嵌入式学习Day27
进程:
进程是操作系统中的一个基本概念,指的是正在执行的程序实例。每个进程都有独立的内存空间、系统资源和执行状态。操作系统通过进程管理来分配资源、调度任务和确保系统的稳定性。
进程的组成
- 代码段:存储程序的指令。
- 数据段:存储全局变量和静态变量。
- 堆:用于动态内存分配。
- 栈:用于存储函数调用和局部变量。
- 进程控制块(PCB):操作系统用于管理进程的数据结构,包含进程状态、程序计数器、寄存器值等信息。
进程的状态
进程在其生命周期中会经历多种状态,常见的状态包括:
- 新建:进程刚被创建。
- 就绪:进程已准备好运行,等待CPU分配。
- 运行:进程正在CPU上执行。
- 阻塞:进程等待某些事件(如I/O操作)完成。
- 终止:进程执行完毕或被强制终止。
linux中的状态,运行态,睡眠态,僵尸,暂停态。
进程与线程的区别:
进程是资源分配的基本单位,而线程是CPU调度的基本单位。一个进程可以包含多个线程,线程共享进程的内存空间和资源,但每个线程有自己的栈和程序计数器。
程序:静态、存储在硬盘中代码,数据的集合
进程:动态、程序执行的过程,包括进程的创建、调度、消亡
.c ----> a.out-----> process(pid)
1)程序是永存,进程是暂时的
2)进程有程序状态的变化,程序没有
3)进程可以并发,程序无并发
4)进程与进程会存在竞争计算机的资源
5)一个程序可以运行多次,变成多个进程
一个进程可以运行一个或多个程序。
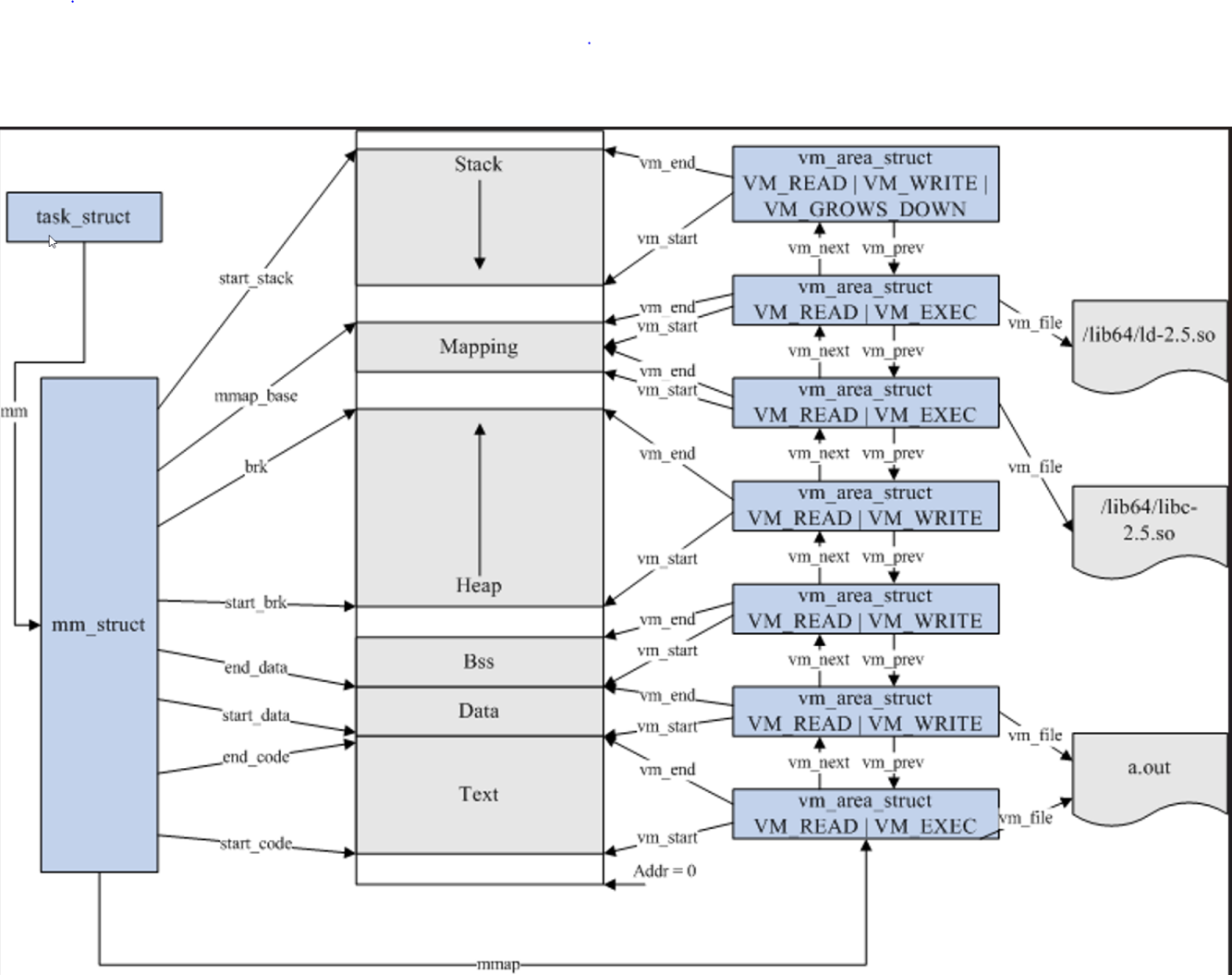
进程内存分布:
代码段(Text Segment)
代码段存储了程序的执行代码,通常是只读的,以防止程序在运行过程中意外修改指令。这部分内存包含了编译后的机器指令。
数据段(Data Segment)
数据段分为初始化数据段和未初始化数据段。初始化数据段存储了程序中明确初始化的全局变量和静态变量。未初始化数据段(BSS段)存储了未初始化的全局变量和静态变量,操作系统在程序启动时会将其初始化为零。
堆(Heap)
堆用于动态内存分配,程序在运行时可以通过malloc、calloc、realloc等函数在堆上申请内存。堆的大小不固定,可以根据需要动态增长或缩减。
栈(Stack)
栈用于存储函数调用的上下文信息,包括局部变量、函数参数、返回地址等。栈是后进先出(LIFO)的数据结构,每次函数调用时都会在栈上分配一个新的栈帧,函数返回时栈帧会被释放。
内存映射段(Memory Mapping Segment)
内存映射段用于将文件或设备映射到进程的地址空间。常见的用途包括动态链接库的加载和内存映射文件(mmap)。
0-3G,是进程的空间,3G-4G是内核的空间,虚拟地址
虚拟地址 * 物理内存和虚拟内存的地址 映射表 1page=4k
进程的作用
进程在计算机系统中扮演着至关重要的角色,具体作用包括:
资源分配
操作系统通过进程为单位分配和管理系统资源,如CPU时间、内存、文件句柄等。每个进程拥有独立的地址空间,确保程序运行时的隔离性和安全性。
并发执行
进程支持多任务并发执行。操作系统通过进程调度算法在多个进程之间切换,使得多个程序可以同时运行,提高系统资源利用率和用户体验。
程序隔离
每个进程运行在独立的内存空间中,互不干扰。这种隔离机制防止了一个进程的崩溃或错误影响其他进程或整个系统的稳定性。
通信与同步
进程间可以通过操作系统提供的机制(如管道、消息队列、共享内存等)进行通信和同步,实现数据交换和协作完成任务。
状态管理
操作系统通过进程控制块(PCB)记录和管理进程的状态(如运行、就绪、阻塞等),确保进程能够正确执行和恢复。
进程调度
操作系统通过进程调度算法决定哪个进程获得CPU资源。常见的调度算法包括:
- 先来先服务(FCFS):按进程到达顺序调度。
- 短作业优先(SJF):优先调度执行时间短的进程。
- 时间片轮转(Round Robin):每个进程分配固定的时间片轮流执行。
- 优先级调度(Priority Scheduling):根据进程优先级进行调度。
内核主要功能之一就是完成进程调度, 硬件,bios,io,文件系统,驱动
调度算法, other,idle、rr,fifo
宏观并行、微观串行
查询进程状态
ps 命令用于显示当前进程的状态。常用的选项包括:
ps aux该命令会列出所有用户的进程,包括进程ID、CPU和内存使用率、启动时间等详细信息。
实时监控进程
top 命令可以实时显示系统中各个进程的资源占用情况,包括CPU、内存等。
top在 top 界面中,可以按 P 键按CPU使用率排序,按 M 键按内存使用率排序。
查找特定进程
pgrep 命令可以根据进程名查找进程ID。
pgrep firefox该命令会返回所有名为 firefox 的进程ID。
显示进程树
pstree 命令以树状图的形式显示进程及其子进程。
pstree该命令可以清晰地展示进程之间的父子关系。
结束进程
kill 命令用于终止指定进程。需要提供进程ID。
kill 1234如果需要强制终止进程,可以使用 -9 选项:
kill -9 1234显示进程详细信息
/proc 文件系统包含了系统中所有进程的详细信息。可以通过访问 /proc/[pid] 目录来查看特定进程的信息。
cat /proc/1234/status该命令会显示进程ID为 1234 的进程状态信息。
查找进程使用的文件
lsof 命令可以列出进程打开的文件。
lsof -p 1234该命令会显示进程ID为 1234 的进程打开的所有文件。
显示进程的资源限制
ulimit 命令可以显示或设置进程的资源限制。
ulimit -a该命令会显示当前shell的资源限制设置。这些命令可以帮助用户有效地管理和监控系统中的进程。
fork:
fork 是一个在 Unix 和类 Unix 操作系统(如 Linux)中用于创建新进程的系统调用。通过 fork,一个进程可以创建一个与自己几乎完全相同的子进程。子进程是父进程的副本,拥有相同的代码、数据和堆栈,但它们在内存中是独立的。
fork 的基本用法
在 C 语言中,fork 函数的原型如下:
#include <unistd.h>pid_t fork(void);fork 函数调用成功后,会返回两次:一次在父进程中,一次在子进程中。在父进程中,fork 返回子进程的进程 ID(PID);在子进程中,fork 返回 0。如果 fork 失败,则返回 -1。
fork 的工作原理
fork 创建的子进程是父进程的副本,包括代码、数据、堆栈、打开的文件描述符等。子进程从 fork 调用处开始执行,与父进程并发运行。由于子进程是父进程的副本,它们共享相同的代码段,但拥有独立的数据段和堆栈。
fork 的常见用途
fork 通常用于以下场景:
- 创建并发执行的子进程,以处理多个任务。
- 在服务器程序中,为每个客户端连接创建一个新的子进程。
- 在 shell 中执行外部命令时,通常会使用
fork创建一个子进程来执行命令。
fork 的注意事项
fork创建的子进程会继承父进程的所有打开的文件描述符,包括标准输入、输出和错误。- 子进程和父进程的执行顺序是不确定的,取决于操作系统的调度策略。
fork是一个相对昂贵的操作,因为它需要复制父进程的整个地址空间。
getpid:
getpid 是一个系统调用,用于获取当前进程的进程 ID(PID)。在 Unix 和类 Unix 系统(如 Linux)中,每个进程都有一个唯一的进程 ID,用于标识该进程。
getppid:
getppid 是一个系统调用,用于获取当前进程的父进程的进程 ID(PID)。这个函数在 C 语言中通过 <unistd.h> 头文件提供。
写时复制:
写时复制(Copy-on-Write,简称COW)是一种优化技术,主要用于在多个进程或线程共享相同资源时,延迟实际的数据复制操作,直到某个进程或线程尝试修改数据时才进行复制。这种技术可以显著减少不必要的内存复制操作,从而提高系统性能。
写时复制的原理
在写时复制机制下,当多个进程或线程共享同一块内存区域时,系统并不会立即为每个进程或线程复制一份独立的数据副本。相反,系统会维护一个引用计数,记录有多少个进程或线程正在共享该数据。只有当某个进程或线程尝试修改数据时,系统才会为该进程或线程创建一个独立的数据副本,并在此副本上进行修改操作。这样,未修改的数据仍然可以被多个进程或线程共享,从而节省内存资源。
写时复制的应用场景
写时复制技术广泛应用于操作系统、数据库管理系统和编程语言中。以下是一些常见的应用场景:
-
操作系统中的进程创建:在Unix/Linux系统中,
fork()系统调用用于创建新进程。使用写时复制技术,fork()不会立即复制父进程的内存空间,而是让子进程共享父进程的内存空间。只有当子进程或父进程尝试修改内存时,才会进行实际的复制操作。 -
虚拟内存管理:在虚拟内存系统中,写时复制技术可以用于管理内存页的复制。当多个进程共享同一内存页时,系统不会立即复制该页,直到某个进程尝试写入该页时才会进行复制。
-
数据库管理系统:在数据库管理系统中,写时复制技术可以用于实现事务的隔离性。多个事务可以共享相同的数据页,直到某个事务尝试修改数据时,系统才会为该事务创建一个独立的数据副本。
写时复制的优缺点
优点:
- 节省内存:通过延迟复制操作,写时复制技术可以显著减少内存使用量,特别是在多个进程或线程共享大量数据时。
- 提高性能:由于减少了不必要的内存复制操作,写时复制技术可以提高系统的整体性能。
缺点:
- 复杂性增加:实现写时复制机制需要额外的逻辑来管理引用计数和复制操作,这增加了系统的复杂性。
- 潜在的性能开销:虽然写时复制可以减少内存复制操作,但在某些情况下,频繁的复制操作可能会导致性能下降,特别是在高并发环境下。
写时复制是一种有效的优化技术,适用于需要共享大量数据的场景。通过合理使用写时复制技术,可以在保证数据一致性的同时,显著提高系统的性能和资源利用率。
父子进程的关系:
子进程是父进程的副本。子进程获得父进程数据段,堆,栈,正文段共享。
在fork之后,一般情况那个会先运行,是不确定的。如果非要确定那个要先运行,需要IPC机制。
区别:
1)fork的返回值
2)pid不同
进程的终止:
进程的终止:8中情况
1)main 中return
2)exit(), c库函数,会执行io库的清理工作,关闭所有 的流,以及所有打开的文件。已经清理函数(atexit)。
3)_exit,_Exit 会关闭所有的已经打开的文件,不执行清理函数。
4) 主线程退出
5)主线程调用pthread_exit
异常终止
6)abort()
7)signal kill pid
8)最后一个线程被pthread_cancle