谷歌开源医疗领域AI语言模型速递:medgemma-27b-text-it
一、模型概述
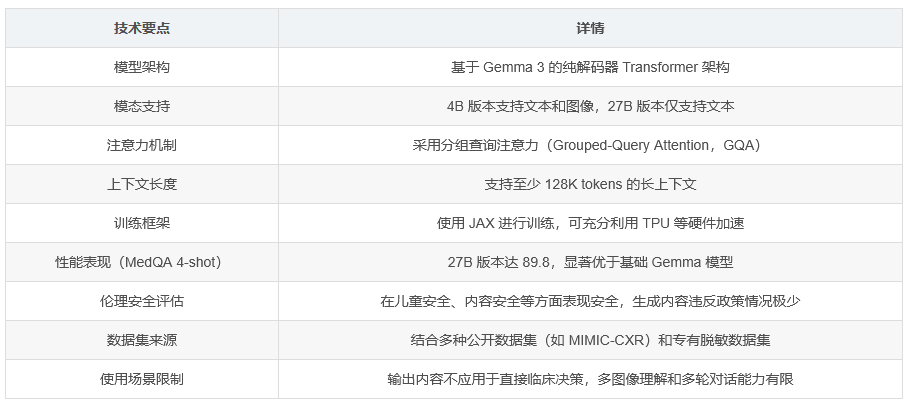
MedGemma 是由谷歌开发的一个医疗领域 AI 模型系列,基于 Gemma 3 架构,旨在加速医疗保健相关 AI 应用的开发。该模型系列包含两个主要变体:4B 多模态版本(支持文本和图像理解)以及 27B 纯文本版本(专为推理计算优化且仅提供指令微调模型)。MedGemma 27B 仅在医学文本上进行训练,适合需要处理医疗文本任务的场景。
二、模型使用方法
文档提供了两种主要的模型调用方式:通过 pipeline API 快速运行模型以及直接加载模型进行更灵活的操作。
(1)通过 pipeline API 调用
需要先安装 transformers 库(版本 4.50.0 及以上),然后使用以下代码:
from transformers import pipeline
import torch
pipe = pipeline("text-generation",model="google/medgemma-27b-text-it",torch_dtype=torch.bfloat16,device="cuda",
)
messages = [{"role": "system","content": "You are a helpful medical assistant."},{"role": "user","content": "How do you differentiate bacterial from viral pneumonia?"}
]
output = pipe(text=messages, max_new_tokens=200)
print(output[0]["generated_text"][-1]["content"])
(2)直接加载模型
除了 pipeline API,还可以直接加载模型和分词器进行更复杂的操作,代码如下:
from transformers import AutoTokenizer, AutoModelForCausalLM
import torch
model_id = "google/medgemma-27b-text-it"
model = AutoModelForCausalLM.from_pretrained(model_id,torch_dtype=torch.bfloat16,device_map="auto",
)
tokenizer = AutoTokenizer.from_pretrained(model_id)
messages = [{"role": "system","content": "You are a helpful medical assistant."},{"role": "user","content": "How do you differentiate bacterial from viral pneumonia?"}
]
inputs = tokenizer.apply_chat_template(messages,add_generation_prompt=True,tokenize=True,return_dict=True,return_tensors="pt",
).to(model.device)
input_len = inputs["input_ids"].shape[-1]
with torch.inference_mode():generation = model.generate(**inputs, max_new_tokens=200, do_sample=False)generation = generation[0][input_len:]
decoded = tokenizer.decode(generation, skip_special_tokens=True)
print(decoded)
三、模型架构与技术规格
MedGemma 基于 Gemma 3 的纯解码器 Transformer 架构,具有以下特点:
-
模态能力:4B 版本支持文本和视觉模态,27B 版本仅支持文本
-
注意力机制:采用分组查询注意力(Grouped-Query Attention,GQA)
-
上下文长度:支持至少 128K tokens 的长上下文
-
训练框架:使用 JAX 进行训练,可充分利用 TPU 等硬件加速
四、性能与验证
MedGemma 在多个医学相关的基准测试中表现出色,以下为部分关键性能指标:
| 指标 | MedGemma 27B | Gemma 27B | MedGemma 4B | Gemma 4B |
|---|---|---|---|---|
| MedQA (4-shot) | 89.8 | 74.9 | 64.4 | 50.7 |
| MedMCQA | 74.2 | 62.6 | 55.7 | 45.4 |
| PubMedQA | 76.8 | 73.4 | 73.4 | 68.4 |
| MMLU Med (text-only) | 87.0 | 83.3 | 70.0 | 67.2 |
| MedXpertQA (text-only) | 26.7 | 15.7 | 14.2 | 11.6 |
| AfriMed-QA | 84.0 | 72.0 | 52.0 | 48.0 |
五、伦理与安全评估
MedGemma 经过了严格的伦理和安全评估,包括儿童安全、内容安全、代表性伤害以及一般医疗风险等方面的测试。测试结果显示,该模型在各个安全类别中均表现出安全水平,且在没有安全过滤的情况下生成的内容违反政策的情况极少。
六、数据集介绍
MedGemma 的训练数据集包含多种公开和专有数据集,涵盖了医学文本和图像等多个领域。主要公开数据集包括:
-
MIMIC-CXR(胸部 X 光片及报告)
-
Slake-VQA(多模态医学图像及问题)
-
PAD-UFES-20(皮肤病变图像及数据)
-
SCIN(皮肤病图像)
-
TCGA(癌症基因组数据)
-
CAMELYON(淋巴结组织病理学图像)
-
PMC-OA(带有图像的生物医学文献)
此外,还使用了多个经过脱敏处理的专有数据集,包括不同部位的 CT 研究、糖尿病视网膜病变筛查的眼底图像、来自不同地区的皮肤状况图像以及多种组织病理学全切片图像等。
七、使用建议与限制
MedGemma 适用于生命科学和医疗保健领域的开发者,作为开发下游医疗应用的起点。然而,该模型存在以下限制:
-
输出内容不应直接用于临床诊断、患者管理决策或治疗建议等临床实践应用
-
多模态能力主要在单图像任务上进行了评估,未测试涉及多图像理解的用例
-
未针对多轮对话应用进行评估或优化
-
对提示词的选择可能比 Gemma 3 更敏感
-
开发者需确保下游应用在具有代表性的数据上进行验证,并注意数据污染问题
MedGemma 核心技术汇总表