R基于逻辑回归模型实现心脏病检测及SHAP值解释项目实战
说明:这是一个机器学习实战项目(附带数据+代码+文档+视频讲解),如需数据+代码+文档+视频讲解可以直接到文章最后关注获取。

1.项目背景
心血管疾病是全球范围内导致死亡的主要原因之一,每年有数百万人因此失去生命。在众多的心脏病中,冠心病尤为常见,它是由向心脏供血的冠状动脉发生硬化或阻塞所引起的。早期发现心脏病的风险因素并进行有效干预对于降低发病率和死亡率至关重要。然而,由于心脏病的发生受到多种复杂因素的影响,包括但不限于年龄、性别、血压、胆固醇水平等,传统的诊断方法往往存在一定的局限性。基于此,利用先进的数据分析技术,特别是逻辑回归模型,对心脏病风险进行预测成为了研究热点之一。
逻辑回归作为一种广泛应用于医学领域的统计分析方法,能够有效地处理二分类问题,并通过概率形式输出结果,非常适合用于心脏病风险评估。通过收集患者的各种生理指标数据,如年龄、性别、体重指数(BMI)、血压、血糖水平等,逻辑回归模型可以学习到这些特征与心脏病发作之间的关系,从而帮助医生更准确地识别高危人群。此外,随着机器学习解释性的日益重视,SHAP(Shapley Additive exPlanations)值作为一种新兴的解释工具,能够为每个预测提供详细的贡献度分析,使得模型不仅限于预测,还能解释为何做出这样的预测,这对于医疗决策支持系统尤为重要。
本项目旨在利用R语言实现一个基于逻辑回归的心脏病检测模型,并采用SHAP值来解释模型的预测结果。首先,我们将从公开的数据集中获取心脏病相关的多维度数据,然后进行必要的数据清洗和预处理工作,以确保数据的质量和一致性。接着,使用逻辑回归模型训练数据,并评估其性能。最后,借助SHAP值深入分析各特征对心脏病预测的重要性及其影响方向,进而提升模型的透明度和可解释性。通过这一系列步骤,我们期望不仅能提高心脏病预测的准确性,还能为临床医生提供有价值的参考信息,辅助制定个性化的治疗方案。
本项目通过R基于逻辑回归模型实现心脏病检测及SHAP值解释项目实战。
2.数据获取
本次建模数据来源于网络(本项目撰写人整理而成),数据项统计如下:
| 编号 | 变量名称 | 描述 |
| 1 | age | 病人的年龄(以年为单位) |
| 2 | sex | 病人性别 (1 = 男, 0 = 女) |
| 3 | cp | 胸痛类型 (1: 典型心绞痛, 2: 非典型心绞痛, 3: 无心绞痛, 4: 无症状) |
| 4 | trestbps | 入院时的静息血压(毫米汞柱) |
| 5 | chol | 血清中的胆固醇含量(毫克/分升) |
| 6 | fbs | 空腹血糖水平 (> 120 mg/dl 为 1, 否则为 0) |
| 7 | restecg | 静息心电图结果 (0: 正常, 1: ST-T 波异常, 2: 可能或肯定的左室肥大) |
| 8 | thalach | 达到的最大心率 |
| 9 | exang | 运动诱发的心绞痛 (1 = 是, 0 = 否) |
| 10 | oldpeak | 相对于休息的旧峰 ST 抑制(连续值) |
| 11 | slope | 峰值运动 ST 段的斜率 (1: 上坡, 2: 平坦, 3: 下坡) |
| 12 | ca | 通过荧光透视显示的主要血管数目(0-3) |
| 13 | thal | 心肌灌注显像的结果 (3 = 正常, 6 = 固定缺陷, 7 = 可逆缺陷) |
| 14 | y | 0 = 没有心脏病病,1 = 有心脏病 |
数据详情如下(部分展示):

3.数据预处理
3.1 查看数据
使用head()方法查看前五行数据:

关键代码:
![]()
3.2数据缺失查看
使用colSums方法统计数据缺失信息:

从上图可以看到,总共有14个变量,数据中无缺失值。
关键代码:

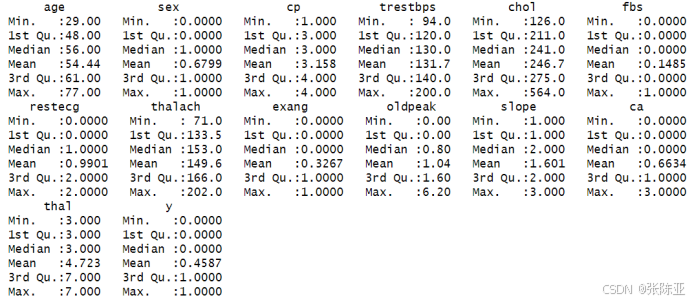
3.3数据描述性统计
通过summary方法来查看数据的平均值、最小值、分位数、最大值。
关键代码如下:

4.探索性数据分析
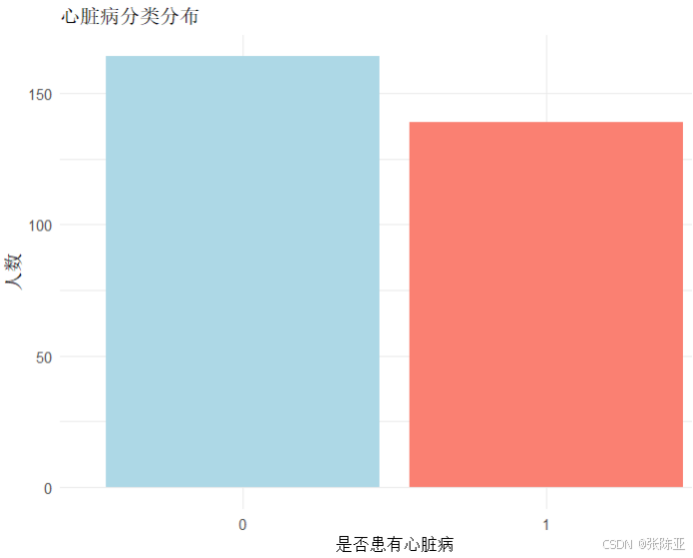
4.1 因变量柱状图
用ggplot工具绘制柱状图:
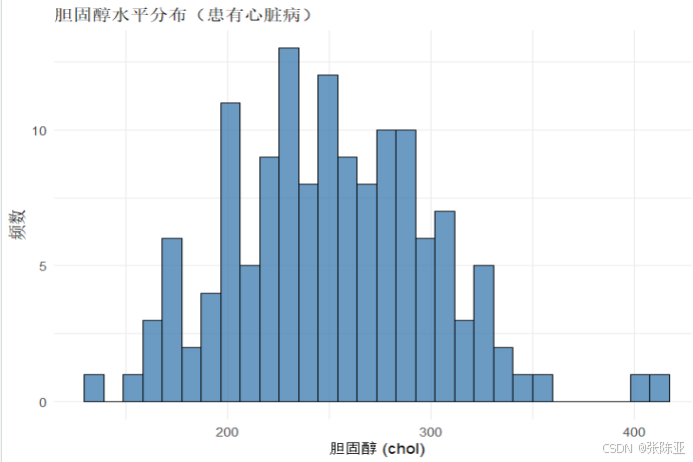
4.2 y=1样本chol变量分布直方图
用ggplot工具绘制直方图:
4.3 相关性分析
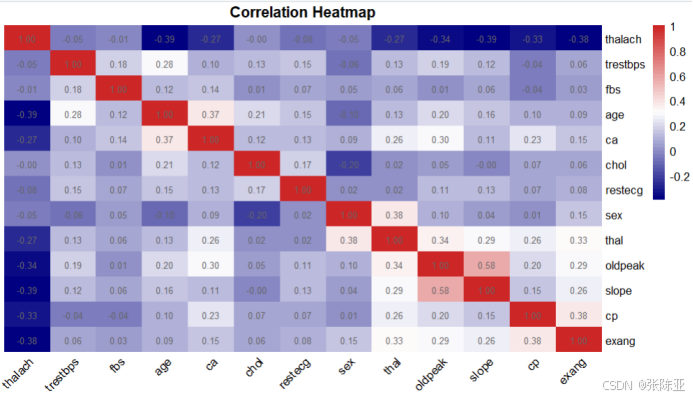
从上图中可以看到,数值越大相关性越强,正值是正相关、负值是负相关。
5.特征工程
5.1 哑特征处理
哑特征处理,即将类别型变量转换为若干二进制变量,以利于统计模型中使用,有效提高模型准确性与解释力。
关键代码如下:
![]()
处理结果部分展示:
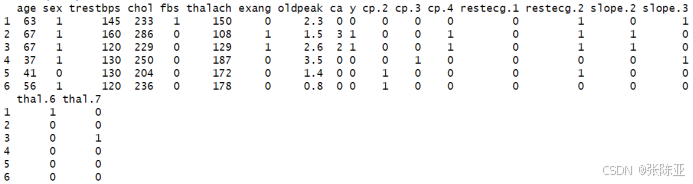
5.2 数据集拆分
通过subset方法按照80%训练集、20%验证集进行划分,关键代码如下:

6.构建逻辑回归分类模型
主要通过R基于逻辑回归模型实现心脏病检测,用于目标分类。
6.1 构建模型
| 模型名称 | 模型参数 |
| 逻辑回归分类模型 | y ~ . |
| data = data | |
| family = binomial(link = 'logit') |
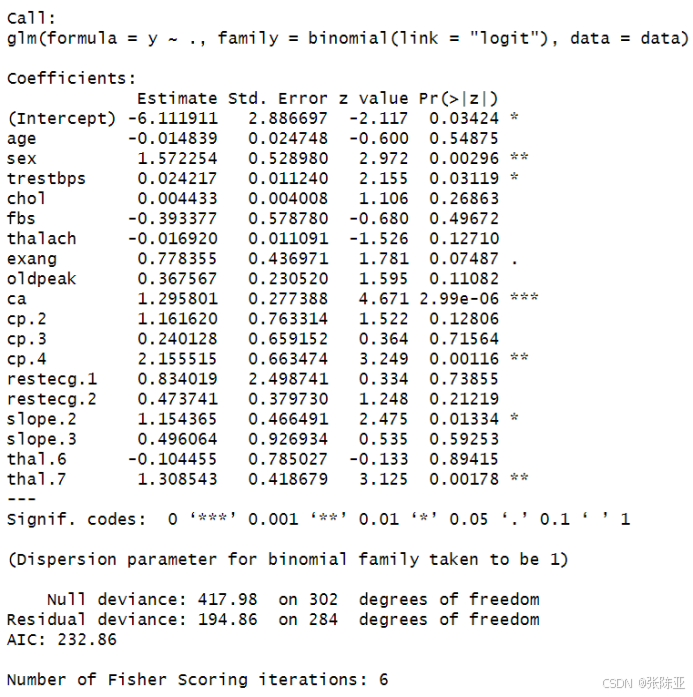
6.2 模型摘要信息
7.模型评估
7.1评估指标及结果
评估指标主要包括准确率、查准率、查全率、F1分值等等。
| 模型名称 | 指标名称 | 指标值 |
| 测试集 | ||
| 逻辑回归分类模型 | 准确率 | 0.8360656 |
| 查准率 | 0.8285714 | |
| 查全率 | 0.8787879 | |
| F1分值 | 0.8529412 | |
从上表可以看出,F1分值为0.8529,说明逻辑回归模型效果良好。
关键代码如下:

7.2 混淆矩阵
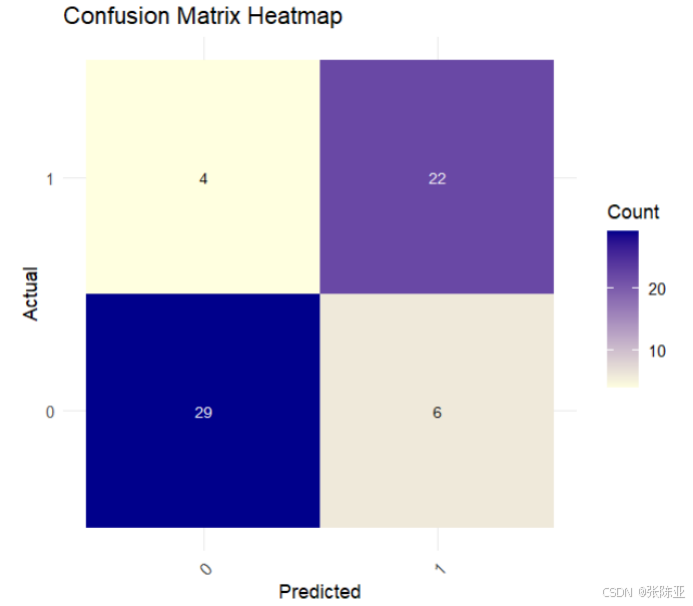
从上图可以看出,实际为0预测不为0的 有6个样本,实际为1预测不为1的 有4个样本,模型效果良好。
7.3 SHAP解释图
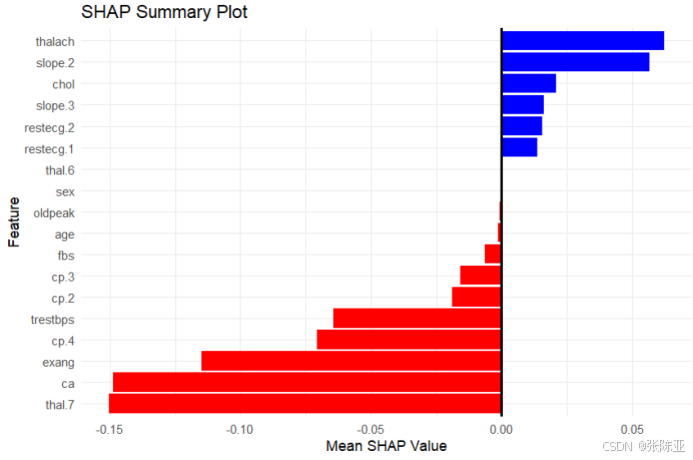
SHAP图通常用来展示特征对模型预测的贡献程度,从上图可以看出,蓝色代表正向影响,红色代表负向影响, SHAP值越大对模型的贡献越大。
8.结论与展望
综上所述,本文采用了通过逻辑回归分类算法来构建分类模型,最终证明了我们提出的模型效果良好。此模型可用于日常产品的建模工作。