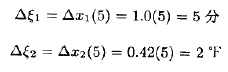响应面分析之最速上升法
本文是实验设计与分析(第6版,Montgomery著傅珏生译)第11章响应面第11.2节的python解决方案。本文尽量避免重复书中的理论,着于提供python解决方案,并与原书的运算结果进行对比。您可以从Detail 下载实验设计与分析(第6版,Montgomery著傅珏生译)电子版。本文假定您已具备python基础,如果您还没有python的基础,可以从Detail 下载相关资料进行学习。
响应曲面法(Response Surface Methodology,RSM)是数学方法和统计方法结合的产物。用于对感兴赶的响应受多个变量影响的问题进行建模和分析,以优化这个响应。例如,设一位化学工程师想求出温度(x1)和压强(x2)的水平以使得过程的产率(y)达到最大值。产率是温度水平和压强水平的函数,比方说
y=f(x1,x2)十ε
其中ε表示响应y的观测误差或噪音。如果记期望响应为E(y)=f(x1,x2)=η,则由
η=f(x1,x2)
表示的曲面称为响应曲面。
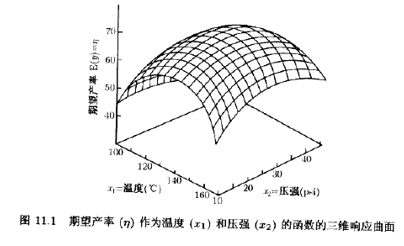
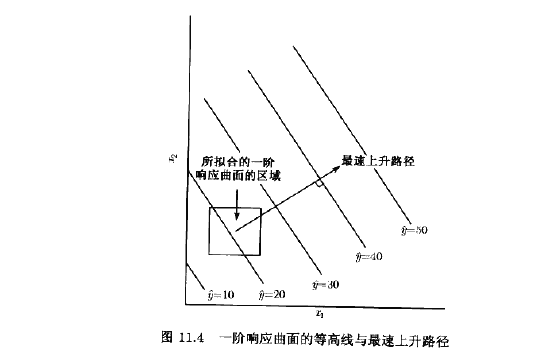
通常像图11.1那样用图形来表示响应曲面,其中η是对x1水平和x2水平画的。前面已经看到过这样的响应曲面图形,特别是在析因设计的各章中。为了有助于目测响应曲面的形状,经常像图11.2那样画出向应曲面的等高线。在等高线图形中,常数值的响应线画在x1,x2平面上。每一条等高线对应于响应曲面的一个特定高度。在前面章节中已看到了等高线图的作用。
在大多数RSM问题中,响应和自变量之间的关系形式是未知的。这样,RSM的第一个步骤就是寻求y和自变量集合之间真实函数关系的一个合适的逼近式。通常,可用在自变量某一区域内的一个低阶多项式来逼近。若响应适合用自变量的线性函数建模,则近似函数是一阶模型
y=β0+β1x1十β1x2十β2x2十···+βxxk+ε(11.1)
如果系统有弯曲,则必须用更高阶的多项式,例如二阶模型
![]()
几乎所有的RSM问题都用这两个模型中的一个或两个。当然,一个多项式模型不可能在自变量的整个空间上都是真实函数关系的合理近似式,但在一个相对小的区域内通常做得很好。
第10章讨论的最小二乘方法可用来估计近似多项式的参数。然后用拟合曲面进行响应曲面分析。如果拟合曲面是真实响应函数的一个合适的近似式,则拟合曲面的分析就近似地等价于实际系统的分析。如果能恰当地利用实验设计来收集数据,就能够最有效地估计棋型参数。拟合响应曲面的设计称为响应曲面设计,11.4节将讨论这些设计。
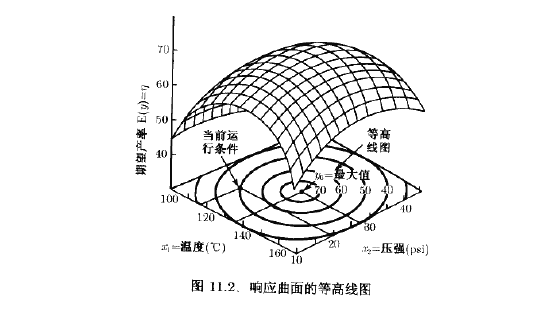
RSM是一种序贯方法。通常,当我们在响应曲面上某个远离最优点的点时,例如,像图11.3中当前运行条件那样的点,在此点处系统只有微小的弯曲,从而用一阶模型是恰当的,现在,我们的目的是要引导实验者沿着改善系统的路径快速而有效地向最优点的附近区域前进。一旦找到最优点的区城,就可以用更精细的模型(例如二阶模型)进行分析以便确定最优点的位置。由
图11.3可见,响应曲面的分析法可以想象为“爬山”一样,山顶代表响应的最大值点。如果真实的最优点是响应的最小值点,则可设想为“落进山谷”。
RSM的最终目的是确定系统的最优运行条件或确定因子空间中满足运行规范的区域。有关RSM更全面的介绍见Myers and Montgomery(2002),Khuri and Cornell(1996),及Box and Draper(1987)。Myes等人的综述论文也是有用的参考资料。
系统最优运行条件的初步估计常常远离实际的最优点。在这种情况下,实验者的目的是要快速地进入到最优点的附近区域。我们希望利用既简单又经济有效的实验方法。当远离最优点时,通常假定在x的一个小区域范围内一阶模型是真实曲面的合适近似。
最速上升法是沿着响应有最大增量的方向逐步移动的方法。当然,如果求的是最小值,则称为最速下降法,所拟合的一阶模型是
![]()
与一阶响应曲面相应的![]() 的等高线,是一组平行直线,如图11.4所示。最速上升的方向就是
的等高线,是一组平行直线,如图11.4所示。最速上升的方向就是![]() 增加得最快的方向。这一方向平行于拟合响应曲面等高线的法线方向。通常取通过感兴趣区域的中心并且垂直于拟合曲面等高线的直线为最速上升路径。这样一来,沿着路径的步长就和回归系数
增加得最快的方向。这一方向平行于拟合响应曲面等高线的法线方向。通常取通过感兴趣区域的中心并且垂直于拟合曲面等高线的直线为最速上升路径。这样一来,沿着路径的步长就和回归系数![]() 成正比。实际的步长大小是由实验者根据工序知识或其他的实际考虑来确定的。
成正比。实际的步长大小是由实验者根据工序知识或其他的实际考虑来确定的。
实验是沿着最速上升的路径进行的,直到观测到的响应不再增加为止,然后,拟合一个新的一阶模型,确定一条新的最速上升路径,继续按上述方法进行。最后,实验者到达最优点的附近区域。这通常由一阶模型的拟合不足来指出。这时,进行添加实验会求得最优点的更为精确的估计。
例11.1一位化学工程师要确定使过程产率最高的操作条件。影响产率的两个可控变量是反应时间和反应温度。工程师当前使用的操作条件是反应时间为35分钟,温度为155℉,产率约为40%。因为此区域不大可能包含最优值,于是她拟合一阶模型并应用最速上升法。
这位工程师认为,所拟合的一阶模型的探测区域应该是反应时间为(30,40)分钟,反应温度为(150,160)℉,为简化计算,将自变量规范在(-1,1)区间内,于是,如果记ξ1为自然变量时间,ξ2为自然变量温度,则规范变量是
![]()
实验设计列在表11.1中,用来收集这些数据的设计是增加5个中心点的22析因设计。在中心点处的重复试验用于估计实验误差,并可以用于检测一阶模型的合适性。而且,过程的当前运行条件也就在设计的中心点处

使用最小二乘法,以一阶模型来拟合这些数据。用二水平设计的方法,可求得以规范变量表示的下列模型:
![]()
在沿着最速上升路径探测之前,应研究一阶模型的适合性。有中心点的22设计使实验者能够
(1)求出误差的一个估计量
(2)检测模型中的交互作用(交叉乘积项)
(3)检测二次效应(弯曲性)
Viscosity =[39.3,40.0,40.9,41.5,40.3,40.5,40.7,40.2,40.6]
Temperature =[30,30,40,40,35,35,35,35,35]
Catalyst =[150,160,150,160,155,155,155,155,155]
data= {"Viscosity":Viscosity,"Temperature":Temperature,"Catalyst":Catalyst}
df =pd.DataFrame(data)
#model = smf.ols('df.Viscosity ~ C(df.Temperature) + C(df.Rate)', data=df).fit()
model = smf.ols('df.Viscosity ~df.Temperature +df.Catalyst', data=df).fit()
#model = smf.ols('df.Yield ~pd.get_dummies(df.Temperature) +pd.get_dummies(df.Pressure)+pd.get_dummies(df.Conc)', data=df).fit()
#model = smf.ols('df.Viscosity ~ df.Temperature + df.Rate + df.Temperature:df.Rate', data=df).fit()
print(model.summary2())
print(model.params)
anovatable=sm.stats.anova_lm(model)
ax = sns.residplot(x=model.predict(df.Temperature), y=df.Viscosity, lowess=False, color='black')
ax.set_xlabel('Fitted value')
ax.set_ylabel('Residuals')
plt.show()
ax = sns.residplot(x=model.predict(df.Rate), y=df.Viscosity, lowess=False, color='black')
ax.set_xlabel('Fitted value')
ax.set_ylabel('Residuals')
plt.show()
fig=plt.figure(figsize=(8,12))
fig=sm.graphics.plot_ccpr_grid(model,fig=fig)
Viscosity =[39.3,40.0,40.9,41.5,40.3,40.5,40.7,40.2,40.6]
Temperature=[-1,-1,1,1,0,0,0,0,0]
Catalyst =[-1,1,-1,1,0,0,0,0,0]
data= {"Viscosity":Viscosity,"Temperature":Temperature,"Catalyst":Catalyst}
df =pd.DataFrame(data)
#model = smf.ols('df.Viscosity ~ C(df.Temperature) + C(df.Rate)', data=df).fit()
model = smf.ols('df.Viscosity ~df.Temperature +df.Catalyst', data=df).fit()
#model = smf.ols('df.Yield ~pd.get_dummies(df.Temperature) +pd.get_dummies(df.Pressure)+pd.get_dummies(df.Conc)', data=df).fit()
#model = smf.ols('df.Viscosity ~ df.Temperature + df.Rate + df.Temperature:df.Rate', data=df).fit()
print(model.summary2())
print(model.params)
>>> print(model.summary2())
C:\Users\Administrator\AppData\Local\Programs\Python\Python311\Lib\site-packages\scipy\stats\_stats_py.py:1736: UserWarning: kurtosistest only valid for n>=20 ... continuing anyway, n=9
warnings.warn("kurtosistest only valid for n>=20 ... continuing "
Results: Ordinary least squares
=================================================================
Model: OLS Adj. R-squared: 0.921
Dependent Variable: df.Viscosity AIC: -3.8073
Date: 2024-03-14 10:46 BIC: -3.2156
No. Observations: 9 Log-Likelihood: 4.9036
Df Model: 2 F-statistic: 47.82
Df Residuals: 6 Prob (F-statistic): 0.000206
R-squared: 0.941 Scale: 0.029537
-----------------------------------------------------------------
Coef. Std.Err. t P>|t| [0.025 0.975]
-----------------------------------------------------------------
Intercept 40.4444 0.0573 705.9869 0.0000 40.3043 40.5846
df.Temperature 0.7750 0.0859 9.0188 0.0001 0.5647 0.9853
df.Catalyst 0.3250 0.0859 3.7821 0.0092 0.1147 0.5353
-----------------------------------------------------------------
Omnibus: 0.188 Durbin-Watson: 2.850
Prob(Omnibus): 0.910 Jarque-Bera (JB): 0.098
Skew: 0.114 Prob(JB): 0.952
Kurtosis: 2.543 Condition No.: 2
=================================================================
Notes:
[1] Standard Errors assume that the covariance matrix of the
errors is correctly specified.
>>> print(model.params)
Intercept 40.444444
df.Temperature 0.775000
df.Catalyst 0.325000
dtype: float64
> sqsigmahat=((40.3)^2+(40.5)^2+(40.7)^2+(40.2)^2+(40.6)^2-(202.3)^2/5)/4
> sqsigmahat
[1] 0.043
F=4*5*(40.425-40.46)^2/(4+5)/sqsigmahat=0.06330749
中心点处的重复试验观测值可用于计算误差的估计量:
![]()
一阶模型假定变量x1和x2对响应有可加效应。变量间的交互作用可用已添加到模型中的交叉乘积项x1x2的系数β12来表示。此系数的最小二乘估计恰好是按普通22析因设计算得的交互作用效应的1/2,或
![]()
单自由度的交互作用的平方和是
![]()
比较SS交互作用和![]() ,得到下列拟合不足统计量:
,得到下列拟合不足统计量:
![]()
它很小,表示交互作用可以忽略。
对直线模型适合性的另一种检测方法,是应用6.6节中所介绍的对纯二次弯曲效应的检测。回忆一下它的构成,也就是,比较设计的析因部分4个点处的平均响应,即![]() ,以及在设计的中心点处的平均响应
,以及在设计的中心点处的平均响应![]() 。如果在真实响应函数中存在二次弯由性,则
。如果在真实响应函数中存在二次弯由性,则![]() 是这种弯曲性的度量。如果β11与β22是“纯二次”项x12子与x22的系数,则
是这种弯曲性的度量。如果β11与β22是“纯二次”项x12子与x22的系数,则![]() 是β11+β22的一个估计。在我们的例子中,纯二次项的一个估计是
是β11+β22的一个估计。在我们的例子中,纯二次项的一个估计是
![]()
与零假设H0: β11+β22=0有关的单自由度的平方和是
![]()
其中nF与nC分别是析因部分的点数和中心点数。因为
![]()
很小,没有显示出纯二次项的影响。
此模型的方差分析概括在表11.2中,交互作用和弯曲性的检验都不显著,而总回归的F检验是显著的,此外,![]() 和
和![]() 的标准差是
的标准差是
![]()
回归系数![]() 和
和![]() 相对于它们的标准差都较大。此时我们没有理由怀疑一阶模型的合适性。
相对于它们的标准差都较大。此时我们没有理由怀疑一阶模型的合适性。
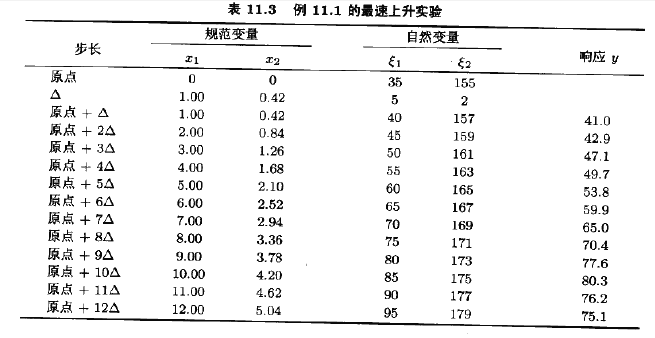
要离开设计中心--点(x1=0,x2=0)--沿最速上升路径移动,对应于沿x2方向每移动0.325个单位,则应沿x1方向移动0.775个单位。于是,最速上升路径经过点(x1=0,x2=0)且斜率为0.325/0.775。工程师决定用5分钟反应时间作为基本步长,由ξ1与x1之间的关系式,知道5分钟反应时间等价于规范变量x1的步长为△x1=1。因此,沿最速上升路径的步长是△x1=1.0000和△x2=
(0.325/0.775)△x1=0.42。
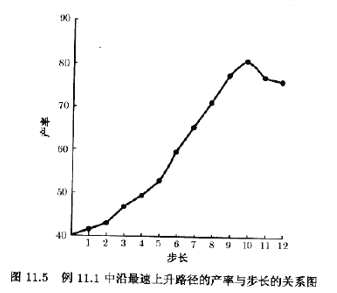
工程师计算了沿此路径的点,并观测了在这些点处的产率直至响应有下降为止。其结果见表11.3,表中既列出了规范变量,也列出了自然变量。虽然规范变量在数学上容易计算,但在过程运行中必须用自然变量。图11.5画出了沿最速上升路径的每步处的产率图。一直到第10步所观测到的响应都是增加的;但是,这以后的每一步收率都是减少的,因此,另一个一阶模型应该在点(ξ1=85,ξ2=175)的附近区域进行拟合。
一个新的一阶模型在点(ξ1=85,ξ2=175)附近拟合。探测的区域对ξ1是[80,90],对ξ2是[170,180],于是,规范变量是
![]()
再次用有5个中心点的22设计。实验设计列在表11.4中。

拟合表11.4的规范数据的一阶模型是
![]()
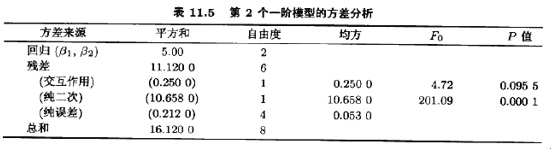
此模型的方差分析,包括交互作用和纯二次项的检测,如表11.5所示。交互作用和纯二次项的检测表明,一阶模型不是合适的近似。真实曲面的弯曲性指明了我们己接近最优点,为更精细地确定最优点,在该点必须做进一步的分析。
Viscosity =[76.5,77.0,78.0,79.5,79.9,80.3,80.0,79.7,79.8]
Temperature =[-1,-1,1,1,0,0,0,0,0]
Catalyst=[-1,1,-1,1,0,0,0,0,0]
data= {"Viscosity":Viscosity,"Temperature":Temperature,"Catalyst":Catalyst}
df =pd.DataFrame(data)
#model = smf.ols('df.Viscosity ~ C(df.Temperature) + C(df.Rate)', data=df).fit()
model = smf.ols('df.Viscosity ~df.Temperature +df.Catalyst', data=df).fit()
#model = smf.ols('df.Yield ~pd.get_dummies(df.Temperature) +pd.get_dummies(df.Pressure)+pd.get_dummies(df.Conc)', data=df).fit()
#model = smf.ols('df.Viscosity ~ df.Temperature + df.Rate + df.Temperature:df.Rate', data=df).fit()
print(model.summary2())
print(model.params)
anovatable=sm.stats.anova_lm(model)
ax = sns.residplot(x=model.predict(df.Temperature), y=df.Viscosity, lowess=False, color='black')
ax.set_xlabel('Fitted value')
ax.set_ylabel('Residuals')
plt.show()
ax = sns.residplot(x=model.predict(df.Rate), y=df.Viscosity, lowess=False, color='black')
ax.set_xlabel('Fitted value')
ax.set_ylabel('Residuals')
plt.show()
fig=plt.figure(figsize=(8,12))
fig=sm.graphics.plot_ccpr_grid(model,fig=fig)
model = smf.ols('df.Viscosity ~df.Temperature +df.Catalyst+df.Temperature :df.Catalyst', data=df).fit()
print(model.summary2())
print(model.params)
anovatable=sm.stats.anova_lm(model)
>>> print(model.summary2())
C:\Users\Administrator\AppData\Local\Programs\Python\Python311\Lib\site-packages\scipy\stats\_stats_py.py:1736: UserWarning: kurtosistest only valid for n>=20 ... continuing anyway, n=9
warnings.warn("kurtosistest only valid for n>=20 ... continuing "
Results: Ordinary least squares
===========================================================================
Model: OLS Adj. R-squared: -0.079
Dependent Variable: df.Viscosity AIC: 35.2399
Date: 2024-03-14 10:52 BIC: 36.0288
No. Observations: 9 Log-Likelihood: -13.620
Df Model: 3 F-statistic: 0.8050
Df Residuals: 5 Prob (F-statistic): 0.543
R-squared: 0.326 Scale: 2.1740
---------------------------------------------------------------------------
Coef. Std.Err. t P>|t| [0.025 0.975]
---------------------------------------------------------------------------
Intercept 78.9667 0.4915 160.6702 0.0000 77.7033 80.2301
df.Temperature 1.0000 0.7372 1.3564 0.2330 -0.8951 2.8951
df.Catalyst 0.5000 0.7372 0.6782 0.5277 -1.3951 2.3951
df.Temperature:df.Catalyst 0.2500 0.7372 0.3391 0.7483 -1.6451 2.1451
---------------------------------------------------------------------------
Omnibus: 7.707 Durbin-Watson: 0.457
Prob(Omnibus): 0.021 Jarque-Bera (JB): 1.377
Skew: -0.163 Prob(JB): 0.502
Kurtosis: 1.112 Condition No.: 2
===========================================================================
Notes:
[1] Standard Errors assume that the covariance matrix of the errors is
correctly specified.
>>> print(model.params)
Intercept 78.966667
df.Temperature 1.000000
df.Catalyst 0.500000
df.Temperature:df.Catalyst 0.250000
dtype: float64
>>> anovatable=sm.stats.anova_lm(model)
>>> anovatable
df sum_sq mean_sq F PR(>F)
df.Temperature 1.0 4.00 4.000 1.839926 0.232992
df.Catalyst 1.0 1.00 1.000 0.459982 0.527745
df.Temperature:df.Catalyst 1.0 0.25 0.250 0.114995 0.748306
Residual 5.0 10.87 2.174 NaN NaN
> sqsigmahat=((79.9)^2+(80.3)^2+(80.0)^2+(79.7)^2+(79.8)^2-(79.9+80.3+80.0+79.7+79.8)^2/5)/4
> sqsigmahat
[1] 0.053
F=4*5*((41.0+42.9+47.1+49.7)/4-(79.9+80.3+80.0+79.7+79.8)/5)^2/(4+5)/sqsigmahat=50675.27
由例11.1可见,最速上升路径与拟合的一阶模型
![]()
的回归系数的特号和大小成比例。容易给出一个一般算法,以确定最速上升路径上点的坐标。假定x1=x2=…=xk=0是基点或原点。则
(1)选取一个过程变量的步长,比方说△xj。通常,选取我们最了解的变量,或选取其回归系数的绝对值![]() 最大的变量。
最大的变量。
(2)其他变量的步长是
![]()
(3)将规范变量的△xi转换至自然变量。
为了说明起见,考虑例11.1最速上升路径的计算。因为x1有最大的回归系数,选取反应时间作为上述方法的步骤1中的变量。5分钟反应时间是步长(根据工序知识)。用规范变量的说法,也就是△x1=1.0,因此,由步骤2,温度的步长是
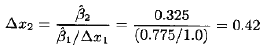
为了将规范步长(△x1=1.0,△x2=0.42)转换为时间和温度的自然单位,用关系式
![]()
其结果为