5月23日day34打卡
GPU训练及类的call方法
知识点回归:
- CPU性能的查看:看架构代际、核心数、线程数
- GPU性能的查看:看显存、看级别、看架构代际
- GPU训练的方法:数据和模型移动到GPU device上
- 类的call方法:为什么定义前向传播时可以直接写作self.fc1(x)
作业
复习今天的内容,在巩固下代码。思考下为什么会出现这个问题。
CPU性能的查看:看架构代际、核心数、线程数:
# pip install wmi -i https://pypi.tuna.tsinghua.edu.cn/simple
# 这是Windows专用的库,Linux和MacOS不支持,其他系统自行询问大模型
# 我想查看一下CPU的型号和核心数
import wmic = wmi.WMI()
processors = c.Win32_Processor()for processor in processors:print(f"CPU 型号: {processor.Name}")print(f"核心数: {processor.NumberOfCores}")print(f"线程数: {processor.NumberOfLogicalProcessors}")
1. 型号解析:Intel Core i7-10875H
- i7:Intel酷睿家族的高端产品线,定位高性能计算(介于i5和i9之间)。
- 10:代表第十代酷睿处理器(Comet Lake架构,2020年发布)。
- 875:具体型号编号(同代中数字越大性能越强,875属于i7系列的中高端型号)。
- H:表示"高性能移动版"(High Performance Mobile),通常用于游戏本/工作站笔记本,功耗较高(典型45W),性能释放强于U/P系列低功耗移动处理器。
2. 核心与线程:8核16线程
- 8核(物理核心):CPU的实际计算单元,每个核心可独立执行指令。
- 16线程(逻辑线程):通过Intel超线程技术(Hyper-Threading)实现,每个物理核心模拟2个逻辑线程,提升多任务并行处理能力(例如同时运行数据预处理、模型训练监控等任务)。
3. 基础频率:2.30GHz
这是CPU的默认运行频率(未满载时的基础频率),实际运行中会根据负载动态调整(最大睿频可达5.1GHz左右,具体取决于散热和功耗限制)。
4. 对机器学习场景的适用性
- 优势:8核16线程的配置非常适合机器学习中的多线程任务(如数据预处理、多模型并行测试、日志记录等CPU密集型操作)。
- 注意:机器学习的核心计算(尤其是深度神经网络训练)通常依赖GPU加速(如你代码中使用的CUDA),但CPU会影响数据加载/预处理的效率。此CPU的性能足以支撑大多数中小型机器学习项目的CPU侧需求。
总结:这是一款面向高性能移动场景的第十代酷睿i7处理器,8核16线程的配置在多任务处理和机器学习辅助计算(非GPU核心计算)中表现优秀,能较好满足你的研究项目需求。
GPU性能的查看:看显存、看级别、看架构代际:
import torch# 检查CUDA是否可用
if torch.cuda.is_available():print("CUDA可用!")# 获取可用的CUDA设备数量device_count = torch.cuda.device_count()print(f"可用的CUDA设备数量: {device_count}")# 获取当前使用的CUDA设备索引current_device = torch.cuda.current_device()print(f"当前使用的CUDA设备索引: {current_device}")# 获取当前CUDA设备的名称device_name = torch.cuda.get_device_name(current_device)print(f"当前CUDA设备的名称: {device_name}")# 获取CUDA版本cuda_version = torch.version.cudaprint(f"CUDA版本: {cuda_version}")# 查看cuDNN版本(如果可用)print("cuDNN版本:", torch.backends.cudnn.version())else:print("CUDA不可用。")1. CUDA可用!
CUDA是NVIDIA专门为GPU设计的“加速工具箱”,相当于给GPU装了套“高效工作套餐”。这句话说明你的电脑/环境已经正确安装了CUDA,GPU可以用来加速计算(比如深度学习训练)。
2. 可用的CUDA设备数量: 1
“CUDA设备”就是支持CUDA的GPU显卡。这句话说明你有1张能用于加速的NVIDIA显卡(比如你后面提到的RTX 2060)。如果有2张显卡,这里会显示2。
3. 当前使用的CUDA设备索引: 0
如果有多个GPU(比如2张显卡),计算机会给它们编号(0号、1号…)。这里“0”表示你当前的程序正在用第1张显卡(编号从0开始)。如果只有1张显卡,那肯定用0号。
4. 当前CUDA设备的名称: NVIDIA GeForce RTX 2060
这是你显卡的“全名”,相当于GPU的“型号”。RTX 2060是NVIDIA的中高端游戏/创作显卡,支持CUDA加速,能高效处理深度学习、视频渲染等任务。
5. CUDA版本: 12.1
CUDA工具包的“版本号”,类似手机系统的版本(比如iOS 17)。不同版本支持不同的GPU功能:
- 12.1是较新的版本,能更好地兼容新模型(比如大语言模型、复杂神经网络);
- 如果版本太旧,可能无法运行某些需要新特性的深度学习代码。
6. cuDNN版本: 90100
cuDNN(读“Q-DNN”)是CUDA的“深度学习专用加速包”,相当于给GPU的深度学习任务装了个“超级加速器”。版本号90100对应的是v9.1.0(9×10000 + 1×100 + 0 = 90100)。
- 它能大幅加速神经网络的核心操作(比如卷积、全连接层);
- 版本越高,对新模型(如Transformer、扩散模型)的优化越好。
总结
这些信息说明你的GPU加速环境完全正常!你的RTX 2060显卡+CUDA 12.1+cuDNN 9.1.0的组合,能高效运行深度学习任务(比如你之前用PyTorch训练的MLP模型),比仅用CPU快几倍到几十倍
GPU训练的方法:数据和模型移动到GPU device上 :
# 设置GPU设备
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")# 定义设备:优先使用 GPU(如果可用),否则用 CPU
print(f"使用设备: {device}")# 加载鸢尾花数据集
iris = load_iris()
X = iris.data # 特征数据
y = iris.target # 标签数据# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)# 归一化数据
from sklearn.preprocessing import MinMaxScaler
scaler = MinMaxScaler()
X_train = scaler.fit_transform(X_train)
X_test = scaler.transform(X_test)# 将数据转换为PyTorch张量并移至GPU
# 分类问题交叉熵损失要求标签为long类型
# 张量具有to(device)方法,可以将张量移动到指定的设备上
X_train = torch.FloatTensor(X_train).to(device)# 特征数据移到 GPU
y_train = torch.LongTensor(y_train).to(device)# 标签数据移到 GPU
X_test = torch.FloatTensor(X_test).to(device)
y_test = torch.LongTensor(y_test).to(device)class MLP(nn.Module):def __init__(self):super(MLP, self).__init__()# 调用父类nn.Module的构造函数(PyTorch模型初始化的标准写法)self.fc1 = nn.Linear(4, 10)# 定义第一个全连接层(输入层→隐藏层):输入4维特征(鸢尾花的4个特征),输出10个隐藏单元self.relu = nn.ReLU()# 定义ReLU激活函数(引入非线性特征,增强模型表达能力)self.fc2 = nn.Linear(10, 3)# 定义第二个全连接层(隐藏层→输出层):输入10个隐藏单元,输出3个神经元(对应3个分类)def forward(self, x):# 前向传播函数:定义数据在模型中的计算流程(x是输入的特征张量)out = self.fc1(x)# 将输入数据通过第一个全连接层(fc1),得到隐藏层的线性输出out = self.relu(out)# 对隐藏层的线性输出应用ReLU激活函数,引入非线性变换(增强模型表达能力)out = self.fc2(out)# 将激活后的隐藏层输出通过第二个全连接层(fc2),得到最终的3维输出(对应3个类别的原始预测分数)return out# 返回最终的预测结果(未经过softmax,交叉熵损失会自动处理概率转换)# 实例化模型并移至GPU
# MLP继承nn.Module类,所以也具有to(device)方法
model = MLP().to(device) # 实例化模型并同时移到 GPU
类的call方法:为什么定义前向传播时可以直接写作self.fc1(x)
我们用「快递柜取件」的例子,类比解释为什么可以直接写 self.fc1(x):
假设场景:你有一个「智能快递柜」(相当于 nn.Linear 层)
- 快递柜的功能是「根据取件码(输入
x),输出对应的快递(输出结果)」。 - 快递柜有两个操作方式:
- 直接按取件按钮(相当于
self.fc1(x)); - 打开柜门手动翻找(相当于
self.fc1.forward(x))。
- 直接按取件按钮(相当于
为什么推荐按按钮(self.fc1(x))?
因为快递柜被设计成:
当你按按钮(触发 __call__ 方法)时,它会自动:
- 执行核心功能:根据取件码找到快递(调用
forward方法); - 记录取件过程:比如几点取的、谁取的(PyTorch 会记录计算图,用于后续反向传播);
- 处理异常:比如取件码错误时提示「不存在」(PyTorch 会处理张量维度不匹配等问题)。
对应到你的代码里:
你代码中的 self.fc1 是一个全连接层(nn.Linear 的实例),它就像这个智能快递柜:
- 当你写
self.fc1(x)时(按按钮),PyTorch 会自动触发它的__call__方法; __call__方法内部会调用self.fc1.forward(x)(执行核心计算),同时偷偷帮你记录计算过程(计算图);- 你完全不需要自己写
self.fc1.forward(x)(手动翻找快递),既麻烦又容易漏记录关键信息。
总结:
self.fc1(x) 是 PyTorch 设计的「懒人按钮」—— 按一下就能触发完整的计算流程(包括核心功能和后台记录),比手动调用 forward 更简单、更安全。
问题思考:为什么一些小型模型或者数据,CPU计算时间比GPU短?
主要是因为 GPU的「启动成本」比CPU高,但「并行能力」比CPU强。就像你搬东西:
- CPU:像一个「灵活的小工」,虽然一次只能搬少量东西(核心少),但说干就干(启动快),搬少量东西时效率高。
- GPU:像一个「大团队的搬运队」,虽然能同时搬很多东西(核心多,并行强),但每次开工前需要花时间集合队伍、分配任务(启动和数据传输的开销)。如果东西很少(小模型/小数据),集合队伍的时间可能比实际搬东西的时间还长,反而更慢。
具体来说:
- 小任务不需要并行:小模型/小数据的计算量少,CPU几个核心就能快速搞定,不需要GPU的「人海战术」。
- GPU的数据搬运耗时:用GPU时,数据需要从内存传到显存(显卡内存),计算完再传回来。小数据时,这个搬运时间可能比实际计算时间还长。
- GPU的启动开销:GPU的并行计算需要额外的调度(比如给每个核心分配任务),小任务时这些调度的时间会「拖后腿」。
举个例子:
你要写100字的小作文(小任务):
- 用CPU(自己写):拿起笔立刻写,5分钟写完。
- 用GPU(叫100个同学一起写):需要花10分钟把纸和笔分给100个同学(数据传输+任务分配),然后每人写1个字,实际写的时间1分钟,但总时间11分钟,反而更慢。
所以,小任务用CPU更快,大任务(比如几万张图片训练)用GPU的并行能力才能发挥优势。
用举例子的方式解释代码:
假设场景:教小朋友认3种水果(苹果、香蕉、橘子)
- 数据集:准备了100张水果图片(80张训练,20张测试),每张图有4个特征(大小、颜色、重量、形状)。
- 模型(MLP):相当于「小朋友的大脑」,需要通过学习训练集的图片,学会根据4个特征判断是哪种水果。
对应代码的每一步解释:
1. 数据准备(代码前半部分)
# 加载数据集(准备100张水果图片)
iris = load_iris()
X = iris.data # 特征数据(每张图的4个特征:大小、颜色、重量、形状)
y = iris.target # 标签数据(每张图的真实水果类型:0=苹果,1=香蕉,2=橘子)# 划分训练集和测试集(80张给小朋友学,20张考试用)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)# 归一化数据(把「大小」「重量」等特征统一到0-1范围,避免「大小」数值太大欺负「颜色」)
scaler = MinMaxScaler()
X_train = scaler.fit_transform(X_train)
X_test = scaler.transform(X_test)# 转成PyTorch张量并移到GPU(把图片和答案写成「小朋友能看懂的语言」,并搬去「高速学习区」GPU)
X_train = torch.FloatTensor(X_train).to(device)
y_train = torch.LongTensor(y_train).to(device)2. 定义模型(MLP类)
class MLP(nn.Module):def __init__(self):super(MLP, self).__init__()self.fc1 = nn.Linear(4, 10) # 第一层:输入4个特征,输出10个「临时结论」(比如「可能是圆的」「可能是黄色的」)self.relu = nn.ReLU() # 激活函数:过滤掉没用的「临时结论」(比如「可能是方的」这种不可能的判断)self.fc2 = nn.Linear(10, 3) # 第二层:把10个「临时结论」汇总,输出3个分数(对应3种水果的「像不像」)类比:小朋友的大脑分两步处理信息:
- 第一步(fc1):根据4个特征,生成10个中间判断(比如「大小像苹果」「颜色像香蕉」...);
- 过滤(relu):去掉明显错误的判断(比如「颜色像苹果但实际是绿色」);
- 第二步(fc2):把剩下的判断汇总,得出「像苹果」「像香蕉」「像橘子」的3个分数。
3. 训练循环(核心代码)
# 实例化模型(找一个「小朋友」开始学习)
model = MLP().to(device)# 损失函数(判断小朋友猜得准不准的「打分器」:猜得越错,分越高)
criterion = nn.CrossEntropyLoss()# 优化器(教小朋友调整自己的「学习方法」的「老师」,这里用SGD)
optimizer = optim.SGD(model.parameters(), lr=0.01)# 开始上课(训练20000轮,相当于上20000节课)
num_epochs = 20000
start_time = time.time()for epoch in range(num_epochs):# 前向传播(小朋友根据当前学习成果,猜训练集的80张图是什么水果)outputs = model(X_train) # 输出3个分数(比如 [0.8, 0.2, 0.1] 表示「最像苹果」)# 计算损失(打分器给小朋友的猜测打分:如果真实是苹果,但小朋友猜成香蕉,分就很高)loss = criterion(outputs, y_train)# 反向传播(分析哪里猜错了:比如「颜色判断」错了,「大小判断」对了)optimizer.zero_grad() # 清空之前的错误记录(避免上节课的错误影响这节课)loss.backward() # 计算每个「临时结论」(参数)对错误的「贡献度」(梯度)# 优化器更新(根据错误分析,调整小朋友的「学习方法」:比如「颜色判断」的权重调大)optimizer.step() # 每100节课汇报一次:「现在猜训练集的错误分是XX」if (epoch + 1) % 100 == 0:print(f'Epoch [{epoch+1}/{num_epochs}], Loss: {loss.item():.4f}')类比:每一轮训练(epoch)相当于一节课:
- 小朋友先猜训练集的80张图(前向传播);
- 老师用打分器(损失函数)告诉小朋友猜得有多错(计算损失);
- 老师分析错误原因(反向传播算梯度),并指导小朋友调整自己的判断逻辑(优化器更新参数);
- 重复20000次,直到小朋友猜得足够准。
4. 可视化损失(最后几行代码)
# 把每100节课的错误分画成曲线,看小朋友是不是越学越准
plt.plot(range(len(losses)), losses)
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.title('Training Loss over Epochs')
plt.show()类比:老师把每节课的错误分记录下来,画成折线图。如果曲线越来越低,说明小朋友越学越准;如果曲线波动大或不降,说明学习方法可能有问题(比如学习速度lr太快/太慢)。
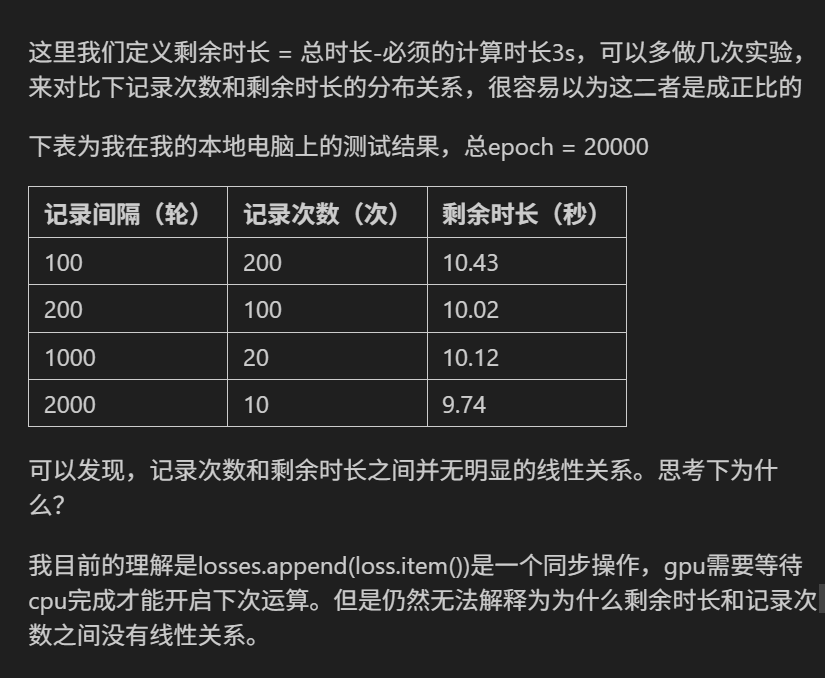
记录次数和剩余时长之间并无明显的线性关系可能的原因:
loss.item() 是同步操作(需要GPU→CPU数据传输并等待完成)确实可能影响单次记录的耗时,但「剩余时长和记录次数无线性关系」的核心原因其实更简单:每次迭代(或记录点)的实际耗时不稳定。
用「煮面」的例子类比解释:
假设你要煮 10 碗面(总时长固定为 100 分钟),每煮完 1 碗记录一次「剩余时长」(总时长 - 已用时间)。但实际煮每碗面的时间可能波动:
- 第 1 碗:火大,用了 5 分钟 → 剩余时长 95 分钟;
- 第 2 碗:水没开,用了 15 分钟 → 剩余时长 80 分钟;
- 第 3 碗:火稳了,用了 8 分钟 → 剩余时长 72 分钟;
……
这时候「记录次数」(1、2、3…)和「剩余时长」(95、80、72…)的关系是乱的,因为每碗面的实际耗时不稳定(有时快、有时慢),导致剩余时长的减少幅度忽大忽小,无法用「每次固定减少 X 分钟」的直线表示。
对应到你的场景:
训练模型时,虽然总轮数(num_epochs)固定,但每轮(epoch)的实际耗时可能波动:
- GPU 可能被其他程序抢占(比如后台下载文件),导致某轮计算变慢;
- 内存/显存的分配可能不稳定(比如某轮需要加载更多数据到显存),增加耗时;
loss.item()虽然是同步操作,但每次传输数据的耗时可能因GPU负载不同而变化(比如某轮GPU更忙,传输更慢)。
这些波动会导致「剩余时长」(总时间 - 已用时间)的减少幅度不稳定,因此和「记录次数」(比如每100轮记录一次)之间没有线性关系。
@浙大疏锦行