Day34 Python打卡训练营
知识点回归:
1. CPU性能的查看:看架构代际、核心数、线程数
2. GPU性能的查看:看显存、看级别、看架构代际
3. GPU训练的方法:数据和模型移动到GPU device上
4. 类的call方法:为什么定义前向传播时可以直接写作self.fc1(x)
要让模型在 GPU 上训练,主要是将模型和数据迁移到 GPU 设备上。
在 PyTorch 里,.to(device) 方法的作用是把张量或者模型转移到指定的计算设备(像 CPU 或者 GPU)上。
- 对于张量(Tensor):调用 .to(device) 之后,会返回一个在新设备上的新张量。
- 对于模型(nn.Module):调用 .to(device) 会直接对模型进行修改,让其所有参数和缓冲区都移到新设备上。
在进行计算时,所有输入张量和模型必须处于同一个设备。要是它们不在同一设备上,就会引发运行时错误。并非所有 PyTorch 对象都有 .to(device) 方法,只有继承自 torch.nn.Module 的模型以及 torch.Tensor 对象才有此方法。
RuntimeError: Tensor for argument #1 'input' is on CPU, but expected it to be on GPU这个常见错误就是输入张量和模型处于不同的设备。
如何衡量GPU的性能好坏呢?
以RTX 3090 Ti, RTX 3080, RTX 3070 Ti, RTX 3070, RTX 4070等为例
-
通过“代” 前两位数字代表“代”: 40xx (第40代), 30xx (第30代), 20xx (第20代)。“代”通常指的是其底层的架构 (Architecture)。每一代新架构的发布,通常会带来工艺制程的进步和其他改进。也就是新一代架构的目标是在能效比和绝对性能上超越前一代同型号的产品。
-
通过级别 后面的数字代表“级别”,
- xx90: 通常是该代的消费级旗舰或次旗舰,性能最强,显存最大 (如 RTX 4090, RTX 3090)。
- xx80: 高端型号,性能强劲,显存较多 (如 RTX 4080, RTX 3080)。
- xx70: 中高端,甜点级,性能和价格平衡较好 (如 RTX 4070, RTX 3070)。
- xx60: 主流中端,性价比较高,适合入门或预算有限 (如 RTX 4060, RTX 3060)。
- xx50: 入门级,深度学习能力有限。
-
通过后缀 Ti 通常是同型号的增强版,性能介于原型号和更高一级型号之间 (如 RTX 4070 Ti 强于 RTX 4070,小于4080)。
-
通过显存容量 VRAM (最重要!!) 他是GPU 自身的独立高速内存,用于存储模型参数、激活值、输入数据批次等。单位通常是 GB(例如 8GB, 12GB, 24GB, 48GB)。如果显存不足,可能无法加载模型,或者被迫使用很小的批量大小,从而影响训练速度和效果
- 训练阶段:小批量梯度是对真实梯度的一个有噪声的估计。批量越小,梯度的方差越大(噪声越大)。显存小只能够使用小批量梯度。
- 推理阶段:有些模型本身就非常庞大(例如大型语言模型、高分辨率图像的复杂 CNN 网络)。即使你将批量大小减到 1,模型参数本身占用的显存可能就已经超出了你的 GPU 显存上限。
import torch# 检查CUDA是否可用 if torch.cuda.is_available():print("CUDA可用!")# 获取可用的CUDA设备数量device_count = torch.cuda.device_count()print(f"可用的CUDA设备数量: {device_count}")# 获取当前使用的CUDA设备索引current_device = torch.cuda.current_device()print(f"当前使用的CUDA设备索引: {current_device}")# 获取当前CUDA设备的名称device_name = torch.cuda.get_device_name(current_device)print(f"当前CUDA设备的名称: {device_name}")# 获取CUDA版本cuda_version = torch.version.cudaprint(f"CUDA版本: {cuda_version}")# 查看cuDNN版本(如果可用)print("cuDNN版本:", torch.backends.cudnn.version())else:print("CUDA不可用。")CUDA可用! 可用的CUDA设备数量: 1 当前使用的CUDA设备索引: 0 当前CUDA设备的名称: NVIDIA GeForce RTX 3080 Ti CUDA版本: 11.1 cuDNN版本: 8005
# 设置GPU设备 device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu") print(f"使用设备: {device}")使用设备: cuda:0
# 加载鸢尾花数据集 iris = load_iris() X = iris.data # 特征数据 y = iris.target # 标签数据# 划分训练集和测试集 X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)# 归一化数据 from sklearn.preprocessing import MinMaxScaler scaler = MinMaxScaler() X_train = scaler.fit_transform(X_train) X_test = scaler.transform(X_test)# 将数据转换为PyTorch张量并移至GPU # 分类问题交叉熵损失要求标签为long类型 # 张量具有to(device)方法,可以将张量移动到指定的设备上 X_train = torch.FloatTensor(X_train).to(device) y_train = torch.LongTensor(y_train).to(device) X_test = torch.FloatTensor(X_test).to(device) y_test = torch.LongTensor(y_test).to(device)class MLP(nn.Module):def __init__(self):super(MLP, self).__init__()self.fc1 = nn.Linear(4, 10)self.relu = nn.ReLU()self.fc2 = nn.Linear(10, 3)def forward(self, x):out = self.fc1(x)out = self.relu(out)out = self.fc2(out)return out# 实例化模型并移至GPU # MLP继承nn.Module类,所以也具有to(device)方法 model = MLP().to(device)# 定义损失函数和优化器 criterion = nn.CrossEntropyLoss() optimizer = optim.SGD(model.parameters(), lr=0.01)# 训练模型 num_epochs = 20000 losses = []start_time = time.time()for epoch in range(num_epochs):# 前向传播outputs = model(X_train)loss = criterion(outputs, y_train)# 反向传播和优化optimizer.zero_grad()loss.backward()optimizer.step()# 记录损失值losses.append(loss.item())# 打印训练信息if (epoch + 1) % 100 == 0:print(f'Epoch [{epoch+1}/{num_epochs}], Loss: {loss.item():.4f}')time_all = time.time() - start_time print(f'Training time: {time_all:.2f} seconds')# 可视化损失曲线 plt.plot(range(num_epochs), losses) plt.xlabel('Epoch') plt.ylabel('Loss') plt.title('Training Loss over Epochs') plt.show()Epoch [100/20000], Loss: 1.0763 Epoch [200/20000], Loss: 1.0542 Epoch [300/20000], Loss: 1.0276 Epoch [400/20000], Loss: 0.9927 Epoch [500/20000], Loss: 0.9465 Epoch [600/20000], Loss: 0.8870 Epoch [700/20000], Loss: 0.8205 Epoch [800/20000], Loss: 0.7541 Epoch [900/20000], Loss: 0.6927 Epoch [1000/20000], Loss: 0.6391 Epoch [1100/20000], Loss: 0.5941 Epoch [1200/20000], Loss: 0.5566 Epoch [1300/20000], Loss: 0.5253 Epoch [1400/20000], Loss: 0.4984 Epoch [1500/20000], Loss: 0.4751 Epoch [1600/20000], Loss: 0.4545 Epoch [1700/20000], Loss: 0.4360 Epoch [1800/20000], Loss: 0.4189 Epoch [1900/20000], Loss: 0.4032 Epoch [2000/20000], Loss: 0.3884 Epoch [2100/20000], Loss: 0.3746 Epoch [2200/20000], Loss: 0.3614 Epoch [2300/20000], Loss: 0.3487 Epoch [2400/20000], Loss: 0.3367 Epoch [2500/20000], Loss: 0.3251 Epoch [2600/20000], Loss: 0.3140 Epoch [2700/20000], Loss: 0.3034 Epoch [2800/20000], Loss: 0.2933 Epoch [2900/20000], Loss: 0.2835 Epoch [3000/20000], Loss: 0.2742 Epoch [3100/20000], Loss: 0.2654 Epoch [3200/20000], Loss: 0.2570 Epoch [3300/20000], Loss: 0.2490 Epoch [3400/20000], Loss: 0.2413 Epoch [3500/20000], Loss: 0.2340 Epoch [3600/20000], Loss: 0.2270 Epoch [3700/20000], Loss: 0.2204 Epoch [3800/20000], Loss: 0.2142 Epoch [3900/20000], Loss: 0.2082 Epoch [4000/20000], Loss: 0.2026 Epoch [4100/20000], Loss: 0.1972 Epoch [4200/20000], Loss: 0.1921 Epoch [4300/20000], Loss: 0.1872 Epoch [4400/20000], Loss: 0.1826 Epoch [4500/20000], Loss: 0.1782 Epoch [4600/20000], Loss: 0.1740 Epoch [4700/20000], Loss: 0.1701 Epoch [4800/20000], Loss: 0.1663 Epoch [4900/20000], Loss: 0.1627 Epoch [5000/20000], Loss: 0.1593 Epoch [5100/20000], Loss: 0.1560 Epoch [5200/20000], Loss: 0.1529 Epoch [5300/20000], Loss: 0.1498 Epoch [5400/20000], Loss: 0.1470 Epoch [5500/20000], Loss: 0.1442 Epoch [5600/20000], Loss: 0.1416 Epoch [5700/20000], Loss: 0.1391 Epoch [5800/20000], Loss: 0.1368 Epoch [5900/20000], Loss: 0.1344 Epoch [6000/20000], Loss: 0.1322 Epoch [6100/20000], Loss: 0.1301 Epoch [6200/20000], Loss: 0.1281 Epoch [6300/20000], Loss: 0.1261 Epoch [6400/20000], Loss: 0.1243 Epoch [6500/20000], Loss: 0.1224 Epoch [6600/20000], Loss: 0.1207 Epoch [6700/20000], Loss: 0.1190 Epoch [6800/20000], Loss: 0.1175 Epoch [6900/20000], Loss: 0.1159 Epoch [7000/20000], Loss: 0.1144 Epoch [7100/20000], Loss: 0.1130 Epoch [7200/20000], Loss: 0.1115 Epoch [7300/20000], Loss: 0.1102 Epoch [7400/20000], Loss: 0.1089 Epoch [7500/20000], Loss: 0.1077 Epoch [7600/20000], Loss: 0.1065 Epoch [7700/20000], Loss: 0.1053 Epoch [7800/20000], Loss: 0.1041 Epoch [7900/20000], Loss: 0.1031 Epoch [8000/20000], Loss: 0.1020 Epoch [8100/20000], Loss: 0.1010 Epoch [8200/20000], Loss: 0.1000 Epoch [8300/20000], Loss: 0.0990 Epoch [8400/20000], Loss: 0.0981 Epoch [8500/20000], Loss: 0.0972 Epoch [8600/20000], Loss: 0.0963 Epoch [8700/20000], Loss: 0.0954 Epoch [8800/20000], Loss: 0.0945 Epoch [8900/20000], Loss: 0.0938 Epoch [9000/20000], Loss: 0.0930 Epoch [9100/20000], Loss: 0.0922 Epoch [9200/20000], Loss: 0.0915 Epoch [9300/20000], Loss: 0.0908 Epoch [9400/20000], Loss: 0.0901 Epoch [9500/20000], Loss: 0.0894 Epoch [9600/20000], Loss: 0.0887 Epoch [9700/20000], Loss: 0.0881 Epoch [9800/20000], Loss: 0.0874 Epoch [9900/20000], Loss: 0.0868 Epoch [10000/20000], Loss: 0.0863 Epoch [10100/20000], Loss: 0.0857 Epoch [10200/20000], Loss: 0.0851 Epoch [10300/20000], Loss: 0.0846 Epoch [10400/20000], Loss: 0.0840 Epoch [10500/20000], Loss: 0.0835 Epoch [10600/20000], Loss: 0.0830 Epoch [10700/20000], Loss: 0.0825 Epoch [10800/20000], Loss: 0.0820 Epoch [10900/20000], Loss: 0.0815 Epoch [11000/20000], Loss: 0.0811 Epoch [11100/20000], Loss: 0.0806 Epoch [11200/20000], Loss: 0.0802 Epoch [11300/20000], Loss: 0.0798 Epoch [11400/20000], Loss: 0.0793 Epoch [11500/20000], Loss: 0.0789 Epoch [11600/20000], Loss: 0.0785 Epoch [11700/20000], Loss: 0.0781 Epoch [11800/20000], Loss: 0.0777 Epoch [11900/20000], Loss: 0.0773 Epoch [12000/20000], Loss: 0.0770 Epoch [12100/20000], Loss: 0.0766 Epoch [12200/20000], Loss: 0.0763 Epoch [12300/20000], Loss: 0.0759 Epoch [12400/20000], Loss: 0.0756 Epoch [12500/20000], Loss: 0.0752 Epoch [12600/20000], Loss: 0.0749 Epoch [12700/20000], Loss: 0.0746 Epoch [12800/20000], Loss: 0.0743 Epoch [12900/20000], Loss: 0.0740 Epoch [13000/20000], Loss: 0.0737 Epoch [13100/20000], Loss: 0.0734 Epoch [13200/20000], Loss: 0.0731 Epoch [13300/20000], Loss: 0.0728 Epoch [13400/20000], Loss: 0.0725 Epoch [13500/20000], Loss: 0.0722 Epoch [13600/20000], Loss: 0.0720 Epoch [13700/20000], Loss: 0.0717 Epoch [13800/20000], Loss: 0.0715 Epoch [13900/20000], Loss: 0.0712 Epoch [14000/20000], Loss: 0.0710 Epoch [14100/20000], Loss: 0.0707 Epoch [14200/20000], Loss: 0.0705 Epoch [14300/20000], Loss: 0.0702 Epoch [14400/20000], Loss: 0.0700 Epoch [14500/20000], Loss: 0.0698 Epoch [14600/20000], Loss: 0.0695 Epoch [14700/20000], Loss: 0.0693 Epoch [14800/20000], Loss: 0.0691 Epoch [14900/20000], Loss: 0.0689 Epoch [15000/20000], Loss: 0.0687 Epoch [15100/20000], Loss: 0.0685 Epoch [15200/20000], Loss: 0.0683 Epoch [15300/20000], Loss: 0.0681 Epoch [15400/20000], Loss: 0.0679 Epoch [15500/20000], Loss: 0.0677 Epoch [15600/20000], Loss: 0.0675 Epoch [15700/20000], Loss: 0.0673 Epoch [15800/20000], Loss: 0.0671 Epoch [15900/20000], Loss: 0.0669 Epoch [16000/20000], Loss: 0.0667 Epoch [16100/20000], Loss: 0.0666 Epoch [16200/20000], Loss: 0.0664 Epoch [16300/20000], Loss: 0.0662 Epoch [16400/20000], Loss: 0.0661 Epoch [16500/20000], Loss: 0.0659 Epoch [16600/20000], Loss: 0.0658 Epoch [16700/20000], Loss: 0.0656 Epoch [16800/20000], Loss: 0.0655 Epoch [16900/20000], Loss: 0.0653 Epoch [17000/20000], Loss: 0.0651 Epoch [17100/20000], Loss: 0.0650 Epoch [17200/20000], Loss: 0.0649 Epoch [17300/20000], Loss: 0.0647 Epoch [17400/20000], Loss: 0.0646 Epoch [17500/20000], Loss: 0.0644 Epoch [17600/20000], Loss: 0.0643 Epoch [17700/20000], Loss: 0.0641 Epoch [17800/20000], Loss: 0.0640 Epoch [17900/20000], Loss: 0.0638 Epoch [18000/20000], Loss: 0.0637 Epoch [18100/20000], Loss: 0.0636 Epoch [18200/20000], Loss: 0.0634 Epoch [18300/20000], Loss: 0.0633 Epoch [18400/20000], Loss: 0.0632 Epoch [18500/20000], Loss: 0.0630 Epoch [18600/20000], Loss: 0.0629 Epoch [18700/20000], Loss: 0.0628 Epoch [18800/20000], Loss: 0.0627 Epoch [18900/20000], Loss: 0.0626 Epoch [19000/20000], Loss: 0.0625 Epoch [19100/20000], Loss: 0.0623 Epoch [19200/20000], Loss: 0.0622 Epoch [19300/20000], Loss: 0.0621 Epoch [19400/20000], Loss: 0.0620 Epoch [19500/20000], Loss: 0.0619 Epoch [19600/20000], Loss: 0.0618 Epoch [19700/20000], Loss: 0.0617 Epoch [19800/20000], Loss: 0.0616 Epoch [19900/20000], Loss: 0.0615 Epoch [20000/20000], Loss: 0.0614 Training time: 11.29 secondsEpoch [100/20000], Loss: 1.0763 Epoch [200/20000], Loss: 1.0542 Epoch [300/20000], Loss: 1.0276 Epoch [400/20000], Loss: 0.9927 Epoch [500/20000], Loss: 0.9465 Epoch [600/20000], Loss: 0.8870 Epoch [700/20000], Loss: 0.8205 Epoch [800/20000], Loss: 0.7541 Epoch [900/20000], Loss: 0.6927 Epoch [1000/20000], Loss: 0.6391 Epoch [1100/20000], Loss: 0.5941 Epoch [1200/20000], Loss: 0.5566 Epoch [1300/20000], Loss: 0.5253 Epoch [1400/20000], Loss: 0.4984 Epoch [1500/20000], Loss: 0.4751 Epoch [1600/20000], Loss: 0.4545 Epoch [1700/20000], Loss: 0.4360 Epoch [1800/20000], Loss: 0.4189 Epoch [1900/20000], Loss: 0.4032 Epoch [2000/20000], Loss: 0.3884 Epoch [2100/20000], Loss: 0.3746 Epoch [2200/20000], Loss: 0.3614 Epoch [2300/20000], Loss: 0.3487 Epoch [2400/20000], Loss: 0.3367 Epoch [2500/20000], Loss: 0.3251 Epoch [2600/20000], Loss: 0.3140 Epoch [2700/20000], Loss: 0.3034 Epoch [2800/20000], Loss: 0.2933 Epoch [2900/20000], Loss: 0.2835 Epoch [3000/20000], Loss: 0.2742 Epoch [3100/20000], Loss: 0.2654 Epoch [3200/20000], Loss: 0.2570 Epoch [3300/20000], Loss: 0.2490 Epoch [3400/20000], Loss: 0.2413 Epoch [3500/20000], Loss: 0.2340 Epoch [3600/20000], Loss: 0.2270 Epoch [3700/20000], Loss: 0.2204 Epoch [3800/20000], Loss: 0.2142 Epoch [3900/20000], Loss: 0.2082 Epoch [4000/20000], Loss: 0.2026 Epoch [4100/20000], Loss: 0.1972 Epoch [4200/20000], Loss: 0.1921 Epoch [4300/20000], Loss: 0.1872 Epoch [4400/20000], Loss: 0.1826 Epoch [4500/20000], Loss: 0.1782 Epoch [4600/20000], Loss: 0.1740 Epoch [4700/20000], Loss: 0.1701 Epoch [4800/20000], Loss: 0.1663 Epoch [4900/20000], Loss: 0.1627 Epoch [5000/20000], Loss: 0.1593 Epoch [5100/20000], Loss: 0.1560 Epoch [5200/20000], Loss: 0.1529 Epoch [5300/20000], Loss: 0.1498 Epoch [5400/20000], Loss: 0.1470 Epoch [5500/20000], Loss: 0.1442 Epoch [5600/20000], Loss: 0.1416 Epoch [5700/20000], Loss: 0.1391 Epoch [5800/20000], Loss: 0.1368 Epoch [5900/20000], Loss: 0.1344 Epoch [6000/20000], Loss: 0.1322 Epoch [6100/20000], Loss: 0.1301 Epoch [6200/20000], Loss: 0.1281 Epoch [6300/20000], Loss: 0.1261 Epoch [6400/20000], Loss: 0.1243 Epoch [6500/20000], Loss: 0.1224 Epoch [6600/20000], Loss: 0.1207 Epoch [6700/20000], Loss: 0.1190 Epoch [6800/20000], Loss: 0.1175 Epoch [6900/20000], Loss: 0.1159 Epoch [7000/20000], Loss: 0.1144 Epoch [7100/20000], Loss: 0.1130 Epoch [7200/20000], Loss: 0.1115 Epoch [7300/20000], Loss: 0.1102 Epoch [7400/20000], Loss: 0.1089 Epoch [7500/20000], Loss: 0.1077 Epoch [7600/20000], Loss: 0.1065 Epoch [7700/20000], Loss: 0.1053 Epoch [7800/20000], Loss: 0.1041 Epoch [7900/20000], Loss: 0.1031 Epoch [8000/20000], Loss: 0.1020 Epoch [8100/20000], Loss: 0.1010 Epoch [8200/20000], Loss: 0.1000 Epoch [8300/20000], Loss: 0.0990 Epoch [8400/20000], Loss: 0.0981 Epoch [8500/20000], Loss: 0.0972 Epoch [8600/20000], Loss: 0.0963 Epoch [8700/20000], Loss: 0.0954 Epoch [8800/20000], Loss: 0.0945 Epoch [8900/20000], Loss: 0.0938 Epoch [9000/20000], Loss: 0.0930 Epoch [9100/20000], Loss: 0.0922 Epoch [9200/20000], Loss: 0.0915 Epoch [9300/20000], Loss: 0.0908 Epoch [9400/20000], Loss: 0.0901 Epoch [9500/20000], Loss: 0.0894 Epoch [9600/20000], Loss: 0.0887 Epoch [9700/20000], Loss: 0.0881 Epoch [9800/20000], Loss: 0.0874 Epoch [9900/20000], Loss: 0.0868 Epoch [10000/20000], Loss: 0.0863 Epoch [10100/20000], Loss: 0.0857 Epoch [10200/20000], Loss: 0.0851 Epoch [10300/20000], Loss: 0.0846 Epoch [10400/20000], Loss: 0.0840 Epoch [10500/20000], Loss: 0.0835 Epoch [10600/20000], Loss: 0.0830 Epoch [10700/20000], Loss: 0.0825 Epoch [10800/20000], Loss: 0.0820 Epoch [10900/20000], Loss: 0.0815 Epoch [11000/20000], Loss: 0.0811 Epoch [11100/20000], Loss: 0.0806 Epoch [11200/20000], Loss: 0.0802 Epoch [11300/20000], Loss: 0.0798 Epoch [11400/20000], Loss: 0.0793 Epoch [11500/20000], Loss: 0.0789 Epoch [11600/20000], Loss: 0.0785 Epoch [11700/20000], Loss: 0.0781 Epoch [11800/20000], Loss: 0.0777 Epoch [11900/20000], Loss: 0.0773 Epoch [12000/20000], Loss: 0.0770 Epoch [12100/20000], Loss: 0.0766 Epoch [12200/20000], Loss: 0.0763 Epoch [12300/20000], Loss: 0.0759 Epoch [12400/20000], Loss: 0.0756 Epoch [12500/20000], Loss: 0.0752 Epoch [12600/20000], Loss: 0.0749 Epoch [12700/20000], Loss: 0.0746 Epoch [12800/20000], Loss: 0.0743 Epoch [12900/20000], Loss: 0.0740 Epoch [13000/20000], Loss: 0.0737 Epoch [13100/20000], Loss: 0.0734 Epoch [13200/20000], Loss: 0.0731 Epoch [13300/20000], Loss: 0.0728 Epoch [13400/20000], Loss: 0.0725 Epoch [13500/20000], Loss: 0.0722 Epoch [13600/20000], Loss: 0.0720 Epoch [13700/20000], Loss: 0.0717 Epoch [13800/20000], Loss: 0.0715 Epoch [13900/20000], Loss: 0.0712 Epoch [14000/20000], Loss: 0.0710 Epoch [14100/20000], Loss: 0.0707 Epoch [14200/20000], Loss: 0.0705 Epoch [14300/20000], Loss: 0.0702 Epoch [14400/20000], Loss: 0.0700 Epoch [14500/20000], Loss: 0.0698 Epoch [14600/20000], Loss: 0.0695 Epoch [14700/20000], Loss: 0.0693 Epoch [14800/20000], Loss: 0.0691 Epoch [14900/20000], Loss: 0.0689 Epoch [15000/20000], Loss: 0.0687 Epoch [15100/20000], Loss: 0.0685 Epoch [15200/20000], Loss: 0.0683 Epoch [15300/20000], Loss: 0.0681 Epoch [15400/20000], Loss: 0.0679 Epoch [15500/20000], Loss: 0.0677 Epoch [15600/20000], Loss: 0.0675 Epoch [15700/20000], Loss: 0.0673 Epoch [15800/20000], Loss: 0.0671 Epoch [15900/20000], Loss: 0.0669 Epoch [16000/20000], Loss: 0.0667 Epoch [16100/20000], Loss: 0.0666 Epoch [16200/20000], Loss: 0.0664 Epoch [16300/20000], Loss: 0.0662 Epoch [16400/20000], Loss: 0.0661 Epoch [16500/20000], Loss: 0.0659 Epoch [16600/20000], Loss: 0.0658 Epoch [16700/20000], Loss: 0.0656 Epoch [16800/20000], Loss: 0.0655 Epoch [16900/20000], Loss: 0.0653 Epoch [17000/20000], Loss: 0.0651 Epoch [17100/20000], Loss: 0.0650 Epoch [17200/20000], Loss: 0.0649 Epoch [17300/20000], Loss: 0.0647 Epoch [17400/20000], Loss: 0.0646 Epoch [17500/20000], Loss: 0.0644 Epoch [17600/20000], Loss: 0.0643 Epoch [17700/20000], Loss: 0.0641 Epoch [17800/20000], Loss: 0.0640 Epoch [17900/20000], Loss: 0.0638 Epoch [18000/20000], Loss: 0.0637 Epoch [18100/20000], Loss: 0.0636 Epoch [18200/20000], Loss: 0.0634 Epoch [18300/20000], Loss: 0.0633 Epoch [18400/20000], Loss: 0.0632 Epoch [18500/20000], Loss: 0.0630 Epoch [18600/20000], Loss: 0.0629 Epoch [18700/20000], Loss: 0.0628 Epoch [18800/20000], Loss: 0.0627 Epoch [18900/20000], Loss: 0.0626 Epoch [19000/20000], Loss: 0.0625 Epoch [19100/20000], Loss: 0.0623 Epoch [19200/20000], Loss: 0.0622 Epoch [19300/20000], Loss: 0.0621 Epoch [19400/20000], Loss: 0.0620 Epoch [19500/20000], Loss: 0.0619 Epoch [19600/20000], Loss: 0.0618 Epoch [19700/20000], Loss: 0.0617 Epoch [19800/20000], Loss: 0.0616 Epoch [19900/20000], Loss: 0.0615 Epoch [20000/20000], Loss: 0.0614 Training time: 11.29 seconds
你这时可能会好奇,不是说gpu比cpu快很多吗?怎么cpu跑了3s,gpu跑了11s。
你问AI,他会告诉你,对于非常小的数据集和简单的模型,CPU 通常会比 GPU 更快。实际上,这并非本质的原因。
这需要你进一步理解二者的区别,深度学习项目的运行时长往往很长,如果只停留在跑通的层面,那是不够的。
本质是因为GPU在计算的时候,相较于cpu多了3个时间上的开销
- 数据传输开销 (CPU 内存 <-> GPU 显存)
- 核心启动开销 (GPU 核心启动时间)
- 性能浪费:计算量和数据批次
-
下面详细介绍下
数据传输开销 (CPU 内存 <-> GPU 显存)
- 在 GPU 进行任何计算之前,数据(输入张量 X_train、y_train,模型参数)需要从计算机的主内存 (RAM) 复制到 GPU 专用的显存 (VRAM) 中。
- 当结果传回 CPU 时(例如,使用 loss.item() 获取损失值用于打印或记录,或者获取最终预测结果),数据也需要从 GPU 显存复制回 CPU 内存。
- 对于少量数据和非常快速的计算任务,这个传输时间可能比 GPU 通过并行计算节省下来的时间还要长。
-
在上述代码中,循环里的 loss.item() 操作会在每个 epoch 都进行一次从 GPU 到 CPU 的数据同步和传输,以便获取标量损失值。对于20000个epoch来说,这会累积不少的传输开销。
核心启动开销 (GPU 核心启动时间)
- GPU 执行的每个操作(例如,一个线性层的前向传播、一个激活函数)都涉及到在 GPU 上启动一个“核心”(kernel)——一个在 GPU 众多计算单元上运行的小程序。
- 启动每个核心都有一个小的、固定的开销。
- 如果核心内的实际计算量非常小(本项目的小型网络和鸢尾花数据),这个启动开销在总时间中的占比就会比较大。相比之下,CPU 执行这些小操作的“调度”开销通常更低。
-
性能浪费:计算量和数据批次
- 这个数据量太少,gpu的很多计算单元都没有被用到,即使用了全批次也没有用到的全部计算单元。
-
综上,数据传输和各种固定开销的总和,超过了 GPU 在这点计算量上通过并行处理所能节省的时间,导致了 GPU 比 CPU 慢的现象。
- CPU (12th Gen Intel Core i9-12900KF): 对于这种小任务,CPU 的单核性能强劲,且没有显著的数据传输到“另一块芯片”的开销。它可以非常迅速地完成计算。
-
这些特性导致GPU在处理鸢尾花分类这种“玩具级别”的问题时,它的优势无法体现,反而会因为上述开销显得“笨重”。
那么什么时候 GPU 会发挥巨大优势?
- 大型数据集: 例如,图像数据集成千上万张图片,每张图片维度很高。
- 大型模型: 例如,深度卷积网络 (CNNs like ResNet, VGG) 或 Transformer 模型,它们有数百万甚至数十亿的参数,计算量巨大。
- 合适的批处理大小: 能够充分利用 GPU 并行性的 batch size,不至于还有剩余的计算量没有被 GPU 处理。
- 复杂的、可并行的运算: 大量的矩阵乘法、卷积等。
-
针对上面反应的3个问题,能够优化的只有数据传输时间,针对性解决即可,很容易想到2个思路:
- 直接不打印训练过程的loss了,但是这样会没办法记录最后的可视化图片,只能肉眼观察loss数值变化。
- 每隔200个epoch保存一下loss,不需要20000个epoch每次都打印,
-
下面先尝试第一个思路:
- GPU (NVIDIA GeForce RTX 3080 Ti):需要花费时间将数据和模型从 CPU 内存移动到 GPU 显存。
- 每次在 GPU 上执行运算(如 model(X_train)、loss.backward()) 都有核心启动的固定开销。
- loss.item() 在每个 epoch 都需要将结果从 GPU 传回 CPU,这在总共 20000 个 epoch 中会累积。
- GPU 强大的并行计算能力在这种小任务上完全没有用武之地。
# 知道了哪里耗时,针对性优化一下 import torch import torch.nn as nn import torch.optim as optim from sklearn.datasets import load_iris from sklearn.model_selection import train_test_split import numpy as np# 仍然用4特征,3分类的鸢尾花数据集作为我们今天的数据集 # 加载鸢尾花数据集 iris = load_iris() X = iris.data # 特征数据 y = iris.target # 标签数据 # 划分训练集和测试集 X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)# # 打印下尺寸 # print(X_train.shape) # print(y_train.shape) # print(X_test.shape) # print(y_test.shape)# 归一化数据,神经网络对于输入数据的尺寸敏感,归一化是最常见的处理方式 from sklearn.preprocessing import MinMaxScaler scaler = MinMaxScaler() X_train = scaler.fit_transform(X_train) X_test = scaler.transform(X_test) #确保训练集和测试集是相同的缩放# 将数据转换为 PyTorch 张量,因为 PyTorch 使用张量进行训练 # y_train和y_test是整数,所以需要转化为long类型,如果是float32,会输出1.0 0.0 X_train = torch.FloatTensor(X_train) y_train = torch.LongTensor(y_train) X_test = torch.FloatTensor(X_test) y_test = torch.LongTensor(y_test)class MLP(nn.Module): # 定义一个多层感知机(MLP)模型,继承父类nn.Moduledef __init__(self): # 初始化函数super(MLP, self).__init__() # 调用父类的初始化函数# 前三行是八股文,后面的是自定义的self.fc1 = nn.Linear(4, 10) # 输入层到隐藏层self.relu = nn.ReLU()self.fc2 = nn.Linear(10, 3) # 隐藏层到输出层 # 输出层不需要激活函数,因为后面会用到交叉熵函数cross_entropy,交叉熵函数内部有softmax函数,会把输出转化为概率def forward(self, x):out = self.fc1(x)out = self.relu(out)out = self.fc2(out)return out# 实例化模型 model = MLP()# 分类问题使用交叉熵损失函数 criterion = nn.CrossEntropyLoss()# 使用随机梯度下降优化器 optimizer = optim.SGD(model.parameters(), lr=0.01)# # 使用自适应学习率的化器 # optimizer = optim.Adam(model.parameters(), lr=0.001)# 训练模型 num_epochs = 20000 # 训练的轮数# 用于存储每个 epoch 的损失值 losses = []import time start_time = time.time() # 记录开始时间for epoch in range(num_epochs): # range是从0开始,所以epoch是从0开始# 前向传播outputs = model.forward(X_train) # 显式调用forward函数# outputs = model(X_train) # 常见写法隐式调用forward函数,其实是用了model类的__call__方法loss = criterion(outputs, y_train) # output是模型预测值,y_train是真实标签# 反向传播和优化optimizer.zero_grad() #梯度清零,因为PyTorch会累积梯度,所以每次迭代需要清零,梯度累计是那种小的bitchsize模拟大的bitchsizeloss.backward() # 反向传播计算梯度optimizer.step() # 更新参数# 记录损失值# losses.append(loss.item())# 打印训练信息if (epoch + 1) % 100 == 0: # range是从0开始,所以epoch+1是从当前epoch开始,每100个epoch打印一次print(f'Epoch [{epoch+1}/{num_epochs}], Loss: {loss.item():.4f}')time_all = time.time() - start_time # 计算训练时间 print(f'Training time: {time_all:.2f} seconds')优化后发现确实效果好,近乎和用cpu训练的时长差不多。所以可以理解为数据从gpu到cpu的传输占用了大量时间。
下面尝试下第二个思路:
import torch import torch.nn as nn import torch.optim as optim from sklearn.datasets import load_iris from sklearn.model_selection import train_test_split from sklearn.preprocessing import MinMaxScaler import time import matplotlib.pyplot as plt# 设置GPU设备 device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu") print(f"使用设备: {device}")# 加载鸢尾花数据集 iris = load_iris() X = iris.data # 特征数据 y = iris.target # 标签数据# 划分训练集和测试集 X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)# 归一化数据 scaler = MinMaxScaler() X_train = scaler.fit_transform(X_train) X_test = scaler.transform(X_test)# 将数据转换为PyTorch张量并移至GPU X_train = torch.FloatTensor(X_train).to(device) y_train = torch.LongTensor(y_train).to(device) X_test = torch.FloatTensor(X_test).to(device) y_test = torch.LongTensor(y_test).to(device)class MLP(nn.Module):def __init__(self):super(MLP, self).__init__()self.fc1 = nn.Linear(4, 10) # 输入层到隐藏层self.relu = nn.ReLU()self.fc2 = nn.Linear(10, 3) # 隐藏层到输出层def forward(self, x):out = self.fc1(x)out = self.relu(out)out = self.fc2(out)return out# 实例化模型并移至GPU model = MLP().to(device)# 分类问题使用交叉熵损失函数 criterion = nn.CrossEntropyLoss()# 使用随机梯度下降优化器 optimizer = optim.SGD(model.parameters(), lr=0.01)# 训练模型 num_epochs = 20000 # 训练的轮数# 用于存储每100个epoch的损失值和对应的epoch数 losses = []start_time = time.time() # 记录开始时间for epoch in range(num_epochs):# 前向传播outputs = model(X_train) # 隐式调用forward函数loss = criterion(outputs, y_train)# 反向传播和优化optimizer.zero_grad()loss.backward()optimizer.step()# 记录损失值if (epoch + 1) % 200 == 0:losses.append(loss.item()) # item()方法返回一个Python数值,loss是一个标量张量print(f'Epoch [{epoch+1}/{num_epochs}], Loss: {loss.item():.4f}')# 打印训练信息if (epoch + 1) % 100 == 0: # range是从0开始,所以epoch+1是从当前epoch开始,每100个epoch打印一次print(f'Epoch [{epoch+1}/{num_epochs}], Loss: {loss.item():.4f}')time_all = time.time() - start_time # 计算训练时间 print(f'Training time: {time_all:.2f} seconds')# 可视化损失曲线 plt.plot(range(len(losses)), losses) plt.xlabel('Epoch') plt.ylabel('Loss') plt.title('Training Loss over Epochs') plt.show()
这里我们定义剩余时长 = 总时长-必须的计算时长3s,可以多做几次实验,来对比下记录次数和剩余时长的分布关系,很容易以为这二者是成正比的
下表为我在我的本地电脑上的测试结果,总epoch = 20000
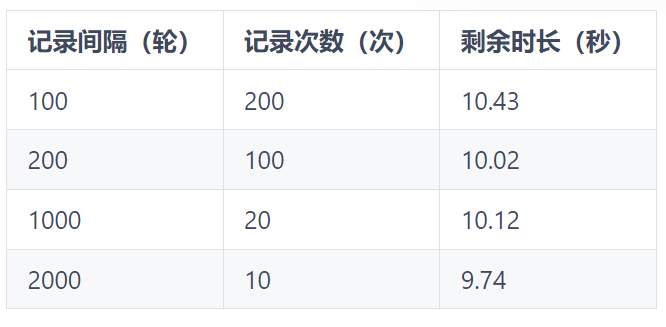
可以发现,记录次数和剩余时长之间并无明显的线性关系。思考下为什么?
我目前的理解是loss.item()是一个同步操作,gou需要等待cpu完成才能开启下次运算。但是仍然无法解释为为什么剩余时长和记录次数之间没有线性关系。
__call__方法
在 Python 中,call 方法是一个特殊的魔术方法(双下划线方法),它允许类的实例像函数一样被调用。这种特性使得对象可以表现得像函数,同时保留对象的内部状态。
# 我们来看下昨天代码中你的定义函数的部分 class MLP(nn.Module): # 定义一个多层感知机(MLP)模型,继承父类nn.Moduledef __init__(self): # 初始化函数super(MLP, self).__init__() # 调用父类的初始化函数# 前三行是八股文,后面的是自定义的self.fc1 = nn.Linear(4, 10) # 输入层到隐藏层self.relu = nn.ReLU()self.fc2 = nn.Linear(10, 3) # 隐藏层到输出层 # 输出层不需要激活函数,因为后面会用到交叉熵函数cross_entropy,交叉熵函数内部有softmax函数,会把输出转化为概率def forward(self, x):out = self.fc1(x)out = self.relu(out)out = self.fc2(out)return out可以注意到,self.fc1 = nn.Linear(4, 10) 此时,是实例化了一个nn.Linear(4, 10)对象,并把这个对象赋值给了MLP的初始化函数中的self.fc1变量。
那为什么下面的前向传播中却可以out = self.fc1(x) 呢?,self.fc1是一个实例化的对象,为什么具备了函数一样的用法,这是因为nn.Linear继承了nn.Module类,nn.Module类中定义了__call__方法。(可以ctrl不断进入来查看)
在 Python 中,任何定义了 call 方法的类,其实例都可以像函数一样被调用。
当调用 self.fc1(x) 时,实际上执行的是:
- self.fc1.call(x)(Python 的隐式调用)
- 而 nn.Module 的 call 方法会调用子类的 forward 方法(即 self.fc1.forward(x))。这个方法就是个前向计算方法。
-
我们来介绍一下call方法是什么
relu是torch.relu()这个函数为了保持写法一致,又封装成了nn.ReLU()这个类。来保证接口的一致性
PyTorch 官方强烈建议使用 self.fc1(x),因为它会触发完整的前向传播流程(包括钩子函数)这是 PyTorch 的核心设计模式,几乎所有组件(如 nn.Conv2d、nn.ReLU、甚至整个模型)都可以这样调用。
# 不带参数的call方法 class Counter:def __init__(self):self.count = 0def __call__(self):self.count += 1return self.count# 使用示例 counter = Counter() print(counter()) # 输出: 1 print(counter()) # 输出: 2 print(counter.count) # 输出: 21 2 2 类名后跟(),表示创建类的实例(对象),仅在第一次创建对象时发生。call方法无参数的情况下,在实例化之后,每次调用实例时触发 call 方法# 带参数的call方法 class Adder:def __call__(self, a, b):print("唱跳篮球rap")return a + badder = Adder() print(adder(3, 5)) # 输出: 8唱跳篮球rap 8@浙大疏锦行