CAU人工智能class4 批次归一化
归一化
在对输入数据进行预处理时会用到归一化,将输入数据的范围收缩到0到1之间,这有利于避免纲量对模型训练产生的影响。
但当模型过深时会产生下述问题:
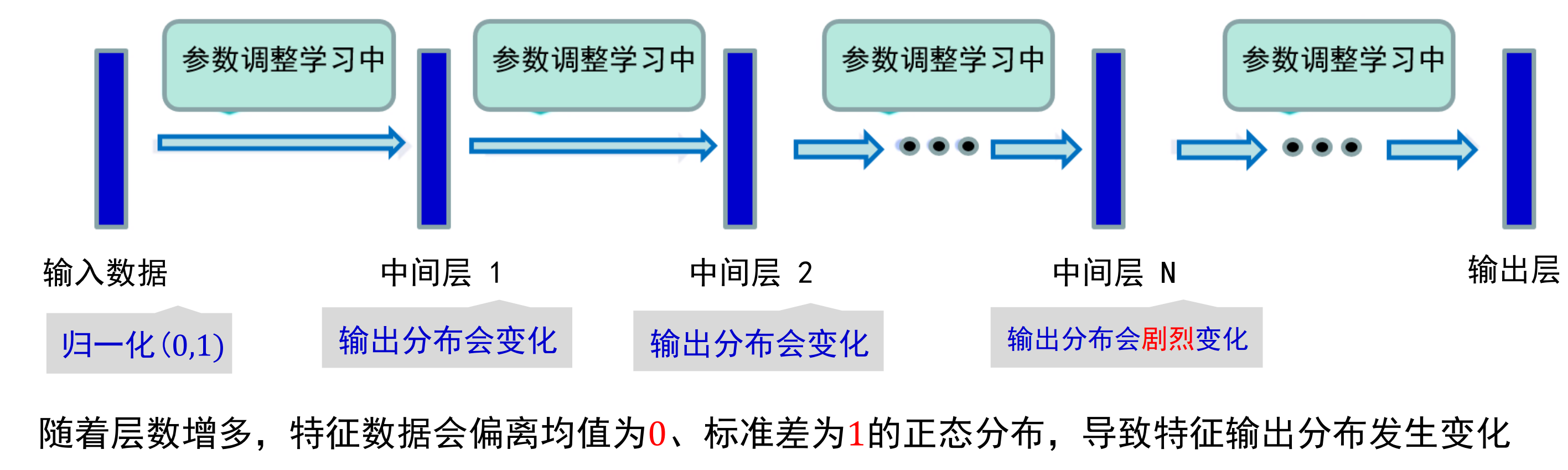
当一个学习系统的输入分布发生变化时,这种现象称之为“内部协变量偏移”(Internal Covariate Shift)。
内部协变量偏移
内部协变量偏移借鉴了统计学中的“协变量偏移”概念, 协变量(Covariate)指的是在分析某一因变量与其关系时,除了自变量以外,可能影响因变量的其他变量。
协变量的存在可能混淆自变量和因变量之间的因果关系,故在研究中通常对协变量进行控制或校正。模型在训练时遇到数据分布发生变化,会影响模型的泛化能力。
内部协变量偏移的影响
需要较低的学习率
如果某一层的输入分布突然变化(例如均值或方差大幅波动),则该层的参数更新可能会破坏之前学到的特征。为了稳定训练,必须使用较小的学习率,这会显著减慢训练速度。
参数初始化敏感
参数初始化不合理会直接影响到模型的收敛速度、训练效率以及最终模型的性能。
原因:
- 引发梯度消失/爆炸问题:在计算梯度时会计算激活函数的倒数(斜率),而特别时饱和的激活函数的斜率在某些位置接近于0(或很大),这就会导致梯度消失或爆炸问题。
- 更快的模型收敛:更快的模型收敛
有利于训练的参数初始化

训练一个深度学习模型,如果希望模型有比较好的收敛效果,需要的前提
条件是每一层的输入数据有稳定的数据分布
批次归一化
批次归一化是对一个 batch 的数据在网络各层的输出做标准化处理,固定小批量里面的均值和方差,使得在不同层数据保持相同分布,即满足标准正态分布。
优点
- 批规一化允许使用更高的学习率
- 并且对初始化的要求不那么严格
- 它还起到了正则化的作用,在某些情况下甚至可以消除对 Dropout 的需求
步骤
𝐵𝑎𝑡𝑐ℎ𝑁𝑜𝑟𝑚 主要思路是在训练时按 𝑚𝑖𝑛𝑖 − 𝑏𝑎𝑡𝑐ℎ 为单位,对神经元的数值进行归一化,使数据的分布满足 均值为 0,方差为 1。具体计算过程如下(4步):
- 计算 𝑚𝑖𝑛𝑖 − 𝑏𝑎𝑡𝑐ℎ 内样本的均值

- 计算 𝑚𝑖𝑛𝑖 − 𝑏𝑎𝑡𝑐ℎ 内样本的方差
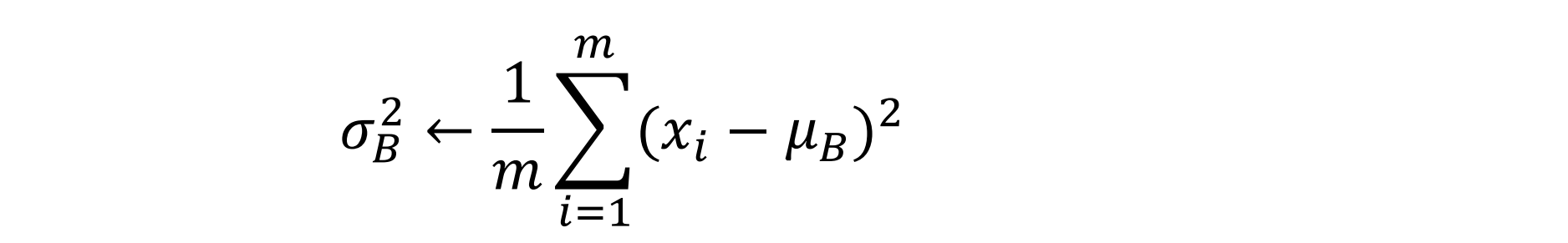
- 归一化


其中 𝜖 是一个微小值(例如 1e−7) - 对标准化的输出进行缩放和平移
如果强行限制输出层的分布满足标准正态化,使得数据集中在激活函数中心的线性区域,反而使激活函数丧失了非线性特性。
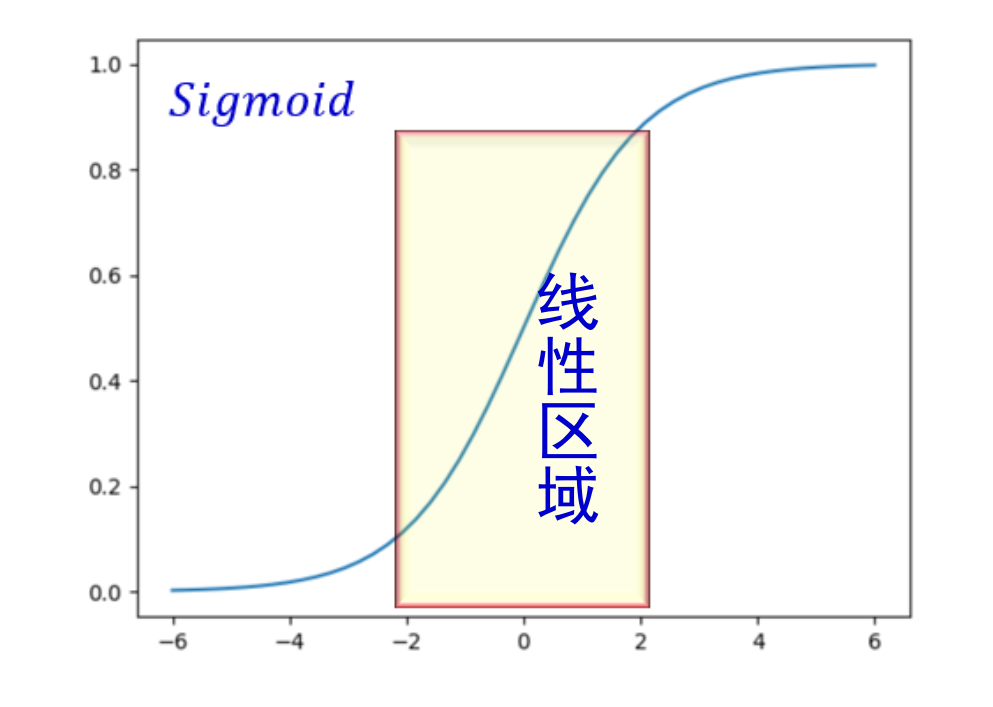
可能会导致某些特征模式的丢失。因此在 BN 操作中为每个卷积核引入了两个可训练参数:缩放 (𝑆𝑐𝑎𝑙𝑒)因子 𝛾 和偏移(𝑆ℎ𝑖𝑓𝑡)因子 𝛽。
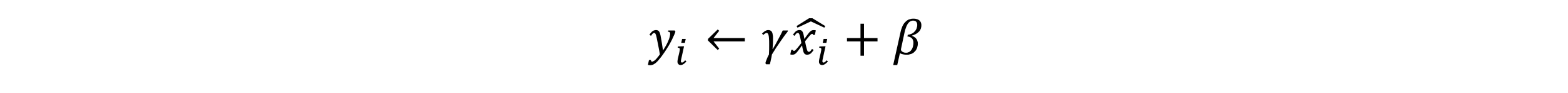
其中γ 和β 是可学习的参数,可以赋初始值 𝛾 = 1,β = 0 , 在训练过程中不断学习调整。而均值 𝜇𝐵 和方差 𝜎𝐵2 是计算得到的。
调节的原理:
γ 的作用:γ 可以调整归一化后数据的方差,使其恢复到原始数据的尺度。

β 的作用:β 可以调整归一化后数据的均值,使其恢复到原始数据的均值。
这样通过调节这两个参数可以保留一部分原数据的分布。
批量归一化的位置
放在激活函数前面
激活函数是类似于 sigmoid 有一定饱和区域的函数。则可以把归一化层放在激活函数之前,在一定程度上可以缓解梯度消失问题
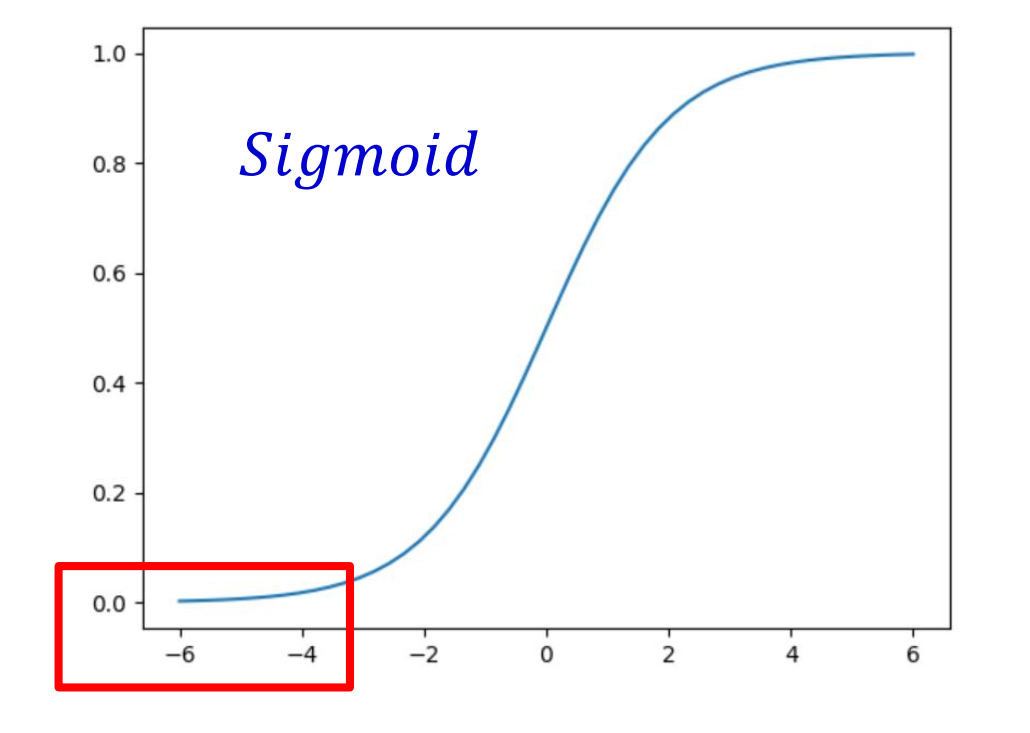
如上图所示:假设未经过 BN 调整。
正态分布均值: −6
方差: 1
意味着 95 % 的值落在位于两个标准差[−2, 2] 的区间内,即 [−8, −4] 之间,而对应的 Sigmoid 函数的值明显接近于 0 ,这是典型的梯度饱和区。意味着梯度变化很小甚至消失。
而当落在的区间比较大时,计算出的梯度同样很小。

问题:

因此要对分布区间进行一定的变换,使其大部分落在函数敏感区间。


放在激活函数之后
如果激活函数是类似于 relu 这样的激活函数,那么可以把归一化层放在激活函数之后,可以有效避免数据在激活之前被转化成相似的模式,从而使得非线性特征分布趋于同化。
批归一化与dropout的冲突
当 Dropout 和 BN 这两个强大的方法在实际上结合使用的时候,反而经常无法获得性能上额外的增益。事实上,当主流卷积网络在同时配备 BN 和 Dropout 时,在很多情况下它们的性能甚至会变得更差。
方差偏移
每层的输入分布由于上一层的参数更新变得不稳定(方差不一致),随着信号变深,最终预测的数值偏差可能会被不断的放大,从而降低系统的性能.
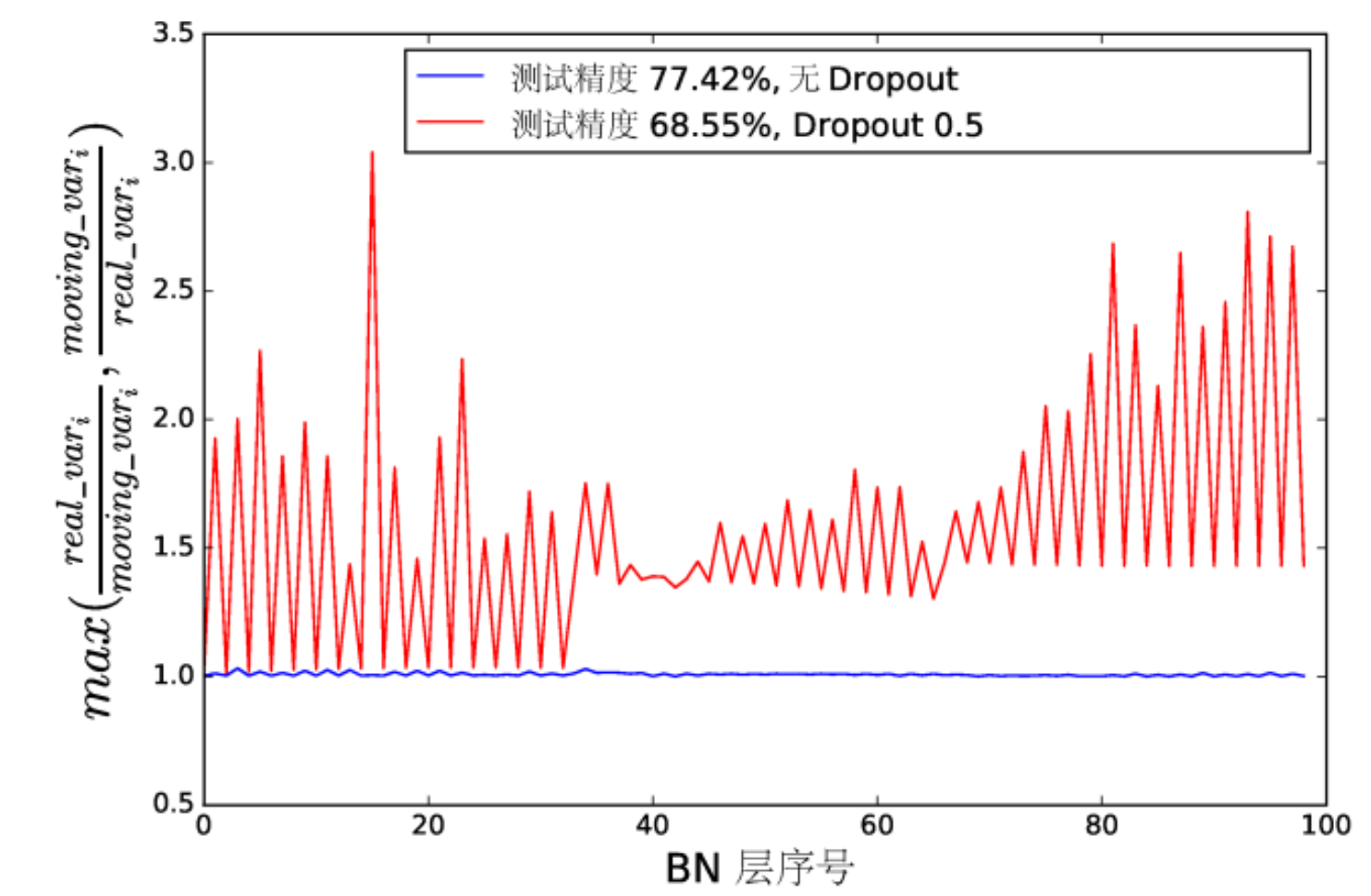
从图中可以看到,没有使用dropout的模型每层的方差变化不大(蓝线),而使用了dropout的红线方差极不稳定(红线)
解决方法
