,当堆内存不足时,会抛出 OutOfMemoryError: Java heap space。
方法区(Method Area):方法区也是线程共享的内存区域,用于存储类的结构信息,如类的字节码、常量池、静态变量、构造函数等数据。在 JDK 1.8 之前,方法区也被称为永久代(PermGen),但从 JDK 1.8 开始,永久代被元空间(Metaspace)取代。元空间使用本地内存(Native Memory)而不是堆内存,避免了永久代的内存溢出问题。方法区的大小可以通过 -XX:MetaspaceSize 和 -XX:MaxMetaspaceSize 参数控制。
虚拟机栈(VM Stack):虚拟机栈是线程私有的,每个线程在创建时都会创建一个虚拟机栈。虚拟机栈由多个栈帧(Stack Frame)组成,每个栈帧对应一个方法调用。栈帧中存储局部变量表、操作数栈、动态链接和方法出口等信息。当方法被调用时,会创建一个新的栈帧并压入栈顶;方法执行完毕后,栈帧被弹出并销毁。虚拟机栈的深度可以通过 -Xss 参数设置,当栈深度超过限制时,会抛出 StackOverflowError。
本地方法栈(Native Method Stack):本地方法栈与虚拟机栈类似,也是线程私有的,但它服务于本地方法(使用 native 关键字修饰的方法)。本地方法栈使用本地方法库实现,不同的 JVM 实现可能有所不同。当本地方法栈溢出时,也会抛出 StackOverflowError。
程序计数器(Program Counter Register):程序计数器是线程私有的,它可以看作是当前线程所执行的字节码的行号指示器。在 JVM 执行字节码时,程序计数器会不断更新,指示下一条要执行的字节码指令。如果线程执行的是 native 方法,程序计数器的值为 undefined。程序计数器是唯一不会出现 OutOfMemoryError 的内存区域。
直接内存(Direct Memory):直接内存不属于 JVM 运行时数据区的一部分,但它也被频繁使用。直接内存通过 ByteBuffer 的 allocateDirect() 方法分配,使用本地内存,避免了 Java 堆和本地内存之间的数据复制,提高了 IO 操作的效率。直接内存的大小不受 Java 堆大小的限制,但受操作系统总内存的限制,当直接内存耗尽时,会抛出 OutOfMemoryError: Direct buffer memory。
JVM 内存分布的各个区域相互协作,共同支持 Java 程序的运行。合理配置各区域的大小和参数,对于优化应用性能和避免内存问题至关重要。例如,对于堆内存,可以根据应用的对象创建和销毁频率,调整新生代和老年代的比例;对于方法区,可以根据加载的类数量,合理设置元空间的大小。
JVM 分代回收机制的原理是什么?
JVM 分代回收机制是基于对象存活周期的不同将内存划分为不同的区域,针对每个区域的特点采用不同的垃圾回收策略,从而提高垃圾回收的效率。这种机制的核心思想是 "大部分对象的生命周期很短,只有少数对象能存活很长时间",因此可以对不同生命周期的对象采取不同的回收策略。
JVM 将堆内存分为新生代(Young Generation)和老年代(Old Generation)。新生代又进一步分为 Eden 区和两个 Survivor 区(通常称为 From 和 To)。这种分代设计的目的是为了优化垃圾回收过程,减少垃圾回收对应用程序的影响。
新生代(Young Generation):大多数对象在创建时会被分配到新生代的 Eden 区。当 Eden 区满时,会触发一次 Minor GC(新生代垃圾回收)。在 Minor GC 过程中,存活的对象会被移动到其中一个 Survivor 区(如 From 区),同时清空 Eden 区。如果 Survivor 区空间不足,部分对象会被直接晋升到老年代。经过多次 Minor GC 后,仍然存活的对象会从一个 Survivor 区移动到另一个 Survivor 区,并且对象的年龄(经历 GC 的次数)会增加。当对象的年龄达到一定阈值(默认 15 次)时,会被晋升到老年代。
老年代(Old Generation):老年代用于存储生命周期较长的对象,如静态变量引用的对象、缓存对象等。当老年代空间不足时,会触发一次 Major GC 或 Full GC(全量垃圾回收)。Full GC 会回收整个堆内存,包括新生代、老年代和方法区(元空间)。由于 Full GC 涉及的内存区域较大,因此会导致较长的停顿时间,影响应用的性能。
分代回收的优势:分代回收机制通过将对象按生命周期分类,针对不同区域采用不同的回收策略,提高了垃圾回收的效率。对于新生代,由于对象存活率低,Minor GC 可以快速回收大量垃圾对象,且采用复制算法(将存活对象复制到 Survivor 区),内存分配和回收速度快。对于老年代,对象存活率高,采用标记 - 清除或标记 - 整理算法更合适,减少了内存碎片的产生。
垃圾回收器的协作:不同的垃圾回收器在分代回收机制中扮演不同的角色。例如,Serial 收集器是一个单线程的收集器,适用于小型应用;Parallel 收集器是多线程的,适用于注重吞吐量的应用;CMS(Concurrent Mark Sweep)收集器是并发的,适用于注重响应时间的应用;G1(Garbage-First)收集器是一种面向服务器的垃圾回收器,将堆内存划分为多个大小相等的区域,动态管理垃圾回收过程。
分代回收的触发条件:
- Minor GC:当 Eden 区空间不足时触发。
- Major GC:当老年代空间不足时触发,通常会伴随一次 Minor GC。
- Full GC:当老年代、元空间或堆外内存不足时触发,或者手动调用
System.gc()时触发。
JVM 分代回收机制通过合理划分内存区域和采用不同的回收策略,有效地提高了垃圾回收的效率,减少了垃圾回收对应用程序的影响。在实际应用中,可以根据应用的特点和性能需求,选择合适的垃圾回收器和调整相关参数,以达到最佳的性能表现。
TCP 和 UDP 的区别是什么?
TCP(传输控制协议)和 UDP(用户数据报协议)是传输层的两种核心协议,二者在设计目标、特性和应用场景上有显著差异。
从连接特性来看,TCP 是面向连接的协议。通信双方在传输数据前需要通过 “三次握手” 建立连接,传输完成后通过 “四次挥手” 释放连接,确保通信链路的可靠性。而 UDP 是无连接的,发送端无需建立连接即可直接发送数据报,接收端也无需确认,因此通信流程更简单,但缺乏连接状态的管理。
可靠性机制是二者的核心区别。TCP 具备完善的可靠性保障机制,包括数据校验、序列号、确认应答、超时重传、流量控制和拥塞控制等。例如,发送端会为每个数据段分配序列号,接收端通过确认应答告知发送端数据已成功接收,若超时未收到确认则重新发送数据,确保数据无丢失、无重复且按序到达。UDP 则不提供这些机制,数据报一旦发出便不再跟踪其状态,可能出现丢失、乱序或重复的情况,可靠性完全由应用层负责。
传输效率与延迟方面,UDP 的无连接特性和缺乏复杂机制使其传输效率更高,延迟更低。由于无需建立连接和维护状态,UDP 的头部开销较小(仅 8 字节),适合对实时性要求高、允许一定数据丢失的场景。TCP 因需要处理连接管理和可靠性机制,头部开销较大(20 字节,可扩展至 60 字节),且存在确认和重传的时间延迟,更适合对数据完整性要求严格的场景。
数据单位与传输方式上,TCP 以字节流的形式传输数据,发送端和接收端通过滑动窗口机制动态调整传输速率,数据无边界,应用层需要自行处理消息边界。UDP 以数据报为单位传输,每个数据报包含完整的源地址和目的地址,具有明确的边界,适合传输小数据块。
应用场景的差异源于上述特性。TCP 常用于文件传输(FTP)、电子邮件(SMTP、POP3)、网页浏览(HTTP/HTTPS)等需要高可靠性的场景;UDP 则适用于实时通信(如视频会议、直播、在线游戏)、传感器数据传输、DNS 查询等对延迟敏感或允许部分数据丢失的场景。
总结来看,TCP 以牺牲效率为代价换取可靠性,适合需要稳定传输的场景;UDP 以效率优先,适合对实时性要求高的场景。开发者需根据具体业务需求选择合适的协议。
TCP 和 UDP 的常用场景有哪些?
TCP(传输控制协议)和 UDP(用户数据报协议)的特性差异决定了它们在不同场景中的适用性。以下结合具体应用场景分析二者的典型应用。
TCP 的常用场景
-
文件传输与数据同步
文件传输(如 FTP、SFTP)需要确保文件内容完整无误,不允许数据丢失或损坏。TCP 的可靠性机制(如确认应答、超时重传)能保证每个字节都被正确接收,因此成为这类场景的首选。例如,企业内部通过 FTP 传输大型文件时,TCP 的稳定传输能力可避免因网络波动导致的文件损坏或传输中断。 -
网页浏览与应用层协议
HTTP 和 HTTPS 协议均基于 TCP 实现。网页内容(如 HTML、图片、视频)需要按顺序正确加载,若数据丢失或乱序会导致页面渲染异常。TCP 的流量控制和拥塞控制机制可适应复杂的网络环境,确保浏览器与服务器之间的稳定通信,例如用户通过 Chrome 访问电商网站时,TCP 保证商品图片和文字信息完整显示。 -
电子邮件与远程登录
电子邮件协议(SMTP、POP3、IMAP)依赖 TCP 传输邮件内容和附件,确保邮件在发送和接收过程中不丢失。远程登录协议(如 SSH、Telnet)也基于 TCP,保证用户输入的命令和服务器返回的结果按序传输,避免因数据乱序导致的操作错误。 -
数据库连接与事务处理
数据库系统(如 MySQL、Oracle)通过 TCP 建立连接,执行查询和事务操作。事务的原子性和一致性要求数据必须准确无误地传输,TCP 的可靠性机制可确保 SQL 语句和查询结果正确传递,例如银行转账操作中,TCP 保证扣款和入账信息的一致性。
UDP 的常用场景
-
实时音视频通信
视频会议(如 Zoom、腾讯会议)、直播(如抖音、B 站直播)和在线游戏(如《王者荣耀》《绝地求生》)对延迟极其敏感。UDP 无需建立连接且传输效率高,能降低数据传输的延迟,满足实时交互的需求。虽然可能出现少量数据丢失,但现代应用层协议(如 WebRTC)通过前向纠错(FEC)等机制弥补可靠性不足,例如游戏中偶尔丢失几个帧数据不会显著影响玩家体验,但延迟过高会导致操作卡顿。 -
传感器与物联网数据传输
物联网设备(如温湿度传感器、智能电表)通常需要频繁发送小数据量的状态信息,且部分场景允许一定数据丢失(如实时温度监控中偶尔漏读一次数据不影响整体趋势分析)。UDP 的低开销和快速传输特性适合这类场景,例如智能家居系统中,多个传感器通过 UDP 向网关发送状态数据,降低设备功耗和网络延迟。 -
DNS 查询与网络监控
DNS(域名系统)查询需要快速获取结果,单次查询的数据量小(通常为几十个字节),且 DNS 服务器通常会提供重试机制,因此 UDP 成为首选。例如,用户在浏览器中输入域名时,本地 DNS 客户端通过 UDP 向 DNS 服务器发送查询请求,迅速获取 IP 地址。此外,网络监控工具(如 SNMP)也常使用 UDP 传输监控数据,减少对被监控设备的资源占用。 -
实时消息推送与日志采集
实时消息推送(如新闻通知、社交 app 消息)和日志采集系统(如分布式日志服务)通常要求高吞吐量和低延迟,允许部分消息丢失(如重复推送一条通知对用户影响不大)。UDP 的无连接特性使其能快速处理大量并发请求,例如移动应用通过 UDP 向用户推送实时新闻,即使少量数据包丢失也不影响整体体验。
选择协议的核心逻辑
- 优先选 TCP:当业务需要高可靠性(如金融交易、文件传输)、数据有序性(如流媒体点播)或复杂交互(如客户端 - 服务器通信)时,TCP 是更合适的选择。
- 优先选 UDP:当业务需要低延迟(如实时音视频)、高吞吐量(如大数据采集)或简单交互(如单次查询)时,UDP 更能发挥优势,且应用层需自行处理可靠性问题(如有必要)。
TCP 如何保证可靠性?具体有哪些机制?
TCP(传输控制协议)通过一系列复杂机制确保数据在不可靠的网络环境中可靠传输,其核心目标是保证数据无丢失、无重复、按序到达,并适应网络拥塞和波动。以下是实现可靠性的关键机制及其工作原理。
1. 序列号与确认应答(ACK)
- 序列号机制:发送端为每个字节的数据分配唯一的序列号(Sequence Number),用于标识数据在字节流中的位置。例如,假设初始序列号为 100,发送 200 字节的数据段,则下一个数据段的序列号为 300。
- 确认应答机制:接收端收到数据后,向发送端返回确认应答(ACK),其中包含期望接收的下一个字节的序列号(即确认号 Acknowledgment Number)。例如,接收端成功收到序列号 100 - 299 的数据后,会返回 ACK 300,表示 “已收到前 200 字节数据,期待接收从 300 开始的数据”。
- 作用:通过序列号和 ACK,发送端可跟踪数据的传输状态,接收端可检测数据是否重复或丢失,确保数据按序接收。
2. 超时重传(Retransmission)
- 原理:发送端在发送数据后启动定时器,若超时未收到对应的 ACK,会重新发送该数据段。超时时间(RTO,Retransmission Timeout)会根据网络往返时间(RTT,Round-Trip Time)动态调整,避免因网络延迟波动导致误判。
- 重传策略:
- 快重传:若接收端连续收到三个相同的 ACK(表明后续数据丢失),发送端无需等待超时,立即重传丢失的数据段,减少延迟。
- 重传队列:未确认的数据会被保存在重传队列中,直到收到对应的 ACK 才会移除,防止数据丢失。
3. 流量控制(Flow Control)
- 目的:避免发送端发送数据过快,导致接收端缓冲区溢出。
- 实现方式:接收端在 ACK 中携带自身接收缓冲区的剩余容量(即窗口大小 Window Size),发送端根据该值调整发送速率。例如,若接收端缓冲区剩余 1000 字节,发送端在收到 ACK 后最多发送 1000 字节数据,直到接收端释放更多缓冲区空间。
- 滑动窗口(Sliding Window):发送端维护一个滑动窗口,窗口内的数据可无需等待 ACK 连续发送,窗口大小由接收端的窗口大小和网络拥塞情况共同决定。窗口随数据确认而向右滑动,提高传输效率。
4. 拥塞控制(Congestion Control)
- 目的:防止网络中数据流量过大导致拥塞,避免路由器丢弃数据包。
- 核心算法:
- 慢启动(Slow Start):初始时拥塞窗口(CWND,Congestion Window)较小(通常为 1 - 2 个最大段大小 MSS),每次收到 ACK 后按指数增长(如从 1 到 2,再到 4、8 等),快速探测网络容量。
- 拥塞避免(Congestion Avoidance):当 CWND 超过阈值(ssthresh)后,转为线性增长(每次增加 1 个 MSS),避免网络拥塞。
- 快恢复(Fast Recovery):当检测到丢包(如收到三个重复 ACK),进入快恢复阶段,将 ssthresh 设为当前 CWND 的一半,CWND 设为 ssthresh + 3*MSS,然后转为拥塞避免,减少丢包后的性能损失。
- 作用:通过动态调整发送端的拥塞窗口,使数据流量与网络带宽匹配,降低丢包率。
5. 数据校验与丢弃重复数据
- 校验和(Checksum):发送端在数据段中添加校验和字段,接收端通过校验和验证数据是否在传输过程中损坏。若校验失败,直接丢弃该数据段,发送端会通过超时重传机制重新发送。
- 重复数据检测:接收端通过序列号判断数据是否重复,若收到重复的数据段,直接丢弃并返回相同的 ACK,避免重复处理数据。
6. 连接管理与状态机
- 三次握手建立连接:
- 客户端发送 SYN 包(序列号 seq = x),请求建立连接。
- 服务器返回 SYN + ACK 包(seq = y,ack = x + 1),确认客户端请求。
- 客户端返回 ACK 包(seq = x + 1,ack = y + 1),完成连接建立。
三次握手确保双方均确认对方的接收和发送能力,避免历史连接的干扰。
- 四次挥手释放连接:
双方均可主动关闭连接,通过四次交互确保所有数据已传输完毕,避免半关闭状态导致的数据丢失。
总结:可靠性机制的协同作用
TCP 的可靠性并非依赖单一机制,而是通过序列号与确认应答跟踪数据状态,超时重传弥补丢包,流量控制适配接收端能力,拥塞控制适应网络环境,校验和与重复检测保证数据完整性,以及连接管理确保通信链路稳定。这些机制相互配合,使 TCP 能在复杂的网络环境中提供稳定可靠的传输服务,成为文件传输、网页浏览等场景的基础协议。
拥塞控制和流量控制的区别是什么?
拥塞控制(Congestion Control)和流量控制(Flow Control)是 TCP 协议中两个关键机制,均用于调节数据传输速率,但二者的目标、作用范围和实现原理存在显著差异。以下从多个维度对比分析。
1. 核心目标不同
- 流量控制:
目标是适配接收端的处理能力,防止发送端发送数据过快导致接收端缓冲区溢出。例如,若接收端应用程序处理数据的速度较慢,接收缓冲区可能被填满,此时流量控制通过限制发送端的速率,避免数据丢失。 - 拥塞控制:
目标是适配网络的整体容量,防止网络中数据流量过大导致拥塞(如路由器队列溢出、丢包率上升)。例如,当多个发送端同时向同一网络路径发送大量数据时,可能超过路由器的处理能力,拥塞控制通过调节发送端的速率,避免网络瘫痪。
2. 作用范围不同
- 流量控制:
是端到端的控制,仅涉及发送端和接收端两个端点。接收端通过反馈自身缓冲区的剩余容量(窗口大小)直接控制发送端的速率,与中间网络设备(如路由器)无关。 - 拥塞控制:
是网络全局的控制,涉及发送端、接收端和中间网络设备。发送端需要根据网络中的拥塞信号(如丢包、延迟增加)调整速率,以避免整个网络出现拥塞,其影响范围包括路径上的所有节点。
3. 触发条件不同
- 流量控制:
触发条件是接收端的接收能力不足。例如,接收端应用程序因忙于处理其他任务而无法及时读取接收缓冲区的数据,导致缓冲区剩余空间减少,此时接收端通过减小窗口大小通知发送端降低速率。 - 拥塞控制:
触发条件是网络资源不足。例如,路由器的队列已满,无法处理更多数据包,导致丢包率上升,此时发送端通过检测丢包(如超时或收到重复 ACK)判断网络拥塞,并调整拥塞窗口大小以降低发送速率。
4. 实现机制不同
| 维度 | 流量控制 | 拥塞控制 |
|---|---|---|
| 关键参数 | 接收端窗口大小(Receiver Window, rwnd) | 拥塞窗口大小(Congestion Window, cwnd) |
| 控制信号 | 接收端在 ACK 中携带 rwnd 值 | 发送端根据丢包、RTT 等信号调整 cwnd |
| 算法逻辑 | 基于接收端反馈的窗口大小直接限制发送速率 | 使用慢启动、拥塞避免、快重传、快恢复等算法 |
| 典型场景 | 接收端处理能力突然下降(如手机切换后台) | 网络中多用户竞争带宽(如视频直播高峰期) |
5. 对传输速率的影响
- 流量控制:
可能导致发送速率长期低于网络容量。例如,若接收端处理能力极低(如 rwnd = 0),发送端会停止发送数据,即使网络本身有足够带宽。 - 拥塞控制:
动态平衡网络容量与发送速率。在网络空闲时,发送端通过慢启动快速提升速率;在网络拥塞时,通过降低 cwnd 避免丢包,确保速率与网络容量匹配。
6. 协同工作方式
尽管二者目标和机制不同,但在 TCP 中协同作用以优化传输效率:
- 流量控制是基础:确保数据不会压垮接收端,是端到端可靠性的基本保障。
- 拥塞控制是扩展:在流量控制的基础上,进一步避免网络拥塞,提升整体网络利用率。
- 示例:当发送端的 cwnd 受限于 rwnd 时(即接收端处理能力低于网络容量),流量控制起主导作用;当 cwnd 受限于网络拥塞时(如 cwnd 超过路由器队列容量),拥塞控制起主导作用。
总结:核心差异与实际意义
- 流量控制解决的是发送端与接收端之间的局部匹配问题,关注接收端的 “个体承受能力”;
- 拥塞控制解决的是发送端与整个网络之间的全局协调问题,关注网络的 “整体负载平衡”。
理解二者的区别有助于在网络优化中精准定位问题:若接收端缓冲区频繁溢出,需优化流量控制参数;若网络频繁出现丢包和延迟,需调整拥塞控制策略。两者共同确保 TCP 在复杂网络环境中既不 “压垮接收端”,也不 “堵塞网络”,实现高效可靠的传输。
如何理解 Redis 的 IO 多路复用?
Redis 的 IO 多路复用(IO Multiplexing)是其实现高性能网络通信的核心技术,尤其在处理大量客户端连接时,能显著提升资源利用率和响应速度。理解这一机制需要从问题背景、核心原理、具体实现和实际效果四个层面展开。
一、问题背景:传统 IO 模型的瓶颈
在传统的网络编程中,服务器处理多个客户端连接通常有两种方式:
- 多线程 / 多进程模型:为每个客户端创建独立的线程或进程处理请求。这种方式在客户端数量较少时有效,但当连接数激增(如数万级),线程 / 进程的创建、销毁和上下文切换会消耗大量系统资源,导致性能急剧下降。
- 阻塞式 IO 循环模型:单线程通过循环依次处理每个客户端连接,若某个连接阻塞(如等待数据读取),会导致整个线程阻塞,无法处理其他连接,实时性差。
Redis 作为内存数据库,需要同时处理大量短连接请求(如每秒数万次读写),上述模型均无法满足性能需求。IO 多路复用通过单线程管理多个文件描述符(FD,File Descriptor),避免了多线程的开销,同时解决了阻塞式 IO 的低效问题。
二、核心原理:事件驱动与文件描述符监控
IO 多路复用的核心思想是:用一个或少数几个线程监控多个文件描述符的 IO 事件(如可读、可写、异常),当某个文件描述符就绪时,触发相应的事件处理函数。具体流程如下:
- 注册事件:将客户端连接的文件描述符注册到多路复用器(Multiplexer)中,并为每个描述符关联读、写等事件的回调函数。
- 等待事件:多路复用器阻塞等待任意一个文件描述符就绪(即有数据可读或可写)。
- 分发事件:当检测到就绪的文件描述符时,多路复用器将事件分发给对应的回调函数处理,处理完成后重新回到等待状态。
这一过程中,单线程通过非阻塞 IO 系统调用(如 select/poll/epoll)避免阻塞,仅在有事件就绪时才执行实际的 IO 操作,从而在单线程内高效处理多个连接。
三、Redis 对多路复用的具体实现
Redis 基于操作系统提供的多路复用 API 实现事件驱动机制,并根据不同系统自动选择最优方案:
- select/poll:早期操作系统普遍支持的接口,但存在明显缺陷:
- select:可监控的文件描述符数量受限(通常为 1024),且采用轮询方式遍历所有描述符,时间复杂度为 O (n),性能随连接数增加而下降。
- poll:通过链表存储描述符,突破了 select 的数量限制,但本质仍是轮询,效率未根本提升。
- epoll(Linux)/kqueue(BSD):现代高性能接口,采用事件通知机制:
- epoll:通过 epoll_ctl () 注册描述符,epoll_wait () 阻塞等待事件,当描述符就绪时通过回调函数主动通知,时间复杂度为 O (1)(仅处理就绪事件),支持数万级连接。
- kqueue:BSD 系统(如 macOS)的类似机制,功能与 epoll 类似,支持高效的事件驱动。
Redis 通过 aeEventLoop 结构体管理事件循环,核心组件包括:
- aeFileEvent:存储文件描述符的事件类型(读 / 写)和回调函数。
- aeTimeEvent:处理定时事件(如心跳检测、过期键删除)。
- aeMain():主循环函数,不断调用多路复用接口等待事件,然后依次处理就绪的文件事件和定时事件。
四、IO 多路复用带来的优势
- 单线程高性能:
避免多线程的上下文切换开销,单线程即可处理大量并发连接。例如,Redis 官方测试显示,单实例可支持超过 10 万次 / 秒的请求。 - 低内存占用:
无需为每个连接创建独立线程,内存使用效率更高,适合 Redis 这种内存密集型应用。 - 事件驱动的灵活性:
可轻松扩展对新事件类型的支持(如网络连接、定时器、信号等),Redis 借此实现了命令请求处理、数据持久化、主从复制等功能的高效协同。
五、适用场景与局限性
- 适用场景:
Redis 的 IO 多路复用特别适合短连接、高并发、低延迟的场景,如缓存查询、实时计数、消息队列等。每个请求的处理逻辑应尽可能简短,避免长时间阻塞事件循环(如复杂计算或磁盘 IO),否则会影响整体性能。 - 局限性:
单线程模型下,CPU 利用率受限于单个核心(Redis 6.0 引入多线程仅用于网络 IO 处理,核心逻辑仍为单线程)。若业务需要大量计算,需通过集群架构扩展,而非依赖单节点性能。
MySQL 哪些字段不适合建立索引?
在 MySQL 中,索引是提高查询效率的重要手段,但并非所有字段都适合建立索引。不当的索引设计不仅会增加存储空间,还会降低写操作的性能。以下是几类不适合建立索引的字段:
1. 很少被查询的字段
索引的价值在于加速查询,但如果某个字段在查询条件中很少被使用,建立索引只会徒增维护成本。例如,用户表中的 “注册 IP” 字段,若业务中极少根据 IP 进行查询,则无需为其创建索引。
2. 基数(Cardinality)过低的字段
基数指字段中不同值的数量。对于基数过低的字段(如性别、状态标志),索引的区分度差,优化效果有限。例如,性别字段只有 “男 / 女” 两个值,即使建立索引,查询时仍需扫描大量数据页,可能不如全表扫描高效。此时可通过 SHOW INDEX FROM table_name 查看 Cardinality 值,若接近行数则表示基数高,适合索引。
3. 频繁更新的字段
索引需要在数据插入、更新或删除时同步维护,频繁更新的字段会导致索引维护开销增大。例如,订单表中的 “支付状态” 字段,若经常被更新,建立索引会影响写操作性能。
4. 大字段或长文本字段
对于 TEXT、BLOB 或超长 VARCHAR 字段,建立索引会占用大量存储空间,且可能导致索引树层级过深,查询效率下降。若确实需要对大字段进行查询,可考虑前缀索引(如 ALTER TABLE table_name ADD INDEX idx_col(col(20))),仅索引前 N 个字符,但需权衡前缀长度与区分度。
5. 参与计算或函数操作的字段
当字段在查询条件中被函数处理(如 WHERE YEAR(create_time)=2023)或参与计算(如 WHERE price*0.9<100)时,索引无法生效。因为索引存储的是原始值,无法直接匹配计算后的结果。此时应优化查询条件,避免对字段进行函数操作。
6. 复合索引中顺序不合理的字段
在复合索引中,字段顺序至关重要。若查询条件未遵循最左前缀原则,索引可能失效。例如,复合索引 (a, b, c) 仅支持 WHERE a=?、WHERE a=? AND b=? 等查询,若仅查询 WHERE b=? 则无法利用该索引。因此,若某个字段在复合索引中位置靠后且单独被查询的频率较高,不适合包含在索引中。
7. 数据分布不均的字段
若字段的值分布极不均匀(如大部分值集中在少数几个值上),索引可能导致查询优化器误判。例如,用户表中的 “国家” 字段,若 90% 的用户都来自同一个国家,基于该字段的查询可能无法有效利用索引,反而增加随机 IO。
慢 SQL 优化的常见方法有哪些?
慢 SQL 是数据库性能瓶颈的常见原因,优化慢 SQL 需从查询语句、索引设计、数据库配置、表结构等多个维度入手。以下是常见的优化方法:
1. 利用索引加速查询
- 添加合适的索引:通过
EXPLAIN分析查询语句,确保 WHERE 子句、JOIN 条件和 ORDER BY 字段上有索引。例如,WHERE a=? AND b=? ORDER BY c可创建复合索引(a, b, c)。 - 优化索引顺序:复合索引遵循最左前缀原则,将筛选性强的字段放在前面。例如,
WHERE gender='男' AND age>18中,若性别基数低而年龄基数高,应优先索引 age。 - 避免索引失效:避免在索引字段上使用函数(如
WHERE YEAR(date)=2023)、计算(如WHERE price*0.9<100)或隐式类型转换(如字符串字段与数字比较)。
2. 优化查询语句结构
- 减少全表扫描:确保查询条件有索引覆盖,避免
SELECT *,只查询需要的字段。例如,将SELECT * FROM users改为SELECT id, name FROM users。 - 拆分复杂查询:对于多表 JOIN 查询,若数据量较大,可拆分为多个单表查询,在应用层组装结果。例如,将
SELECT u.name, o.order_no FROM users u JOIN orders o ON u.id=o.user_id拆分为先查询用户,再批量查询订单。 - 避免子查询:子查询(尤其是相关子查询)效率较低,可改用 JOIN 或 CTE(公共表表达式)替代。例如:
-- 低效子查询 SELECT name FROM users WHERE id IN (SELECT user_id FROM orders WHERE amount>100); -- 优化为 JOIN SELECT u.name FROM users u JOIN orders o ON u.id=o.user_id WHERE o.amount>100;
3. 调整数据库参数配置
- 增大缓冲池(Buffer Pool):对于 InnoDB 存储引擎,缓冲池负责缓存数据页和索引页,增大其大小(如
innodb_buffer_pool_size=8G)可减少磁盘 IO。 - 优化查询缓存:开启查询缓存(
query_cache_type=1)可缓存频繁执行的查询结果,但需注意写操作会使相关缓存失效,适用于读多写少的场景。 - 调整日志参数:适当增大
innodb_log_file_size和innodb_log_files_in_group可减少日志文件切换频率,提升写性能。
4. 优化表结构与数据类型
- 选择合适的数据类型:例如,用 TINYINT 代替 INT 存储布尔值或状态码,用 DATETIME 代替 VARCHAR 存储日期时间,减少存储空间和内存占用。
- 垂直拆分大表:将不常用的字段拆分到单独的表中,减少单表数据量。例如,用户表中,将个人简介、头像等不常用字段拆分到扩展表。
- 水平分片(Sharding):对于数据量极大的表(如亿级记录),可按业务规则(如时间、地域)将数据分散到多个表或服务器。
5. 分析执行计划与定位问题
- 使用 EXPLAIN:通过
EXPLAIN SELECT ...查看查询执行计划,重点关注type(访问类型,理想值为const、eq_ref、ref)、key(使用的索引)和rows(估计扫描的行数)。 - 监控慢查询日志:开启慢查询日志(
slow_query_log=1),记录执行时间超过阈值(long_query_time=1)的 SQL,分析高频出现的慢 SQL。 - 使用性能分析工具:如 MySQL Enterprise Monitor、pt-query-digest 等,自动分析慢 SQL 并提供优化建议。
6. 优化特殊操作
- 批量插入数据:将多次单条插入改为批量插入(如
INSERT INTO users (name) VALUES ('a'), ('b'), ('c')),减少事务开销。 - 优化 GROUP BY 和 ORDER BY:确保 GROUP BY 和 ORDER BY 字段使用相同的索引,避免文件排序(Filesort)。
- 避免大事务:长事务会占用锁资源,导致其他查询阻塞,尽量拆分大事务为多个小事务。
7. 硬件升级与架构优化
- 升级硬件配置:增加内存、使用 SSD 替代 HDD、提升 CPU 性能等。
- 读写分离:主库负责写操作,从库负责读操作,分摊查询压力。
- 引入缓存层:对热点数据(如商品信息、用户配置)使用 Redis 缓存,减少数据库访问。
什么是索引下推(Index Condition Pushdown)?
索引下推(Index Condition Pushdown,ICP)是 MySQL 5.6 引入的一项查询优化技术,用于减少回表操作,提升查询效率。理解 ICP 需先明确索引结构和查询流程。
在 MySQL 中,二级索引(非主键索引)通常包含索引列和主键值。当查询仅需索引列数据时,可直接通过索引树返回结果(索引覆盖);若需查询其他字段,则需通过索引中的主键值回表(Row Fetch)到主键索引获取完整数据。
ICP 的核心思想:将部分 WHERE 子句的过滤条件下推到存储引擎层,在扫描索引时直接过滤不满足条件的记录,减少回表次数。
示例说明:
假设有表 users,包含索引 (last_name, first_name),查询语句为:
SELECT * FROM users WHERE last_name='张' AND first_name LIKE '三%';
未使用 ICP 时:
- 存储引擎通过索引定位到所有
last_name='张'的记录。 - 将这些记录的主键值返回给服务器层。
- 服务器层根据主键回表,获取完整数据。
- 服务器层在内存中过滤
first_name LIKE '三%'的记录。
使用 ICP 时:
- 存储引擎在扫描索引时,同时评估
last_name='张' AND first_name LIKE '三%'。 - 仅将满足条件的记录的主键值返回给服务器层。
- 服务器层直接回表获取符合条件的完整数据,无需二次过滤。
ICP 的优势:
- 减少回表次数:如示例中,若
last_name='张'的记录有 100 条,但仅 10 条满足first_name LIKE '三%',ICP 可将回表次数从 100 次降至 10 次。 - 降低 CPU 与内存开销:过滤操作在存储引擎层完成,减少了返回给服务器层的数据量。
ICP 的适用条件:
- 查询需使用二级索引,且 WHERE 子句包含索引列的条件。
- 过滤条件可下推到存储引擎层(如比较操作、LIKE 前缀匹配等)。
- 索引类型支持(如 InnoDB、MyISAM,不支持 MEMORY 引擎)。
ICP 的限制:
- 对于
SELECT *且索引无法覆盖的查询,ICP 仍需回表,但可减少回表次数。 - 若过滤条件仅涉及主键或索引覆盖的字段,ICP 无优化效果(因无需回表)。
- 子查询中的条件无法下推,如
WHERE id IN (SELECT id FROM other_table WHERE ...)。
查看 ICP 是否生效:
通过 EXPLAIN 分析查询计划,若 Extra 列显示 Using index condition,则表示启用了 ICP。
Redis 中 ZSet 的数据结构是什么?什么是跳表(Skip List)?
Redis 的有序集合(ZSet)是一种存储键值对(score, member)的数据结构,支持按分数(score)排序和快速查找。其底层实现结合了跳表(Skip List)和哈希表(Hash Table),以平衡插入、删除、查找和范围查询的性能。
ZSet 的数据结构
ZSet 在 Redis 中的核心结构是 zset,包含两个关键组件:
- 哈希表(dict):存储
member到score的映射,支持 O (1) 时间复杂度的member存在性检查和分数查询。 - 跳表(zskiplist):按分数排序存储
(score, member)对,支持 O (logN) 时间复杂度的插入、删除和范围查询。
这种组合设计的优势在于:
- 哈希表保证了
ZSCORE、ZINCRBY等命令的高效执行。 - 跳表支持按分数范围的快速遍历(如
ZRANGE、ZREVRANGE)。
跳表(Skip List)的原理
跳表是一种随机化的数据结构,通过在链表基础上增加多层索引来加速查找,其平均时间复杂度为 O (logN),最坏情况为 O (N)。与平衡树(如红黑树)相比,跳表的优势在于实现简单、支持范围查询更高效。
跳表的核心思想:
- 在原始链表之上创建多层索引,每层索引都是下一层的子集。
- 最高层索引的节点数最少,搜索时从最高层开始,快速跳过大量节点,逐步降低层级直到找到目标节点。
跳表的结构特点:
- 多层链表:每层都是一个有序链表,最底层包含所有节点。
- 节点随机层级:每个节点的层级(Level)在插入时随机确定(通常为 1 到 32 之间),层级越高出现概率越低(如 50% 的概率为 1 层,25% 为 2 层,依此类推)。
- 前向指针:每个节点包含多个前向指针,分别指向不同层级的后续节点。
跳表的操作示例:
假设有一个有序链表 1 → 3 → 4 → 6 → 7 → 9 → 12 → 15 → 17,构建跳表时:
- 随机为每个节点分配层级,如节点
3被分配为 3 层,节点6为 2 层,其他节点为 1 层。 - 构建多层索引:
- 第 3 层:
3 → 17 - 第 2 层:
3 → 6 → 15 → 17 - 第 1 层:
1 → 3 → 4 → 6 → 7 → 9 → 12 → 15 → 17(原始链表)
- 第 3 层:
查找节点 12 时,从第 3 层开始:
- 第 3 层:从
3出发,发现17大于12,降至第 2 层。 - 第 2 层:从
3到6到15,发现15大于12,降至第 1 层。 - 第 1 层:从
6到7到9到12,找到目标节点。
Redis 跳表的实现细节
Redis 对跳表进行了以下优化:
- 双向指针:每个节点包含指向前驱和后继的指针,支持逆序遍历(如
ZREVRANGE)。 - 跨度(Span):每个前向指针包含跨度值,表示跳过的节点数,用于快速计算排名(如
ZRANK)。 - 表头和表尾节点:跳表包含表头(header)和表尾(tail)节点,简化边界处理。
跳表节点结构(redis.h/zskiplistNode):
typedef struct zskiplistNode { sds ele; // 成员对象 double score; // 分数 struct zskiplistNode *backward; // 后退指针 struct zskiplistLevel { struct zskiplistNode *forward; // 前进指针 unsigned long span; // 跨度 } level[]; // 层级数组,动态分配
} zskiplistNode;
跳表结构(redis.h/zskiplist):
typedef struct zskiplist { struct zskiplistNode *header, *tail; // 表头和表尾节点 unsigned long length; // 节点数量 int level; // 最大层级
} zskiplist;
跳表 vs 平衡树
| 维度 | 跳表(Skip List) | 平衡树(如红黑树) |
|---|---|---|
| 实现复杂度 | 简单,易于理解和维护 | 复杂,需处理旋转、颜色等操作 |
| 范围查询 | O (logN + M)(M 为结果数) | O (logN + M),但实现更复杂 |
| 插入 / 删除 | 平均 O (logN),无需调整结构 | O (logN),需旋转维护平衡 |
| 内存占用 | 每个节点需额外指针(约 2 倍) | 每个节点需额外颜色位 |
Redis 的过期删除策略有哪些?
Redis 的过期删除策略用于处理设置了过期时间的键(Key),确保过期数据及时被清理,释放内存空间。Redis 采用 ** 惰性删除(Lazy Expiration)和定期删除(Periodic Expiration)** 两种策略协同工作,并通过内存淘汰机制应对内存不足的情况。
1. 惰性删除(Lazy Expiration)
核心思想:当访问某个键时,才检查该键是否过期,若过期则立即删除并返回空值。
实现方式:
- 当执行
GET、HGET等读取操作时,Redis 会首先检查键是否过期。 - 若过期,Redis 会删除该键并返回空值(如
nil)。 - 若未过期,正常返回键值。
优点:
- 无需额外开销,仅在访问时检查,减少 CPU 消耗。
- 对内存友好,未被访问的过期键会暂时保留,避免频繁删除操作。
缺点:
- 若过期键长期未被访问,会持续占用内存,可能导致内存泄漏。例如,设置了过期时间的缓存数据若不再被访问,会一直留在内存中。
2. 定期删除(Periodic Expiration)
核心思想:Redis 服务器定期(默认每秒 10 次)随机检查一部分键,删除其中过期的键。
实现步骤:
- 随机抽样:从过期键字典中随机选择 20 个键。
- 删除检查:删除这 20 个键中已过期的键。
- 循环处理:若过期键比例超过 25%,重复步骤 1 和 2,直到过期键比例低于阈值或执行时间超过 25ms(避免长时间阻塞)。
配置参数:
hz:控制定期删除的频率,默认 10 次 / 秒,可通过CONFIG SET hz 20调整。值越大,检查越频繁,内存释放更及时,但可能增加 CPU 负担。
优点:
- 定期清理过期键,避免惰性删除导致的内存占用问题。
- 通过随机抽样和时间限制,平衡了内存清理和服务器性能。
缺点:
- 无法保证所有过期键被及时删除,极端情况下仍可能存在短暂的内存占用。
- 若过期键数量庞大,可能导致定期删除耗时过长,影响服务器响应。
3. 内存淘汰机制(Eviction Policy)
当 Redis 内存使用达到上限(maxmemory)时,触发内存淘汰机制,主动删除部分键以释放空间。Redis 提供多种淘汰策略,可通过 maxmemory-policy 配置:
- volatile-lru(默认):删除最近最少使用(LRU)的过期键。
- allkeys-lru:删除最近最少使用(LRU)的键,无论是否过期。
- volatile-lfu:删除最不经常使用(LFU)的过期键。
- allkeys-lfu:删除最不经常使用(LFU)的键。
- volatile-random:随机删除过期键。
- allkeys-random:随机删除任意键。
- volatile-ttl:删除剩余时间最短(TTL)的过期键。
- noeviction:拒绝写操作,仅允许读操作,直到有内存释放。
选择策略建议:
- 若需缓存大量数据且希望优先淘汰冷数据,可选择
allkeys-lru或allkeys-lfu。 - 若业务中键有明确的过期时间,可选择
volatile-lru或volatile-ttl。
4. 实际应用中的权衡
- 内存与 CPU 的平衡:惰性删除节省 CPU 但可能浪费内存,定期删除释放内存但消耗 CPU。需根据业务场景调整
hz参数,如读写密集型应用可适当降低频率。 - 过期键分布影响:若大量键同时过期,可能导致定期删除时瞬间压力增大,需避免集中设置过期时间。
- 监控与调优:通过
INFO memory监控内存使用和expired_keys指标,及时调整maxmemory和淘汰策略。
Redis 为什么执行命令是单线程的?为什么性能依然高效?
Redis 执行命令采用单线程模型,主要原因在于其设计目标和架构特性。单线程设计能避免多线程带来的锁竞争和上下文切换开销,简化了数据结构和算法的实现。例如,在多线程环境下,对共享数据的并发访问需要复杂的同步机制,而单线程模型无需考虑这些问题,使 Redis 内部实现更加简洁高效。
Redis 的高性能源于多方面因素的协同作用。首先,它是纯内存操作,数据存储在内存中,读写速度极快,内存访问的响应时间通常在微秒级别。其次,Redis 使用高效的数据结构,如跳表、哈希表等,这些数据结构的操作时间复杂度大多为 O (1) 或 O (logN),保证了单个命令的快速执行。此外,Redis 采用了 I/O 多路复用技术,通过单线程监听多个套接字的读写事件,能高效处理大量并发连接,进一步提升了整体吞吐量。
虽然 Redis 执行命令是单线程的,但它在处理网络 I/O 时使用了非阻塞 I/O 和多路复用技术。例如,在 Linux 系统中,Redis 采用 epoll 机制,通过事件驱动的方式处理多个客户端连接,避免了传统阻塞 I/O 模型中一个连接阻塞导致整个线程无法处理其他连接的问题。这种设计使得 Redis 单线程也能高效处理大量并发请求,每秒可处理数万甚至十万级的命令。
值得注意的是,Redis 6.0 引入了多线程特性,但仅用于网络 I/O 处理,命令执行仍然是单线程的。网络 I/O 多线程可以并行处理客户端请求和响应,进一步提升了 Redis 在高并发场景下的性能。但核心命令执行保持单线程,确保了数据操作的原子性和线程安全,避免了多线程编程的复杂性。
观察者模式与策略模式的区别是什么?各自的使用场景和优势是什么?
观察者模式和策略模式是两种不同的设计模式,它们解决的问题和应用场景有明显区别。
观察者模式定义了一种一对多的依赖关系,让多个观察者对象同时监听一个主题对象。这个主题对象在状态发生变化时,会通知所有观察者对象,使它们能够自动更新自己的状态。例如,在一个天气监测系统中,天气数据是主题对象,而显示天气的各种组件(如手机应用、网站、桌面 Widget)是观察者。当天气数据更新时,所有观察者都会收到通知并更新显示。
观察者模式的优势在于实现了对象间的解耦,主题对象不需要知道具体的观察者是谁,只需要维护一个观察者列表并在状态变化时通知它们。这种模式适用于一个对象的状态变化需要通知多个其他对象的场景,如事件处理系统、消息通知系统等。它的使用场景包括发布 - 订阅系统、GUI 组件间的交互等。
策略模式则是定义了一系列算法,并将每个算法封装起来,使它们可以相互替换。策略模式让算法的变化独立于使用算法的客户端。例如,在一个电商系统中,计算订单折扣可以有多种策略:新用户折扣、节日折扣、会员折扣等。系统可以根据不同的场景选择不同的折扣策略,而不需要修改订单处理的核心逻辑。
策略模式的优势在于提供了一种灵活的方式来替换算法,避免了使用大量的条件语句。它将算法的实现和使用分离,使得代码更易于维护和扩展。策略模式适用于多种算法解决同一类问题的场景,如排序算法选择、支付方式选择等。它的使用场景包括游戏中的角色行为、文件压缩算法选择等。
两者的主要区别在于:观察者模式关注的是对象间的通知机制,解决的是一个对象状态变化如何通知多个依赖对象的问题;而策略模式关注的是算法的封装和替换,解决的是如何在运行时选择不同算法的问题。观察者模式是一种行为模式,而策略模式是一种对象创建模式。
常见的设计模式有哪些?请举例说明责任链模式、单例模式、工厂模式的应用场景。
常见的设计模式包括创建型模式、结构型模式和行为型模式三大类。创建型模式主要用于对象的创建过程,结构型模式关注如何将类或对象组合成更大的结构,行为型模式则用于处理对象之间的交互和职责分配。
责任链模式是一种行为型设计模式,它将请求的发送者和接收者解耦,使多个对象都有机会处理这个请求。这些对象连接成一条链,并沿着这条链传递该请求,直到有一个对象处理它为止。例如,在一个公司的请假审批系统中,员工请假的请求会依次经过组长、经理、总监等层级的审批。每个审批者都可以决定是否处理该请求或将其传递给下一个审批者。责任链模式的应用场景包括请求审批流程、日志处理、异常处理等。它的优势在于可以动态地添加或修改处理者,提高了系统的灵活性和可维护性。
单例模式是一种创建型设计模式,它确保一个类只有一个实例,并提供一个全局访问点来获取这个实例。例如,在一个应用程序中,数据库连接池通常设计为单例模式,因为创建多个数据库连接池会导致资源浪费和管理混乱。单例模式的应用场景包括配置管理、线程池、缓存等。它的优势在于减少了系统资源消耗,避免了多个实例导致的不一致问题。
工厂模式是一种创建型设计模式,它定义了一个创建对象的接口,让子类决定实例化哪个类。工厂模式将对象的创建和使用分离,提高了代码的可维护性和可扩展性。例如,在一个游戏开发中,不同类型的武器(如剑、弓箭、魔法杖)可以通过武器工厂来创建。客户端只需要知道需要什么类型的武器,而不需要知道具体的创建过程。工厂模式的应用场景包括对象创建逻辑复杂、需要根据不同条件创建不同类型对象的情况。它的优势在于将对象的创建逻辑集中管理,降低了客户端代码与具体实现类的耦合度。
这些设计模式在实际开发中被广泛应用,能够帮助开发者解决各种常见的软件设计问题,提高代码的质量和可维护性。例如,责任链模式可以使请求处理流程更加灵活,单例模式可以确保系统资源的合理利用,工厂模式可以简化对象的创建过程。