ollama 部署模型休眠、释放问题
存在问题
ollama部署的LLM模型,一段时间不发送请求,模型资源就会被释放,下次聊天的时候就得重新调起模型、第一句话响应很慢。
这是因为ollama部署的模型默认是5分钟没有收到请求就会被释放,因此需要根据具体情况调整这个模型存活的时长。
解决思路
第一种情况、在POST参数中设置
在 POST 模型 API 时,有一个可选参数 keep_alive,用于控制模型在请求后加载到内存中的时间(默认:5m,即五分钟)。
如果需要无限期保留模型、模型一直加载在内存里,这个参数可以设置为负数,如 -1。
curl http://localhost:11434/api/generate -d '{"model": "llama3.2","keep_alive": -1
}'
如果需要卸载模型,可以设置该参数为0:
curl http://localhost:11434/api/generate -d '{"model": "llama3.2","keep_alive": 0
}'
第二种情况、在Dify具体应用的模型参数中设置
在Dify界面中,设置模型配置参数中的【模型存活时间】,这个是用于设置模型在生成响应后在内存中保留的时间。
这里的时间需要是一个带有单位的持续时间字符串(例如,'10m’表示10分钟,24h’表示24小时)。
负数表示无限期地保留模型,'0’表示在生成响应后立即卸载模型。
有效的时间单位有’s(秒)、‘m’(分钟)、h’(小时)。(默认值:5m)
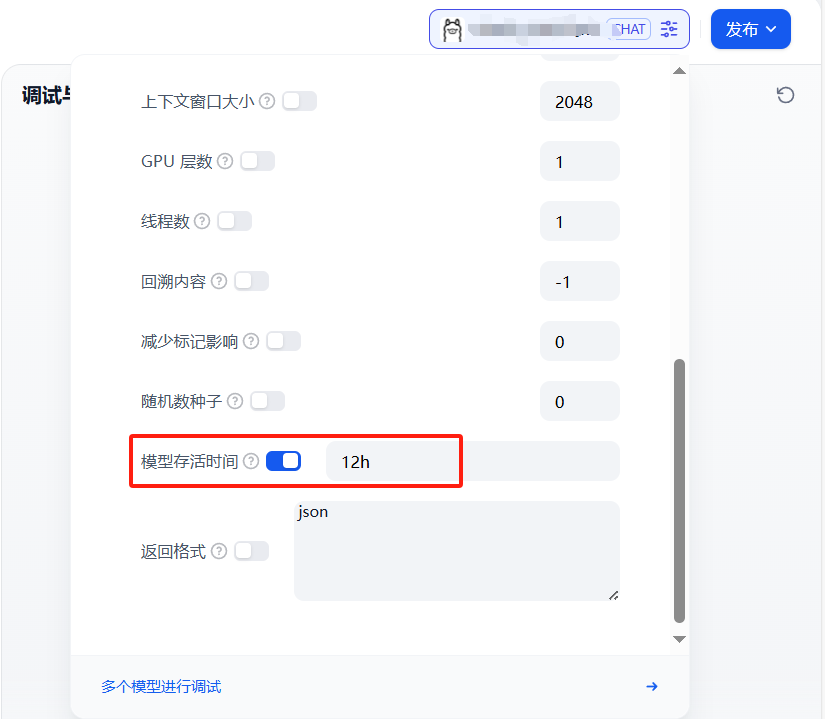
例如,我们把这个参数设置为12h,这样在12个小时之内,模型就会加载在内存中,不会被中途释放,隔一段时间进行对话、也不会有重新加载模型的卡顿问题。
参考文档
https://github.com/ollama/ollama/blob/main/docs/api.md#generate-a-chat-completion