机器学习实战:犯罪率预测模型
今天将和大家分享一个机器学习实战项目,该项目从数据预处理、建立不同的学习模型,到根据人口和经济信息找到更强大的阈值来预测不同地区的犯罪率。 根据不同的衡量标准,挑选出 10 种严重影响高犯罪率地区的特征。运用到的算法包括:决策树分类器、高斯朴素贝叶斯、线性支持向量机、线性回归、岭回归、多项式特征、KNN、多项式 SVC。
决策树
from sklearn.tree import DecisionTreeClassifier
import matplotlib.pyplot as plt
import pandas as pd
import numpy as np
df=pd.read_csv('communities-crime-clean.csv') # 数据获取:在#公众号:数据STUDIO 后台回复 【crime 即可免费获取!
df['highCrime'] = np.where(df['ViolentCrimesPerPop']>0.1, 1, 0)
pos=df[(df['highCrime'] == 1)]
pos_percentage=len(pos)/len(df)
neg_percentage=1-pos_percentage
print('positive instance percentage is ',pos_percentage)
print('negative instance percentage is ',neg_percentage)
positive instance percentage is 0.6271951831409934
negative instance percentage is 0.37280481685900657
from sklearn.model_selection import cross_val_score
from sklearn import tree
initial=pd.read_csv('communities-crime-clean.csv')
initial = initial.drop('communityname', 1)
initial = initial.drop('ViolentCrimesPerPop', 1)
initial = initial.drop('fold', 1)initial = initial.drop('state', 1)
Y = df['highCrime']
clf = tree.DecisionTreeClassifier(max_depth=3)
# clf = tree.DecisionTreeClassifier()
clf = clf.fit(initial, Y)
clf
y_pred = clf.predict(initial)
list(initial)
feature_name=list(initial)
import pydotplus
from IPython.display import Image
classname=['High','Low']
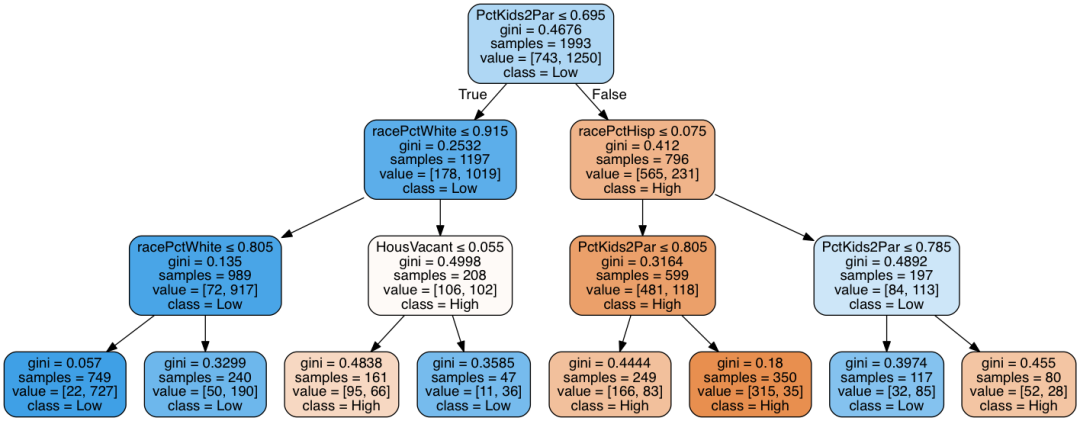
dot_data = tree.export_graphviz(clf, out_file=None, feature_names=list(initial), class_names=classname, filled=True, rounded=True, special_characters=True)
graph = pydotplus.graph_from_dot_data(dot_data)
Image(graph.create_png())
from sklearn.model_selection import cross_val_score
fold=df['fold']
scores = cross_val_score(clf, initial, Y,fold,'accuracy',10)
print('cross_val_accuracy is ',scores)
print('cross_val_accuracy_avg is ',np.array(scores).mean())
scores = cross_val_score(clf, initial, Y,fold,'precision',10)
print('cross_val_precision is ',scores)
print('cross_val_precision_avg is ',np.array(scores).mean())
scores = cross_val_score(clf, initial, Y,fold,'recall',10)
print('cross_val_recall is ',scores)
print('cross_val_recall_avg is ',np.array(scores).mean())
cross_val_accuracy is [ 0.79 0.875 0.83 0.84924623 0.65326633 0.758793970.84924623 0.7839196 0.79396985 0.79899497]
cross_val_accuracy_avg is 0.798243718593
cross_val_precision is [ 0.78231293 0.85211268 0.84210526 0.88 0.75454545 0.881188120.85185185 0.94565217 0.79166667 0.85123967]
cross_val_precision_avg is 0.843267479959
cross_val_recall is [ 0.92 0.968 0.896 0.88 0.664 0.712 0.92 0.696 0.912 0.824]
cross_val_recall_avg is 0.8392
from sklearn.metrics import accuracy_score
print ('Accuracy is', accuracy_score(Y,y_pred)*100)
from sklearn.metrics import precision_score
print ('Precesion is', precision_score(Y,y_pred)*100)
from sklearn.metrics import recall_score
print ('Recall is', recall_score(Y,y_pred)*100)
Accuracy is 83.592574009
Precesion is 90.0260190807
Recall is 83.04
y=[]
x=[]
for i in range (1,16):clf = tree.DecisionTreeClassifier(max_depth=i)clf = clf.fit(initial, Y)y_pred = clf.predict(initial)scores = cross_val_score(clf, initial, Y,None,'accuracy',cv=10)y.append(np.array(scores).mean())x.append(i)plt.plot(x, y)plt.show()print('',y)
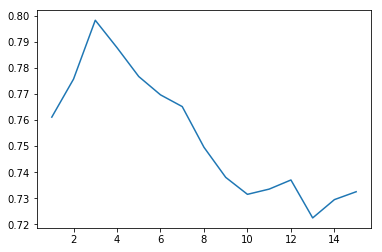
[0.76111306532663314, 0.77569346733668343, 0.79824371859296483, 0.78773366834170866, 0.7766758793969849, 0.76965577889447234, 0.76515829145728653, 0.74956030150753772, 0.73803517587939704, 0.73152763819095479, 0.73353517587939687, 0.73703015075376888, 0.72249246231155773, 0.72950502512562809, 0.73252512562814076]
根据上图,我们可以在决策树分类器中获得最佳的最大深度喂养数。随着 max_depth 数的增加,cross_val_score_accuracy 的平均值不断上升,到 3 时开始下降。 因此,在决策树分类器中,max_depth=3 可以获得最佳的数据集分析性能。 我们在 feature_importances 数组中最多选取四个最大的信息增益,使用基尼法计算后得到下图所示的四个特征。
feature_selection = clf.feature_importances_ ind = np.argpartition(feature_selection, -4)[-4:]print('ind is ',ind)
print('4_max_normalized_feature is ',feature_selection[ind])for x in range(0, len(ind)):index=ind[x]print(index)print('feature_name[index] is ',feature_name[index])
ind is [71 5 3 44]
4_max_normalized_feature is [ 0.02009928 0.09165031 0.16830665 0.71994376]
71
feature_name[index] is HousVacant
5
feature_name[index] is racePctHisp
3
feature_name[index] is racePctWhite
44
feature_name[index] is PctKids2Par
由于交叉验证要求我们在一个缩小的数据集上进行训练,然后在我们没有训练过的数据上进行测试,因此与完整数据集的训练和测试相比,平均准确率、精确度和召回分数都有所下降。
高斯朴素贝叶斯
from sklearn.naive_bayes import GaussianNB
gnb = GaussianNB()
y_pred = gnb.fit(initial, Y).predict(initial)print("mislabel num is ",(Y != y_pred).sum())# print ('sigma is ',gnb.sigma_)
variance=gnb.sigma_
stand_deviation =np.sqrt( variance)
# print('standard deviation is',stand_deviation);
sum_standard=stand_deviation[0]+stand_deviation[1]
# print('sum of standard deviation is',sum_standard);# print ('theta is ',gnb.theta_)
mean=gnb.theta_
difference=mean[0]-mean[1]
# print('difference is ',abs(difference))
normalized_feature=abs(difference)/sum_standard
# print('normalized_feature is ',normalized_feature)ind = np.argpartition(normalized_feature, -10)[-10:]print('ind is ',ind)
print('10_max_normalized_feature is ',normalized_feature[ind])for x in range(0, len(ind)):index=ind[x]print(index)print('feature_name[index] is ',feature_name[index])from sklearn.model_selection import cross_val_score
fold=df['fold']
scores = cross_val_score(gnb, initial, Y,fold,'accuracy',10)
print('cross_val_accuracy is ',scores)
print('cross_val_accuracy_avg is ',np.array(scores).mean())
scores = cross_val_score(gnb, initial, Y,fold,'precision',10)
print('cross_val_precision is ',scores)
print('cross_val_precision_avg is ',np.array(scores).mean())
scores = cross_val_score(gnb, initial, Y,fold,'recall',10)
print('cross_val_recall is ',scores)
print('cross_val_recall_avg is ',np.array(scores).mean())
mislabel num is 442
ind is [38 44 45 41 15 46 50 3 43 40]
10_max_normalized_feature is [ 0.61686366 0.80974842 0.66500857 0.67464461 0.66107643 0.642949450.70926105 0.73522995 0.74554481 0.69397809]
38
feature_name[index] is MalePctDivorce
44
feature_name[index] is PctKids2Par
45
feature_name[index] is PctYoungKids2Par
41
feature_name[index] is TotalPctDiv
15
feature_name[index] is pctWInvInc
46
feature_name[index] is PctTeen2Par
50
feature_name[index] is PctIlleg
3
feature_name[index] is racePctWhite
43
feature_name[index] is PctFam2Par
40
feature_name[index] is FemalePctDiv
cross_val_accuracy is [ 0.775 0.8 0.825 0.79899497 0.70351759 0.653266330.81407035 0.73366834 0.71356784 0.79899497]
cross_val_accuracy_avg is 0.761608040201
cross_val_precision is [ 0.86363636 0.92929293 0.95 0.92079208 0.94594595 0.868421050.92307692 1. 0.77868852 0.93814433]
cross_val_precision_avg is 0.911799814828
cross_val_recall is [ 0.76 0.736 0.76 0.744 0.56 0.528 0.768 0.576 0.76 0.728]
cross_val_recall_avg is 0.692
μμσσ是选择预测特征的度量,由相关系数公式得出,即σσ。根据相关系数的定义,为了使真正敏感的协方差标准化,我们需要除以方差来得到 X 和 Y 之间的相关系数指标,因此,μμσσ ,即绝对相关系数,可以估计属性与 T/F 标签之间关系的强度。如果数值越大,则关系越强。因此,它可以作为找出预测特征的标准。
在数据集上,Naive Bayes 的平均准确率和召回率均低于决策树。 这可能是由于数据集中的特征之间存在相关性,而根据定义,Naive Bayes 分类器假定这些特征是有条件独立的。有趣的是,两者都发现 PctKids2Par 是最具预测性的特征。
LinearSVC
from sklearn import svm
lin_svc = svm.LinearSVC(C=0.01447, penalty="l1", dual=False).fit(initial, Y)
# using L1-norm (sparsity method) to make unless feature weight become 0 , C value increase->more complex model having more weight
feature_weight=abs(lin_svc.coef_[0])
print("",feature_weight)
for i in range(0,len(feature_weight)):if(feature_weight[i]!=0):print('select_feature_is ',feature_name[i], ' feature_weight is ', feature_weight[i])from sklearn.model_selection import cross_val_score
fold=df['fold']
scores = cross_val_score(lin_svc, initial, Y,fold,'accuracy',10)
print('cross_val_accuracy is ',scores)
print('cross_val_accuracy_avg is ',np.array(scores).mean())
scores = cross_val_score(lin_svc, initial, Y,fold,'precision',10)
print('cross_val_precision is ',scores)
print('cross_val_precision_avg is ',np.array(scores).mean())
scores = cross_val_score(lin_svc, initial, Y,fold,'recall',10)
print('cross_val_recall is ',scores)
print('cross_val_recall_avg is ',np.array(scores).mean())
[ 0. 0. 0.14001883 0.60158853 0. 0.298460940. 0. 0. 0. 0. 0. 0.0. 0. 0. 0. 0. 0. 0.0. 0. 0. 0. 0. 0. 0.0. 0. 0. 0. 0. 0. 0.0. 0. 0. 0. 0. 0.0.20685957 1.40999677 0. 0. 0.5248893 0. 0.0. 0. 0. 0.37405216 0. 0. 0.0. 0. 0. 0. 0. 0. 0.0. 0. 0. 0. 0. 0. 0.0.18042693 0. 0. 0. 0. 0. 0.0. 0. 0. 0. 0. 0. 0.0. 0. 0. 0. 0.17249698 0. 0.0. 0. 0. 0. 0. 0. 0.0. 0. 0. 0. ]
select_feature_is racepctblack feature_weight is 0.140018826615
select_feature_is racePctWhite feature_weight is 0.601588527123
select_feature_is racePctHisp feature_weight is 0.298460944212
select_feature_is FemalePctDiv feature_weight is 0.206859566967
select_feature_is TotalPctDiv feature_weight is 1.40999677397
select_feature_is PctKids2Par feature_weight is 0.524889297296
select_feature_is PctIlleg feature_weight is 0.374052163259
select_feature_is PctPersDenseHous feature_weight is 0.180426932386
select_feature_is MedRentPctHousInc feature_weight is 0.172496983106
cross_val_accuracy is [ 0.775 0.875 0.87 0.85427136 0.73366834 0.698492460.77386935 0.85427136 0.83919598 0.79899497]
cross_val_accuracy_avg is 0.80727638191
cross_val_precision is [ 0.75641026 0.84615385 0.88372093 0.88188976 0.90909091 0.815533980.78169014 0.96153846 0.82068966 0.81021898]
cross_val_precision_avg is 0.846693692191
cross_val_recall is [ 0.944 0.968 0.912 0.896 0.64 0.68 0.88 0.816 0.952 0.888]
cross_val_recall_avg is 0.8576
在这种估计预测特征的方法中,我们使用 L1 准则作为 LinearSVC 中的惩罚。L1 被称为最小绝对误差,用于计算用于调整模型的惩罚值。它具有稀疏性,可将不具预测性特征的系数降为零,并将其从模型调整计算中移除。
惩罚值 C 代表了模型的复杂程度。我们将 C 调到一个较低的值,以最多选出 11 个预测性特征。这是因为在设置较低的 C 值时,L1 模型更有可能将特征系数降为零。racePctWhite、racePctHisp、PctKids2Par、PctIlleg、FemalePctDiv 和 TotalPctDiv 都是与之前模型一致的特征。PctPersDenseHous、pctWPubAsst、racepctblack 和 pctUrban 在以前的模型中没有预测性,但它们在 LinearSVC 模型中的系数也很低,因此模型选择这些特征有些随意,因为它们只会对模型进行微小的调整以纠正错误。
与决策树相比,LinearSVC 提高了该数据集的准确度、精确度和召回率。这可能是因为 LinearSVC 能够为数据集找到最佳的线性分割超平面,而决策树只能使用轴对齐平面以等级方式分割数据集。有趣的是,LinearSVC 与之前的模型有一个不同的最具预测性的特征,即 TotalPctDiv。这可能意味着 TotalPctDiv 作为非轴对齐平面的线性搜索器更为有效。
线性回归
from sklearn import linear_model
from sklearn.metrics import mean_squared_error
from sklearn.model_selection import cross_val_predictlr = linear_model.LinearRegression(normalize=True)
Y = df['ViolentCrimesPerPop']
predicted = cross_val_predict(lr, initial, Y, cv=10)
print('10_fold_cv_MSE is ',mean_squared_error(Y, predicted))
y_pred = lr.fit(initial, Y).predict(initial)print('MSE on training set is ',mean_squared_error(Y, y_pred))# print('coef is ',lr.coef_)min=np.min(lr.coef_)
print('min is ',min)
index_min = np.argmin(lr.coef_)
print(index_min)
max=np.max(lr.coef_)
print('max is ',max)
index_max = np.argmax(lr.coef_)
print(index_max)
print('coefficient[min] is ',feature_name[index_min])print('coefficient[max] is ',feature_name[index_max])
10_fold_cv_MSE is 0.0201026984667
MSE on training set is 0.0165167748803
min is -0.675694478803
67
max is 0.635088116499
64
coefficient[min] is PctPersOwnOccup
coefficient[max] is PersPerOccupHous
岭回归
from sklearn.linear_model import Ridge
from sklearn.linear_model import RidgeCV
# Using RidgeCV to reduce the amount of verfitting
ridge_model = RidgeCV(alphas=[10.0,1.0,0.1, 0.01, 0.001])
print(ridge_model)
ridge_reg_score = cross_val_predict(ridge_model, initial, Y, cv=10)
ridge_fit = ridge_model.fit(initial, Y)
#To get the best alpha
print('Best Alpha: ', ridge_model.alpha_)
ridge_predict = ridge_model.predict(initial)
#accuracy of each Fold
print(ridge_reg_score)
#mean accuracy of 10 Folds
print(ridge_reg_score.mean())#MSE 10 Fold CV
print('10_fold_cv_MSE is: ',mean_squared_error(Y, ridge_reg_score))#MSE on the Training set
mse_ridge = np.mean((ridge_predict - Y) ** 2)
print ("Mean Square Error on training set: ", mse_ridge)
RidgeCV(alphas=[10.0, 1.0, 0.1, 0.01, 0.001], cv=None, fit_intercept=True,gcv_mode=None, normalize=False, scoring=None, store_cv_values=False)
Best Alpha: 1.0
[ 0.15629536 0.29723509 0.52328122 ..., 0.09344901 0.163008330.16714695]
0.237082421104
10_fold_cv_MSE is: 0.0198039525288
Mean Square Error on training set: 0.016763529155169456
在这个问题上,与脊回归相比,线性回归显然存在一些过度拟合,因为脊回归的 MSE 比线性回归差,但脊回归的 CV-MSE 比线性回归好。线性回归无法将公式中的特征系数降为零,这显然对该数据集的方法有一定影响。
多项式回归
from sklearn.preprocessing import *
from sklearn.pipeline import Pipeline
from sklearn.linear_model import LinearRegressionpol = PolynomialFeatures(degree = 2)
print(pol)lin_reg = LinearRegression()
pip = Pipeline([("polynomial Feature", pol),("linear_Regression", lin_reg)])
poly_reg_score = cross_val_predict(pip, initial, Y, cv=10)
p_fit = pip.fit(initial, Y)
p_predict = pip.predict(initial)
#accuracy of each fold
print(poly_reg_score)
#mean accuracy of 10 Folds
print(poly_reg_score.mean())#MSE 10 Fold CV
print('10_fold_cv_MSE is ',mean_squared_error(Y, poly_reg_score))#MSE on Training Set
mse_poly = np.mean((p_predict - Y) ** 2)
print ("Mean Square Error on training set: ", mse_poly)
PolynomialFeatures(degree=2, include_bias=True, interaction_only=False)
[ 0.54690473 0.53204015 0.32259675 ..., -0.19221053 0.172855220.40108437]
0.235721580411
10_fold_cv_MSE is 0.129955108714
Mean Square Error on training set: 1.3968962136279826e-28
就该数据集而言,线性模型明显优于二次模型。数据集的真实模型更有可能是线性模型,而不是二次模型。
脏数据
df=pd.read_csv('communities-crime-full.csv') # 数据获取:在#公众号:数据STUDIO 后台回复 【crime】 即可免费获取!
df
df['highCrime'] = np.where(df['ViolentCrimesPerPop']>0.1, 1, 0)
Y = df['highCrime']# print('total len is ',len(Y))
initial=pd.read_csv('communities-crime-full.csv')
initial = initial.drop('communityname', 1)
initial = initial.drop('ViolentCrimesPerPop', 1)
initial = initial.drop('fold', 1)
initial = initial.drop('state', 1)
initial = initial.drop('community', 1)
initial = initial.drop('county', 1)feature_name=list(initial)
initial=initial.convert_objects(convert_numeric=True)
New_data=initial.fillna(initial.mean())
# print('before...')
# print(initial)
# print('after...')
# print(New_data)
clf = tree.DecisionTreeClassifier(max_depth=3)
# clf = tree.DecisionTreeClassifier()
clf = clf.fit(New_data, Y)
clf
fold=df['fold']
scores = cross_val_score(clf, New_data, Y,fold,'accuracy',10)
print('cross_val_accuracy is ',scores)
print('cross_val_accuracy_avg is ',np.array(scores).mean())
scores = cross_val_score(clf, New_data, Y,fold,'precision',10)
print('cross_val_precision is ',scores)
print('cross_val_precision_avg is ',np.array(scores).mean())
scores = cross_val_score(clf, New_data, Y,fold,'recall',10)
print('cross_val_recall is ',scores)
print('cross_val_recall_avg is ',np.array(scores).mean())
cross_val_accuracy is [ 0.81094527 0.81 0.805 0.79899497 0.82914573 0.773869350.85427136 0.83417085 0.80904523 0.8040201 ]
cross_val_accuracy_avg is 0.812946286157
cross_val_precision is [ 0.90740741 0.85365854 0.84677419 0.84 0.85826772 0.857142860.92105263 0.92592593 0.85950413 0.90566038]
cross_val_precision_avg is 0.877539377831
cross_val_recall is [ 0.77777778 0.84 0.84 0.84 0.872 0.768 0.840.8 0.832 0.768 ]
cross_val_recall_avg is 0.817777777778
y=[]
x=[]
for i in range (1,16):clf = tree.DecisionTreeClassifier(max_depth=i)clf = clf.fit(New_data, Y)y_pred = clf.predict(New_data)scores = cross_val_score(clf, New_data, Y,None,'accuracy',cv=10)y.append(np.array(scores).mean())x.append(i)plt.plot(x, y)plt.show()
print('y is ',y)
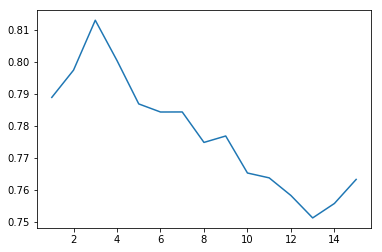
y is [0.78886085902147562, 0.79737344683617095,
0.81294628615715392, 0.80036095902397564,
0.78682827070676775, 0.784303195079877,
0.78432078301957542, 0.77480812020300505,
0.77681563289082234, 0.76526284407110179,
0.76374533113327836, 0.75824020600515007,
0.75124510612765305, 0.75575515637890944,
0.7632602565064126]
feature_selection = clf.feature_importances_ ind = np.argpartition(feature_selection, -4)[-4:]print('ind is ',ind)
print('4_max_normalized_feature is ',feature_selection[ind])for x in range(0, len(ind)):index=ind[x]print(index)print('feature_name[index] is ',feature_name[index])
ind is [29 5 3 44]
4_max_normalized_feature is [ 0.02422915 0.04857088 0.09191501 0.35879597]
29
feature_name[index] is PctLess9thGrade
5
feature_name[index] is racePctHisp
3
feature_name[index] is racePctWhite
44
feature_name[index] is PctKids2Par
在相同参数下,干净数据和完整数据之间的 CV 结果使准确性略有提高。这可能是因为缺失值被各自列的平均值所替代。数据集整体方差的减少可能会提高性能。最具预测性的特征保持不变,因此无法解释脏特征可用于分割的原因。
PCA&K-NN
from sklearn.decomposition import PCA
from sklearn.neighbors import KNeighborsClassifierdf=pd.read_csv('communities-crime-clean.csv')
df['highCrime'] = np.where(df['ViolentCrimesPerPop']>0.1, 1, 0)
initial=pd.read_csv('communities-crime-clean.csv')
Y = df['highCrime']
fold=df['fold']
state=df['state']
community=df['communityname']
initial = initial.drop('fold', 1)
initial = initial.drop('state', 1)
initial = initial.drop('communityname', 1)
initial = initial.drop('ViolentCrimesPerPop', 1)x=[]
y=[]
for k in range (1,16):y.append([])
for i in range (2,15):pca = PCA(n_components=i)pca.fit(initial)pcdf = pca.transform(initial)for j in range (1,16):knn = KNeighborsClassifier(j)knn.fit(pcdf,Y)scores = cross_val_score(knn,pcdf,Y,fold,'accuracy',10)y[j-1].append(np.mean(scores))x.append(i)plt.plot(x,y[0],'r-',x,y[1],'g-',x,y[2],'b-',x,y[3],'r--',x,y[4],'g--',x,y[5],'b--',x,y[6],'r-.',x,y[7],'g-.',x,y[8],'b-.',x,y[9],'r:',x,y[10],'g:',x,y[11],'b:',x,y[12],'c-',x,y[13],'m-',x,y[14],'y-')
plt.show()
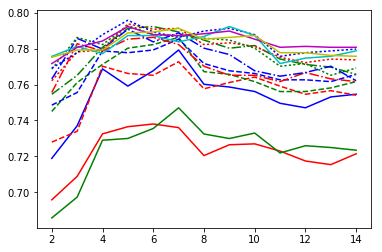
-
X轴为元件数
-
Y轴为精度
-
红色实线为k=1
-
绿色实线为k=2
-
蓝色-实线为k=3 实线为 k=3
-
红色虚线为 k=4
-
绿色虚线为 k=5
-
蓝色虚线为 k=6
-
红色虚点 线是 k=7
-
绿色虚线是 k=8
-
蓝色虚线是 k=9
-
红色虚线是 k=10
-
绿色虚线是 k=11
-
蓝色虚线是 k=12 点线为 k=12
-
青色实线为 k=13
-
洋红色实线为 k=14
-
黄色实线为 k=15
-
蓝色虚线在 n 个分量=5 表示 k=12 时性能最佳
pca = PCA(n_components=5)
pca.fit(initial)
pca.components_
上下滑动查看更多源码
array([[ -2.04052546e-02, 9.75132690e-03, -1.28371329e-01,1.23044608e-01, 6.52084194e-02, -6.14280591e-02,-4.72820587e-02, -4.60121765e-02, -4.71777648e-02,-3.46626378e-02, -1.56537431e-02, 1.52570830e-01,1.88492101e-01, 1.03286139e-01, -7.18548440e-03,1.48691465e-01, -6.12543207e-02, -1.73401439e-01,4.48956257e-03, 1.79662679e-01, 1.61193740e-01,1.40327609e-01, 1.07194806e-01, 4.39239209e-02,8.19922061e-02, 7.74816512e-02, 1.13058167e-01,-3.97531389e-02, -1.91357751e-01, -1.50661446e-01,-1.59431939e-01, 1.42844505e-01, -1.52692314e-01,1.10214847e-01, -2.33208904e-02, 1.61083945e-02,-1.34972468e-01, 1.35500286e-01, -1.06437345e-01,-4.01754009e-02, -1.01677202e-01, -1.09737150e-01,-1.29668589e-02, 1.62749424e-01, 1.68736871e-01,1.78676474e-01, 1.33751535e-01, -1.18987095e-02,1.12613742e-02, -3.11151955e-02, -1.50870947e-01,-6.64631737e-03, -4.14686662e-02, -4.77028848e-02,-4.49797848e-02, -4.97956803e-02, 6.22271445e-03,3.61716851e-03, 6.69008024e-03, 4.08774764e-03,2.16062354e-02, -4.56107809e-02, -6.59365027e-02,-4.86852812e-02, 2.29232532e-02, 3.67738154e-02,-4.79458198e-02, 1.22711019e-01, -8.44847108e-02,-9.64958429e-02, 1.09751354e-01, -3.41640913e-02,7.40567876e-02, 1.04629295e-01, -1.07733239e-01,-4.70222532e-02, 4.19420273e-02, -1.99593745e-01,-1.09298585e-01, 1.61984123e-01, 1.64369571e-01,1.63985961e-01, 1.67068789e-01, 1.63565391e-01,1.93204244e-01, 1.67100994e-01, -4.34843126e-02,5.72625982e-02, -1.60733392e-02, -1.90625776e-02,-1.34111688e-02, 2.94298202e-02, -4.96684542e-02,3.38877946e-02, -1.86070060e-02, -2.20883944e-02,-8.86291687e-03, -1.40120126e-02, 3.93038079e-02,-4.30436519e-02],[ 4.65107143e-02, 7.31007190e-02, 2.97025733e-02,-1.58534468e-01, 1.59178377e-01, 1.90141431e-01,1.83388364e-02, 4.98339305e-02, 3.60912415e-02,-6.85006568e-02, 5.03646766e-02, 1.79413485e-01,3.49315055e-02, 4.75614065e-02, -2.98432226e-02,-3.88640765e-02, -7.24146284e-02, 6.26498274e-02,-6.90031511e-02, 2.64331353e-02, 2.15127910e-02,3.98709889e-02, 3.11563777e-02, 1.61664886e-02,-2.11443793e-03, 1.76561650e-02, 1.13249219e-03,4.44772229e-02, 3.75167294e-02, 5.83546767e-02,3.54672293e-02, 2.79190895e-02, 5.03081110e-02,1.69247652e-02, -3.09069782e-02, -1.63984466e-02,-1.84144383e-02, 9.43444321e-03, 1.66036743e-03,9.47740644e-02, 3.14749068e-02, 1.73305868e-02,8.70286054e-02, -3.54616992e-02, -4.70713715e-02,-2.20965430e-02, -3.80259959e-02, -5.20351884e-02,-7.29741943e-02, 3.66921355e-02, 9.36376749e-02,5.51732345e-02, 8.55569626e-02, 9.96086929e-02,1.07522904e-01, 1.14090535e-01, 2.48913152e-01,2.53173277e-01, 2.55635505e-01, 2.54071885e-01,-2.16690578e-01, 2.09656366e-01, 1.49733800e-01,1.36121701e-01, 7.53719140e-02, 6.65356817e-02,1.07242118e-01, -1.00592409e-01, 1.87340413e-01,7.55166956e-02, -1.02483947e-01, 3.81778676e-02,1.20197054e-02, -8.64467137e-02, 2.59321557e-02,-7.93014450e-02, 6.71860874e-03, -6.38694259e-03,5.33376938e-02, 1.24416081e-01, 1.30880632e-01,1.30976515e-01, 1.14243563e-01, 1.08325561e-01,1.30358452e-01, 1.00888414e-01, 7.85087111e-02,1.25190223e-01, -1.14538720e-02, 3.25126269e-02,3.44237881e-02, 2.41529233e-01, -1.19628987e-01,-5.53248292e-02, -3.66483592e-02, -5.65180964e-02,6.84213385e-03, 1.48630105e-01, 1.16127641e-01,7.84299457e-02],[ -6.88867065e-02, 1.84378241e-01, -1.48539892e-01,3.24645126e-02, -2.55345025e-02, 1.78205053e-01,2.47372875e-02, -3.55922556e-02, -5.78614528e-02,-5.86804780e-02, -7.33692924e-02, -2.23215311e-01,3.07009099e-02, 3.59936390e-02, 8.68329756e-02,-4.86515830e-02, -8.52261033e-03, 5.69111176e-02,-1.75402785e-02, -1.04361123e-02, -7.07669742e-02,-9.32039347e-02, 1.80356460e-03, -9.24773897e-03,3.74745612e-03, -1.35761441e-02, -3.41734747e-02,-6.33391840e-02, -1.85142354e-02, 1.39808419e-01,1.15570752e-01, -1.35757692e-01, 6.88762492e-02,-9.40577088e-03, 1.08697744e-01, -1.18418021e-01,1.20619985e-01, -1.06310891e-01, -1.22333471e-01,-1.14450261e-01, -1.10821933e-01, -1.22157582e-01,1.84837285e-01, 1.38075445e-01, 1.14626935e-01,9.95829780e-02, 1.46309984e-01, -6.88250775e-02,-8.21942016e-02, -5.48599188e-02, -1.03823499e-01,-1.36906550e-02, -1.43921798e-01, -1.37061365e-01,-1.30465199e-01, -1.08800742e-01, 2.67842306e-03,1.37421407e-02, 2.00639539e-02, 3.06104590e-02,-1.43209729e-01, 1.39570861e-01, 1.69417145e-01,1.97454475e-01, 2.25731533e-01, 1.84573941e-01,1.95254268e-01, 1.33745273e-01, 1.30250019e-01,-1.12362349e-01, 1.48020795e-01, -1.02540972e-01,6.65738445e-02, 1.43029379e-01, -1.30006653e-02,6.17312073e-02, 4.86888593e-02, 3.09150261e-02,6.83081568e-02, -1.94465266e-02, -2.83618382e-02,-4.30280380e-02, -2.12406819e-02, -1.49121313e-02,-1.84716473e-02, -6.43359486e-03, -3.64432461e-02,1.33429220e-02, -7.05597153e-03, -5.51658886e-02,-3.87890402e-02, 6.19267105e-02, 9.03999176e-02,1.08540850e-01, 1.19724503e-01, 1.39962944e-01,-3.50889121e-02, -5.24427182e-02, -1.10702926e-01,-1.36254487e-01],[ -3.80659489e-02, 9.39381894e-02, -8.72498183e-02,4.99208446e-02, 2.77345526e-02, 1.14081463e-02,1.73810113e-01, 1.63077667e-01, 1.79193131e-01,-1.78816249e-01, -4.81228555e-02, -3.34288540e-01,-3.16081069e-02, 1.38364575e-01, 1.75909675e-01,-1.10614016e-02, -1.70490224e-01, -8.04102142e-02,-1.44853738e-01, -2.26184249e-02, -5.67523952e-02,-6.58759791e-02, -4.03184208e-02, -2.28327658e-02,-7.81584688e-02, -2.68879159e-02, -6.60839533e-02,-3.98978044e-02, 5.68827794e-02, -6.65450492e-02,-1.01121892e-01, 9.11635240e-02, -6.33457708e-02,7.14798133e-02, -7.38017874e-02, 6.15589432e-02,-5.91537052e-02, 4.01544710e-02, -5.71937194e-02,6.09171417e-02, -3.27547260e-02, -4.78618161e-02,1.78865461e-02, 7.50941373e-02, 8.30942536e-02,7.58574169e-02, 6.26500424e-02, 4.79646196e-02,5.30031167e-02, -4.87688887e-02, -8.84047391e-02,-2.17840032e-02, 2.03880738e-01, 1.98981289e-01,1.87121487e-01, 1.71971096e-01, 3.37355574e-02,2.27792006e-02, 1.24137598e-02, 3.25715232e-03,4.26717149e-02, -2.88251387e-02, -9.55407268e-03,2.22090960e-03, 3.49842650e-02, 3.08502556e-02,5.84426584e-02, -6.04239766e-02, 2.39236427e-02,-1.30815065e-02, -6.82667856e-03, -4.98688283e-02,3.22796331e-04, -5.33363438e-02, -1.23384450e-01,-8.74260505e-02, 2.40377163e-01, 2.00265022e-02,-3.92003843e-02, -6.40547239e-02, -6.32263355e-02,-6.07790598e-02, -2.71661653e-02, -4.76947157e-02,-5.87489155e-02, -5.19831719e-02, 1.02618984e-02,-1.84619413e-02, -1.30101395e-01, -3.44592113e-02,-2.41518370e-02, -5.22472535e-02, -8.47702641e-02,-2.38308579e-01, -2.75193590e-01, -1.89050676e-01,-1.37314954e-03, -1.21594901e-01, -1.60052484e-01,-8.79764951e-02],[ -9.50828959e-02, -1.13399144e-01, -1.51177574e-01,1.09693631e-01, 3.56697409e-02, 1.48117304e-02,-3.81528262e-02, -5.38088051e-02, -1.26974909e-03,2.25863117e-01, -1.09419563e-01, -5.59794391e-01,-2.60973589e-02, -2.00050057e-01, 6.76622935e-02,7.98120169e-02, 1.94447324e-01, 3.50209396e-02,8.18529675e-02, 1.54528400e-02, 6.60206577e-02,4.97418601e-02, 4.83785985e-03, -3.04697624e-03,6.56457909e-02, -2.03462111e-02, 1.74769753e-02,-8.68190921e-02, 5.15682341e-02, 8.61823341e-02,4.85593730e-02, 6.10834622e-02, 3.64983491e-02,-1.60041511e-01, -1.91061672e-02, 9.70978454e-02,-9.38970436e-03, 5.44983905e-02, -3.76628203e-02,2.63637772e-02, -5.37096564e-02, -4.70993379e-02,-1.33731146e-01, -8.60518976e-04, 1.29673225e-02,1.24061253e-03, 1.38624213e-02, -6.66615867e-02,-5.76874177e-02, -7.31596199e-02, -9.13312941e-02,-1.93896897e-02, 4.66407403e-02, 3.57372578e-02,1.42334552e-02, -3.47443618e-03, 1.17710851e-01,1.08725026e-01, 9.99159434e-02, 8.92904777e-02,-7.55787755e-02, 5.73889035e-02, -8.96706478e-02,-9.79135971e-02, -1.49635276e-01, -1.49198957e-01,-1.08078857e-01, -4.68960759e-02, -2.54624496e-02,1.06634953e-01, -1.28560799e-01, -9.11659188e-02,-5.32418701e-02, -4.25626428e-02, -1.13994295e-01,6.77706984e-02, -1.85833888e-01, 3.89587930e-02,5.04470811e-02, 1.16318565e-01, 1.28935379e-01,1.39189621e-01, 1.59458777e-02, 3.94100074e-02,5.48388033e-02, 2.68673629e-02, 7.77539289e-02,1.96159427e-02, 6.54114452e-02, -4.58920302e-02,-3.09453668e-02, 1.06858571e-01, -1.90001068e-02,4.51153564e-02, 1.25245612e-02, 2.09824935e-02,-7.97404722e-02, 5.28959376e-02, 3.94286694e-02,-1.28698204e-01]])
1
pca.explained_variance_ratio_
array([ 0.26753256, 0.1879639 , 0.08245766, 0.07097958, 0.04612133])
pcdf = pca.transform(initial)
pcdf
array([[ 0.42940989, -0.53929962, 0.31031455, 0.61492902, -0.78039836],[-1.19933196, -0.90092286, 0.31801596, 0.06578611, 0.08519296],[-1.25540273, -0.45223119, -0.37326947, -0.57765154, -0.34191667],..., [-0.39828125, -0.04847062, -0.72054899, 1.84903697, 0.50341825],[-0.06739216, -0.87415147, 0.57794265, 0.14245351, -0.03894366],[-0.53794345, -0.94270676, -0.0499251 , 0.22885668, 0.51675747]])
from sklearn.metrics import f1_score
knn = KNeighborsClassifier(n_neighbors=12)
knn.fit(pcdf,Y)
y_pred = knn.predict(pcdf)
print ('fl score is', f1_score(Y,y_pred,average="binary")*100)
print ('Accuracy is', accuracy_score(Y,y_pred)*100)
print ('Precision is', precision_score(Y,y_pred)*100)
print ('Recall is', recall_score(Y,y_pred)*100)
fl score is 87.0279146141
Accuracy is 84.1445057702
Precision is 89.3760539629
Recall is 84.8
scores = cross_val_score(knn,pcdf,Y,fold,'accuracy',10)
print ('Cross validation accuracy is', np.mean(scores)*100)
scores = cross_val_score(knn,pcdf,Y,fold,'precision',10)
print ('Cross validation precision is', np.mean(scores)*100)
scores = cross_val_score(knn,pcdf,Y,fold,'recall',10)
print ('Cross validation recall is', np.mean(scores)*100)
Cross validation accuracy is 79.5728643216
Cross validation precision is 85.3588446077
Cross validation recall is 81.6
KNN 是一种将距离作为数据分类最重要因素的分组方法。这与 PCA 降维过程中特定特征的丢失相结合,使得寻找可靠的预测特征变得非常困难。
因此,预测特征的最佳估计值是捕捉数据集中最大变异百分比的特征向量的最大值特征。
feature_name=list(initial)ind = np.argpartition(pca.components_[0], -10)[-10:]print('ind is ',ind)
print('10_max_vector_components is ',pca.components_[0][ind])for x in range(0, len(ind)):index=ind[x]print(index)print('vector_component[index] is ',feature_name[index])
ind is [83 84 80 19 45 44 81 82 85 12]
10_max_vector_components is [ 0.16356539 0.19320424 0.16436957 0.17966268 0.17867647 0.168736870.16398596 0.16706879 0.16710099 0.1884921 ]
83
vector_component[index] is RentMedian
84
vector_component[index] is RentHighQ
80
vector_component[index] is OwnOccMedVal
19
vector_component[index] is medFamInc
45
vector_component[index] is PctYoungKids2Par
44
vector_component[index] is PctKids2Par
81
vector_component[index] is OwnOccHiQuart
82
vector_component[index] is RentLowQ
85
vector_component[index] is MedRent
12
vector_component[index] is medIncome
PCA 到 K-NN 的结果与决策树相似。 最重要的特征与本项目中实施的其他方法大相径庭,这可能是因为它们不是来自分类算法,而是来自降维算法中方差最大的特征。
df=pd.read_csv('communities-crime-full.csv')
df['highCrime'] = np.where(df['ViolentCrimesPerPop']>0.1, 1, 0)
Y = df['highCrime']
fold=df['fold']
x=[]
y=[]
for k in range (1,16):y.append([])
for i in range (2,15):pca = PCA(n_components=i)pca.fit(New_data)pcdf = pca.transform(New_data)for j in range (1,16):knn = KNeighborsClassifier(j)knn.fit(pcdf,Y)scores = cross_val_score(knn,pcdf,Y,fold,'accuracy',10)y[j-1].append(np.mean(scores))x.append(i)plt.plot(x,y[0],'r-',x,y[1],'g-',x,y[2],'b-',x,y[3],'r--',x,y[4],'g--',x,y[5],'b--',x,y[6],'r-.',x,y[7],'g-.',x,y[8],'b-.',x,y[9],'r:',x,y[10],'g:',x,y[11],'b:',x,y[12],'c-',x,y[13],'m-',x,y[14],'y-')
plt.show()
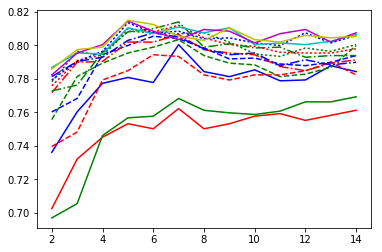
-
X轴为元件数
-
Y轴为精度
-
红色实线为k=1
-
绿色实线为k=2
-
蓝色-实线为k=3 实线为 k=3
-
红色虚线为 k=4
-
绿色虚线为 k=5
-
蓝色虚线为 k=6
-
红色虚点 线是 k=7
-
绿色虚线是 k=8
-
蓝色虚线是 k=9
-
红色虚线是 k=10
-
绿色虚线是 k=11
-
蓝色虚线是 k=12 点线为 k=12
-
青色实线为 k=13
-
品红色实线为 k=14
-
黄色实线为 k=15
-
当 n 个分量=5 时,洋红色实线和黄色实线具有最佳的整体性能,即 k=14 或 k=15。
pca = PCA(n_components=5)
pca.fit(New_data)
pca.components_
上下滑动查看更多源码
array([[ -2.05868501e-02, 9.75819912e-03, -1.29180835e-01,1.23575532e-01, 6.51854594e-02, -6.12052661e-02, -4.71845615e-02, -4.58094979e-02, -4.69925869e-02, -3.46798200e-02, -1.58243934e-02, 1.52668790e-01, 1.88267648e-01, 1.03334631e-01, -7.14474897e-03, 1.48575631e-01, -6.12402679e-02, -1.73533941e-01, 4.48558660e-03, 1.79462994e-01, 1.60939303e-01, 1.39935680e-01, 1.07041398e-01, 4.38929392e-02, 8.17176372e-02, 7.72774286e-02, 1.12556720e-01, -3.99788267e-02, -1.91486828e-01, -1.50541901e-01, -1.59258997e-01, 1.42536645e-01, -1.52856395e-01, 1.10267208e-01, -2.31152613e-02, 1.59113810e-02, -1.34624608e-01, 1.35089944e-01, -1.06389755e-01, -4.01904725e-02, -1.01626911e-01, -1.09689028e-01, -1.30285003e-02, 1.62909635e-01, 1.68913509e-01, 1.78892728e-01, 1.33961330e-01, -1.19086566e-02, 1.13146990e-02, -3.13687988e-02, -1.51377480e-01, -6.74700915e-03, -4.12695813e-02, -4.74095615e-02, -4.46525297e-02, -4.94256892e-02, 6.35142666e-03, 3.75876254e-03, 6.81875408e-03, 4.21425077e-03, 2.14181944e-02, -4.54304685e-02, -6.59391760e-02, -4.86718847e-02, 2.28736171e-02, 3.67529738e-02, -4.79318387e-02, 1.22493153e-01, -8.43731596e-02, -9.62425586e-02, 1.09319821e-01, -3.43569546e-02, 7.41003342e-02, 1.04408975e-01, -1.07887955e-01, -4.71985297e-02, 4.19944916e-02, -1.99421474e-01, -1.09429549e-01, 1.61768522e-01, 1.64129372e-01, 1.63707871e-01, 1.66983540e-01, 1.63428242e-01, 1.92985675e-01, 1.66914307e-01, -4.35293153e-02, 5.71062436e-02, -1.63828072e-02, -1.92055231e-02, -1.35438884e-02, 2.95190229e-02, -4.97565225e-02, 3.36026722e-02, -1.88183002e-02, -2.21857619e-02, -4.63842657e-03, -2.64715412e-03, 4.20720223e-03, -2.31004954e-03, -5.52546036e-03, -4.21871028e-03, -2.20889575e-03, -2.65097265e-03, 1.08946443e-02, 1.06736688e-02, -1.63479261e-02, -3.68487189e-03, 5.04525423e-03, -1.42347240e-02, -4.16911191e-03, -2.07038440e-03, -2.31712141e-04, -8.97404282e-03, -1.39853291e-02, 3.90428108e-02, -8.32220497e-03, -3.79567997e-03, 3.33890172e-03, -1.15603140e-03, -4.28819862e-02, 9.32330717e-04], [ 4.68639304e-02, 7.31251825e-02, 2.94188314e-02, -1.58220527e-01, 1.59104229e-01, 1.90051472e-01, 1.83043796e-02, 4.97386824e-02, 3.59877393e-02, -6.85646744e-02, 5.07144763e-02, 1.79297229e-01, 3.50297988e-02, 4.76717756e-02, -2.97755818e-02, -3.87378572e-02, -7.24769102e-02, 6.24234139e-02, -6.89038231e-02, 2.64968261e-02, 2.15455911e-02, 3.98701627e-02, 3.12271105e-02, 1.62075966e-02, -2.10808433e-03, 1.76112481e-02, 1.02745962e-03, 4.48732684e-02, 3.72397160e-02, 5.81793684e-02, 3.53253360e-02, 2.79148074e-02, 5.00265309e-02, 1.70491364e-02, -3.08381913e-02, -1.63961178e-02, -1.83951828e-02, 9.43162815e-03, 1.58915249e-03, 9.45763446e-02, 3.13870740e-02, 1.72464263e-02, 8.70368571e-02, -3.52047755e-02, -4.68061362e-02, -2.17934050e-02, -3.77603241e-02, -5.20114577e-02, -7.28971659e-02, 3.70130036e-02, 9.32890801e-02, 5.54406119e-02, 8.53144495e-02, 9.93808609e-02, 1.07338338e-01, 1.13948035e-01, 2.48579858e-01, 2.52833761e-01, 2.55312440e-01, 2.53771648e-01, -2.16506113e-01, 2.09492816e-01, 1.49664834e-01, 1.36063635e-01, 7.54231798e-02, 6.66207884e-02, 1.07125434e-01, -1.00297666e-01, 1.87225412e-01, 7.53170557e-02, -1.02260835e-01, 3.84991245e-02, 1.21472215e-02, -8.61935843e-02, 2.59797018e-02, -7.92858584e-02, 6.87774077e-03, -6.51768428e-03, 5.32542334e-02, 1.24288167e-01, 1.30764625e-01, 1.30889686e-01, 1.14193597e-01, 1.08271499e-01, 1.30274472e-01, 1.00831939e-01, 7.83111031e-02, 1.24975506e-01, -1.17828505e-02, 3.27873210e-02, 3.47183706e-02, 2.41255800e-01, -1.19521012e-01, -5.52463068e-02, -3.65771479e-02, -5.63829176e-02, 6.14926427e-03, -2.45272242e-03, -5.56686982e-03, -1.96535515e-03, 7.96570877e-03, 4.91202461e-04, 5.50445938e-03, -2.44773620e-03, -1.05967382e-02, -1.77931817e-02, 7.87784130e-04, 2.09044482e-02, 1.99615130e-02, 1.78463585e-02, 5.18484769e-03, 3.05491448e-03, 1.21730619e-02, 7.09576587e-03, 1.48413480e-01, 1.16065578e-01, 4.19626663e-03, 8.26703658e-03, 2.09301869e-03, 3.24510172e-03, 7.81436545e-02, 3.12458599e-03], [ -7.01961926e-02, 1.84131950e-01, -1.50169556e-01, 3.37207418e-02, -2.52705194e-02, 1.78352168e-01, 2.57733179e-02, -3.43783853e-02, -5.64394006e-02, -5.90721632e-02, -7.47197801e-02, -2.25147079e-01, 2.97812080e-02, 3.62703328e-02, 8.76994474e-02, -4.86952453e-02, -9.02553083e-03, 5.63141126e-02, -1.81266147e-02, -1.10481614e-02, -7.13904606e-02, -9.41348354e-02, 1.31489827e-03, -9.57188329e-03, 2.95137023e-03, -1.40305857e-02, -3.49368573e-02, -6.47231862e-02, -1.79491722e-02, 1.39590608e-01, 1.15039702e-01, -1.35350756e-01, 6.84719997e-02, -9.28720237e-03, 1.08435765e-01, -1.17949493e-01, 1.20478037e-01, -1.06286392e-01, -1.22302979e-01, -1.13958241e-01, -1.10633094e-01, -1.22040908e-01, 1.84024125e-01, 1.38353767e-01, 1.15113919e-01, 1.00004462e-01, 1.46600625e-01, -6.82361399e-02, -8.15355138e-02, -5.64206908e-02, -1.05136108e-01, -1.43037724e-02, -1.42151331e-01, -1.35326358e-01, -1.28886313e-01, -1.07364824e-01, 3.25725590e-03, 1.42163293e-02, 2.04216280e-02, 3.08869658e-02, -1.43082031e-01, 1.39495395e-01, 1.68567342e-01, 1.96669359e-01, 2.24936832e-01, 1.83889093e-01, 1.94915662e-01, 1.32583084e-01, 1.30172333e-01, -1.11540353e-01, 1.46782047e-01, -1.04024832e-01, 6.64976137e-02, 1.41892895e-01, -1.48446123e-02, 6.07560473e-02, 4.97990860e-02, 3.12506554e-02, 6.78822251e-02, -2.00143401e-02, -2.89525768e-02, -4.36697812e-02, -2.16342126e-02, -1.55561494e-02, -1.93100100e-02, -7.21299190e-03, -3.62382637e-02, 1.29884521e-02, -8.01039602e-03, -5.63361078e-02, -3.96849960e-02, 6.17991892e-02, 8.96899129e-02, 1.06592532e-01, 1.17673863e-01, 1.38482602e-01, -1.07327875e-02, -9.60999174e-03, 1.02177603e-02, -1.07043315e-02, -1.07962056e-02, -1.07888138e-02, -8.74362568e-04, -9.60800780e-03, 6.55111569e-03, -6.32391501e-03, -2.01295563e-02, 2.43391877e-02, 2.57865005e-03, 5.49144347e-03, -9.48896266e-03, -9.81620700e-03, 5.93890128e-03, -3.58501263e-02, -5.30665787e-02, -1.12363926e-01, -2.03427651e-02, -9.63313671e-03, 3.25350116e-03, -6.40231842e-03, -1.36474860e-01, -6.86069655e-03], [ -3.82910164e-02, 9.11240924e-02, -8.87064296e-02, 5.13768833e-02, 2.84470532e-02, 1.07418603e-02, 1.72596129e-01, 1.63024838e-01, 1.79123415e-01, -1.76990823e-01, -4.82204251e-02, -3.30034190e-01, -3.30246118e-02, 1.37076568e-01, 1.74246694e-01, -1.10089587e-02, -1.69298085e-01, -8.08900182e-02, -1.43773376e-01, -2.35655770e-02, -5.69173770e-02, -6.63142706e-02, -4.07551888e-02, -2.29228829e-02, -7.90364912e-02, -2.73486749e-02, -6.68901871e-02, -4.04814105e-02, 5.65553506e-02, -6.71239025e-02, -1.01280404e-01, 9.05659040e-02, -6.40389749e-02, 7.12668467e-02, -7.36803823e-02, 6.10658820e-02, -5.88827321e-02, 3.94127519e-02, -5.49029963e-02, 6.11242573e-02, -3.07058258e-02, -4.56110133e-02, 1.53494222e-02, 7.39088301e-02, 8.22265685e-02, 7.51908940e-02, 6.17097662e-02, 4.87145914e-02, 5.39012094e-02, -4.96499663e-02, -8.91463557e-02, -2.20302569e-02, 2.04942038e-01, 2.00221128e-01, 1.88375453e-01, 1.73202885e-01, 3.45394045e-02, 2.35726069e-02, 1.31562200e-02, 3.94934951e-03, 4.29841440e-02, -2.90396671e-02, -1.14567292e-02, 6.58309360e-05, 3.20438551e-02, 2.82690165e-02, 5.63351449e-02, -6.23831557e-02, 2.32490786e-02, -1.05404257e-02, -1.02621061e-02, -4.97477905e-02, -3.74623704e-04, -5.53332653e-02, -1.24386908e-01, -8.89721854e-02, 2.39463513e-01, 1.98648399e-02, -4.03203154e-02, -6.43476955e-02, -6.35568168e-02, -6.11471758e-02, -2.70722373e-02, -4.79785334e-02, -5.92837288e-02, -5.25383590e-02, 1.05665062e-02, -1.88057903e-02, -1.30858194e-01, -3.48237892e-02, -2.44505531e-02, -5.18188485e-02, -8.59608636e-02, -2.39565951e-01, -2.75744629e-01, -1.90021805e-01, -9.94871276e-03, -1.09817239e-02, 9.37189989e-03, -1.19025813e-02, -8.79702175e-03, -7.42482986e-03, 6.13187141e-03, -1.09940138e-02, 1.04227974e-02, 1.07612918e-02, -2.11487603e-02, -4.75475189e-04, 7.89172608e-03, -1.44988803e-02, -7.93857527e-03, 6.78572388e-04, -3.58122923e-03, -1.62357310e-03, -1.20567826e-01, -1.60285456e-01, -7.52920396e-03, -8.76180649e-03, 2.35442476e-03, 2.42475648e-02, -8.58900049e-02, -6.98797479e-03], [ 1.00315934e-01, 1.18336105e-01, 1.60399486e-01, -1.16681291e-01, -3.59641584e-02, -1.67940009e-02, 4.27743425e-02, 5.44337347e-02, 3.65812184e-03, -2.28503122e-01, 1.13981466e-01, 5.39910254e-01, 3.04157859e-02, 2.00729354e-01, -6.17613163e-02, -7.81008944e-02, -1.95996931e-01, -3.23820647e-02, -8.46171791e-02, -1.11540009e-02, -6.23694500e-02, -4.42133851e-02, -3.11427179e-03, 3.78473750e-03, -6.17758693e-02, 2.13563117e-02, -1.46334765e-02, 9.32772585e-02, -4.69838718e-02, -8.64867172e-02, -5.00196208e-02, -5.35460313e-02, -3.41184008e-02, 1.57757308e-01, 1.51185877e-02, -8.90017431e-02, 5.35193261e-03, -4.78040162e-02, 3.21823352e-02, -2.30484500e-02, 4.87392539e-02, 4.17391708e-02, 1.37717579e-01, 1.20432826e-03, -1.32854426e-02, -2.05104622e-03, -1.39278796e-02, 6.31705545e-02, 5.39709056e-02, 7.94376006e-02, 9.64266779e-02, 2.16949224e-02, -4.49652657e-02, -3.49153737e-02, -1.36340320e-02, 3.64299639e-03, -1.20475988e-01, -1.11954711e-01, -1.03129674e-01, -9.26589747e-02, 7.76583174e-02, -6.01912289e-02, 9.24977576e-02, 1.00593539e-01, 1.53343482e-01, 1.52442763e-01, 1.09620767e-01, 5.11965018e-02, 2.46846100e-02, -1.12842069e-01, 1.36257447e-01, 9.67275088e-02, 5.26174271e-02, 4.68407225e-02, 1.21553103e-01, -6.03350137e-02, 1.84330090e-01, -3.60133140e-02, -4.65489713e-02, -1.13426964e-01, -1.25289686e-01, -1.34564973e-01, -1.65083104e-02, -3.78473739e-02, -5.20977229e-02, -2.47045013e-02, -7.54984053e-02, -1.97632310e-02, -6.22415470e-02, 5.03111644e-02, 3.43772573e-02, -1.10049455e-01, 2.30965339e-02, -4.14587493e-02, -1.13722991e-02, -1.79777812e-02, 1.61502638e-02, -9.56405213e-03, -1.49623427e-02, -1.16788749e-02, 2.10841283e-02, -6.31787139e-04, 1.36820120e-02, -9.56713166e-03, -2.04838636e-02, -2.26024472e-02, 4.30154633e-02, -4.05519610e-03, -1.20765397e-02, 2.71771697e-02, 1.19720492e-02, 1.49781495e-02, -1.06359864e-02, 8.42578552e-02, -5.67255976e-02, -3.47616262e-02, 3.58072624e-02, 1.39400088e-02, -1.15767835e-02, 2.54602403e-02, 1.25088670e-01, -1.57024593e-02]])
pca.explained_variance_ratio_
array([ 0.25854019, 0.18166128, 0.07971167, 0.06863376, 0.0447857 ])
pcdf = pca.transform(New_data)
pcdf
array([[ 0.35772934, -0.28927626, -0.55437695, 0.12694531, 0.42805094],[-0.16418724, 0.26989243, -0.95874063, 0.24922094, 0.14474592],[-0.60595542, -0.51332098, 0.07151308, -0.02621491, -0.01678202],..., [-0.58777866, 0.19536295, -0.19990588, -0.85729035, 0.11442621],[ 0.54779527, 0.72318122, -0.35253007, 0.05258148, -0.29110964],[-0.39754717, 2.11859241, 0.69516673, 0.24787927, 0.53698403]])
knn = KNeighborsClassifier(n_neighbors=14)
knn.fit(pcdf,Y)
y_pred = knn.predict(pcdf)
print ('fl score is', f1_score(Y,y_pred,average="binary")*100)
print ('Accuracy is', accuracy_score(Y,y_pred)*100)
print ('Precision is', precision_score(Y,y_pred)*100)
print ('Recall is', recall_score(Y,y_pred)*100)
fl score is 86.8001634655
Accuracy is 83.8014042126
Precision is 88.7959866221
Recall is 84.8920863309
scores = cross_val_score(knn,pcdf,Y,fold,'accuracy',10)
print ('Cross validation accuracy is', np.mean(scores)*100)
scores = cross_val_score(knn,pcdf,Y,fold,'precision',10)
print ('Cross validation precision is', np.mean(scores)*100)
scores = cross_val_score(knn,pcdf,Y,fold,'recall',10)
print ('Cross validation recall is', np.mean(scores)*100)
Cross validation accuracy is 81.4403747594
Cross validation precision is 86.8883347272
Cross validation recall is 82.9726984127
K-nn 是一种将距离作为数据分类最重要因素的分组方法。这与 PCA 降维过程中特定特征的丢失相结合,使得寻找可靠的预测特征变得非常困难。
因此,预测特征的最佳估计值是捕捉数据集中方差百分比最大的特征向量的最大值特征。
ind = np.argpartition(pca.components_[0], -10)[-10:]print('ind is ',ind)
print('10_max_vector_components is ',pca.components_[0][ind])for x in range(0, len(ind)):index=ind[x]print(index)print('vector_component[index] is ',feature_name[index])
ind is [83 81 80 82 44 85 45 19 84 12]
10_max_vector_components is [ 0.16342824 0.16370787 0.16412937 0.16698354 0.16891351 0.166914310.17889273 0.17946299 0.19298567 0.18826765]
83
vector_component[index] is RentMedian
81
vector_component[index] is OwnOccHiQuart
80
vector_component[index] is OwnOccMedVal
82
vector_component[index] is RentLowQ
44
vector_component[index] is PctKids2Par
85
vector_component[index] is MedRent
45
vector_component[index] is PctYoungKids2Par
19
vector_component[index] is medFamInc
84
vector_component[index] is RentHighQ
12
vector_component[index] is medIncome
PCA 和 K-NN 在增加缺失数据特征后,分类效果有所改善。这可能是因为新特征增加了一些方差,而这些方差在维度降低的空间中转化为类别之间更大的距离。
PolynomialSVC
df=pd.read_csv('communities-crime-clean.csv')
df['highCrime'] = np.where(df['ViolentCrimesPerPop']>0.1, 1, 0)
Y = df['highCrime']
fold=df['fold']
from sklearn.svm import SVC
x=[]
y=[]
for k in range (1,5):y.append([])
for i in range (0,4):for j in range (1,5):poly_svc = SVC(C=2**i, kernel='poly', degree=j).fit(initial, Y)scores = cross_val_score(poly_svc,initial,Y,fold,'accuracy',10)y[j-1].append(np.mean(scores))x.append(2**i) plt.plot(x,y[0],'r-',x,y[1],'g-',x,y[2],'b-',x,y[3],'y-')
plt.show()
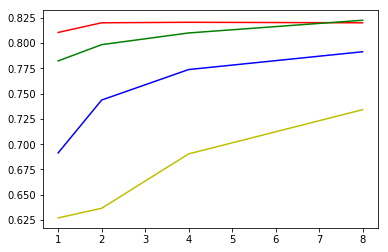
X 轴为误差惩罚 (C) 项
Y 轴为准确度
红色=度数 1
绿色=度数 2
蓝色=度数 3
黄色=度数 4
与线性模型相比,度数 2 的性能最佳。误差惩罚值为 8 时性能最佳。
poly_svc = SVC(C=8, kernel='poly', degree=2).fit(initial, Y)
scores = cross_val_score(poly_svc,initial,Y,fold,'accuracy',10)
print ('Cross validation accuracy is', np.mean(scores)*100)
scores = cross_val_score(poly_svc,initial,Y,fold,'precision',10)
print ('Cross validation precision is', np.mean(scores)*100)
scores = cross_val_score(poly_svc,initial,Y,fold,'recall',10)
print ('Cross validation recall is', np.mean(scores)*100)
Cross validation accuracy is 82.233919598
Cross validation precision is 85.8005724921
Cross validation recall is 86.8
目前还没有合理的方法来评估多项式 SVC 的大多数预测特征。
在该数据集上,与线性 SVC 相比,2 级多项式 SVC 的分类效果略优于线性 SVC。
df=pd.read_csv('communities-crime-full.csv')
df['highCrime'] = np.where(df['ViolentCrimesPerPop']>0.1, 1, 0)
Y = df['highCrime']
fold=df['fold']
x=[]
y=[]
for k in range (1,5):y.append([])
for i in range (0,4):for j in range (1,5):poly_svc = SVC(C=2**i, kernel='poly', degree=j).fit(New_data, Y)scores = cross_val_score(poly_svc,New_data,Y,fold,'accuracy',10)y[j-1].append(np.mean(scores))x.append(2**i) plt.plot(x,y[0],'r-',x,y[1],'g-',x,y[2],'b-',x,y[3],'y-')
plt.show()
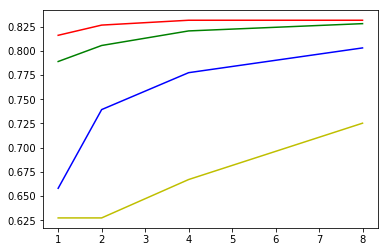
-
X 轴为误差惩罚 (C) 项
-
Y 轴为准确度
-
红色=度数 1
-
绿色=度数 2
-
蓝色=度数 3
-
黄色=度数 4
-
与线性模型相比,度数 2 的性能最佳。误差惩罚值为 4 时,在收益明显递减之前性能最佳。
poly_svc = SVC(C=4, kernel='poly', degree=2).fit(New_data, Y)
scores = cross_val_score(poly_svc,New_data,Y,fold,'accuracy',10)
print ('Cross validation accuracy is', np.mean(scores)*100)
scores = cross_val_score(poly_svc,New_data,Y,fold,'precision',10)
print ('Cross validation precision is', np.mean(scores)*100)
scores = cross_val_score(poly_svc,New_data,Y,fold,'recall',10)
print ('Cross validation recall is', np.mean(scores)*100)
Cross validation accuracy is 82.045641141
Cross validation precision is 84.1192072837
Cross validation recall is 88.0888888889
使用多项式 SVC 评估大多数预测特征并没有合理的方法。
多项式 SVC 对于脏数据集中的缺失数据有相当大的适应能力,准确度和精确度损失很小,召回率却有所提高。不过,绘图结果表明,线性 SVC 在脏数据上的表现可能会优于多项式 SVC。
新阈值
df=pd.read_csv('communities-crime-clean.csv')
# df.describe()
df['ViolentCrimesPerPop'].plot.hist()
print('average is ',np.average(df['ViolentCrimesPerPop']))
Q1, median, Q3 = np.percentile(df['ViolentCrimesPerPop'], [25, 50, 75])
print("Q1(25%) is ",Q1)
print("median is ",median)
print("Q3(75%) is ",Q3)
print("average between Q3 and Q1 is ",(Q3+Q1)/2)
plt.show()
plt.boxplot(df['ViolentCrimesPerPop'])
plt.show()
average is 0.237982940291
Q1(25%) is 0.07
median is 0.15
Q3(75%) is 0.33
average between Q3 and Q1 is 0.2
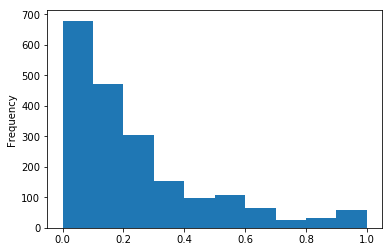
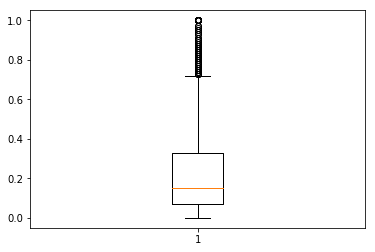
根据直方图和方框图,我们可以了解 “每人口暴力犯罪 ”在数据集中的分布情况。在数据集的第二部分有很多离群值,所以均值(0.2379)不适合作为阈值。 然后,根据四分位偏差法得出 Q1、中位数和 Q3,中位数与 Q1 和 Q3 之间的平均值不同。由于从 Q1 到 Q3 的距离已经消除了离群值的问题,Q1 和 Q3 之间的平均值比中位数更适合作为新的临界值。因此,0.2(Q1 和 Q3 之间的平均值)是最有用的阈值。
决策树的新阈值
df=pd.read_csv('communities-crime-full.csv')
df
df['highCrime'] = np.where(df['ViolentCrimesPerPop']>0.2, 1, 0)
Y = df['highCrime']
clf = tree.DecisionTreeClassifier(max_depth=3)
# clf = tree.DecisionTreeClassifier()
clf = clf.fit(New_data, Y)
clf
fold=df['fold']
scores = cross_val_score(clf, New_data, Y,fold,'accuracy',10)
print('cross_val_accuracy is ',scores) print ('Cross validation accuracy is', np.mean(scores)*100)
scores = cross_val_score(clf,New_data,Y,fold,'precision',10)
print ('Cross validation precision is', np.mean(scores)*100)
scores = cross_val_score(clf,New_data,Y,fold,'recall',10)
print ('Cross validation recall is', np.mean(scores)*100)cross_val_accuracy is [ 0.785 0.805 0.775 0.785 0.805 0.820.79396985 0.84422111 0.85353535 0.79292929]
Cross validation accuracy is 80.5965560124
Cross validation precision is 76.8498938447
Cross validation recall is 74.6975308642
import matplotlib.pyplot as plt
y=[]
x=[]
for i in range (1,16):clf = tree.DecisionTreeClassifier(max_depth=i)clf = clf.fit(New_data, Y)y_pred = clf.predict(New_data)scores = cross_val_score(clf, New_data, Y,None,'accuracy',cv=10,n_jobs = -1)y.append(np.array(scores).mean())x.append(i)plt.plot(x, y)plt.show()
print('y is ',y)
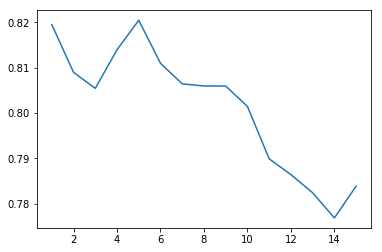
y is [0.8195286533678493, 0.80898319882239478, 0.80546556012385173, 0.81397558499568556, 0.8204881731891781, 0.81099578701588748, 0.80645287041266944, 0.80598063550073606, 0.8059654586061622, 0.80146045885995643, 0.78990500482209025, 0.78642013095781949, 0.78241013146540794, 0.77686970204558148, 0.78388728998528001]
classname=['High','Low']
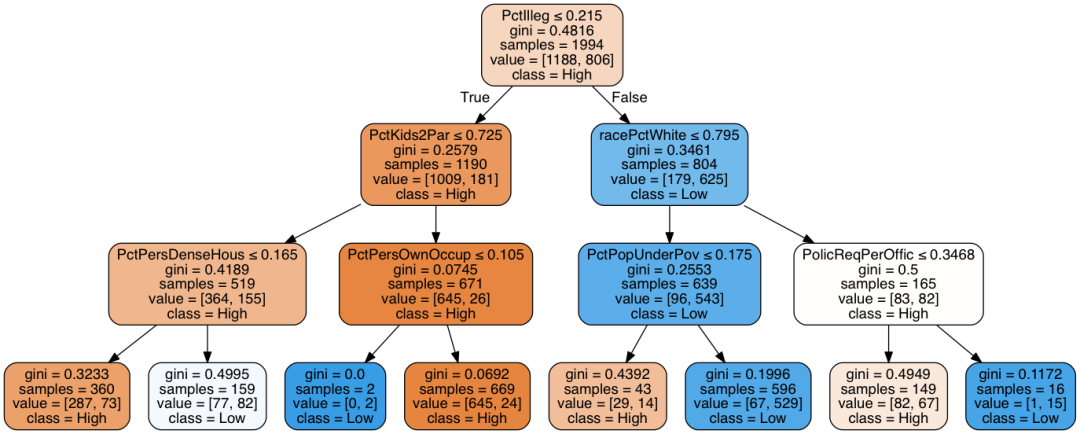
clf = tree.DecisionTreeClassifier(max_depth=3)clf = clf.fit(New_data, Y)
dot_data = tree.export_graphviz(clf, out_file=None, feature_names=list(New_data), class_names=classname, filled=True, rounded=True, special_characters=True)
graph = pydotplus.graph_from_dot_data(dot_data)
Image(graph.create_png())
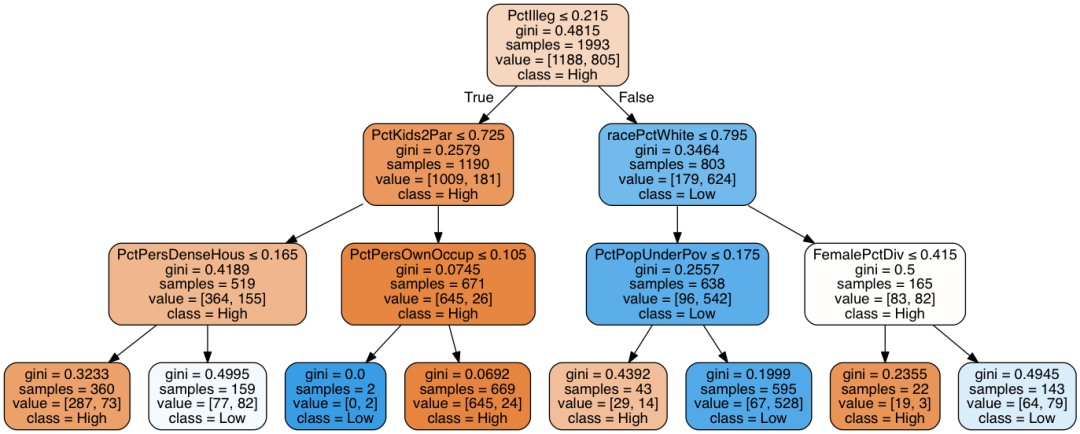
df=pd.read_csv('communities-crime-clean.csv')
df
df['highCrime'] = np.where(df['ViolentCrimesPerPop']>0.2, 1, 0)
Y = df['highCrime']clf = tree.DecisionTreeClassifier(max_depth=3)clf = clf.fit(initial, Y)
clf
import pydotplus
from IPython.display import Image
classname=['High','Low']
dot_data = tree.export_graphviz(clf, out_file=None, feature_names=list(initial), class_names=classname, filled=True, rounded=True, special_characters=True)
graph = pydotplus.graph_from_dot_data(dot_data)
Image(graph.create_png())
fold=df['fold']
scores = cross_val_score(clf, initial, Y,fold,'accuracy',10)
print('cross_val_accuracy is ',scores) print ('Cross validation accuracy is', np.mean(scores)*100)
scores = cross_val_score(clf,initial,Y,fold,'precision',10)
print ('Cross validation precision is', np.mean(scores)*100)
scores = cross_val_score(clf,initial,Y,fold,'recall',10)
print ('Cross validation recall is', np.mean(scores)*100)# y_pred = clf.predict(initial)
# print ('Accuracy is', accuracy_score(Y,y_pred)*100)
# from sklearn.metrics import precision_score
# print ('Precesion is', precision_score(Y,y_pred)*100)
# from sklearn.metrics import recall_score
# print ('Recall is', recall_score(Y,y_pred)*100)
cross_val_accuracy is [ 0.745 0.815 0.78 0.805 0.855 0.728643220.8040201 0.85929648 0.65151515 0.77777778]
Cross validation accuracy is 78.2125272829
Cross validation precision is 76.6395399224
Cross validation recall is 70.549382716
y=[]
x=[]for i in range (1,16):clf = tree.DecisionTreeClassifier(max_depth=i)clf = clf.fit(initial, Y)y_pred = clf.predict(initial)scores = cross_val_score(clf, initial, Y,None,'accuracy',cv=10)y.append(np.array(scores).mean())x.append(i)plt.plot(x, y)plt.show()
print('y is ',y)
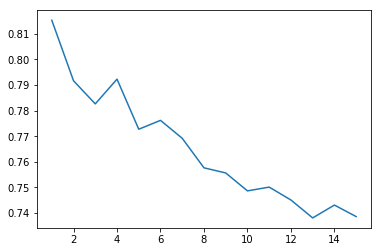
y is [0.81532196335211415, 0.79165542358255925, 0.78263032333384097, 0.79229937566620989, 0.77271871986193597, 0.77619095477386935, 0.76916585452515096, 0.75763555149484796, 0.75563060250748693, 0.7486205014973859, 0.75009781229379224, 0.7450524846454496, 0.7380525607837165, 0.74307017410283749, 0.73857266128622912]
使用新阈值后,单个特征 PctIlleg 对数据集的预测性变得很高,但其他可能的分割特征却失去了线性分割的效果。因此,使用新阈值后,最有效的决策树深度为 1。在此数据集上使用决策树,似乎可以大大受益于采用更明智的方法来决定阈值。
Naive Bayes 高斯算法的新阈值
gnb = GaussianNB()
y_pred = gnb.fit(initial, Y).predict(initial)print("mislabel num is ",(Y != y_pred).sum())# print ('sigma is ',gnb.sigma_)
variance=gnb.sigma_
stand_deviation =np.sqrt( variance)
# print('standard deviation is',stand_deviation);
sum_standard=stand_deviation[0]+stand_deviation[1]
# print('sum of standard deviation is',sum_standard);# print ('theta is ',gnb.theta_)
mean=gnb.theta_
difference=mean[0]-mean[1]
# print('difference is ',abs(difference))
normalized_feature=abs(difference)/sum_standard
print('normalized_feature is ',normalized_feature)ind = np.argpartition(normalized_feature, -10)[-10:]print('ind is ',ind)
print('10_max_normalized_feature is ',normalized_feature[ind])for x in range(0, len(ind)):index=ind[x]print(index)print('feature_name[index] is ',feature_name[index])from sklearn.model_selection import cross_val_score
fold=df['fold']
scores = cross_val_score(gnb, initial, Y,fold,'accuracy',10)
print('cross_val_accuracy is ',np.mean(scores)*100)
scores = cross_val_score(gnb, initial, Y,fold,'precision',10)
print('cross_val_precision is ',np.mean(scores)*100)
scores = cross_val_score(gnb, initial, Y,fold,'recall',10)
print('cross_val_recall is ',np.mean(scores)*100)
mislabel num is 352
normalized_feature is [ 0.33306076 0.03258098 0.57607554 0.72301674 0.04198184 0.359789370.05081276 0.1491096 0.09012258 0.07690147 0.31722709 0.021025570.50499798 0.32275839 0.10399085 0.68789992 0.12525604 0.637700180.08482528 0.52115517 0.39921489 0.24898057 0.33249932 0.119589450.18131628 0.1593845 0.29721696 0.4271772 0.57247427 0.468734160.53762178 0.35764455 0.53696231 0.35122208 0.02515546 0.102577240.31749042 0.37536845 0.57546639 0.2216214 0.65369163 0.634668320.12098212 0.77237886 0.84288241 0.71696935 0.66301396 0.040486040.17378054 0.41761193 0.78896678 0.26418494 0.1721343 0.221365470.25550443 0.30076635 0.22549075 0.24285105 0.24483414 0.253578010.26564133 0.32422931 0.37334747 0.29009904 0.029548 0.139658550.28580806 0.58538383 0.50490824 0.52004923 0.37863295 0.382785320.32275872 0.49473664 0.41475204 0.00776573 0.07533747 0.548948920.33590694 0.22200447 0.19982129 0.17949289 0.26929275 0.266070020.25915258 0.27192261 0.31631812 0.06354522 0.00477544 0.30586930.28550505 0.18870544 0.07895563 0.20978568 0.03719001 0.038332810.17172126 0.20808489 0.05305622 0.32220227]
ind is [41 17 40 46 15 45 50 3 43 44]
10_max_normalized_feature is [ 0.63466832 0.63770018 0.65369163 0.66301396 0.68789992 0.716969350.78896678 0.72301674 0.77237886 0.84288241]
41
feature_name[index] is TotalPctDiv
17
feature_name[index] is pctWPubAsst
40
feature_name[index] is FemalePctDiv
46
feature_name[index] is PctTeen2Par
15
feature_name[index] is pctWInvInc
45
feature_name[index] is PctYoungKids2Par
50
feature_name[index] is PctIlleg
3
feature_name[index] is racePctWhite
43
feature_name[index] is PctFam2Par
44
feature_name[index] is PctKids2Par
cross_val_accuracy is 80.023638394
cross_val_precision is 78.6578155819
cross_val_recall is 71.049382716
对于 Naive Bayes 而言,相对于负类的性能有所提高,但相对于正类的性能在新阈值下有所下降。最具预测性的特征 PctIlleg 保持不变。这是因为阈值的变化相对较小,这意味着真类和假类的分布变化很小。
df=pd.read_csv('communities-crime-full.csv')
df
df['highCrime'] = np.where(df['ViolentCrimesPerPop']>0.2, 1, 0)
Y = df['highCrime']
gnb = GaussianNB()
y_pred = gnb.fit(New_data, Y).predict(New_data)print("mislabel num is ",(Y != y_pred).sum())# print ('sigma is ',gnb.sigma_)
variance=gnb.sigma_
stand_deviation =np.sqrt( variance)
# print('standard deviation is',stand_deviation);
sum_standard=stand_deviation[0]+stand_deviation[1]
# print('sum of standard deviation is',sum_standard);# print ('theta is ',gnb.theta_)
mean=gnb.theta_
difference=mean[0]-mean[1]
# print('difference is ',abs(difference))
normalized_feature=abs(difference)/sum_standard
print('normalized_feature is ',normalized_feature)ind = np.argpartition(normalized_feature, -10)[-10:]print('ind is ',ind)
print('10_max_normalized_feature is ',normalized_feature[ind])for x in range(0, len(ind)):index=ind[x]print(index)print('feature_name[index] is ',feature_name[index])fold=df['fold']
scores = cross_val_score(gnb, New_data, Y,fold,'accuracy',10)
print('cross_val_accuracy is ',np.mean(scores)*100)
scores = cross_val_score(gnb, New_data, Y,fold,'precision',10)
print('cross_val_precision is ',np.mean(scores)*100)
scores = cross_val_score(gnb, New_data, Y,fold,'recall',10)
print('cross_val_recall is ',np.mean(scores)*100)
上下滑动查看更多源码
mislabel num is 433
normalized_feature is [ 0.33274269 0.03287805 0.57704633 0.72386798 0.04153745 0.359209580.05085409 0.14858366 0.08981515 0.07740031 0.31675301 0.02003120.5055121 0.32354202 0.10375662 0.68832887 0.12581775 0.638500660.08474548 0.52167001 0.39959873 0.24903205 0.33286641 0.120011920.18105687 0.15930465 0.29580373 0.42703688 0.57319478 0.469219760.53793289 0.35770605 0.53779681 0.35200369 0.02540681 0.10219820.31726384 0.37483834 0.57581793 0.22154289 0.65395151 0.634993710.1209443 0.77307217 0.84355664 0.7176549 0.66376979 0.0401360.1738027 0.41755548 0.78979398 0.26386201 0.17174017 0.220539710.25428553 0.29914528 0.22489731 0.2422117 0.24418607 0.252924520.26491873 0.32366511 0.37324073 0.28994221 0.02975956 0.140110860.28591501 0.58523484 0.50463683 0.51953768 0.37782316 0.382535580.3232456 0.49444454 0.41492867 0.00694628 0.07560749 0.549400920.3366176 0.2224585 0.20026634 0.1799043 0.27004056 0.266781220.25976563 0.2725392 0.31659364 0.06348605 0.0036156 0.305574080.28526692 0.18802784 0.07818792 0.20897814 0.03780238 0.037938010.08299957 0.00568712 0.07997473 0.00846305 0.08778019 0.05947480.05154299 0.00572539 0.09659065 0.12639754 0.13300739 0.083319620.01847506 0.14980505 0.0849018 0.02588542 0.03252549 0.171515790.20762746 0.05273112 0.1076328 0.08065815 0.02012642 0.040798090.32180019 0.0090319 ]
ind is [41 17 45 46 50 15 3 44 40 43]
10_max_normalized_feature is [ 0.63499371 0.63850066 0.7176549 0.66376979 0.78979398 0.688328870.72386798 0.84355664 0.65395151 0.77307217]
41
feature_name[index] is TotalPctDiv
17
feature_name[index] is pctWPubAsst
45
feature_name[index] is PctYoungKids2Par
46
feature_name[index] is PctTeen2Par
50
feature_name[index] is PctIlleg
15
feature_name[index] is pctWInvInc
3
feature_name[index] is racePctWhite
44
feature_name[index] is PctKids2Par
40
feature_name[index] is FemalePctDiv
43
feature_name[index] is PctFam2Par
cross_val_accuracy is 77.9804197756
cross_val_precision is 80.3603495074
cross_val_recall is 60.1635802469
1
与干净的数据集相比,Naive Bayes 的表现相当糟糕,这可能是因为缺失数据的替换使得两个类别的方差和均值更加接近。
LinearSVC中的新阈值
df=pd.read_csv('communities-crime-clean.csv')
df['highCrime'] = np.where(df['ViolentCrimesPerPop']>0.2, 1, 0)
Y = df['highCrime']
lin_svc = svm.LinearSVC(C=0.014, penalty="l1", dual=False).fit(initial, Y)
# using L1-norm (sparsity method) to make unless feature weight become 0 , C value increase->more complex model having more weight
feature_weight=abs(lin_svc.coef_[0])
for i in range(0,len(feature_weight)):if(feature_weight[i]!=0):print('select_feature_is ',feature_name[i],' feature_weight_is ',feature_weight[i])from sklearn.model_selection import cross_val_score
fold=df['fold']
scores = cross_val_score(lin_svc, initial, Y,fold,'accuracy',10)
print('cross_val_accuracy is ',scores,' average ',np.mean(scores)*100)
scores = cross_val_score(lin_svc, initial, Y,fold,'precision',10)
print('cross_val_precision is ',scores,' average ',np.mean(scores)*100)
scores = cross_val_score(lin_svc, initial, Y,fold,'recall',10)
print('cross_val_recall is ',scores,' average ',np.mean(scores)*100)
select_feature_is racePctWhite feature_weight_is 0.614112356594
select_feature_is racePctHisp feature_weight_is 0.153482138736
select_feature_is pctUrban feature_weight_is 0.00344247204978
select_feature_is pctWPubAsst feature_weight_is 0.188160299684
select_feature_is TotalPctDiv feature_weight_is 0.6944110073
select_feature_is PctKids2Par feature_weight_is 0.603895961438
select_feature_is PctIlleg feature_weight_is 0.911383833717
select_feature_is PctPersDenseHous feature_weight_is 0.227670704675
select_feature_is PctHousOccup feature_weight_is 0.0926189601815
select_feature_is PctHousNoPhone feature_weight_is 0.062885686857
select_feature_is LemasSwFTFieldPerPop feature_weight_is 0.153428115968
cross_val_accuracy is [ 0.785 0.845 0.8 0.815 0.85 0.728643220.84924623 0.84422111 0.77272727 0.84343434] average 81.3327216893
cross_val_precision is [ 0.7375 0.94642857 0.83606557 0.89285714 0.9047619 0.740740740.8125 0.90163934 0.72151899 0.88888889] average 83.8290115405
cross_val_recall is [ 0.72839506 0.65432099 0.62962963 0.61728395 0.7037037 0.5 0.81250.6875 0.7125 0.7 ] average 67.4583333333
对于 LinearSVC 而言,与同一模型相比,其性能下降了。该模型似乎并没有从我们确定相关阈值的方法中受益。有趣的是,它与采用新阈值的决策树具有相同的最具预测性的特征。
df=pd.read_csv('communities-crime-full.csv')
df['highCrime'] = np.where(df['ViolentCrimesPerPop']>0.2, 1, 0)
Y = df['highCrime']
fold=df['fold']
feature_name=list(New_data)
lin_svc = svm.LinearSVC(C=0.014, penalty="l1", dual=False).fit(New_data, Y)
# using L1-norm (sparsity method) to make unless feature weight become 0 , C value increase->more complex model having more weight
feature_weight=abs(lin_svc.coef_[0])
for i in range(0,len(feature_weight)):if(feature_weight[i]!=0):print('select_feature_is ',feature_name[i],' feature_weight_is ',feature_weight[i])from sklearn.model_selection import cross_val_score
fold=df['fold']
scores = cross_val_score(lin_svc, New_data, Y,fold,'accuracy',10)
print('cross_val_accuracy is ',scores,' average ',np.mean(scores)*100)
scores = cross_val_score(lin_svc, New_data, Y,fold,'precision',10)
print('cross_val_precision is ',scores,' average ',np.mean(scores)*100)
scores = cross_val_score(lin_svc, New_data, Y,fold,'recall',10)
print('cross_val_recall is ',scores,' average ',np.mean(scores)*100)
select_feature_is racePctWhite feature_weight_is 0.616754261271
select_feature_is racePctHisp feature_weight_is 0.1539511259
select_feature_is pctUrban feature_weight_is 0.00335099672919
select_feature_is pctWPubAsst feature_weight_is 0.189393357691
select_feature_is TotalPctDiv feature_weight_is 0.695595603405
select_feature_is PctKids2Par feature_weight_is 0.600583877083
select_feature_is PctIlleg feature_weight_is 0.911209269573
select_feature_is PctPersDenseHous feature_weight_is 0.225560742182
select_feature_is PctHousOccup feature_weight_is 0.093368705894
select_feature_is PctHousNoPhone feature_weight_is 0.0626665123771
select_feature_is LemasPctOfficDrugUn feature_weight_is 0.153443795657
cross_val_accuracy is [ 0.79 0.8 0.845 0.805 0.835 0.8050.84422111 0.81909548 0.87373737 0.84848485] average 82.6553880514
cross_val_precision is [ 0.83050847 0.78873239 0.82894737 0.78378378 0.9 0.838709680.87692308 0.82352941 0.91044776 0.85714286] average 84.3872480559
cross_val_recall is [ 0.60493827 0.69135802 0.77777778 0.71604938 0.66666667 0.641975310.7125 0.7 0.7625 0.75 ] average 70.237654321
在新阈值上,与干净数据集相比,最具预测性的特征保持不变,但缺失数据特征的额外维度似乎提高了准确度、精确度和召回率,但仍比干净数据上的原始阈值线性 SVM 差。
决策森林
决策森林使用随机森林算法。节点从随机特征子集和这些特征的一组随机阈值的最佳分割中选出。
from sklearn.ensemble import RandomForestClassifier
df=pd.read_csv('communities-crime-clean.csv')
df['highCrime'] = np.where(df['ViolentCrimesPerPop']>0.1, 1, 0)
initial=pd.read_csv('communities-crime-clean.csv')
initial = initial.drop('communityname', 1)
initial = initial.drop('ViolentCrimesPerPop', 1)
initial = initial.drop('fold', 1)initial = initial.drop('state', 1)
fold=df['fold']
Y = df['highCrime']
feature_name=list(initial)
clf = RandomForestClassifier(n_estimators=10,max_features='sqrt')
clf = clf.fit(initial, Y)
# dot_data = tree.export_graphviz(clf, out_file=None,
# feature_names=list(initial),
# class_names='highCrime',
# filled=True, rounded=True,
# special_characters=True)
# graph = pydotplus.graph_from_dot_data(dot_data)
# Image(graph.create_png())
y_pred = clf.predict(initial)
feature_importance=clf.feature_importances_
print("feature importance is ",feature_importance)
print ("length feature array",len(feature_importance))
for i in range (0,len(feature_importance)):if(feature_importance[i]!=0):print("index is ",feature_name[i])index_max = np.argmax(feature_importance)
print(index_max)print('coefficient[max] is ',feature_name[index_max])
上下滑动查看更多源码
feature importance is [ 0.00336806 0.00491396 0.01238699 0.02674893 0.00337491 0.038566910.00411972 0.00708183 0.00461754 0.01074888 0.00613592 0.001829330.00391672 0.00487733 0.00895112 0.01952189 0.00575116 0.006893670.01018738 0.00493616 0.00399692 0.00752718 0.00687497 0.003272740.00300188 0.00897779 0.00695895 0.00631996 0.03405884 0.006978790.00582739 0.0034084 0.0051311 0.00874668 0.00857364 0.005213630.00789191 0.00516418 0.01413912 0.00680554 0.05179789 0.012486770.00464176 0.0675767 0.08668071 0.00851479 0.01116792 0.00522530.00600332 0.04634655 0.04988121 0.00653971 0.00756071 0.006311570.00652946 0.00713335 0.00649662 0.0033839 0.00204338 0.005184340.00422714 0.00463978 0.01008159 0.00662434 0.00318486 0.00418690.00566659 0.00509673 0.03738034 0.00717 0.0006355 0.007956240.00481612 0.02132551 0.00519539 0.00320467 0.00574201 0.006071250.01026423 0.00285569 0.00521735 0.00312597 0.00523414 0.005480820.00468501 0.00338149 0.00577543 0.00722884 0.00740814 0.001874280.00058616 0.00541836 0.00692136 0.00458545 0.00679113 0.005992760.0030062 0.00609317 0.00465275 0.00091233]
length feature array 100
index is population
index is householdsize
index is racepctblack
index is racePctWhite
index is racePctAsian
index is racePctHisp
index is agePct12t21
index is agePct12t29
index is agePct16t24
index is agePct65up
index is numbUrban
index is pctUrban
index is medIncome
index is pctWWage
index is pctWFarmSelf
index is pctWInvInc
index is pctWSocSec
index is pctWPubAsst
index is pctWRetire
index is medFamInc
index is perCapInc
index is whitePerCap
index is blackPerCap
index is indianPerCap
index is AsianPerCap
index is OtherPerCap
index is HispPerCap
index is NumUnderPov
index is PctPopUnderPov
index is PctLess9thGrade
index is PctNotHSGrad
index is PctBSorMore
index is PctUnemployed
index is PctEmploy
index is PctEmplManu
index is PctEmplProfServ
index is PctOccupManu
index is PctOccupMgmtProf
index is MalePctDivorce
index is MalePctNevMarr
index is FemalePctDiv
index is TotalPctDiv
index is PersPerFam
index is PctFam2Par
index is PctKids2Par
index is PctYoungKids2Par
index is PctTeen2Par
index is PctWorkMomYoungKids
index is PctWorkMom
index is NumIlleg
index is PctIlleg
index is NumImmig
index is PctImmigRecent
index is PctImmigRec5
index is PctImmigRec8
index is PctImmigRec10
index is PctRecentImmig
index is PctRecImmig5
index is PctRecImmig8
index is PctRecImmig10
index is PctSpeakEnglOnly
index is PctNotSpeakEnglWell
index is PctLargHouseFam
index is PctLargHouseOccup
index is PersPerOccupHous
index is PersPerOwnOccHous
index is PersPerRentOccHous
index is PctPersOwnOccup
index is PctPersDenseHous
index is PctHousLess3BR
index is MedNumBR
index is HousVacant
index is PctHousOccup
index is PctHousOwnOcc
index is PctVacantBoarded
index is PctVacMore6Mos
index is MedYrHousBuilt
index is PctHousNoPhone
index is PctWOFullPlumb
index is OwnOccLowQuart
index is OwnOccMedVal
index is OwnOccHiQuart
index is RentLowQ
index is RentMedian
index is RentHighQ
index is MedRent
index is MedRentPctHousInc
index is MedOwnCostPctInc
index is MedOwnCostPctIncNoMtg
index is NumInShelters
index is NumStreet
index is PctForeignBorn
index is PctBornSameState
index is PctSameHouse85
index is PctSameCity85
index is PctSameState85
index is LandArea
index is PopDens
index is PctUsePubTrans
index is LemasPctOfficDrugUn
44
coefficient[max] is PctKids2Par
1
print ('fl score is', f1_score(Y,y_pred,average="binary")*100)
print ('Accuracy is', accuracy_score(Y,y_pred)*100)
print ('Precesion is', precision_score(Y,y_pred)*100)
print ('Recall is', recall_score(Y,y_pred)*100)
fl score is 99.316994777
Accuracy is 99.1470145509
Precesion is 99.7578692494
Recall is 98.88
scores = cross_val_score(clf,initial,Y,fold,'accuracy',10)
print ('Cross validation accuracy is', np.mean(scores)*100)
scores = cross_val_score(clf,initial,Y,fold,'precision',10)
print ('Cross validation precision is', np.mean(scores)*100)
scores = cross_val_score(clf,initial,Y,fold,'recall',10)
print ('Cross validation recall is', np.mean(scores)*100)
Cross validation accuracy is 78.8198492462
Cross validation precision is 87.0202118052
Cross validation recall is 80.72
其性能与标准决策树相对一致。最具预测性的特征与决策树相同,即 PctKids2Par。随机决策森林似乎并没有因为模型复杂度的增加而带来多少好处。