【MySQL】CRUD
CRUD 简介
CRUD是对数据库中的记录进行基本的增删改查操作
- Create(创建)
- Retrieve(读取)
- Update(更新)
- Delete(删除)
一、新增(Create)
语法:
INSERT [INTO] table_name [(colum [, column] ...)]
VALUES (value_list) [, (value_list)] ...- INTO 可以省略但是一般不省略
- 表名后跟着要增加数据的列名,同时 数据的位置 也要对应 列的位置
示例:
2.1 单行数据 + 全列插入
-- 插入两条记录,value_list 数量必须和定义表的列的数量及顺序一致
INSERT INTO EXAM
VALUES (1,'唐三藏',70,80,90);INSERT INTO EXAM
VALUES (2,'孙悟空',90,90,90);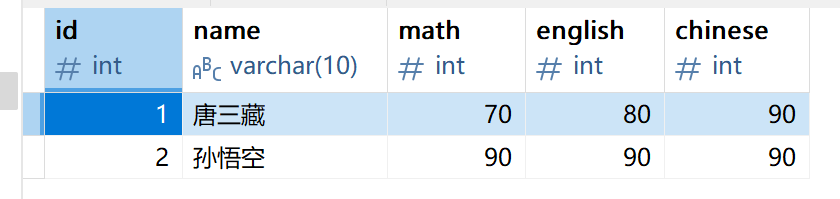
2.2 多行数据 + 指定列插入
-- 插入两条记录,value_list 数量必须和指定列数量及顺序一致
INSERT INTO EXAM(id,name,math) VALUES
(3,'猪八戒',60),
(4,'沙悟净',70);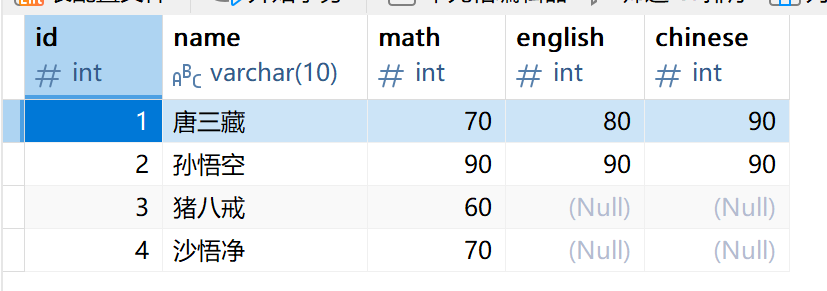
二、查询(Retrieve)
语法:
SELECT[DISTINCT]select_expr [, select_expr] ...[FROM table_references][WHERE where_condition][GROUP BY {col_name | expr}, ...][HAVING where_condition][ORDER BY {col_name | expr } [ASC | DESC], ...][LIMIT {[offset,] row_count | row_count OFFSET offset}]示例:
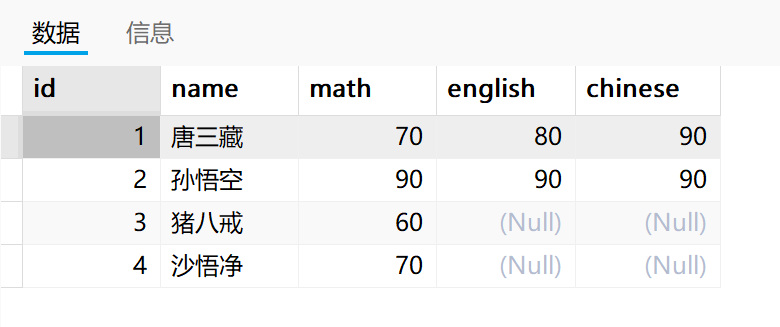
3.1 查询表中所有的列
select * from 表名;- select:表示查询的关键字
- * :所有的列
- from 表名:要从哪个表中查询数据
3.2 查询指定列
select 列名1 [,列名2] from 表名;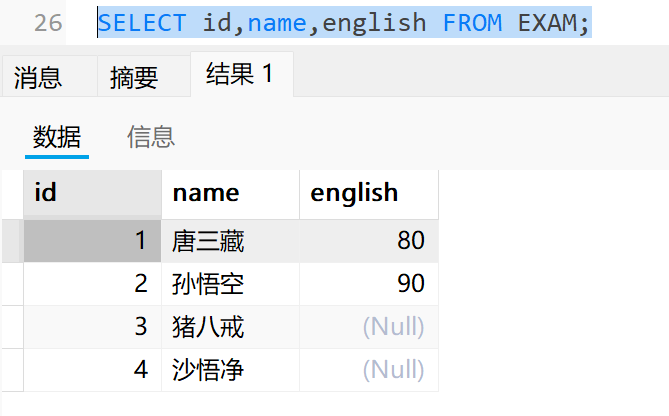
3.3 查询字段为表达式
常量表达式
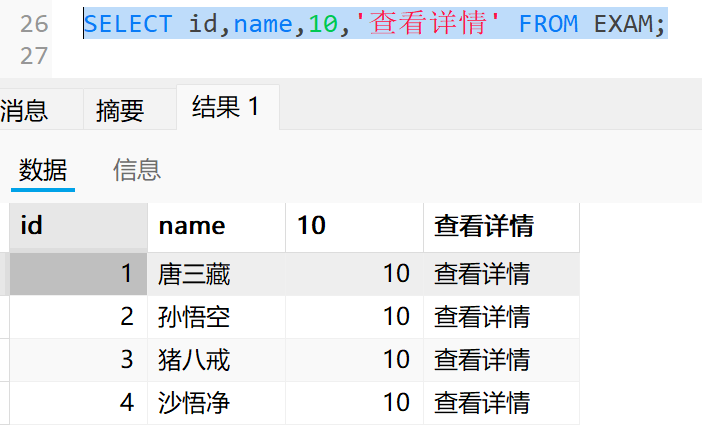
查询列表中的表达式可以是表中不存在的值或列,如果是字符串常量要写到单引号中
算术表达式
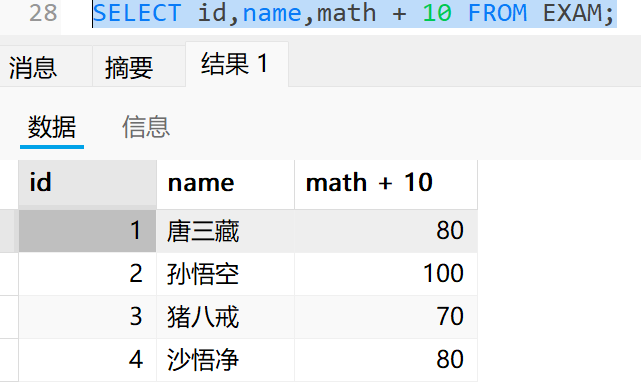
可以通过加上 as 来修改临时列名
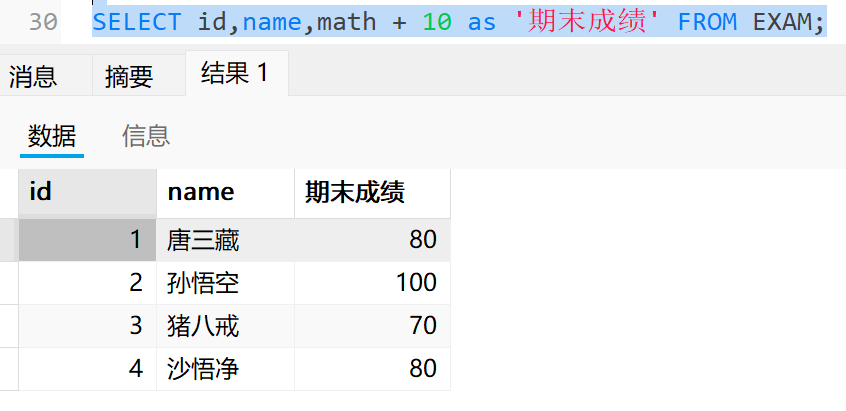
所有的 select 操作,都会先从物理表(真实存在的表)中查询对应的值,再计算表达式的值,合并结果后,通过临时表返回。
3.4 去重查询
通过 DISTINCT 关键字来对某列数据进行去重
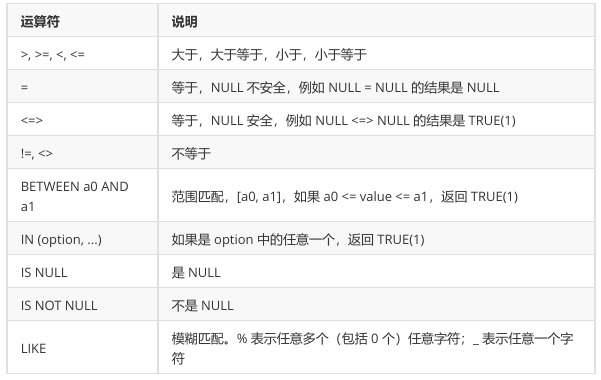
3.5 条件查询
比较运算符:
逻辑运算符:
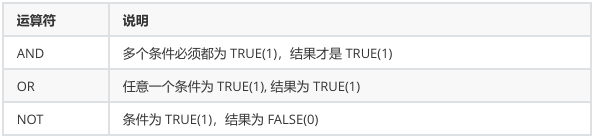
- WHERE条件可以使用表达式,但不能使用别名
- AND的优先级高于OR,在同时使用时,需要使用小括号()包裹优先执行的部分
代码示例:
插入数据:
INSERT INTO EXAM (id,name, chinese, math, english) VALUES(1,'唐三藏', 67, 98, 56),(2,'孙悟空', 87.5, 78, 77),(3,'猪悟能', 88, 98.5, 90),(4,'曹孟德', 82, 84, 67),(5,'刘玄德', 55.5, 85, 45),(6,'孙权', 70, 73, 78.5),(7,'宋公明', 75, 65, 30);-- 查询英语不及格的同学(<60)
SELECT name,english FROM EXAM WHERE english < 60;-- 查询语文成绩好于英语成绩的同学
SELECT name,chinese,english FROM EXAM WHERE chinese > english;-- 查询语文成绩大于80分且英语成绩大于80分的同学
SELECT * FROM EXAM WHERE chinese > 80 AND english > 80;-- 查询语文成绩大于80分或者英语成绩大于80分的同学
SELECT * FROM EXAM WHERE chinese > 80 OR english > 80;-- 查询语文成绩在 [80,90] 之间的同学
SELECT name,chinese FROM EXAM WHERE chinese BETWEEN 80 AND 90;-- 也可以使用 AND
SELECT name,chinese FROM EXAM WHERE chinese >= 80 AND chinese <= 90;-- 查询数学成绩是 58 或 59 的同学
SELECT name,math FROM EXAM WHERE math IN (58,59);-- 模糊查询
-- %匹配任意多个(包括0个)字符
SELECT name FROM EXAM WHERE name LIKE '孙%'; -- 匹配到孙悟空,孙权
-- _匹配严格的一个任意字符
SELECT name FROM EXAM WHERE name LIKE '孙_'; -- 匹配到孙权-- 查询数学成绩为空的人的数据
SELECT name,math FROM EXAM WHERE math is NULL;-- 查询数学成绩不为空的人的数据
SELECT name,math FROM EXAM WHERE math is NOT NULL;3.6 排序
语法:
-- ASC 为升序(从小到大)
-- DESC 为降序(从大到小)
-- 默认为ASC
SELECT ... FROM table_name [WHERE ...] ORDER BY {col_name | expr } [ASC | DESC], ... ;- 查询中没有 ORDER BY 子句返回的顺序永远是未定义的
- ORDER BY 子句中可以使用列的别名进行排序
- NULL 进行排序时,视为比任何值都小
3.7 分页查询
像前面提到的 SELECT * FROM 表名 不能有效限制结果集的大小,是不安全的查询,有可能把服务器的资源耗尽,通过分页查询可以有效减少服务器的压力,同时也有较好的用户体验
-- 起始下标为0,
-- 从 0 开始,筛选 n 条结果
SELECT ... FROM table_name [WHERE ...] [ORDER BY ...] LIMIT n;-- 从 s 开始,筛选 n 条结果
SELECT ... FROM table_name [WHERE ...] [ORDER BY ...] LIMIT s,n;-- 从 s 开始,筛选 n 条结果,用法比第二种更明确
SELECT ... FROM table_name [WHERE ...] [ORDER BY ...] LIMIT n OFFSET s;
三、修改(Updata)
语法:
Update 表名 set 列名 = 值 [,列名=值]... WHERE 条件;- 以原值的基础上做变更时,不能使用 math += 30 这样的语法
- 不加 WHERE 条件时,会导致全表数据被列新
四、删除(Delete)
语法:
DELETE FROM table_name [WHERE ...] [ORDER BY ...] [LIMIT ...]代码示例:
-- 删除孙悟空同学的考试成绩
DELETE FROM EXAM WHERE name = '孙悟空';-- 删除整表数据
DELETE FROM EXAM;- 不加 WHERE 条件时,会导致全表数据被删除
五、截断表
让表恢复到最开始创建的状态
语法:
TRUNCATE [TABLE] tbl_name;- 只能对整表进行操作,不像 DELETE 一样针对部分数据
- 不对数据操作所以比 DELETE 更快,TRUNCATE 在删除数据时不经过真正的事务,所以无法回溯
- 会重置 AUTO_INCREMENT 项
AUTO_INCREMENT 是创建列时添加的关键字,可以让数据库帮我们对这个列的数据进行自增,像 ID 这样,每次插入数据都会自动 + 1
六、插入查询结果
把一个查询获取的值插入到另一个表中
语法:
INSERT INTO table_name [(column [, column ...])] SELECT ...- 查询出来的列要与插入的列一一对应
当我们需要删除表中的数据,重复的数据只能有一份时,如果每次查询都使用 DISTINCT 进行去重操作会严重影响效率。可以通过创建一个与 要被去重的表 结构相同的表,把去重的记录写到新表中,以后查询都从新表中查,这样真实的数据不丢失,又能保证查询效率。
七、聚合函数
7.1 常用函数
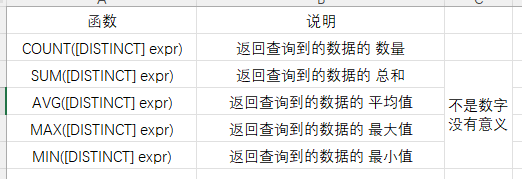
可以通过 COUNT(*) 来获取表中数据的数量,这个是 SQL 语言级别的标准,对于所有的软件都通用。
在 MYISAM 存储引擎中有一个变量记录了表中的记录数,获取记录可以通过这个变量直接读取,效率极高,但是不同数据库读取方式可能不同,要酌情使用
八、Group by 分组查询
GROUP BY 可以将一个数据集分为若干个小组,方便进行其他数据处理
语法:
SELECT {col_name | expr} ,...,aggregate_function (aggregate_expr) -- 查询列表FROM table_referencesGROUP BY {col_name | expr}, ... -- 分组条件[HAVING where_condition] -- 针对分组之后的结果进行过滤- 查询列表中如果要写列名,列必须是group by中的列,或是包含在聚合函数中
- aggregate_function:聚合函数,比如COUNT(),SUM(),AVG()...
Having 子句
使用 GROUP BY 对结果进行处理之后,对分组的结果进行过滤时,不能使用 WHERE 子句,而要使用 HAVING 子句
Having 与 Where 的区别
- Having 用于对分组结果的条件过滤
- Where 用于对表中真实数据的条件过滤
九、内置函数
在现在互联网项目中使用很少,因为可能对数据库的性能造成影响,一般把对数据的处理放在应用中
日期函数:

字符串函数:

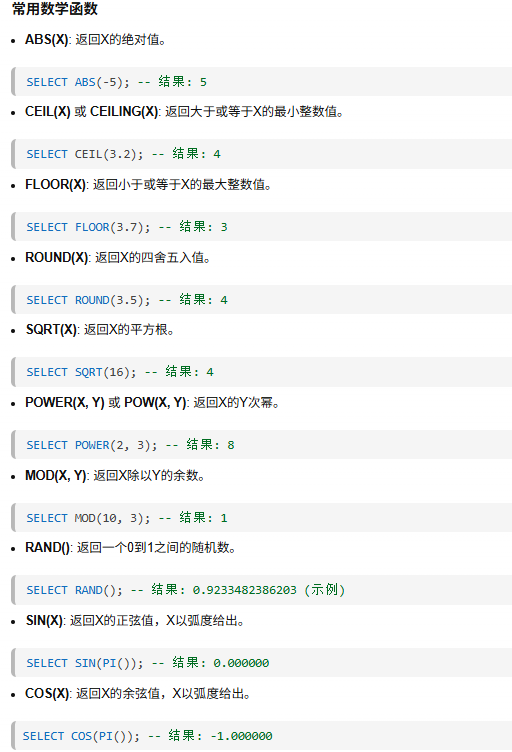
数学函数: