【论文阅读】Stop Overthinking:高效大模型推理技术综述
【论文阅读】Stop Overthinking:高效大模型推理技术综述
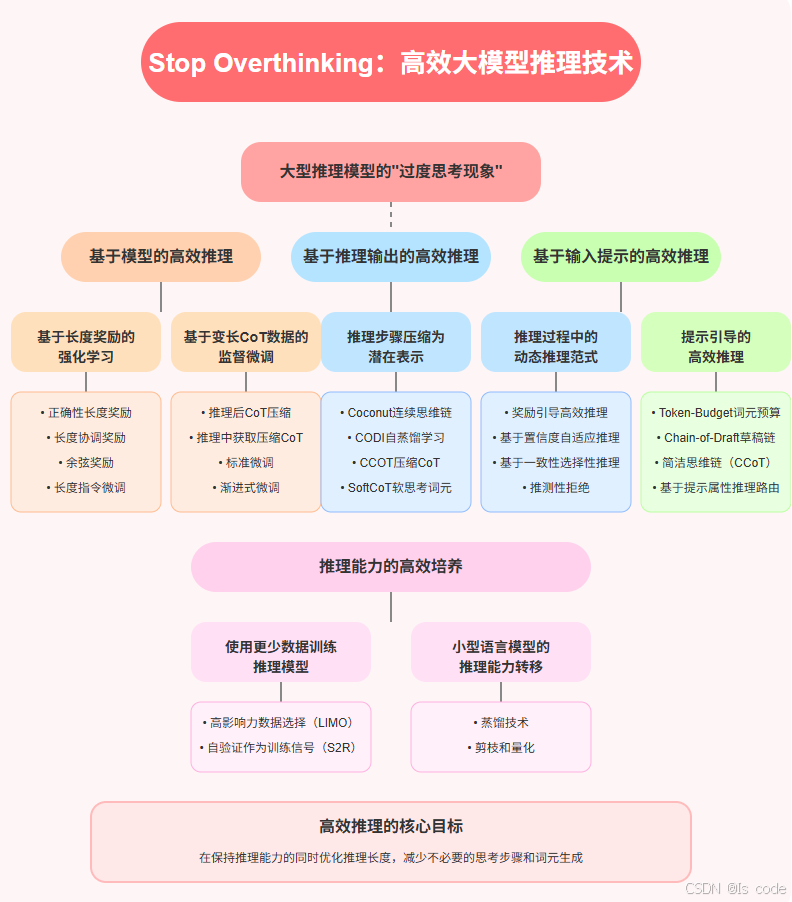
创新点结构图
1. 引言:告别冗长推理,迎接高效思考
大型语言模型(LLMs)近年来展现出了惊人的能力,特别是在复杂任务的推理方面。最新的大型推理模型(Large Reasoning Models,LRMs)如OpenAI的o1和DeepSeek-R1,通过监督微调(SFT)和强化学习(RL)技术增强了思维链(Chain-of-Thought,CoT)推理能力,在数学和编程等系统2推理领域取得了显著进步。
然而,这些模型存在一个明显的问题:虽然更长的CoT推理序列提高了准确性,但也带来了大量冗余输出,导致计算负担显著增加,这被称为"过度思考现象"(overthinking phenomenon)。举个例子,当我们问"2加3等于几?"这样简单的问题时,一些推理模型可能会生成数百甚至上千个词元(token)来解释这个过程,而这些词元中大部分是不必要的。
过度思考不仅浪费计算资源(以OpenAI o1为例,每百万生成词元的成本高达60美元),还会增加延迟,限制了推理模型在实时自动驾驶系统、交互式助手、机器人控制和在线搜索引擎等计算敏感的实际应用中的使用。
高效推理的核心目标是:在保持推理能力的同时优化推理长度,减少不必要的思考步骤和词元生成,从而降低计算成本并提高响应速度。本论文是第一个系统探讨当前高效推理进展的结构化综述,将现有研究分类为几个关键方向,并提供了对未来研究的深刻见解。
简而言之,高效推理就像训练我们的思维:不是每个问题都需要长篇大论的分析,有时简短精确的思考反而更有效率。想象一下,当你问"今天天气如何?“,你希望得到的是"晴天,23°C”,而不是一篇关于大气压力、风向和温度变化的长篇论文。高效推理模型就是要实现这种简洁有效的回答能力。
2. 研究背景:长链推理模型与过度思考现象
2.1 思维链推理的兴起
思维链(CoT)是大型语言模型实现推理能力的关键方法之一。在这种方法中,模型被引导在给出最终答案前输出推理思考链,这种方式已被证明可以显著提高准确性。
传统的CoT方法及其变体包括:
- 自一致性CoT(Self-consistency CoT):通过采样多样化的推理路径,选择最一致的答案
- 思维树(Tree-of-Thought):将思考过程结构化为树形,允许回溯
- 思维图(Graph-of-Thoughts):将思维结构化为图形,允许循环以细化单个思维
这些方法虽然有效,但都在提示工程层面工作,需要模型根据外部提示生成推理步骤。
2.2 大型推理模型的内部机制
最新的推理模型(如DeepSeek-R1和OpenAI o1)通过训练在内部学习了推理行为,不再依赖外部提示。这些模型通过迭代生成中间步骤,逐步完善解决方案,直到达到最终答案。这种方法与提示工程策略有本质区别,因为推理能力已经"内化"在模型中。
根据推测,OpenAI o1模型利用蒙特卡洛树搜索(MCTS)等树形搜索和处理奖励模型(PRM)来系统探索各种推理路径。而DeepSeek-R1则通过监督微调和强化学习,特别关注数学和编码任务上的规则基础奖励,使模型在提供最终答案前按预定义格式生成推理过程。
2.3 过度思考问题剖析
"过度思考现象"指的是LLMs生成过于详细或不必要复杂的推理步骤,损害了问题解决效率。当我们问"0.9和0.11哪个更大?"这样简单的问题时,QwQ-32B需要19秒,DeepSeek-R1需要42秒才能给出最终答案,这显然是低效的。
过度思考的后果包括:
- 高计算成本:生成和处理大量不必要的词元
- 响应延迟增加:用户需要等待较长时间
- 可能的错误引入:冗长的推理步骤可能会引入错误或降低逻辑清晰度
有趣的是,这个挑战在一定程度上源于推理模型的训练方式——它们被设计来生成扩展的推理步骤以追求正确答案。例如,DeepSeek-R1-Zero训练时间越长,其响应长度和基准性能都会增长,这被视为成功推理训练的指标。因此,在推理阶段追求效率实际上是与某些预训练目标"背道而驰"的。
3. 核心方法:基于模型的高效推理
从模型角度出发的方法主要关注如何微调LLMs,以提高它们内在的简洁高效推理能力。这包括两个主要策略:基于长度奖励的强化学习和基于变长CoT数据的监督微调。
3.1 基于长度奖励的强化学习
大多数推理模型使用基于RL的方法进行训练(如DeepSeek-R1、OpenAI o1等),主要关注准确性奖励和格式奖励。为了提高推理长度效率,一些研究提出将长度奖励整合到RL框架中,有效缩短推理过程。
长度奖励的核心理念是:为简短且正确的答案分配更高的分数,同时惩罚冗长或不正确的回答,从而优化推理路径的长度。主要方法包括:
- 基于正确性的长度奖励:正确答案根据长度给予不同奖励,更短的正确答案获得更高奖励
- 长度协调奖励(Length-Harmonizing Reward):基于参考模型输出和预测结果之间的CoT长度比率计算奖励
- 余弦奖励:基于Dirichlet函数的简洁奖励公式和"超出长度惩罚"评分
- 长度指令微调:在训练数据中添加指定长度约束的指令(如"用N个词元思考")
- 长度偏好数据集训练:使用构建的长度偏好数据集进行微调
这些RL方法可以缓解推理模型中的过度思考问题,实现对计算资源的高效利用,同时保持原有的推理能力。
3.2 基于变长CoT数据的监督微调
使用变长CoT数据微调LLMs是提高推理效率的另一种有效方法。这种方法通常涉及两个步骤:
- 通过各种方法构建变长CoT推理数据集
- 使用收集到的数据在推理模型上应用SFT,使LLMs学习简洁的推理链
3.2.1 构建变长CoT推理数据集
变长CoT推理数据集指的是包含长/短推理步骤的数据集,可以指导LLMs得出正确答案。现有工作通常通过向预训练推理模型提问来收集长CoT数据。在此基础上,关键挑战是:如何收集短CoT数据?主要有两种方法:
推理后CoT压缩:
- 通过启发式标准或LLMs在完整推理后减少冗余推理步骤
- 例如,丢弃推理过程,只使用问题和答案;或使用GPT-4作为压缩器减少推理过程长度;或根据语义重要性减少推理词元
推理过程中获取压缩CoT数据:
- 在推理和推断期间提示LLMs生成简短的推理步骤
- 例如,使用类似人类的步骤跳过方法;寻找最优词元预算以约束推理完成;或采样多条推理路径并选择最短的一条
3.2.2 微调方法
收集变长CoT数据后,现有工作通过几种方式微调LLMs以实现高效推理:
标准微调:
- 使用标准方法微调LLMs(如LoRA或完全微调)
- 在推理高效数据集上最小化困惑度损失函数或DPO损失函数
- LoRA使LLMs能够适应简短推理步骤,只需调整不到1%的参数
渐进式微调:
- 在微调过程中逐步减少推理步骤
- 例如,渐进式减少微调LLMs时数据的推理步骤;或通过混合无推理和长推理LLMs的参数来控制推理步骤的生成
这些方法不仅限于RL训练的推理模型,还可以通过注入高效推理能力来直接增强推理模型。
4. 创新技术:基于推理输出的高效推理
从推理步骤输出的角度,这些方法关注修改输出模式以增强LLMs简洁高效推理的能力。这包括两个主要方向:将推理步骤压缩为更少的潜在表示,以及推理过程中的动态推理范式。
4.1 将推理步骤压缩为更少的潜在表示
虽然标准CoT方法通过明确写出推理步骤来提高LLM性能,但近期研究表明,简单添加中间"思考"词元甚至无意义的填充(如"…")也可以提高性能。这表明好处通常在于更多的隐藏计算,而非纯粹的文本分解。
基于这一洞见,一些新方法专注于压缩或替换显式CoT,使用更紧凑的潜在表示。这些方法大致分为两类:
训练LLMs使用潜在表示进行推理:
- Coconut(连续思维链):将LLM的最终层隐藏状态作为"连续思考"代替传统离散词元
- CODI:通过自蒸馏学习连续潜在CoT
- CCOT:将长CoT推理压缩为短内容丰富的连续思考词元
- Heima:为多模态大语言模型引入潜在推理
- Token Assorted:采用混合方法,在训练中用VQ-VAE学习的离散潜在词元替换部分CoT
保持LLMs冻结的同时训练辅助模块:
- SoftCoT:在冻结的预训练LLM基础上,轻量级辅助模型生成实例特定的软思考词元
这些方法暗示了向潜在推理的更广泛转变,在这种推理中,关键思考以压缩的非文本形式进行。随着LLMs变得更大、任务变得更复杂,这些灵活紧凑的潜在CoT范式有助于平衡彻底推理与计算效率。
4.2 推理过程中的动态推理范式
现有工作专注于修改推理过程中的推理范式,以实现更高效的推理。关键在于选择合适的标准来指导推理策略。当前的无训练方法使用各种标准探索动态推理,如奖励引导、基于置信度的自适应推理和基于一致性的选择性推理。
奖励引导的高效推理:
- 推测性拒绝:优化Best-of-N(BoN)解码,动态减少计算开销
- 奖励引导的推测解码(RSD):利用奖励模型评估轻量级草稿模型的中间输出
基于置信度/确定性的自适应推理:
- 动态并行树搜索:通过自适应批处理动态并行化节点扩展
- Dynasor:基于Certaindex(确定性指标)动态分配计算资源
- FastMCTS:优化多步推理数据合成的置信度方法
- 长度过滤投票:基于预测不确定性选择最可靠的CoT长度组
基于一致性的选择性推理:
- 自截断Best-of-N:通过内部嵌入一致性提前评估样本质量
这些方法通过在推理过程中动态调整计算资源分配,实现更高效的推理过程。此外,还有一种基于总结的动态推理方法,通过训练LLMs总结中间思考步骤来优化推理效率。
5. 实用策略:基于输入提示的高效推理
从输入提示和问题的角度,这些方法专注于强制长度约束或基于输入提示的特性路由LLMs,以实现简洁高效的推理。
5.1 提示引导的高效推理
提示引导的高效推理明确指示LLMs生成更少的推理步骤,这是一种直接而高效的方法。不同方法提出不同提示来确保模型输出简洁推理:
通过各种提示强制简洁推理:
- Token-Budget:设置词元预算以减少不必要的推理词元
- Chain-of-Draft:鼓励分步推理但限制冗长,如"每个思考步骤最多用5个词"
- 简洁思维链(CCoT):指示模型"简洁"地执行分步推理
- Token Complexity:通过带有明确压缩指令的提示系统研究推理长度和模型准确性
这些提示方法通过直接指导模型生成更简洁的推理,在不牺牲准确性的情况下减少词元使用。
5.2 基于提示属性的推理路由
用户提供的提示可能涉及从简单到复杂的各种任务。高效推理的路由策略可以根据查询的复杂性和不确定性动态确定语言模型处理方式。理想情况下,推理模型可以自动将简单查询分配给更快但推理能力较弱的LLMs,而将复杂查询分配给更慢但更强大的推理LLMs。
主要策略包括:
- 未知标准:如Claude 3.7 Sonnet,能够根据任务复杂性分配思考时间
- 训练分类器:如RouteLLM,训练查询路由器根据复杂性将查询分派给合适的LLMs
- 基于不确定性:如Self-Ref,使LLMs通过提取内在不确定性分数自主决定何时路由
这些路由策略通过避免在简单问题上过度使用计算资源,同时确保复杂问题得到足够处理,提高了整体推理效率。
6. 推理能力的高效培养:有效训练数据与模型压缩
6.1 使用更少数据训练推理模型
提高推理模型效率不仅需要优化模型架构,还需要优化用于训练的数据。最近的工作表明,精心选择、构建和利用训练数据可以显著减少数据需求,同时保持或甚至提高推理性能。
主要方法包括:
- 最小但高影响力的数据选择:如LIMO,通过精心策划的示例引发复杂推理能力
- 自验证作为数据高效训练信号:如S2R,通过RL向LLMs注入自验证和自校正能力
这些方法挑战了复杂推理任务需要大量训练数据的传统观念,证明了战略性数据选择的强大价值。
6.2 小型语言模型的推理能力——通过蒸馏和模型压缩
LLMs在复杂任务上展示了卓越的推理能力,但其巨大的计算和内存需求限制了在资源受限环境中的部署。为了解决这个问题,研究了两种主要方法:蒸馏和模型压缩。
蒸馏:
- 将LLMs的推理能力转移到SLMs同时保持效率
- 应对"小模型学习差距"挑战,SLMs难以模仿大模型的推理深度
- 采用混合蒸馏、反事实蒸馏、反馈驱动蒸馏等多种技术
剪枝和量化:
- 通过量化和剪枝将LLM压缩为SLM
- 量化(降低模型精度)能很好地保留推理性能
- 剪枝(移除特定权重或神经元)导致推理质量严重下降
这些方法表明,高效转移推理能力不仅需要减小模型大小,还需要精心结构化知识转移过程,以保留逻辑深度和泛化能力。
7. 评估与基准测试
随着LLMs在复杂推理任务上能力的不断提高,对严格、标准化的评估指标和框架的需求变得越来越重要。
Sys2Bench:
- 一个全面的套件,用于评估LLMs在五个推理类别中的能力
- 包括11个多样化数据集,涵盖算术、逻辑、常识、算法和规划任务
- 研究表明,单靠扩展推理时间计算有局限性,需要多样化方法
评估过度思考:
- 系统分析LLMs中的"过度思考"现象
- 确定了分析瘫痪、肆意行动和过早脱离等模式
- 提出"过度思考分数"并证明减少过度思考可以提高性能
计算最优测试时间缩放(TTS):
- 研究TTS策略对LLM性能的影响
- 发现计算最优TTS策略高度依赖于政策模型、过程奖励模型和问题难度
- 证明适当的TTS策略可以使较小模型在复杂推理任务上超越显著较大的模型
8. 应用与讨论
8.1 应用领域
自动驾驶:
- 高效推理LLMs帮助理解大量传感器数据
- 提升决策能力,规划困难驾驶情况,快速反应意外事件
- 解释决策过程,增强乘客和监管机构的信心
具身AI:
- 使机器人和智能设备更智能地理解和应对周围环境
- 快速决定最佳移动方式,处理意外变化,安全与人交互
- 提高具身AI系统在日常环境中的可靠性、安全性和实用性
医疗保健:
- 帮助医生和研究人员更容易处理大量医疗数据
- 分析患者记录、测试结果和医学研究,识别重要趋势和模式
- 使医疗流程更加顺畅可靠,改善患者护理和结果
8.2 讨论与展望
提升推理能力:
- Meta-Reasoner:利用上下文多臂赌博机评估推理进展,选择最佳策略
- ITT:将每个Transformer层视为内部思考过程的一步,通过自适应路由动态分配额外处理
高效推理安全性:
- 安全性和效率往往相互矛盾,优化一方会导致另一方性能下降
- 在长推理模型中平衡安全性和效率仍是一个具有挑战性的研究领域
RL与SFT孰优孰劣:
- RL允许模型通过试错学习,奖励满意决策,有助于创新解决问题
- SFT使用精心选择的高效CoT示例训练模型,行为更一致,控制更容易
- 实践中,结合两种方法可能是有前景的方向
9. 结论与思考
本论文提供了LLMs高效推理的第一个结构化综述,将现有方法分为三个领域:基于模型、基于推理输出和基于输入提示的方法。此外,还讨论了高效数据利用、较小模型的推理能力、评估技术和基准测试,并提供了持续更新的公共知识库以支持未来研究。
高效推理方法在各个领域提供了显著的实际好处:减少医疗诊断的计算成本,增强自动驾驶的实时决策和安全性,提高具身AI系统的可靠性和实用性,以及在金融算法交易和风险评估中实现更快、更有利可图的响应。这些进步凸显了高效推理在LLMs中的广泛经济和社会价值。
回想起来,效率并不意味着牺牲质量。相反,高效推理就像精炼思考的艺术——做到恰到好处,既不过度也不不足。随着我们继续研究如何在保持准确性的同时提高推理效率,LLMs将能够更好地服务于对资源敏感的实际应用,从而扩大其在日常环境中的实用性和可访问性。
参考资料
- Yang Sui等. (2025). Stop Overthinking: A Survey on Efficient Reasoning for Large Language Models. arXiv:2503.16419.
- Daya Guo等. (2025). DeepSeek-R1: Incentivizing reasoning capability in LLMs via reinforcement learning. arXiv:2501.12948.
- OpenAI. (2025). Learning to reason with LLMs. https://openai.com/index/learning-to-reason-with-llms/
- Jason Wei等. (2022). Chain-of-thought prompting elicits reasoning in large language models. NeurIPS 35:24824-24837.
- Shibo Hao等. (2024). Training large language models to reason in a continuous latent space. arXiv:2412.06769.
- Hanshi Sun等. (2024). Fast best-of-n decoding via speculative rejection. arXiv:2410.20290.
- Tingxu Han等. (2024). Token-budget-aware LLM reasoning. arXiv:2412.18547.