【LangChain大模型应用与多智能体开发 ② 接入智谱AI】
目录
一、智谱AI
1.GLM-4
Ⅰ、基础能力(英文)
Ⅱ、指令跟随能力(中英)
Ⅲ、对齐能力(中文)
Ⅳ、长文本能力
Ⅴ、多模态 - 文生图能力
2.智谱AI调用
Ⅰ、安装包
Ⅱ、导入智谱AI模块
Ⅲ、使用API调用智谱大模型
Ⅳ、获取模型的回答结果
Ⅴ、流式输出模型的回答
二、将智谱AI接口整合在LangChain中
1.类定义:ZhipuAIGLM4 继承自 LLM
Ⅰ、类属性
Ⅱ、构造函数 __init__
2.方法实现:核心功能封装
Ⅰ、属性 __llm_type__
Ⅱ、核心方法 invoke
Ⅲ、兼容方法 _call
Ⅳ、流式方法 stream
3.实例化与调用:使用示例
4.与LangChain的集成
Ⅰ、消息类型兼容
Ⅱ、接口适配
5.完整代码
三、在LangChain中手动封装智谱模型
1.导入模块与类型声明
2.类定义:ZhipuAIGLM4 继承自 LLM
3.构造函数 __init__
4.属性 __llm_type
5.核心方法 invoke
6.兼容方法 _call
7.流式方法 stream
8.实例化与调用实例
9.完整代码
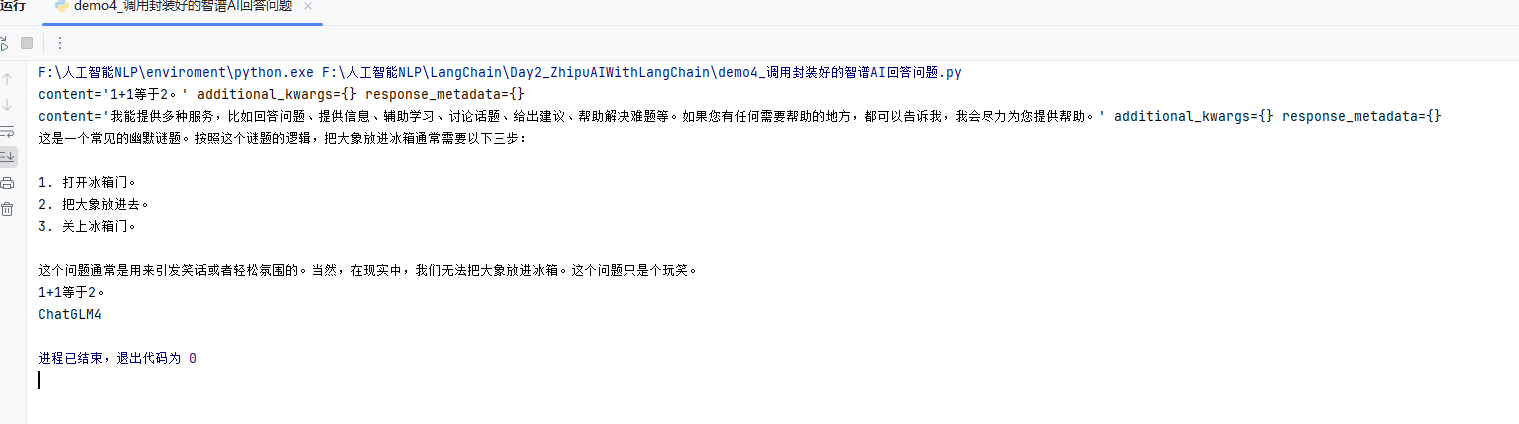
四、调用以LangChain封装好的智谱模型
代码运行流程
1.导入自定义模型类并实例化
2.调用invoke方法(单轮对话)
3.传入历史对话调用invoke方法(多轮对话)
4.流式调用 stream 方法
5.直接调用 invoke 方法并访问回复内容
6.查看调用的智谱模型类型
7.完整代码
脚步虽缓,不停则远。梦想在心,坚持成真。
—— 25.5.24
一、智谱AI
1.GLM-4
新一代基座大模型GLM-4,整体性能相比GLM3全面提升60%,逼近GPT-4;支持更长上下文;更强的多模态;支持更快推理速度,更多并发,大大降低推理成本;同时GLM-4增强了智能体能力。
Ⅰ、基础能力(英文)
GLM-4 在 MMLU、GSM8K、MATH、BBH、HellaSwag、HumanEval等数据集上,分别达到GPT-4 94%、95%、91%、99%、90%、100%的水平。
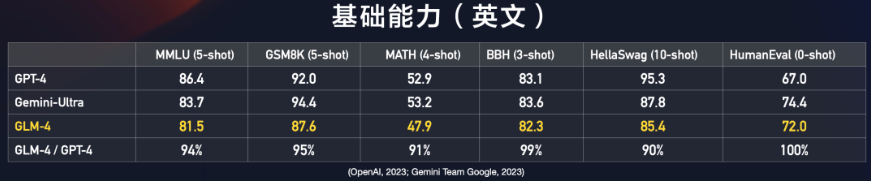
Ⅱ、指令跟随能力(中英)
GLM-4在IFEval的prompt级别上中、英分别达到GPT-4的88%、85%的水平,在Instruction级别上中、英分别达到GPT-4的90%、89%的水平。
Ⅲ、对齐能力(中文)
GLM-4在中文对齐能力上整体超过GPT-4。

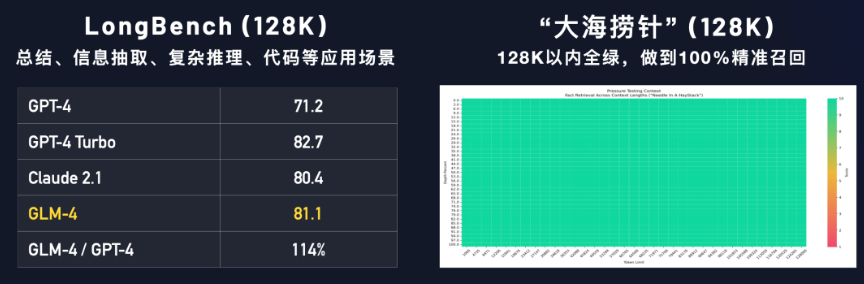
Ⅳ、长文本能力
我们在LongBench(128K)测试集上对多个模型进行评测,GLM-4性能超过 Claude 2.1;在「大海捞针」(128K)实验中,GLM-4的测试结果为 128K以内全绿,做到100%精准召回。
Ⅴ、多模态 - 文生图能力
CogView3在文生图多个评测指标上,相比DALLE3 约在 91.4% ~99.3%的水平之间。

GLM-4 实现自主根据用户意图,自动理解、规划复杂指令,自由调用网页浏览器、Code Interpreter代码解释器和多模态文生图大模型,以完成复杂任务。 简单来讲,即只需一个指令,GLM-4会自动分析指令,结合上下文选择决定调用合适的工具。
GLM-4能够通过自动调用python解释器,进行复杂计算(例如复杂方程、微积分等),在GSM8K、MATH、Math23K等多个评测集上都取得了接近或同等GPT-4 All Tools的水平。
GLM-4 能够自行规划检索任务、自行选择信息源、自行与信息源交互,在准确率上能够达到 78.08,是GPT-4 All Tools 的116%。
GLM-4 能够根据用户提供的Function描述,自动选择所需 Function并生成参数,以及根据 Function 的返回值生成回复;同时也支持一次输入进行多次 Function 调用,支持包含中文及特殊符号的 Function 名字。这一方面GLM-4 All Tools 与 GPT-4 Turbo 相当。
2.智谱AI调用
智谱AI新用户可以体验领取免费tokens:
网站链接: 智谱
Ⅰ、安装包
首先,在使用前应该先安装智谱大模型的安装包:
使用清华园安装:pip3 install -i https://pypi.tuna.tsinghua.edu.cn/simple ZhipuAI
Ⅱ、导入智谱AI模块
ZhipuAI():
from zhipuai import ZhipuAIclient = ZhipuAI(api_key=your_zhipuai_api_key)Ⅲ、使用API调用智谱大模型
智谱大模型客户端对象.chat.completions.create():
prompt = "以色列为什么喜欢战争?"
response = client.chat.completions.create(model="glm-4",messages=[{"role":"user","content":"你好"},{"role":"assistant","content":"我是人工智能助手"},{"role":"user","content":prompt}]
)print(response)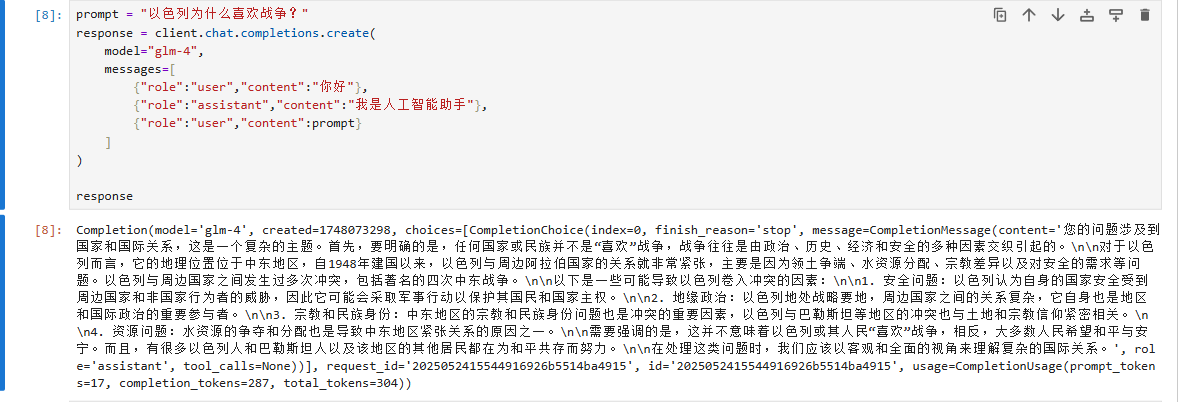
Ⅳ、获取模型的回答结果
print(response.choices[0].message.content)
Ⅴ、流式输出模型的回答
智谱大模型客户端对象.chat.completions.create():
prompt = "glm-4原理是什么?使用了多少的参数进行训练?"
response = client.chat.completions.create(model="glm-4",messages=[{"role":"user","content":"你好"},{"role":"assistant","content":"我是人工智能助手"},{"role":"user","content":prompt}],stream=True
)for chunk in response:print(chunk.choices[0].delta.content,end="")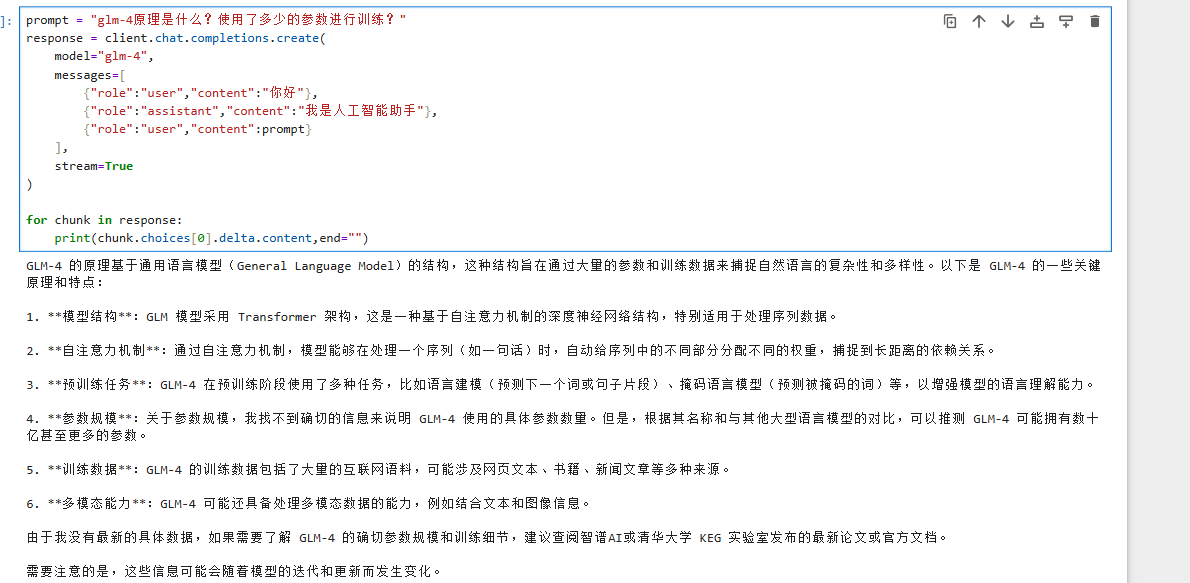
二、将智谱AI接口整合在LangChain中
注:Pydantic v2 要求所有类属性(尤其是作为模型字段的属性)必须显式声明类型
1.类定义:ZhipuAIGLM4 继承自 LLM
Ⅰ、类属性
history:维护多轮对话的上下文,格式与智谱 API 要求的messages参数一致。
client:初始化智谱 AI 的 SDK 客户端,持有 API 密钥。
history: List[dict] = [] # 存储对话历史,每个元素为 {"role": "user/assistant", "content": "文本"}client: object = None # 智谱AI客户端,用于调用APIⅡ、构造函数 __init__
ZhipuAI():智谱 AI(Zhipu.AI)提供的 Python SDK 客户端类的构造函数,用于初始化与智谱大模型的连接,获取调用 API 的客户端对象。
| 参数名 | 类型 | 必选 | 说明 |
|---|---|---|---|
api_key | str | ✅ | 智谱 AI 平台申请的 API 密钥(用于身份验证,需在 官网 注册获取)。 |
api_base | str | ❌ | API 服务地址(默认值为智谱官方地址,一般无需修改)。 |
timeout | int | ❌ | 请求超时时间(秒),默认值通常为 60。 |
model | str | ❌ | 默认使用的模型名称(如 "glm-4"),可在调用具体接口时覆盖。 |
def __init__(self):super().__init__()self.client = ZhipuAI(api_key="Your_ZhipuAPI_Key") # 填入实际API密钥2.方法实现:核心功能封装
Ⅰ、属性 __llm_type__
@property:装饰器(Decorator),用于将类方法转换为只读属性或可读写属性。它允许开发者以属性访问的形式调用方法,同时隐藏实现细节,控制数据的访问、修改和删除行为。
@propertydef _llm_type(self):return "ChatGLM4"Ⅱ、核心方法 invoke
isinstance():Python 内置函数,用于判断一个对象是否是某个类或类型的实例,或是否是其中多个类或类型中的一个。
| 参数名 | 类型 | 必选 | 说明 |
|---|---|---|---|
obj | object | ✅ | 要检查的对象。 |
class_or_type | type/list[type] | ✅ | 类、类型或类型列表(如 str、int、(str, int))。 |
to_string():将对象转换为字符串表示形式,通常用于处理非字符串类型的输入(如 LangChain 的 Prompt 对象),确保输入符合模型接口要求。
append():Python 列表的实例方法,用于向列表末尾添加一个元素,原地修改列表,无返回值。
| 参数名 | 类型 | 必选 | 说明 |
|---|---|---|---|
obj | object | ✅ | 要添加的元素(可以是任意类型,如字符串、数字、字典等)。 |
client.chat.completions.create():智谱 AI SDK 中用于调用对话模型 API 的核心方法,支持多轮对话和流式输出,返回模型生成的响应。
| 参数名 | 类型 | 必选 | 说明 |
|---|---|---|---|
model | str | ✅ | 模型名称(如 "glm-4"、"glm-3-turbo")。 |
messages | list[dict] | ✅ | 对话消息列表,每个元素为 {"role": "user/assistant", "content": "文本"}。 |
temperature | float | ❌ | 生成随机性(0-2,默认 0.7):值越高越创意,越低越确定。 |
max_tokens | int | ❌ | 最大生成 Token 数(默认由模型限制,如 GLM-4 支持 8K tokens)。 |
stop | list[str] | ❌ | 停止生成的标记列表(如 ["###"],生成中遇到时终止)。 |
stream | bool | ❌ | 是否启用流式输出(默认 False,启用后返回迭代器逐块生成内容)。 |
def invoke(self, prompt, history=[]):if history is None:history = []if not isinstance(prompt, str):prompt = prompt.to_string()history.append({"role": "user", "content": prompt})response = self.client.chat.completions.create(model="glm-4",messages=history)result = response.choices[0].message.contentreturn AIMessage(content=result)Ⅲ、兼容方法 _call
def _call(self, prompt, history=[]):return self.invoke(prompt, history)Ⅳ、流式方法 stream
yield:yield 是一个关键字,用于定义生成器函数(Generator Function)。生成器是一种特殊的迭代器,具有延迟计算(Lazy Evaluation)的特性,适用于处理大规模数据或需要逐块生成结果的场景。
核心作用:
① 创建生成器:带有 yield 的函数不再是普通函数,而是生成器函数。调用生成器函数不会立即执行代码,而是返回一个生成器对象,只有当使用 next() 或迭代(for 循环)时才会执行函数体。
② 暂停与恢复执行:当执行到 yield 时,函数会暂停执行,并返回 yield 后的值。下次调用 next() 或继续迭代时,函数从暂停处恢复执行,直到遇到下一个 yield 或函数结束。
③ 逐块生成数据:适用于需要逐步生成结果的场景(如读取大文件、流式数据处理),避免一次性加载所有数据到内存,节省资源。
def stream(self, prompt, history=[]):if history is None:history = []if not isinstance(prompt, str):prompt = prompt.to_string()history.append({"role": "user", "content": prompt})response = self.client.chat.completions.create(model="glm-4",messages=history,stream=True)for chunk in response:yield chunk.choices[0].delta.content
3.实例化与调用:使用示例
# 实例化
model = ZhipuAIGLM4()
print(model.invoke("给我生成一个三十字以内的励志、坚持文案"))
for i in model.stream("大模型学习路线"):print(i, end="")4.与LangChain的集成
Ⅰ、消息类型兼容
返回值AIMessage是 LangChain 的标准消息类型,可直接用于ChatChain等组件,实现多轮对话逻辑。
Ⅱ、接口适配
通过_call和stream方法适配 LangChain 的LLM和StreamingLLM接口,支持无缝集成到 LangChain 的代理(Agent)或链(Chain)中。
5.完整代码
from typing import Listfrom langchain.llms.base import LLM
from zhipuai import ZhipuAI
from langchain_core.messages.ai import AIMessageclass ZhipuAIGLM4(LLM):# 用来存放历史数据history: List[dict] = []# 用来存放ZhipuAI的客户端调用对象client:object = Nonedef __init__(self):super().__init__()self.client = ZhipuAI(api_key="Your_ZhipuAPI_Key") # 填入实际API密钥@propertydef _llm_type(self):return "ChatGLM4"def invoke(self, prompt, history=[]):if history is None:history = []if not isinstance(prompt, str):prompt = prompt.to_string()history.append({"role": "user", "content": prompt})response = self.client.chat.completions.create(model="glm-4",messages=history)result = response.choices[0].message.contentreturn AIMessage(content=result)def _call(self, prompt, history=[]):return self.invoke(prompt, history)def stream(self, prompt, history=[]):if history is None:history = []if not isinstance(prompt, str):prompt = prompt.to_string()history.append({"role": "user", "content": prompt})response = self.client.chat.completions.create(model="glm-4",messages=history,stream=True)for chunk in response:yield chunk.choices[0].delta.content# 实例化
model = ZhipuAIGLM4()
print(model.invoke("给我生成一个三十字以内的励志、坚持文案"))
for i in model.stream("大模型学习路线"):print(i, end="")
三、在LangChain中手动封装智谱模型
1.导入模块与类型声明
typing.List:用于声明列表类型(如对话历史 history 的类型为 List[dict])。
langchain.llms.base.LLM:LangChain 的基础 LLM 类,自定义模型需继承此类。
zhipuai.ZhipuAI:智谱 AI 的 Python SDK 客户端类,用于调用模型 API。
langchain_core.messages.ai.AIMessage:LangChain 的 AI 消息类型,用于封装模型回复。
from typing import Listfrom langchain.llms.base import LLM
from zhipuai import ZhipuAI
from langchain_core.messages.ai import AIMessage2.类定义:ZhipuAIGLM4 继承自 LLM
history: List[dict]:存储多轮对话的历史记录,每个元素为 {"role": "user/assistant", "content": "文本"} 格式的字典。
client: object:智谱 AI 客户端对象,用于发起 API 请求。
class ZhipuAIGLM4(LLM):# 用来存放历史数据history: List[dict] = []# 用来存放ZhipuAI的客户端调用对象client: object = None3.构造函数 __init__
super().__init__():调用父类(LLM)的构造函数,完成 LangChain 框架所需的初始化。
self.client = ZhipuAI(...):实例化智谱 AI 客户端,需将 "Your_ZhipuAPI_Key" 替换为实际申请的 API 密钥。
ZhipuAI():智谱 AI(Zhipu.AI)提供的 Python SDK 客户端类的构造函数,用于初始化与智谱大模型的连接,获取调用 API 的客户端对象。
| 参数名 | 类型 | 必选 | 说明 |
|---|---|---|---|
api_key | str | ✅ | 智谱 AI 平台申请的 API 密钥(用于身份验证,需在 官网 注册获取)。 |
api_base | str | ❌ | API 服务地址(默认值为智谱官方地址,一般无需修改)。 |
timeout | int | ❌ | 请求超时时间(秒),默认值通常为 60。 |
model | str | ❌ | 默认使用的模型名称(如 "glm-4"),可在调用具体接口时覆盖。 |
def __init__(self):super().__init__()self.client = ZhipuAI(api_key="Your_ZhipuAPI_Key")4.属性 __llm_type
@property:装饰器(Decorator),用于将类方法转换为只读属性或可读写属性。它允许开发者以属性访问的形式调用方法,同时隐藏实现细节,控制数据的访问、修改和删除行为。
@property
def _llm_type(self):return "ChatGLM4"5.核心方法 invoke
isinstance():Python 内置函数,用于判断一个对象是否是某个类或类型的实例,或是否是其中多个类或类型中的一个。
| 参数名 | 类型 | 必选 | 说明 |
|---|---|---|---|
obj | object | ✅ | 要检查的对象。 |
class_or_type | type/list[type] | ✅ | 类、类型或类型列表(如 str、int、(str, int))。 |
to_string():将对象转换为字符串表示形式,通常用于处理非字符串类型的输入(如 LangChain 的 Prompt 对象),确保输入符合模型接口要求。
append():Python 列表的实例方法,用于向列表末尾添加一个元素,原地修改列表,无返回值。
| 参数名 | 类型 | 必选 | 说明 |
|---|---|---|---|
obj | object | ✅ | 要添加的元素(可以是任意类型,如字符串、数字、字典等)。 |
智谱语言模型实例.chat.completions.create():智谱 AI SDK 中用于调用对话模型 API 的核心方法,支持多轮对话和流式输出,返回模型生成的响应。
| 参数名 | 类型 | 必选 | 说明 |
|---|---|---|---|
model | str | ✅ | 模型名称(如 "glm-4"、"glm-3-turbo")。 |
messages | list[dict] | ✅ | 对话消息列表,每个元素为 {"role": "user/assistant", "content": "文本"}。 |
temperature | float | ❌ | 生成随机性(0-2,默认 0.7):值越高越创意,越低越确定。 |
max_tokens | int | ❌ | 最大生成 Token 数(默认由模型限制,如 GLM-4 支持 8K tokens)。 |
stop | list[str] | ❌ | 停止生成的标记列表(如 ["###"],生成中遇到时终止)。 |
stream | bool | ❌ | 是否启用流式输出(默认 False,启用后返回迭代器逐块生成内容)。 |
def invoke(self, prompt, history=[]):if history is None:history = []if not isinstance(prompt, str):prompt = prompt.to_string()history.append({"role": "user", "content": prompt})response = self.client.chat.completions.create(model="glm-4",messages=history)result = response.choices[0].message.contentreturn AIMessage(content=result)6.兼容方法 _call
def _call(self, prompt, history=[]):return self.invoke(prompt, history)7.流式方法 stream
isinstance():Python 内置函数,用于判断一个对象是否是某个类或类型的实例,或是否是其中多个类或类型中的一个。
| 参数名 | 类型 | 必选 | 说明 |
|---|---|---|---|
obj | object | ✅ | 要检查的对象。 |
class_or_type | type/list[type] | ✅ | 类、类型或类型列表(如 str、int、(str, int))。 |
to_string():将对象转换为字符串表示形式,通常用于处理非字符串类型的输入(如 LangChain 的 Prompt 对象),确保输入符合模型接口要求。
append():Python 列表的实例方法,用于向列表末尾添加一个元素,原地修改列表,无返回值。
| 参数名 | 类型 | 必选 | 说明 |
|---|---|---|---|
obj | object | ✅ | 要添加的元素(可以是任意类型,如字符串、数字、字典等)。 |
智谱语言模型实例.chat.completions.create():智谱 AI SDK 中用于调用对话模型 API 的核心方法,支持多轮对话和流式输出,返回模型生成的响应。
| 参数名 | 类型 | 必选 | 说明 |
|---|---|---|---|
model | str | ✅ | 模型名称(如 "glm-4"、"glm-3-turbo")。 |
messages | list[dict] | ✅ | 对话消息列表,每个元素为 {"role": "user/assistant", "content": "文本"}。 |
temperature | float | ❌ | 生成随机性(0-2,默认 0.7):值越高越创意,越低越确定。 |
max_tokens | int | ❌ | 最大生成 Token 数(默认由模型限制,如 GLM-4 支持 8K tokens)。 |
stop | list[str] | ❌ | 停止生成的标记列表(如 ["###"],生成中遇到时终止)。 |
stream | bool | ❌ | 是否启用流式输出(默认 False,启用后返回迭代器逐块生成内容)。 |
yield:yield 是一个关键字,用于定义生成器函数(Generator Function)。生成器是一种特殊的迭代器,具有延迟计算(Lazy Evaluation)的特性,适用于处理大规模数据或需要逐块生成结果的场景。
核心作用:
① 创建生成器:带有 yield 的函数不再是普通函数,而是生成器函数。调用生成器函数不会立即执行代码,而是返回一个生成器对象,只有当使用 next() 或迭代(for 循环)时才会执行函数体。
② 暂停与恢复执行:当执行到 yield 时,函数会暂停执行,并返回 yield 后的值。下次调用 next() 或继续迭代时,函数从暂停处恢复执行,直到遇到下一个 yield 或函数结束。
③ 逐块生成数据:适用于需要逐步生成结果的场景(如读取大文件、流式数据处理),避免一次性加载所有数据到内存,节省资源。
def stream(self, prompt, history=[]):if history is None:history = []if not isinstance(prompt, str):prompt = prompt.to_string()history.append({"role": "user", "content": prompt})response = self.client.chat.completions.create(model="glm-4",messages=history,stream=True)for chunk in response:yield chunk.choices[0].delta.content8.实例化与调用实例
if __name__ == "__main__":# 实例化model = ZhipuAIGLM4()print(model.invoke("给我生成一个三十字以内的励志、坚持文案"))for i in model.stream("大模型学习路线"):print(i, end="")9.完整代码
from typing import Listfrom langchain.llms.base import LLM
from zhipuai import ZhipuAI
from langchain_core.messages.ai import AIMessageclass ZhipuAIGLM4(LLM):# 用来存放历史数据history: List[dict] = []# 用来存放ZhipuAI的客户端调用对象client: object = Nonedef __init__(self):super().__init__()self.client = ZhipuAI(api_key="Your_ZhipuAPI_Key")@propertydef _llm_type(self):return "ChatGLM4"def invoke(self, prompt, history=[]):if history is None:history = []if not isinstance(prompt, str):prompt = prompt.to_string()history.append({"role": "user", "content": prompt})response = self.client.chat.completions.create(model="glm-4",messages=history)result = response.choices[0].message.contentreturn AIMessage(content=result)def _call(self, prompt, history=[]):return self.invoke(prompt, history)def stream(self, prompt, history=[]):if history is None:history = []if not isinstance(prompt, str):prompt = prompt.to_string()history.append({"role": "user", "content": prompt})response = self.client.chat.completions.create(model="glm-4",messages=history,stream=True)for chunk in response:yield chunk.choices[0].delta.contentif __name__ == "__main__":# 实例化model = ZhipuAIGLM4()print(model.invoke("给我生成一个三十字以内的励志、坚持文案"))for i in model.stream("大模型学习路线"):print(i, end="")
四、调用以LangChain封装好的智谱模型
代码运行流程
导入模型类 → 实例化模型 → 单轮对话测试 → 多轮对话测试 → 流式输出测试 → 结果解析 → 模型类型验证1.导入自定义模型类并实例化
从自定义模块 demo3_封装ZhipuAI调用大模型 中导入 ZhipuAIGLM4 类,该类封装了智谱 GLM-4 模型的调用逻辑。
from Day2_ZhipuAIWithLangChain.demo3_封装ZhipuAI调用大模型 import ZhipuAIGLM4# 实例化ZhipuAIGLM4类
model = ZhipuAIGLM4()2.调用invoke方法(单轮对话)
# 使用invoke方法替代直接调用实例
print(model.invoke("请用中文回答:1+1等于多少"))3.传入历史对话调用invoke方法(多轮对话)
# 传入历史对话数据(格式应为字典列表)
history = [{"role": "user", "content": "你好,请问你叫什么名字?"},{"role": "assistant", "content": "我叫小明。"}
]
print(model.invoke("请用中文回答:那你能做什么?", history=history))4.流式调用 stream 方法
# 流式回答问题
for chunk in model.stream("把大象放进冰箱需要几步?"):print(chunk, end="", flush=True)
print()5.直接调用 invoke 方法并访问回复内容
# 直接调用invoke方法
response = model.invoke("请用中文回答:1+1等于多少")
print(response.content)6.查看调用的智谱模型类型
# 查看模型类型
print(model._llm_type)7.完整代码
from Day2_ZhipuAIWithLangChain.demo3_封装ZhipuAI调用大模型 import ZhipuAIGLM4# 实例化ZhipuAIGLM4类
model = ZhipuAIGLM4()# 使用invoke方法替代直接调用实例
print(model.invoke("请用中文回答:1+1等于多少"))# 传入历史对话数据(格式应为字典列表)
history = [{"role": "user", "content": "你好,请问你叫什么名字?"},{"role": "assistant", "content": "我叫小明。"}
]
print(model.invoke("请用中文回答:那你能做什么?", history=history))# 流式回答问题
for chunk in model.stream("把大象放进冰箱需要几步?"):print(chunk, end="", flush=True)
print()# 直接调用invoke方法
response = model.invoke("请用中文回答:1+1等于多少")
print(response.content)# 查看模型类型
print(model._llm_type)