分布式锁(详解)
分布式锁介绍
分布式锁 和 高并发是相违背的,分布式锁就是并行操作 串行化。
分布式锁是什么?
根据百度百科定义,分布式锁是控制分布式系统之间同步访问共享资源的一种方式。使用它的意义在于,当不同系统或同一系统的不同服务器共享相同资源时,能够让它们互斥访问这些资源,以保证资源状态的一致性。
分布式锁主要包括以下几个特点:
- 可重入:当一个进程或者线程获得锁后,该进程或线程在未释放该锁之前,还能再次获得该锁;
- 互斥性:同一时刻,只能有一个客户端获得锁;
- 可释放:不管获得锁的客户端进程或线程是否正常结束,必须保证锁能在有限时间内被释放;
- 高可用、高性能:获取锁、释放锁的过程需保证高可用、高性能,只有这样才能保证分布式锁对系统自身业务影响最小。
如图:
分布式锁在项目中有哪些应用场景:
使用分布式锁的场景一般需要满足以下场景
1、系统是一个分布式系统,集群集群,Java的锁已经锁不住了。
2、操作共享资源,比如库里唯一的用户数据。
3、同步访问,即多个进程同时操作共享资源。
分布式锁场景:
- 互联网秒杀
- 抢优惠券
- 接口幂等性检验
分布式锁实现方式:
- 基于数据库实现
- 基于Zookeeper实现
- 基于Redis实现
其他:
- Chubby:谷歌公司实现的粗粒度分布式锁服务,底层使用了Paxos一致性算法
- Tair:淘宝的分布式Key/Value存储系统,主要是使用Tair的put()方法,原理和Redis类似
- Memcached:利用Memcached的add命令,此命令是原子性操作,只有在key不存在的情况下才能add成功,也就意味着加锁成功
分布式锁的使用场景是什么?
-
单体架构中:多个线程都是属于同一个进程的,所以在线程并发执行时,遇到资源竞争时,可以利用ReentrantLock、synchronized等技术来作为锁,来控制共享资源的使用。
-
分布式架构中:多个线程是可能处于不同进程中的,而这些线程并发执行遇到资源竞争时,利用ReentrantLock、synchronized等技术是没办法来控制多个进程中的线程的,所以需要分布式锁,意思就是,需要一个分布式锁生成器,分布式系统中的应用程序都可以来使用这个生成器所提供的锁,从而达到多个进程中的线程使用同一把锁。
分布锁有哪些解决方案?
1、Zookeeper:利用的是Zookeeper的临时节点、顺序节点、watch机制来实现,zookeeper分布式锁的特点是高一致性,因为zookeeper保证的是CP,所以由它实现的分布式锁更可靠,不会出现混乱。
2、Redis:利用redis的setnx、lua脚本、消费订阅等机制来实现的,redis分布式锁的特点是高可用,因为redis保证的是AP,所以由它实现的分布式锁可能不可靠 不稳定,可能会出现多个客户端同时加到锁的情况。很多大公司会基于Redis做扩展开发。setnx key value ex 10s,Redisson。watch dog.
3、基于数据库,比如Mysql。主键或唯一索引的唯一性。
我们需要怎么样的分布式锁?
- 可以保证在分布式部署的应用集群中,同一个方法在同一时间只能被一台机器上的一个线程执行。
- 这把锁要是一把可重入锁(避免死锁)
- 这把锁最好是一把阻塞锁(根据业务需求考虑要不要这条)
- 这把锁最好是一把公平锁(根据业务需求考虑要不要这条)
- 有高可用的获取锁和释放锁功能
- 获取锁和释放锁的性能要好
三种方案比较:
分布式锁的三种实现方式
目前几乎很多大型网站及应用都是分布式部署的,分布式场景中的数据一致性问题一直是一个比较重要的话题。分布式的CAP理论告诉我们“任何一个分布式系统都无法同时满足一致性(Consistency)、可用性(Availability)和分区容错性(Partition tolerance),最多只能同时满足两项。”所以,很多系统在设计之初就要对这三者做出取舍。
在互联网领域的绝大多数的场景中,都需要牺牲强一致性来换取系统的高可用性,系统往往只需要保证“最终一致性”,只要这个最终时间是在用户可以接受的范围内即可。
在很多场景中,我们为了保证数据的最终一致性,需要很多的技术方案来支持,比如分布式事务、分布式锁等。有的时候,我们需要保证一个方法在同一时间内只能被同一个线程执行。
- 基于数据库实现分布式锁;
- 基于缓存(Redis等)实现分布式锁;
- 基于Zookeeper实现分布式锁;
上面几种方式,哪种方式都无法做到完美。就像CAP一样,在复杂性、可靠性、性能等方面无法同时满足,所以,根据不同的应用场景选择最适合自己的才是王道。
从理解的难易程度角度(从低到高)
数据库 > 缓存 > Zookeeper
从实现的复杂性角度(从低到高)
Zookeeper >= 缓存 > 数据库
从性能角度(从高到低)
缓存 > Zookeeper >= 数据库
从可靠性角度(从高到低)
Zookeeper > 缓存 > 数据库
Zookeeper和Redis做分布式锁的区别:
Redis:
1、Redis只保证最终一致性,副本间的数据复制是异步进行(Set是写,Get是读,Redis集群一般是读写分离架构,存在主从同步延迟情况),主从切换之后可能有部分数据没有复制过去可能会【丢失锁】情况,故强一致性要求的业务不推荐使用Redis,推荐使用zk。
2、Redis集群各方法的响应时间均为最低。随着并发量和业务数量的提升其响应时间会有明显上升,但是极限qps可以达到最大且基本无异常。
Zookeeper:
1、使用Zookeeper集群,锁原理是使用Zookeeper的临时顺序节点,临时顺序节点的生命周期在Client与集群的Session结束时结束。因此如果某个Client节点存在网络问题,与Zookeeper集群断开连接,Session超时同样会导致锁被错误的释放(导致被其他线程错误地持有),因此Zookeeper也无法保证完全一致。
2、ZK具有较好的稳定性;响应时间小。但是随着并发量和业务数量的提升其响应时间和qps会明显下降。
总结:
1、Zookeeper每次进行锁操作前都要创建若干节点,完成后要释放节点,会浪费很多时间;zookeeper的支持的并发量有限。
2、而Redis只是简单的数据操作,没有这个问题。Redis支持的并发量大。
分布式锁面试题:
1.为什么需要分布式锁?
public synchronized void test() {System.out.println("获取到锁");
}
public void test2() {synchronized (Test.class) {System.out.println("获取到锁");}
}
假设我们把上述代码部署到多台服务器上,这个互斥锁还能生效吗?答案是否定的,这时分布式锁应运而生。
2.Redis分布式锁?
接下来我给大家讲解完整的演变过程,让大家更深刻的理解分布式锁。

Redis setnx
线程1申请加锁,这时没有人持有锁,加锁成功:
127.0.0.1:6379> setnx lock 1
(integer) 1
线程2申请加锁,此时发现有人持有锁未释放,加锁失败:
127.0.0.1:6379> setnx lock 1
(integer) 0
线程1执行完成业务逻辑后,执行DEL命令释放锁:
127.0.0.1:6379> del lock
(integer) 1
存在问题:
①假设线程1执行到一半,系统挂了,这时锁还没释放,就会造成死锁。
②如果Redis加锁后,Master还没同步给Slave就挂了,会导致有两个客户端获取到锁
解决方案:setnx expire
Redis setnx expire
为了解决上述死锁问题,我们在setnx后,给这个key加上失效时间。
此时线程1加锁的代码改成:
127.0.0.1:6379> setnx lock 1 ## 加锁
(integer) 1
127.0.0.1:6379> expire lock 3 ## 设置 key 3秒失效
(integer) 1
存在问题:
①假设setnx lock 1执行成功了,但是expire lock 3执行失败了,还是会存在死锁问题,这两个命令需要保证原子性。
②失效时间是我们写死的,不能自动续约,如果业务执行时间超过失效时间,会出现线程1还在执行,线程2就加锁成功了,并有没达到互斥效果。
③如果Redis加锁后,Master还没同步给Slave就挂了,会导致有两个客户端获取到锁
解决方案:RedissonLock
RedissonLock
上述两个问题,RedissonLock都解决了,我通过源码给大家剖析,看RedissonLock是如何解决的,基础好的小伙伴可以好好读读源码,其实RedissonLock源码也不难。
我先写结论,基础较弱的小伙伴,只要记得结论就行:

①RedisssonLock底层使用的是lua脚本执行的redis指令,lua脚本可以保证加锁和失效指令的原子性。
②RedisssonLock底层有个看门狗机制,加锁成功后,会开启一个定时调度任务,每隔10秒去检查锁是否释放,如果没有释放,把失效时间刷新成30秒。这样锁就可以一直续期,不会释放。
我看的是3.12.5版本源码,不同版本实现上可能存在一些差异。
应用程序加锁代码:
RLock lock = redissonLock.getLock("anyLock");
lock.lock();
RedissonLock加锁核心代码:

RedissonLock获取锁核心代码:

底层加锁逻辑:

KEYS[1] = anyLock,锁的名称。
ARGV[1] = 30000,失效时间,通过lockWatchdogTimeout配置。
ARGV[2] = c1b51ddb-1505-436c-a308-b3b75b4bd407:1,他是ConnectionManager的ID,我们可以简单的把它理解为一个客户端的一个线程对应的唯一标志性。
RedissonLock解锁核心代码:

存在问题:如果redis是单节点,存在单节点故障问题;如果做主从架构,Redis加锁后,Master还没同步给Slave就挂了,会导致有两个客户端获取到锁
有小伙伴问我,如果这里我用集群会存在这个问题吗?集群的本质是分片,这个key最终还是会落到某个具体的节点,这个节点要么是单独存在,要么是主从架构,所以还是会存在上述问题。
解决方案:RedLock
补充:虽然RedLock可以解决上述问题,但是在生产环境中我们很少使用,因为它部署成本很高,相比RedissonLock性能也略微有所下降。
如果业务能接受极端情况下存在互斥失败问题,并且对性能要求比较高,我们会选择RedissonLock,并做好响应的兜底方案。
如果业务对数据要求绝对正确,我们会采用Zookeeper来做分布式锁。
Redlock
我们假设有5个完全相互独立的Redis Master单机节点,所以我们需要在5台机器上面运行这些实例,如下图所示(请注意这张图中5个Master节点完全相互独立)
为了取到锁,客户端应该执行以下操作:

①获取当前Unix时间,以毫秒为单位。
②依次尝试从N个Master实例使用相同的key和随机值获取锁(假设这个key是LOCK_KEY)。当向Redis设置锁时,客户端应该设置一个网络连接和响应超时时间,这个超时时间应该小于锁的失效时间。例如你的锁自动失效时间为10秒,则超时时间应该在5-50毫秒之间。这样可以避免服务器端Redis已经挂掉的情况下,客户端还在死死地等待响应结果。如果服务器端没有在规定时间内响应,客户端应该尽快尝试另外一个Redis实例。
③客户端使用当前时间减去开始获取锁时间(步骤1记录的时间)就得到获取锁使用的时间。当且仅当从大多数的Redis节点都取到锁,并且使用的时间小于锁失效时间时,锁才算获取成功。
④如果取到了锁,key的真正有效时间等于有效时间减去获取锁所使用的时间(步骤3计算的结果)。
⑤如果因为某些原因,获取锁失败(没有在至少N/2+1个Redis实例取到锁或者取锁时间已经超过了有效时间),客户端应该在所有的Redis实例上进行解锁(即便某些Redis实例根本就没有加锁成功)。
缺点:像我们系统,并发量比较大,生产环境必须要做分片才能扛住并发,像上述方案,我们需要准备5个Redis集群,这种机器成本是非常高的。
3.Zookeeper分布式锁

如果有一把锁,被多个人给竞争,此时多个人会排队,第一个拿到锁的人会执行,然后释放锁,后面的每个人都会去监听排在自己前面的那个人创建的node上,一旦某个人释放了锁,排在自己后面的人就会被zookeeper给通知,一旦被通知了之后,就ok了,自己就获取到了锁,就可以执行代码了。
为了帮助大家理解,我暂时不用框架,通过手写代码带大家理解Zookeeper锁:


此时有小伙伴问,如果业务执行一半,系统宕机了怎么办?
zk创建的是临时节点,客户端获取到锁执行业务,执行到一半突然挂掉(Session连接断开),那么这个临时节点就会自动删除掉,其他客户端自动获取锁,不会存在死锁问题。
一般生产环境我们都会使用Curator来完成分布式锁编码,他提供了可重入锁、非可重入锁、Semaphore、可重入读写锁、MultiLock等各种分布式锁。
说说分布式锁吧?
对于一个单机的系统,我们可以通过synchronized或者ReentrantLock等这些常规的加锁方式来实现,然而对于一个分布式集群的系统而言,单纯的本地锁已经无法解决问题,所以就需要用到分布式锁了,通常我们都会引入三方组件或者服务来解决这个问题,比如数据库、Redis、Zookeeper等。
通常来说,分布式锁要保证互斥性、不死锁、可重入等特点。
互斥性指的是对于同一个资源,任意时刻,都只有一个客户端能持有锁。
不死锁指的是必须要有锁超时这种机制,保证在出现问题的时候释放锁,不会出现死锁的问题。
可重入指的是对于同一个线程,可以多次重复加锁。
那你分别说说使用数据库、Redis和Zookeeper的实现原理?
数据库的话可以使用乐观锁或者悲观锁的实现方式。
乐观锁通常就是数据库中我们会有一个版本号,更新数据的时候通过版本号来更新,这样的话效率会比较高,悲观锁则是通过for update的方式,但是会带来很多问题,因为他是一个行级锁,高并发的情况下可能会导致死锁、客户端连接超时等问题,一般不推荐使用这种方式。
Redis是通过set命令来实现,在2.6.2版本之前,实现方式可能是这样:

setNX命令代表当key不存在时返回成功,否则返回失败。
但是这种实现方式把加锁和设置过期时间的步骤分成两步,他们并不是原子操作,如果加锁成功之后程序崩溃、服务宕机等异常情况,导致没有设置过期时间,那么就会导致死锁的问题,其他线程永远都无法获取这个锁。
之后的版本中,Redis提供了原生的set命令,相当于两命令合二为一,不存在原子性的问题,当然也可以通过lua脚本来解决。
set命令如下格式:

key 为分布式锁的key
value 为分布式锁的值,一般为不同的客户端设置不同的值
NX 代表如果要设置的key已存在,则取消设置
EX 代表过期时间为秒,PX则为毫秒,比如上面示例中为10秒过期
Zookeeper是通过创建临时顺序节点的方式来实现。
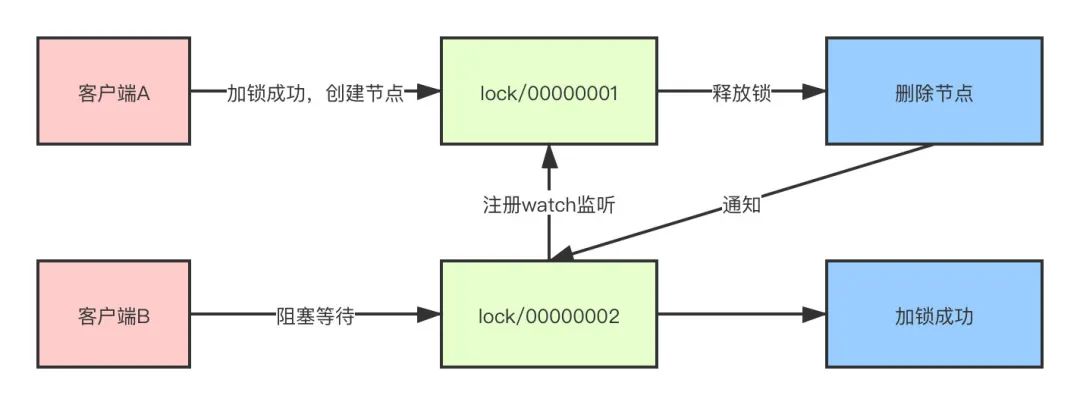
- 当需要对资源进行加锁时,实际上就是在父节点之下创建一个临时顺序节点。
- 客户端A来对资源加锁,首先判断当前创建的节点是否为最小节点,如果是,那么加锁成功,后续加锁线程阻塞等待
- 此时,客户端B也来尝试加锁,由于客户端A已经加锁成功,所以客户端B发现自己的节点并不是最小节点,就会去取到上一个节点,并且对上一节点注册监听
- 当客户端A操作完成,释放锁的操作就是删除这个节点,这样就可以触发监听事件,客户端B就会得到通知,同样,客户端B判断自己是否为最小节点,如果是,那么则加锁成功
你说改为set命令之后就解决了问题?那么还会不会有其他的问题呢?
虽然set解决了原子性的问题,但是还是会存在两个问题。
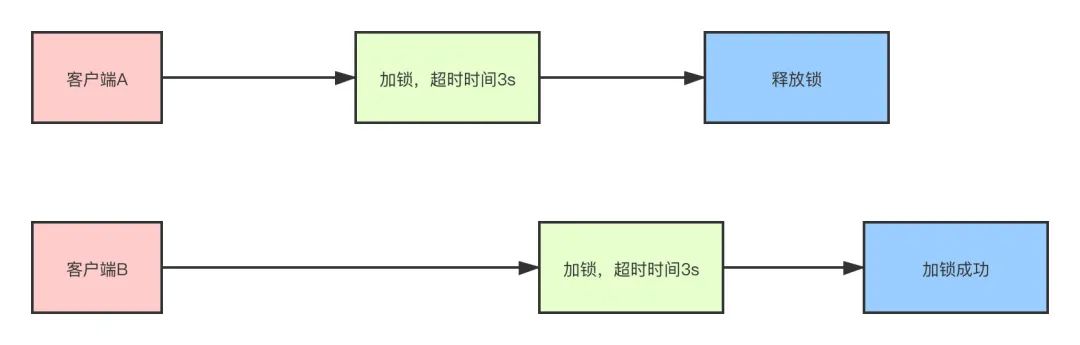
锁超时问题
比如客户端A加锁同时设置超时时间是3秒,结果3s之后程序逻辑还没有执行完成,锁已经释放。客户端B此时也来尝试加锁,那么客户端B也会加锁成功。
这样的话,就导致了并发的问题,如果代码幂等性没有处理好,就会导致问题产生。
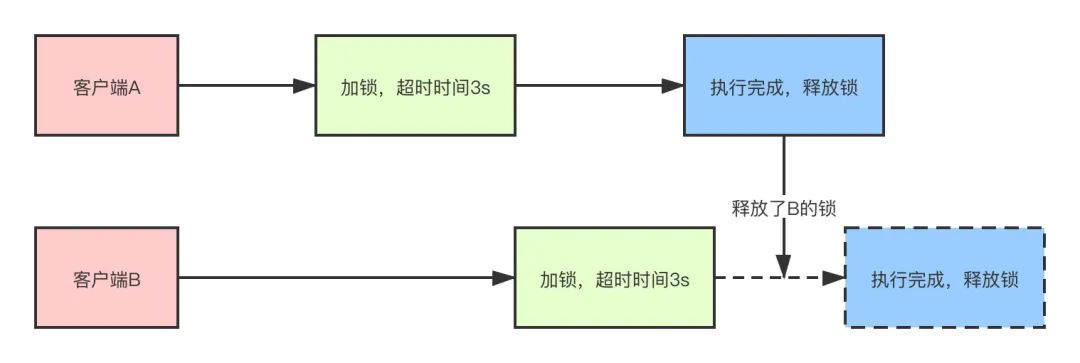
锁误删除
还是类似的问题,客户端A加锁同时设置超时时间3秒,结果3s之后程序逻辑还没有执行完成,锁已经释放。客户端B此时也来尝试加锁,这时客户端A代码执行完成,执行释放锁,结果释放了客户端B的锁。
那上面两个问题你有什么好的解决方案吗?
锁超时
这个有两个解决方案。
- 针对锁超时的问题,我们可以根据平时业务执行时间做大致的评估,然后根据评估的时间设置一个较为合理的超时时间,这样能一大部分程度上避免问题。
- 自动续租,通过其他的线程为将要过期的锁延长持有时间
锁误删除
每个客户端的锁只能自己解锁,一般我们可以在使用set命令的时候生成随机的value,解锁使用lua脚本判断当前锁是否自己持有的,是自己的锁才能释放。
#加锁
SET key random_value NX EX 10
#解锁
if redis.call("get",KEYS[1]) == ARGV[1] thenreturn redis.call("del",KEYS[1])
elsereturn 0
end
了解RedLock算法吗?
因为在Redis的主从架构下,主从同步是异步的,如果在Master节点加锁成功后,指令还没有同步到Slave节点,此时Master挂掉,Slave被提升为Master,新的Master上并没有锁的数据,其他的客户端仍然可以加锁成功。
对于这种问题,Redis作者提出了RedLock红锁的概念。
RedLock的理念下需要至少2个Master节点,多个Master节点之间完全互相独立,彼此之间不存在主从同步和数据复制。
主要步骤如下:
- 获取当前Unix时间
- 按照顺序依次尝试从多个节点锁,如果获取锁的时间小于超时时间,并且超过半数的节点获取成功,那么加锁成功。这样做的目的就是为了避免某些节点已经宕机的情况下,客户端还在一直等待响应结果。举个例子,假设现在有5个节点,过期时间=100ms,第一个节点获取锁花费10ms,第二个节点花费20ms,第三个节点花费30ms,那么最后锁的过期时间就是100-(10+20+30),这样就是加锁成功,反之如果最后时间<0,那么加锁失败
- 如果加锁失败,那么要释放所有节点上的锁
那么RedLock有什么问题吗?
其实RedLock存在不少问题,所以现在其实一般不推荐使用这种方式,而是推荐使用Redission的方案,他的问题主要如下几点。
性能、资源
因为需要对多个节点分别加锁和解锁,而一般分布式锁的应用场景都是在高并发的情况下,所以耗时较长,对性能有一定的影响。此外因为需要多个节点,使用的资源也比较多,简单来说就是费钱。
节点崩溃重启
比如有1~5号五个节点,并且没有开启持久化,客户端A在1,2,3号节点加锁成功,此时3号节点崩溃宕机后发生重启,就丢失了加锁信息,客户端B在3,4,5号节点加锁成功。
那么,两个客户端A\B同时获取到了同一个锁,问题产生了,怎么解决?
- Redis作者建议的方式就是延时重启,比如3号节点宕机之后不要立刻重启,而是等待一段时间后再重启,这个时间必须大于锁的有效时间,也就是锁失效后再重启,这种人为干预的措施真正实施起来就比较困难了
- 第二个方案那么就是开启持久化,但是这样对性能又造成了影响。比如如果开启AOF默认每秒一次刷盘,那么最多丢失一秒的数据,如果想完全不丢失的话就对性能造成较大的影响。
GC、网络延迟
对于RedLock,Martin Kleppmann提出了很多质疑,我就只举这样一个GC或者网络导致的例子。(这个问题比较多,我就不一一举例了,心里有一个概念就行了,文章地址:https://martin.kleppmann.com/2016/02/08/how-to-do-distributed-locking.html)
从图中我们可以看出,client1线获取到锁,然后发生GC停顿,超过了锁的有效时间导致锁被释放,然后锁被client2拿到,然后两个客户端同时拿到锁在写数据,问题产生。
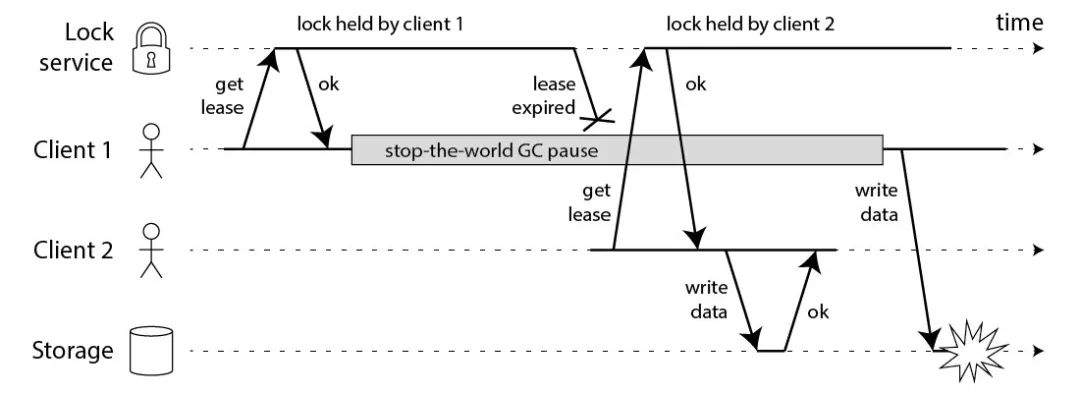
图片来自Martin Kleppmann
时钟跳跃
同样的例子,假设发生网络分区,4、5号节点变为一个独立的子网,3号节点发生始终跳跃(不管人为操作还是同步导致)导致锁过期,这时候另外的客户端就可以从3、4、5号节点加锁成功,问题又发生了。
那你说说有什么好的解决方案吗?
上面也提到了,其实比较好的方式是使用Redission,它是一个开源的Java版本的Redis客户端,无论单机、哨兵、集群环境都能支持,另外还很好地解决了锁超时、公平非公平锁、可重入等问题,也实现了RedLock,同时也是官方推荐的客户端版本。
那么Redission实现原理呢?
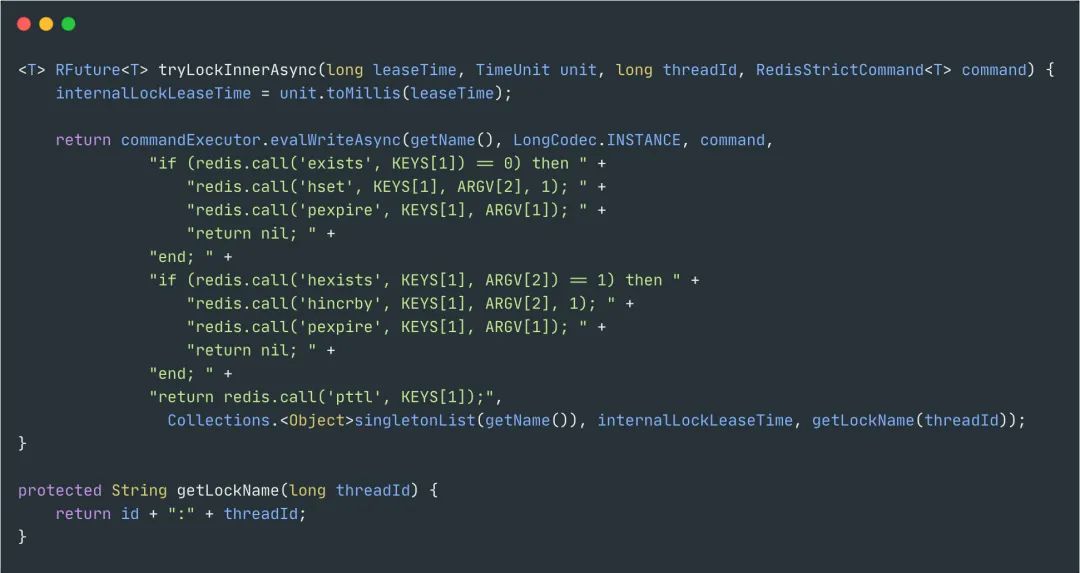
加锁、可重入
首先,加锁和解锁都是通过lua脚本去实现的,这样做的好处是为了兼容老版本的redis同时保证原子性。
KEYS[1]为锁的key,ARGV[2]为锁的value,格式为uuid+线程ID,ARGV[1]为过期时间。
主要的加锁逻辑也比较容易看懂,如果key不存在,通过hash的方式保存,同时设置过期时间,反之如果存在就是+1。
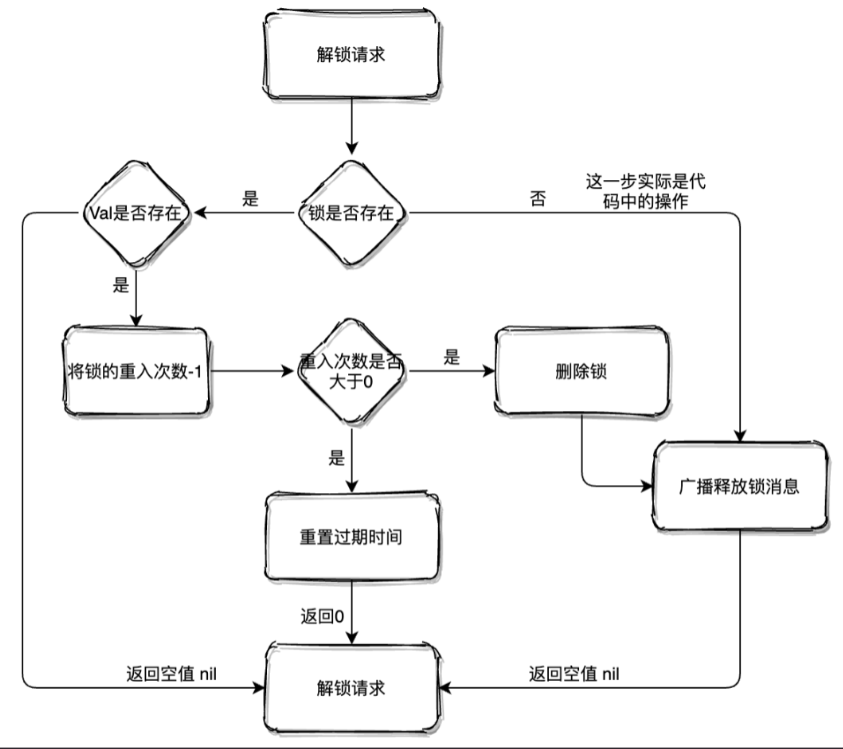
对应的就是hincrby', KEYS[1], ARGV[2], 1这段命令,对hash结构的锁重入次数+1。
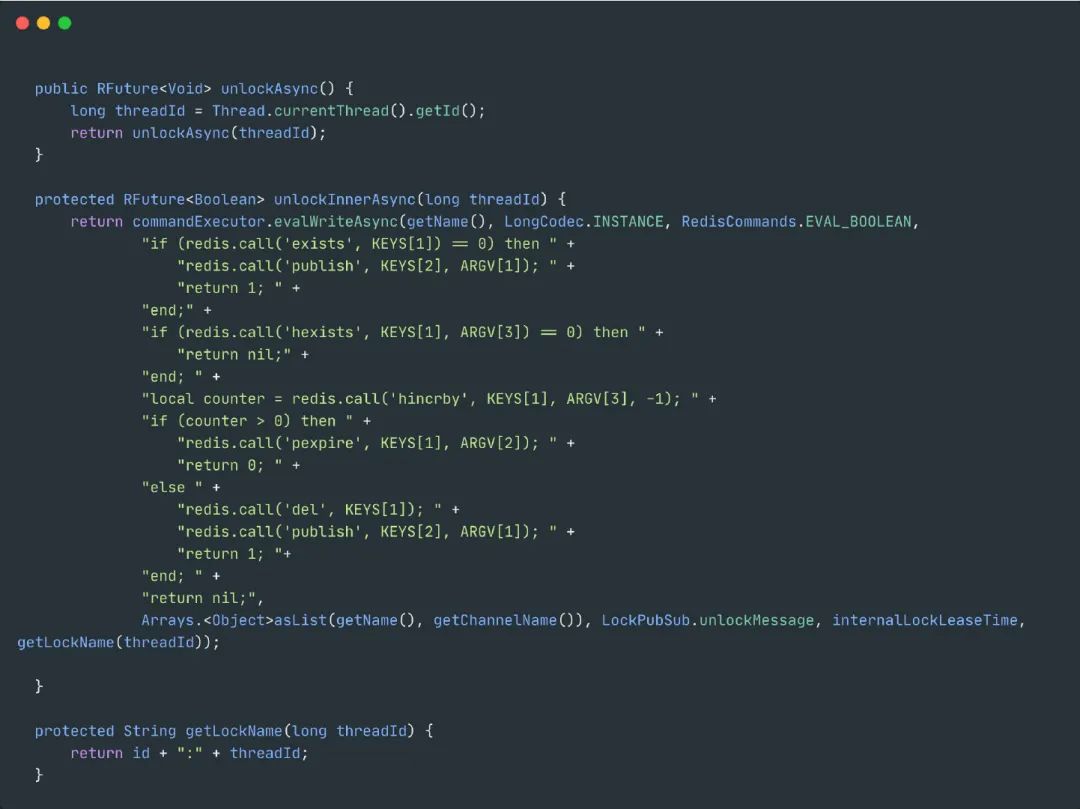
解锁
- 如果key都不存在了,那么就直接返回
- 如果key、field不匹配,那么说明不是自己的锁,不能释放,返回空
- 释放锁,重入次数-1,如果还大于0那么久刷新过期时间,反之那么久删除锁
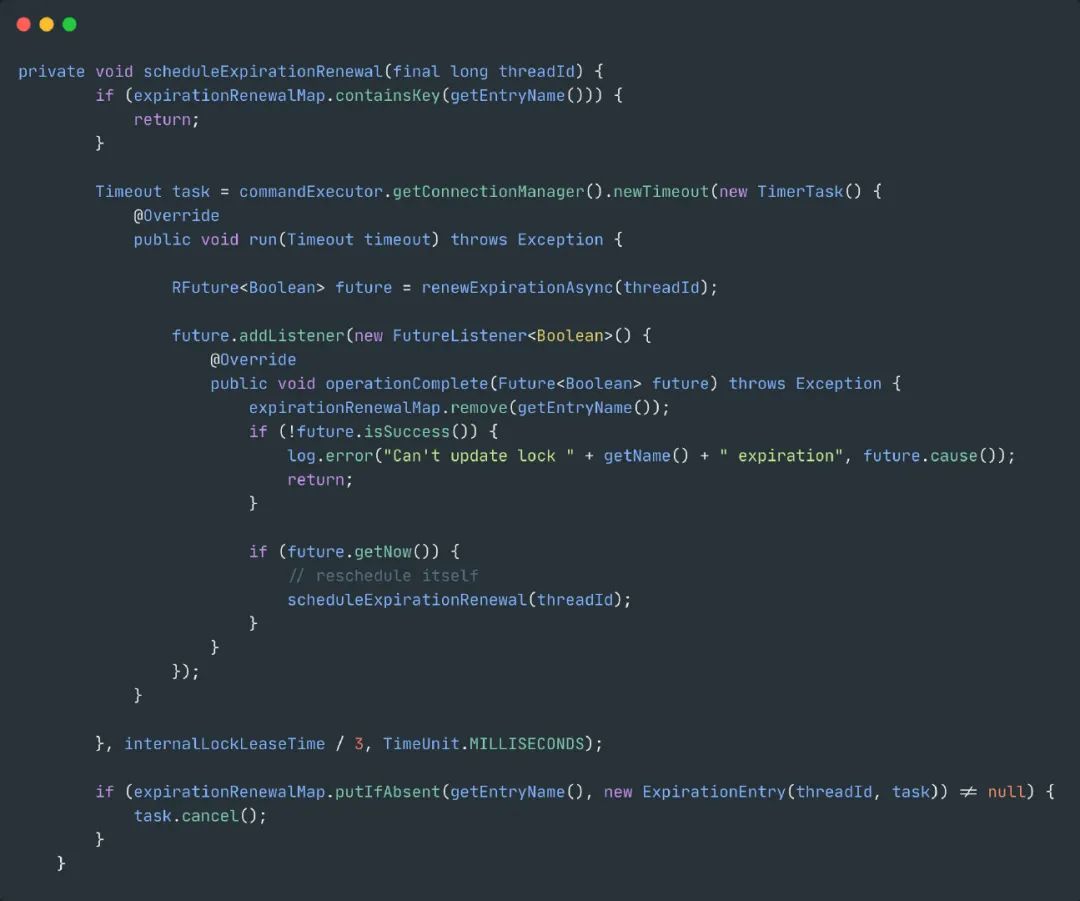
watchdog
也叫做看门狗,也就是解决了锁超时导致的问题,实际上就是一个后台线程,默认每隔10秒自动延长锁的过期时间。
默认的时间就是internalLockLeaseTime / 3,internalLockLeaseTime默认为30秒。
最后,实际生产中对于不同的场景该如何选择?
首先,如果对于并发不高并且比较简单的场景,通过数据库乐观锁或者唯一主键的形式就能解决大部分的问题。
然后,对于Redis实现的分布式锁来说性能高,自己去实现的话比较麻烦,要解决锁续租、lua脚本、可重入等一系列复杂的问题。
对于单机模式而言,存在单点问题。
对于主从架构或者哨兵模式,故障转移会发生锁丢失的问题,因此产生了红锁,但是红锁的问题也比较多,并不推荐使用,推荐的使用方式是用Redission。
但是,不管选择哪种方式,本身对于Redis来说不是强一致性的,某些极端场景下还是可能会存在问题。
对于Zookeeper的实现方式而言,本身就是保证数据一致性的,可靠性更高,所以不存在Redis的各种故障转移带来的问题,自己实现也比较简单,但是性能相比Redis稍差。
不过,实际中我们当然是有啥用啥,老板说用什么就用什么,我才不管那么多。
首先想想为什么要有分布式锁?
保证一个方法在高并发情况下的同一时间只能被同一个线程执行。
锁的用途?
(1)允许多个客户端操作共享资源
这种情况下,对共享资源的操作一定是幂等性操作,无论你操作多少次都不会出现不同结果。在这里使用锁,无外乎就是为了避免重复操作共享资源从而提高效率。
(2)只允许一个客户端操作共享资源
这种情况下,对共享资源的操作一般是非幂等性操作。在这种情况下,如果出现多个客户端操作共享资源,就可能意味着数据不一致,数据丢失。
redis的分布式锁如何实现?
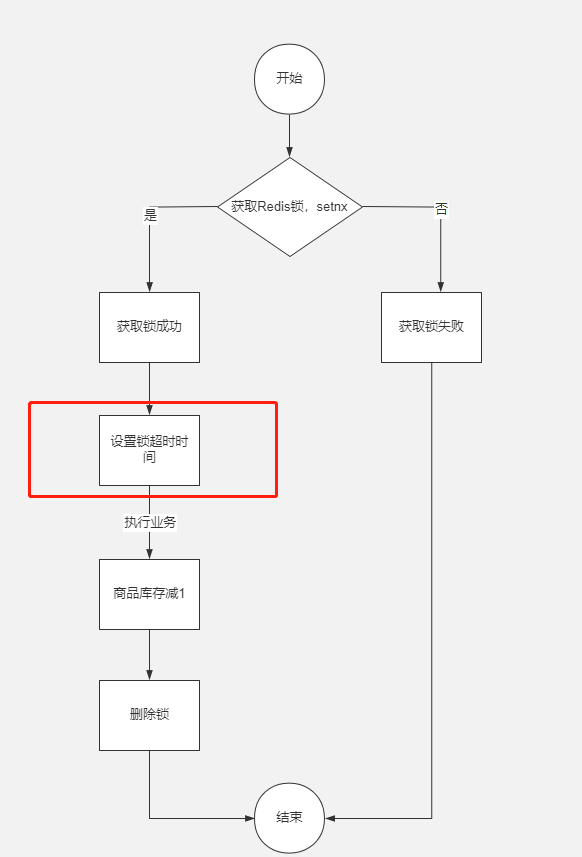
正常情况下redis使用setnx lock加锁,使用del lock释放锁就可以了。但是如果还没释放锁,服务中途就挂了,这样锁得不到释放造成死锁。可以加上超时时间,等服务启了在释放锁。
因为setnx和expire指令不是原子性,redis在2.8以后加入set扩展命令,使得这两个命令能一起执行。
问题一:分布式锁不能解决超时问题
如果在加锁或者释放锁的期间,业务逻辑太长了导致超时时间过了业务还没执行完,第二个线程重新持有锁 就造成业务的得不到严格执行。这时候需要lua脚本执行。确保原子性。
问题二:可重入锁
redis使用redission插件,首先客户端会发lua脚本个redis查找是否有同名锁,没有就加锁。有就等待该线程释放锁。锁一旦加上会启动一个watch dog,这是一个后台线程,每过十秒检查是否持有锁,如果还持有就会延长key的生存时间。
如果reids主节点宕机了,那么系统会自动切换到slave节点上。但是主从在切换过程中,主从复制是异步的操作,就导致锁丧失了安全性,可能导致第二个线程占有原先的锁。
问题三:主节点宕机,锁安全得不到保障
也是使用redission,其中有一个redlock红锁。Redlock的算法大致是这样。假设有N个主节点。在此我们假设N为5。这些节点相互独立,互不影响。在不同服务器上运行实例。保证不会同时宕机。
客户端应该执行以下操作:
- 获取当前时间,精准到毫秒
- 使用相同的key和value依次请求5个redis获取锁。这时候客户端应该建立请求响应时间和超时时间。超时时间应该小于锁的失效时间。这样可以避免如果是redis挂了,客户端就没必要等待,继续去下一个redis获取锁。
- 只有获取超过半数redis的锁并且获取锁的时间小于锁的失效时间才算获取成功。
- 如果获取锁失败 应该释放全部的锁
问题四:加锁失败怎么处理
- 抛出异常,通知用户稍后重试
- Sleep 一会重试
- 将请求转移到延时队列。稍后重试
Mysql分布式锁:
思路:在mysql中插入一条记录,表明获取锁。删除一条记录,表明释放锁。 且在mysql表中设置一个unique key字段, 当有一台机器获得锁后, 其他机器无法获取。
有几个问题:
-
如果一台机器获得锁,在释放锁之前进程挂了, 那么其他机器无法获取到锁。 可以引入锁有效时间的概念,超时后,删除记录,释放锁(必须做到可删除), 同时产生告警。
-
万一获取锁的操作失败了,就直接做错误处理, 也不太好。 可以引入循环重试的方式来解决,控制重试次数。
MySQL如何做分布式锁:
在MySQL中创建一张表,设置一个主键或者UNIQUE KEY 这个 KEY就是要锁的KEY(商品ID),所以同一个KEY在mysql表里只能插入一次了,这样对锁的竞争就交给了数据库,处理同一个KEY 数据库保证了只有一个节点能插入成功,其他节点都会插入失败。
DB分布式锁的实现:通过主键ID 或者 唯一索性 的唯一性进行加锁,说白了就是加锁的形式是向一张表中插入一条数据,该条数据的id就是一把分布式锁,例如当一次请求插入了一条id为1的数据,其他想要进行插入数据的并发请求必须等第一次请求执行完成后删除这条id为1的数据才能继续插入,实现了分布式锁的功能。
分布式锁:排他锁
方案1:
表结构
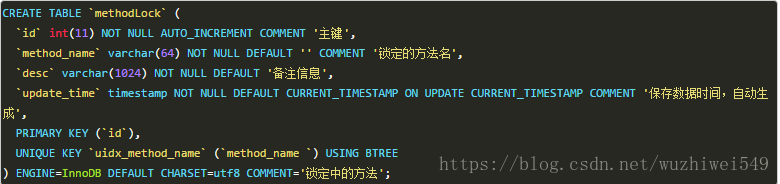
获取锁
INSERT INTO method_lock (method_name, desc) VALUES ('methodName', 'methodName');
对method_name做了唯一性约束,这里如果有多个请求同时提交到数据库的话,数据库会保证只有一个操作可以成功。
方案2:
表结构
DROP TABLE IF EXISTS `method_lock`;
CREATE TABLE `method_lock` (`id` int(11) unsigned NOT NULL AUTO_INCREMENT COMMENT '主键',`method_name` varchar(64) NOT NULL COMMENT '锁定的方法名',`state` tinyint NOT NULL COMMENT '1:未分配;2:已分配',`update_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP,`version` int NOT NULL COMMENT '版本号',`PRIMARY KEY (`id`),UNIQUE KEY `uidx_method_name` (`method_name`) USING BTREE
) ENGINE=InnoDB AUTO_INCREMENT=3 DEFAULT CHARSET=utf8 COMMENT='锁定中的方法';
先获取锁的信息
select id, method_name, state,version from method_lock where state=1 and method_name='methodName';
占有锁
update t_resoure set state=2, version=2, update_time=now() where method_name='methodName' and state=1 and version=2;
如果没有更新影响到一行数据,则说明这个资源已经被别人占位了。
缺点:
1、这把锁强依赖数据库的可用性,数据库是一个单点,一旦数据库挂掉,会导致业务系统不可用。
2、这把锁没有失效时间,一旦解锁操作失败,就会导致锁记录一直在数据库中,其他线程无法再获得到锁。
3、这把锁只能是非阻塞的,因为数据的insert操作,一旦插入失败就会直接报错。没有获得锁的线程并不会进入排队队列,要想再次获得锁就要再次触发获得锁操作。
4、这把锁是非重入的,同一个线程在没有释放锁之前无法再次获得该锁。因为数据中数据已经存在了。
解决方案:
1、数据库是单点?搞两个数据库,数据之前双向同步。一旦挂掉快速切换到备库上。
2、没有失效时间?只要做一个定时任务,每隔一定时间把数据库中的超时数据清理一遍。
3、非阻塞的?搞一个while循环,直到insert成功再返回成功。
4、非重入的?在数据库表中加个字段,记录当前获得锁的机器的主机信息和线程信息,那么下次再获取锁的时候先查询数据库,如果当前机器的主机信息和线程信息在数据库可以查到的话,直接把锁分配给他就可以了。
分布式锁:悲观锁乐观锁
主要有两种方式:
- 悲观锁
- 乐观锁
A. 悲观锁(排他锁)
利用select … where xx=yy for update排他锁
注意:这里需要注意的是 where xx=yy,xx 字段必须要走索引,否则会锁表。有些情况下,比如表不大,mysql优化器会不走这个索引,导致锁表问题。
核心思想:以「悲观的心态」操作资源,无法获得锁成功,就一直阻塞着等待。
注意:该方式有很多缺陷,一般不建议使用。
实现:
创建一张资源锁表:
CREATE TABLE `resource_lock` (`id` int(4) NOT NULL AUTO_INCREMENT COMMENT '主键',`resource_name` varchar(64) NOT NULL DEFAULT '' COMMENT '锁定的资源名',`owner` varchar(64) NOT NULL DEFAULT '' COMMENT '锁拥有者',`desc` varchar(1024) NOT NULL DEFAULT '备注信息',`update_time` timestamp NOT NULL DEFAULT '' COMMENT '保存数据时间,自动生成',PRIMARY KEY (`id`),UNIQUE KEY `uidx_resource_name` (`resource_name `) USING BTREE
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COMMENT='锁定中的资源';
注意:resource_name 锁资源名称必须有唯一索引
使用事务查询更新:
@Transaction
public void lock(String name) {ResourceLock rlock = exeSql("select * from resource_lock where resource_name = name for update");if (rlock == null) {exeSql("insert into resource_lock(reosurce_name,owner,count) values (name, 'ip',0)");}
}
使用 for update 锁定的资源。如果执行成功,会立即返回,执行插入数据库,后续再执行一些其他业务逻辑,直到事务提交,执行结束;如果执行失败,就会一直阻塞着。
可以在数据库客户端工具上测试出来这个效果,当在一个终端执行了 for update,不提交事务。在另外的终端上执行相同条件的 for update,会一直卡着
虽然也能实现分布式锁的效果,但是会存在性能瓶颈。
优点:
简单易用,好理解,保障数据强一致性。
缺点:
1)在 RR 事务级别,select 的 for update 操作是基于间隙锁(gap lock) 实现的,是一种悲观锁的实现方式,所以存在阻塞问题。
2)高并发情况下,大量请求进来,会导致大部分请求进行排队,影响数据库稳定性,也会耗费服务的CPU等资源。
当获得锁的客户端等待时间过长时,会提示:
[40001][1205] Lock wait timeout exceeded; try restarting transaction
高并发情况下,也会造成占用过多的应用线程,导致业务无法正常响应。
3)如果优先获得锁的线程因为某些原因,一直没有释放掉锁,可能会导致死锁的发生。
4)锁的长时间不释放,会一直占用数据库连接,可能会将数据库连接池撑爆,影响其他服务。
5)MySql数据库会做查询优化,即便使用了索引,优化时发现全表扫效率更高,则可能会将行锁升级为表锁,此时可能就更悲剧了。
6)不支持可重入特性,并且超时等待时间是全局的,不能随便改动。
B. 乐观锁
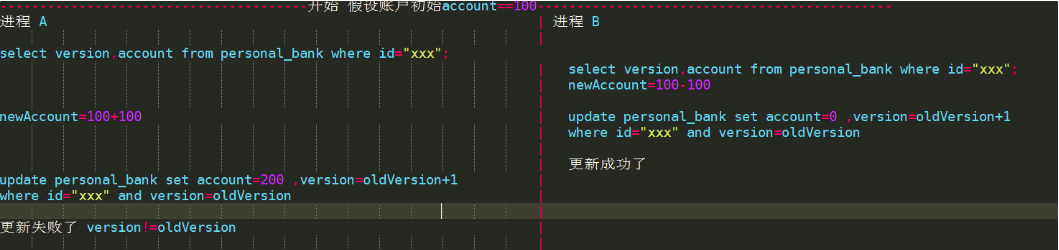
所谓乐观锁与悲观锁最大区别在于基于CAS思想,表中添加一个时间戳或者是版本号的字段来实现,update xx set version=new_version where xx=yy and version=Old_version,通过增加递增的版本号字段实现乐观锁。
不具有互斥性,不会产生锁等待而消耗资源,操作过程中认为不存在并发冲突,只有update version失败后才能觉察到。
抢购、秒杀就是用了这种实现以防止超卖。
如下图:
实现:
创建一张资源锁表:
CREATE TABLE `resource`(`id` int(4) NOT NULL AUTO_INCREMENT COMMENT '主键',`resource_name` varchar(64) NOT NULL DEFAULT '' COMMENT '资源名',`share` varchar(64) NOT NULL DEFAULT '' COMMENT '状态',`version` int(4) NOT NULL DEFAULT '' COMMENT '版本号',`desc` varchar(1024) NOT NULL DEFAULT '备注信息',`update_time` timestamp NOT NULL DEFAULT '' COMMENT '保存数据时间,自动生成',PRIMARY KEY (`id`),UNIQUE KEY `uidx_resource_name` (`resource_name `) USING BTREE
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COMMENT='资源';
为表添加一个字段,版本号或者时间戳都可以。通过版本号或者时间戳,来保证多线程同时间操作共享资源的有序性和正确性。
伪代码实现:
Resrouce resource = exeSql("select * from resource where resource_name = xxx");
boolean succ = exeSql("update resource set version= 'newVersion' ... where resource_name = xxx and version = 'oldVersion'");if (!succ) {// 发起重试
}
实际代码中可以写个while循环不断重试,版本号不一致,更新失败,重新获取新的版本号,直到更新成功。
优点:
- 实现简单,复杂度低
- 保障数据一致性
缺点:
- 性能低,并且有锁表的风险
- 可靠性差
- 非阻塞操作失败后,需要轮询,占用CPU资源
- 长时间不commit或者是长时间轮询,可能会占用较多的连接资源
分布式锁:代码实现:
1、分布式锁服务端
单独启动一个应用,用来提供分布式锁,实现锁的关闭和开启。相当于redis的服务器
1.1、创建锁表
DROP TABLE IF EXISTS `qrtz_distribute_lock`;
CREATE TABLE `qrtz_distribute_lock` (`id` varchar(32) CHARACTER SET utf8 COLLATE utf8_bin NOT NULL COMMENT '主键',`key` varchar(255) CHARACTER SET utf8 COLLATE utf8_bin NOT NULL COMMENT '锁名称',`val` tinyint(255) NULL DEFAULT 1 COMMENT '值',`remark` varchar(255) CHARACTER SET utf8 COLLATE utf8_bin NULL DEFAULT NULL COMMENT '描述',`update` timestamp(0) NULL DEFAULT NULL COMMENT '更新时间',PRIMARY KEY (`id`) USING BTREE,UNIQUE INDEX `KEY_INDEX`(`key`) USING BTREE
) ENGINE = InnoDB CHARACTER SET = utf8 COLLATE = utf8_bin ROW_FORMAT = Dynamic;
数据库表如下图所示:

其中key自行实现唯一性,数据库不做约束
1.2、锁的查询和删除
@Repository
public interface DistributeLockDao extends JpaRepository<DistributeLock, String> {/** 根据key查询锁 **/DistributeLock findByKey(String key);/** 根据key删除锁 **/void deleteByKey(String key);
}
1.3、加锁和解锁
@Service
public class DistributeLockService {@AutowiredDistributeLockDao lockDao;@Transactionalpublic synchronized Boolean lock(DistributeLock lock) {DistributeLock locked = lockDao.findByKey(lock.getKey());if(locked == null) { //没有锁,新增锁lock.setUpdate(new Date());lock.setVal(true);lock = lockDao.saveAndFlush(lock);return true;}if(locked.getVal()) { //有锁,且已锁,不可用locked = new DistributeLock();locked.setVal(false);return false;}// 有锁,可用locked.setVal(true);locked.setUpdate(new Date());locked = lockDao.saveAndFlush(locked);return true;}/*** 取消分布式锁* @return*/@Transactionalpublic synchronized Boolean unLock(DistributeLock lock) {lockDao.deleteByKey(lock.getKey());lock.setVal(false);return true;}
}
1.4、提供取锁和解锁的接口
@RestController
public class DistributeLockController {@AutowiredDistributeLockService lockService;@RequestMapping("lock")public Boolean lock(@Validated DistributeLock lock) {return lockService.lock(lock);}@RequestMapping("unLock")public Boolean unLock(@Validated DistributeLock lock) {return lockService.unLock(lock);}
}
2、分布式锁客户端
2.1、切点注解
@Documented
@Target(ElementType.METHOD)
@Retention(RetentionPolicy.RUNTIME)
public @interface Lock {/*** 保证唯一性,默认是全限定类名 + 方法全称(含参数列表)* @return*/String key() default "";String describe() default "";/*** 获取锁超时时间* @return*/int timeout() default 5000;
}
数据库未解锁前的数据:

2.1、实现分布式锁切面
@Aspect
@Component
public class DistributeLockAspect {/** 分布式锁服务端的ip和端口, 服务端contextPath若不为‘distribute’,则需要修改 **/public static final String DISTRIBUTE_SERVER_ADDRESS = "localhost:9876";private static final String userAgent = "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3409.0 Safari/537.36";private static final CloseableHttpClient httpclient = HttpClients.createDefault();/*** 线程池*/ThreadPoolExecutor executor = (ThreadPoolExecutor) Executors.newFixedThreadPool(20);/*** 存放key*/ThreadLocal<String> keys = new ThreadLocal<>();// order = 1@Before(value = "@annotation(Lock)")public void doBefore(JoinPoint joinPoint) throws InterruptedException, ExecutionException, TimeoutException {MethodSignature methodSignature = (MethodSignature) joinPoint.getSignature();Method method = methodSignature.getMethod();String key = null, describe = null;int timeout = 0;if (method != null) {Lock lock = method.getAnnotation(Lock.class);describe = lock.describe();timeout = lock.timeout();key = lock.key();}keys.set(getLockKey(key, joinPoint));String remark = describe;String lockKey = keys.get();while (true) {Future<Boolean> future = executor.submit(() -> {// 在此处使用keys.get(), key可能会为nullString result = sendGet("http://" + DISTRIBUTE_SERVER_ADDRESS + "/distribute/lock?key=" + lockKey + "&remark=" + remark);;if(StringUtils.equals(result, "true") || StringUtils.equals(result, "false")) {return Boolean.parseBoolean(result);}return null;});Boolean flag = future.get(timeout, TimeUnit.MILLISECONDS);if(flag == null) {throw new IllegalArgumentException("network exception");}if(flag != null) {if(future.get()) {break;} else {continue;}}}}// order = 2@Around(value = "@annotation(Lock)")public Object around(ProceedingJoinPoint proceedingJoinPoint){try {Object ret= proceedingJoinPoint.proceed();return ret;} catch (Throwable throwable) {throwable.printStackTrace();}return null;}// order = 3@After(value = "@annotation(Lock)")public void after(JoinPoint joinPoint){}// order = 4@AfterReturning(pointcut = "@annotation(Lock)",returning = "ret")public void doAfterReturning(Object ret) {sendGet("http://" + DISTRIBUTE_SERVER_ADDRESS + "/distribute/unLock?key=" + keys.get());keys.remove();}// order = 方法抛出异常时@AfterThrowing(pointcut = "@annotation(Lock)",throwing = "ex")public void AfterThrowing(JoinPoint joinPoint,Throwable ex){MethodSignature methodSignature = (MethodSignature) joinPoint.getSignature();Method method = methodSignature.getMethod();sendGet("http://" + DISTRIBUTE_SERVER_ADDRESS + "/distribute/unLock?key=" + keys.get());keys.remove();}/*** 分布式锁的key, 默认由全限定类名 + 具体方法(含参数)* @param key* @param joinPoint* @return*/private String getLockKey(String key, JoinPoint joinPoint) {if(StringUtils.isNotBlank(key)) {return key;}MethodSignature methodSignature = (MethodSignature) joinPoint.getSignature();Method method = methodSignature.getMethod();String[] names = StringUtils.split(method.toString(), " ");for(String name : names) {if(StringUtils.indexOf(name, "(") > -1 && StringUtils.indexOf(name, ")") > -1) {return name;}}return null;}private String sendGet(String url) {String result = null;HttpGet httpGet = new HttpGet(url);httpGet.setHeader("User-Agent", userAgent);try(CloseableHttpResponse response = httpclient.execute(httpGet)) {HttpEntity entity = response.getEntity();if (entity != null) {result = EntityUtils.toString(entity);}} catch (Exception e) {e.printStackTrace();}return result;}
}
Zookeeper分布式锁:
zookeeper用主从节点实现锁,cp,保持一致性,数据可能会有延迟,性能不如redis。
基于Zookeeper的分布式锁实现原理是什么?
顺序节点特性:
使用Zookeeper的顺序节点随性,假如我们在/lock/目录下创建3个节点,ZK集群会按照发起创建的顺序来创建节点,节点分别为/lock/0000000001、/lock/0000000002、/lock/0000000003,最后一位数是依次递增的,节点名由zk来完成。
临时节点特性:
ZK中还有一种名为临时节点的节点,临时节点由某个客户端创建,当客户端与ZK集群断开连接,则该节点自动被删除。EPHEMERAL_SEQUENTIAL(ephemeral_sequential)为临时顺序节点。
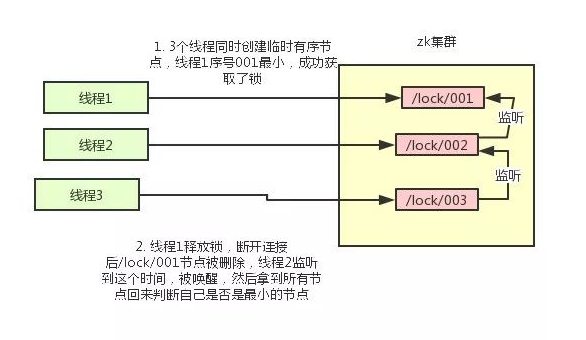
根据ZK中节点是否存在。可以作为分布式锁的锁状态,以此来实现一个分布式锁,下面是分布式锁的基本逻辑:
1、客户端1调用create() 方法创建名为"/业务ID/lock-的临时顺序节点。"
2、客户端1调用getChildren(“业务ID”) 方法来获取所有已经创建的子节点。
3、客户端获取到所有子节点path之后,如果发送自己在步骤1中创建的节点是所有节点中序号最小的,就是看自己创建的序列号是否排第一,如果是第一,那么就认为这个客户端获得了锁,在它前面没有别的客户端拿到锁。
4、如果创建的节点不是所有节点中需要最小的,那么则监视比自己创建节点的序列号小的最大的节点,进入等待。直到下次监视的子节点变更的时候,再进行子节点的获取,判断是否获取锁。
zk分布式锁实现原理:
- 创建一个持久节点,要获得锁的时候就在“持久节点”下创建一个“临时顺序节点”。如果存在节点就依次往下。
- 如果自己不是“持久节点”下的第一个节点,就对自己上一个节点加监听器,
- 只要上一个节点释放锁(删除节点),自己就排到前面去了,相当于是一个排队机制。
而且用临时顺序节点,如果某个客户端创建临时顺序节点之后,自己宕机了,zk感知到那个客户端宕机,会自动删除对应的临时顺序节点,相当于自动释放锁,或者是自动取消自己的排队,解决了惊群效应。
分布式锁:理论概念
让我们来回顾一下Zookeeper节点的概念:
Zookeeper的数据存储结构就像一棵树,这棵树由节点组成,这种节点叫做Znode。
Znode分为四种类型:
1.持久节点 (PERSISTENT)
默认的节点类型。创建节点的客户端与zookeeper断开连接后,该节点依旧存在 。
2.持久节点顺序节点(PERSISTENT_SEQUENTIAL)
所谓顺序节点,就是在创建节点时,Zookeeper根据创建的时间顺序给该节点名称进行编号:
3.临时节点(EPHEMERAL)
和持久节点相反,当创建节点的客户端与zookeeper断开连接后,临时节点会被删除:
4.临时顺序节点(EPHEMERAL_SEQUENTIAL)
顾名思义,临时顺序节点结合和临时节点和顺序节点的特点:在创建节点时,Zookeeper根据创建的时间顺序给该节点名称进行编号;当创建节点的客户端与zookeeper断开连接后,临时节点会被删除。
Zookeeper分布式锁的原理
Zookeeper分布式锁恰恰应用了临时顺序节点。具体如何实现呢?让我们来看一看详细步骤:
获取锁
首先,在Zookeeper当中创建一个持久节点ParentLock。当第一个客户端想要获得锁时,需要在ParentLock这个节点下面创建一个临时顺序节点 Lock1。
之后,Client1查找ParentLock下面所有的临时顺序节点并排序,判断自己所创建的节点Lock1是不是顺序最靠前的一个。如果是第一个节点,则成功获得锁。
这时候,如果再有一个客户端 Client2 前来获取锁,则在ParentLock下载再创建一个临时顺序节点Lock2。
Client2查找ParentLock下面所有的临时顺序节点并排序,判断自己所创建的节点Lock2是不是顺序最靠前的一个,结果发现节点Lock2并不是最小的。
于是,Client2向排序仅比它靠前的节点Lock1注册Watcher,用于监听Lock1节点是否存在。这意味着Client2抢锁失败,进入了等待状态。
这时候,如果又有一个客户端Client3前来获取锁,则在ParentLock下载再创建一个临时顺序节点Lock3。
Client3查找ParentLock下面所有的临时顺序节点并排序,判断自己所创建的节点Lock3是不是顺序最靠前的一个,结果同样发现节点Lock3并不是最小的。
于是,Client3向排序仅比它靠前的节点Lock2注册Watcher,用于监听Lock2节点是否存在。这意味着Client3同样抢锁失败,进入了等待状态。
这样一来,Client1得到了锁,Client2监听了Lock1,Client3监听了Lock2。这恰恰形成了一个等待队列,很像是Java当中ReentrantLock所依赖的
释放锁
释放锁分为两种情况:
1.任务完成,客户端显示释放
当任务完成时,Client1会显示调用删除节点Lock1的指令。
2.任务执行过程中,客户端崩溃
获得锁的Client1在任务执行过程中,如果Duang的一声崩溃,则会断开与Zookeeper服务端的链接。根据临时节点的特性,相关联的节点Lock1会随之自动删除。
由于Client2一直监听着Lock1的存在状态,当Lock1节点被删除,Client2会立刻收到通知。这时候Client2会再次查询ParentLock下面的所有节点,确认自己创建的节点Lock2是不是目前最小的节点。如果是最小,则Client2顺理成章获得了锁。
同理,如果Client2也因为任务完成或者节点崩溃而删除了节点Lock2,那么Client3就会接到通知。
最终,Client3成功得到了锁。
方案:
可以直接使用zookeeper第三方库Curator客户端,这个客户端中封装了一个可重入的锁服务。
Curator提供的InterProcessMutex是分布式锁的实现。acquire方法用户获取锁,release方法用于释放锁。
https://github.com/apache/curator/
缺点:
性能上可能并没有缓存服务那么高。因为每次在创建锁和释放锁的过程中,都要动态创建、销毁瞬时节点来实现锁功能。ZK中创建和删除节点只能通过Leader服务器来执行,然后将数据同不到所有的Follower机器上。
其实,使用Zookeeper也有可能带来并发问题,只是并不常见而已。考虑这样的情况,由于网络抖动,客户端可ZK集群的session连接断了,那么zk以为客户端挂了,就会删除临时节点,这时候其他客户端就可以获取到分布式锁了。就可能产生并发问题。这个问题不常见是因为zk有重试机制,一旦zk集群检测不到客户端的心跳,就会重试,Curator客户端支持多种重试策略。多次重试之后还不行的话才会删除临时节点。(所以,选择一个合适的重试策略也比较重要,要在锁的粒度和并发之间找一个平衡。)
总结
下面的表格总结了Zookeeper和Redis分布式锁的优缺点:
| 分布式锁 | 优点 | 缺点 |
|---|---|---|
| Zookeeper | 有封装好的框架容易实现。有等待锁的队列,大大提升强锁的效率。 | 添加和删除即节点性能较低。 |
| Redis | Set和Del指令的性能较高 | 实现复杂:需要考虑超时,原子性,误删等问题。没有等待锁的队列,只能在客户端自旋来等待 效率低。 |
分布式锁:代码实现
1.实现思想
ZooKeeper是一个为分布式应用提供一致性服务的开源组件,它内部是一个分层的文件系统目录树结构,规定同一个目录下只能有一个唯一文件名。
基于ZooKeeper实现分布式锁的步骤如下:
-
创建一个目录mylock;
-
线程A想获取锁就在mylock目录下创建临时顺序节点;
-
获取mylock目录下所有的子节点,然后获取比自己小的兄弟节点,如果不存在,则说明当前线程顺序号最小,获得锁;
-
线程B获取所有节点,判断自己不是最小节点,设置监听比自己次小的节点;
-
线程A处理完,删除自己的节点,线程B监听到变更事件,判断自己是不是最小的节点,如果是则获得锁。
整个过程如图:
业界推荐直接使用Apache的开源库Curator,它是一个ZooKeeper客户端,Curator提供的InterProcessMutex是分布式锁的实现,acquire方法用于获取锁,release方法用于释放锁。
使用方式很简单:
InterProcessMutex interProcessMutex = new InterProcessMutex(client,"/anyLock");
interProcessMutex.acquire();
interProcessMutex.release();
其实现分布式锁的核心源码如下:
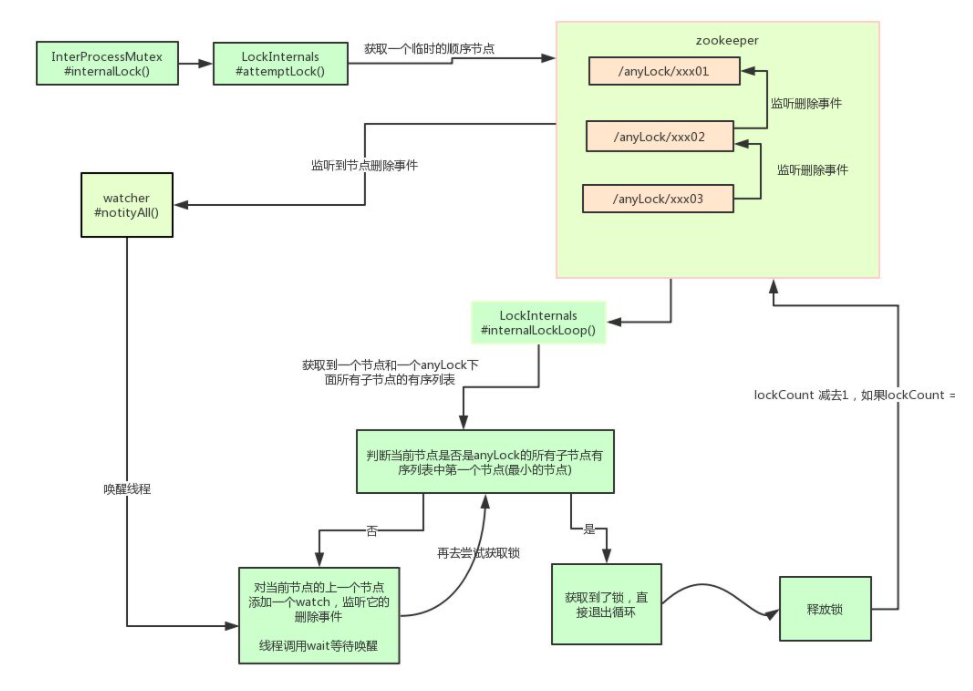
private boolean internalLockLoop(long startMillis, Long millisToWait, String ourPath) throws Exception
{ boolean haveTheLock = false; boolean doDelete = false; try { if ( revocable.get() != null ) { client.getData().usingWatcher(revocableWatcher).forPath(ourPath); } while ( (client.getState() == CuratorFrameworkState.STARTED) && !haveTheLock ) { // 获取当前所有节点排序后的集合 List<String> children = getSortedChildren(); // 获取当前节点的名称 String sequenceNodeName = ourPath.substring(basePath.length() + 1); // +1 to include the slash // 判断当前节点是否是最小的节点 PredicateResults predicateResults = driver.getsTheLock(client, children, sequenceNodeName, maxLeases); if ( predicateResults.getsTheLock() ) { // 获取到锁 haveTheLock = true; } else { // 没获取到锁,对当前节点的上一个节点注册一个监听器 String previousSequencePath = basePath + "/" + predicateResults.getPathToWatch(); synchronized(this){ Stat stat = client.checkExists().usingWatcher(watcher).forPath(previousSequencePath); if ( stat != null ){ if ( millisToWait != null ){ millisToWait -= (System.currentTimeMillis() - startMillis); startMillis = System.currentTimeMillis(); if ( millisToWait <= 0 ){ doDelete = true; // timed out - delete our node break; } wait(millisToWait); }else{ wait(); } } } // else it may have been deleted (i.e. lock released). Try to acquire again } } } catch ( Exception e ) { doDelete = true; throw e; } finally{ if ( doDelete ){ deleteOurPath(ourPath); } } return haveTheLock;
}
其实 Curator 实现分布式锁的底层原理和上面分析的是差不多的。如图详细描述其原理:
另外,可基于Zookeeper自身的特性和原生Zookeeper API自行实现分布式锁。
优点:
- 可靠性非常高
- 性能较好
- CAP模型属于CP,基于ZAB一致性算法实现
缺点:
- 性能并不如Redis(主要原因是在写操作,即获取锁释放锁都需要在Leader上执行,然后同步到follower)
- 实现复杂度高
分布式锁:锁问题
基于zookeeper临时有序节点可以实现的分布式锁。
大致思想即为:每个客户端对某个方法加锁时,在zookeeper上的与该方法对应的指定节点的目录下,生成一个唯一的瞬时有序节点。 判断是否获取锁的方式很简单,只需要判断有序节点中序号最小的一个。 当释放锁的时候,只需将这个瞬时节点删除即可。同时,其可以避免服务宕机导致的锁无法释放,而产生的死锁问题。
来看下Zookeeper能不能解决前面提到的问题。
-
锁无法释放?使用Zookeeper可以有效的解决锁无法释放的问题,因为在创建锁的时候,客户端会在ZK中创建一个临时节点,一旦客户端获取到锁之后突然挂掉(Session连接断开),那么这个临时节点就会自动删除掉。其他客户端就可以再次获得锁。
-
非阻塞锁?使用Zookeeper可以实现阻塞的锁,客户端可以通过在ZK中创建顺序节点,并且在节点上绑定监听器,一旦节点有变化,Zookeeper会通知客户端,客户端可以检查自己创建的节点是不是当前所有节点中序号最小的,如果是,那么自己就获取到锁,便可以执行业务逻辑了。
-
不可重入?使用Zookeeper也可以有效的解决不可重入的问题,客户端在创建节点的时候,把当前客户端的主机信息和线程信息直接写入到节点中,下次想要获取锁的时候和当前最小的节点中的数据比对一下就可以了。如果和自己的信息一样,那么自己直接获取到锁,如果不一样就再创建一个临时的顺序节点,参与排队。
-
单点问题?使用Zookeeper可以有效的解决单点问题,ZK是集群部署的,只要集群中有半数以上的机器存活,就可以对外提供服务。
-
公平问题?使用Zookeeper可以解决公平锁问题,客户端在ZK中创建的临时节点是有序的,每次锁被释放时,ZK可以通知最小节点来获取锁,保证了公平。
问题又来了,我们知道Zookeeper需要集群部署,会不会出现Redis集群那样的数据同步问题呢?
Zookeeper是一个保证了弱一致性即最终一致性的分布式组件。
Zookeeper采用称为Quorum Based Protocol的数据同步协议。假如Zookeeper集群有N台Zookeeper服务器(N通常取奇数,3台能够满足数据可靠性同时有很高读写性能,5台在数据可靠性和读写性能方面平衡最好),那么用户的一个写操作,首先同步到N/2 + 1台服务器上,然后返回给用户,提示用户写成功。基于Quorum Based Protocol的数据同步协议决定了Zookeeper能够支持什么强度的一致性。
在分布式环境下,满足强一致性的数据储存基本不存在,它要求在更新一个节点的数据,需要同步更新所有的节点。这种同步策略出现在主从同步复制的数据库中。但是这种同步策略,对写性能的影响太大而很少见于实践。因为Zookeeper是同步写N/2+1个节点,还有N/2个节点没有同步更新,所以Zookeeper不是强一致性的。
用户的数据更新操作,不保证后续的读操作能够读到更新后的值,但是最终会呈现一致性。牺牲一致性,并不是完全不管数据的一致性,否则数据是混乱的,那么系统可用性再高分布式再好也没有了价值。牺牲一致性,只是不再要求关系型数据库中的强一致性,而是只要系统能达到最终一致性即可。
Zookeeper是否满足最终一致性,需要看客户端的编程方式。
不满足最终一致性的做法
- A进程向Zookeeper的/z写入一个数据,成功返回
- A进程通知B进程,A已经修改了/z的数据
- B读取Zookeeper的/z的数据
- 由于B连接的Zookeeper的服务器有可能还没有得到A写入数据的更新,那么B将读不到A写入的数据
满足最终一致性的做法
- B进程监听Zookeeper上/z的数据变化
- A进程向Zookeeper的/z写入一个数据,成功返回前,Zookeeper需要调用注册在/z上的监听器,Leader将数据变化的通知告诉B
- B进程的事件响应方法得到响应后,去取变化的数据,那么B一定能够得到变化的值
- 这里的因果一致性提现在Leader和B之间的因果一致性,也就是是Leader通知了数据有变化
第二种事件监听机制也是对Zookeeper进行正确编程应该使用的方法,所以,Zookeeper应该是满足因果一致性的
所以我们在基于Zookeeper实现分布式锁的时候,应该使用满足因果一致性的做法,即等待锁的线程都监听Zookeeper上锁的变化,在锁被释放的时候,Zookeeper会将锁变化的通知告诉满足公平锁条件的等待线程。
可以直接使用zookeeper第三方库客户端,这个客户端中封装了一个可重入的锁服务。
public boolean tryLock(long timeout, TimeUnit unit) throws InterruptedException { try { return interProcessMutex.acquire(timeout, unit); } catch (Exception e) { e.printStackTrace(); } return true;
} public boolean unlock() { try { interProcessMutex.release(); } catch (Throwable e) { log.error(e.getMessage(), e); } finally { executorService.schedule(new Cleaner(client, path), delayTimeForClean, TimeUnit.MILLISECONDS); } return true;
}
使用ZK实现的分布式锁好像完全符合了本文开头我们对一个分布式锁的所有期望。但是,其实并不是,Zookeeper实现的分布式锁其实存在一个缺点,那就是性能上可能并没有缓存服务那么高。因为每次在创建锁和释放锁的过程中,都要动态创建、销毁瞬时节点来实现锁功能。ZK中创建和删除节点只能通过Leader服务器来执行,然后将数据同不到所有的Follower机器上。
使用Zookeeper实现分布式锁的优点
有效的解决单点问题,不可重入问题,非阻塞问题以及锁无法释放的问题。实现起来较为简单。
使用Zookeeper实现分布式锁的缺点
性能上不如使用缓存实现分布式锁。 需要对ZK的原理有所了解。
分布式锁:图解
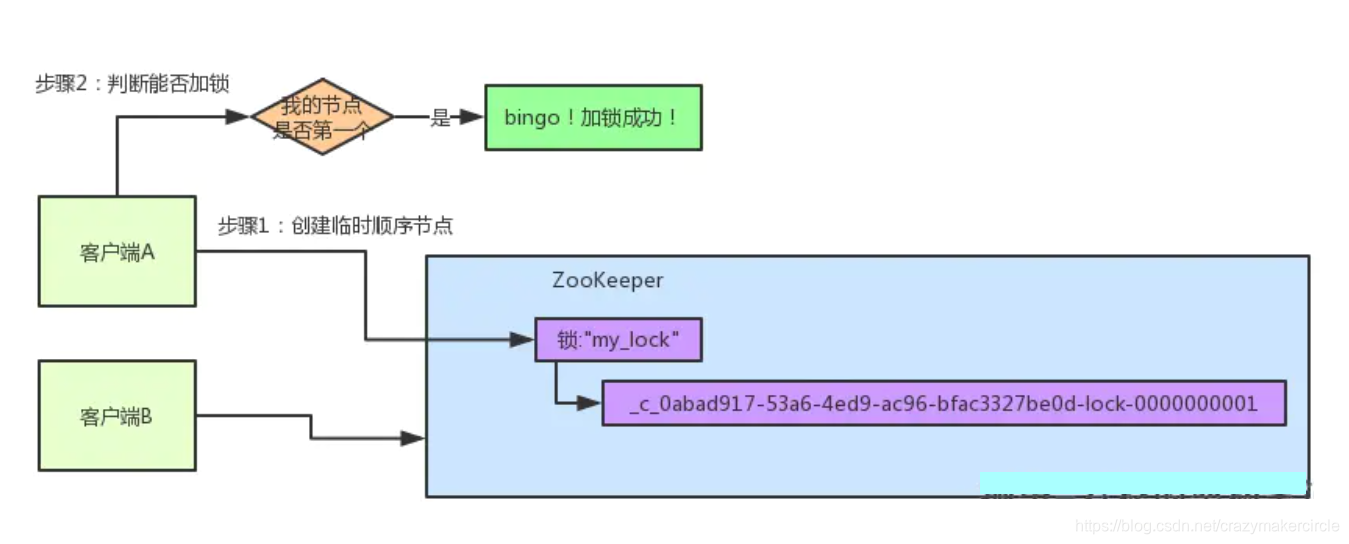
客户端B过来排队
接着假如说,客户端A都加完锁了,客户端B过来想要加锁了,这个时候他会干一样的事儿:先是在"my_lock"这个锁节点下创建一个临时顺序节点,此时名字会变成类似于:

大家看看下面的图:
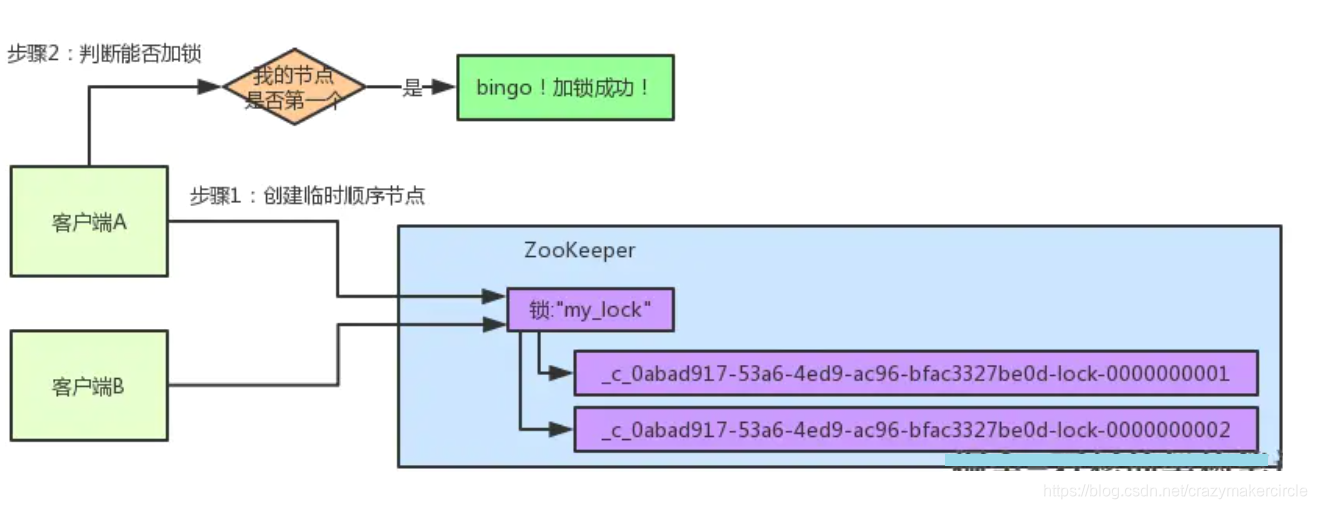
客户端B因为是第二个来创建顺序节点的,所以zk内部会维护序号为"2"。
接着客户端B会走加锁判断逻辑,查询"my_lock"锁节点下的所有子节点,按序号顺序排列,此时他看到的类似于:
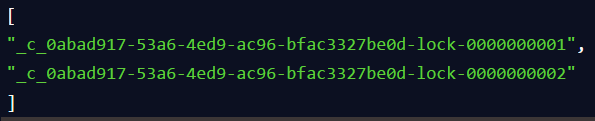
同时检查自己创建的顺序节点,是不是集合中的第一个?
明显不是啊,此时第一个是客户端A创建的那个顺序节点,序号为"01"的那个。所以加锁失败!
客户端B开启监听客户端A
加锁失败了以后,客户端B就会通过ZK的API对他的顺序节点的上一个顺序节点加一个监听器。zk天然就可以实现对某个节点的监听。
如果大家还不知道zk的基本用法,可以百度查阅,非常的简单。客户端B的顺序节点是:

他的上一个顺序节点,不就是下面这个吗?

即客户端A创建的那个顺序节点!
所以,客户端B会对:

这个节点加一个监听器,监听这个节点是否被删除等变化!大家看下面的图。
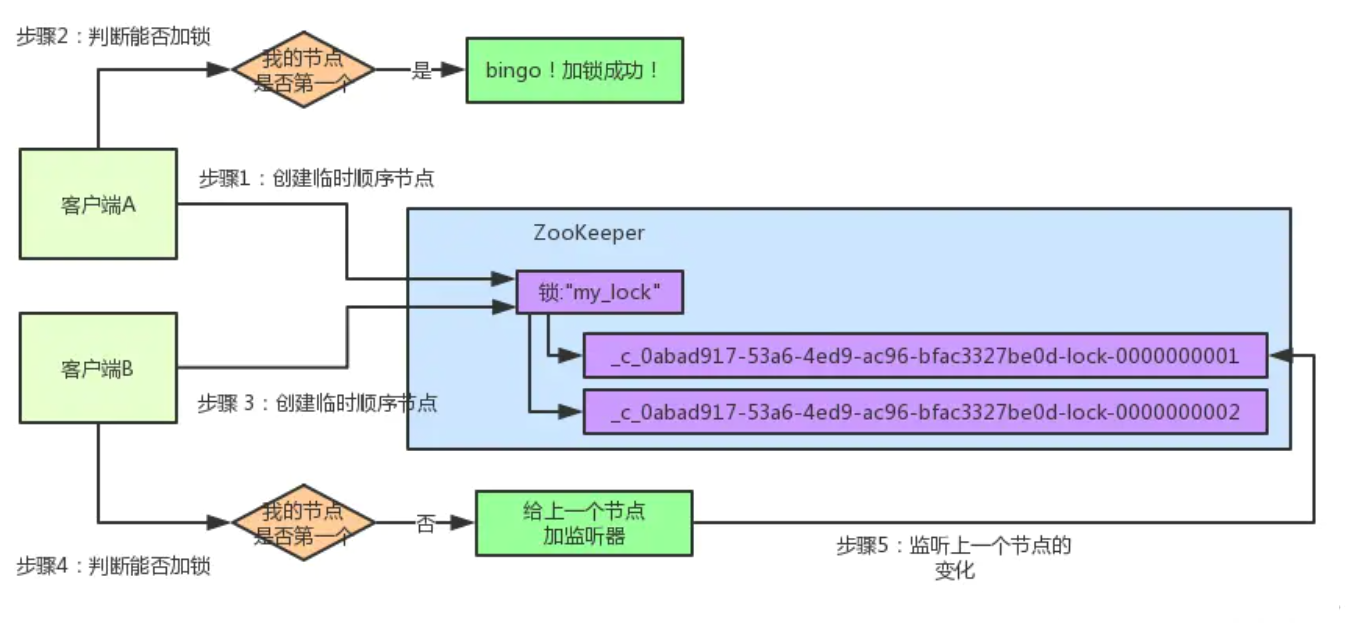
接着,客户端A加锁之后,可能处理了一些代码逻辑,然后就会释放锁。那么,释放锁是个什么过程呢?
其实很简单,就是把自己在zk里创建的那个顺序节点,也就是:

这个节点给删除。
删除了那个节点之后,zk会负责通知监听这个节点的监听器,也就是客户端B之前加的那个监听器,说:兄弟,你监听的那个节点被删除了,有人释放了锁。
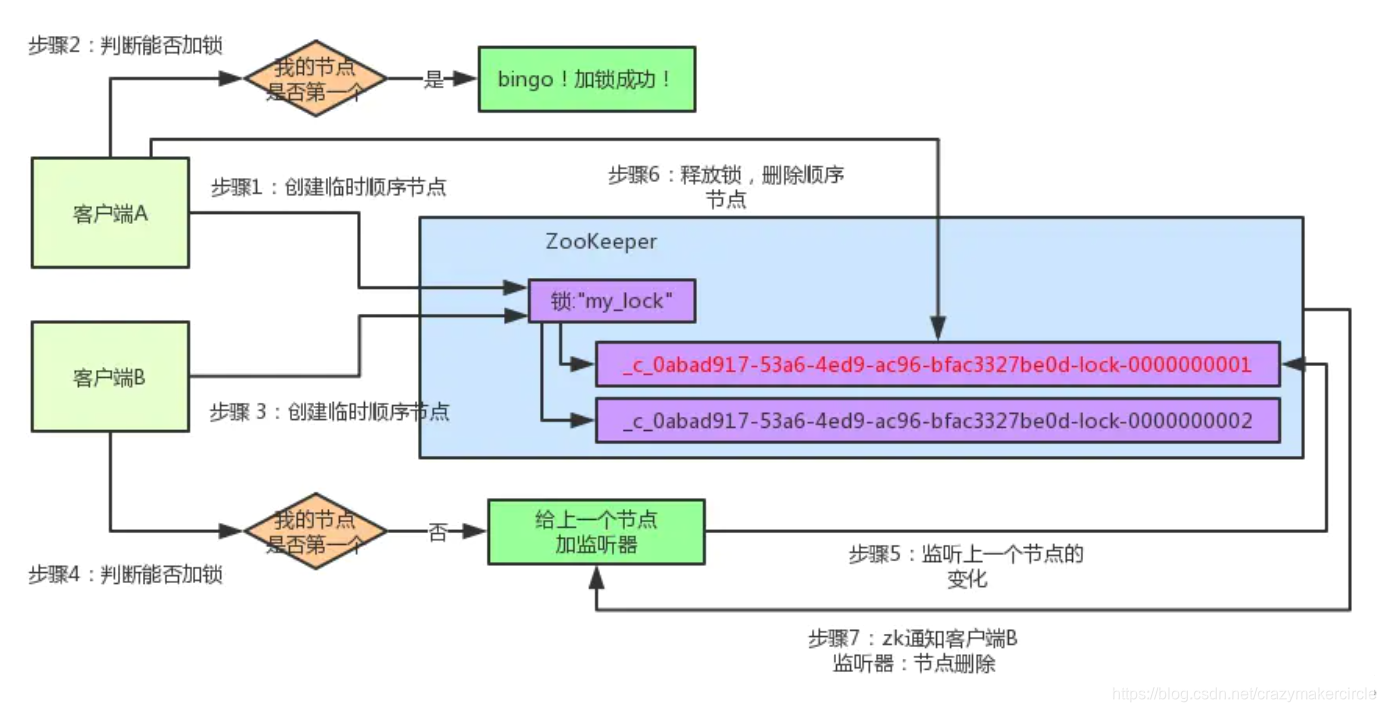
此时客户端B的监听器感知到了上一个顺序节点被删除,也就是排在他之前的某个客户端释放了锁。
客户端B抢锁成功
此时,就会通知客户端B重新尝试去获取锁,也就是获取"my_lock"节点下的子节点集合,此时为:

集合里此时只有客户端B创建的唯一的一个顺序节点了!
然后呢,客户端B判断自己居然是集合中的第一个顺序节点,bingo!可以加锁了!直接完成加锁,运行后续的业务代码即可,运行完了之后再次释放锁。
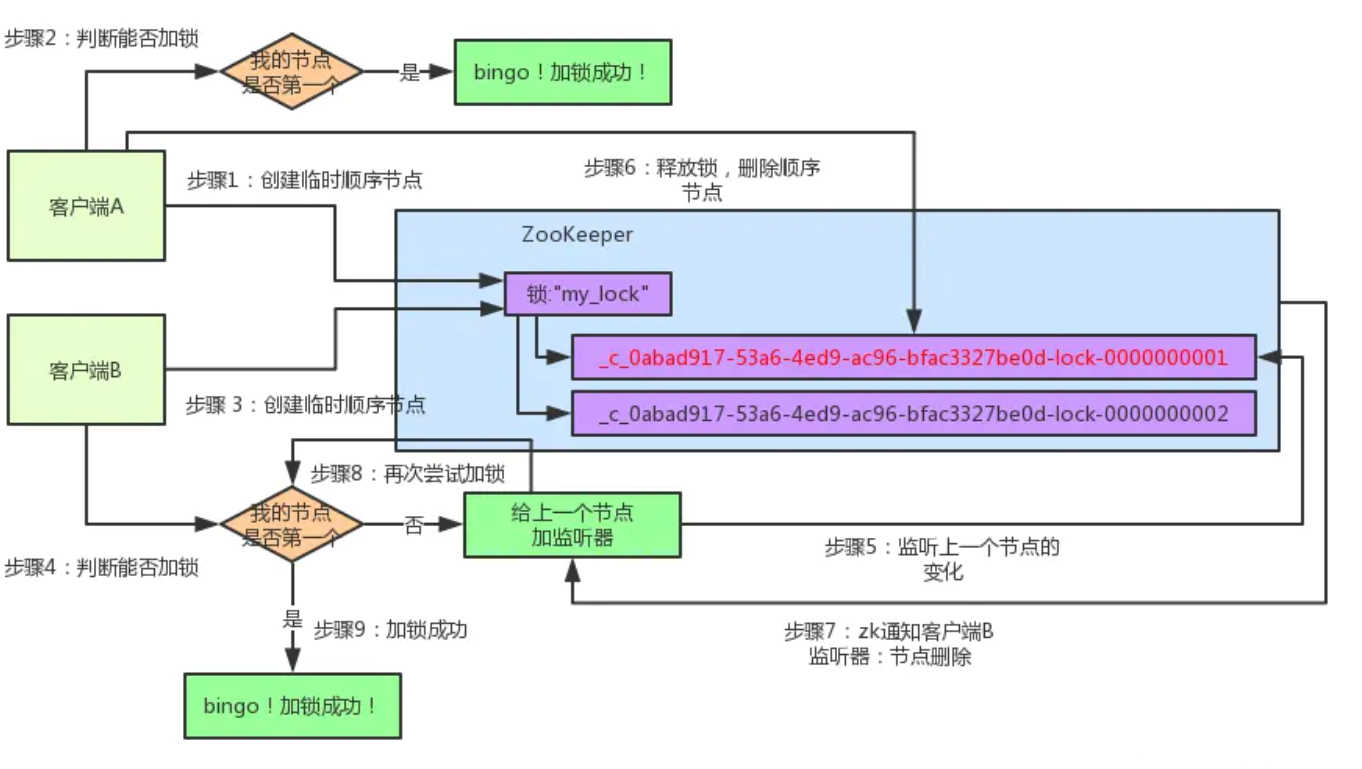
分布式锁的基本实现
接下来就是基于ZooKeeper,实现一下分布式锁。首先,定义了一个锁的接口Lock,很简单,仅仅两个抽象方法:一个加锁方法,一个解锁方法。Lock接口的代码如下:
package com.crazymakercircle.zk.distributedLock;/*** create by 尼恩 @ 疯狂创客圈**/
public interface Lock {/*** 加锁方法** @return 是否成功加锁*/boolean lock() throws Exception;/*** 解锁方法** @return 是否成功解锁*/boolean unlock();
}
分布式锁:基础方法
Znode包含哪些元素
- data:Znode 存储的数据信息。
- ACL:记录 Znode 的访问权限,即那些人或哪些IP可以访问本节点。
- stat:包含 Znode 的各种元数据,比如事务ID、版本号、时间戳、大小等。
- child:当前节点的子节点引用。
注意:Zookeeper 是为读多写少的场景所设计。Znode并不是用来存储大规模业务数据,而是用于存储少量的状态和配置信息,每个节点的数据最大不能超过 1MB。
Zookeeper 的基本操作
- 创建节点
create - 删除节点
delete - 判断节点是否存在
exists - 获得一个节点的数据
getData - 设置一个节点的数据
setData - 获取节点下的所有节点
getChildren
其中,exests , getData , getChildren 属于读操作。Zookeeper 客户端在请求读操作的时候,可以选择是否设置 Watch。
Zookeeper 的事件通知
我们可以把 Watch 理解成是注册在特定 Znode 上的触发器。当这个 Znode 发生改变,也就是调用了 create , delete ,setData 等方法的时候,将会出发 Znode 上注册的对应事件,请求 Watch 的客户端会接受到异步通知。
具体交互过程:
- 客户端调用
getData方法,watch参数是true。服务端接收到请求,返回节点数据,并且在对应的哈希表里插入被 Watch 的 Znode 路径,以及 Watcher 列表。 - 当 Watch 的 Znode 已删除,服务端会查找哈希表,找到该 Znode 对应的所有 Watcher,异步通知客户端,并且删除哈希表中对应的 Key-Value。
Zookeeper 的一致性
Zookeeper 身为分布式系统协调服务,为了防止单机挂掉的情况,Zookeeper 维护了一个集群。

Zookeeper Service 集群是一主多从结构。
在更新数据时,首先更新到主节点(这里的节点指的是服务器,不是 Znode),在同步到从节点。
在读取数据时,直接读取任意从节点。
为了保证主从节点的数据一致性,Zookeeper 采用 ZAB协议,这种协议非常类似于一致性算法那 Paxos 和 Raft。
什么是ZAB协议
Zookeeper Atomic Broadcast,有效解决了 Zookeeper 集群崩溃恢复,以及主从同步数据的问题。
ZAB 协议定义的三种节点状态
- Looking:选举状态。
- Following:Follower节点(从节点)所处的状态。
- Leading:Leader节点(主节点)所处状态。
最大 ZXID:
最大 ZXID 也就是节点本地的最新事务编号,包含 epoch 和计数两部分。epoch是纪元的意思,相当于Raft算法选主时候的 term。
ZAB 崩溃恢复
加入 Zookeeper 当前主节点挂掉了,集群会进行奔溃恢复。ZAB 的奔溃恢复分成三个阶段:
1、Leader Election
- 选举阶段,此时集群中的节点处于 Looking 状态。它们会向其他节点发起投票,投票当中包含自己的服务器ID 和最新事务ID(ZXID)。
- 接下来,节点会用自身的 ZXID 和从其他节点接收到的 ZXID 作比较,如果发现别人家的 ZXID 比自己大,也就是数据比自己新,那么就重新发起投票,投票给目前已知最大的ZXID所属节点。
- 每次投票后,服务器都会统计投票数量,判断是否有某个节点得到半数以上的投票。如果存在这样的节点,该节点就会成为准 Leader,状态变成 Leading。其他节点的状态变为 Following。
2、Discovery
发现阶段,用于在从节点中发现最新的 ZXID和事务日志(为了防止某些意外的情况,比如因网络原因在上一阶段产生了多个Leader的情况)。
- 在这一阶段,Leader 集思广益,接受所有Follower发来各自的最新 epoch 值。Leader从中选出最大的epoch,基于此值加 1,生成新的 epoch 分发给各个 Follower。
- 各个 Follower 收到全新的 epoch 后,返回 ACK 给Leader,带上各自最大的 ZXID 和历史事务日志。Leader 选出最大的ZXID,并更新自身历史日志。
3、Synchronization
同步阶段,把 Leader 刚才收集得到的最新历史事务日志,同步给集群中所有的 Follower。只有当半数 Follower 同步成功,这个准 Leader 才能成为正式的 Leader。
自此,故障恢复正式完成。
ZAB 的数据写入:
ZAB 的数据写入涉及到 Broadcast 阶段,简单来说,就是 Zookeeper 常规情况下更新数据的时候,由 Leader 广播到所有的 Follower。其过程如下:
- 客户端发出写入数据请求给任意 Follower。
- Follower 把写入数据请求转发给 Leader。
- Leader 采用二阶段提交方式,先发送 Propose 广播给 Follower。
- Follower 接收到 Propose 消息,写入日志成功后,返回 ACK 消息给 Leader。
- Leader 接收到半数以上 ACK 消息,返回成功给客户端,并且广播 Commit 请求给 Follower。

总结
ZAB 协议既不是强一致性,也不是若一致性,而是处于两者之间的单调一致性(顺序一致性)。它依靠事务 ID 和版本号,保证了数据的更新和读取是有序的。
Zookeeper 的应用场景
分布式锁
利用 Zookeeper 的临时顺序节点,可以轻松实现分布式锁。
服务注册和发现:
利用 Znode 和 Watcher,可以实现分布式服务的注册和发现。
共享配置和状态信息:
Redis 的分布式解决方案 Codis,就利用了 Zookeeper 来存放数据路由表和 codis-proxy 节点的元信息。同时 codis-config 发起的命令都会通过 Zookeeper 同步到各个存活的 codis-proxy。
此外, Kafka、HBase、Hadoop,也都依靠 Zookeeper 同步节点信息,实现高可用。
Redis分布式锁:
Redis分布式锁官网:http://redis.cn/topics/distlock.htm
Redis分布式锁底层是如何实现的?
1、首先利用setnx来保证:如果key不存在才能获取到锁,如果key存在,则获取不到锁
2、然后还要利用lua脚本来保证多个redis操作的原子性
3、同时还要考虑到锁过期,所以需要额外的一个看门狗定时任务来监听锁是否需要续约
4、同时还要考虑到redis节点挂掉后的情况,所以需要采用红锁的方式来同时向N/2+1个节点申请锁,都申请到了才证明获取锁成功,这样就算其中某个redis节点挂掉了,锁也不能被其他客户端获取到

格式:setnx key value
将key的值设为value,当且仅当key不存在。
若给定的key已经存在,则setnx不做任何动作。
setnx是【set if not exists】(如果不存在,则set)的简写。
可用版本:>=1.0.0
Redis做分布式锁用什么命令?
setnx
格式:setnx key value 将 key的值设为value,当且仅当key不存在。若给定的key已经存在,则 setnx 不做任何东走,操作失败。
setnx 是【set if Not eXists】(如果不存在,则SET)的简写。
加锁:set key value nx ex 10s
释放锁:delete key
Redis做分布式锁死锁有哪些情况,如何解决?
情况1:加锁,没有释放锁。需要加释放锁的操作。比如 delete key。
情况2:加锁后,程序还没有执行释放锁,程序挂了。需要用的key的过期机制。
Redis如何做分布式锁?
假设有两个服务A、B都希望获得锁,执行过程大致如下:
Step1:服务A为了获得锁,向Redis发送如下命令:set productid:lock 0xx9p03001 nx ex 30000 其中,"productid"由自己定义,可以是与本次业务有关的id,"0xx9p03001"是一串随机值,必须保证全局唯一,“nx"指的是当且仅当key(也就是案例中的"productid:lock”)在Redis中ub存在时,返回执行成功,否则执行失败。“ex 30000” 指的是在30秒后,key将被自动删除。执行命令返回成功,表明服务成功的获得了锁。
Step2:服务B为了获得锁,向Redis发起同样的命令:set productid:lock 0000111 nx ex 30000,由于Redis内已经存在同名key,且并未过期,因此命令执行失败,服务B未能获得锁。服务B进入循环请求状态,比如每隔1秒钟(自行设置)向Redis发送请求,直到执行成功并获得锁。
Step3:服务A的业务代码执行执行时长超过了30秒,导致key超时,因此Redis自动删除了key。此时服务B再次发送命令执行成功,假设本次请求中设置的value值为0000222。此时需要在服务A中对key进行续期。
Step4:服务A执行完毕,为了释放锁,服务A会主动向Redis发起删除key的请求。注意:在删除key之前,一定要判断服务A持有的value与Redis内存储的value是否一致。比如当前场景下,Redis中的锁早就不是服务A持有的那一把了,而是由服务2创建,如果贸然使用服务A持有的key来删除锁,则会误会服务2的锁释放掉。此外,由于删除锁时涉及到一系列判断逻辑,因此一般使用lua脚本,具体如下:
if redis.call("get",keys[1])==argv[1] thenreturn redis.call("del",keys[1])
elsereturn 0
end
Redis分布式锁实现:
setnx+setex:存在设置超时时间失败的情况,导致死锁
set(key,value,nx,px):将setnx+setex变成原子操作
问题:
- 任务超时,锁自动释放,导致并发问题。使用redisson解决(看门狗监听,自动续期)
- 以及锁和释放锁不是同一个线程的问题。在value中存入uuid(线程唯一标识),删除锁时判断该标识(使用lua保证原子操作)
- 不可重入,使用redisson解决(实现机制类似AQS,计数)
- 异步复制可能造成锁丢失,使用redLock解决
1、顺序向五个节点请求加锁
2、根据一定的超时时间来推断是不是跳过该节点
3、三个节点加锁成功并且花费时间小于锁的有效期
4、认定加锁成功
分布式锁:代码实现
获取锁使用命令:
SET resource_name my_random_value NX PX 30000
方案:
try{lock = redisTemplate.opsForValue().setIfAbsent(lockKey, LOCK);logger.info("cancelCouponCode是否获取到锁:"+lock);if (lock) {// TODOredisTemplate.expire(lockKey,1, TimeUnit.MINUTES); //成功设置过期时间return res;}else {logger.info("cancelCouponCode没有获取到锁,不执行任务!");}
}finally{if(lock){ redisTemplate.delete(lockKey);logger.info("cancelCouponCode任务结束,释放锁!"); }else{logger.info("cancelCouponCode没有获取到锁,无需释放锁!");}
}
缺点:
在这种场景(主从结构)中存在明显的竞态:
- 客户端A从master获取到锁,
- 在master将锁同步到slave之前,master宕掉了。
- slave节点被晋级为master节点,
- 客户端B取得了同一个资源被客户端A已经获取到的另外一个锁。安全失效!
下面以减库存接口为例子,访问接口的时候自动减商品的库存
方案一:
@Service
public class RedisLockDemo {@Autowiredprivate StringRedisTemplate redisTemplate;public String deduceStock() {ValueOperations<String, String> valueOperations = redisTemplate.opsForValue();//获取redis中的库存int stock = Integer.valueOf(valueOperations.get("stock"));if (stock > 0) {int newStock = stock - 1;valueOperations.set("stock", newStock + "");System.out.println("扣减库存成功, 剩余库存:" + newStock);} else {System.out.println("库存已经为0,不能继续扣减");}return "success";}
}
表示:
- 先从Redis中读取stock的值,表示商品的库存
- 判断商品库存是否大于0,如果大于0,则库存减1,然后再保存到Redis里面去,否则就报错
1. 改进
方案一这种简单的从Redis读取、判断值再减1保存到Redis的操作,很容易在并发场景下出问题:商品超卖。
比如:假设商品的库存有50个,有3个用户同时访问该接口,先是同时读取Redis中商品的库存值,即都是读取到了50,即同时执行到了这一行:
int stock = Integer.valueOf(valueOperations.get("stock"));
然后减1,即到了这一行:
int newStock = stock - 1;
此时3个用户的realStock都是49,然后3个用户都去设置stock为49,那么就会产生库存明明被3个用户抢了,理论上是应该减去3的,结果库存数只减去了1导致商品超卖。
这种问题的产生原因是因为读取库存、减库存、保存到Redis这几步并不是原子操作
那么可以使用加并发锁synchronized来解决:
@Service
public class RedisLockDemo {@Autowiredprivate StringRedisTemplate redisTemplate;public String deduceStock() {ValueOperations<String, String> valueOperations = redisTemplate.opsForValue();synchronized (this) {//获取redis中的库存int stock = Integer.valueOf(valueOperations.get("stock"));if (stock > 0) {int newStock = stock - 1;valueOperations.set("stock", newStock + "");System.out.println("扣减库存成功, 剩余库存:" + newStock);} else {System.out.println("库存已经为0,不能继续扣减");}}return "success";}
}
注意:在Java中关键字synchronized可以保证在同一时刻,只有一个线程可以执行某个方法或某个代码块。
2. 再改进
以上的代码在单体模式下并没太大问题,但是在分布式或集群架构环境下存在问题,比如架构如下:
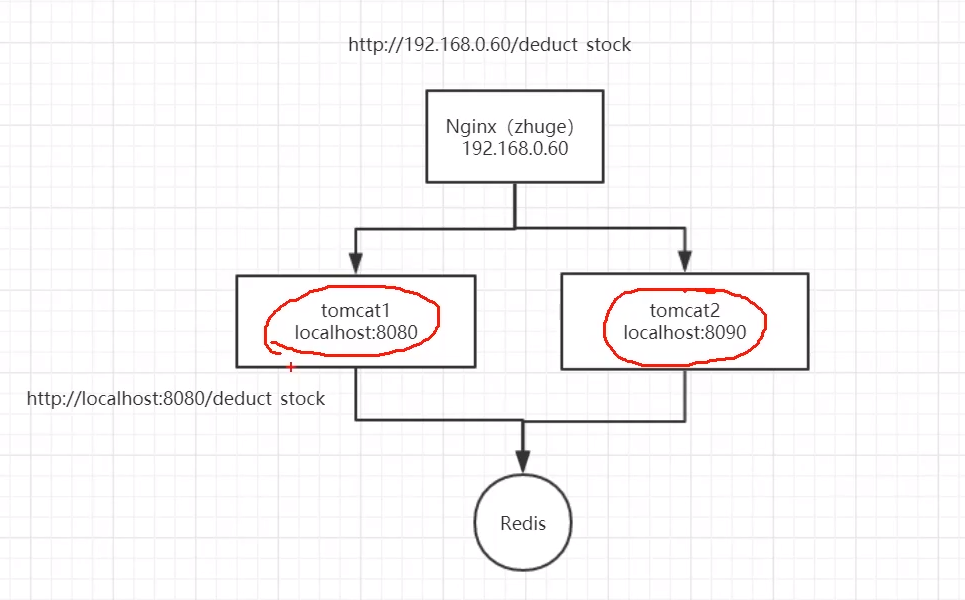
在分布式或集群架构下,synchronized只能保证当前的主机在同一时刻只能有一个线程执行减库存操作,但如图同时有多个请求过来访问的时候,不同主机在同一时刻依然是可以访问减库存接口的,这就导致问题1(商品超卖)在集群架构下依然存在。
注意:可以使用JMeter来模拟出高并发场景下访问Nginx来测试触发上面的问题
解决方法
使用如下的分布式锁进行解决
注意:方案一并不能称之为分布式锁的
方案二:
分布式锁的简单实现如图:
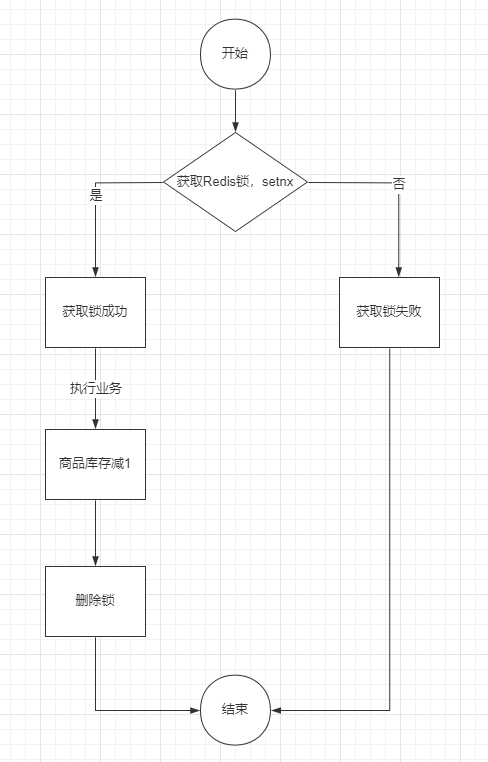
代码实现如下:
@Service
public class RedisLockDemo {@Autowiredprivate StringRedisTemplate redisTemplate;public String deduceStock() {ValueOperations<String, String> valueOperations = redisTemplate.opsForValue();String lockKey = "product_001";//加锁: setnxBoolean isSuccess = valueOperations.setIfAbsent(lockKey, "1");if(null == isSuccess || isSuccess) {System.out.println("服务器繁忙, 请稍后重试");return "error";}//------ 执行业务逻辑 ----start------int stock = Integer.valueOf(valueOperations.get("stock"));if (stock > 0) {int newStock = stock - 1;//执行业务操作减库存valueOperations.set("stock", newStock + "");System.out.println("扣减库存成功, 剩余库存:" + newStock);} else {System.out.println("库存已经为0,不能继续扣减");}//------ 执行业务逻辑 ----end------//释放锁redisTemplate.delete(lockKey);return "success";}
}
其实就是对每一个商品加一把锁,代码里面是product_001
- 使用setnx对商品进行加锁
- 如成功说明加锁成功,如失败说明有其他请求抢占了该商品的锁,则当前请求失败退出
- 加锁成功之后进行扣减库存操作
- 删除商品锁
1.改进1
上面的方式是有可能会造成死锁的,比如说加锁成功之后,扣减库存的逻辑可能抛异常了,即并不会执行到释放锁的逻辑,那么该商品锁是一直没有释放,会成为死锁的,其他请求完全无法扣减该商品的
使用try...catch...finally的方式可以解决抛异常的问题,如下:
@Service
public class RedisLockDemo {@Autowiredprivate StringRedisTemplate redisTemplate;public String deduceStock() {ValueOperations<String, String> valueOperations = redisTemplate.opsForValue();String lockKey = "product_001";try {//加锁: setnxBoolean isSuccess = valueOperations.setIfAbsent(lockKey, "1");if(null == isSuccess || isSuccess) {System.out.println("服务器繁忙, 请稍后重试");return "error";}//------ 执行业务逻辑 ----start------int stock = Integer.valueOf(valueOperations.get("stock"));if (stock > 0) {int newStock = stock - 1;//执行业务操作减库存valueOperations.set("stock", newStock + "");System.out.println("扣减库存成功, 剩余库存:" + newStock);} else {System.out.println("库存已经为0,不能继续扣减");}//------ 执行业务逻辑 ----end------} finally {//释放锁redisTemplate.delete(lockKey);}return "success";}
}
把释放锁的逻辑放到finally里面去,即不管try里面的逻辑最终是成功还是失败都会执行释放锁的逻辑
2.改进2
那么上面的方式是不是能够解决死锁的问题呢?
其实不然,除了抛异常之外,比如程序崩溃、服务器宕机、服务器重启、请求超时被终止、发布、人为kill等都有可能导致释放锁的逻辑没有执行,比如对商品加分布式锁成功之后,在扣减库存的时候服务器正在执行重启,会导致没有执行释放锁。
可以通过对锁设置超时时间来防止死锁的发生,使用Redis的expire命令可以对key进行设置超时时间,如图:
代码实现如下:
@Service
public class RedisLockDemo {@Autowiredprivate StringRedisTemplate redisTemplate;public String deduceStock() {ValueOperations<String, String> valueOperations = redisTemplate.opsForValue();String lockKey = "product_001";try {//加锁: setnxBoolean isSuccess = valueOperations.setIfAbsent(lockKey, "1");//expire增加超时时间redisTemplate.expire(lockKey, 10, TimeUnit.SECONDS);if(null == isSuccess || isSuccess) {System.out.println("服务器繁忙, 请稍后重试");return "error";}//------ 执行业务逻辑 ----start------int stock = Integer.valueOf(valueOperations.get("stock"));if (stock > 0) {int newStock = stock - 1;//执行业务操作减库存valueOperations.set("stock", newStock + "");System.out.println("扣减库存成功, 剩余库存:" + newStock);} else {System.out.println("库存已经为0,不能继续扣减");}//------ 执行业务逻辑 ----end------} finally {//释放锁redisTemplate.delete(lockKey);}return "success";}
}
加锁成功之后,把锁的超时时间设置为10秒,即10秒之后自动会释放锁,避免死锁的发生。
3. 改进3
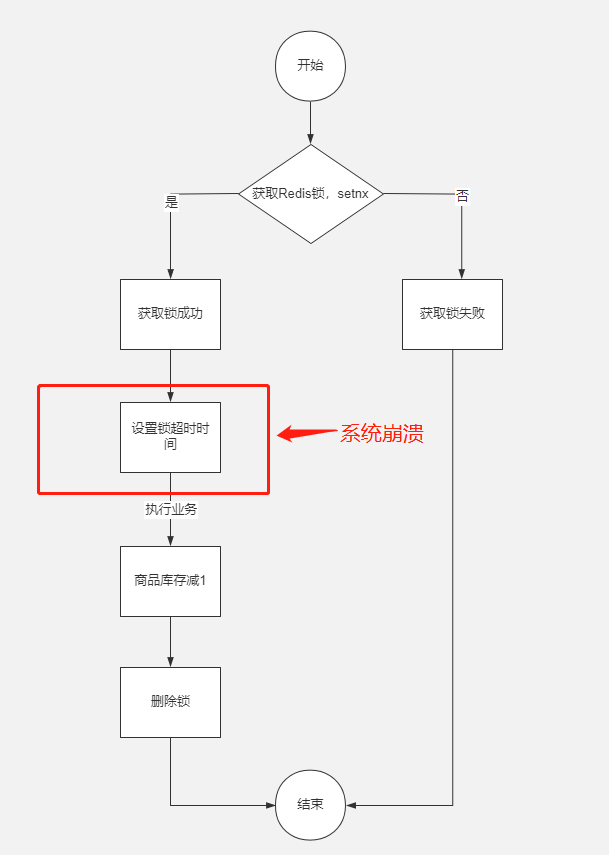
但是上面的方式同样会产生死锁问题,加锁和对锁设置超时时间并不是原子操作,在加锁成功之后,即将执行设置超时时间的时候系统发生崩溃,同样还是会导致死锁。
如图:
对此,有两种做法:
- lua脚本
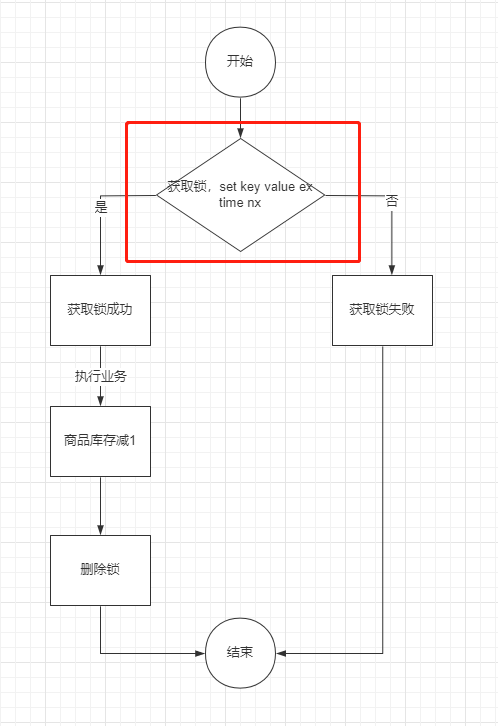
- set原生命令(Redis 2.6.12版本及以上)
一般是推荐使用set命令,Redis官方在2.6.12版本对set命令增加了NX、EX、PX等参数,即可以将上面的加锁和设置时间放到一条命令上执行,通过set命令即可:
命令官方文档:https://redis.io/commands/set
用法可参考:Redis命令参考
如图:

SET key value NX 等同于 SETNX key value命令,并且可以使用EX参数来设置过期时间
注意:其实目前在Redis 2.6.12版本之后,所说的setnx命令,并非单单指Redis的SETNX key value命令,一般是代指Redis中对set命令加上nx参数进行使用,一般不会直接使用SETNX key value命令了
注意:Redis2.6.12之前的版本,只能通过lua脚本来保证原子性了。
如图:
代码实现如下:
@Service
public class RedisLockDemo {@Autowiredprivate StringRedisTemplate redisTemplate;public String deduceStock() {ValueOperations<String, String> valueOperations = redisTemplate.opsForValue();String lockKey = "product_001";try {//加锁: setnx 和 expire增加超时时间Boolean isSuccess = valueOperations.setIfAbsent(lockKey, "1", 10, TimeUnit.SECONDS);if(null == isSuccess || isSuccess) {System.out.println("服务器繁忙, 请稍后重试");return "error";}//------ 执行业务逻辑 ----start------int stock = Integer.valueOf(valueOperations.get("stock"));if (stock > 0) {int newStock = stock - 1;//执行业务操作减库存valueOperations.set("stock", newStock + "");System.out.println("扣减库存成功, 剩余库存:" + newStock);} else {System.out.println("库存已经为0,不能继续扣减");}//------ 执行业务逻辑 ----end------} finally {//释放锁redisTemplate.delete(lockKey);}return "success";}
}
4. 改进4
以上的方式其实还是存在着问题,在高并发场景下会存在问题,超时时间设置不合理导致的问题
大概的流程图可参考:
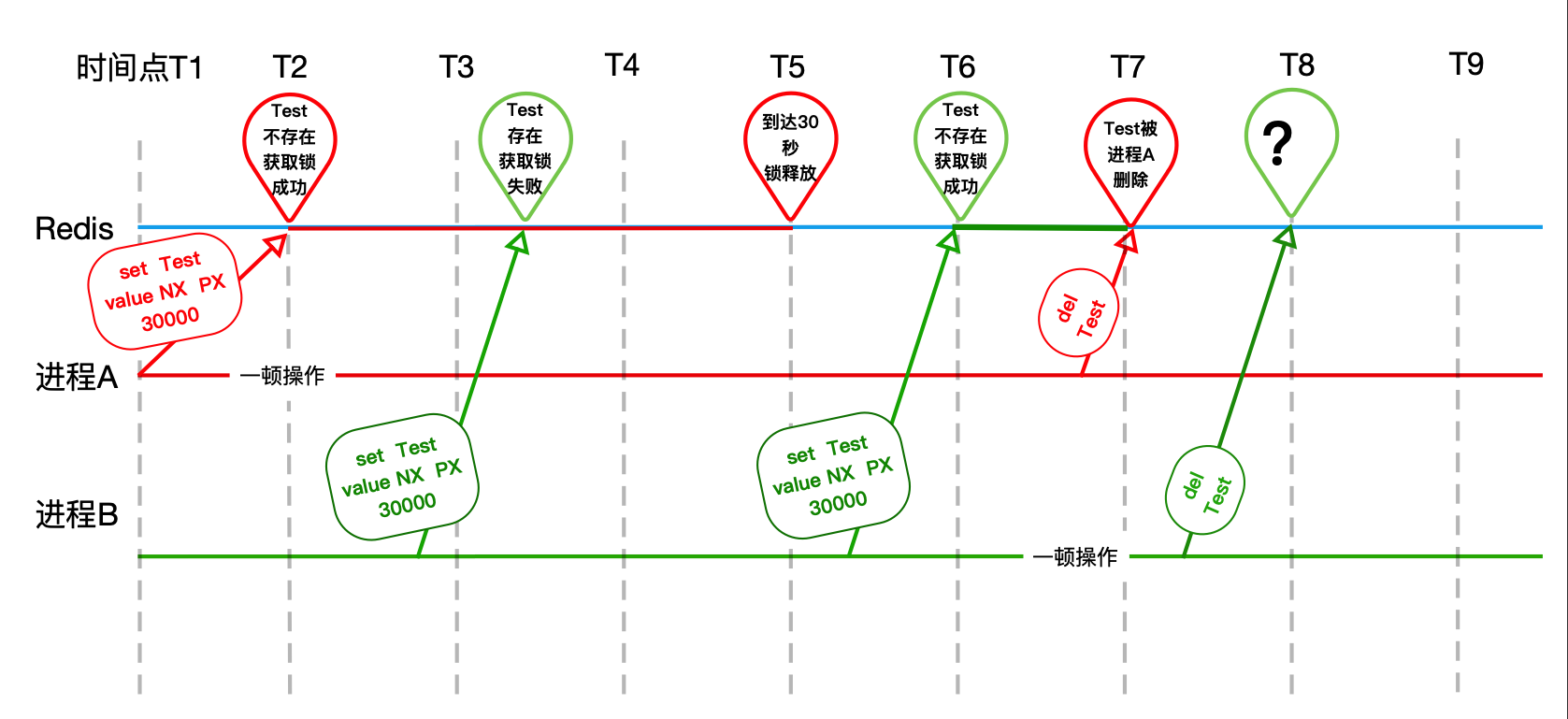
流程:
- 进程A加锁之后,扣减库存的时间超过设置的超时时间,这里设置的锁是10秒
- 在第10秒的时候由于时间到期了所以进程A设置的锁被Redis释放了(T5)
- 刚好进程B请求进来了,加锁成功(T6)
- 进程A操作完成(扣减库存)之后,把进程B设置的锁给释放了
- 刚好进程C请求进来了,加锁成功
- 进程B操作完成之后,也把进程C设置的锁给释放了
- 以此类推…
解决方法也很简单:
- 加锁的时候,把值设置为唯一值,比如说UUID这种随机数
- 释放锁的时候,获取锁的值判断value是不是当前进程设置的唯一值,如果是再去删除
如图:
代码如下:
@Service
public class RedisLockDemo {@Autowiredprivate StringRedisTemplate redisTemplate;public String deduceStock() {ValueOperations<String, String> valueOperations = redisTemplate.opsForValue();String lockKey = "product_001";String clientId = UUID.randomUUID().toString();try {//加锁: setnx 和 expire增加超时时间Boolean isSuccess = valueOperations.setIfAbsent(lockKey, clientId, 10, TimeUnit.SECONDS);if(null == isSuccess || isSuccess) {System.out.println("服务器繁忙, 请稍后重试");return "error";}//------ 执行业务逻辑 ----start------int stock = Integer.valueOf(valueOperations.get("stock"));if (stock > 0) {int newStock = stock - 1;//执行业务操作减库存valueOperations.set("stock", newStock + "");System.out.println("扣减库存成功, 剩余库存:" + newStock);} else {System.out.println("库存已经为0,不能继续扣减");}//------ 执行业务逻辑 ----end------} finally {if (clientId.equals(valueOperations.get(lockKey))) {//释放锁redisTemplate.delete(lockKey);}}return "success";}
}
5. 改进5
上面的方式其实存在一个明显的问题,就是在finally代码块中,释放锁的时候,get和del并非原子操作,存在进程安全问题。
那么删除锁的正确姿势是使用lua脚本,通过redis的eval/evalsha命令来运行:
-- lua删除锁:
-- KEYS和ARGV分别是以集合方式传入的参数,对应上文的Test和uuid。
-- 如果对应的value等于传入的uuid。
if redis.call('get', KEYS[1]) == ARGV[1] then -- 执行删除操作return redis.call('del', KEYS[1]) else -- 不成功,返回0return 0
end
通俗一点的说,即lua脚本能够保证原子性,在lua脚本里执行是一个命令(eval/evalsha)去执行的,一条命令没有执行完,其他客户端是看不到的。
到此,基本上Redis的分布式锁的实现思想如下:
- 获取锁的时候,使用setnx加锁,并使用expire命令为锁添加一个超时时间,超过该时间则自动释放锁,锁的value值为一个随机生成的UUID,通过此在释放锁的时候进行判断。
- 获取锁的时候还设置一个获取的超时时间,若超过这个时间则放弃获取锁。
- 释放锁的时候,通过UUID判断是不是该锁,若是该锁,则执行delete进行锁释放。
6.改进6
虽然通过上面的方式解决了会删除其他进程的锁的问题,但是超时时间的设置依然是没有解决的,设置成多少依然是个比较棘手的问题,设置少了容易导致业务没有执行完锁就被释放了,而设置过大万一服务出现异常无法正常释放锁会导致出现异常锁的时间也很长。
怎么解决这个问题呢?
目前大公司的一个方案是这样子的:
- 在加锁成功之后,启动一个守护线程
- 守护线程每隔1/3的锁的超时时间就去延迟锁的超时时间,比如说锁设置为30秒,那就是每隔10秒就去延长锁的超时时间,重新设置为30秒
- 业务代码执行完成,关闭守护线程
在实际操作中,需要注意几点:
- 只续对的:和释放锁一样,需要判断锁的对象有没有发生变化,否则会造成无论谁加锁,守护线程都会重新设置锁的超时时间
- 不能动不动就续:守护线程要在合理的时间再去设置锁的超时时间,否则会造成资源的浪费
- 及时销毁:如果加锁的线程/进程已经处理完业务了,那么守护进程应该被销毁,否则会造成资源的浪费
方案三:
上面的方案还得考虑Redis的部署问题。
众所周知,Redis有3种部署方式:
- 单机模式
- Master-Slave + Sentinel(哨兵)选举模式
- Redis Cluster(集群)模式
使用 Redis 做分布式锁的缺点在于:如果采用单机部署模式,会存在单点问题,只要 Redis 故障了。加锁就不行了。
采用 Master-Slave 模式/集群模式,如下:
线程1加了锁去执行业务了
刚好Redis的 master 发生故障挂掉了,此时还没有将数据同步到 slave 上
集群会选举一个新的 master 出来,但是新的 master 上并没有这个锁
线程2可以在新选举产生的 master 上去加锁,然后处理业务
这样的话,就导致了两个线程同时持有了锁,锁就不再具有安全性。
针对这个问题,有两个解决方案:
- RedLock
- Zookeeper【推荐】
1. RedLock
红锁
Redis官网的Redlock:https://redis.io/topics/distlock
基于以上的考虑,Redis的作者提出了一个RedLock的算法。
这个算法的意思大概是这样的:假设 Redis 的部署模式是 Redis Cluster,总共有 5 个 Master 节点。
通过以下步骤获取一把锁:
- 获取当前时间戳,单位是毫秒。
- 轮流尝试在每个 Master 节点上创建锁,过期时间设置较短,一般就几十毫秒。
- 尝试在大多数节点上建立一个锁,比如 5 个节点就要求是 3 个节点(n / 2 +1)。
- 客户端计算建立好锁的时间,如果建立锁的时间小于超时时间,就算建立成功了。
- 要是锁建立失败了,那么就依次删除这个锁。
- 只要别人建立了一把分布式锁,你就得不断轮询去尝试获取锁。
如图:
但是这样的这种算法还是颇具争议的,可能还会存在不少的问题,无法保证加锁的过程一定正确,不太推荐。

方案四:
组件依赖:首先我们要通过Maven引入Jedis开源组件,在pom.xml文件加入下面的代码:
<dependency><groupId>redis.clients</groupId><artifactId>jedis</artifactId><version>2.9.0</version>
</dependency>
加锁代码
正确姿势
Talk is cheap, show me the code。先展示代码,再带大家慢慢解释为什么这样实现:
public class RedisTool {private static final String LOCK_SUCCESS = "OK";private static final String SET_IF_NOT_EXIST = "NX";private static final String SET_WITH_EXPIRE_TIME = "PX";/*** 尝试获取分布式锁* @param jedis Redis客户端* @param lockKey 锁* @param requestId 请求标识* @param expireTime 超期时间* @return 是否获取成功*/public static boolean tryGetDistributedLock(Jedis jedis, String lockKey, String requestId, int expireTime) {String result = jedis.set(lockKey, requestId, SET_IF_NOT_EXIST, SET_WITH_EXPIRE_TIME, expireTime);if (LOCK_SUCCESS.equals(result)) {return true;}return false;}}
可以看到,我们加锁就一行代码:jedis.set(String key, String value, String nxxx, String expx, int time),这个set()方法一共有五个形参:
- 第一个为key,我们使用key来当锁,因为key是唯一的。
- 第二个为value,我们传的是requestId,很多童鞋可能不明白,有key作为锁不就够了吗,为什么还要用到value?原因就是我们在上面讲到可靠性时,分布式锁要满足第四个条件解铃还须系铃人,通过给value赋值为requestId,我们就知道这把锁是哪个请求加的了,在解锁的时候就可以有依据。requestId可以使用
UUID.randomUUID().toString()方法生成。 - 第三个为nxxx,这个参数我们填的是NX,意思是SET IF NOT EXIST,即当key不存在时,我们进行set操作;若key已经存在,则不做任何操作;
- 第四个为expx,这个参数我们传的是PX,意思是我们要给这个key加一个过期的设置,具体时间由第五个参数决定。
- 第五个为time,与第四个参数相呼应,代表key的过期时间。
总的来说,执行上面的set()方法就只会导致两种结果:1. 当前没有锁(key不存在),那么就进行加锁操作,并对锁设置个有效期,同时value表示加锁的客户端。2. 已有锁存在,不做任何操作。
心细的童鞋就会发现了,我们的加锁代码满足我们可靠性里描述的三个条件。首先,set()加入了NX参数,可以保证如果已有key存在,则函数不会调用成功,也就是只有一个客户端能持有锁,满足互斥性。其次,由于我们对锁设置了过期时间,即使锁的持有者后续发生崩溃而没有解锁,锁也会因为到了过期时间而自动解锁(即key被删除),不会发生死锁。最后,因为我们将value赋值为requestId,代表加锁的客户端请求标识,那么在客户端在解锁的时候就可以进行校验是否是同一个客户端。由于我们只考虑Redis单机部署的场景,所以容错性我们暂不考虑。
错误示例1
比较常见的错误示例就是使用jedis.setnx()和jedis.expire()组合实现加锁,代码如下:
public static void wrongGetLock1(Jedis jedis, String lockKey, String requestId, int expireTime) {Long result = jedis.setnx(lockKey, requestId);if (result == 1) {// 若在这里程序突然崩溃,则无法设置过期时间,将发生死锁jedis.expire(lockKey, expireTime);}}
setnx()方法作用就是SET IF NOT EXIST,expire()方法就是给锁加一个过期时间。乍一看好像和前面的set()方法结果一样,然而由于这是两条Redis命令,不具有原子性,如果程序在执行完setnx()之后突然崩溃,导致锁没有设置过期时间。那么将会发生死锁。网上之所以有人这样实现,是因为低版本的jedis并不支持多参数的set()方法。
错误示例2
这一种错误示例就比较难以发现问题,而且实现也比较复杂。实现思路:使用jedis.setnx()命令实现加锁,其中key是锁,value是锁的过期时间。执行过程:1. 通过setnx()方法尝试加锁,如果当前锁不存在,返回加锁成功。2. 如果锁已经存在则获取锁的过期时间,和当前时间比较,如果锁已经过期,则设置新的过期时间,返回加锁成功。代码如下:
public static boolean wrongGetLock2(Jedis jedis, String lockKey, int expireTime) {long expires = System.currentTimeMillis() + expireTime;String expiresStr = String.valueOf(expires);// 如果当前锁不存在,返回加锁成功if (jedis.setnx(lockKey, expiresStr) == 1) {return true;}// 如果锁存在,获取锁的过期时间String currentValueStr = jedis.get(lockKey);if (currentValueStr != null && Long.parseLong(currentValueStr) < System.currentTimeMillis()) {// 锁已过期,获取上一个锁的过期时间,并设置现在锁的过期时间String oldValueStr = jedis.getSet(lockKey, expiresStr);if (oldValueStr != null && oldValueStr.equals(currentValueStr)) {// 考虑多线程并发的情况,只有一个线程的设置值和当前值相同,它才有权利加锁return true;}}// 其他情况,一律返回加锁失败return false;}
那么这段代码问题在哪里?1. 由于是客户端自己生成过期时间,所以需要强制要求分布式下每个客户端的时间必须同步。 2. 当锁过期的时候,如果多个客户端同时执行jedis.getSet()方法,那么虽然最终只有一个客户端可以加锁,但是这个客户端的锁的过期时间可能被其他客户端覆盖。3. 锁不具备拥有者标识,即任何客户端都可以解锁。
解锁代码
正确姿势
还是先展示代码,再带大家慢慢解释为什么这样实现:
public class RedisTool {private static final Long RELEASE_SUCCESS = 1L;/*** 释放分布式锁* @param jedis Redis客户端* @param lockKey 锁* @param requestId 请求标识* @return 是否释放成功*/public static boolean releaseDistributedLock(Jedis jedis, String lockKey, String requestId) {String script = "if redis.call('get', KEYS[1]) == ARGV[1] then return redis.call('del', KEYS[1]) else return 0 end";Object result = jedis.eval(script, Collections.singletonList(lockKey), Collections.singletonList(requestId));if (RELEASE_SUCCESS.equals(result)) {return true;}return false;}}
可以看到,我们解锁只需要两行代码就搞定了!第一行代码,我们写了一个简单的Lua脚本代码,上一次见到这个编程语言还是在《黑客与画家》里,没想到这次居然用上了。第二行代码,我们将Lua代码传到jedis.eval()方法里,并使参数KEYS[1]赋值为lockKey,ARGV[1]赋值为requestId。eval()方法是将Lua代码交给Redis服务端执行。
那么这段Lua代码的功能是什么呢?其实很简单,首先获取锁对应的value值,检查是否与requestId相等,如果相等则删除锁(解锁)。那么为什么要使用Lua语言来实现呢?因为要确保上述操作是原子性的。关于非原子性会带来什么问题,可以阅读【解锁代码-错误示例2】 。
简单来说,就是在eval命令执行Lua代码的时候,Lua代码将被当成一个命令去执行,并且直到eval命令执行完成,Redis才会执行其他命令。
错误示例1
最常见的解锁代码就是直接使用jedis.del()方法删除锁,这种不先判断锁的拥有者而直接解锁的方式,会导致任何客户端都可以随时进行解锁,即使这把锁不是它的。
public static void wrongReleaseLock1(Jedis jedis, String lockKey) {jedis.del(lockKey);
}
错误示例2
这种解锁代码乍一看也是没问题,甚至我之前也差点这样实现,与正确姿势差不多,唯一区别的是分成两条命令去执行,代码如下:
public static void wrongReleaseLock2(Jedis jedis, String lockKey, String requestId) {// 判断加锁与解锁是不是同一个客户端if (requestId.equals(jedis.get(lockKey))) {// 若在此时,这把锁突然不是这个客户端的,则会误解锁jedis.del(lockKey);}}
如代码注释,问题在于如果调用jedis.del()方法的时候,这把锁已经不属于当前客户端的时候会解除他人加的锁。那么是否真的有这种场景?答案是肯定的,比如客户端A加锁,一段时间之后客户端A解锁,在执行jedis.del()之前,锁突然过期了,此时客户端B尝试加锁成功,然后客户端A再执行del()方法,则将客户端B的锁给解除了。
总结
本文主要介绍了如何使用Java代码正确实现Redis分布式锁,对于加锁和解锁也分别给出了两个比较经典的错误示例。其实想要通过Redis实现分布式锁并不难,只要保证能满足可靠性里的四个条件。互联网虽然给我们带来了方便,只要有问题就可以google,然而网上的答案一定是对的吗?其实不然,所以我们更应该时刻保持着质疑精神,多想多验证。
如果你的项目中Redis是多机部署的,那么可以尝试使用Redisson实现分布式锁,这是Redis官方提供的Java组件。
秒杀方案:
最近在项目中遇到了类似“秒杀”的业务场景,在本篇博客中,我将用一个非常简单的demo,阐述实现所谓“秒杀”的基本思路。
业务场景:
所谓秒杀,从业务角度看,是短时间内多个用户“争抢”资源,这里的资源在大部分秒杀场景里是商品;将业务抽象,技术角度看,秒杀就是多个线程对资源进行操作,所以实现秒杀,就必须控制线程对资源的争抢,既要保证高效并发,也要保证操作的正确。
一些可能的实现
刚才提到过,实现秒杀的关键点是控制线程对资源的争抢,根据基本的线程知识,可以不加思索的想到下面的一些方法:
1、秒杀在技术层面的抽象应该就是一个方法,在这个方法里可能的操作是将商品库存-1,将商品加入用户的购物车等等,在不考虑缓存的情况下应该是要操作数据库的。那么最简单直接的实现就是在这个方法上加上synchronized关键字,通俗的讲就是锁住整个方法;
2、锁住整个方法这个策略简单方便,但是似乎有点粗暴。可以稍微优化一下,只锁住秒杀的代码块,比如写数据库的部分;
3、既然有并发问题,那我就让他“不并发”,将所有的线程用一个队列管理起来,使之变成串行操作,自然不会有并发问题。
上面所述的方法都是有效的,但是都不好。为什么?第一和第二种方法本质上是“加锁”,但是锁粒度依然比较高。什么意思?试想一下,如果两个线程同时执行秒杀方法,这两个线程操作的是不同的商品,从业务上讲应该是可以同时进行的,但是如果采用第一二种方法,这两个线程也会去争抢同一个锁,这其实是不必要的。第三种方法也没有解决上面说的问题。
那么如何将锁控制在更细的粒度上呢?可以考虑为每个商品设置一个互斥锁,以和商品ID相关的字符串为唯一标识,这样就可以做到只有争抢同一件商品的线程互斥,不会导致所有的线程互斥。分布式锁恰好可以帮助我们解决这个问题。
何为分布式锁
分布式锁是控制分布式系统之间同步访问共享资源的一种方式。在分布式系统中,常常需要协调他们的动作。如果不同的系统或是同一个系统的不同主机之间共享了一个或一组资源,那么访问这些资源的时候,往往需要互斥来防止彼此干扰来保证一致性,在这种情况下,便需要使用到分布式锁。
我们来假设一个最简单的秒杀场景:数据库里有一张表,column分别是商品ID,和商品ID对应的库存量,秒杀成功就将此商品库存量-1。现在假设有1000个线程来秒杀两件商品,500个线程秒杀第一个商品,500个线程秒杀第二个商品。我们来根据这个简单的业务场景来解释一下分布式锁。
通常具有秒杀场景的业务系统都比较复杂,承载的业务量非常巨大,并发量也很高。这样的系统往往采用分布式的架构来均衡负载。那么这1000个并发就会是从不同的地方过来,商品库存就是共享的资源,也是这1000个并发争抢的资源,这个时候我们需要将并发互斥管理起来。这就是分布式锁的应用。
而key-value存储系统,如redis,因为其一些特性,是实现分布式锁的重要工具。
具体的实现
先来看看一些redis的基本命令:
SETNX key value
如果key不存在,就设置key对应字符串value。在这种情况下,该命令和SET一样。当key已经存在时,就不做任何操作。SETNX是”SET if Not eXists”。
expire KEY seconds
设置key的过期时间。如果key已过期,将会被自动删除。
del KEY
删除key
由于笔者的实现只用到这三个命令,就只介绍这三个命令,更多的命令以及redis的特性和使用,可以参考redis官网。
需要考虑的问题
1、用什么操作redis?幸亏redis已经提供了jedis客户端用于java应用程序,直接调用jedis API即可。
2、怎么实现加锁?“锁”其实是一个抽象的概念,将这个抽象概念变为具体的东西,就是一个存储在redis里的key-value对,key是于商品ID相关的字符串来唯一标识,value其实并不重要,因为只要这个唯一的key-value存在,就表示这个商品已经上锁。
3、如何释放锁?既然key-value对存在就表示上锁,那么释放锁就自然是在redis里删除key-value对。
4、阻塞还是非阻塞?笔者采用了阻塞式的实现,若线程发现已经上锁,会在特定时间内轮询锁。
5、如何处理异常情况?比如一个线程把一个商品上了锁,但是由于各种原因,没有完成操作(在上面的业务场景里就是没有将库存-1写入数据库),自然没有释放锁,这个情况笔者加入了锁超时机制,利用redis的expire命令为key设置超时时长,过了超时时间redis就会将这个key自动删除,即强制释放锁(可以认为超时释放锁是一个异步操作,由redis完成,应用程序只需要根据系统特点设置超时时间即可)。
talk is cheap,show me the code
在代码实现层面,注解有并发的方法和参数,通过动态代理获取注解的方法和参数,在代理中加锁,执行完被代理的方法后释放锁。
几个注解定义:
cachelock是方法级的注解,用于注解会产生并发问题的方法:
@Target(ElementType.METHOD)
@Retention(RetentionPolicy.RUNTIME)
@Documented
public @interface CacheLock {String lockedPrefix() default "";//redis 锁key的前缀long timeOut() default 2000;//轮询锁的时间int expireTime() default 1000;//key在redis里存在的时间,1000S
}
lockedObject是参数级的注解,用于注解商品ID等基本类型的参数:
@Target(ElementType.PARAMETER)
@Retention(RetentionPolicy.RUNTIME)
@Documented
public @interface LockedObject {//不需要值
}
LockedComplexObject也是参数级的注解,用于注解自定义类型的参数:
@Target(ElementType.PARAMETER)
@Retention(RetentionPolicy.RUNTIME)
@Documented
public @interface LockedComplexObject {String field() default "";//含有成员变量的复杂对象中需要加锁的成员变量,如一个商品对象的商品ID}
CacheLockInterceptor实现InvocationHandler接口,在invoke方法中获取注解的方法和参数,在执行注解的方法前加锁,执行被注解的方法后释放锁:
public class CacheLockInterceptor implements InvocationHandler{public static int ERROR_COUNT = 0;private Object proxied;public CacheLockInterceptor(Object proxied) {this.proxied = proxied;}@Overridepublic Object invoke(Object proxy, Method method, Object[] args) throws Throwable {CacheLock cacheLock = method.getAnnotation(CacheLock.class);//没有cacheLock注解,passif(null == cacheLock){System.out.println("no cacheLock annotation"); return method.invoke(proxied, args);}//获得方法中参数的注解Annotation[][] annotations = method.getParameterAnnotations();//根据获取到的参数注解和参数列表获得加锁的参数Object lockedObject = getLockedObject(annotations,args);String objectValue = lockedObject.toString();//新建一个锁RedisLock lock = new RedisLock(cacheLock.lockedPrefix(), objectValue);//加锁boolean result = lock.lock(cacheLock.timeOut(), cacheLock.expireTime());if(!result){//取锁失败ERROR_COUNT += 1;throw new CacheLockException("get lock fail");}try{//加锁成功,执行方法return method.invoke(proxied, args);}finally{lock.unlock();//释放锁}}/*** * @param annotations* @param args* @return* @throws CacheLockException*/private Object getLockedObject(Annotation[][] annotations,Object[] args) throws CacheLockException{if(null == args || args.length == 0){throw new CacheLockException("方法参数为空,没有被锁定的对象");}if(null == annotations || annotations.length == 0){throw new CacheLockException("没有被注解的参数");}//不支持多个参数加锁,只支持第一个注解为lockedObject或者lockedComplexObject的参数int index = -1;//标记参数的位置指针for(int i = 0;i < annotations.length;i++){for(int j = 0;j < annotations[i].length;j++){if(annotations[i][j] instanceof LockedComplexObject){//注解为LockedComplexObjectindex = i;try {return args[i].getClass().getField(((LockedComplexObject)annotations[i][j]).field());} catch (NoSuchFieldException | SecurityException e) {throw new CacheLockException("注解对象中没有该属性" + ((LockedComplexObject)annotations[i][j]).field());}}if(annotations[i][j] instanceof LockedObject){index = i;break;}}//找到第一个后直接break,不支持多参数加锁if(index != -1){break;}}if(index == -1){throw new CacheLockException("请指定被锁定参数");}return args[index];}
}
最关键的RedisLock类中的lock方法和unlock方法:
/*** 加锁* 使用方式为:* lock();* try{* executeMethod();* }finally{* unlock();* }* @param timeout timeout的时间范围内轮询锁* @param expire 设置锁超时时间* @return 成功 or 失败*/public boolean lock(long timeout,int expire){long nanoTime = System.nanoTime();timeout *= MILLI_NANO_TIME;try {//在timeout的时间范围内不断轮询锁while (System.nanoTime() - nanoTime < timeout) {//锁不存在的话,设置锁并设置锁过期时间,即加锁if (this.redisClient.setnx(this.key, LOCKED) == 1) {this.redisClient.expire(key, expire);//设置锁过期时间是为了在没有释放//锁的情况下锁过期后消失,不会造成永久阻塞this.lock = true;return this.lock;}System.out.println("出现锁等待");//短暂休眠,避免可能的活锁Thread.sleep(3, RANDOM.nextInt(30));} } catch (Exception e) {throw new RuntimeException("locking error",e);}return false;}public void unlock() {try {if(this.lock){redisClient.delKey(key);//直接删除}} catch (Throwable e) {}}
上述的代码是框架性的代码,现在来讲解如何使用上面的简单框架来写一个秒杀函数。
先定义一个接口,接口里定义了一个秒杀方法:
public interface SeckillInterface {
/**
*现在暂时只支持在接口方法上注解
*///cacheLock注解可能产生并发的方法@CacheLock(lockedPrefix="TEST_PREFIX")public void secKill(String userID,@LockedObject Long commidityID);//最简单的秒杀方法,参数是用户ID和商品ID。可能有多个线程争抢一个商品,所以商品ID加上LockedObject注解
}
上述SeckillInterface接口的实现类,即秒杀的具体实现:
public class SecKillImpl implements SeckillInterface{static Map<Long, Long> inventory ;static{inventory = new HashMap<>();inventory.put(10000001L, 10000l);inventory.put(10000002L, 10000l);}@Overridepublic void secKill(String arg1, Long arg2) {//最简单的秒杀,这里仅作为demo示例reduceInventory(arg2);}//模拟秒杀操作,姑且认为一个秒杀就是将库存减一,实际情景要复杂的多public Long reduceInventory(Long commodityId){inventory.put(commodityId,inventory.get(commodityId) - 1);return inventory.get(commodityId);}}
模拟秒杀场景,1000个线程来争抢两个商品:
@Testpublic void testSecKill(){int threadCount = 1000;int splitPoint = 500;CountDownLatch endCount = new CountDownLatch(threadCount);CountDownLatch beginCount = new CountDownLatch(1);SecKillImpl testClass = new SecKillImpl();Thread[] threads = new Thread[threadCount];//起500个线程,秒杀第一个商品for(int i= 0;i < splitPoint;i++){threads[i] = new Thread(new Runnable() {public void run() {try {//等待在一个信号量上,挂起beginCount.await();//用动态代理的方式调用secKill方法SeckillInterface proxy = (SeckillInterface) Proxy.newProxyInstance(SeckillInterface.class.getClassLoader(), new Class[]{SeckillInterface.class}, new CacheLockInterceptor(testClass));proxy.secKill("test", commidityId1);endCount.countDown();} catch (InterruptedException e) {// TODO Auto-generated catch blocke.printStackTrace();}}});threads[i].start();}//再起500个线程,秒杀第二件商品for(int i= splitPoint;i < threadCount;i++){threads[i] = new Thread(new Runnable() {public void run() {try {//等待在一个信号量上,挂起beginCount.await();//用动态代理的方式调用secKill方法SeckillInterface proxy = (SeckillInterface) Proxy.newProxyInstance(SeckillInterface.class.getClassLoader(), new Class[]{SeckillInterface.class}, new CacheLockInterceptor(testClass));proxy.secKill("test", commidityId2);//testClass.testFunc("test", 10000001L);endCount.countDown();} catch (InterruptedException e) {// TODO Auto-generated catch blocke.printStackTrace();}}});threads[i].start();}long startTime = System.currentTimeMillis();//主线程释放开始信号量,并等待结束信号量,这样做保证1000个线程做到完全同时执行,保证测试的正确性beginCount.countDown();try {//主线程等待结束信号量endCount.await();//观察秒杀结果是否正确System.out.println(SecKillImpl.inventory.get(commidityId1));System.out.println(SecKillImpl.inventory.get(commidityId2));System.out.println("error count" + CacheLockInterceptor.ERROR_COUNT);System.out.println("total cost " + (System.currentTimeMillis() - startTime));} catch (InterruptedException e) {// TODO Auto-generated catch blocke.printStackTrace();}}
在正确的预想下,应该每个商品的库存都减少了500,在多次试验后,实际情况符合预想。如果不采用锁机制,会出现库存减少499,498的情况。
这里采用了动态代理的方法,利用注解和反射机制得到分布式锁ID,进行加锁和释放锁操作。当然也可以直接在方法进行这些操作,采用动态代理也是为了能够将锁操作代码集中在代理中,便于维护。
通常秒杀场景发生在web项目中,可以考虑利用spring的AOP特性将锁操作代码置于切面中,当然AOP本质上也是动态代理。
小结
这篇文章从业务场景出发,从抽象到实现阐述了如何利用redis实现分布式锁,完成简单的秒杀功能,也记录了笔者思考的过程,希望能给阅读到本篇文章的人一些启发。
分布式锁:Redlock算法:
就像本文开头所讲的,借助Redis来实现一个分布式锁(Distributed Lock)的做法,已经有很多人尝试过。人们构建这样的分布式锁的目的,是为了对一些共享资源进行互斥访问。
但是,这些实现虽然思路大体相近,但实现细节上各不相同,它们能提供的安全性和可用性也不尽相同。所以,Redis的作者antirez给出了一个更好的实现,称为Redlock,算是Redis官方对于实现分布式锁的指导规范。
在Redlock之前,很多人对于分布式锁的实现都是基于单个Redis节点的。而Redlock是基于多个Redis节点(都是Master)的一种实现。为了能理解Redlock,我们首先需要把简单的基于单Redis节点的算法描述清楚,因为它是Redlock的基础。
基于单Redis节点的分布式锁
首先,Redis客户端为了获取锁,向Redis节点发送如下命令:
SET resource_name my_random_value NX PX 30000
上面的命令如果执行成功,则客户端成功获取到了锁,接下来就可以访问共享资源了;而如果上面的命令执行失败,则说明获取锁失败。
注意,在上面的SET命令中:
- my_random_value是由客户端生成的一个随机字符串,它要保证在足够长的一段时间内在所有客户端的所有获取锁的请求中都是唯一的。
- NX表示只有当resource_name对应的key值不存在的时候才能SET成功。这保证了只有第一个请求的客户端才能获得锁,而其它客户端在锁被释放之前都无法获得锁。
- PX 30000表示这个锁有一个30秒的自动过期时间。当然,这里30秒只是一个例子,客户端可以选择合适的过期时间。
最后,当客户端完成了对共享资源的操作之后,执行下面的Redis Lua脚本来释放锁:
if redis.call("get",KEYS[1]) == ARGV[1] thenreturn redis.call("del",KEYS[1])
elsereturn 0
end
这段Lua脚本在执行的时候要把前面的my_random_value作为ARGV[1]的值传进去,把resource_name作为KEYS[1]的值传进去。
至此,基于单Redis节点的分布式锁的算法就描述完了。这里面有好几个问题需要重点分析一下。
首先第一个问题,这个锁必须要设置一个过期时间。否则的话,当一个客户端获取锁成功之后,假如它崩溃了,或者由于发生了网络分割(network partition)导致它再也无法和Redis节点通信了,那么它就会一直持有这个锁,而其它客户端永远无法获得锁了。antirez在后面的分析中也特别强调了这一点,而且把这个过期时间称为锁的有效时间(lock validity time)。获得锁的客户端必须在这个时间之内完成对共享资源的访问。
第二个问题,第一步获取锁的操作,网上不少文章把它实现成了两个Redis命令:
SETNX resource_name my_random_value
EXPIRE resource_name 30
虽然这两个命令和前面算法描述中的一个SET命令执行效果相同,但却不是原子的。如果客户端在执行完SETNX后崩溃了,那么就没有机会执行EXPIRE了,导致它一直持有这个锁。
第三个问题,也是antirez指出的,设置一个随机字符串my_random_value是很有必要的,它保证了一个客户端释放的锁必须是自己持有的那个锁。假如获取锁时SET的不是一个随机字符串,而是一个固定值,那么可能会发生下面的执行序列:
- 客户端1获取锁成功。
- 客户端1在某个操作上阻塞了很长时间。
- 过期时间到了,锁自动释放了。
- 客户端2获取到了对应同一个资源的锁。
- 客户端1从阻塞中恢复过来,释放掉了客户端2持有的锁。
之后,客户端2在访问共享资源的时候,就没有锁为它提供保护了。
第四个问题,释放锁的操作必须使用Lua脚本来实现。释放锁其实包含三步操作:’GET’、判断和’DEL’,用Lua脚本来实现能保证这三步的原子性。否则,如果把这三步操作放到客户端逻辑中去执行的话,就有可能发生与前面第三个问题类似的执行序列:
- 客户端1获取锁成功。
- 客户端1访问共享资源。
- 客户端1为了释放锁,先执行’GET’操作获取随机字符串的值。
- 客户端1判断随机字符串的值,与预期的值相等。
- 客户端1由于某个原因阻塞住了很长时间。
- 过期时间到了,锁自动释放了。
- 客户端2获取到了对应同一个资源的锁。
- 客户端1从阻塞中恢复过来,执行
DEL操纵,释放掉了客户端2持有的锁。
实际上,在上述第三个问题和第四个问题的分析中,如果不是客户端阻塞住了,而是出现了大的网络延迟,也有可能导致类似的执行序列发生。
前面的四个问题,只要实现分布式锁的时候加以注意,就都能够被正确处理。但除此之外,antirez还指出了一个问题,是由failover引起的,却是基于单Redis节点的分布式锁无法解决的。正是这个问题催生了Redlock的出现。
这个问题是这样的。假如Redis节点宕机了,那么所有客户端就都无法获得锁了,服务变得不可用。为了提高可用性,我们可以给这个Redis节点挂一个Slave,当Master节点不可用的时候,系统自动切到Slave上(failover)。但由于Redis的主从复制(replication)是异步的,这可能导致在failover过程中丧失锁的安全性。考虑下面的执行序列:
- 客户端1从Master获取了锁。
- Master宕机了,存储锁的key还没有来得及同步到Slave上。
- Slave升级为Master。
- 客户端2从新的Master获取到了对应同一个资源的锁。
于是,客户端1和客户端2同时持有了同一个资源的锁。锁的安全性被打破。针对这个问题,antirez设计了Redlock算法,我们接下来会讨论。
【其它疑问】
前面这个算法中出现的锁的有效时间(lock validity time),设置成多少合适呢?如果设置太短的话,锁就有可能在客户端完成对于共享资源的访问之前过期,从而失去保护;如果设置太长的话,一旦某个持有锁的客户端释放锁失败,那么就会导致所有其它客户端都无法获取锁,从而长时间内无法正常工作。看来真是个两难的问题。
而且,在前面对于随机字符串my_random_value的分析中,antirez也在文章中承认的确应该考虑客户端长期阻塞导致锁过期的情况。如果真的发生了这种情况,那么共享资源是不是已经失去了保护呢?antirez重新设计的Redlock是否能解决这些问题呢?
分布式锁Redlock
由于前面介绍的基于单Redis节点的分布式锁在failover的时候会产生解决不了的安全性问题,因此antirez提出了新的分布式锁的算法Redlock,它基于N个完全独立的Redis节点(通常情况下N可以设置成5)。
运行Redlock算法的客户端依次执行下面各个步骤,来完成获取锁的操作:
- 获取当前时间(毫秒数)。
- 按顺序依次向N个Redis节点执行获取锁的操作。这个获取操作跟前面基于单Redis节点的获取锁的过程相同,包含随机字符串
my_random_value,也包含过期时间(比如PX 30000,即锁的有效时间)。为了保证在某个Redis节点不可用的时候算法能够继续运行,这个获取锁的操作还有一个超时时间(time out),它要远小于锁的有效时间(几十毫秒量级)。客户端在向某个Redis节点获取锁失败以后,应该立即尝试下一个Redis节点。这里的失败,应该包含任何类型的失败,比如该Redis节点不可用,或者该Redis节点上的锁已经被其它客户端持有(注:Redlock原文中这里只提到了Redis节点不可用的情况,但也应该包含其它的失败情况)。 - 计算整个获取锁的过程总共消耗了多长时间,计算方法是用当前时间减去第1步记录的时间。如果客户端从大多数Redis节点(>= N/2+1)成功获取到了锁,并且获取锁总共消耗的时间没有超过锁的有效时间(lock validity time),那么这时客户端才认为最终获取锁成功;否则,认为最终获取锁失败。
- 如果最终获取锁成功了,那么这个锁的有效时间应该重新计算,它等于最初的锁的有效时间减去第3步计算出来的获取锁消耗的时间。
- 如果最终获取锁失败了(可能由于获取到锁的Redis节点个数少于N/2+1,或者整个获取锁的过程消耗的时间超过了锁的最初有效时间),那么客户端应该立即向所有Redis节点发起释放锁的操作(即前面介绍的Redis Lua脚本)。
当然,上面描述的只是获取锁的过程,而释放锁的过程比较简单:客户端向所有Redis节点发起释放锁的操作,不管这些节点当时在获取锁的时候成功与否。
由于N个Redis节点中的大多数能正常工作就能保证Redlock正常工作,因此理论上它的可用性更高。我们前面讨论的单Redis节点的分布式锁在failover的时候锁失效的问题,在Redlock中不存在了,但如果有节点发生崩溃重启,还是会对锁的安全性有影响的。具体的影响程度跟Redis对数据的持久化程度有关。
假设一共有5个Redis节点:A, B, C, D, E。设想发生了如下的事件序列:
- 客户端1成功锁住了A, B, C,获取锁成功(但D和E没有锁住)。
- 节点C崩溃重启了,但客户端1在C上加的锁没有持久化下来,丢失了。
- 节点C重启后,客户端2锁住了C, D, E,获取锁成功。
这样,客户端1和客户端2同时获得了锁(针对同一资源)。
在默认情况下,Redis的AOF持久化方式是每秒写一次磁盘(即执行fsync),因此最坏情况下可能丢失1秒的数据。为了尽可能不丢数据,Redis允许设置成每次修改数据都进行fsync,但这会降低性能。当然,即使执行了fsync也仍然有可能丢失数据(这取决于系统而不是Redis的实现)。所以,上面分析的由于节点重启引发的锁失效问题,总是有可能出现的。为了应对这一问题,antirez又提出了延迟重启(delayed restarts)的概念。也就是说,一个节点崩溃后,先不立即重启它,而是等待一段时间再重启,这段时间应该大于锁的有效时间(lock validity time)。这样的话,这个节点在重启前所参与的锁都会过期,它在重启后就不会对现有的锁造成影响。
关于Redlock还有一点细节值得拿出来分析一下:在最后释放锁的时候,antirez在算法描述中特别强调,客户端应该向所有Redis节点发起释放锁的操作。也就是说,即使当时向某个节点获取锁没有成功,在释放锁的时候也不应该漏掉这个节点。这是为什么呢?设想这样一种情况,客户端发给某个Redis节点的获取锁的请求成功到达了该Redis节点,这个节点也成功执行了SET操作,但是它返回给客户端的响应包却丢失了。这在客户端看来,获取锁的请求由于超时而失败了,但在Redis这边看来,加锁已经成功了。因此,释放锁的时候,客户端也应该对当时获取锁失败的那些Redis节点同样发起请求。实际上,这种情况在异步通信模型中是有可能发生的:客户端向服务器通信是正常的,但反方向却是有问题的。
【其它疑问】
前面在讨论单Redis节点的分布式锁的时候,最后我们提出了一个疑问,如果客户端长期阻塞导致锁过期,那么它接下来访问共享资源就不安全了(没有了锁的保护)。这个问题在Redlock中是否有所改善呢?显然,这样的问题在Redlock中是依然存在的。
另外,在算法第4步成功获取了锁之后,如果由于获取锁的过程消耗了较长时间,重新计算出来的剩余的锁有效时间很短了,那么我们还来得及去完成共享资源访问吗?如果我们认为太短,是不是应该立即进行锁的释放操作?那到底多短才算呢?又是一个选择难题。
Martin的分析
Martin Kleppmann在2016-02-08这一天发表了一篇blog,名字叫”How to do distributed locking “,
地址:https://martin.kleppmann.com/2016/02/08/how-to-do-distributed-locking.html
Martin在这篇文章中谈及了分布式系统的很多基础性的问题(特别是分布式计算的异步模型),对分布式系统的从业者来说非常值得一读。这篇文章大体可以分为两大部分:
- 前半部分,与Redlock无关。Martin指出,即使我们拥有一个完美实现的分布式锁(带自动过期功能),在没有共享资源参与进来提供某种fencing机制的前提下,我们仍然不可能获得足够的安全性。
- 后半部分,是对Redlock本身的批评。Martin指出,由于Redlock本质上是建立在一个同步模型之上,对系统的记时假设(timing assumption)有很强的要求,因此本身的安全性是不够的。
首先我们讨论一下前半部分的关键点。Martin给出了下面这样一份时序图:

在上面的时序图中,假设锁服务本身是没有问题的,它总是能保证任一时刻最多只有一个客户端获得锁。上图中出现的lease这个词可以暂且认为就等同于一个带有自动过期功能的锁。客户端1在获得锁之后发生了很长时间的GC pause,在此期间,它获得的锁过期了,而客户端2获得了锁。当客户端1从GC pause中恢复过来的时候,它不知道自己持有的锁已经过期了,它依然向共享资源(上图中是一个存储服务)发起了写数据请求,而这时锁实际上被客户端2持有,因此两个客户端的写请求就有可能冲突(锁的互斥作用失效了)。
初看上去,有人可能会说,既然客户端1从GC pause中恢复过来以后不知道自己持有的锁已经过期了,那么它可以在访问共享资源之前先判断一下锁是否过期。但仔细想想,这丝毫也没有帮助。因为GC pause可能发生在任意时刻,也许恰好在判断完之后。
也有人会说,如果客户端使用没有GC的语言来实现,是不是就没有这个问题呢?Martin指出,系统环境太复杂,仍然有很多原因导致进程的pause,比如虚存造成的缺页故障(page fault),再比如CPU资源的竞争。即使不考虑进程pause的情况,网络延迟也仍然会造成类似的结果。
总结起来就是说,即使锁服务本身是没有问题的,而仅仅是客户端有长时间的pause或网络延迟,仍然会造成两个客户端同时访问共享资源的冲突情况发生。而这种情况其实就是我们在前面已经提出来的“客户端长期阻塞导致锁过期”的那个疑问。
那怎么解决这个问题呢?Martin给出了一种方法,称为fencing token。fencing token是一个单调递增的数字,当客户端成功获取锁的时候它随同锁一起返回给客户端。而客户端访问共享资源的时候带着这个fencing token,这样提供共享资源的服务就能根据它进行检查,拒绝掉延迟到来的访问请求(避免了冲突)。如下图:

在上图中,客户端1先获取到的锁,因此有一个较小的fencing token,等于33,而客户端2后获取到的锁,有一个较大的fencing token,等于34。客户端1从GC pause中恢复过来之后,依然是向存储服务发送访问请求,但是带了fencing token = 33。存储服务发现它之前已经处理过34的请求,所以会拒绝掉这次33的请求。这样就避免了冲突。
现在我们再讨论一下Martin的文章的后半部分。
Martin在文中构造了一些事件序列,能够让Redlock失效(两个客户端同时持有锁)。为了说明Redlock对系统记时(timing)的过分依赖,他首先给出了下面的一个例子(还是假设有5个Redis节点A, B, C, D, E):
- 客户端1从Redis节点A, B, C成功获取了锁(多数节点)。由于网络问题,与D和E通信失败。
- 节点C上的时钟发生了向前跳跃,导致它上面维护的锁快速过期。
- 客户端2从Redis节点C, D, E成功获取了同一个资源的锁(多数节点)。
- 客户端1和客户端2现在都认为自己持有了锁。
上面这种情况之所以有可能发生,本质上是因为Redlock的安全性(safety property)对系统的时钟有比较强的依赖,一旦系统的时钟变得不准确,算法的安全性也就保证不了了。Martin在这里其实是要指出分布式算法研究中的一些基础性问题,或者说一些常识问题,即好的分布式算法应该基于异步模型(asynchronous model),算法的安全性不应该依赖于任何记时假设(timing assumption)。在异步模型中:进程可能pause任意长的时间,消息可能在网络中延迟任意长的时间,甚至丢失,系统时钟也可能以任意方式出错。一个好的分布式算法,这些因素不应该影响它的安全性(safety property),只可能影响到它的活性(liveness property),也就是说,即使在非常极端的情况下(比如系统时钟严重错误),算法顶多是不能在有限的时间内给出结果而已,而不应该给出错误的结果。这样的算法在现实中是存在的,像比较著名的Paxos,或Raft。但显然按这个标准的话,Redlock的安全性级别是达不到的。
随后,Martin觉得前面这个时钟跳跃的例子还不够,又给出了一个由客户端GC pause引发Redlock失效的例子。如下:
- 客户端1向Redis节点A, B, C, D, E发起锁请求。
- 各个Redis节点已经把请求结果返回给了客户端1,但客户端1在收到请求结果之前进入了长时间的GC pause。
- 在所有的Redis节点上,锁过期了。
- 客户端2在A, B, C, D, E上获取到了锁。
- 客户端1从GC pause从恢复,收到了前面第2步来自各个Redis节点的请求结果。客户端1认为自己成功获取到了锁。
- 客户端1和客户端2现在都认为自己持有了锁。
Martin给出的这个例子其实有点小问题。在Redlock算法中,客户端在完成向各个Redis节点的获取锁的请求之后,会计算这个过程消耗的时间,然后检查是不是超过了锁的有效时间(lock validity time)。也就是上面的例子中第5步,客户端1从GC pause中恢复过来以后,它会通过这个检查发现锁已经过期了,不会再认为自己成功获取到锁了。随后antirez在他的反驳文章中就指出来了这个问题,但Martin认为这个细节对Redlock整体的安全性没有本质的影响。
抛开这个细节,我们可以分析一下Martin举这个例子的意图在哪。初看起来,这个例子跟文章前半部分分析通用的分布式锁时给出的GC pause的时序图是基本一样的,只不过那里的GC pause发生在客户端1获得了锁之后,而这里的GC pause发生在客户端1获得锁之前。但两个例子的侧重点不太一样。Martin构造这里的这个例子,是为了强调在一个分布式的异步环境下,长时间的GC pause或消息延迟(上面这个例子中,把GC pause换成Redis节点和客户端1之间的消息延迟,逻辑不变),会让客户端获得一个已经过期的锁。从客户端1的角度看,Redlock的安全性被打破了,因为客户端1收到锁的时候,这个锁已经失效了,而Redlock同时还把这个锁分配给了客户端2。换句话说,Redis服务器在把锁分发给客户端的途中,锁就过期了,但又没有有效的机制让客户端明确知道这个问题。而在之前的那个例子中,客户端1收到锁的时候锁还是有效的,锁服务本身的安全性可以认为没有被打破,后面虽然也出了问题,但问题是出在客户端1和共享资源服务器之间的交互上。
在Martin的这篇文章中,还有一个很有见地的观点,就是对锁的用途的区分。他把锁的用途分为两种:
- 为了效率(efficiency),协调各个客户端避免做重复的工作。即使锁偶尔失效了,只是可能把某些操作多做一遍而已,不会产生其它的不良后果。比如重复发送了一封同样的email。
- 为了正确性(correctness)。在任何情况下都不允许锁失效的情况发生,因为一旦发生,就可能意味着数据不一致(inconsistency),数据丢失,文件损坏,或者其它严重的问题。
最后,Martin得出了如下的结论:
- 如果是为了效率(efficiency)而使用分布式锁,允许锁的偶尔失效,那么使用单Redis节点的锁方案就足够了,简单而且效率高。Redlock则是个过重的实现(heavyweight)。
- 如果是为了正确性(correctness)在很严肃的场合使用分布式锁,那么不要使用Redlock。它不是建立在异步模型上的一个足够强的算法,它对于系统模型的假设中包含很多危险的成分(对于timing)。而且,它没有一个机制能够提供fencing token。那应该使用什么技术呢?Martin认为,应该考虑类似Zookeeper的方案,或者支持事务的数据库。
Martin对Redlock算法的形容是:
neither fish nor fowl (非驴非马)
【其它疑问】
- Martin提出的fencing token的方案,需要对提供共享资源的服务进行修改,这在现实中可行吗?
- 根据Martin的说法,看起来,如果资源服务器实现了fencing token,它在分布式锁失效的情况下也仍然能保持资源的互斥访问。这是不是意味着分布式锁根本没有存在的意义了?
- 资源服务器需要检查fencing token的大小,如果提供资源访问的服务也是包含多个节点的(分布式的),那么这里怎么检查才能保证fencing token在多个节点上是递增的呢?
- Martin对于fencing token的举例中,两个fencing token到达资源服务器的顺序颠倒了(小的fencing token后到了),这时资源服务器检查出了这一问题。如果客户端1和客户端2都发生了GC pause,两个fencing token都延迟了,它们几乎同时到达了资源服务器,但保持了顺序,那么资源服务器是不是就检查不出问题了?这时对于资源的访问是不是就发生冲突了?
- 分布式锁+fencing的方案是绝对正确的吗?能证明吗?
注意:除了RedLock之外目前并没有有效解决Redis主从切换导致锁失效的方法。在这种情况下(一致性要求非常高的情况下)一般是不会使用Redis,而推荐使用Zookeeper。
分布式锁:Redisson实现:
目前业界对于Redis的分布式锁有了现成的实现方案了,比较出名的是Redisson开源框架。
Redisson 是 Redis 的 Java 实现的客户端,其 API 提供了比较全面的 Redis 命令的支持。
Redission 通过 Netty 支持非阻塞 I/O。
Redisson 封装了锁的实现,让我们像操作我们的本地 Lock一样来使用,除此之外还有对集合、对象、常用缓存框架等做了友好的封装,易于使用。
除此之外,Redisson还实现了分布式锁的自动续期机制、锁的互斥自等待机制、锁的可重入加锁于释放锁的机制,可以说Redisson对分布式锁的实现是实现了一整套机制的。
Redisson 可以便捷的支持多种Redis部署架构:
- 单机模式
- Master-Slave + Sentinel(哨兵)选举模式
- Redis Cluster(集群)模式
引入Redission之后,使用上非常简单,RedissonClient客户端提供了众多的接口实现,支持可重入锁、公平锁、读写锁、锁超时、RedLock等都提供了完整实现。
使用如下:
A. 引入maven
<dependency><groupId>org.redisson</groupId><artifactId>redisson-spring-boot-starter</artifactId><version>3.13.4</version>
</dependency>
B. 增加配置文件
@Configuration
public class RedissonConfig {@Beanpublic Redisson redisson() {Config config = new Config();//单机版//config.useSingleServer().setAddress("redis://192.168.1.1:8001").setDatabase(0);//集群版config.useClusterServers().addNodeAddress("redis://192.168.1.1:8001").addNodeAddress("redis://192.168.1.1:8002").addNodeAddress("redis://192.168.1.2:8001").addNodeAddress("redis://192.168.1.2:8002").addNodeAddress("redis://192.168.1.3:8001").addNodeAddress("redis://192.168.1.3:8002");return (Redisson) Redisson.create(config);}
}
C. 分布式锁的实现
@Service
public class RedisLockDemo {@Autowiredprivate StringRedisTemplate redisTemplate;@Autowiredprivate Redisson redisson;public String deduceStock() {String lockKey = "lockKey";RLock redissonLock = redisson.getLock(lockKey);try {//加锁(超时默认30s), 实现锁续命的功能(后台启动一个timer, 默认每10s检测一次是否持有锁)redissonLock.lock();//------ 执行业务逻辑 ----start------int stock = Integer.valueOf(redisTemplate.opsForValue().get("stock"));if (stock > 0) {int newStock = stock - 1;//执行业务操作减库存redisTemplate.opsForValue().set("stock", newStock + "");System.out.println("扣减库存成功, 剩余库存:" + newStock);} else {System.out.println("库存已经为0,不能继续扣减");}//------ 执行业务逻辑 ----end------} finally {//解锁redissonLock.unlock();}return "success";}
}
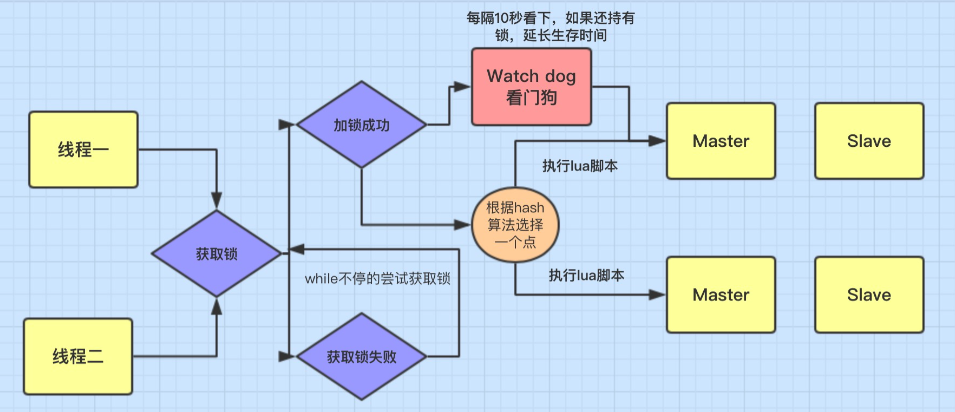
实现的原理如下:
RedissonLock的使用介绍
// 锁默认有效时间30秒,每10秒去检查并重新设置超时时间
void lock(); // 超过锁有效时间 leaseTime,就会释放锁
void lock(long leaseTime, TimeUnit unit);// 尝试获取锁;成功则返回true,失败则返回false
boolean tryLock();// 不会去启动定时任务;在 time 时间内还没有获取到锁,则返回false
boolean tryLock(long time, TimeUnit unit) throws InterruptedException;// 不会去启动定时任务;当 waitTime 的时间到了,还没有获取到锁则返回false;若获取到锁了,锁的有效时间设置为 leaseTime
boolean tryLock(long waitTime, long leaseTime, TimeUnit unit) throws InterruptedException;
也就是说,用法非常简单,但是内部上实现了方案二里面的所有细节:
- 为了兼容老的Redis版本,Redisson 所有指令都通过 Lua 脚本执行,Redis 支持 Lua 脚本原子性执行。
- Redisson 设置的Key 的默认过期时间为 30s,如果某个客户端持有一个锁超过了 30s 怎么办?Redisson 中有一个 Watchdog 的概念,翻译过来就是看门狗,它会在你获取锁之后,每隔 10s 帮你把 Key 的超时时间设为 30s。
- 如果获取锁失败,Redsson会通过while循环一直尝试获取锁(可自定义等待时间,超时后返回失败)
这样的话,就算一直持有锁也不会出现 Key 过期了,其他线程获取到锁的问题了。
另外,Redssion还提供了对Redlock算法的支持,用法也很简单:
RedissonClient redisson = Redisson.create(config);
RLock lock1 = redisson.getFairLock("lock1");
RLock lock2 = redisson.getFairLock("lock2");
RLock lock3 = redisson.getFairLock("lock3");
RedissonRedLock multiLock = new RedissonRedLock(lock1, lock2, lock3);
multiLock.lock();
multiLock.unlock();
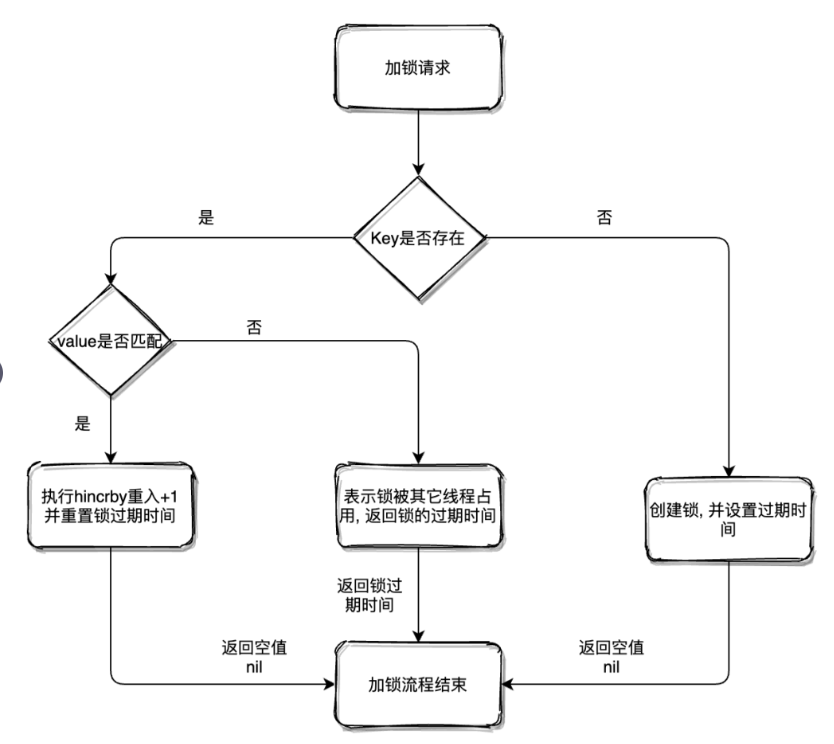
Redisson里面关于加锁/获取锁的Lua脚本流程图如下:
释放锁的Lua脚本流程图如下:
强烈建议大家看一下Redisson里面关于分布式锁的源码,更多关于Redisson的资料可参考:
- Redisson官网
- Redisson官方中文文档
- Github
- Redisson分布式锁实战与Watch Dog机制解读
- Redisson分布式的原理
- 一文掌握Redisson分布式锁的原理
注意:Redison并不能有效的解决Redis的主从切换问题的,目前推荐使用Zookeeper分布式锁来解决。
分布式锁-Redission
Redission 为 Redis 官网分布式解决方案
官网: Redisson: Redis Java client with features of In-Memory Data Grid
github: https://github.com/redisson/redisson#quick-start

功能

usedBy

API


使用
<!--Maven-->
<dependency><groupId>org.redisson</groupId><artifactId>redisson</artifactId><version>3.10.4</version>
</dependency>
// 1. Create config object
Config = ...
// 2. Create Redisson instance
RedissonClient redisson = Redisson.create(config);
// 3. Get Redis based object or service you need
RMap<MyKey, MyValue> map = redisson.getMap("myMap");RLock lock = redisson.getLock("myLock")
lock.lock();
//业务代码
lock.unlock();
原理

分析
加锁机制
源码分析:
//org.redisson.RedissonLock#tryLockInnerAsync
return this.commandExecutor.evalWriteAsync(this.getName(), LongCodec.INSTANCE, command, "if (redis.call('exists', KEYS[1]) == 0) then redis.call('hset', KEYS[1], ARGV[2], 1); redis.call('pexpire', KEYS[1], ARGV[1]); return nil; end; if (redis.call('hexists', KEYS[1], ARGV[2]) == 1) then redis.call('hincrby', KEYS[1], ARGV[2], 1); redis.call('pexpire', KEYS[1], ARGV[1]); return nil; end;
return redis.call('pttl', KEYS[1]);"
, Collections.singletonList(this.getName()), new Object[]{this.internalLockLeaseTime, this.getLockName(threadId)});
为何要使用lua语言?
因为一大堆复杂的业务逻辑,可以通过封装在lua脚本中发送给redis,保证这段复杂业务逻辑执行的原子性
lua字段解释:
**KEYS[1]**代表的是你加锁的那个key,比如说:
RLock lock = redisson.getLock(“myLock”);
这里你自己设置了加锁的那个锁key就是“myLock”。
**ARGV[1]**代表的就是锁key的默认生存时间,默认30秒。
**ARGV[2]**代表的是加锁的客户端的ID,类似于下面这样:
8743c9c0-0795-4907-87fd-6c719a6b4586:1
第一段if判断语句,就是用“exists myLock”命令判断一下,如果你要加锁的那个锁key不存在的话,你就进行加锁。
如何加锁呢?很简单,用下面的命令:
hset myLock
8743c9c0-0795-4907-87fd-6c719a6b4586:1 1
通过这个命令设置一个hash数据结构,这行命令执行后,会出现一个类似下面的数据结构:
myLock:{8743c9c0-0795-4907-87fd-6c719a6b4586:1 1}
接着会执行“pexpire myLock 30000”命令,设置myLock这个锁key的生存时间是30秒(默认)
锁互斥机制
那么在这个时候,如果客户端2来尝试加锁,执行了同样的一段lua脚本,会咋样呢?
很简单,第一个if判断会执行“exists myLock”,发现myLock这个锁key已经存在了。
接着第二个if判断,判断一下,myLock锁key的hash数据结构中,是否包含客户端2的ID,但是明显不是的,因为那里包含的是客户端1的ID。
所以,客户端2会获取到pttl myLock返回的一个数字,这个数字代表了myLock这个锁key的剩余生存时间。比如还剩15000毫秒的生存时间。
此时客户端2会进入一个while循环,不停的尝试加锁。
watch dog自动延期机制
客户端1加锁的锁key默认生存时间才30秒,如果超过了30秒,客户端1还想一直持有这把锁,怎么办呢?
简单!只要客户端1一旦加锁成功,就会启动一个watch dog看门狗,他是一个后台线程,会每隔10秒检查一下,如果客户端1还持有锁key,那么就会不断的延长锁key的生存时间。
可重入加锁机制
如果客户端1都已经持有了这把锁了,结果可重入的加锁会怎么样呢?
RLock lock = redisson.getLock("myLock")
lock.lock();
//业务代码
lock.lock();
//业务代码
lock.unlock();
lock.unlock();
分析上面那段lua脚本。
第一个if判断肯定不成立,“exists myLock”会显示锁key已经存在了。
第二个if判断会成立,因为myLock的hash数据结构中包含的那个ID,就是客户端1的那个ID,也就是“8743c9c0-0795-4907-87fd-6c719a6b4586:1”
此时就会执行可重入加锁的逻辑,他会用:
incrby myLock
8743c9c0-0795-4907-87fd-6c71a6b4586:1 1
通过这个命令,对客户端1的加锁次数,累加1。
此时myLock数据结构变为下面这样:
myLock:{8743c9c0-0795-4907-87fd-6c719a6b4586:1 2}
释放锁机制
如果执行lock.unlock(),就可以释放分布式锁,此时的业务逻辑也是非常简单的。
其实说白了,就是每次都对myLock数据结构中的那个加锁次数减1。
如果发现加锁次数是0了,说明这个客户端已经不再持有锁了,此时就会用:
“del myLock”命令,从redis里删除这个key。
然后呢,另外的客户端2就可以尝试完成加锁了。
这就是所谓的分布式锁的开源Redisson框架的实现机制。
一般我们在生产系统中,可以用Redisson框架提供的这个类库来基于redis进行分布式锁的加锁与释放锁。
封装工具类
import java.util.concurrent.TimeUnit;
import com.caisebei.aspect.lock.springaspect.lock.DistributedLocker;
import org.redisson.api.RLock;
/*** redis分布式锁帮助类* @author caisebei**/
public class RedissLockUtil {private static DistributedLocker redissLock;public static void setLocker(DistributedLocker locker) {redissLock = locker;}/*** 加锁* @param lockKey* @return*/public static RLock lock(String lockKey) {return redissLock.lock(lockKey);}
/*** 释放锁* @param lockKey*/public static void unlock(String lockKey) {redissLock.unlock(lockKey);}/*** 释放锁* @param lock*/public static void unlock(RLock lock) {redissLock.unlock(lock);}
/*** 带超时的锁* @param lockKey* @param timeout 超时时间 单位:秒*/public static RLock lock(String lockKey, int timeout) {return redissLock.lock(lockKey, timeout);}/*** 带超时的锁* @param lockKey* @param unit 时间单位* @param timeout 超时时间*/public static RLock lock(String lockKey, TimeUnit unit ,int timeout) {return redissLock.lock(lockKey, unit, timeout);}/*** 尝试获取锁* @param lockKey* @param waitTime 最多等待时间* @param leaseTime 上锁后自动释放锁时间* @return*/public static boolean tryLock(String lockKey, int waitTime, int leaseTime) {return redissLock.tryLock(lockKey, TimeUnit.SECONDS, waitTime, leaseTime);}/*** 尝试获取锁* @param lockKey* @param unit 时间单位* @param waitTime 最多等待时间* @param leaseTime 上锁后自动释放锁时间* @return*/public static boolean tryLock(String lockKey, TimeUnit unit, int waitTime, int leaseTime) {return redissLock.tryLock(lockKey, unit, waitTime, leaseTime);}
}
优点
支持redis单实例、redis哨兵、redis cluster、redis master-slave等各种部署架构,基于Redis 所以具有Redis 功能使用的封装,功能齐全。许多公司试用后可以用到企业级项目中,社区活跃度高。
在springboot 中单机及哨兵自动装配如下
/*** 哨兵模式自动装配* @return*/@Bean@ConditionalOnProperty(name="redisson.master-name")RedissonClient redissonSentinel() {Config config = new Config();SentinelServersConfig serverConfig = config.useSentinelServers().addSentinelAddress(redssionProperties.getSentinelAddresses()).setMasterName(redssionProperties.getMasterName()).setTimeout(redssionProperties.getTimeout()).setMasterConnectionPoolSize(redssionProperties.getMasterConnectionPoolSize()).setSlaveConnectionPoolSize(redssionProperties.getSlaveConnectionPoolSize());if(StringUtils.isNotBlank(redssionProperties.getPassword())) {serverConfig.setPassword(redssionProperties.getPassword());}return Redisson.create(config);}/*** 单机模式自动装配* @return*/@Bean@ConditionalOnProperty(name="redisson.address")RedissonClient redissonSingle() {Config config = new Config();SingleServerConfig serverConfig = config.useSingleServer().setAddress(redssionProperties.getAddress()).setTimeout(redssionProperties.getTimeout()).setConnectionPoolSize(redssionProperties.getConnectionPoolSize()).setConnectionMinimumIdleSize(redssionProperties.getConnectionMinimumIdleSize());if(StringUtils.isNotBlank(redssionProperties.getPassword())) {serverConfig.setPassword(redssionProperties.getPassword());}return Redisson.create(config);}
缺点
最大的问题,就是如果你对某个redis master实例,写入了myLock这种锁key的value,此时会异步复制给对应的master slave实例。
但是这个过程中一旦发生redis master宕机,主备切换,redis slave变为了redis master。
接着就会导致,客户端2来尝试加锁的时候,在新的redis master上完成了加锁,而客户端1也以为自己成功加了锁。
此时就会导致多个客户端对一个分布式锁完成了加锁。
这时系统在业务语义上一定会出现问题,导致脏数据的产生。
所以这个就是redis cluster,或者是redis master-slave架构的主从异步复制导致的redis分布式锁的最大缺陷:在redis master实例宕机的时候,可能导致多个客户端同时完成加锁。
补充:
Redission 还支持了RedLock 算法实现,但是目前存在争议,可自行查询及谨慎使用



分布式锁:Lua脚本:
Redis的分布式锁实现
1. 利用setnx+expire命令 (错误的做法)
Redis的SETNX命令,setnx key value,将key设置为value,当键不存在时,才能成功,若键存在,什么也不做,成功返回1,失败返回0 。 SETNX实际上就是SET IF NOT Exists的缩写
因为分布式锁还需要超时机制,所以我们利用expire命令来设置,所以利用setnx+expire命令的核心代码如下:
public boolean tryLock(String key,String requset,int timeout) {Long result = jedis.setnx(key, requset);// result = 1时,设置成功,否则设置失败if (result == 1L) {return jedis.expire(key, timeout) == 1L;} else {return false;}
}
实际上上面的步骤是有问题的,setnx和expire是分开的两步操作,不具有原子性,如果执行完第一条指令应用异常或者重启了,锁将无法过期。
一种改善方案就是使用Lua脚本来保证原子性(包含setnx和expire两条指令)
2. 使用Lua脚本(包含setnx和expire两条指令)
代码如下
public boolean tryLock_with_lua(String key, String UniqueId, int seconds) {String lua_scripts = "if redis.call('setnx',KEYS[1],ARGV[1]) == 1 then" +"redis.call('expire',KEYS[1],ARGV[2]) return 1 else return 0 end";List<String> keys = new ArrayList<>();List<String> values = new ArrayList<>();keys.add(key);values.add(UniqueId);values.add(String.valueOf(seconds));Object result = jedis.eval(lua_scripts, keys, values);//判断是否成功return result.equals(1L);
}
3. 使用 set key value [EX seconds][PX milliseconds][NX|XX] 命令 (正确做法)
Redis在 2.6.12 版本开始,为 SET 命令增加一系列选项:
SET key value[EX seconds][PX milliseconds][NX|XX]
- EX seconds: 设定过期时间,单位为秒
- PX milliseconds: 设定过期时间,单位为毫秒
- NX: 仅当key不存在时设置值
- XX: 仅当key存在时设置值
set命令的nx选项,就等同于setnx命令,代码过程如下:
public boolean tryLock_with_set(String key, String UniqueId, int seconds) {return "OK".equals(jedis.set(key, UniqueId, "NX", "EX", seconds));
}
value必须要具有唯一性,我们可以用UUID来做,设置随机字符串保证唯一性,至于为什么要保证唯一性?假如value不是随机字符串,而是一个固定值,那么就可能存在下面的问题:
- 1.客户端1获取锁成功
- 2.客户端1在某个操作上阻塞了太长时间
- 3.设置的key过期了,锁自动释放了
- 4.客户端2获取到了对应同一个资源的锁
- 5.客户端1从阻塞中恢复过来,因为value值一样,所以执行释放锁操作时就会释放掉客户端2持有的锁,这样就会造成问题
所以通常来说,在释放锁时,我们需要对value进行验证
释放锁的实现
释放锁时需要验证value值,也就是说我们在获取锁的时候需要设置一个value,不能直接用del key这种粗暴的方式,因为直接del key任何客户端都可以进行解锁了,所以解锁时,我们需要判断锁是否是自己的,基于value值来判断,代码如下:
public boolean releaseLock_with_lua(String key,String value) {String luaScript = "if redis.call('get',KEYS[1]) == ARGV[1] then " +"return redis.call('del',KEYS[1]) else return 0 end";return jedis.eval(luaScript, Collections.singletonList(key), Collections.singletonList(value)).equals(1L);
}
这里使用Lua脚本的方式,尽量保证原子性。
使用 set key value [EX seconds][PX milliseconds][NX|XX] 命令 看上去很OK,实际上在Redis集群的时候也会出现问题,比如说A客户端在Redis的master节点上拿到了锁,但是这个加锁的key还没有同步到slave节点,master故障,发生故障转移,一个slave节点升级为master节点,B客户端也可以获取同个key的锁,但客户端A也已经拿到锁了,这就导致多个客户端都拿到锁。
所以针对Redis集群这种情况,还有其他方案
4. Redlock算法 与 Redisson 实现
Redis作者 antirez基于分布式环境下提出了一种更高级的分布式锁的实现Redlock,原理如下:
假设有5个独立的Redis节点(注意这里的节点可以是5个Redis单master实例,也可以是5个Redis Cluster集群,但并不是有5个主节点的cluster集群):
- 获取当前Unix时间,以毫秒为单位
- 依次尝试从5个实例,使用相同的key和具有唯一性的value(例如UUID)获取锁,当向Redis请求获取锁时,客户端应该设置一个网络连接和响应超时时间,这个超时时间应用小于锁的失效时间,例如你的锁自动失效时间为10s,则超时时间应该在5~50毫秒之间,这样可以避免服务器端Redis已经挂掉的情况下,客户端还在死死地等待响应结果。如果服务端没有在规定时间内响应,客户端应该尽快尝试去另外一个Redis实例请求获取锁
- 客户端使用当前时间减去开始获取锁时间(步骤1记录的时间)就得到获取锁使用的时间,当且仅当从大多数(N/2+1,这里是3个节点)的Redis节点都取到锁,并且使用的时间小于锁失败时间时,锁才算获取成功。
- 如果取到了锁,key的真正有效时间等于有效时间减去获取锁所使用的时间(步骤3计算的结果)
- 如果某些原因,获取锁失败(没有在至少N/2+1个Redis实例取到锁或者取锁时间已经超过了有效时间),客户端应该在所有的Redis实例上进行解锁(即便某些Redis实例根本就没有加锁成功,防止某些节点获取到锁但是客户端没有得到响应而导致接下来的一段时间不能被重新获取锁)
Redisson实现简单分布式锁
对于Java用户而言,我们经常使用Jedis,Jedis是Redis的Java客户端,除了Jedis之外,Redisson也是Java的客户端,Jedis是阻塞式I/O,而Redisson底层使用Netty可以实现非阻塞I/O,该客户端封装了锁的,继承了J.U.C的Lock接口,所以我们可以像使用ReentrantLock一样使用Redisson,具体使用过程如下。
1、首先加入POM依赖
<dependency><groupId>org.redisson</groupId><artifactId>redisson</artifactId><version>3.10.6</version>
</dependency>
2、使用Redisson,代码如下(与使用ReentrantLock类似)
// 1. 配置文件
Config config = new Config();
config.useSingleServer().setAddress("redis://127.0.0.1:6379").setPassword(RedisConfig.PASSWORD).setDatabase(0);
//2. 构造RedissonClient
RedissonClient redissonClient = Redisson.create(config);//3. 设置锁定资源名称
RLock lock = redissonClient.getLock("redlock");
lock.lock();
try {System.out.println("获取锁成功,实现业务逻辑");Thread.sleep(10000);
} catch (InterruptedException e) {e.printStackTrace();
} finally {lock.unlock();
}
Redis实现的分布式锁轮子
下面利用SpringBoot + Jedis + AOP的组合来实现一个简易的分布式锁。
1. 自定义注解
自定义一个注解,被注解的方法会执行获取分布式锁的逻辑
@Target(ElementType.METHOD)
@Retention(RetentionPolicy.RUNTIME)
@Documented
@Inherited
public @interface RedisLock {/*** 业务键** @return*/String key();/*** 锁的过期秒数,默认是5秒** @return*/int expire() default 5;/*** 尝试加锁,最多等待时间** @return*/long waitTime() default Long.MIN_VALUE;/*** 锁的超时时间单位** @return*/TimeUnit timeUnit() default TimeUnit.SECONDS;
}
2. AOP拦截器实现
在AOP中我们去执行获取分布式锁和释放分布式锁的逻辑,代码如下:
@Aspect
@Component
public class LockMethodAspect {@Autowiredprivate RedisLockHelper redisLockHelper;@Autowiredprivate JedisUtil jedisUtil;private Logger logger = LoggerFactory.getLogger(LockMethodAspect.class);@Around("@annotation(com.redis.lock.annotation.RedisLock)")public Object around(ProceedingJoinPoint joinPoint) {Jedis jedis = jedisUtil.getJedis();MethodSignature signature = (MethodSignature) joinPoint.getSignature();Method method = signature.getMethod();RedisLock redisLock = method.getAnnotation(RedisLock.class);String value = UUID.randomUUID().toString();String key = redisLock.key();try {final boolean islock = redisLockHelper.lock(jedis,key, value, redisLock.expire(), redisLock.timeUnit());logger.info("isLock : {}",islock);if (!islock) {logger.error("获取锁失败");throw new RuntimeException("获取锁失败");}try {return joinPoint.proceed();} catch (Throwable throwable) {throw new RuntimeException("系统异常");}} finally {logger.info("释放锁");redisLockHelper.unlock(jedis,key, value);jedis.close();}}
}
3. Redis实现分布式锁核心类
@Component
public class RedisLockHelper {private long sleepTime = 100;/*** 直接使用setnx + expire方式获取分布式锁* 非原子性** @param key* @param value* @param timeout* @return*/public boolean lock_setnx(Jedis jedis,String key, String value, int timeout) {Long result = jedis.setnx(key, value);// result = 1时,设置成功,否则设置失败if (result == 1L) {return jedis.expire(key, timeout) == 1L;} else {return false;}}/*** 使用Lua脚本,脚本中使用setnex+expire命令进行加锁操作** @param jedis* @param key* @param UniqueId* @param seconds* @return*/public boolean Lock_with_lua(Jedis jedis,String key, String UniqueId, int seconds) {String lua_scripts = "if redis.call('setnx',KEYS[1],ARGV[1]) == 1 then" +"redis.call('expire',KEYS[1],ARGV[2]) return 1 else return 0 end";List<String> keys = new ArrayList<>();List<String> values = new ArrayList<>();keys.add(key);values.add(UniqueId);values.add(String.valueOf(seconds));Object result = jedis.eval(lua_scripts, keys, values);//判断是否成功return result.equals(1L);}/*** 在Redis的2.6.12及以后中,使用 set key value [NX] [EX] 命令** @param key* @param value* @param timeout* @return*/public boolean lock(Jedis jedis,String key, String value, int timeout, TimeUnit timeUnit) {long seconds = timeUnit.toSeconds(timeout);return "OK".equals(jedis.set(key, value, "NX", "EX", seconds));}/*** 自定义获取锁的超时时间** @param jedis* @param key* @param value* @param timeout* @param waitTime* @param timeUnit* @return* @throws InterruptedException*/public boolean lock_with_waitTime(Jedis jedis,String key, String value, int timeout, long waitTime,TimeUnit timeUnit) throws InterruptedException {long seconds = timeUnit.toSeconds(timeout);while (waitTime >= 0) {String result = jedis.set(key, value, "nx", "ex", seconds);if ("OK".equals(result)) {return true;}waitTime -= sleepTime;Thread.sleep(sleepTime);}return false;}/*** 错误的解锁方法—直接删除key** @param key*/public void unlock_with_del(Jedis jedis,String key) {jedis.del(key);}/*** 使用Lua脚本进行解锁操纵,解锁的时候验证value值** @param jedis* @param key* @param value* @return*/public boolean unlock(Jedis jedis,String key,String value) {String luaScript = "if redis.call('get',KEYS[1]) == ARGV[1] then " +"return redis.call('del',KEYS[1]) else return 0 end";return jedis.eval(luaScript, Collections.singletonList(key), Collections.singletonList(value)).equals(1L);}
}
4. Controller层控制
定义一个TestController来测试我们实现的分布式锁
@RestController
public class TestController {@RedisLock(key = "redis_lock")@GetMapping("/index")public String index() {return "index";}
}
分布式锁:Redisson
为了降低利用 Redis 实现分布式锁的门槛,Redis 官方推荐开发者使用 Redisson 实现分布式锁。下面为大家演示如何利用 Spring Boot 整合 Redisson 实现分布式锁。
**1.**新建 Maven 项目 distributedLock,并在其 pom 文件中添加如下依赖:
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency><dependency>
<groupId>org.redisson</groupId>
<artifactId>redisson</artifactId>
<version>3.6.5</version>
</dependency><dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
/dependency>
</dependencies>
注意: 这里务必要注意 Redisson 的版本问题。刚开始我采用的是 3.4.2 版本,程序启动时就报错 “Caused by: java.lang.IllegalArgumentException: port out of range:-1”,之后换成 3.6.5 版本,便能正常启动了。
**2.**新建 application.properties 文件,并在文件中添加如下配置内容:
server.port=8080redisson.address=redis://192.168.1.120:6379
redisson.password=hcb13579
redisson.timeout=3000
注意:redisson.address 需要以 redis:// 为前缀,否则无法连接 Redis。
3. 新建分布式锁接口及其实现类。
分布式锁接口定义如下:
public interface DistributedLocker {/*** 加锁* @param lockKey*/void lock(String lockKey);/*** 释放锁* @param lockKey*/void unLock(String lockKey);/*** 带有超时时间加锁* @param lockKey* @param timeout*/void lock(String lockKey,int timeout);/*** 带有超时时间加锁,并指定时间单位* @param lockKey* @param timeout* @param timeUnit*/void lock(String lockKey, int timeout, TimeUnit timeUnit);
}
利用 RedissonClient 实现分布式锁接口,代码如下:
public class RedissonDistributedLocker implements DistributedLocker {private RedissonClient redissonClient;public void setRedissonClient(RedissonClient redissonClient) {this.redissonClient = redissonClient;}...此处省略部分实现代码}
4. 定义获取 Redis 相关信息配置类,代码如下:
@ConfigurationProperties(prefix = "redisson")
public class RedissonProperties {//redis连接地址private String address;//访问redis密码private String password;...此处省略部分实现代码
}
5. 新建 RedissonClient、RedissonDistributedLocker 实例,并初始化 RedissonLockUtil 工具类中 DistributedLocker 对象:
@Configuration
@ConditionalOnClass(Config.class)
@EnableConfigurationProperties(RedissonProperties.class)
public class RedissonAutoConfiguration {@Autowiredprivate RedissonProperties redssonProperties;@Bean@ConditionalOnProperty(name="redisson.address")RedissonClient redissonSingle() {Config config = new Config();//设置serverConfig连接地址信息、超时时间等信息SingleServerConfig serverConfig = config.useSingleServer().setAddress(redssonProperties.getAddress()).setTimeout(redssonProperties.getTimeout()).setConnectionPoolSize(redssonProperties.getConnectionPoolSize()).setConnectionMinimumIdleSize(redssonProperties.getConnectionMiniumIdleSize());if(!StringUtils.isEmpty(redssonProperties.getPassword())) {serverConfig.setPassword(redssonProperties.getPassword());}//返回RedissonClient实例return Redisson.create(config);}@BeanDistributedLocker distributedLocker(RedissonClient redissonSingle) {RedissonDistributedLocker locker = new RedissonDistributedLocker();//设置RedissonDistributedLocker对象中RedissonClient对象locker.setRedissonClient(redissonSingle());//设置工具类RedissonLockUtil中DistributedLocker对象RedissonLockUtil.setLocker(locker);return locker;}
}
**6.**在控制器 DistributedLockController 中新增接口 distributedLock,并利用多线程模拟分布式锁功能。
**7.**依次启动 Redis、应用程序,并利用 Postman 调用接口:http://localhost:8080/lock/redissonLock,对分布式锁功能进行测试,截图如下:
接下来,我们看下这种方法的优点及存在的问题。
优点主要有:
- Redis 基于内存操作,性能比较好;
- 可以设置超时时间,当客户端与 Redis Server 断开后,锁仍然能被释放。
主要存在的问题包括:
- 非重入锁;
- 靠开发者的经验来预估锁超时时间,很难准确。
分布式锁:完美方案
前言
在某些场景中,多个进程必须以互斥的方式独占共享资源,这时用分布式锁是最直接有效的。
随着技术快速发展,数据规模增大,分布式系统越来越普及,一个应用往往会部署在多台机器上(多节点),在有些场景中,为了保证数据不重复,要求在同一时刻,同一任务只在一个节点上运行,即保证某一方法同一时刻只能被一个线程执行。在单机环境中,应用是在同一进程下的,只需要保证单进程多线程环境中的线程安全性,通过 JAVA 提供的 volatile、ReentrantLock、synchronized 以及 concurrent 并发包下一些线程安全的类等就可以做到。而在多机部署环境中,不同机器不同进程,就需要在多进程下保证线程的安全性了。因此,分布式锁应运而生。
以往的工作中看到或用到几种实现方案,有基于zk的,也有基于redis的。由于实现上逻辑不严谨,线上时不时会爆出几个死锁case。那么,究竟什么样的分布式锁实现,才算是比较好的方案?
常见分布式锁方案对比
| 分类 | 方案 | 实现原理 | 优点 | 缺点 |
|---|---|---|---|---|
| 基于数据库 | 基于mysql 表唯一索引 | 1.表增加唯一索引 2.加锁:执行insert语句,若报错,则表明加锁失败 3.解锁:执行delete语句 | 完全利用DB现有能力,实现简单 | 1.锁无超时自动失效机制,有死锁风险 2.不支持锁重入,不支持阻塞等待 3.操作数据库开销大,性能不高 |
| 基于数据库 | 基于MongoDB findAndModify原子操作 | 1.加锁:执行findAndModify原子命令查找document,若不存在则新增 2.解锁:删除document | 实现也很容易,较基于MySQL唯一索引的方案,性能要好很多 | 1.大部分公司数据库用MySQL,可能缺乏相应的MongoDB运维、开发人员 2.锁无超时自动失效机制 |
| 基于分布式协调系统 | 基于ZooKeeper | 1.加锁:在/lock目录下创建临时有序节点,判断创建的节点序号是否最小。若是,则表示获取到锁;否,则则watch /lock目录下序号比自身小的前一个节点 2.解锁:删除节点 | 1.由zk保障系统高可用 2.Curator框架已原生支持系列分布式锁命令,使用简单 | 需单独维护一套zk集群,维保成本高 |
| 基于缓存 | 基于redis命令 | 1. 加锁:执行setnx,若成功再执行expire添加过期时间 2. 解锁:执行delete命令 | 实现简单,相比数据库和分布式系统的实现,该方案最轻,性能最好 | 1.setnx和expire分2步执行,非原子操作;若setnx执行成功,但expire执行失败,就可能出现死锁 2.delete命令存在误删除非当前线程持有的锁的可能 3.不支持阻塞等待、不可重入 |
| 基于缓存 | 基于redis Lua脚本能力 | 1. 加锁:执行SET lock_name random_value EX seconds NX 命令 2. 解锁:执行Lua脚本,释放锁时验证random_value – ARGV[1]为random_value, KEYS[1]为lock_name if redis.call(“get”, KEYS[1]) == ARGV[1] then return redis.call(“del”,KEYS[1]) else return 0 end | 同上;实现逻辑上也更严谨,除了单点问题,生产环境采用用这种方案,问题也不大。 | 不支持锁重入,不支持阻塞等待 |
表格中对比了几种常见的方案,redis+lua基本可应付工作中分布式锁的需求。然而,当偶然看到redisson分布式锁实现方案(传送门),相比以上方案,redisson保持了简单易用、支持锁重入、支持阻塞等待、Lua脚本原子操作,不禁佩服作者精巧的构思和高超的编码能力。下面就来学习下redisson这个牛逼框架,是怎么实现的。
分布式锁需满足四个条件
首先,为了确保分布式锁可用,我们至少要确保锁的实现同时满足以下四个条件:
- 互斥性。在任意时刻,只有一个客户端能持有锁。
- 不会发生死锁。即使有一个客户端在持有锁的期间崩溃而没有主动解锁,也能保证后续其他客户端能加锁。
- 解铃还须系铃人。加锁和解锁必须是同一个客户端,客户端自己不能把别人加的锁给解了,即不能误解锁。
- 具有容错性。只要大多数Redis节点正常运行,客户端就能够获取和释放锁。
Redisson 分布式锁的实现
Redisson 分布式重入锁用法
Redisson 支持单点模式、主从模式、哨兵模式、集群模式,这里以单点模式为例:
// 1.构造redisson实现分布式锁必要的Config
Config config = new Config();
config.useSingleServer().setAddress("redis://127.0.0.1:5379").setPassword("123456").setDatabase(0);
// 2.构造RedissonClient
RedissonClient redissonClient = Redisson.create(config);
// 3.获取锁对象实例(无法保证是按线程的顺序获取到)
RLock rLock = redissonClient.getLock(lockKey);
try {/*** 4.尝试获取锁* waitTimeout 尝试获取锁的最大等待时间,超过这个值,则认为获取锁失败* leaseTime 锁的持有时间,超过这个时间锁会自动失效(值应设置为大于业务处理的时间,确保在锁有效期内业务能处理完)*/boolean res = rLock.tryLock((long)waitTimeout, (long)leaseTime, TimeUnit.SECONDS);if (res) {//成功获得锁,在这里处理业务}
} catch (Exception e) {throw new RuntimeException("aquire lock fail");
}finally{//无论如何, 最后都要解锁rLock.unlock();
}
redisson这个框架重度依赖了Lua脚本和Netty,代码很牛逼,各种Future及FutureListener的异步、同步操作转换。
自己先思考下,如果要手写一个分布式锁组件,怎么做?肯定要定义2个接口:加锁、解锁;大道至简,redisson的作者就是在加锁和解锁的执行层面采用Lua脚本,逼格高,而且重要有原子性保证啊。当然,redisson的作者毕竟牛逼,加锁和解锁过程中还巧妙地利用了redis的发布订阅功能,后面会讲到。下面先对加锁和解锁Lua脚本了解下。
加锁&解锁Lua脚本
加锁、解锁Lua脚本是redisson分布式锁实现最重要的组成部分。首先不看代码,先研究下Lua脚本都是什么逻辑
1、加锁Lua脚本
- 脚本入参
| 参数 | 示例值 | 含义 |
|---|---|---|
| KEY个数 | 1 | KEY个数 |
| KEYS[1] | my_first_lock_name | 锁名 |
| ARGV[1] | 60000 | 持有锁的有效时间:毫秒 |
| ARGV[2] | 58c62432-bb74-4d14-8a00-9908cc8b828f:1 | 唯一标识:获取锁时set的唯一值,实现上为redisson客户端ID(UUID)+线程ID |
- 脚本内容
-- 若锁不存在:则新增锁,并设置锁重入计数为1、设置锁过期时间
if (redis.call('exists', KEYS[1]) == 0) thenredis.call('hset', KEYS[1], ARGV[2], 1);redis.call('pexpire', KEYS[1], ARGV[1]);return nil;
end;-- 若锁存在,且唯一标识也匹配:则表明当前加锁请求为锁重入请求,故锁重入计数+1,并再次设置锁过期时间
if (redis.call('hexists', KEYS[1], ARGV[2]) == 1) thenredis.call('hincrby', KEYS[1], ARGV[2], 1);redis.call('pexpire', KEYS[1], ARGV[1]);return nil;
end;-- 若锁存在,但唯一标识不匹配:表明锁是被其他线程占用,当前线程无权解他人的锁,直接返回锁剩余过期时间
return redis.call('pttl', KEYS[1]);
- 脚本解读

Q:返回nil、返回剩余过期时间有什么目的?
A:当且仅当返回nil,才表示加锁成功;客户端需要感知加锁是否成功的结果
2、解锁Lua脚本
- 脚本入参
| 参数 | 示例值 | 含义 |
|---|---|---|
| KEY个数 | 2 | KEY个数 |
| KEYS[1] | my_first_lock_name | 锁名 |
| KEYS[2] | redisson_lock__channel:{my_first_lock_name} | 解锁消息PubSub频道 |
| ARGV[1] | 0 | redisson定义0表示解锁消息 |
| ARGV[2] | 30000 | 设置锁的过期时间;默认值30秒 |
| ARGV[3] | 58c62432-bb74-4d14-8a00-9908cc8b828f:1 | 唯一标识;同加锁流程 |
- 脚本内容
-- 若锁不存在:则直接广播解锁消息,并返回1
if (redis.call('exists', KEYS[1]) == 0) thenredis.call('publish', KEYS[2], ARGV[1]);return 1;
end;-- 若锁存在,但唯一标识不匹配:则表明锁被其他线程占用,当前线程不允许解锁其他线程持有的锁
if (redis.call('hexists', KEYS[1], ARGV[3]) == 0) thenreturn nil;
end; -- 若锁存在,且唯一标识匹配:则先将锁重入计数减1
local counter = redis.call('hincrby', KEYS[1], ARGV[3], -1);
if (counter > 0) then -- 锁重入计数减1后还大于0:表明当前线程持有的锁还有重入,不能进行锁删除操作,但可以友好地帮忙设置下过期时期redis.call('pexpire', KEYS[1], ARGV[2]); return 0;
else -- 锁重入计数已为0:间接表明锁已释放了。直接删除掉锁,并广播解锁消息,去唤醒那些争抢过锁但还处于阻塞中的线程redis.call('del', KEYS[1]); redis.call('publish', KEYS[2], ARGV[1]); return 1;
end;return nil;
- 脚本解读
Q1:广播解锁消息有什么用?
A:是为了通知其他争抢锁阻塞住的线程,从阻塞中解除,并再次去争抢锁。
Q2:返回值0、1、nil有什么不一样?
A:当且仅当返回1,才表示当前请求真正触发了解锁Lua脚本;但客户端又并不关心解锁请求的返回值,好像没什么用?
源码搞起
1、加锁流程源码
读加锁源码时,可以把tryAcquire(leaseTime, unit, threadId)方法直接视为执行加锁Lua脚本。直接进入org.redisson.RedissonLock#tryLock(long, long, java.util.concurrent.TimeUnit)源码
@Overridepublic boolean tryLock(long waitTime, long leaseTime, TimeUnit unit) throws InterruptedException {// 获取锁能容忍的最大等待时长long time = unit.toMillis(waitTime);long current = System.currentTimeMillis();final long threadId = Thread.currentThread().getId();// 【核心点1】尝试获取锁,若返回值为null,则表示已获取到锁Long ttl = tryAcquire(leaseTime, unit, threadId);// lock acquiredif (ttl == null) {return true;}// 还可以容忍的等待时长=获取锁能容忍的最大等待时长 - 执行完上述操作流逝的时间time -= (System.currentTimeMillis() - current);if (time <= 0) {acquireFailed(threadId);return false;}current = System.currentTimeMillis();// 【核心点2】订阅解锁消息,见org.redisson.pubsub.LockPubSub#onMessage/*** 4.订阅锁释放事件,并通过await方法阻塞等待锁释放,有效的解决了无效的锁申请浪费资源的问题:* 基于信息量,当锁被其它资源占用时,当前线程通过 Redis 的 channel 订阅锁的释放事件,一旦锁释放会发消息通知待等待的线程进行竞争* 当 this.await返回false,说明等待时间已经超出获取锁最大等待时间,取消订阅并返回获取锁失败* 当 this.await返回true,进入循环尝试获取锁*/final RFuture<RedissonLockEntry> subscribeFuture = subscribe(threadId);//await 方法内部是用CountDownLatch来实现阻塞,获取subscribe异步执行的结果(应用了Netty 的 Future)if (!await(subscribeFuture, time, TimeUnit.MILLISECONDS)) {if (!subscribeFuture.cancel(false)) {subscribeFuture.addListener(new FutureListener<RedissonLockEntry>() {@Overridepublic void operationComplete(Future<RedissonLockEntry> future) throws Exception {if (subscribeFuture.isSuccess()) {unsubscribe(subscribeFuture, threadId);}}});}acquireFailed(threadId);return false;}// 订阅成功try {// 还可以容忍的等待时长=获取锁能容忍的最大等待时长 - 执行完上述操作流逝的时间time -= (System.currentTimeMillis() - current);if (time <= 0) {// 超出可容忍的等待时长,直接返回获取锁失败acquireFailed(threadId);return false;}while (true) {long currentTime = System.currentTimeMillis();// 尝试获取锁;如果锁被其他线程占用,就返回锁剩余过期时间【同上】ttl = tryAcquire(leaseTime, unit, threadId);// lock acquiredif (ttl == null) {return true;}time -= (System.currentTimeMillis() - currentTime);if (time <= 0) {acquireFailed(threadId);return false;}// waiting for messagecurrentTime = System.currentTimeMillis();// 【核心点3】根据锁TTL,调整阻塞等待时长;// 注意:这里实现非常巧妙,1、latch其实是个信号量Semaphore,调用其tryAcquire方法会让当前线程阻塞一段时间,避免了在while循环中频繁请求获取锁;//2、该Semaphore的release方法,会在订阅解锁消息的监听器消息处理方法org.redisson.pubsub.LockPubSub#onMessage调用;当其他线程释放了占用的锁,会广播解锁消息,监听器接收解锁消息,并释放信号量,最终会唤醒阻塞在这里的线程。if (ttl >= 0 && ttl < time) {getEntry(threadId).getLatch().tryAcquire(ttl, TimeUnit.MILLISECONDS);} else {getEntry(threadId).getLatch().tryAcquire(time, TimeUnit.MILLISECONDS);}time -= (System.currentTimeMillis() - currentTime);if (time <= 0) {acquireFailed(threadId);return false;}}} finally {// 取消解锁消息的订阅unsubscribe(subscribeFuture, threadId);}}
接下的再获取锁方法 tryAcquire的实现,真的就是执行Lua脚本!
private Long tryAcquire(long leaseTime, TimeUnit unit, long threadId) {// tryAcquireAsync异步执行Lua脚本,get方法同步获取返回结果return get(tryAcquireAsync(leaseTime, unit, threadId));
}// 见org.redisson.RedissonLock#tryAcquireAsync
private <T> RFuture<Long> tryAcquireAsync(long leaseTime, TimeUnit unit, final long threadId) {if (leaseTime != -1) {// 实质是异步执行加锁Lua脚本return tryLockInnerAsync(leaseTime, unit, threadId, RedisCommands.EVAL_LONG);}RFuture<Long> ttlRemainingFuture = tryLockInnerAsync(commandExecutor.getConnectionManager().getCfg().getLockWatchdogTimeout(), TimeUnit.MILLISECONDS, threadId, RedisCommands.EVAL_LONG);ttlRemainingFuture.addListener(new FutureListener<Long>() {@Overridepublic void operationComplete(Future<Long> future) throws Exception {//先判断这个异步操作有没有执行成功,如果没有成功,直接返回,如果执行成功了,就会同步获取结果if (!future.isSuccess()) {return;}Long ttlRemaining = future.getNow();// lock acquired//如果ttlRemaining为null,则会执行一个定时调度的方法scheduleExpirationRenewalif (ttlRemaining == null) {scheduleExpirationRenewal(threadId);}}});return ttlRemainingFuture;
}// 见org.redisson.RedissonLock#tryLockInnerAsync
<T> RFuture<T> tryLockInnerAsync(long leaseTime, TimeUnit unit, long threadId, RedisStrictCommand<T> command) {internalLockLeaseTime = unit.toMillis(leaseTime);return commandExecutor.evalWriteAsync(getName(), LongCodec.INSTANCE, command,"if (redis.call('exists', KEYS[1]) == 0) then " +"redis.call('hset', KEYS[1], ARGV[2], 1); " +"redis.call('pexpire', KEYS[1], ARGV[1]); " +"return nil; " +"end; " +"if (redis.call('hexists', KEYS[1], ARGV[2]) == 1) then " +"redis.call('hincrby', KEYS[1], ARGV[2], 1); " +"redis.call('pexpire', KEYS[1], ARGV[1]); " +"return nil; " +"end; " +"return redis.call('pttl', KEYS[1]);",Collections.<Object>singletonList(getName()), internalLockLeaseTime, getLockName(threadId));
}
加锁过程小结
1、锁其实也是一种资源,各线程争抢锁操作对应到redisson中就是争抢着去创建一个hash结构,谁先创建就代表谁获得锁;hash的名称为锁名,hash里面内容仅包含一条键值对,键为redisson客户端唯一标识+持有锁线程id,值为锁重入计数;给hash设置的过期时间就是锁的过期时间。放个图直观感受下:
2、加锁流程核心就3步
Step1:尝试获取锁,这一步是通过执行加锁Lua脚本来做;
Step2:若第一步未获取到锁,则去订阅解锁消息,当获取锁到剩余过期时间后,调用信号量方法阻塞住,直到被唤醒或等待超时
Step3:一旦持有锁的线程释放了锁,就会广播解锁消息。于是,第二步中的解锁消息的监听器会释放信号量,获取锁被阻塞的那些线程就会被唤醒,并重新尝试获取锁。
比如 RedissonLock中的变量internalLockLeaseTime,默认值是30000毫秒,还有调用tryLockInnerAsync()传入的一个从连接管理器获取的getLockWatchdogTimeout(),他的默认值也是30000毫秒,这些都和redisson官方文档所说的watchdog机制有关,看门狗,还是很形象的描述这一机制,那么看门狗到底做了什么,为什么这么做,来看下核心代码.
先思考一个问题,假设在一个分布式环境下,多个服务实例请求获取锁,其中服务实例1成功获取到了锁,在执行业务逻辑的过程中,服务实例突然挂掉了或者hang住了,那么这个锁会不会释放,什么时候释放?回答这个问题,自然想起来之前我们分析的lua脚本,其中第一次加锁的时候使用pexpire给锁key设置了过期时间,默认30000毫秒,由此来看如果服务实例宕机了,锁最终也会释放,其他服务实例也是可以继续获取到锁执行业务。但是要是30000毫秒之后呢,要是服务实例1没有宕机但是业务执行还没有结束,所释放掉了就会导致线程问题,这个redisson是怎么解决的呢?这个就一定要实现自动延长锁有效期的机制。
异步执行完lua脚本执行完成之后,设置了一个监听器,来处理异步执行结束之后的一些工作。在操作完成之后会去执行operationComplete方法,先判断这个异步操作有没有执行成功,如果没有成功,直接返回,如果执行成功了,就会同步获取结果,如果ttlRemaining为null,则会执行一个定时调度的方法scheduleExpirationRenewal,回想一下之前的lua脚本,当加锁逻辑
处理结束,返回了一个nil;如此说来 就一定会走定时任务了。来看下定时调度scheduleExpirationRenewal代码
private void scheduleExpirationRenewal(final long threadId) {if (expirationRenewalMap.containsKey(getEntryName())) {return;}Timeout task = commandExecutor.getConnectionManager().newTimeout(new TimerTask() {@Overridepublic void run(Timeout timeout) throws Exception {RFuture<Boolean> future = commandExecutor.evalWriteAsync(getName(), LongCodec.INSTANCE, RedisCommands.EVAL_BOOLEAN,"if (redis.call('hexists', KEYS[1], ARGV[2]) == 1) then " +"redis.call('pexpire', KEYS[1], ARGV[1]); " +"return 1; " +"end; " +"return 0;",Collections.<Object>singletonList(getName()), internalLockLeaseTime, getLockName(threadId));future.addListener(new FutureListener<Boolean>() {@Overridepublic void operationComplete(Future<Boolean> future) throws Exception {expirationRenewalMap.remove(getEntryName());if (!future.isSuccess()) {log.error("Can't update lock " + getName() + " expiration", future.cause());return;}if (future.getNow()) {// reschedule itselfscheduleExpirationRenewal(threadId);}}});}}, internalLockLeaseTime / 3, TimeUnit.MILLISECONDS);if (expirationRenewalMap.putIfAbsent(getEntryName(), task) != null) {task.cancel();}}
首先,会先判断在expirationRenewalMap中是否存在了entryName,这是个map结构,主要还是判断在这个服务实例中的加锁客户端的锁key是否存在,如果已经存在了,就直接返回;第一次加锁,肯定是不存在的,接下来就是搞了一个TimeTask,延迟internalLockLeaseTime/3之后执行,这里就用到了文章一开始就提到奇妙的变量,算下来就是大约10秒钟执行一次,调用了一个异步执行的方法

如图也是调用异步执行了一段lua脚本,首先判断这个锁key的map结构中是否存在对应的key8a9649f5-f5b5-48b4-beaa-d0c24855f9ab:anyLock:1,如果存在,就直接调用pexpire命令设置锁key的过期时间,默认30000毫秒。
OK,现在思路就清晰了,在上面任务调度的方法中,也是异步执行并且设置了一个监听器,在操作执行成功之后,会回调这个方法,如果调用失败会打一个错误日志并返回,更新锁过期时间失败;然后获取异步执行的结果,如果为true,就会调用本身,如此说来又会延迟10秒钟去执行这段逻辑,所以,这段逻辑在你成功获取到锁之后,会每隔十秒钟去执行一次,并且,在锁key还没有失效的情况下,会把锁的过期时间继续延长到30000毫秒,也就是说只要这台服务实例没有挂掉,并且没有主动释放锁,看门狗都会每隔十秒给你续约一下,保证锁一直在你手中。完美的操作。
到现在来说,加锁,锁自动延长过期时间,都OK了,然后就是说在你执行业务,持有锁的这段时间,别的服务实例来尝试加锁又会发生什么情况呢?或者当前客户端的别的线程来获取锁呢?很显然,肯定会阻塞住,我们来通过代码看看是怎么做到的。还是把眼光放到之前分析的那段加锁lua代码上,当加锁的锁key存在的时候并且锁key对应的map结构中当前客户端的唯一key也存在时,会去调用hincrby命令,将唯一key的值自增一,并且会pexpire设置key的过期时间为30000毫秒,然后返回nil,可以想象这里也是加锁成功的,也会继续去执行定时调度任务,完成锁key过期时间的续约,这里呢,就实现了锁的可重入性。
那么当以上这种情况也没有发生呢,这里就会直接返回当前锁的剩余有效期,相应的也不会去执行续约逻辑。此时一直返回到上面的方法,如果加锁成功就直接返回;否则就会进入一个死循环,去尝试加锁,并且也会在等待一段时间之后一直循环尝试加锁,阻塞住,知道第一个服务实例释放锁。对于不同的服务实例尝试会获取一把锁,也和上面的逻辑类似,都是这样实现了锁的互斥。
紧接着,我们来看看锁释放的逻辑,其实也很简单,调用了lock.unlock()方法,跟着代码走流程发现,也是异步调用了一段lua脚本,lua脚本,应该就比较清晰,也就是通过判断锁key是否存在,如果不存在直接返回;否则就会判断当前客户端对应的唯一key的值是否存在,如果不存在就会返回nil;否则,值自增-1,判断唯一key的值是否大于零,如果大于零,则返回0;否则删除当前锁key,并返回1;返回到上一层方法,也是针对返回值进行了操作,如果返回值是1,则会去取消之前的定时续约任务,如果失败了,则会做一些类似设置状态的操作,这一些和解锁逻辑也没有什么关系,可以不去看他。
解锁流程源码
解锁流程相对比较简单,完全就是执行解锁Lua脚本,无额外的代码逻辑,直接看org.redisson.RedissonLock#unlock代码
@Overridepublic void unlock() {// 执行解锁Lua脚本,这里传入线程id,是为了保证加锁和解锁是同一个线程,避免误解锁其他线程占有的锁Boolean opStatus = get(unlockInnerAsync(Thread.currentThread().getId()));if (opStatus == null) {throw new IllegalMonitorStateException("attempt to unlock lock, not locked by current thread by node id: "+ id + " thread-id: " + Thread.currentThread().getId());}if (opStatus) {cancelExpirationRenewal();}}// 见org.redisson.RedissonLock#unlockInnerAsync
protected RFuture<Boolean> unlockInnerAsync(long threadId) {return commandExecutor.evalWriteAsync(getName(), LongCodec.INSTANCE, RedisCommands.EVAL_BOOLEAN,"if (redis.call('exists', KEYS[1]) == 0) then " +"redis.call('publish', KEYS[2], ARGV[1]); " +"return 1; " +"end;" +"if (redis.call('hexists', KEYS[1], ARGV[3]) == 0) then " +"return nil;" +"end; " +"local counter = redis.call('hincrby', KEYS[1], ARGV[3], -1); " +"if (counter > 0) then " +"redis.call('pexpire', KEYS[1], ARGV[2]); " +"return 0; " +"else " +"redis.call('del', KEYS[1]); " +"redis.call('publish', KEYS[2], ARGV[1]); " +"return 1; "+"end; " +"return nil;",Arrays.<Object>asList(getName(), getChannelName()), LockPubSub.unlockMessage, internalLockLeaseTime, getLockName(threadId));}
c.加锁&解锁流程串起来
上面结合Lua脚本和源码,分别分析了加锁流程和解锁流程。下面升级下挑战难度,模拟下多个线程争抢锁会是怎样的流程。示意图如下,比较关键的三处已用红色字体标注。

概括下整个流程
1、线程A和线程B两个线程同时争抢锁。线程A很幸运,最先抢到了锁。线程B在获取锁失败后,并未放弃希望,而是主动订阅了解锁消息,然后再尝试获取锁,顺便看看没有抢到的这把锁还有多久就过期,线程B就按需阻塞等锁释放。
2、线程A拿着锁干完了活,自觉释放了持有的锁,于此同时广播了解锁消息,通知其他抢锁的线程再来枪;
3、解锁消息的监听者LockPubSub收到消息后,释放自己持有的信号量;线程B就瞬间从阻塞中被唤醒了,接着再抢锁,这次终于抢到锁了!后面再按部就班,干完活,解锁
其他料
Q1:订阅频道名称(如:redisson_lock__channel:{my_first_lock_name})为什么有大括号?
A:
1.在redis集群方案中,如果Lua脚本涉及多个key的操作,则需限制这些key在同一个slot中,才能保障Lua脚本执行的原子性。否则运行会报错Lua script attempted to access a non local key in a cluster node . channel;
2.HashTag是用{}包裹key的一个子串,若设置了HashTag,集群会根据HashTag决定key分配到哪个slot;HashTag不支持嵌套,只有第一个左括号{和第一个右括号}里面的内容才当做HashTag参与slot计算;通常,客户端都会封装这个计算逻辑。
// 见org.redisson.cluster.ClusterConnectionManager#calcSlot
@Override
public int calcSlot(String key) {if (key == null) {return 0;}int start = key.indexOf('{');if (start != -1) {int end = key.indexOf('}');key = key.substring(start+1, end);}int result = CRC16.crc16(key.getBytes()) % MAX_SLOT;log.debug("slot {} for {}", result, key);return result;
}
3.在解锁Lua脚本中,操作了两个key:一个是锁名my_lock_name,一个是解锁消息发布订阅频道redisson_lock__channel:{my_first_lock_name},按照上面slot计算方式,两个key都会按照内容my_first_lock_name来计算,故能保证落到同一个slot
**Q2:**redisson代码几乎都是以Lua脚本方式与redis服务端交互,如何跟踪这些脚本执行过程?
A:启动一个redis客户端终端,执行monitor命令以便在终端上实时打印 redis 服务器接收到的命令;然后debug执行redisson加锁/解锁测试用例,即可看到代码运行过程中实际执行了哪些Lua脚本
eg:上面整体流程示意图的测试用例位:
@RunWith(SpringRunner.class)
@SpringBootTest
public class RedissonDistributedLockerTest {private static final Logger log = LoggerFactory.getLogger(RedissonDistributedLocker.class);@Resourceprivate DistributedLocker distributedLocker;private static final ExecutorService executorServiceB = Executors.newSingleThreadExecutor();private static final ExecutorService executorServiceC = Executors.newSingleThreadExecutor();@Testpublic void tryLockUnlockCost() throws Exception {StopWatch stopWatch = new StopWatch("加锁解锁耗时统计");stopWatch.start();for (int i = 0; i < 10000; i++) {String key = "mock-key:" + UUID.randomUUID().toString().replace("-", "");Optional<LockResource> optLocked = distributedLocker.tryLock(key, 600000, 600000);Assert.assertTrue(optLocked.isPresent());optLocked.get().unlock();}stopWatch.stop();log.info(stopWatch.prettyPrint());}@Testpublic void tryLock() throws Exception {String key = "mock-key:" + UUID.randomUUID().toString().replace("-", "");Optional<LockResource> optLocked = distributedLocker.tryLock(key, 600000, 600000);Assert.assertTrue(optLocked.isPresent());Optional<LockResource> optLocked2 = distributedLocker.tryLock(key, 600000, 600000);Assert.assertTrue(optLocked2.isPresent());optLocked.get().unlock();}/*** 模拟2个线程争抢锁:A先获取到锁,A释放锁后,B再获得锁*/@Testpublic void tryLock2() throws Exception {String key = "mock-key:" + UUID.randomUUID().toString().replace("-", "");CountDownLatch countDownLatch = new CountDownLatch(1);Future<Optional<LockResource>> submit = executorServiceB.submit(() -> {countDownLatch.await();log.info("B尝试获得锁:thread={}", currentThreadId());return distributedLocker.tryLock(key, 600000, 600000);});log.info("A尝试获得锁:thread={}", currentThreadId());Optional<LockResource> optLocked = distributedLocker.tryLock(key, 300000, 600000);Assert.assertTrue(optLocked.isPresent());log.info("A已获得锁:thread={}", currentThreadId());countDownLatch.countDown();optLocked.get().unlock();log.info("A已释放锁:thread={}", currentThreadId());Optional<LockResource> lockResource2 = submit.get();Assert.assertTrue(lockResource2.isPresent());executorServiceB.submit(() -> {log.info("B已获得锁:thread={}", currentThreadId());lockResource2.get().unlock();log.info("B已释放锁:thread={}", currentThreadId());});}/*** 模拟3个线程争抢锁:A先获取到锁,A释放锁后,B和C同时争抢锁*/@Testpublic void tryLock3() throws Exception {String key = "mock-key:" + UUID.randomUUID().toString().replace("-", "");log.info("A尝试获得锁:thread={}", currentThreadId());Optional<LockResource> optLocked = distributedLocker.tryLock(key, 600000, 600000);if (optLocked.isPresent()) {log.info("A已获得锁:thread={}", currentThreadId());}Assert.assertTrue(optLocked.isPresent());CyclicBarrier cyclicBarrier = new CyclicBarrier(2);Future<Optional<LockResource>> submitB = executorServiceB.submit(() -> {cyclicBarrier.await();log.info("B尝试获得锁:thread={}", currentThreadId());return distributedLocker.tryLock(key, 600000, 600000);});Future<Optional<LockResource>> submitC = executorServiceC.submit(() -> {cyclicBarrier.await();log.info("C尝试获得锁:thread={}", currentThreadId());return distributedLocker.tryLock(key, 600000, 600000);});optLocked.get().unlock();log.info("A已释放锁:thread={}", currentThreadId());CountDownLatch countDownLatch = new CountDownLatch(2);executorServiceB.submit(() -> {log.info("B已获得锁:thread={}", currentThreadId());try {submitB.get().get().unlock();} catch (InterruptedException | ExecutionException e) {e.printStackTrace();}log.info("B已释放锁:thread={}", currentThreadId());countDownLatch.countDown();});executorServiceC.submit(() -> {log.info("C已获得锁:thread={}", currentThreadId());try {submitC.get().get().unlock();} catch (InterruptedException | ExecutionException e) {e.printStackTrace();}log.info("C已释放锁:thread={}", currentThreadId());countDownLatch.countDown();});countDownLatch.await();}private static Long currentThreadId() {return Thread.currentThread().getId();}@Testpublic void tryLockWaitTimeout() throws Exception {String key = "mock-key:" + UUID.randomUUID().toString();Optional<LockResource> optLocked = distributedLocker.tryLock(key, 10, 2000);Assert.assertTrue(optLocked.isPresent());Optional<LockResource> optLockResource = CompletableFuture.supplyAsync(() -> {long now = System.currentTimeMillis();Optional<LockResource> optLockedAgain = distributedLocker.tryLock(key, 1000, 10);long cost = System.currentTimeMillis() - now;log.info("cost={}", cost);return optLockedAgain;}).exceptionally(th -> {log.error("Exception: ", th);return Optional.empty();}).join();Assert.assertTrue(!optLockResource.isPresent());}@Testpublic void tryLockWithLeaseTime() throws Exception {String key = "mock-key-with-leaseTime:" + UUID.randomUUID().toString();Optional<LockResource> optLocked = distributedLocker.tryLock(key, 3000, 1000);Assert.assertTrue(optLocked.isPresent());// 可重入Optional<LockResource> optLockedAgain = distributedLocker.tryLock(key, 3000, 1000);Assert.assertTrue(optLockedAgain.isPresent());}/*** 模拟1000个并发请求枪一把锁*/@Testpublic void tryLockWithLeaseTimeOnMultiThread() throws Exception {int totalThread = 1000;String key = "mock-key-with-leaseTime:" + UUID.randomUUID().toString();AtomicInteger tryAcquireLockTimes = new AtomicInteger(0);AtomicInteger acquiredLockTimes = new AtomicInteger(0);ExecutorService executor = Executors.newFixedThreadPool(totalThread);for (int i = 0; i < totalThread; i++) {executor.submit(new Runnable() {@Overridepublic void run() {tryAcquireLockTimes.getAndIncrement();Optional<LockResource> optLocked = distributedLocker.tryLock(key, 10, 10000);if (optLocked.isPresent()) {acquiredLockTimes.getAndIncrement();}}});}executor.awaitTermination(15, TimeUnit.SECONDS);Assert.assertTrue(tryAcquireLockTimes.get() == totalThread);Assert.assertTrue(acquiredLockTimes.get() == 1);}@Testpublic void tryLockWithLeaseTimeOnMultiThread2() throws Exception {int totalThread = 100;String key = "mock-key-with-leaseTime:" + UUID.randomUUID().toString();AtomicInteger tryAcquireLockTimes = new AtomicInteger(0);AtomicInteger acquiredLockTimes = new AtomicInteger(0);ExecutorService executor = Executors.newFixedThreadPool(totalThread);for (int i = 0; i < totalThread; i++) {executor.submit(new Runnable() {@Overridepublic void run() {long now = System.currentTimeMillis();Optional<LockResource> optLocked = distributedLocker.tryLock(key, 10000, 5);long cost = System.currentTimeMillis() - now;log.info("tryAcquireLockTimes={}||wait={}", tryAcquireLockTimes.incrementAndGet(), cost);if (optLocked.isPresent()) {acquiredLockTimes.getAndIncrement();// 主动释放锁optLocked.get().unlock();}}});}executor.awaitTermination(20, TimeUnit.SECONDS);log.info("tryAcquireLockTimes={}, acquireLockTimes={}", tryAcquireLockTimes.get(), acquiredLockTimes.get());Assert.assertTrue(tryAcquireLockTimes.get() == totalThread);Assert.assertTrue(acquiredLockTimes.get() == totalThread);}}public interface DistributedLocker {Optional<LockResource> tryLock(String lockKey, int waitTime);Optional<LockResource> tryLock(String lockKey, int waitTime, int leaseTime);}public interface LockResource {void unlock();}
执行的Lua脚本如下:
加锁:redissonClient.getLock(“my_first_lock_name”).tryLock(600000, 600000);
解锁:redissonClient.getLock(“my_first_lock_name”).unlock();
# 线程A
## 1.1.1尝试获取锁 -> 成功
1568357723.205362 [0 127.0.0.1:56419] "EVAL" "if (redis.call('exists', KEYS[1]) == 0) then redis.call('hset', KEYS[1], ARGV[2], 1); redis.call('pexpire', KEYS[1], ARGV[1]); return nil; end; if (redis.call('hexists', KEYS[1], ARGV[2]) == 1) then redis.call('hincrby', KEYS[1], ARGV[2], 1); redis.call('pexpire', KEYS[1], ARGV[1]); return nil; end; return redis.call('pttl', KEYS[1]);" "1" "my_first_lock_name" "600000" "58c62432-bb74-4d14-8a00-9908cc8b828f:1"
1568357723.205452 [0 lua] "exists" "my_first_lock_name"
1568357723.208858 [0 lua] "hset" "my_first_lock_name" "58c62432-bb74-4d14-8a00-9908cc8b828f:1" "1"
1568357723.208874 [0 lua] "pexpire" "my_first_lock_name" "600000"# 线程B
### 2.1.1尝试获取锁,未获取到,返回锁剩余过期时间
1568357773.338018 [0 127.0.0.1:56417] "EVAL" "if (redis.call('exists', KEYS[1]) == 0) then redis.call('hset', KEYS[1], ARGV[2], 1); redis.call('pexpire', KEYS[1], ARGV[1]); return nil; end; if (redis.call('hexists', KEYS[1], ARGV[2]) == 1) then redis.call('hincrby', KEYS[1], ARGV[2], 1); redis.call('pexpire', KEYS[1], ARGV[1]); return nil; end; return redis.call('pttl', KEYS[1]);" "1" "my_first_lock_name" "600000" "58c62432-bb74-4d14-8a00-9908cc8b828f:26"
1568357773.338161 [0 lua] "exists" "my_first_lock_name"
1568357773.338177 [0 lua] "hexists" "my_first_lock_name" "58c62432-bb74-4d14-8a00-9908cc8b828f:26"
1568357773.338197 [0 lua] "pttl" "my_first_lock_name"## 2.1.1.3 添加订阅(非Lua脚本) -> 订阅成功
1568357799.403341 [0 127.0.0.1:56421] "SUBSCRIBE" "redisson_lock__channel:{my_first_lock_name}"## 2.1.1.4 再次尝试获取锁 -> 未获取到,返回锁剩余过期时间
1568357830.683631 [0 127.0.0.1:56418] "EVAL" "if (redis.call('exists', KEYS[1]) == 0) then redis.call('hset', KEYS[1], ARGV[2], 1); redis.call('pexpire', KEYS[1], ARGV[1]); return nil; end; if (redis.call('hexists', KEYS[1], ARGV[2]) == 1) then redis.call('hincrby', KEYS[1], ARGV[2], 1); redis.call('pexpire', KEYS[1], ARGV[1]); return nil; end; return redis.call('pttl', KEYS[1]);" "1" "my_first_lock_name" "600000" "58c62432-bb74-4d14-8a00-9908cc8b828f:26"
1568357830.684371 [0 lua] "exists" "my_first_lock_name"
1568357830.684428 [0 lua] "hexists" "my_first_lock_name" "58c62432-bb74-4d14-8a00-9908cc8b828f:26"
1568357830.684485 [0 lua] "pttl" "my_first_lock_name"# 线程A
## 3.1.1 释放锁并广播解锁消息,0代表解锁消息
1568357922.122454 [0 127.0.0.1:56420] "EVAL" "if (redis.call('exists', KEYS[1]) == 0) then redis.call('publish', KEYS[2], ARGV[1]); return 1; end;if (redis.call('hexists', KEYS[1], ARGV[3]) == 0) then return nil;end; local counter = redis.call('hincrby', KEYS[1], ARGV[3], -1); if (counter > 0) then redis.call('pexpire', KEYS[1], ARGV[2]); return 0; else redis.call('del', KEYS[1]); redis.call('publish', KEYS[2], ARGV[1]); return 1; end; return nil;" "2" "my_first_lock_name" "redisson_lock__channel:{my_first_lock_name}" "0" "30000" "58c62432-bb74-4d14-8a00-9908cc8b828f:1"
1568357922.123645 [0 lua] "exists" "my_first_lock_name"
1568357922.123701 [0 lua] "hexists" "my_first_lock_name" "58c62432-bb74-4d14-8a00-9908cc8b828f:1"
1568357922.123741 [0 lua] "hincrby" "my_first_lock_name" "58c62432-bb74-4d14-8a00-9908cc8b828f:1" "-1"
1568357922.123775 [0 lua] "del" "my_first_lock_name"
1568357922.123799 [0 lua] "publish" "redisson_lock__channel:{my_first_lock_name}" "0"# 线程B
## 监听到解锁消息消息 -> 释放信号量,阻塞被解除;4.1.1.1 再次尝试获取锁 -> 获取成功
1568357975.015206 [0 127.0.0.1:56419] "EVAL" "if (redis.call('exists', KEYS[1]) == 0) then redis.call('hset', KEYS[1], ARGV[2], 1); redis.call('pexpire', KEYS[1], ARGV[1]); return nil; end; if (redis.call('hexists', KEYS[1], ARGV[2]) == 1) then redis.call('hincrby', KEYS[1], ARGV[2], 1); redis.call('pexpire', KEYS[1], ARGV[1]); return nil; end; return redis.call('pttl', KEYS[1]);" "1" "my_first_lock_name" "600000" "58c62432-bb74-4d14-8a00-9908cc8b828f:26"
1568357975.015579 [0 lua] "exists" "my_first_lock_name"
1568357975.015633 [0 lua] "hset" "my_first_lock_name" "58c62432-bb74-4d14-8a00-9908cc8b828f:26" "1"
1568357975.015721 [0 lua] "pexpire" "my_first_lock_name" "600000"## 4.1.1.3 取消订阅(非Lua脚本)
1568358031.185226 [0 127.0.0.1:56421] "UNSUBSCRIBE" "redisson_lock__channel:{my_first_lock_name}"# 线程B
## 5.1.1 释放锁并广播解锁消息
1568358255.551896 [0 127.0.0.1:56417] "EVAL" "if (redis.call('exists', KEYS[1]) == 0) then redis.call('publish', KEYS[2], ARGV[1]); return 1; end;if (redis.call('hexists', KEYS[1], ARGV[3]) == 0) then return nil;end; local counter = redis.call('hincrby', KEYS[1], ARGV[3], -1); if (counter > 0) then redis.call('pexpire', KEYS[1], ARGV[2]); return 0; else redis.call('del', KEYS[1]); redis.call('publish', KEYS[2], ARGV[1]); return 1; end; return nil;" "2" "my_first_lock_name" "redisson_lock__channel:{my_first_lock_name}" "0" "30000" "58c62432-bb74-4d14-8a00-9908cc8b828f:26"
1568358255.552125 [0 lua] "exists" "my_first_lock_name"
1568358255.552156 [0 lua] "hexists" "my_first_lock_name" "58c62432-bb74-4d14-8a00-9908cc8b828f:26"
1568358255.552200 [0 lua] "hincrby" "my_first_lock_name" "58c62432-bb74-4d14-8a00-9908cc8b828f:26" "-1"
1568358255.552258 [0 lua] "del" "my_first_lock_name"
1568358255.552304 [0 lua] "publish" "redisson_lock__channel:{my_first_lock_name}" "0"
需要特别注意的是,RedissonLock 同样没有解决 节点挂掉的时候,存在丢失锁的风险的问题。而现实情况是有一些场景无法容忍的,所以 Redisson 提供了实现了redlock算法的 RedissonRedLock,RedissonRedLock 真正解决了单点失败的问题,代价是需要额外的为 RedissonRedLock 搭建Redis环境。
所以,如果业务场景可以容忍这种小概率的错误,则推荐使用 RedissonLock, 如果无法容忍,则推荐使用 RedissonRedLock。
redlock算法
Redis 官网对 redLock 算法的介绍大致如下:
The Redlock algorithm
在分布式版本的算法里我们假设我们有N个Redis master节点,这些节点都是完全独立的,我们不用任何复制或者其他隐含的分布式协调机制。之前我们已经描述了在Redis单实例下怎么安全地获取和释放锁。我们确保将在每(N)个实例上使用此方法获取和释放锁。在我们的例子里面我们把N设成5,这是一个比较合理的设置,所以我们需要在5台机器上面或者5台虚拟机上面运行这些实例,这样保证他们不会同时都宕掉。为了取到锁,客户端应该执行以下操作:
-
获取当前Unix时间,以毫秒为单位。
-
依次尝试从5个实例,使用相同的key和具有唯一性的value(例如UUID)获取锁。当向Redis请求获取锁时,客户端应该设置一个尝试从某个Reids实例获取锁的最大等待时间(超过这个时间,则立马询问下一个实例),这个超时时间应该小于锁的失效时间。例如你的锁自动失效时间为10秒,则超时时间应该在5-50毫秒之间。这样可以避免服务器端Redis已经挂掉的情况下,客户端还在死死地等待响应结果。如果服务器端没有在规定时间内响应,客户端应该尽快尝试去另外一个Redis实例请求获取锁。
-
客户端使用当前时间减去开始获取锁时间(步骤1记录的时间)就得到获取锁消耗的时间。当且仅当从大多数(N/2+1,这里是3个节点)的Redis节点都取到锁,并且使用的总耗时小于锁失效时间时,锁才算获取成功。
-
如果取到了锁,key的真正有效时间 = 有效时间(获取锁时设置的key的自动超时时间) - 获取锁的总耗时(询问各个Redis实例的总耗时之和)(步骤3计算的结果)。
-
如果因为某些原因,最终获取锁失败(即没有在至少 “N/2+1 ”个Redis实例取到锁或者“获取锁的总耗时”超过了“有效时间”),客户端应该在所有的Redis实例上进行解锁(即便某些Redis实例根本就没有加锁成功,这样可以防止某些节点获取到锁但是客户端没有得到响应而导致接下来的一段时间不能被重新获取锁)。
用 Redisson 实现分布式锁(红锁 RedissonRedLock)及源码分析(实现三)
这里以三个单机模式为例,需要特别注意的是他们完全互相独立,不存在主从复制或者其他集群协调机制。
Config config1 = new Config();
config1.useSingleServer().setAddress("redis://172.0.0.1:5378").setPassword("a123456").setDatabase(0);
RedissonClient redissonClient1 = Redisson.create(config1);Config config2 = new Config();
config2.useSingleServer().setAddress("redis://172.0.0.1:5379").setPassword("a123456").setDatabase(0);
RedissonClient redissonClient2 = Redisson.create(config2);Config config3 = new Config();
config3.useSingleServer().setAddress("redis://172.0.0.1:5380").setPassword("a123456").setDatabase(0);
RedissonClient redissonClient3 = Redisson.create(config3);/*** 获取多个 RLock 对象*/
RLock lock1 = redissonClient1.getLock(lockKey);
RLock lock2 = redissonClient2.getLock(lockKey);
RLock lock3 = redissonClient3.getLock(lockKey);/*** 根据多个 RLock 对象构建 RedissonRedLock (最核心的差别就在这里)*/
RedissonRedLock redLock = new RedissonRedLock(lock1, lock2, lock3);try {/*** 4.尝试获取锁* waitTimeout 尝试获取锁的最大等待时间,超过这个值,则认为获取锁失败* leaseTime 锁的持有时间,超过这个时间锁会自动失效(值应设置为大于业务处理的时间,确保在锁有效期内业务能处理完)*/boolean res = redLock.tryLock((long)waitTimeout, (long)leaseTime, TimeUnit.SECONDS);if (res) {//成功获得锁,在这里处理业务}
} catch (Exception e) {throw new RuntimeException("aquire lock fail");
}finally{//无论如何, 最后都要解锁redLock.unlock();
}
最核心的变化就是需要构建多个 RLock ,然后根据多个 RLock 构建成一个 RedissonRedLock,因为 redLock 算法是建立在多个互相独立的 Redis 环境之上的(为了区分可以叫为 Redission node),Redission node 节点既可以是单机模式(single),也可以是主从模式(master/salve),哨兵模式(sentinal),或者集群模式(cluster)。这就意味着,不能跟以往这样只搭建 1个 cluster、或 1个 sentinel 集群,或是1套主从架构就了事了,需要为 RedissonRedLock 额外搭建多几套独立的 Redission 节点。 比如可以搭建3个 或者5个 Redission节点,具体可看视资源及业务情况而定。
下图是一个利用多个 Redission node 最终 组成 RedLock分布式锁的例子,需要特别注意的是每个 Redission node 是互相独立的,不存在任何复制或者其他隐含的分布式协调机制。


Redisson 实现redlock算法源码分析(RedLock)
加锁核心代码
org.redisson.RedissonMultiLock#tryLock
public boolean tryLock(long waitTime, long leaseTime, TimeUnit unit) throws InterruptedException {long newLeaseTime = -1;if (leaseTime != -1) {newLeaseTime = unit.toMillis(waitTime)*2;}long time = System.currentTimeMillis();long remainTime = -1;if (waitTime != -1) {remainTime = unit.toMillis(waitTime);}long lockWaitTime = calcLockWaitTime(remainTime);/*** 1. 允许加锁失败节点个数限制(N-(N/2+1))*/int failedLocksLimit = failedLocksLimit();/*** 2. 遍历所有节点通过EVAL命令执行lua加锁*/List<RLock> acquiredLocks = new ArrayList<>(locks.size());for (ListIterator<RLock> iterator = locks.listIterator(); iterator.hasNext();) {RLock lock = iterator.next();boolean lockAcquired;/*** 3.对节点尝试加锁*/try {if (waitTime == -1 && leaseTime == -1) {lockAcquired = lock.tryLock();} else {long awaitTime = Math.min(lockWaitTime, remainTime);lockAcquired = lock.tryLock(awaitTime, newLeaseTime, TimeUnit.MILLISECONDS);}} catch (RedisResponseTimeoutException e) {// 如果抛出这类异常,为了防止加锁成功,但是响应失败,需要解锁所有节点unlockInner(Arrays.asList(lock));lockAcquired = false;} catch (Exception e) {// 抛出异常表示获取锁失败lockAcquired = false;}if (lockAcquired) {/***4. 如果获取到锁则添加到已获取锁集合中*/acquiredLocks.add(lock);} else {/*** 5. 计算已经申请锁失败的节点是否已经到达 允许加锁失败节点个数限制 (N-(N/2+1))* 如果已经到达, 就认定最终申请锁失败,则没有必要继续从后面的节点申请了* 因为 Redlock 算法要求至少N/2+1 个节点都加锁成功,才算最终的锁申请成功*/if (locks.size() - acquiredLocks.size() == failedLocksLimit()) {break;}if (failedLocksLimit == 0) {unlockInner(acquiredLocks);if (waitTime == -1 && leaseTime == -1) {return false;}failedLocksLimit = failedLocksLimit();acquiredLocks.clear();// reset iteratorwhile (iterator.hasPrevious()) {iterator.previous();}} else {failedLocksLimit--;}}/*** 6.计算 目前从各个节点获取锁已经消耗的总时间,如果已经等于最大等待时间,则认定最终申请锁失败,返回false*/if (remainTime != -1) {remainTime -= System.currentTimeMillis() - time;time = System.currentTimeMillis();if (remainTime <= 0) {unlockInner(acquiredLocks);return false;}}}if (leaseTime != -1) {List<RFuture<Boolean>> futures = new ArrayList<>(acquiredLocks.size());for (RLock rLock : acquiredLocks) {RFuture<Boolean> future = ((RedissonLock) rLock).expireAsync(unit.toMillis(leaseTime), TimeUnit.MILLISECONDS);futures.add(future);}for (RFuture<Boolean> rFuture : futures) {rFuture.syncUninterruptibly();}}/*** 7.如果逻辑正常执行完则认为最终申请锁成功,返回true*/return true;
}
分布式锁:加解锁 续租 一致
分布式锁及其应用场景
应用开发时,如果需要在同进程内的不同线程并发访问某项资源,可以使用各种互斥锁、读写锁;
如果一台主机上的多个进程需要并发访问某项资源,则可以使用进程间同步的原语,例如信号量、管道、共享内存等。
但如果多台主机需要同时访问某项资源,就需要使用一种在全局可见并具有互斥性的锁了。
这种锁就是分布式锁,可以在分布式场景中对资源加锁,避免竞争资源引起的逻辑错误。
为何需要分布式锁
Martin Kleppmann 是英国剑桥大学的分布式系统的研究员,之前和 Redis 之父 Antirez 进行过关于 RedLock(红锁,后续有讲到)是否安全的激烈讨论。
Martin 认为一般我们使用分布式锁有两个场景:
- 效率:使用分布式锁可以避免不同节点重复相同的工作,这些工作会浪费资源。比如用户付了钱之后有可能不同节点会发出多封短信。
- 正确性:加分布式锁同样可以避免破坏正确性的发生,如果两个节点在同一条数据上面操作,比如多个节点机器对同一个订单操作不同的流程有可能会导致该笔订单最后状态出现错误,造成损失。
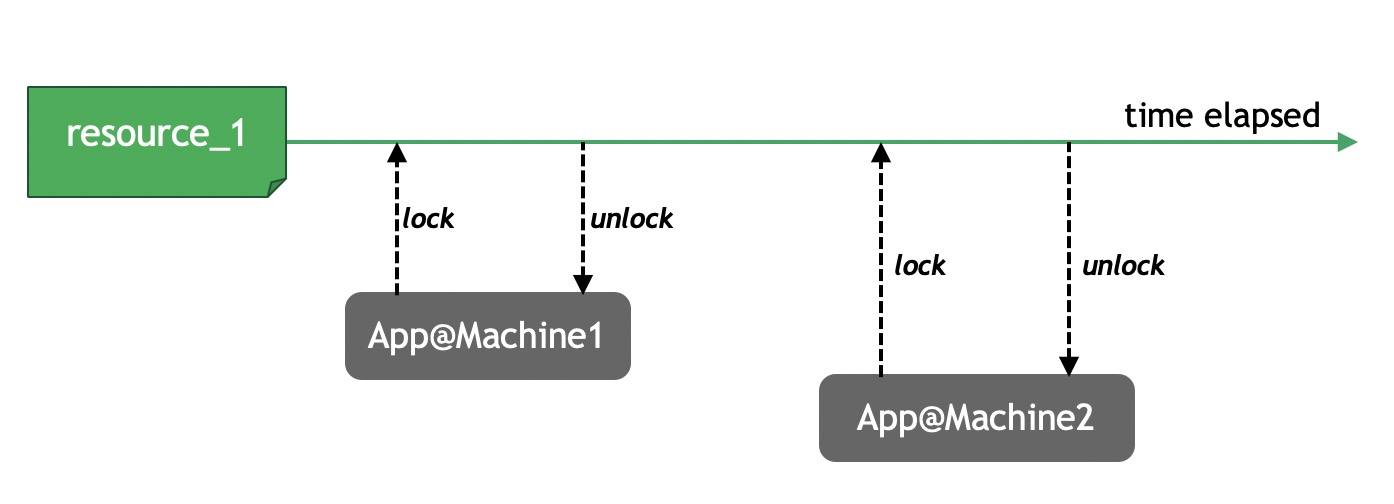
分布式锁的特性
互斥性
在任意时刻,只有一个客户端持有锁。
不死锁
分布式锁本质上是一个基于租约(Lease)的租借锁,如果客户端获得锁后自身出现异常,锁能够在一段时间后自动释放,资源不会被锁死。
和本地锁一样支持锁超时,防止死锁。
一致性
硬件故障或网络异常等外部问题,以及慢查询、自身缺陷等内部因素都可能导致Redis发生高可用切换,replica提升为新的master。
此时,如果业务对互斥性的要求非常高,锁需要在切换到新的master后保持原状态。
加锁和解锁需要高效,同时也需要保证高可用防止分布式锁失效,可以增加降级。
可重入性
同一个节点上的同一个线程如果获取了锁之后那么也可以再次获取这个锁
支持阻塞和非阻塞:
和 ReentrantLock 一样支持 lock 和 trylock 以及 tryLock(long timeOut)。
支持公平锁和非公平锁(可选)
公平锁的意思是按照请求加锁的顺序获得锁,非公平锁就相反是无序的。这个一般来说实现的比较少。
使用原生Redis实现分布式锁
加锁
在Redis中加锁非常简便,直接使用SET命令即可。示例及关键选项说明如下:
SET resource_1 random_value NX EX 5
表 1. 关键选项说明
参数/选项 说明 resource_1 分布式锁的key,只要这个key存在,相应的资源就处于加锁状态,无法被其它客户端访问。 random_value 一个随机字符串,不同客户端设置的值不能相同。 EX
设置过期时间,单位为秒。
您也可以使用PX选项设置单位为毫秒的过期时间。
NX 如果需要设置的key在Redis中已存在,则取消设置。
示例代码为resource_1这个key设置了5秒的过期时间,如果客户端不释放这个key,5秒后key将过期,锁就会被系统回收,此时其它客户端就能够再次为资源加锁并访问资源了。
解锁
解锁一般使用DEL命令,但可能存在下列问题。
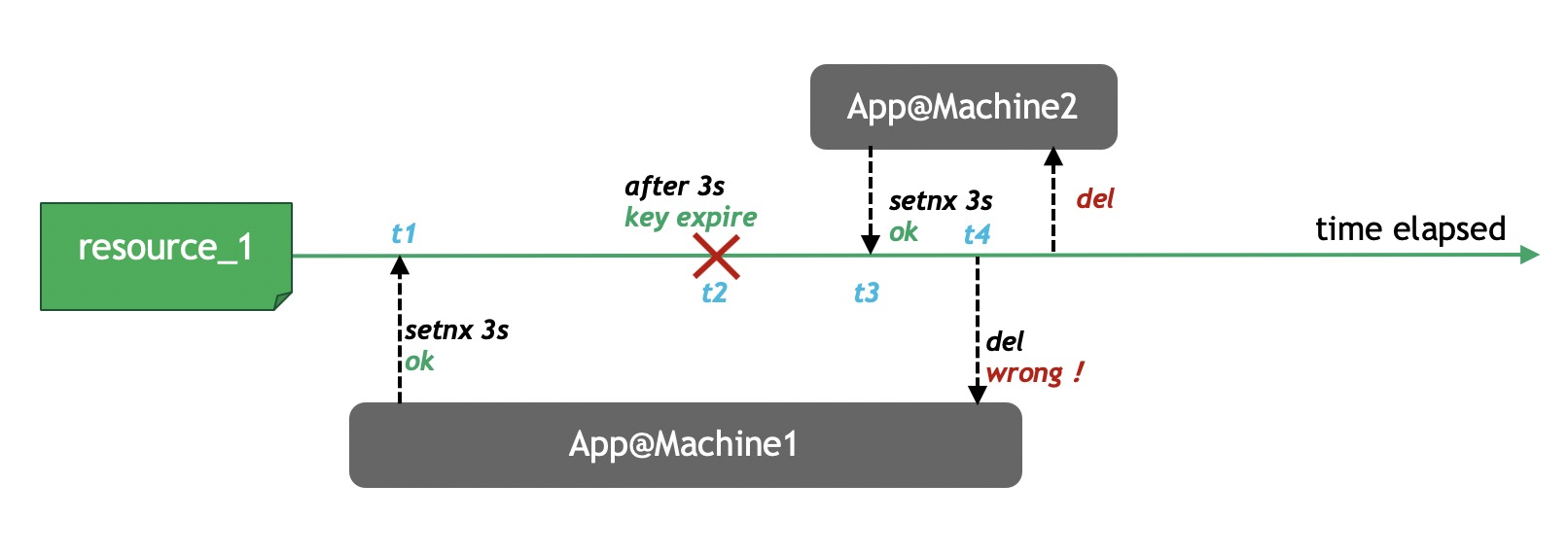
- t1时刻,App1设置了分布式锁resource_1,过期时间为3秒。
- App1由于程序慢等原因等待超过了3秒,而resource_1已经在t2时刻被释放。
- t3时刻,App2获得这个分布式锁。
- App1从等待中恢复,在t4时刻运行
DEL resource_1将App2持有的分布式锁释放了。
从上述过程可以看出,一个客户端设置的锁,必须由自己解开。因此客户端需要先使用GET命令确认锁是不是自己设置的,然后再使用DEL解锁。在Redis中通常需要用Lua脚本来实现自锁自解:
if redis.call("get",KEYS[1]) == ARGV[1] thenreturn redis.call("del",KEYS[1])
elsereturn 0
end
续租
当客户端发现在锁的租期内无法完成操作时,就需要延长锁的持有时间,进行续租(renew)。同解锁一样,客户端应该只能续租自己持有的锁。在Redis中可使用如下Lua脚本来实现续租:
if redis.call("get",KEYS[1]) == ARGV[1] thenreturn redis.call("expire",KEYS[1], ARGV[2])
elsereturn 0
end
如何保障一致性
集群问题
1.主备切换
为了保证 Redis 的可用性,一般采用主从方式部署。主从数据同步有异步和同步两种方式,Redis 将指令记录在本地内存 buffer 中,然后异步将 buffer 中的指令同步到从节点,从节点一边执行同步的指令流来达到和主节点一致的状态,一边向主节点反馈同步情况。
在包含主从模式的集群部署方式中,当主节点挂掉时,从节点会取而代之,但客户端无明显感知。当客户端 A 成功加锁,指令还未同步,此时主节点挂掉,从节点提升为主节点,新的主节点没有锁的数据,当客户端 B 加锁时就会成功。
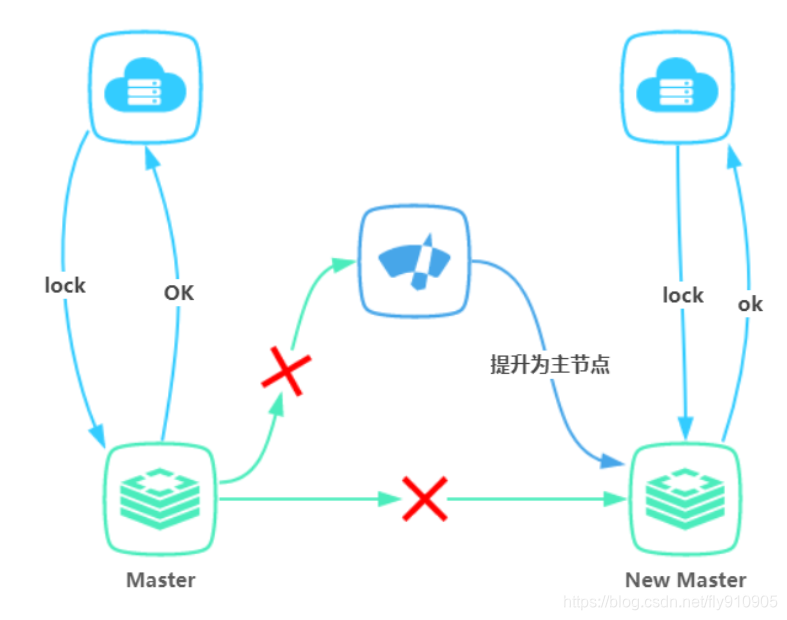
2. 集群脑裂
集群脑裂指因为网络问题,导致 Redis master 节点跟 slave 节点和 sentinel 集群处于不同的网络分区,因为 sentinel 集群无法感知到 master 的存在,所以将 slave 节点提升为 master 节点,此时存在两个不同的 master 节点。Redis Cluster 集群部署方式同理。
当不同的客户端连接不同的 master 节点时,两个客户端可以同时拥有同一把锁。如下:
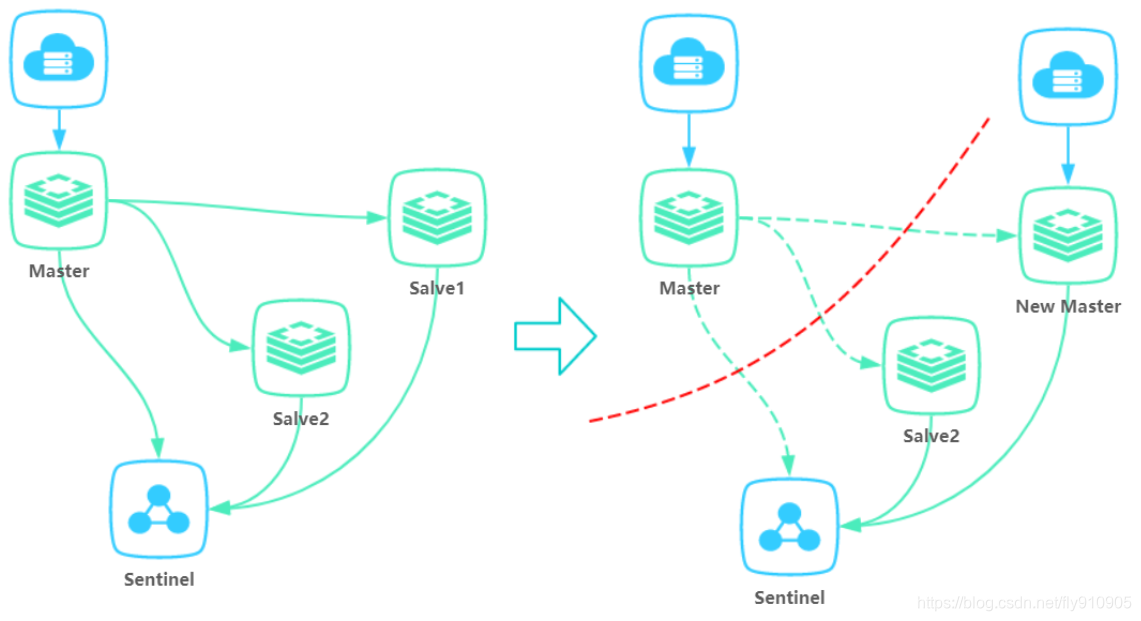
集群问题解决
Redis的主从同步(replication)是异步进行的,如果向master发送请求修改了数据后master突然出现异常,发生高可用切换,缓冲区的数据可能无法同步到新的master(原replica)上,导致数据不一致。如果丢失的数据跟分布式锁有关,则会导致锁的机制出现问题,从而引起业务异常。下文介绍三种保障一致性的方法。
使用红锁(RedLock)
红锁是Redis作者提出的一致性解决方案。红锁的本质是一个概率问题:如果一个主从架构的Redis在高可用切换期间丢失锁的概率是k%,那么相互独立的N个Redis同时丢失锁的概率是多少?如果用红锁来实现分布式锁,那么丢锁的概率是(k%)^N。鉴于Redis极高的稳定性,此时的概率已经完全能满足产品的需求。
说明 红锁的实现并非这样严格,一般保证`M(1个同时锁上即可,但通常仍旧可以满足需求。
红锁的问题:
- 加锁和解锁的延迟较大。
- 难以在集群版或者标准版(主从架构)的Redis实例中实现。
- 占用的资源过多,为了实现红锁,需要创建多个互不相关的云Redis实例或者自建Redis。
使用WAIT命令。
Redis的**WAIT命令会阻塞当前客户端,直到这条命令之前的所有写入命令都成功从master同步到指定数量的replica,命令中可以设置单位为毫秒的等待超时时间。在云Redis版中使用WAIT命令提高分布式锁**一致性的示例如下:
SET resource_1 random_value NX EX 5
WAIT 1 5000
使用以上代码,客户端在加锁后会等待数据成功同步到replica才继续进行其它操作,最大等待时间为5000毫秒。执行WAIT命令后如果返回结果是1则表示同步成功,无需担心数据不一致。相比红锁,这种实现方法极大地降低了成本。
需要注意的是:
- WAIT只会阻塞发送它的客户端,不影响其它客户端。
- WAIT返回正确的值表示设置的锁成功同步到了replica,但如果在正常返回前发生高可用切换,数据还是可能丢失,此时WAIT只能用来提示同步可能失败,无法保证数据不丢失。您可以在WAIT返回异常值后重新加锁或者进行数据校验。
- 解锁不一定需要使用WAIT,因为锁只要存在就能保持互斥,延迟删除不会导致逻辑问题。
分布式锁:看门狗
1、锁住对象,并且设置一个过期时间(业务逻辑操作时间一定小于超时时间)
原先能想到的就是这样的一个方案然后代码实现如下:
public static boolean lock(String key, Long expireTime) {final long expires = Objects.nonNull(expireTime) ? expireTime : 10L;return (Boolean) redisTemplate.execute((RedisCallback) connection -> {byte[] locks = key.getBytes();boolean acquire = connection.setNX(locks, key.getBytes());// 如果设置过期时间为空就删除keyif (acquire && !connection.expire(locks, expires)) {connection.del(locks);acquire = false;}return acquire;});
}
目前的案例里面分布式锁主要锁的是新增商品名称,业务就是新增商品而已
@PostMapping("addGoods")
@ApiOperation(value = "新增商品", notes = "新增商品")
public Result<Goods> addGoods(@RequestBody Goods goods) {final String key = "seckill-shopping:" + goods.getName();boolean lock = RedisUtil.lock(key, 10L);if (lock) {log.info("\n{} -->获取锁成功", Thread.currentThread().getName());goods = this.goodsService.insert(goods);RedisUtil.removelock(key);return Result.success(goods);}log.info("\n{} --> 获取锁失败", Thread.currentThread().getName());return Result.failure("服务暂时无法加载。。。");
使用jmeter开启5个线程迭代两次,看代码其实结果应该都可以猜得出来每一轮迭代只会成功一条数据,其他的都会失败,看看结果确实是这样的:

我们设计的时候默认的过期时间设置为了10s,假如业务操作导致超过了过期时间,我们看看会有什么问题。假设第一个获取到锁的业务操作时间为29s,其他的都是正常执行的看一下结果,第一个请求获取的锁过期了但是业务还在执行中,其他请求可以获取到锁并且可以执行业务,这就出现了超过过期时间锁不住的问题。(但是如果业务逻辑百分之百不会超过过期时间那就没必要续期了)

如果不需要续期但是上面的都只是单次获取失败就失败了,如果有的业务应该是多少时间内尝试获取失败才算失败,所以加上了一个尝试获取时间(getTime单位:秒)
public static boolean lock(String key, Long getTime, Long expireTime) {final long gets = Objects.nonNull(getTime) ? getTime : 10L;LocalDateTime localDateTime = LocalDateTime.now().plusSeconds(gets);final long expires = Objects.nonNull(expireTime) ? expireTime : 10L;return (Boolean) redisTemplate.execute((RedisCallback) connection -> {byte[] locks = key.getBytes();while (localDateTime.isAfter(LocalDateTime.now())) {boolean acquire = connection.setNX(locks, key.getBytes());// 如果设置过期时间失败就删除keyif (acquire && connection.expire(locks, expires)) {return true;} else if (acquire) {connection.del(locks);}// 随机休眠几毫秒int time = random.nextInt(10);try {Thread.sleep(time);} catch (InterruptedException e) {e.printStackTrace();}}return false;});
}
2、续过期时间(续期)
续期很多都是使用了Redis的看门狗,那么这个看门狗要怎么使用呢?
首先引入Redisson依赖
<dependency><groupId>org.redisson</groupId><artifactId>redisson-spring-boot-starter</artifactId><version>3.9.1</version>
</dependency>
默认配置文件里面数据:
spring:redis:database: 0host: 127.0.0.1port: 6379password: 123456
并且使用了自动配置,看门狗就使用了默认的时间
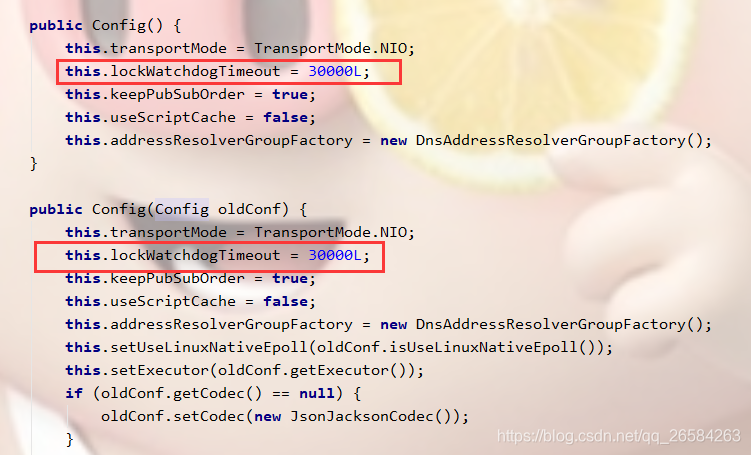
@PostMapping("addGoods")
@ApiOperation(value = "新增商品", notes = "新增商品")
public Result<Goods> addGoods(@RequestBody Goods goods) {RLock rLock = RedisUtils.getRLock(goods.getName());boolean islock = false;try {islock = rLock.tryLock(30, TimeUnit.SECONDS);if (islock) {log.info("\n{} --> 获取锁成功", Thread.currentThread().getName());goods = this.goodsService.insert(goods);if (count == 0) {++count;try {log.info("\n{} --> 获取到锁的睡眠40s", Thread.currentThread().getName());Thread.sleep(40000);log.info("\n{} --> 获取到锁的醒了", Thread.currentThread().getName());} catch (InterruptedException e) {e.printStackTrace();}}return Result.success(goods);}} catch (Exception e) {log.info("\n{} --> 获取锁失败:{}", Thread.currentThread().getName(), e);} finally {if (islock) {rLock.unlock();}}log.info("\n{} --> 获取锁失败", Thread.currentThread().getName());return Result.failure("服务暂时无法加载。。。");
}
对应有很多加锁的方法,只有tryLock方法才会续期的哦。
对应tryLock方法有:
rLock.tryLock(); 默认锁定30s,一次获取锁
rLock.tryLock(20, TimeUnit.SECONDS);默认锁定30s,20s内获取不到锁就返回失败
rLock.tryLock(20,60, TimeUnit.SECONDS); 默认锁定30s,20s内获取不到锁就返回失败,60s锁自动过期。
运行以后可以发现

锁相关的问题还有很多,由于使用的是redis就要考虑一个问题了,就是分布式锁还要考虑redis部署的问题,要使用分布式锁的前提你要把相对应的问题考虑清楚,否则上线都是问题了。
以上的是小辉对分布式锁理解以及使用,如果代码要用到线上项目请自己测试后评估后使用,因为最近看到了使用开源代码引发的线上事故,如果不是很了解的东西尽量少用或者不用,除非它是一个成熟的东西
分布书锁:原理
面试问题
Redis锁的过期时间小于业务的执行时间该如何续期?
问题分析
首先如果你之前用Redis的分布式锁的姿势正确,并且看过相应的官方文档的话,这个问题So easy.我们来看
很多同学在用分布式锁时,都是直接百度搜索找一个Redis分布式锁工具类就直接用了,其实Redis分布式锁比较正确的姿势是采用redisson这个客户端工具
可重入锁(Reentrant Lock):
基于Redis的Redisson分布式可重入锁 RLock Java对象实现了 java.util.concurrent.locks.Lock 接口。同事还提供了异步(Async)、反射式(Reactive)和RxJava2标准的接口。
RLock lock = redisson.getLock("anyLock");
// 最常见的使用方法
lock.lock();
大家都知道,如果负责存储这个分布式锁的Redisson节点宕机以后,而且这个锁正好处于锁住的状态时,这个锁会出现锁死的状态。为了避免这种情况的发生,Redission内部提供了一个监控锁的看门狗,它的作用是在Redisson实例被关闭前,不断的延长锁的有效期。默认情况下,看门狗的检查锁的超时时间是30秒钟,也可以通过修改Config.lockWatchdogTimeout来另行指定。
另外Redisson还通过加锁的方法提供了 leaseTime 的参数来指定加锁的时间。超过这个时间后锁便自动解开了。
如何回答
只要客户端一旦加锁成功,就会启动一个watch dog看门狗,他是一个后台线程,会每隔10秒检查一下,如果客户端还持有锁key,那么就会不断的延长锁key的生存时间。
默认情况下,加锁的时间是30秒,.如果加锁的业务没有执行完,就会进行一次续期,把锁重置成30秒.那这个时候可能又有同学问了,那业务的机器万一宕机了呢?宕机了定时任务跑不了,就续不了期,那自然30秒之后锁就解开了呗.
底层原理

1)加锁机制
咱们来看上面那张图,现在某个客户端要加锁。如果该客户端面对的是一个redis cluster集群,他首先会根据hash节点选择一台机器。
这里注意,仅仅只是选择一台机器!这点很关键!
紧接着,就会发送一段lua脚本到redis上,那段lua脚本如下所示:

为啥要用lua脚本呢?
因为一大坨复杂的业务逻辑,可以通过封装在lua脚本中发送给redis,保证这段复杂业务逻辑执行的原子性。
那么,这段lua脚本是什么意思呢?
**KEYS[1]**代表的是你加锁的那个key,比如说:
RLock lock = redisson.getLock(“myLock”);
这里你自己设置了加锁的那个锁key就是“myLock”。
**ARGV[1]**代表的就是锁key的默认生存时间,默认30秒。
**ARGV[2]**代表的是加锁的客户端的ID,类似于下面这样:
8743c9c0-0795-4907-87fd-6c719a6b4586:1
给大家解释一下,第一段if判断语句,就是用“exists myLock”命令判断一下,如果你要加锁的那个锁key不存在的话,你就进行加锁。
如何加锁呢?很简单,用下面的命令:
hset myLock
8743c9c0-0795-4907-87fd-6c719a6b4586:1 1
通过这个命令设置一个hash数据结构,这行命令执行后,会出现一个类似下面的数据结构:

上述就代表“8743c9c0-0795-4907-87fd-6c719a6b4586:1”这个客户端对“myLock”这个锁key完成了加锁。
接着会执行“pexpire myLock 30000”命令,设置myLock这个锁key的生存时间是30秒。
好了,到此为止,ok,加锁完成了。
(2)锁互斥机制
那么在这个时候,如果客户端2来尝试加锁,执行了同样的一段lua脚本,会咋样呢?
很简单,第一个if判断会执行“exists myLock”,发现myLock这个锁key已经存在了。
接着第二个if判断,判断一下,myLock锁key的hash数据结构中,是否包含客户端2的ID,但是明显不是的,因为那里包含的是客户端1的ID。
所以,客户端2会获取到pttl myLock返回的一个数字,这个数字代表了myLock这个锁key的剩余生存时间。比如还剩15000毫秒的生存时间。
此时客户端2会进入一个while循环,不停的尝试加锁。
(3)watch dog自动延期机制
客户端1加锁的锁key默认生存时间才30秒,如果超过了30秒,客户端1还想一直持有这把锁,怎么办呢?
简单!只要客户端1一旦加锁成功,就会启动一个watch dog看门狗,他是一个后台线程,会每隔10秒检查一下,如果客户端1还持有锁key,那么就会不断的延长锁key的生存时间。
(4)可重入加锁机制
那如果客户端1都已经持有了这把锁了,结果可重入的加锁会怎么样呢?
比如下面这种代码:

这时我们来分析一下上面那段lua脚本。
第一个if判断肯定不成立,“exists myLock”会显示锁key已经存在了。
第二个if判断会成立,因为myLock的hash数据结构中包含的那个ID,就是客户端1的那个ID,也就是“8743c9c0-0795-4907-87fd-6c719a6b4586:1”
此时就会执行可重入加锁的逻辑,他会用:
incrby myLock
8743c9c0-0795-4907-87fd-6c71a6b4586:1 1
通过这个命令,对客户端1的加锁次数,累加1。
此时myLock数据结构变为下面这样:

大家看到了吧,那个myLock的hash数据结构中的那个客户端ID,就对应着加锁的次数
(5)释放锁机制
如果执行lock.unlock(),就可以释放分布式锁,此时的业务逻辑也是非常简单的。
其实说白了,就是每次都对myLock数据结构中的那个加锁次数减1。
如果发现加锁次数是0了,说明这个客户端已经不再持有锁了,此时就会用:
“del myLock”命令,从redis里删除这个key。
然后呢,另外的客户端2就可以尝试完成加锁了。
这就是所谓的分布式锁的开源Redisson框架的实现机制。
一般我们在生产系统中,可以用Redisson框架提供的这个类库来基于redis进行分布式锁的加锁与释放锁。
(6)Redis分布式锁的缺点
其实上面那种方案最大的问题,就是如果你对某个redis master实例,写入了myLock这种锁key的value,此时会异步复制给对应的master slave实例。
但是这个过程中一旦发生redis master宕机,主备切换,redis slave变为了redis master。
接着就会导致,客户端2来尝试加锁的时候,在新的redis master上完成了加锁,而客户端1也以为自己成功加了锁。
此时就会导致多个客户端对一个分布式锁完成了加锁。
这时系统在业务语义上一定会出现问题,导致各种脏数据的产生。
所以这个就是redis cluster,或者是redis master-slave架构的主从异步复制导致的redis分布式锁的最大缺陷:在redis master实例宕机的时候,可能导致多个客户端同时完成加锁。
(7)Redis红锁
Redis作者针对Redis分布式锁的缺点提出了红锁的概念算法如下:
- 顺序向五个节点请求加锁
- 根据一定的超时时间来推断是不是跳过该节点
- 三个节点加锁成功并且花费时间小于锁的有效期
- 认定加锁成功
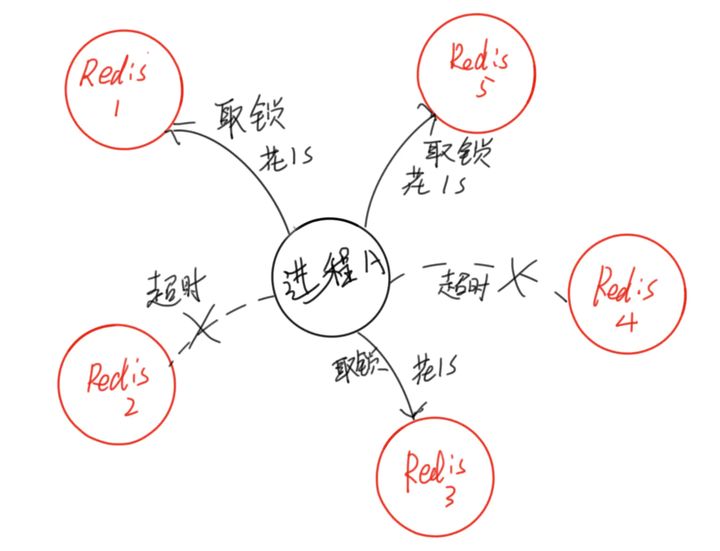
也就是说,假设锁30秒过期,三个节点加锁花了31秒,自然是加锁失败了。这只是举个例子,实际上并不应该等每个节点那么长时间,就像官网所说的那样,假设有效期是10秒,那么单个redis实例操作超时时间,应该在5到50毫秒(注意时间单位)还是假设我们设置有效期是30秒,图中超时了两个redis节点。那么加锁成功的节点总共花费了3秒,所以锁的实际有效期是小于27秒的。即扣除加锁成功三个实例的3秒,还要扣除等待超时redis实例的总共时间。
关于红锁的争论:Martin Kleppmann和antirez的redLock辩论. 一个是很有资历的分布式架构师,一个是redis之父。
所以说如果项目里要使用红锁,除了红锁的介绍,不妨要多看两篇文章,即:
- Martin Kleppmann的质疑贴
- antirez的反击贴
有些人是不是觉得大佬们都是杠精啊,天天就想着极端情况。 其实高可用嘛,拼的就是99.999…% 中小数点后面的位数。
其实,在实际场景中,红锁是很少使用的。这是因为使用了红锁后会影响高并发环境下的性能,使得程序的体验更差。所以,在实际场景中,我们一般都是要保证Redis集群的可靠性。同时,使用红锁后,当加锁成功的RLock个数不超过总数的一半时,会返回加锁失败,即使在业务层面任务加锁成功了,但是红锁也会返回加锁失败的结果。另外,使用红锁时,需要提供多套Redis的主从部署架构,同时,这多套Redis主从架构中的Master节点必须都是独立的,相互之间没有任何数据交互。
分布书锁:分段锁:
怎么在高并发的场景去实现一个高性能的分布式锁呢?
电商网站在大促的时候并发量很大:
(1)若抢购不是同一个商品,则可以增加Redis集群的cluster来实现,因为不是同一个商品,所以通过计算 key 的hash会落到不同的 cluster上;
(2)若抢购的是同一个商品,则计算key的hash值会落同一个cluster上,所以加机器也是没有用的。
针对第二个问题,可以使用库存分段锁的方式去实现。
分段锁
假如产品1有200个库存,可以将这200个库存分为10个段存储(每段20个),每段存储到一个cluster上;将key使用hash计算,使这些key最后落在不同的cluster上。
每个下单请求锁了一个库存分段,然后在业务逻辑里面,就对数据库或者是Redis中的那个分段库存进行操作即可,包括查库存 -> 判断库存是否充足 -> 扣减库存。
具体可以参照 ConcurrentHashMap 的源码去实现,它使用的就是分段锁。
原理如图:
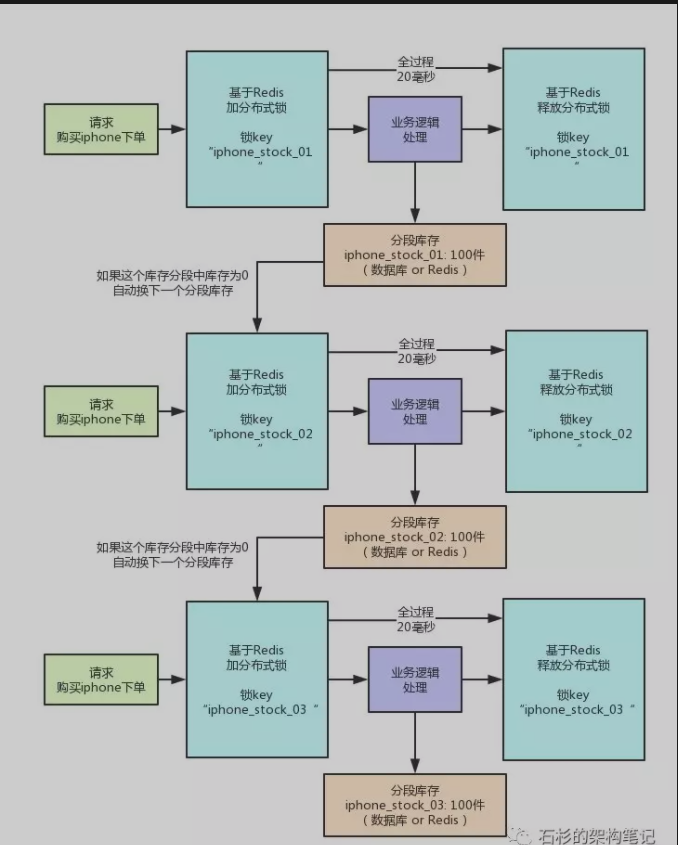
总结:
- 追求数据可靠性/强一致性:使用Zookeeper
- 追求性能:选择Redis,推荐Redisson
- Redis分布式锁目前最大问题在于:主从模式下/集群模式下,master节点宕机,异步同步数据导致锁丢失问题
- Redis的RedLock算法具有很大争议性,一般不推荐使用
分布书锁:原理
面试问题
Redis锁的过期时间小于业务的执行时间该如何续期?
问题分析
首先如果你之前用Redis的分布式锁的姿势正确,并且看过相应的官方文档的话,这个问题So easy.我们来看
很多同学在用分布式锁时,都是直接百度搜索找一个Redis分布式锁工具类就直接用了,其实Redis分布式锁比较正确的姿势是采用redisson这个客户端工具
可重入锁(Reentrant Lock):
基于Redis的Redisson分布式可重入锁 RLock Java对象实现了 java.util.concurrent.locks.Lock 接口。同事还提供了异步(Async)、反射式(Reactive)和RxJava2标准的接口。
RLock lock = redisson.getLock("anyLock");
// 最常见的使用方法
lock.lock();
大家都知道,如果负责存储这个分布式锁的Redisson节点宕机以后,而且这个锁正好处于锁住的状态时,这个锁会出现锁死的状态。为了避免这种情况的发生,Redission内部提供了一个监控锁的看门狗,它的作用是在Redisson实例被关闭前,不断的延长锁的有效期。默认情况下,看门狗的检查锁的超时时间是30秒钟,也可以通过修改Config.lockWatchdogTimeout来另行指定。
另外Redisson还通过加锁的方法提供了 leaseTime 的参数来指定加锁的时间。超过这个时间后锁便自动解开了。
如何回答
只要客户端一旦加锁成功,就会启动一个watch dog看门狗,他是一个后台线程,会每隔10秒检查一下,如果客户端还持有锁key,那么就会不断的延长锁key的生存时间。
默认情况下,加锁的时间是30秒,.如果加锁的业务没有执行完,就会进行一次续期,把锁重置成30秒.那这个时候可能又有同学问了,那业务的机器万一宕机了呢?宕机了定时任务跑不了,就续不了期,那自然30秒之后锁就解开了呗.
底层原理
1)加锁机制
咱们来看上面那张图,现在某个客户端要加锁。如果该客户端面对的是一个redis cluster集群,他首先会根据hash节点选择一台机器。
这里注意,仅仅只是选择一台机器!这点很关键!
紧接着,就会发送一段lua脚本到redis上,那段lua脚本如下所示:
为啥要用lua脚本呢?
因为一大坨复杂的业务逻辑,可以通过封装在lua脚本中发送给redis,保证这段复杂业务逻辑执行的原子性。
那么,这段lua脚本是什么意思呢?
**KEYS[1]**代表的是你加锁的那个key,比如说:
RLock lock = redisson.getLock(“myLock”);
这里你自己设置了加锁的那个锁key就是“myLock”。
**ARGV[1]**代表的就是锁key的默认生存时间,默认30秒。
**ARGV[2]**代表的是加锁的客户端的ID,类似于下面这样:
8743c9c0-0795-4907-87fd-6c719a6b4586:1
给大家解释一下,第一段if判断语句,就是用“exists myLock”命令判断一下,如果你要加锁的那个锁key不存在的话,你就进行加锁。
如何加锁呢?很简单,用下面的命令:
hset myLock
8743c9c0-0795-4907-87fd-6c719a6b4586:1 1
通过这个命令设置一个hash数据结构,这行命令执行后,会出现一个类似下面的数据结构:
上述就代表“8743c9c0-0795-4907-87fd-6c719a6b4586:1”这个客户端对“myLock”这个锁key完成了加锁。
接着会执行“pexpire myLock 30000”命令,设置myLock这个锁key的生存时间是30秒。
好了,到此为止,ok,加锁完成了。
(2)锁互斥机制
那么在这个时候,如果客户端2来尝试加锁,执行了同样的一段lua脚本,会咋样呢?
很简单,第一个if判断会执行“exists myLock”,发现myLock这个锁key已经存在了。
接着第二个if判断,判断一下,myLock锁key的hash数据结构中,是否包含客户端2的ID,但是明显不是的,因为那里包含的是客户端1的ID。
所以,客户端2会获取到pttl myLock返回的一个数字,这个数字代表了myLock这个锁key的剩余生存时间。比如还剩15000毫秒的生存时间。
此时客户端2会进入一个while循环,不停的尝试加锁。
(3)watch dog自动延期机制
客户端1加锁的锁key默认生存时间才30秒,如果超过了30秒,客户端1还想一直持有这把锁,怎么办呢?
简单!只要客户端1一旦加锁成功,就会启动一个watch dog看门狗,他是一个后台线程,会每隔10秒检查一下,如果客户端1还持有锁key,那么就会不断的延长锁key的生存时间。
(4)可重入加锁机制
那如果客户端1都已经持有了这把锁了,结果可重入的加锁会怎么样呢?
比如下面这种代码:
这时我们来分析一下上面那段lua脚本。
第一个if判断肯定不成立,“exists myLock”会显示锁key已经存在了。
第二个if判断会成立,因为myLock的hash数据结构中包含的那个ID,就是客户端1的那个ID,也就是“8743c9c0-0795-4907-87fd-6c719a6b4586:1”
此时就会执行可重入加锁的逻辑,他会用:
incrby myLock
8743c9c0-0795-4907-87fd-6c71a6b4586:1 1
通过这个命令,对客户端1的加锁次数,累加1。
此时myLock数据结构变为下面这样:
大家看到了吧,那个myLock的hash数据结构中的那个客户端ID,就对应着加锁的次数
(5)释放锁机制
如果执行lock.unlock(),就可以释放分布式锁,此时的业务逻辑也是非常简单的。
其实说白了,就是每次都对myLock数据结构中的那个加锁次数减1。
如果发现加锁次数是0了,说明这个客户端已经不再持有锁了,此时就会用:
“del myLock”命令,从redis里删除这个key。
然后呢,另外的客户端2就可以尝试完成加锁了。
这就是所谓的分布式锁的开源Redisson框架的实现机制。
一般我们在生产系统中,可以用Redisson框架提供的这个类库来基于redis进行分布式锁的加锁与释放锁。
(6)Redis分布式锁的缺点
其实上面那种方案最大的问题,就是如果你对某个redis master实例,写入了myLock这种锁key的value,此时会异步复制给对应的master slave实例。
但是这个过程中一旦发生redis master宕机,主备切换,redis slave变为了redis master。
接着就会导致,客户端2来尝试加锁的时候,在新的redis master上完成了加锁,而客户端1也以为自己成功加了锁。
此时就会导致多个客户端对一个分布式锁完成了加锁。
这时系统在业务语义上一定会出现问题,导致各种脏数据的产生。
所以这个就是redis cluster,或者是redis master-slave架构的主从异步复制导致的redis分布式锁的最大缺陷:在redis master实例宕机的时候,可能导致多个客户端同时完成加锁。
(7)Redis红锁
Redis作者针对Redis分布式锁的缺点提出了红锁的概念算法如下:
- 顺序向五个节点请求加锁
- 根据一定的超时时间来推断是不是跳过该节点
- 三个节点加锁成功并且花费时间小于锁的有效期
- 认定加锁成功
也就是说,假设锁30秒过期,三个节点加锁花了31秒,自然是加锁失败了。这只是举个例子,实际上并不应该等每个节点那么长时间,就像官网所说的那样,假设有效期是10秒,那么单个redis实例操作超时时间,应该在5到50毫秒(注意时间单位)还是假设我们设置有效期是30秒,图中超时了两个redis节点。那么加锁成功的节点总共花费了3秒,所以锁的实际有效期是小于27秒的。即扣除加锁成功三个实例的3秒,还要扣除等待超时redis实例的总共时间。
关于红锁的争论:Martin Kleppmann和antirez的redLock辩论. 一个是很有资历的分布式架构师,一个是redis之父。
所以说如果项目里要使用红锁,除了红锁的介绍,不妨要多看两篇文章,即:
- Martin Kleppmann的质疑贴
- antirez的反击贴
有些人是不是觉得大佬们都是杠精啊,天天就想着极端情况。 其实高可用嘛,拼的就是99.999…% 中小数点后面的位数。
其实,在实际场景中,红锁是很少使用的。这是因为使用了红锁后会影响高并发环境下的性能,使得程序的体验更差。所以,在实际场景中,我们一般都是要保证Redis集群的可靠性。同时,使用红锁后,当加锁成功的RLock个数不超过总数的一半时,会返回加锁失败,即使在业务层面任务加锁成功了,但是红锁也会返回加锁失败的结果。另外,使用红锁时,需要提供多套Redis的主从部署架构,同时,这多套Redis主从架构中的Master节点必须都是独立的,相互之间没有任何数据交互。
分布书锁:分段锁:
怎么在高并发的场景去实现一个高性能的分布式锁呢?
电商网站在大促的时候并发量很大:
(1)若抢购不是同一个商品,则可以增加Redis集群的cluster来实现,因为不是同一个商品,所以通过计算 key 的hash会落到不同的 cluster上;
(2)若抢购的是同一个商品,则计算key的hash值会落同一个cluster上,所以加机器也是没有用的。
针对第二个问题,可以使用库存分段锁的方式去实现。
分段锁
假如产品1有200个库存,可以将这200个库存分为10个段存储(每段20个),每段存储到一个cluster上;将key使用hash计算,使这些key最后落在不同的cluster上。
每个下单请求锁了一个库存分段,然后在业务逻辑里面,就对数据库或者是Redis中的那个分段库存进行操作即可,包括查库存 -> 判断库存是否充足 -> 扣减库存。
具体可以参照 ConcurrentHashMap 的源码去实现,它使用的就是分段锁。
原理如图:
总结:
- 追求数据可靠性/强一致性:使用Zookeeper
- 追求性能:选择Redis,推荐Redisson
- Redis分布式锁目前最大问题在于:主从模式下/集群模式下,master节点宕机,异步同步数据导致锁丢失问题
- Redis的RedLock算法具有很大争议性,一般不推荐使用