【AI论文】工具之星(Tool-Star):通过强化学习赋能具备大型语言模型(LLM)思维的多工具推理器
摘要:最近,大型语言模型(LLMs)通过大规模强化学习(RL)显示出卓越的推理能力。 然而,利用RL算法在LLMs中实现有效的多工具协同推理仍然是一个开放的挑战。 在本文中,我们介绍了Tool-Star,这是一个基于RL的框架,旨在使LLM能够在逐步推理过程中自主调用多个外部工具。 Tool-Star集成了六种工具,并在数据合成和培训中采用了系统设计。 为了解决工具使用数据稀缺的问题,我们提出了一种通用的工具集成推理数据合成管道,它将工具集成提示与基于提示的采样相结合,以自动和可扩展地生成工具使用轨迹。 随后的质量归一化和难度感知分类过程过滤掉低质量的样本,并将数据集从易到难进行组织。 此外,我们提出了一种两阶段训练框架,通过以下方式增强多工具协同推理:(1)冷启动微调,通过工具调用反馈引导LLM探索推理模式; 以及(2)一种具有分层奖励设计的多工具自批评RL算法,该算法增强了奖励理解并促进了有效的工具协作。 对10多个具有挑战性的推理基准的实验分析突出了Tool-Star的有效性和效率。 代码可以在https://github.com/dongguanting/Tool-Star上找到。Huggingface链接:Paper page,论文链接:2505.16410
研究背景和目的
研究背景
近年来,大型语言模型(LLMs)在自然语言处理领域取得了显著的进展,特别是在大规模强化学习(RL)的推动下,展现出了强大的推理能力。这些模型,如Deepseek R1和OpenAI o1,在链式思维(CoT)推理中展现出了深度思考、自我反思等复杂行为,从而显著提高了在复杂推理任务上的表现。然而,现实世界中的推理场景往往要求模型不仅能够进行内部推理,还需要与外部环境进行交互,通过调用外部工具来获取信息、执行计算或进行精确操作。
尽管工具集成推理(TIR)作为增强LLMs推理能力的一种新兴范式,受到了广泛关注,但现有研究主要集中在从强模型中蒸馏工具使用轨迹,并通过监督微调(SFT)指导弱模型进行模仿学习。这种方法虽然有效,但严重依赖于高质量的工具使用数据,且难以使LLMs自主发现有效的工具使用模式。此外,现有的RL方法虽然鼓励探索高效的工具使用行为,但主要聚焦于单个工具的使用,缺乏对多工具协同推理的系统性研究。
研究目的
本文旨在填补这一研究空白,通过提出Tool-Star框架,探索如何利用强化学习使LLMs能够在逐步推理过程中自主调用多个外部工具,实现多工具协同推理。具体而言,本研究旨在:
- 设计一个通用的工具集成推理数据合成管道:通过结合工具集成提示和基于提示的采样,自动且可扩展地生成工具使用轨迹,解决工具使用数据稀缺的问题。
- 提出一个两阶段训练框架:通过冷启动微调和多工具自批评RL算法,增强LLMs的多工具协同推理能力。冷启动微调阶段通过工具调用反馈引导LLMs探索推理模式,而多工具自批评RL算法则通过分层奖励设计,强化奖励理解,促进有效的工具协作。
- 验证Tool-Star框架的有效性和效率:在多个具有挑战性的推理基准上进行实验分析,展示Tool-Star在提升LLMs多工具协同推理能力方面的优势。
研究方法
数据合成
为了解决工具使用数据稀缺的问题,本文设计了一个通用的工具集成推理数据合成管道。该管道包括三个主要步骤:
- 数据收集与采样:从开源的知识型和计算型推理数据集中收集高质量的训练集,并通过工具集成提示和基于提示的采样两种策略,自动生成大规模的工具使用轨迹。
- 工具使用质量归一化:通过控制工具调用频率、去除重复工具调用和格式标准化等策略,确保工具使用的合理性。
- 难度感知数据分类:根据工具使用的必要性和样本难度,将数据集分为冷启动微调数据集和强化学习数据集,实现从易到难的渐进式学习。
训练框架
本文提出了一个两阶段训练框架,以增强LLMs的多工具协同推理能力:
- 冷启动微调:在冷启动阶段,通过监督微调使LLMs初步具备通过工具调用解决问题的理解。具体而言,使用冷启动数据集对LLMs进行微调,使其能够根据工具调用反馈探索推理模式。
- 多工具自批评RL算法:在RL阶段,引入多工具自批评RL算法,通过分层奖励设计强化奖励理解,促进有效的工具协作。该算法包括记忆回放机制、分层奖励设计和自批评RL算法三个核心组件。记忆回放机制通过缓存工具请求和输出,提高工具调用的效率;分层奖励设计不仅评估答案的正确性和工具使用格式,还为多个工具的有效使用提供额外奖励;自批评RL算法则通过自采样奖励数据,帮助LLMs更好地内化奖励结构。
研究结果
整体性能
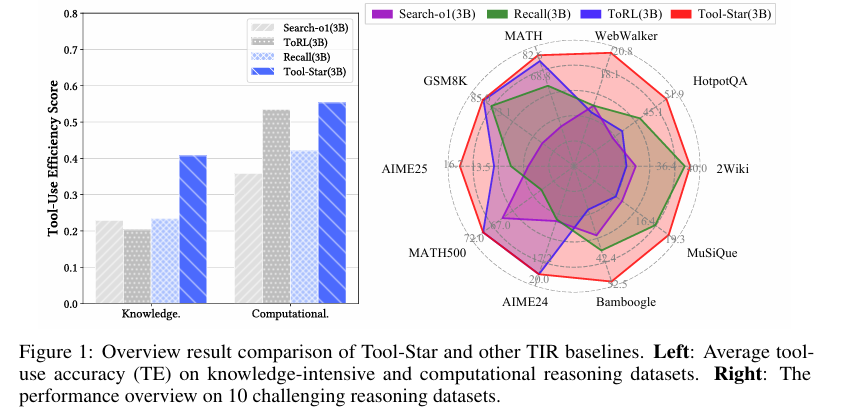
实验结果表明,Tool-Star在多个具有挑战性的推理基准上显著优于现有基线方法。在计算型推理任务(如AIME24、MATH500)和知识密集型推理任务(如WebWalker、HotpotQA)上,Tool-Star均展现出了强大的推理能力和工具使用效率。具体而言,Tool-Star在平均工具使用准确率(TE)和整体性能上均优于其他TIR方法,证明了其在多工具协同推理方面的优势。
定量分析
通过消融实验,本文进一步验证了Tool-Star框架中各个组件的重要性。实验结果表明,移除冷启动阶段或RL阶段均会导致性能显著下降,说明这两个阶段在Tool-Star框架中均不可或缺且相互补充。此外,引入分层奖励和自批评机制后,模型性能进一步提升,证明了这些设计策略的有效性。
工具使用效率
在工具使用效率方面,Tool-Star同样表现优异。通过比较不同TIR方法在知识密集型和计算型推理数据集上的工具使用准确率,发现Tool-Star能够高效地调用工具进行逐步推理,且在不同任务类型和基线方法上均保持较高的工具使用准确率。
研究局限
尽管Tool-Star在多工具协同推理方面取得了显著进展,但仍存在以下局限性:
- 工具多样性有限:目前,Tool-Star框架仅集成了六种工具,相比现有工作中依赖单一工具的方法已有显著进步,但仍有大量工具等待探索。未来研究可以进一步扩展工具类型和集成方式,以增强LLMs的推理能力。
- 骨干模型参数规模受限:由于计算资源有限和滚出过程耗时较长,本研究主要关注0.5B、1.5B和3B参数规模的模型。尽管“参数规模缩放分析”提供了Tool-Star框架可扩展性的初步证据,但未来研究可以在更大规模的模型上进行实验,以评估其在更复杂任务和模型容量上的泛化能力。
- 评估指标有限:本文主要关注工具使用准确率和整体推理性能作为评估指标,未来研究可以考虑引入更多评估指标,如工具调用的时效性、资源消耗等,以更全面地评估Tool-Star框架的性能。
未来研究方向
针对Tool-Star框架的局限性和当前研究的不足,未来研究可以从以下几个方面展开:
- 扩展工具多样性:探索更多类型的工具,并将其集成到Tool-Star框架中。例如,可以引入视觉语言模型(VLMs)作为外部工具,以解锁视觉理解能力;或者采用模型上下文协议,实现更灵活的工具调用。
- 扩展骨干模型参数规模:在更大规模的模型上进行实验,以评估Tool-Star框架在更复杂任务和模型容量上的泛化能力。这有助于进一步验证Tool-Star框架的可扩展性和有效性。
- 引入更多评估指标:除了工具使用准确率和整体推理性能外,还可以考虑引入工具调用的时效性、资源消耗等评估指标,以更全面地评估Tool-Star框架的性能。
- 探索新的训练策略:尝试将Tool-Star框架与其他先进的训练策略相结合,如课程学习、元学习等,以进一步提升LLMs的多工具协同推理能力。
- 实际应用场景验证:将Tool-Star框架应用于实际场景中,如智能客服、自动问答系统等,以验证其在真实世界中的有效性和实用性。