Kubernetes上的爬虫排队术——任务调度与弹性扩缩容实战
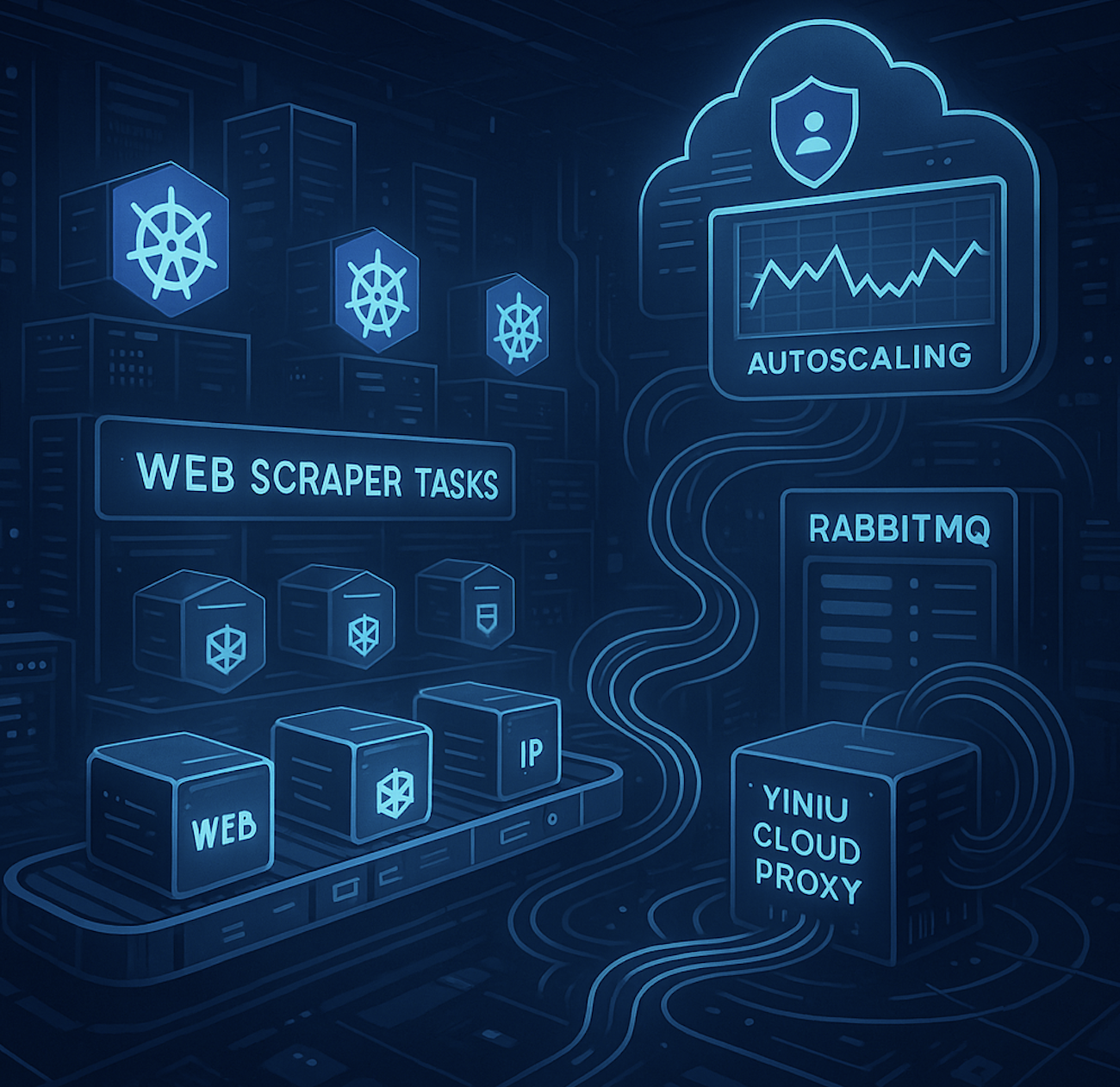
一、背景介绍:为什么要在 Kubernetes 上跑爬虫?
随着网站反爬技术日益严格,传统单机爬虫系统逐渐面临瓶颈。Kubernetes(简称 K8s)作为容器编排利器,天然具备任务调度、负载均衡、故障自动恢复等特性,非常适合构建可水平扩展的爬虫队列系统。
本次实战将实现:
- 📦 使用 Docker 容器打包爬虫任务
- 📊 使用 RabbitMQ 任务队列实现爬虫任务排队
- ⛽ 使用亿牛云代理(域名、端口、用户名、密码)
- 🛡 设置随机 User-Agent 防止封禁
- ☁ 自动根据任务压力扩展 Pod 实例(Horizontal Pod Autoscaler)
二、环境准备
1. 技术栈
- Python 3.10
- Scrapy + requests
- RabbitMQ(任务队列)
- Kubernetes(使用 kubectl / minikube / cloud K8s 均可)
- Docker(打包爬虫镜像)
- 亿牛云爬虫代理
2. 安装依赖
pip install scrapy pika requests
三、核心步骤:任务调度 + 爬虫代理 + 弹性伸缩
1. 创建 RabbitMQ 队列生产者
用于生产任务(汽车新闻栏目页链接)。
# task_producer.py
import pikaconnection = pika.BlockingConnection(pika.ConnectionParameters(host='rabbitmq-service'))
channel = connection.channel()channel.queue_declare(queue='news_tasks', durable=True)# 示例:推送任务
for page in range(1, 11):url = f"https://news.yiche.com/qichexinwen/p{page}/"channel.basic_publish(exchange='',routing_key='news_tasks',body=url,properties=pika.BasicProperties(delivery_mode=2)) # 持久化消息print("✅ 已推送任务")
connection.close()
2. 编写爬虫消费者(Worker)
# news_spider.py
import pika
import requests
from bs4 import BeautifulSoup
import random# 亿牛云代理配置 www.16yun.cn
PROXY = "http://16YUN:16IP@proxy.16yun.cn:3100"USER_AGENTS = ["Mozilla/5.0 (Windows NT 10.0; Win64; x64)...","Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7)...",# 更多 User-Agent 可加入
]def fetch_and_parse(url):headers = {"User-Agent": random.choice(USER_AGENTS)}proxies = {"http": PROXY,"https": PROXY}resp = requests.get(url, headers=headers, proxies=proxies, timeout=10)if resp.status_code != 200:print(f"❌ 请求失败:{url}")return []soup = BeautifulSoup(resp.text, "html.parser")articles = []for item in soup.select(".module .item"):title = item.select_one("h3")link = item.select_one("a")if title and link:articles.append({"title": title.get_text(strip=True),"url": link["href"]})return articlesdef callback(ch, method, properties, body):url = body.decode()print(f"📥 正在处理:{url}")articles = fetch_and_parse(url)# 将数据写入本地归档with open("news_data.txt", "a", encoding="utf-8") as f:for a in articles:f.write(f"{a['title']} - {a['url']}\n")print(f"✅ 完成:{len(articles)}条")ch.basic_ack(delivery_tag=method.delivery_tag)# 连接 RabbitMQ
connection = pika.BlockingConnection(pika.ConnectionParameters(host='rabbitmq-service'))
channel = connection.channel()
channel.queue_declare(queue='news_tasks', durable=True)channel.basic_qos(prefetch_count=1)
channel.basic_consume(queue='news_tasks', on_message_callback=callback)print("🔄 等待任务中...")
channel.start_consuming()
3. Dockerfile 构建爬虫镜像
# Dockerfile
FROM python:3.10-slimWORKDIR /app
COPY . /appRUN pip install -r requirements.txtCMD ["python", "news_spider.py"]
4. Kubernetes 部署配置
创建 deployment.yaml:
apiVersion: apps/v1
kind: Deployment
metadata:name: news-spider
spec:replicas: 1selector:matchLabels:app: news-spidertemplate:metadata:labels:app: news-spiderspec:containers:- name: spiderimage: your-registry/news-spider:latestenv:- name: PROXYvalue: "http://testuser:testpass@proxy.enewcloud.cc:10001"
---
apiVersion: autoscaling/v2
kind: HorizontalPodAutoscaler
metadata:name: spider-hpa
spec:scaleTargetRef:apiVersion: apps/v1kind: Deploymentname: news-spiderminReplicas: 1maxReplicas: 10metrics:- type: Resourceresource:name: cputarget:type: UtilizationaverageUtilization: 50
四、完整代码仓库结构
k8s-news-spider/
├── Dockerfile
├── news_spider.py
├── task_producer.py
├── requirements.txt
├── deployment.yaml
requirements.txt 内容:
requests
pika
beautifulsoup4
五、常见错误排查
| 问题 | 解决方法 |
|---|---|
| 容器连接 RabbitMQ 报错 | 确保 RabbitMQ 在同一 namespace 下并已启用服务 |
| 访问目标站返回 403 | 检查 User-Agent 是否合理,代理是否被封 |
| 无法扩容 | 检查是否部署 HPA controller,Pod 是否配置资源限制 |
| 数据采集为空 | 检查 HTML 结构是否有变,必要时更新解析逻辑 |
六、总结提升
本教程构建了一个完整的容器化 + 队列化 + 可扩缩容的爬虫系统。通过 RabbitMQ 实现任务调度,通过亿牛云代理与随机 User-Agent 防止限制,通过 Kubernetes 实现容器水平扩展,适合构建大规模网页采集系统的原型架构。