【T2I】Controllable Generation with Text-to-ImageDiffusion Models: A Survey
code: 2403
GitHub - PRIV-Creation/Awesome-Controllable-T2I-Diffusion-Models: A collection of resources on controllable generation with text-to-image diffusion models.
Abstract
在快速发展的视觉生成领域,扩散模型带来了革命性的变化,其文本引导生成功能令人印象深刻,标志着功能的重大转变。然而,仅仅依靠文本来调节这些模型并不能完全满足不同应用和场景的各种复杂要求。认识到这一不足,各种研究都旨在控制预训练的文本到图像(T2I)模型,以支持新的条件。在本调查报告中,我们对有关 T2I 扩散模型可控生成的文献进行了全面回顾,涵盖了该领域的理论基础和实践进展。我们的综述首先简要介绍了去噪扩散概率模型(DDPM)和广泛使用的 T2I 扩散模型的基础知识。然后,我们揭示了扩散模型的控制机制,从理论上分析了如何在去噪过程中引入新条件以生成条件。此外,我们还对这一领域的研究进行了详细概述,并从条件的角度将其分为不同的类别:特定条件生成、多重条件生成和通用可控生成。
INTRODUCTION
DIFFUSION模型代表了视觉生成的范式转变,其性能显著优于传统框架,如生成对抗网络(gan)[1] -[8]。作为参数化的马尔可夫链,扩散模型表现出将随机噪声转换为复杂图像的非凡能力,从噪声依次发展为高保真的视觉表示。随着技术的进步,扩散模型在图像生成和相关的下游任务中显示出巨大的潜力。
随着这些模型生成的图像质量的提高,一个关键的挑战变得越来越明显:实现对这些生成模型的精确控制,以满足复杂和多样化的人类需求。这项任务不仅仅是增强图像分辨率或真实感;它包括精心地将生成的输出与用户的具体和细微的需求以及他们的创造性愿望结合起来。在广泛的多模态文本-图像数据集[9]-[17]的出现和引导机制[18]-[21]的发展的推动下,文本到图像(tt2i)扩散模型已经成为可控视觉生成景观[21]-[26]的基石。这些模型能够生成真实的、高质量的图像,准确地反映自然语言提供的描述。
虽然基于文本的条件在推动可控生成领域向前发展方面发挥了重要作用,但它们本身缺乏完全满足所有用户需求的能力。这种限制在某些情况下尤其明显,比如对一个看不见的人的描述或独特的艺术风格,仅通过文本提示是无法有效传达的。这些场景在T2I生成过程中构成了重大挑战,因为这种视觉表示的细微差别和复杂性很难用文本形式封装。认识到这一差距,大量研究已将重点转向将超出文本描述范围的新条件整合到T2I扩散模型中。强大且开源的T2I扩散模型的出现进一步促进了这一支点,如图1a所示。这些进步导致了对不同条件的探索,从而丰富了条件生成的可能性范围,并解决了各种应用中用户更复杂和细致的需求。
在AIGC领域有大量的研究文章,包括扩散模型理论和架构[28]、高效扩散模型[29]、多模态图像合成和编辑[30]、视觉扩散模型[31]-[34]和文本到3d应用[35]。然而,他们往往只提供一个粗略的控制文本到图像扩散模型或主要集中在替代模式。缺乏对T2I模型中新条件的整合和影响的深入分析突出了未来研究和探索的一个关键领域。
本研究对文本到图像扩散模型的可控生成进行了详尽的回顾,包括理论基础和实际应用。首先,我们简要概述了T2I扩散模型的背景,并深入研究了这些方法的理论基础,阐明了如何将新条件整合到T2I扩散模型中。这一探索揭示了先前研究的基础,并促进了对该领域的更深层次的理解。随后,我们对以往的研究进行了全面的概述,突出了它们的独特贡献和显著特征。此外,我们还探讨了这些方法的各种应用,展示了它们在不同背景和相关任务中的实际效用和影响。
贡献:
• 我们从条件的角度引入了结构良好的可控生成方法分类,揭示了该研究领域固有的挑战和复杂性。
• 我们对将新条件纳入T2I扩散模型所必需的两个核心理论机制进行了深入分析:条件分数预测和条件指导分数估计,提供了对这些机制如何在颗粒水平上发挥作用的细致理解。
• 我们的审查是全面的,根据我们提出的分类涵盖了广泛的条件生成研究。我们一丝不苟地强调了每种方法的显著特征和鲜明特征。
• 我们展示了在各种生成任务中使用T2I扩散模型的条件生成的各种应用,展示了它在AIGC时代作为一个基本和有影响力的方面的出现。
本文的其余部分组织如下。第2节简要介绍了去噪扩散概率模型(ddpm),展示了广泛使用的文本到图像扩散模型,并给出了一个结构良好的分类。在第3节中,我们分析了控制机制,并揭示了如何在文本到图像的扩散模型中引入新的条件。在第4节中,根据我们提出的分类,我们总结了控制文本到图像扩散模型的现有方法。最后,第7节演示了可控文本到图像生成的应用。
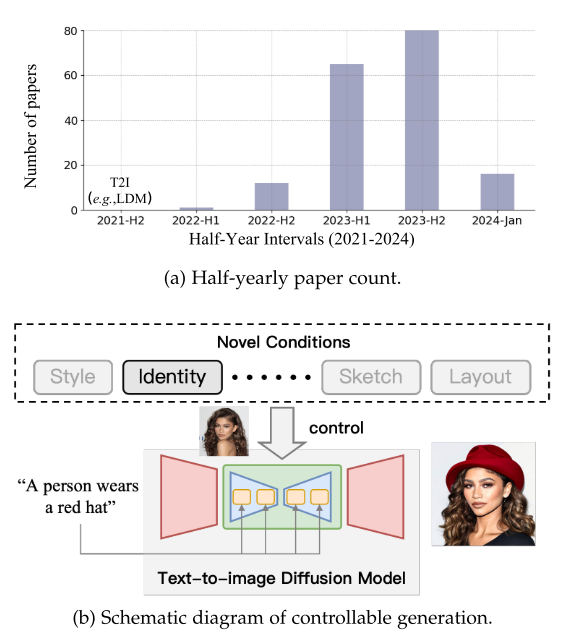
图1: T2I扩散模型的条件生成概述。(a)我们绘制了基于T2I扩散模型的可控发电的论文数量,这意味着在大功率发电机释放后,可控发电的论文数量正在迅速增加。(b)我们提出了一个使用T2I扩散模型的可控生成示意图,其中引入了文本之外的新条件来引导结果。示例图像来自[27]。
PRELIMINARIES
Denoising Diffusion Probabilistic Models
去噪扩散概率模型(ddpm)代表了一类新的基于反向扩散原理的生成模型。这些模型被表述为参数化的马尔可夫链,通过一系列步骤将噪声逐渐转换为结构化数据来合成图像。
Forward Process. 这些模型被表述为参数化的马尔可夫链,通过一系列步骤将噪声逐渐转换为结构化数据来合成图像。扩散过程从数据分布x0 ~ q(x0)开始,并在T个时间步长上逐渐添加高斯噪声。在每一步t中,数据xt被一个转换核去噪:
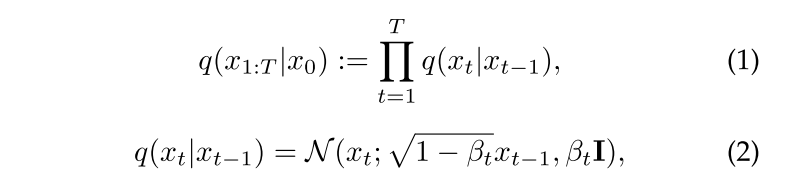
其中βt是噪声的方差超参数。
Reverse Process. 在DDPM的反向过程中,模型的目标是逐步去噪数据,从而近似于马尔可夫链的反向。这个过程从噪声向量xT开始,向原始数据分布q(x0)过渡。生成模型将反转pθ(xt−1|xt)参数化为正态分布:
![]()
其中深度神经网络,通常由UNet等架构实例化,参数化平均值µθ(xt, t)和方差Σθ(xt, t)。UNet将带噪数据xt和时间步长t作为正态分布的输入和输出参数,从而预测模型逆转扩散过程所需的噪声ϵθ。为了合成新的数据实例x0,我们首先对噪声向量xT ~ p(xT)进行采样,然后依次从学习到的过渡核xT−1 ~ pθ(xT−1| xT)中采样,直到t = 1,完成反向扩散过程。
Text-to-Image Diffusion Models
在本节中,我们重点介绍几个关键的和广泛使用的文本到图像的基础模型。关于这些模型的详细信息系统地汇编并呈现在表1中。

• GLIDE 为了生成与自由格式文本提示对齐的图像,GLIDE直观地将类条件扩散模型(即ADM[18])中的类标签替换为文本,从而形式化了第一个文本到图像扩散模型。作者探讨了文本条件反射的两种不同指导。
对于分类器制导,GLIDE在噪声图像空间中训练CLIP模型来提供CLIP制导。继[20]之后,GLIDE还研究了无分类器引导(CFG)进行比较,该方法在图像真实感和人类评估者的文本对齐方面都产生了更可取的结果,并被选为文本到图像生成的基本机制。对于文本条件,GLIDE首先通过可训练的transforms 36]将输入文本c转换为一个记号序列。随后,他们用集合文本特征代替类嵌入,并进一步将投影序列文本特征连接到扩散模型中每个注意层的注意上下文。GLIDE在与DALL·E[22]相同的数据集上训练扩散模型和文本转换器。扩散模型被训练来预测p(xt−1|xt, c)并生成具有CFG的图像。
• Imagen 继GLIDE之后,Imagen采用无分类器引导(CFG)进行文本到图像的生成。Imagen不是在GLIDE中从头开始训练任务指定的文本编码器,而是利用预训练和冻结的大型语言模型(大型语言模型)作为其文本编码器,旨在减少计算需求。作者对各种大型语言模型进行了比较分析,包括在图像文本数据集(例如CLIP[39])和仅在文本语料库(例如BERT [40], T5[37])上训练的大型语言模型。他们的研究结果表明,与扩大图像扩散模型相比,增加语言模型的规模更有效地提高了样本的保真度和图像与文本之间的一致性。此外,Imagen对不同文本条件反射方法的探索揭示了交叉注意是最有效的方法。
• DALL·E 2 为了利用来自CLIP[39]等对比模型的图像的鲁棒的语义和风格表示,DALL·e2(也称为unCLIP)训练生成扩散解码器来反转CLIP图像编码器。生成过程包括以下步骤。首先,给定图像标题y及其文本嵌入zt,先验p(zi|zt)弥合CLIP文本和图像潜在空间之间的差距,其中zi是图像嵌入。其次,解码器p(x|zi)从图像嵌入生成图像x。具体来说,解码器是一个从GLIDE架构改进的扩散模型,其中CLIP嵌入被投影并添加到现有的时间步嵌入中。先验可以使用自回归方法或扩散模型进行优化,后者表现出更好的性能。
• Latent Diffusion Model (LDM) 为了在有限的计算资源上进行扩散模型训练和推理,并生成高质量和灵活性的高分辨率图像,LDM在预训练的自编码器的潜在空间中应用去噪过程。具体来说,自编码器E将图像x∈Dx映射到一个空间潜空间z = E(x)。为了开发条件图像生成器,LDM使用交叉注意机制增强底层UNet,以有效地模拟条件分布p(zt−1|zt, c),其中c是条件输入,例如文本提示和分割掩码。
在文本到图像生成领域,作者使用了LAION-400M数据集来训练14.5亿个参数的文本到图像LDM模型,该模型能够生成分辨率为256 × 256的图像(潜在分辨率为32×32)。对于文本输入的编码,使用BERT标记器[40]作为文本编码器。
• Stable Diffusion (SD). 在潜在扩散模型(LDM)框架的基础上,Stability AI开发并推出了几个系列的文本到图像扩散模型,称为稳定扩散。SD在文本到图像生成方面展示了无与伦比的能力,并且由于其模型是开源的,因此在社区中得到了广泛的使用。
Taxonomy
利用文本到扩散模型的条件生成任务代表了一个多面和复杂的领域。从条件的角度来看,我们将该任务分为三个子任务(见图2)。大多数作品研究如何在特定条件下生成图像,例如图像引导生成,草图到图像生成。为了揭示这些方法的力学原理和特点,我们进一步根据它们的条件类型对它们进行了分类。这项任务的主要挑战在于如何使预训练的文本到图像(t2i)扩散模型能够学习对新类型的条件进行建模,并在确保生成的图像质量高的同时与文本条件结合生成。此外,一些方法研究如何使用多种条件生成图像,例如给定角色的身份和姿势。这些任务的主要挑战是多个条件的集成,需要在生成的结果中同时表达多个条件的能力。此外,一些作品试图发展一种条件不可知论的生成方法,可以利用这些条件产生结果。
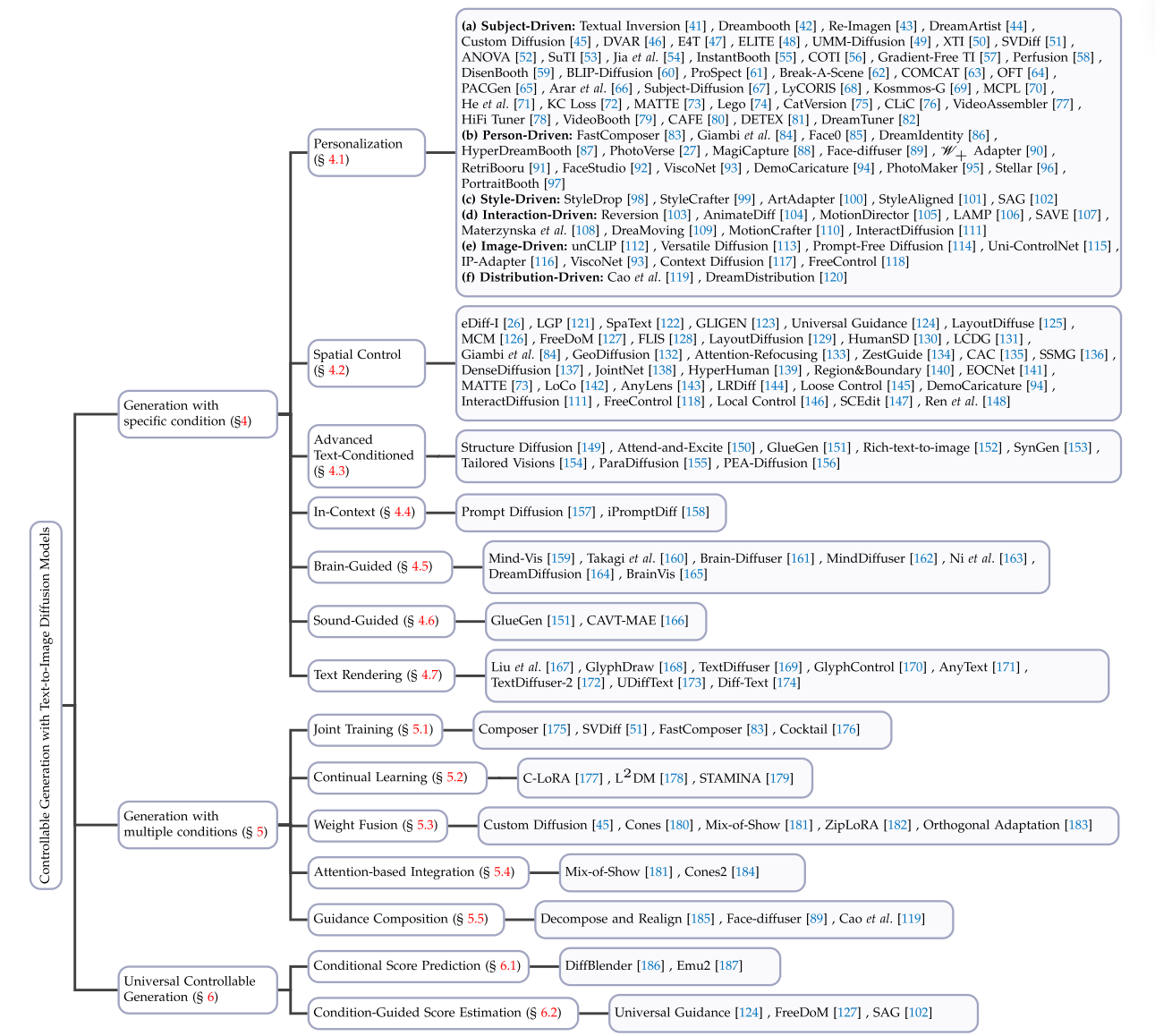
图2: 可控生成分类。从条件的角度,我们将可控生成方法分为三个子任务:特定条件生成、多条件生成和通用可控生成。
HOW TO CONTROL TEXT-TO-IMAGE DIFFUSION MODELS WITH NOVEL CONDITIONS

Conditional Score Prediction
T2I扩散模型利用ϵθ(xt, ctext, t)来预测∇xt log pt(x|ctext),而控制扩散模型的一种基本而强大的方法是在采样过程中通过条件分数预测,其中这些方法将cnovel引入ϵθ(xt, ctext, t),构造一个≈ε (xt, ctext, cnovel,T)直接预测∇xt log pt(x|ctext, cnovel)。然后,条件分数预测方法的CFG去噪过程如下:
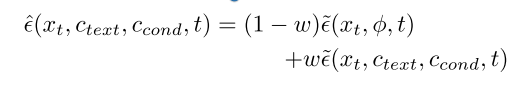
我们在这里说明了几种主流的方法来获得λ (xt,文本,cnovel, t)。
Model-based Conditional Score Prediction. 一些方法使用额外的编码器E对新条件进行编码,并将编码后的特征输入ϵθ,其中条件分数预测过程如下:
![]()
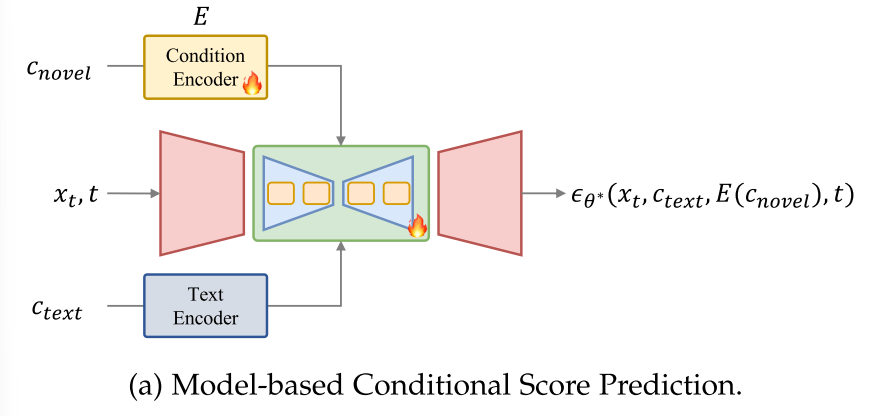

Tuning-based Conditional Score Prediction. 基于调优的方法通常侧重于适应特定的条件,通常是在数据有限的情况下,例如单次或少量样本学习示例。这些方法通过将文本条件text或模型参数θ转换为特定于给定条件的形式来实现条件预测,如图3b所示。这可以表示为:
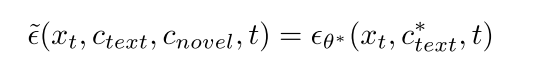
其中条件信息被记在text和θ中。
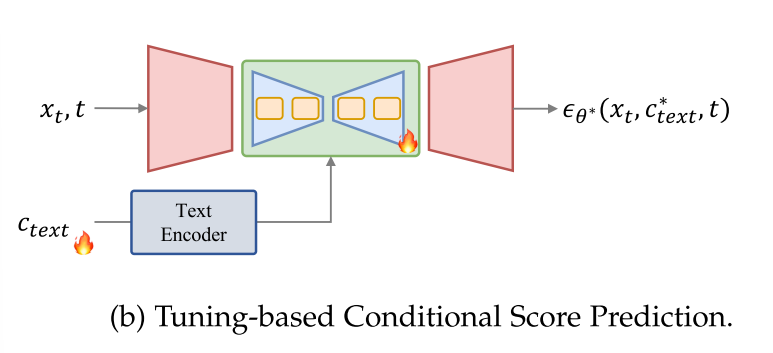

Training-free Conditional Score Prediction.
虽然上述技术需要一个训练过程,但有些方法是以不需要培训的方式设计的(参见图3c)。他们通过UNet结构的内在能力引入直接控制生成的条件,如调节交叉注意图来控制布局[135 “Localized text-to-image generation for free via cross attention control],[142 Loco: Locally constrained training-free layout-to-image synthesis],或者引入参考图像在自注意力机制中的特征来控制样式[101 Style aligned image generation via shared attention]。

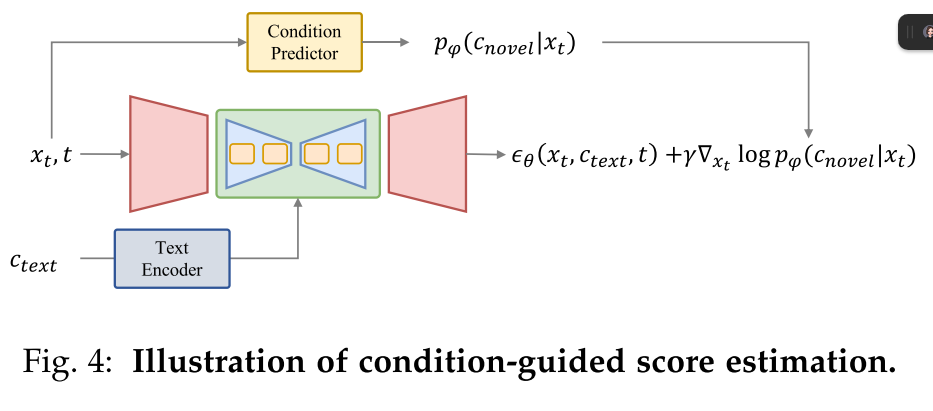
Condition-Guided Score Estimation
与预测∇xt log pt(x|ctext, cnovel)的条件分数预测方法不同,条件引导估计方法的目的是在不需要CFG的情况下获得∇xt log pt(cnovel|xt),它通常训练一个带有参数φ的附加模型,从潜在或内部特征中预测条件,记为pφ(cnovel|xt)。它可以通过反向传播获得∇xt log pt(cnovel|x),如图4所示。去噪过程现在为:
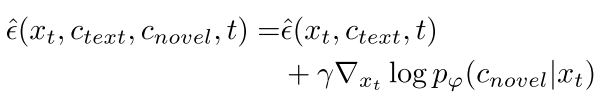
其中γ为调整条件分数的超参数,λ (xt, ctext, t)为具有CFG的文本条件扩散模型的原始分数预测。
CONTROLLABLE TEXT-TO-IMAGE GENERATION WITH SPECIFIC CONDITIONS
在文本到图像扩散模型的基础上,引入新的条件来引导生成过程是一项复杂而多方面的任务。在接下来的章节中,我们根据条件视角回顾了现有的条件生成方法,并对其方法进行了全面的批判。
Personalization
个性化任务旨在从范例图像中捕获和利用不易通过文本描述的概念作为生成条件进行可控生成。在本节中,我们将概述这些个性化条件,并对它们进行分类,以便更清楚地了解它们的各种应用程序和功能。我们在图5中展示了个性化的结果。

Subject-Driven Generation
在本节中,我们提供主题驱动生成方法的详细概述。主题驱动的生成任务(也称为以主题为中心的个性化)旨在生成保留所提供示例的主题的视觉内容。在实践中,许多主题驱动的生成方法并不局限于文本到图像扩散模型对主题类型的特定条件可控生成;它们通常表现出更通用的能力。因此,本章中讨论的许多方法可以扩展到更广泛的自定义任务。在总结这些作品时,我们采用更广阔的视角,尽可能地展示它们的普遍适用性,旨在更好地理解它们的贡献和作用。
根据第3节中提到的控制机制,由于所有这些方法都使用条件评分预测来引入条件,因此我们根据它们的管道对它们进行分类:基于调谐的方法,其调整模型参数或嵌入以适应特定条件;基于模型的方法,采用编码器提取个性化条件并将其输入扩散模型;无培训方法,利用外部参考来引导生成过程,而不需要训练。
Tuning-based Personalized Score Prediction. 从提供的样本中掌握概念的一种简单而有效的方法是选择性地调整参数子集,以在文本到图像模型中重建这些概念,其中更新的参数针对所需的概念[41],[42],[44],[50],[61],[72],[77]。
作为文本到图像扩散模型的基本输入,文本在使这些模型适应特定用户需求方面起着至关重要的作用。Textual Inversion(TI)[41]采用了一种创新的方法,将用户提供的概念嵌入到文本嵌入空间中的新“词”中。此方法扩展标记器的字典,并使用对所提供的图像进行去噪处理来优化其他标记。DreamBooth[42]遵循类似的路径,但使用低频词(即sks)来表示概念,并使用特定类别的先验保存损失来更新UNet的参数,以增强生成输出的多样性。TI和DreamBooth的直接且适应性强的框架将它们建立为许多后续基于调优的方法的基础模型。此外,Custom Diffusion[45]分析了微调过程中的权重偏差,并发现了跨注意层参数的关键作用,特别是关键和值投影(即Wk和Wv)。这种见解导致对这些投影进行集中更新,并结合额外的文本标记和正则化损失进行微调。
已经采取了一些方法来扩展文本嵌入空间,特别是通过考虑每个UNet层的区别[50 p+: Extended
textual conditioning in text-to-image generation],[61 Prospect: Prompt spectrum for attribute-aware personalization of diffusion models]。它们在不同的层中应用不同的文本嵌入。相比之下,CatVersion[75]偏离了对文本嵌入和UNet参数的关注,主张在文本编码器的特征密集空间内调整连接嵌入。这种方法被认为在学习个性化概念与其基类之间的细微差别方面更有效,有助于保留模型内的先验知识。
此外,参数有效调谐(PEFT)[191] -[194]在个性化方法中起着关键作用[63]。低阶自适应(Low-rank Adaptation, LoRA)[192]已被广泛应用于各种个性化技术[42],[59],[104],[177],[181]。此外,Xiang等人提出了方差分析[52],它选择了适配器[191],并揭示了在交叉注意块之后放置适配器可以显著提高性能。为了促进PEFT在扩散模型微调中的综合应用和评估,LyCORIS[68]开发了一个开源库1。该库包含了广泛的PEFT方法,包括但不限于LoRA[192]、LoHa和DyLoRA[193]。LyCORIS进一步引入了一个详细的框架,用于系统分析和评估这些PEFT技术,显著推进了扩散模型个性化领域。
此外,个性化领域的一个关键挑战是将特定概念从提供的样本中解脱出来。许多研究[59],[62],[65],[74],[81]已经发现了一个常见的问题,即在定制过程中,无关信息与预期概念交织在一起,例如在主题驱动生成中无意中学习图像周围的上下文。为了有效地从样本中分离和提取基本概念信息,一些作品[62 Break-a-scene: Extracting multiple concepts from a single image]、[70 An image is worth multiple words: Learning object level concepts using multi-concept prompt learning]、[76]研究了显式掩模的使用。类似地,Disenbooth[59]和DETEX[81]侧重于减轻个性化过程中背景元素的影响。DETEX更进一步,旨在将主体的姿态信息与整体概念解耦。同时,PACGen[65]采用了激进的数据增强技术,改变了样本中个性化概念的大小和位置,从而有助于将空间信息与核心概念本身分离开来。
此外,在小规模数据集上训练扩散模型往往会遇到另一个重大挑战:它可能会损害生成模型的更广泛适用性,从而需要在保真度和可编辑性之间取得微妙的平衡[82]。为了解决这一问题,一些研究引入了保存机制,重点关注防止输入样本[42]、[45]、[51]、[58]过拟合的策略,[64]、[78]。例如,灌注[58]通过将概念的交叉注意键锁定到其先前的类别并采用门控秩-1方法进行概念学习来解决这个问题。SVDiff[51]采用不同的方法,调整模型权重矩阵中的奇异值。该技术旨在最大限度地降低过拟合风险,并减轻语言漂移等问题。此外,OFT[64]强调了权矩阵中超球面能量对于维持模型的语义生成能力的重要性。因此,它引入了正交微调方法,进一步有助于在有限的训练数据下保持模型的泛化能力。
除了上述方法外,一些研究人员还探索了旨在优化生成性能、加快调优过程和最小化GPU内存使用的替代训练技术[46],[56],[57],[71],[73],[75]。具体来说,DVAR[46]识别了用于评估概念学习收敛性的标准训练指标的局限性,并利用简单的基于方差的早期停止准则,提高了微调过程的效率。无梯度文本反演[57]采用了一种创新的方法,将优化过程分为搜索空间中的降维和子空间中的非凸、无梯度优化两部分。该方法在对性能影响最小的情况下实现了显著的优化加速。MATTE[73]深入研究了时间步长和UNet层在个性化各种概念类别(如颜色、对象、布局和样式)中的作用,旨在提高不同概念类型的性能。针对文本反演中对高质量数据的需求,COTI[56]引入了一个主动可控的数据选择框架,通过扩大数据范围来改进文本反演。同样,He等人[71]采用了以数据为中心的方法,提出了一种在文本和图像级别生成正则化数据集的新策略,进一步丰富了该领域的研究领域。
Model-based Personalized Score Prediction. 基于模型的方法使用编码器来嵌入概念,在从图像中提取概念时,与基于调优的方法相比,提供了显著的速度优势。一些工作专注于领域感知编码器,专门设计用于嵌入来自目标域[47],[55]的图像。例如,InstantBooth[55]使用了一个专门的编码器和适配器,在人脸和猫域上进行了训练,以提取文本嵌入和详细的补丁特征,用于概念学习。相比之下,其他基于模型的方法选择了域不可知的方法,在开放世界图像上训练编码器以提取更广义的条件[48],[49],[53],[66],[67],[69],[77],[79]。这些方法通常使用大型预训练模型,如CLIP[39]和BLIP-2[195]作为图像编码器,专注于微调有限数量的参数,如投影层[48],[49],[66],[82]。例如,ELITE[48]基于CLIP[39]集成了一个全局映射网络和一个本地映射网络。全局网络将分层图像特征转化为多个文本嵌入,局部网络将补丁特征注入到交叉关注层中进行详细重建。BLIP-Diffusion[60]通过预训练BLIP-2[195]编码器进行文本对齐图像表示,并开发学习主题表示的任务,从而推进定制,从而能够生成新的主题再现。在E4T b[47]之后,Arar等人[66]引入了一种用于获取文本嵌入的编码器,并提出了一个超网络来预测UNet中lora风格的注意力权重偏移。SuTI[53]采用了一种独特的方法,灵感来自学徒学习[196],在数百万个互联网图像集群上训练大量的专家模型。然后,学徒模型被教导模仿这些专家的行为。CAFE[80]构建了一个基于预训练大语言模型和扩散模型的定制助手。
Training-free Personalized Score Prediction. 在合成过程中从参考图像中提取概念信息是实现无训练个性化的关键技术。与自然语言处理中的检索增强生成类似,利用样本中的知识可以帮助模型忠实地生成给定的概念。Re-Imagen[43]代表了一种新方法,可以生成不常见或罕见类别的图像,例如Chortai(狗)和Picarones(食物)。该方法利用外部多模态知识库,利用从该数据库检索到的相关图像-文本对作为图像生成的参考。除此之外,还有几种方法,无论是基于调优的还是基于模型的,都使用参考图像来提高生成图像中视觉细节的准确性和保真度[77],[78],[91]。
Person-Driven Generation
个人驱动的生成任务(也称为以人为中心的个性化)特别关注于创建以人为中心的视觉输出,这些输出与范例样本中描述的个人保持相同的身份。虽然人驱动生成是更广泛的主题驱动生成类别的一个专门子集,并且与此任务相关的几种方法已经在前一节中讨论过,但在这一部分中,我们将重点强调和分析那些明确为人驱动生成量身定制的技术。
与基于模型的主题驱动生成类似,许多人驱动的方法将面部图像编码到文本嵌入空间中,以提供身份条件[27],[83],[85]-[87]。例如,为了在身份保存和可编辑性之间取得平衡,Xiao等人[83]引入了一种新颖的方法,将文本提示与来自个人参考图像的视觉特征相结合,称为FastComposer。具体来说,该方法通过多层感知器将与人相关的文本嵌入(如“男人”和“女人”)与视觉特征融合,有效地封装了人的身份的文本和视觉条件。除CLIP[39]外,Face0[85]和DreamIdentity[86]还使用预训练的人脸识别模型[197]作为其面部图像编码器,其中Face0使用Inception ResNet V1 [198], DreamIdentity引入vita风格[199]的多字多尺度(M²ID)编码器。虽然大多数方法使用多模态预训练图像编码器(例如CLIP[39])或面部识别模型[197],但W+ Adapter[90]引入了一种使用StyleGAN反转编码器的创新方法。
受检索增强生成(retrieval-augmented generation, RAG)的启发,Tang等人[91]引入了一种新的基于检索的方法,专门为以人为中心的个性化定制。为了补充这种方法,他们还提供了一个名为RetriBooru-V1的动漫人物数据集,该数据集的独特特点是增强了身份和服装标签。该方法的核心是使用冻结变分自编码器(VAE)[200]对参考图像进行编码,并通过交叉注意层和零卷积层无缝集成到生成过程中。这些层在准确定位参考属性(如身份和服装特征)在生成图像中的正确几何位置方面起着至关重要的作用,从而确保输出的高度保真度和相关性。
与主题驱动的方法相比,人驱动的生成方法可以从人脸分割中获益良多,人脸分割可以通过解析模型或注释[27]获得,[83],[95]-[97]。例如,一些作品,如Stellar[96],在数据处理过程中使用面具来消除背景元素,从而在输入数据中突出对人类身份的关注。相反,其他方法利用面罩来构建[27],[83],[95],[97]或调整[88]损失函数。
Style-Driven Generation
风格条件生成任务旨在从给定样本中提取风格信息,作为可控生成的条件。
与基于调优的主题驱动方法类似,StyleDrop[98]在Muse[198]上使用适配器的微调[191]、[201]来将模型定制为特定的风格条件,并进一步提出了一种快速工程技术来构建训练数据,有效地将主题线索与风格分离开来。同时,有几种方法正在探索编码器的结合,这些编码器旨在为条件生成生成与样式相关的嵌入[99],[100]。为了解决从样式引用中借用内容的问题,ArtAdapter[100]引入了一种创新的辅助内容适配器(ACA),它旨在为UNet提供必要的内容线索,从而确保模型保持对样式元素的关注。
此外,有几种方法试图为风格一致的图像生成建立无需训练的框架[101],[102 Towards accurate
guided diffusion sampling through symplectic adjoint method]。例如,StyleAligned[101]旨在生成一系列遵循给定参考样式的图像。该方法在自注意力机制层中引入了一种新颖的注意力共享机制,促进了单个图像特征与附加参考图像特征之间的交互。这样的设计使生成过程能够同时考虑和融合多个图像的风格元素。此外,StyleAligned通过使用自适应实例规范化(AdaIN)[202]规范化查询和键来增强样式属性的对齐,进一步优化生成图像的样式一致性。
Interaction-Driven Generation
交互条件生成任务专门用于学习和生成与交互相关的概念,如人类行为和人-对象交互(HOI)。从本质上讲,这个任务围绕着使用“动词”作为条件反射元素的新想法。
对于动作驱动的图像生成,Huang等人[189]提出了一种动作解纠缠标识符(action- disentangled Identifier, ADI)来解耦主体身份和动作,以改进动作条件学习。为了阻止动作不可知特征的反转,ADI从构造的样本三元组中提取梯度不变性,并掩盖不相关通道的更新,从而有效地确保了动作条件嵌入到文本嵌入中。
此外,revversion[103]已被开发用于理解样本图像中描述的关系,例如在“对象A <被画在>对象B上”的场景中,<被画在>上作为个性化条件。该方法引入了一种新的关系导向对比学习机制,独特地利用介词作为正样本来准确引导关系提示,而其他词作为负样本。此外,Reversion采用了关系焦点重要性采样技术,该技术在训练过程中优先选择具有较高噪声水平的样本,这有助于模型学习高级语义关系。
Tian等人[111]引入了InteractDiffusion模型来封装人机交互(HOI)信息,以实现可控生成。他们方法的核心是构建包含人、动作和对象的三重标签,以及相应的边界框,这些标签通过InteractDiffusion中的交互嵌入进行标记,以学习和表示这些主题之间的复杂关系。
Image-Driven Generation
图像条件生成任务旨在通过使用范例图像作为提示,从多个角度(例如,内容和风格)生成类似的图像。
unCLIP[38]是探索使用图像提示进行图像生成的早期工作,提出了一个两阶段模型:一个先验模型,在给定文本标题的情况下生成CLIP图像嵌入,一个解码器,在图像嵌入的条件下生成图像。Xu等人[113]将现有的单流扩散管道扩展为多任务多模态网络,称为通用扩散(VD),该网络在一个统一的模型中处理文本到图像、图像到文本和变体的多个流。Xing等人[114]在文本到图像模型中引入了免提示扩散(Prompt-Free Diffusion)来丢弃带有图像的文本,仅使用视觉输入来生成新图像。他们提出了一个语义上下文编码器(SeeCoder),由主干encoder, a decoder, and a query transformer[195]组成,用于对范例图像进行编码。在推理过程中,SeeCoder将取代Stable Diffusion中的CLIP文本编码器,将参考图像作为输入。IP-Adapter[116]解耦了交叉注意机制,该机制分离了文本特征和图像特征的交叉注意层,为预训练的文本到图像扩散模型实现了图像提示能力。这些方法直接使用图像作为提示,而ViscoNet[93]使用分段人物图像为以人为中心的生成提供时尚参考。
Distribution-Driven Generation
分布条件生成任务旨在理解和学习多个样本图像的数据分布,目的是生成反映这种分布的各种结果。这种方法不同于以主题为中心的个性化,因为它侧重于调整文本到图像的模型,以生成更广泛、更抽象的概念或类别,而不是单个主题。
Cao等人[119]引入了指导-解耦个性化框架,该框架旨在生成具有高度保真度和可编辑性的特定概念(例如,面孔)。该框架独特地将条件指导解耦为两个不同的组件:概念指导和控制指导。概念指导组件经过专门训练,以遵循底层数据分布的方式引导采样过程,从而确保准确生成参考概念。此外,DreamDistribution[120]被提出用于学习提示分布,保留一组可学习的文本嵌入,以在CLIP文本编码器特征空间中建模它们的分布。然后利用一种重参数化技巧从该分布中采样并更新可学习的嵌入。
Spatial Control
由于文本难以表示结构信息(即位置和密集标签),因此利用空间信号控制文本到图像的扩散方法,如layout[10][203]、人体姿势[204]-[207]、人体解析[208]-[212]、分割掩码[213],[214]等,是扩散模型中一个重要的研究领域。在这种情况下,我们开始与一些统一的空间控制方法的简要概述,其次是更详细的探索到各种具体类别的结构,如边界框和关键点。
Spatial-Conditional Score Prediction
在空间条件分数预测领域,开发了建模方法来模拟@ ϵθ(xt, ctext, cspatial, t),目的是生成与给定空间条件cspatial一致的结果。我们在这里概述了基于模型和无训练的空间条件分数预测方法,因为基于调优的方法[73]更抽象地概念化结构条件(例如布局),而没有明确地利用空间条件。
• Model-based Score Prediction. ControlNet[190]在广义空间控制方法中脱颖而出,被认为是一项开创性的工作,并于2023年获得了著名的Marr奖。与简单调整原始扩散模型[45]参数的方法有很大不同[87],ControlNet通过在UNet结构中加入额外的编码器副本引入了一种创新架构。这个增加的编码器通过提出的“零卷积”与原始UNet层连接,以防止过拟合和灾难性遗忘。ControlNet架构的简单性和适应性不仅被证明是有效的,而且在随后的许多研究中被广泛采用[82],[136],[176],[186],[215]-[218]。类似地,t2i - adapter[219]被提出用于在文本到图像扩散模型和外部控制信号中对齐内部知识。SCEdit[147]提出了一个高效的生成式调优框架,该框架使用名为SC-Tuner的轻量级调优模块集成和编辑跳过连接。
虽然ControlNet[190]需要对每种类型的控制信号进行不同的训练模型,但一些研究人员已经追求能够处理各种空间信号的更广义方法的发展[115],[176],[215],[216]。为了应对这一挑战,秦等人[215]引入了一个任务感知的超网络,旨在调节扩散模型以适应不同类型的条件,称为uniccontrol。在这种方法中,使用混合专家(MOE)适配器对条件进行编码。同时,任务指令通过任务感知超网络转换为任务嵌入,并将其集成到零卷积中,以精确调制条件特征注入模型。
在布局条件分数预测领域,已经引入了各种创新方法[111]、[122]、[123]、[126]、[128]、[129]、[132]、[136]、[141]、[143]、[144]。GLIGEN[123]采用基础语言作为生成的基础,通过门控机制将这些基础信息嵌入到新的可训练层中,从而实现更可控的生成。此外,SpaText[122]通过引入CLIP图像嵌入来构建空间文本表示,他们将这些对象嵌入堆叠在相同形状和位置的片段中以控制布局。此外,也有一些研究聚焦于人脸域,在人脸解析条件下合成人脸图像[84]、[125]、[148]、[148]。
为了加强空间控制,已经开发了几种方法来联合降噪空间结构条件。JointNet[138]是预先训练的文本到图像扩散模型的扩展,为深度图等密集模态引入了一个新的分支,其中原始网络的副本与RGB分支错综复杂地连接在一起,促进了不同模态之间的复杂交互。此外,Liu等人[139 Hyperhuman: Hyper-realistic human generation with latent structural diffusion]提出了潜在结构扩散模型,该模型创新性地在RGB图像合成的同时对深度和表面法线进行去噪。
虽然上述方法希望生成与给定条件完全对齐的图像,但有些方法研究使用粗糙和不完整的空间条件[115],[145],[146]。具体来说,LooseControl[145]从图像中提取3D框控制的代理深度,并通过LoRA[192]微调ControlNet[190],通过仅指定场景边界和主要对象的位置来创建复杂的环境(例如,房间,街景)。
• Training-free Score Prediction. 由于注意机制明确地模拟了文本和图像标记之间的关系,因此调节注意图成为分数预测中控制结构的关键无训练技术[26 ediffi: Text-to-image diffusion models with an ensemble of expert denoisers],[118 “Freecontrol: Training-free spatial control of any text-to-image diffusion model with any condition],[135 “Localized text-to-image generation for free via cross attention control],[137 Dense text-to-image generation with attention modulation],[142 “Loco: Locally constrained training-free layout-to-image synthesis]。ediffi[26]提出了一种名为“paint-with-words”(也称为pww)的技术,通过对应的分割映射来校正每个单词的交叉注意映射,以控制对象的位置。此外,DenseDiffusion[137]通过设计多重正则化引入了一种更广泛的调制方法,提高了布局控制在分数预测中的精度和灵活性。
Spatial-Guided Score Estimation
虽然许多方法都坚持条件分数预测的范式,如ControlNet,但一些研究通过sptail引导的分数估计来探索空间控制[121],[124],[127],[131]。值得注意的是,LGP[121]是早期的先驱,它创新地引入了潜在边缘预测器,旨在从UNet架构中的一系列中间特征中推断草图信息。它利用条件草图和预测草图之间的相似度来计算梯度,然后利用梯度来指导分数估计过程。它的方法和见解一直是该领域众多后续研究努力的灵感来源[131],[133],[134],[220]。ZestGuide[134]利用从交叉注意层中提取的分割图,在去噪过程中通过基于梯度的引导将生成与输入蒙版对齐。
Advanced Text-Conditioned Generation
虽然文本是文本到图像扩散模型的基本条件,但该领域仍然存在一些挑战。首先,文本引导合成,特别是涉及多个主题或丰富描述的复杂文本,经常遇到文本不对齐的问题。此外,这些模型在英语数据集上的主要训练导致了多语言生成能力的明显缺乏。为了解决这一限制,已经提出了旨在扩大这些模型的语言范围的创新方法。
• Improving Textual Alignment. 文本对齐在文本到图像扩散模型中起着关键作用,提供了对生成过程的基本控制。尽管在多模态文本图像数据集上进行了训练,但这些生成模型往往难以准确地捕获和反映文本描述中包含的全部信息。为了应对这一挑战,人们开发了各种创新方法[149]、[150]、[152]。具体来说,Attendand-Excite[150]代表了这一领域的早期努力,引入了一种基于注意力的生成语义护理(GSN)机制。这种机制改进了交叉注意单元,以更有效地确保准确生成文本提示中描述的所有主题。Structure Diffusion[149]利用语言洞察力来操纵交叉注意图,旨在更准确地绑定属性并改进图像组成。Ge等人[152]提出了一种富文本到图像的框架,该框架首先通过扩散模型处理纯文本,以收集注意图、噪声生成和残差特征图。随后,将富文本格式化为JSON,为每个令牌范围提供详细属性,从而增强模型将可视化内容与复杂文本描述对齐的能力。此外,SynGen[153]在文本到图像的生成中采用了一种独特的方法,首先对文本提示符进行语法分析。该分析旨在识别提示符中的实体及其修饰符。在此之后,SynGen利用了一种新的损失函数,旨在将交叉注意映射与语法所指示的语言绑定对齐。此外,Tailored Visions[154]利用历史用户与系统的交互来重写用户提示,以增强用户提示与其预期的视觉输出的表达性和一致性。为了提高长段落(最多512个单词)的文本对齐,Wu等人[155]为段落到图像生成任务引入了一种信息丰富的扩散模型,称为ParaDiffusion,该模型采用大型语言模型(例如Llama V2[221])对长文本进行编码。然后使用LoRA进行微调[192],以在生成时对齐文本-图像特征空间。
• Multilingual-Guided Generation. GlueGen[151]将多语言语言模型(例如XLM-Roberta[222])与现有的文本到图像模型相结合,允许从英语以外的字幕生成高质量的图像。PEADiffusion[156]是一种基于知识蒸馏的简单即插即用语言迁移方法,该方法在教师知识蒸馏下训练一个轻量级的类似mlp的参数高效适配器,只有6M个参数,同时训练一个小型并行数据语料库。
In-Context Generation
上下文生成任务涉及基于一对任务特定的示例图像和文本指导,对新的查询图像理解和执行特定的任务。
Wang等人[157]引入了提示扩散,这是一种使用上下文提示在多个任务上联合训练的新方法。该方法在训练任务的高质量上下文生成方面显示出令人印象深刻的结果,并有效地推广到具有相关提示的新的、未见过的视觉任务。在此基础上,Chen等人[158]通过结合视觉编码器调制的文本编码器进一步增强了提示扩散。这一创新解决了几个挑战,包括昂贵的预训练,限制性问题表述,有限的视觉理解,以及对非分布任务的不充分泛化。此外,najdenkoska提出了一种分离视觉上下文编码和保留查询图像结构的新框架。这导致了从视觉环境和文本提示中学习的能力,也可以从它们中的任何一个中学习。
Brain-Guided Generation
大脑引导的生成任务侧重于直接控制大脑活动的图像生成,例如脑电图(EEG)记录和功能性磁共振成像(fMRI),而无需将思想转化为文本。该领域的早期研究已经使用生成对抗网络(GANs)和变分自编码器(VAEs)从大脑信号中重建视觉图像[223]-[226]。最近,随着视觉扩散模型的采用,该研究取得了进展,增强了将复杂的大脑活动准确转化为连贯的视觉表征的能力[159]-[165]。
Chen等[159]提出了一种基于双条件潜扩散模型(MinDVis)的稀疏掩膜脑模型,用于人类视觉解码。他们首先使用掩模模型学习fMRI数据的有效自监督表示,然后使用双重条件反射增强潜在扩散模型。MindDiffuser[162]也是一种两阶段图像重建模型。在第一阶段,将从fMRI中解码的VQ-VAE潜表示和CLIP文本嵌入放入稳定扩散的图像到图像处理中,得到包含语义和结构信息的初步图像。然后,利用fMRI解码的低阶CLIP视觉特征作为监督信息,在第一阶段通过反向传播不断调整这两个特征,使结构信息对齐。
虽然上述方法是重建功能性磁共振成像的视觉结果,但有些方法选择脑电图(EEG)[164],[165],这是一种无创且低成本的记录大脑电活动的方法。DreamDiffusion[164]利用预训练的文本到图像模型,并采用时间掩码信号建模来预训练EEG编码器,以实现有效和鲁棒的的EEG表示。此外,该方法进一步利用CLIP图像编码器提供额外的监督,以更好地对齐EEG,文本和图像嵌入与有限的EEG-图像对。
Sound-Guided Generation
GlueGen[151]将AudioCLIP等多模态编码器与稳定扩散模型对齐,从而实现声音到图像的生成。Yang等人[166]提出了一个统一的框架“Align, Adapt, and Inject”(AAI),用于声音引导图像的生成、编辑和风格化。特别是,该方法将输入声音转换为声音标记,就像普通单词一样,可以与现有的基于扩散的强大文本到图像模型一起使用。
Text Rendering
在合成图像中呈现文本的任务是至关重要的,特别是考虑到文本在各种视觉形式(如海报、书籍封面和模因)中的广泛应用。
unCLIP[38]中的分析强调了原始CLIP文本嵌入在准确建模提示中的拼写信息方面的不足,从该分析中获得灵感,随后的努力(如ediffi[26]和Imagen[24])试图利用大型语言模型(如T5[37])的功能,这些模型是在纯文本语料库上训练的。作为图像生成中的文本编码器。此外,DeepFloyd IF 2遵循Imagen[24]的设计原则,在渲染图像上的清晰文本方面表现出令人印象深刻的熟练程度,展示了在这一具有挑战性的领域的重大进步。
同时,设计了一些方法来提高现有文本到图像扩散模型的文本渲染能力[167]-[169],[171]-[174]。Liu等人[167]发现流行的文本到图像模型缺乏字符级输入特征,这使得预测单词作为一系列符号的视觉构成变得更加困难。GlyphControl[170]利用额外的字形条件信息来增强现成的稳定扩散模型在生成准确视觉文本方面的性能。TextDiffuser等[169]首先生成从文本提示中提取的关键词的布局,然后以文本提示和生成的布局为条件生成图像。作者还提供了一个带有OCR注释的大规模文本图像数据集MARIO-10M,其中包含1000万对带有文本识别、检测和字符级分割注释的图像-文本对。Zhang等人[174]提出了Diff-Text,这是一种无需训练的场景文本生成框架,适用于任何语言。Difftext利用渲染草图图像作为ControlNet渲染文本的先验条件[190],提出了一种局部注意力约束来解决场景文本位置不合理的问题。
CONTROLLABLE GENERATION WITH MULTIPLE CONDITIONS
多条件生成任务的目的是在多种条件下生成图像,例如以用户定义的姿势生成特定的人,或者以三种个性化身份生成人。在本节中,我们将从技术角度对这些方法进行全面概述,并将其分类为联合训练(第5.1节);权重融合(第5.3节)、基于注意力的融合(第5.4节)、引导融合(第5.5节)和持续学习(第5.2节)。需要注意的是,其他一些可控生成方法也显示出无需专门设计的多条件合成能力[41],[42],[215]。
Joint Training
设计多条件框架并对其进行联合训练是实现多条件生成的一种简单而有效的途径。这些方法通常集中在多条件编码器和训练策略上。
Composer[175]使用堆叠卷积层将所有条件(包括文本标题、深度图、草图等)投影到具有与噪声潜在相同空间大小的均匀维嵌入中。它利用联合训练策略从一组表示生成图像,其中每个条件的独立退出概率为0.5,放弃所有条件的概率为0.1,保留所有条件的概率为0.1。此外,Cocktail[176]提出了可控归一化方法(ControlNorm),该方法有一个额外的层来生成两组以所有模态为条件的可学习参数。这两组参数用于融合外部条件信号和原始信号。
从数据的角度来看,SVDiff[51]利用cut-mixunmix机制生成多主题。它通过类似于cutmix的数据增强来增强多概念数据,并重写对应的文本提示符。它还利用了跨注意力映射的非混合正则化,确保文本嵌入仅在对应区域有效。这种注意图约束机制也应用在FastComposer中[83]。
Continual Learning
在基于训练的条件分数预测工作中,为了解决知识的“灾难性遗忘”问题,通常提出了持续学习方法。具体而言,CLoRA[177]由跨注意层的连续自正则化LoRA组成。它利用过去的LoRA权重增量来调节新的LoRA权重增量,通过指导哪些参数是最可用的,以进行持续的概念学习。此外,L2DM[178]设计了一个任务感知的记忆增强模块和一个弹性概念蒸馏模块,它们分别可以保护对先前概念和过去每个个性化概念的知识。它利用彩虹记忆库策略来管理长期记忆和短期记忆,并提供正则化样本,以保障个性化过程中的知识。在训练中,作者进一步提出了概念注意艺术家模块和正交注意艺术家模块来更新噪声潜,以获得更好的性能。STAMINA[179]在持续学习中引入了遗忘正则化(forgettingregularization)和稀疏正则化(sparsity-regularization),避免了遗忘学习过的概念,并确保没有存储或推理成本。
Weight Fusion
在通过微调使T2I扩散模型适应新条件的领域中,权值融合是一种合并多个条件的直观方法。这些方法的重点是实现包含每个条件的内聚权重混合,同时确保保留单个条件的可控性。目标是将各种条件方面无缝集成到统一模型中,从而增强其在不同场景中的多功能性和适用性。这需要在保持每个条件影响的完整性和实现有效的整体综合之间取得微妙的平衡。作为合并多个条件的直观方法。这些方法的重点是实现包含每个条件的内聚权重混合,同时确保保留单个条件的可控性。目标是将各种条件方面无缝集成到统一模型中,从而增强其在不同场景中的多功能性和适用性。这需要在保持每个条件影响的完整性和实现有效的整体综合之间取得微妙的平衡。
由于个性化条件通常表示UNet的权值或文本嵌入,因此权值融合是生成多个个性化条件下图像的一种直观有效的方法。具体来说,锥体[180]在个性化后进一步微调概念神经元,以获得更好的生成质量和多主题生成能力。自定义扩散[45]引入了一种约束优化方法来合并微调后的键值矩阵,如下所示:
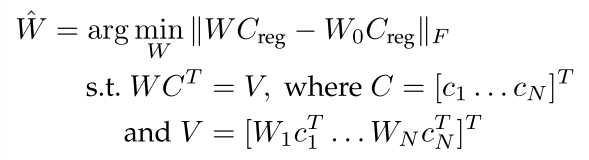
其中![]() 表示添加的n个概念对应的更新键和值矩阵,Creg是用于正则化的随机采样文本特征。公式13的目标直观地设计为确保目标标题中的单词始终与经过微调的概念矩阵派生的值保持一致。同样,Mix-of-Show[181]引入了梯度融合,通过
表示添加的n个概念对应的更新键和值矩阵,Creg是用于正则化的随机采样文本特征。公式13的目标直观地设计为确保目标标题中的单词始终与经过微调的概念矩阵派生的值保持一致。同样,Mix-of-Show[181]引入了梯度融合,通过![]() 更新权值W,其中Xi表示第i个概念的输入激活,|·|F表示Frobenius范数。为了整合以主题为中心和以风格为中心的条件,ZipLoRA[182]通过最小化混合和原始LoRA模型生成的主题/风格图像之间的差异以及内容和风格LoRA列之间的余弦相似度来合并LoRA风格权重。Po等[183]提出正交自适应替代LoRA进行微调,鼓励自定义模型具有正交残差权值以实现高效融合。
更新权值W,其中Xi表示第i个概念的输入激活,|·|F表示Frobenius范数。为了整合以主题为中心和以风格为中心的条件,ZipLoRA[182]通过最小化混合和原始LoRA模型生成的主题/风格图像之间的差异以及内容和风格LoRA列之间的余弦相似度来合并LoRA风格权重。Po等[183]提出正交自适应替代LoRA进行微调,鼓励自定义模型具有正交残差权值以实现高效融合。
Attention-based Integration
基于注意力的整合方法调整注意力地图,在合成图像中战略性地定位受试者,从而精确控制每种情况在最终构图中的表现方式和位置。例如,Cones2[184]使用Edited CA←Softmax(CA⊕{η(t)·Msi |i = 1,···,N}编辑交叉关注地图,其中⊕表示将交叉关注地图CA与预定义布局M的相应维度相加的操作,η(t)是控制不同时间步t编辑强度的凹函数。Mix-of-Show[181 Orthogonal adaptation for modular customization of diffusion models]采用区域可控采样方法,在交叉关注中整合全局提示和多个区域提示以及预定义掩码。
Guidance Composition
制导合成是一种综合多种条件下图像的综合机制,将每种条件下的独立去噪结果进行综合。这个过程在数学上表示为:
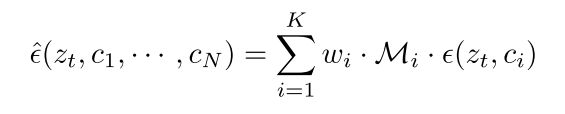
其中,λ (zt, ci)表示每个条件的导向,而wi和Mi是用于整合这些结果的各自权重和空间掩码。
为了整合多个概念,分解和重新排列[185]通过它们的交叉注意图得到相应的Mi。类似地,Face-diffuser[89]提出了一种显著性自适应噪声融合方法,将文本驱动扩散模型和拟议的主体增强扩散模型的结果结合起来。此外,Cao等[119]提出了以概念为中心的个性化的广义无分类器制导(generalized classifier-free guidance, GCFG),通过手动设置强度wi,将概念制导和控制制导相结合。
UNIVERSAL CONTROLLABLE TEXT-TO-IMAGE GENERATION
除了针对特定条件定制的方法之外,还存在用于适应图像生成中的任意条件的通用方法。这些方法根据其理论基础大致可分为两类:通用条件分数预测框架和通用条件指导分数估计。
Universal Conditional Score Prediction Framework
通用条件分数预测框架包括创建一个能够对任何给定条件进行编码的框架,并利用它们来预测图像合成过程中每个时间步的噪声。这种方法提供了一种通用的解决方案,可以灵活地适应不同的条件。通过将条件信息直接集成到生成模型中,该方法允许动态调整图像生成过程以响应各种条件,使其具有通用性并适用于各种图像合成场景。
DiffBlender[186]被提议纳入来自不同类型模态的条件。它将条件分类为多种类型,以采用不同的技术进行引导生成。首先,在ResNet块中注入包含空间丰富信息的图像形式条件[227]。然后,通过局部自注意力机制模块传递接地箱、关键点等空间条件,精确定位合成结果的期望位置。此外,调色板和风格等非空间条件通过全局自注意力机制模块与文本标记连接,然后馈送到交叉注意层。此外,Emu2[187]利用具有370亿个参数的大型生成式多模态模型进行任务不可知的上下文学习,以构建通用可控的T2I生成框架。经过高质量数据集的混合训练后,它能够接受文本、位置和图像等混合条件作为输入,并在上下文中生成图像。
Universal Condition-Guided Score Estimation
其他方法利用条件引导的分数估计,将各种条件纳入文本到图像的扩散模型。主要的挑战在于在去噪过程中如何从潜在信号中获得特定条件的引导。
Universal Guidance[124]观察到在去噪扩散隐式模型(DDIM)[228]中提出的重构干净图像适合作为通用制导函数提供信息反馈来指导图像生成。给定任意条件c和现成的预测器f,去噪过程遵循:

UG使用了各种预测器,包括CLIP[39](用于文本或样式条件)、分割网络[229](用于分割地图条件)、人脸识别模型[230]、[231](用于身份条件)和对象检测器[232](用于边界框条件)。在实验中展示了不同条件下条件生成的能力。
与Universal Guidance[124]类似,FreeDom[127]利用现成的预测器来构建与时间无关的能量函数来指导生成过程。它还开发了有效的时间旅行策略,将当前的中间结果zt返回j步到zt+j,并将其重新采样到第t个时间步。该机制解决了与大数据域(如ImageNet[233])条件不一致的问题。
虽然上述条件引导采样方法利用现成模型和一步估计过程来预测与条件相关的条件,但Pan等人[102]在两个内部阶段提出了simplecit伴随指导(SAG),其中,SAG首先通过n次函数调用来估计干净的图像,然后使用辛伴随法精确地获得梯度。
APPLICATIONS
在本节中,我们将重点介绍利用生成过程中的新条件来解决特定任务的创新方法。通过强调这些开创性的方法,我们旨在强调条件生成不仅重塑了内容创作的格局,而且拓宽了各个领域的创造力和功能的视野。随后的讨论将提供对这些模型的变革性影响及其在各种应用中的潜力的见解。
Image Manipulation
在控制预先训练的文本到图像扩散模型的进步允许更通用的图像编辑技术。例如,受DreamBooth b[42]的启发,SINE[234]构建了文本提示符,用于通过源图像微调预训练的文本到图像模型为“一张[∗][类]的照片/绘画”,并通过一种新的基于模型的无分类器指导编辑图像。此外,控制条件的多功能性通过整合文本之外的条件进一步增强了编辑过程。例如,Choi等人[235]对扩散模型进行了定制,使用参考图像中的特定元素作为编辑标准,例如将源图像中的猫替换为参考图像中的猫的外观。此外,还有几种方法[236]通过空间控制来利用空间操作,使用草图或布局来直观地调整图像中元素的排列。
Image Completion and Inpainting
灵活控制机制的进步也极大地扩展了图像绘制和完成领域的能力。具体来说,DreamInpainter[237]利用主题驱动的生成方法在参考图像的帮助下个性化遮罩区域的填充。此外,Realfill[238]采用了类似的方法,利用参考图像来实现真实连贯的图像补全。此外,通过多条件控制,Uni-inpaint[239]集成了多种控制条件,如文本描述、笔画和范例图像,以同时指导遮罩区域内的生成。
Image Composition
图像合成是一项具有挑战性的任务,涉及多个复杂的图像处理阶段,如色彩协调、几何校正、阴影生成等。而大规模预训练扩散模型中的强先验可以统一地解决问题。通过添加适配器来控制预训练的文本到图像扩散模型,ObjectStitch[240]提出了一个对象组合框架,可以处理多个方面,如视点、几何、照明和阴影。此外,DreamCom[241]在几个前景目标图像上定制了文本到图像模型,以增强目标细节的可保存性。此外,ControlCom[242]通过在U-Net中插入任务指示向量来控制生成过程,提出了一种可控的图像合成方法,将四个与合成相关的任务统一为一个指示向量。
Text/Image-to-3D Generation
文本/图像到3D任务旨在从文本描述或图像(对)重建3D表示。在早期,由于依赖昂贵的3D注释,这项任务发展缓慢。大规模文本到图像扩散模型的强大开放世界知识带来了有效的解决方案,而无需繁重的3D注释要求。例如,Zero-1-to-3[243]通过个性化潜在扩散模型[23],构建了视点条件下的图像平移扩散模型,生成输入对象图像的多个视图。然后将配对后的图像输入NeRF[244]模型进行重建。
随着分数蒸馏采样(SDS)损失的发展,文本/图像到3d生成的最新进展是一个重要的里程碑。这种由DreamFusion[245]引入的创新方法,标志着大规模2D扩散模型成功适应了3D生成。通过SDS,可以将文本-图像模型的控制方法转移到文本- 3d生成。通常,DreamBooth3D[246]结合了DreamBooth b[42]和DreamFusion[245],从拍摄的几张主题图像中个性化文本到3d生成模型。同样,一些方法[247]、[248]、[248]、[249]使ControlNet[190]适应SDS过程,通过空间信号(如深度图、草图)控制3D生成。
CONCLUSION
在这个全面的调查中,我们深入研究了文本到图像扩散模型的条件生成领域,揭示了包含在文本引导生成过程中的新条件。首先,我们为读者提供基础知识,介绍去噪扩散概率模型,突出的文本到图像扩散模型,以及结构良好的分类。随后,我们揭示了在T2I扩散模型中引入新条件的机制。然后,我们对以往的条件生成方法进行了总结,并从理论基础、技术进步和解决策略等方面进行了分析。此外,我们探讨了可控生成的实际应用,强调了其在人工智能生成内容时代的重要作用和巨大潜力。本调查旨在全面了解可控T2I发电的现状,从而促进这一动态研究领域的持续发展和扩展。