python学习打卡day33
DAY 33 简单的神经网络
知识点回顾:
- PyTorch和cuda的安装
- 查看显卡信息的命令行命令(cmd中使用)
- cuda的检查
- 简单神经网络的流程
- 数据预处理(归一化、转换成张量)
- 模型的定义
- 继承nn.Module类
- 定义每一个层
- 定义前向传播流程
- 定义损失函数和优化器
- 定义训练流程
- 可视化loss过程
预处理补充:
注意事项:
1. 分类任务中,若标签是整数(如 0/1/2 类别),需转为long类型(对应 PyTorch 的torch.long),否则交叉熵损失函数会报错。
2. 回归任务中,标签需转为float类型(如torch.float32)。
作业:今日的代码,要做到能够手敲。这已经是最简单最基础的版本了。
import pandas as pd
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import MinMaxScaler
import torch
import torch.nn as nn
import torch.optim as optim
import matplotlib.pyplot as plt
iris=load_iris()
X=iris.data
y=iris.target
X_train,X_test,y_train,y_test=train_test_split(X,y,test_size=0.2,random_state=42)
scaler=MinMaxScaler()
X_train=scaler.fit_transform(X_train)
X_test=scaler.transform(X_test)
X_train=torch.FloatTensor(X_train)
X_test=torch.FloatTensor(X_test)
y_train=torch.LongTensor(y_train)
y_test=torch.LongTensor(y_test)class MLP(nn.Module):def __init__(self):super(MLP,self).__init__()self.fc1=nn.Linear(4,10)self.relu=nn.ReLU()self.fc2=nn.Linear(10,3)def forward(self,x):out=self.fc1(x)out=self.relu(out)out=self.fc2(out)return out
model=MLP()criterion=nn.CrossEntropyLoss()
optimizer=optim.Adam(model.parameters(),lr=0.01)num_epochs=20000
losses=[]
for epoch in range(num_epochs):outputs=model.forward(X_train)loss=criterion(outputs,y_train)optimizer.zero_grad()loss.backward()optimizer.step()losses.append(loss.item())if(epoch+1)%100==0:print(f'Epoch[{epoch+1}/{num_epochs}],loss:{loss.item():.4f}')plt.plot(range(num_epochs), losses)#()内对应的是X轴和Y轴的数据
plt.ylabel('Loss')
plt.title('Training Loss over Epochs')
plt.show()
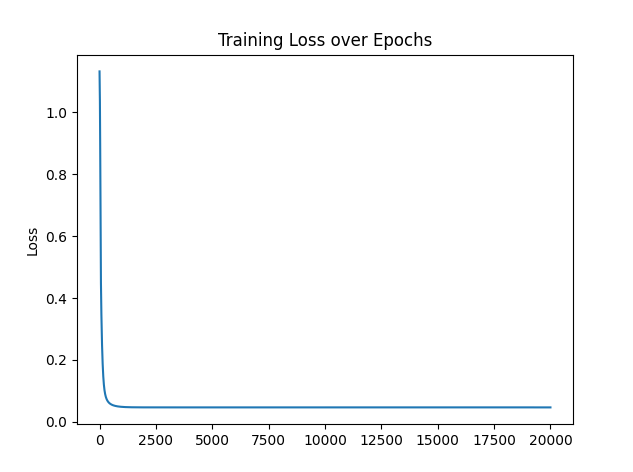
使用Adam优化器不到2000轮就收敛了,且损失要比SGD小
@浙大疏锦行