西交交互增强与细节引导的具身导航!OIKG:基于观察图交互与关键细节融合框架下的视觉语言导航

-
作者:Yifan Xie, Binkai Ou, Fei Ma, and Yaohua Liu
-
单位:西安交通大学,广东智能科学与技术研究院,BoardWare 信息系统有限公司,广东省人工智能与数字经济(深圳)实验室
-
论文标题:Observation-Graph Interaction and Key-Detail Guidance for Vision and Language Navigation
-
论文链接:https://www.arxiv.org/pdf/2503.11006
主要贡献
-
提出了观察图交互模块(Observation-graph Interaction Module),通过解耦角度信息和视觉信息,并利用几何嵌入增强导航空间中的边表示,从而减少特征干扰并提升空间关系的理解能力。
-
设计了关键细节引导模块(Key-Detail Guidance Module),动态提取指令中的细粒度位置和物体信息,实现更精确的视觉与语言对齐,帮助智能体更好地遵循复杂指令。
-
在 R2R 和 RxR 数据集上的实验表明,OIKG 在多个评估指标上均达到了 最佳性能,验证了其在提升导航精度方面的有效性。
研究背景
视觉与语言导航(VLN)任务要求智能体根据自然语言指令在复杂环境中导航。该任务的核心挑战包括:
-
跨模态对齐:智能体需要将视觉观察与语言指令进行有效结合,但现有方法往往无法很好地整合这两类信息,导致导航性能受限。
-
细粒度信息利用不足:许多方法仅将指令作为一个整体处理,缺乏对指令中细粒度导航线索的提取和利用。
-
路径规划的局限性:现有方法在处理视觉和角度信息时未充分考虑其特性差异,可能导致特征表示的干扰,影响路径规划的准确性。
研究方法
问题定义
-
VLN 任务的目标是让智能体根据自然语言指令导航至目标位置。
-
具体而言,智能体在离散环境中通过路径图(包含节点和边)进行导航,需要处理视觉信息并理解语言指令,最终在固定时间内到达目标位置。
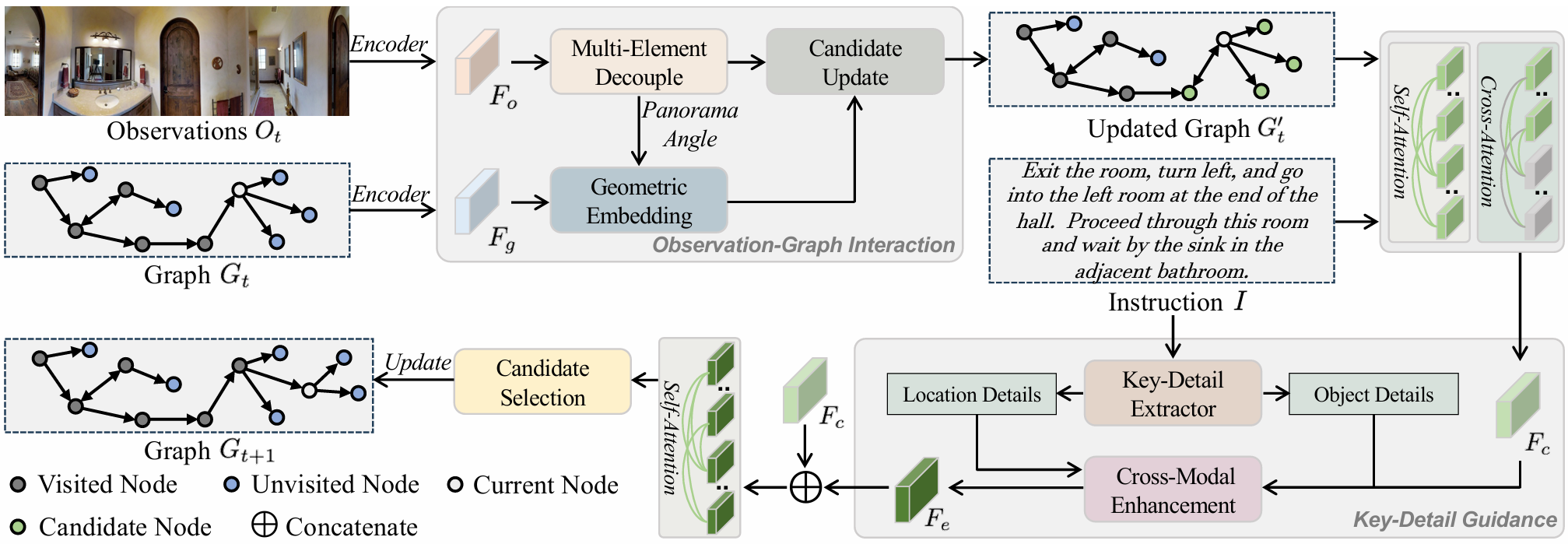
模型架构
OIKG 框架的核心架构包括以下模块:
-
观察特征提取:从全景视图中提取视觉特征。
-
图结构构建:构建有向图结构,记录已访问节点及其连接关系。
-
观察图交互模块:解耦视觉和角度信息,并通过几何嵌入增强图的边表示。
-
关键细节引导模块:动态提取指令中的位置和物体细节,增强视觉与语言的对齐。
-
候选节点选择:基于增强后的特征预测目标节点,并更新图结构。
观察图交互模块
该模块的核心功能是减少视觉和角度信息之间的干扰,并增强图的边表示:
-
特征解耦:将观察特征分解为角度嵌入和视觉嵌入。
-
几何嵌入:利用三角函数计算相对角度的差异,并将其嵌入到图的边表示中。
-
边表示更新:通过 Transformer 解码器更新图的边特征,使智能体能够更好地理解空间关系。
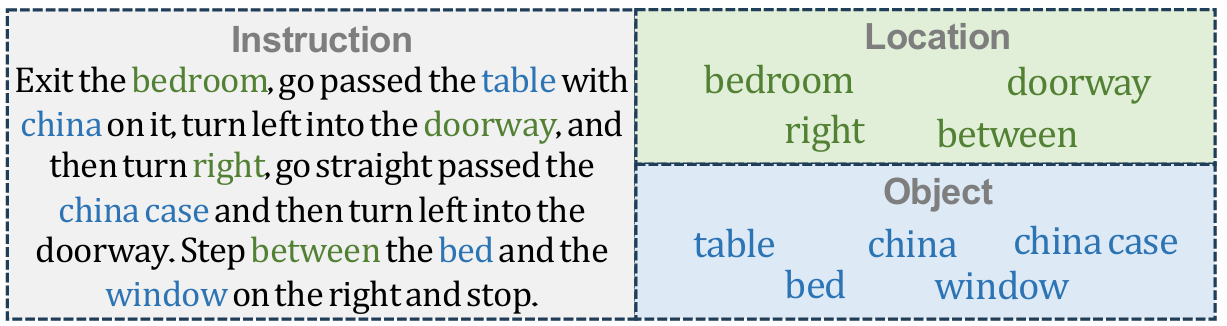
关键细节引导模块
该模块通过动态提取指令中的细粒度信息来增强导航能力:
-
细粒度信息提取:基于预定义的位置和物体词库,从指令中提取相关特征。
-
交叉模态增强:通过交叉注意力机制将视觉特征与细粒度语言特征进行融合,生成增强后的特征。
-
导航决策:基于增强后的特征计算候选节点的对齐分数,选择最优路径。
损失函数
-
预训练阶段:使用掩码语言建模(MLM)作为预训练目标,学习文本与图特征的对齐。
-
微调阶段:结合教师强制和学生强制策略,优化导航路径的准确性。
实验
实施细节
-
框架:基于 PyTorch 实现,使用 NVIDIA A6000 GPU。
-
优化器:AdamW,预训练学习率 2e-5,微调学习率 1e-5。
-
数据集:R2R 和 RxR 数据集,包含多语言和复杂路径的导航任务。
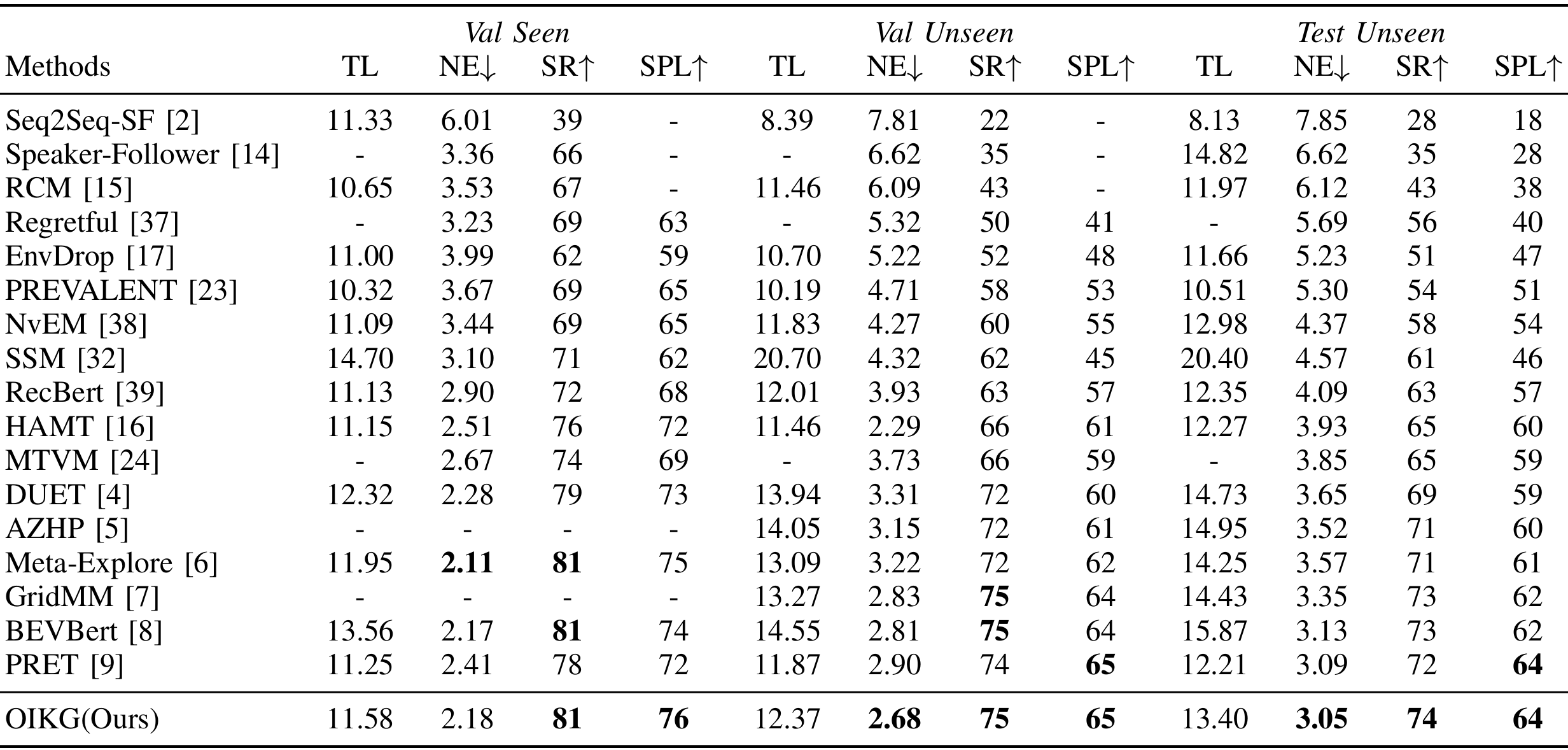
R2R 数据集上的实验
-
数据集特点:包含 10,800 个全景视图和 7,189 条轨迹,路径为最短路径。
-
评估指标:轨迹长度(TL)、导航误差(NE)、成功率(SR)和路径长度加权的成功率(SPL)。
-
实验结果:OIKG 在所有指标上均优于现有方法,特别是在 SPL 指标上表现突出。
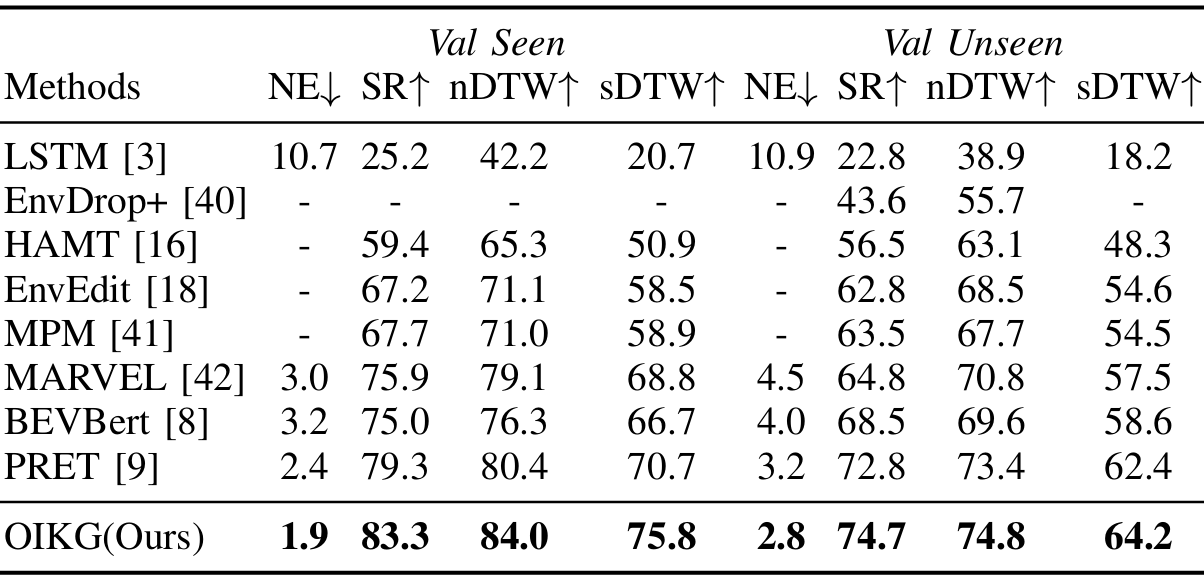
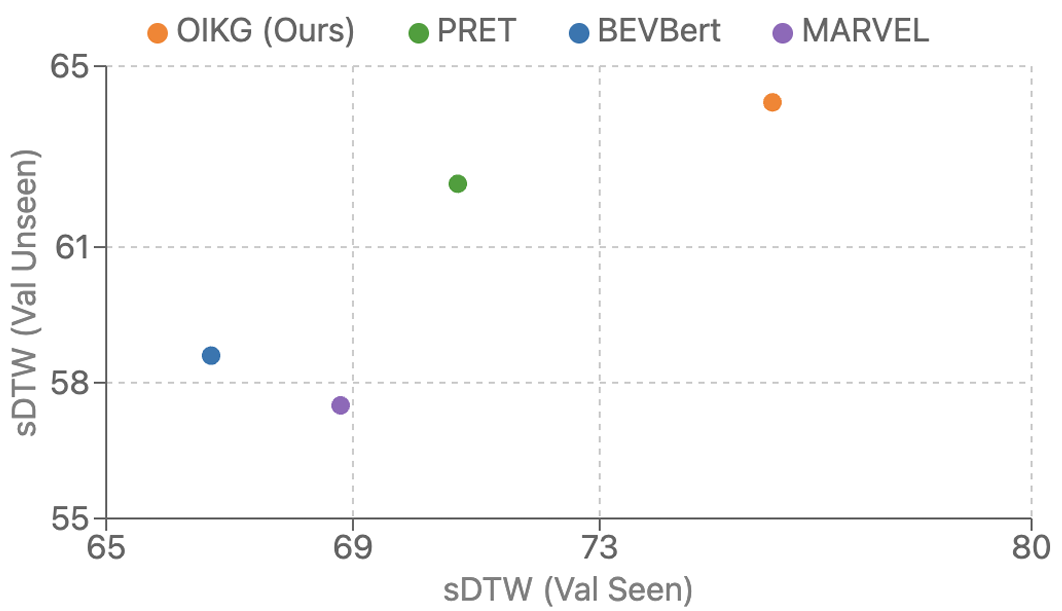
RxR 数据集上的实验
-
数据集特点:包含 126,000 条指令,路径更长且非最短路径,指令更复杂。
-
评估指标:导航误差(NE)、成功率(SR)、归一化动态时间规整(nDTW)和成功率加权动态时间规整(sDTW)。
-
实验结果:OIKG 在所有指标上均达到最佳性能,尤其是在更具挑战性的 RxR 数据集上表现出色。
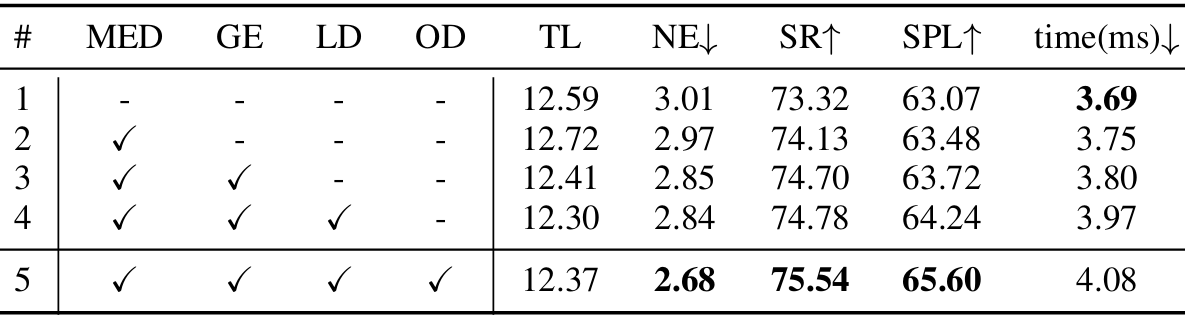
消融研究
-
实验设置:在 R2R 验证未见集合上进行。
-
关键结论:每个模块(如特征解耦、几何嵌入、位置细节和物体细节)均对性能提升有显著贡献,且不会显著增加推理时间。
结论与未来工作
-
结论:
-
OIKG 通过观察图交互和关键细节引导模块,有效解决了现有方法在视觉与语言导航中的不足。
-
实验结果表明,该方法在多个数据集和指标上均优于现有技术,为未来视觉与语言导航任务的研究提供了新的方向。
-
-
未来工作:
-
多模态融合:结合其他模态(如语音、触觉)以增强智能体的感知能力。
-
跨语言导航:扩展到更多语言,提升模型的通用性。
-
复杂环境中的导航:在更具挑战性的环境中验证模型的鲁棒性。
-
