在 Ubuntu 24.04 LTS 上 Docker 部署 DB-GPT
一、DB-GPT 简介
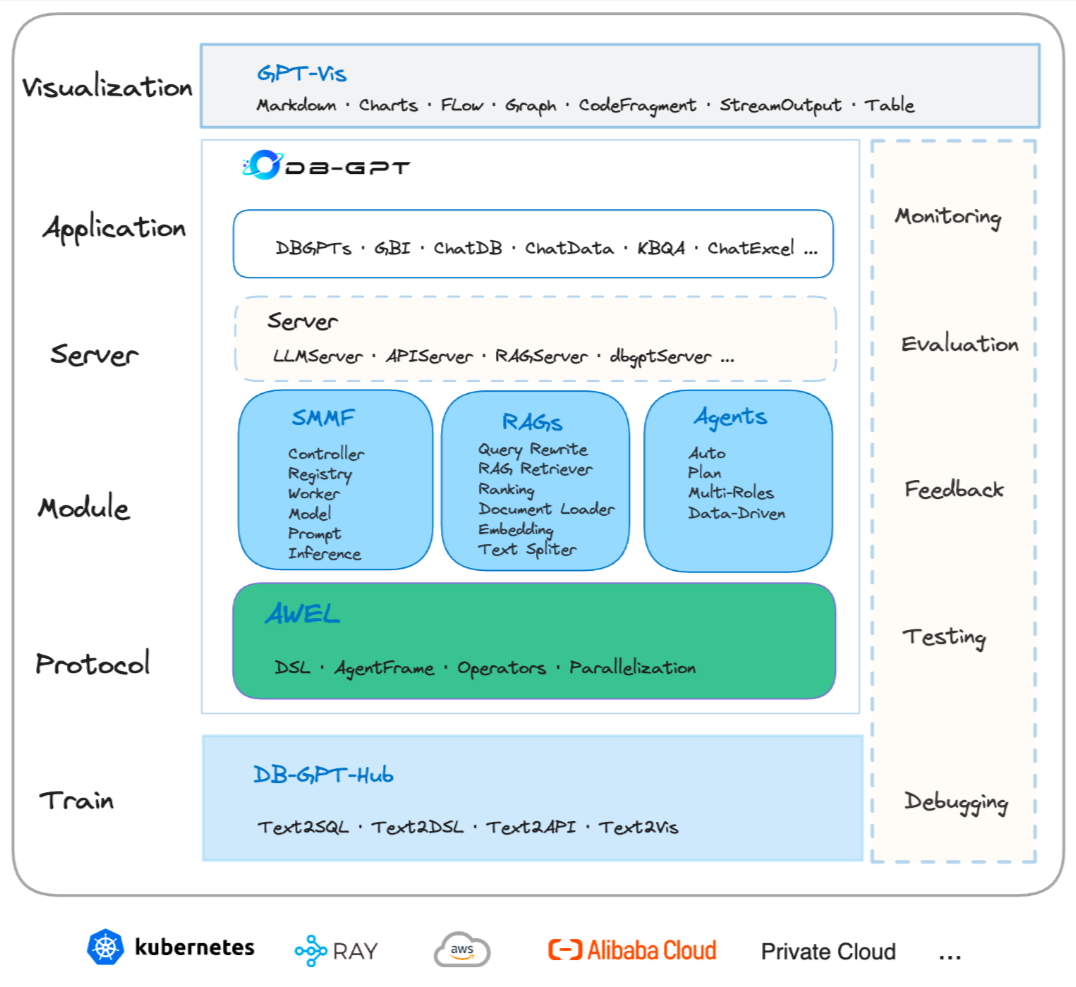
DB-GPT 是一个开源的AI原生数据应用开发框架(AI Native Data App Development framework with AWEL(Agentic Workflow Expression Language) and Agents)。目的是构建大模型领域的基础设施,通过开发多模型管理(SMMF)、Text2SQL效果优化、RAG框架以及优化、Multi-Agents 框架协作、AWEL (智能体工作流编排)等多种技术能力,让围绕数据库构建大模型应用更简单,更方便。
数据3.0 时代,基于模型、数据库,企业/开发者可以用更少的代码搭建自己的专属应用。
官方英文文档地址:http://docs.dbgpt.cn/docs/overview/
官方中文文档地址:https://www.yuque.com/eosphoros/dbgpt-docs/bex30nsv60ru0fmx
官网快速部署地址:http://docs.dbgpt.cn/docs/next/installation/docker/
官网开源仓库地址:https://github.com/eosphoros-ai/DB-GPT
截至目前,最新的版本:v0.7.1
二、DB-GPT 安装
首先,登录 Ubuntu 24.04 LTS 系统终端;在安装 DB-GPT 的目录下进行代码下载:
git clone https://github.com/eosphoros-ai/DB-GPT.git代码下载好之后,可以进行安装部署。目前有源码安装(最新版本不再支持 pip,而是采用 uv)、docker 安装 、docker compose 安装 等主流安装方式。
2.1 Docker 快速安装
# 拉取 dbgpt-openai 最新镜像
docker pull eosphorosai/dbgpt-openai:latest
# ${SILICONFLOW_API_KEY} 替换成 硅基流动 的大模型调用 API 密钥
docker run -it --rm -e SILICONFLOW_API_KEY=${SILICONFLOW_API_KEY} -p 5670:5670 --name dbgpt eosphorosai/dbgpt-openai
# 访问地址 http://localhost:5670 验证是否安装正常可用
2.2 Docker Compose 安装
# 进行下载好的 DB-GPT 仓库的根目录
cd ~/MyDB-GPT/DB-GPT/# 维护${SILICONFLOW_API_KEY} 硅基流动的大模型调用 API 密钥;${SILICONFLOW_API_KEY}替换成你自己的 API 密钥,不要把下面傻傻的一字不差抄上去
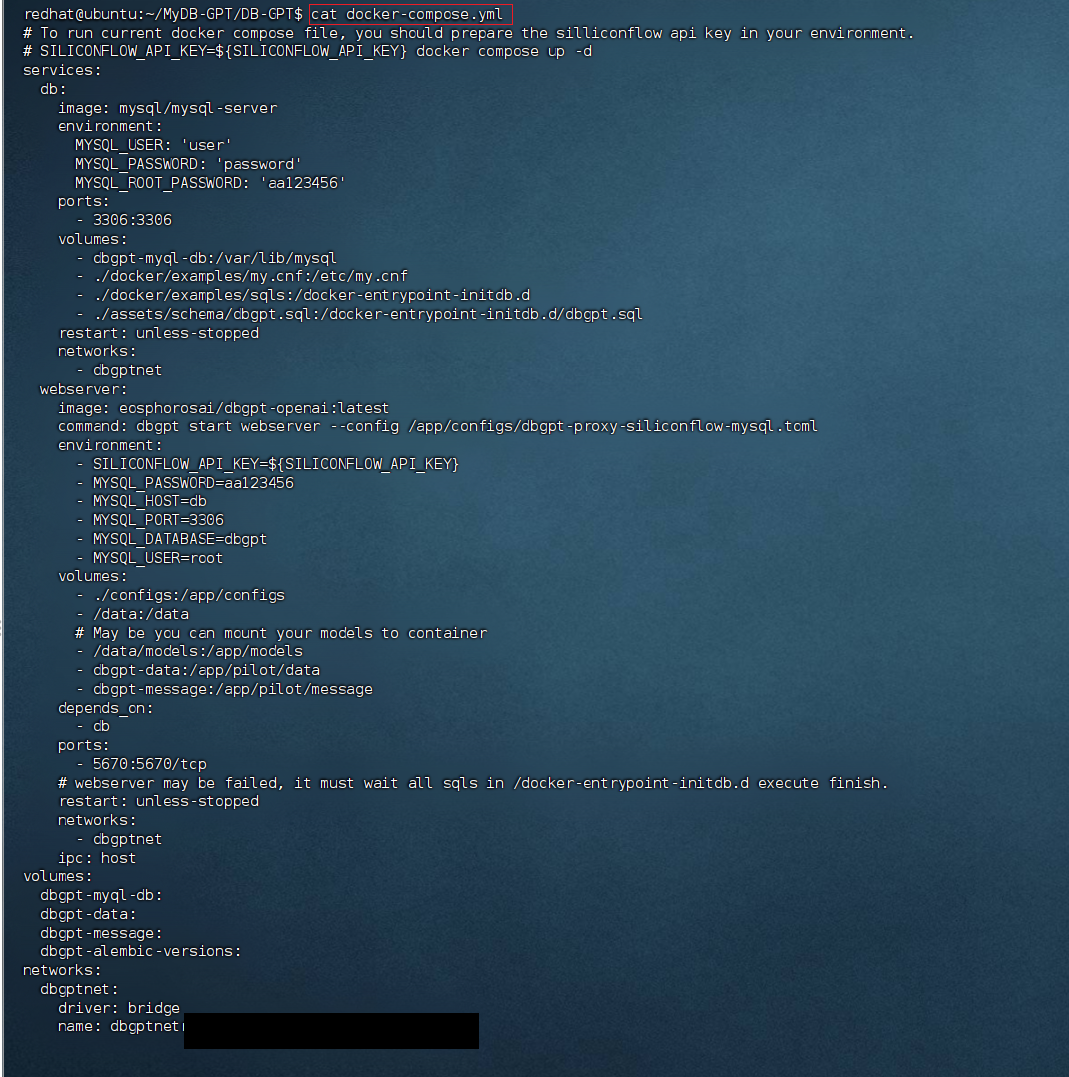
SILICONFLOW_API_KEY=${SILICONFLOW_API_KEY}# 查看 DB-GPT 仓库的根目录的docker-compose.yml内容 (里面的应用端口如果和现有应用端口冲突,记得调整,否则忽略。例如:机子已经安装了mysql占用了3306端口,如果不改启动的是否就会报端口冲突)
# 开始docker compose部署安装
docker compose -f docker-compose.yml -p dbgptnet up -d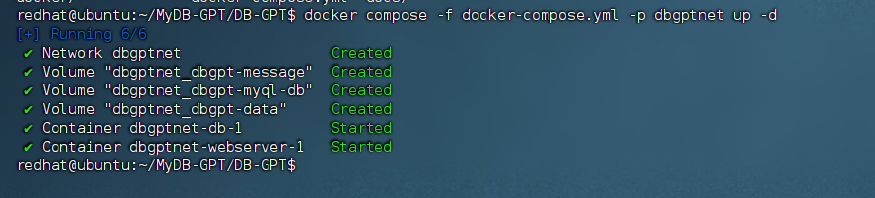
# 访问地址 http://IP:5670 验证是否安装正常可用
三、DB-GPT 入门使用
3.1 模型供应商与模型配置
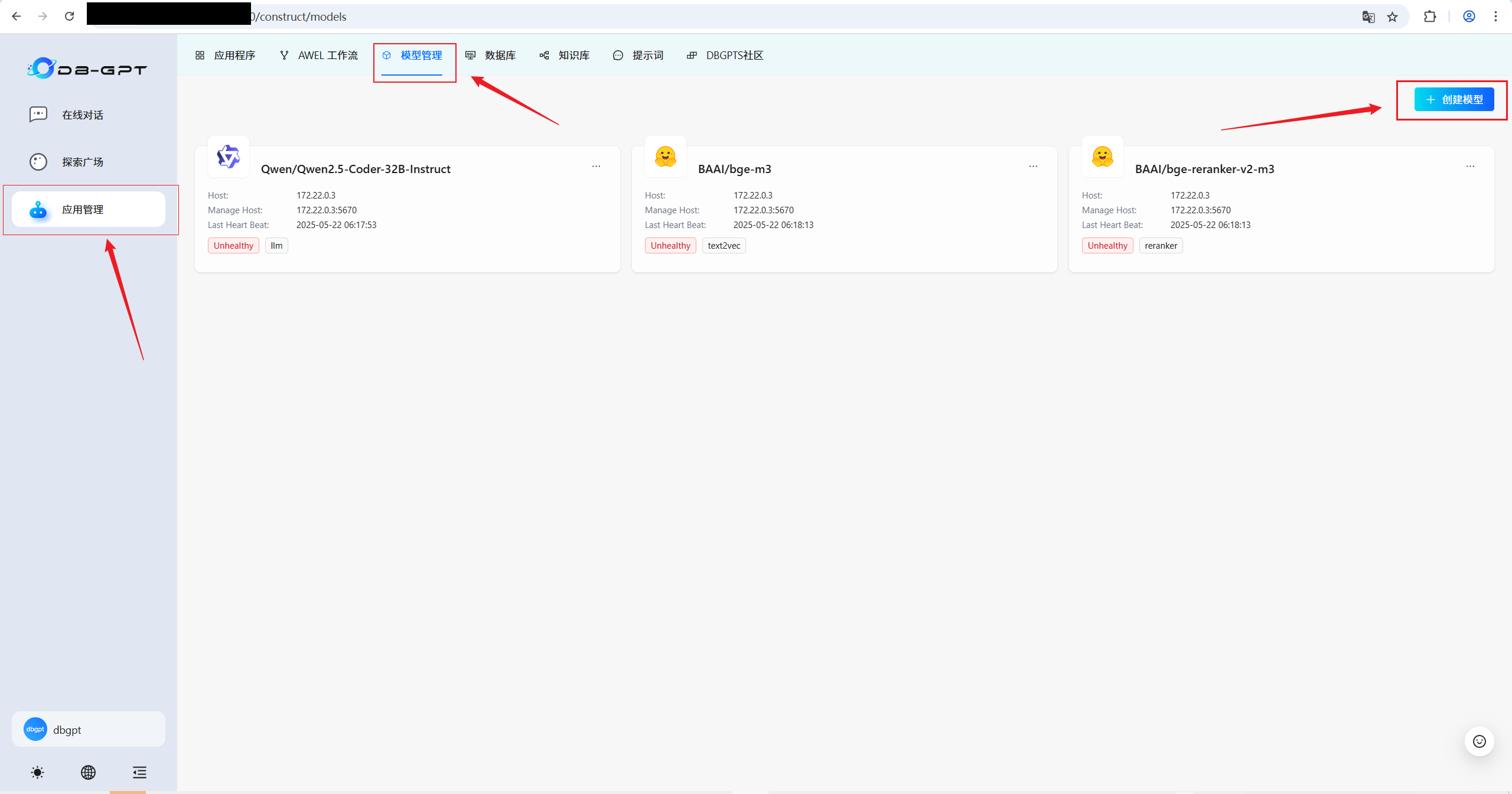
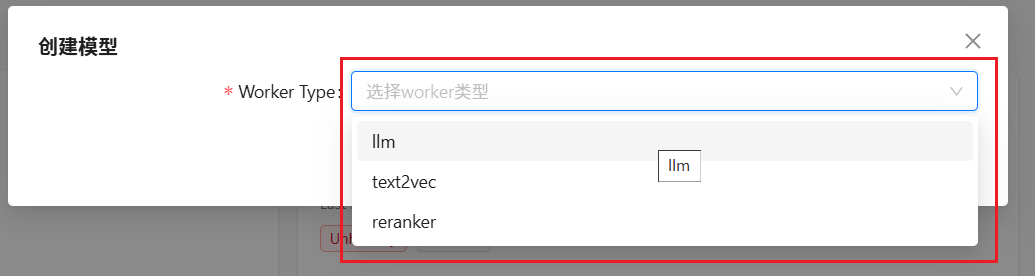
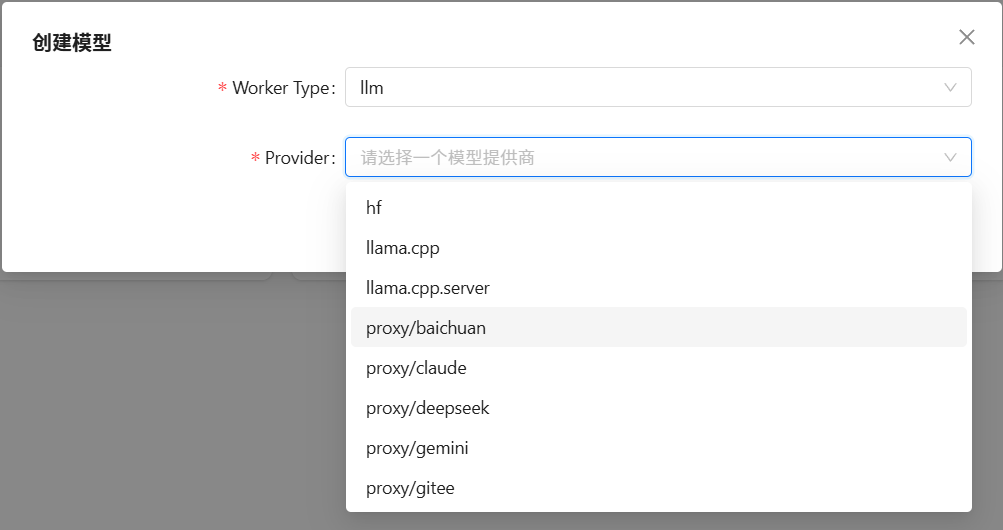
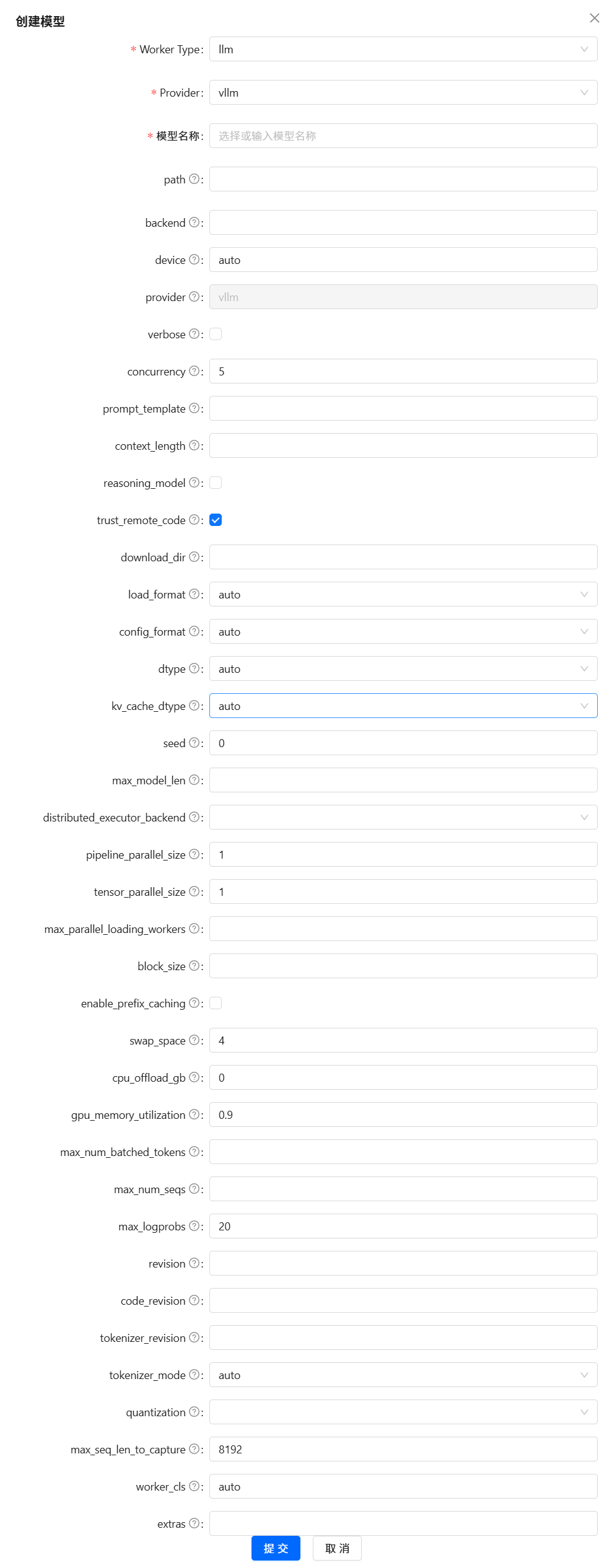
按照上面的步骤,依次添加 llm 、text2vec 和 reranker 三种类型的模型;然后,再选择合适的模型供应商;并最后填写添加的模型与相关调参。
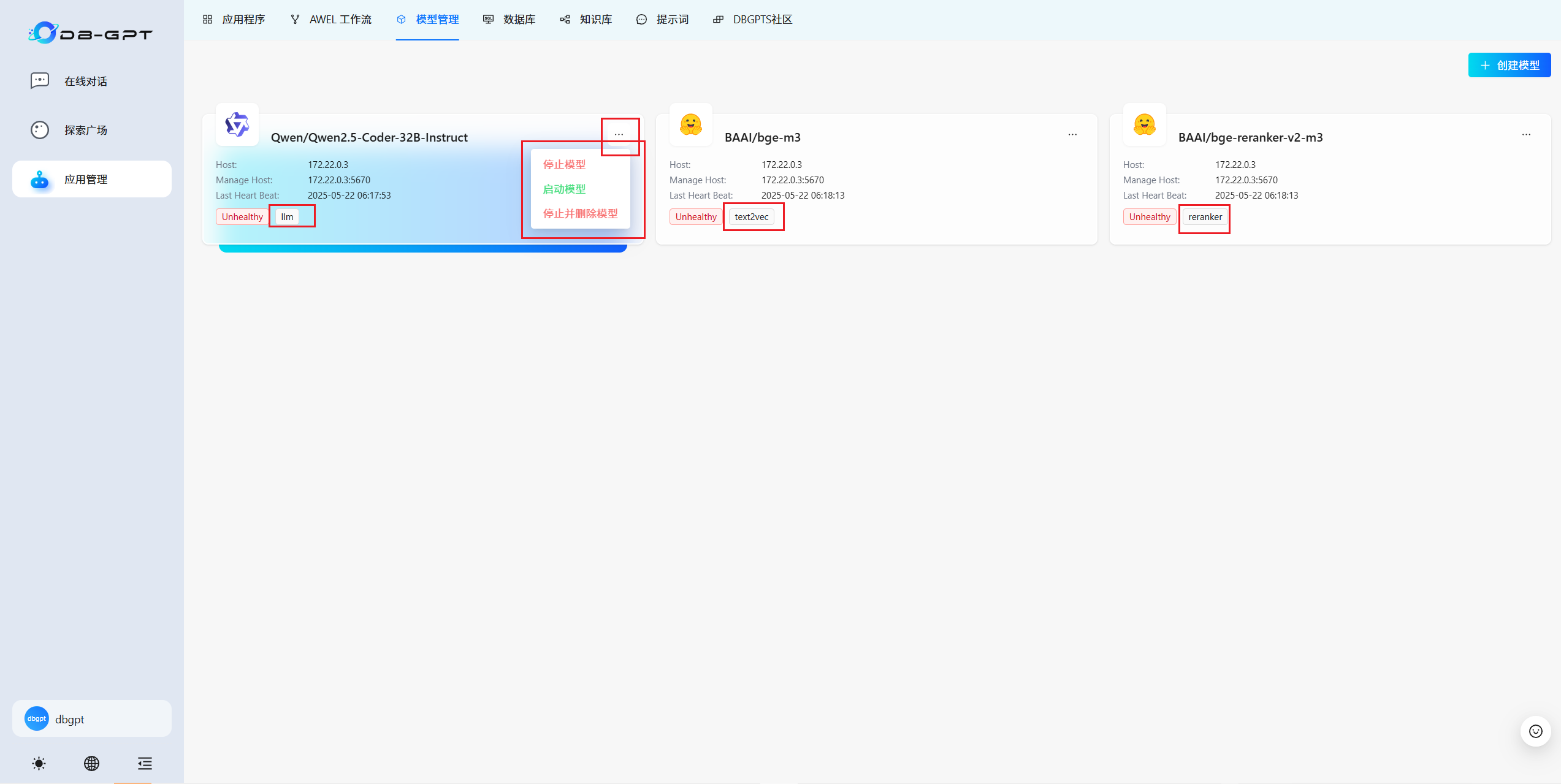
3.2 维护数据源
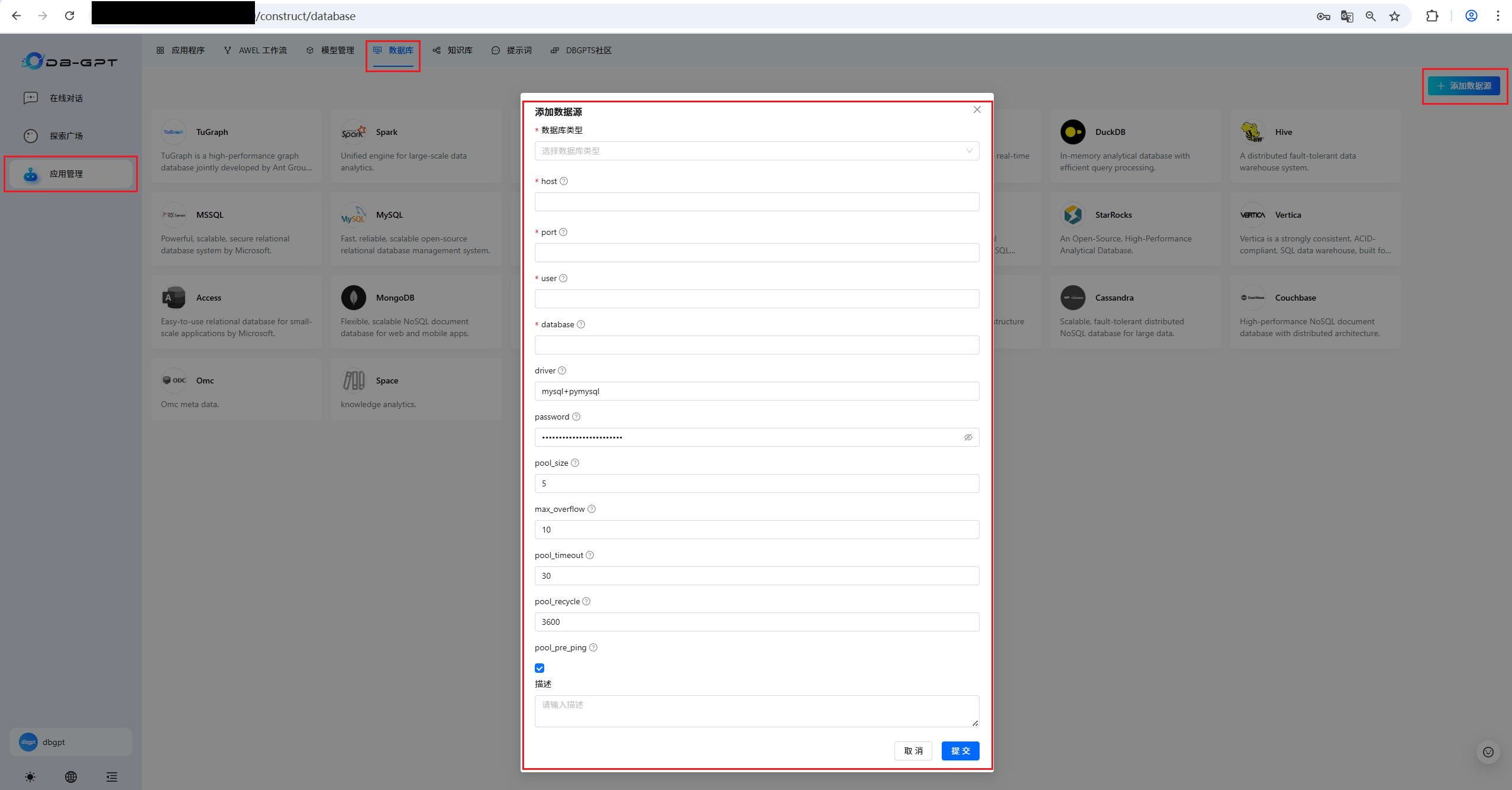
按照上面步骤,依次选择数据库类型与相关配置。
3.3 维护知识库
Text2SQL中最重要的SQL业务背景知识的三大知识库(每个单独的数据源,都需要维护该数据源对应的三个独立的 DDL 知识库 、DB Description 知识库 和 Q->SQL 知识库):
第一类是 DDL(Data Definition Language)知识库,它主要提供数据库表结构信息,包括表名、列名、数据类型以及主键、外键等约束条件。
第二类是 DB Description 知识库,用于说明数据库中表和列的含义,这对于模型理解数据的语义非常重要。
第三类是 Q->SQL 知识库,它包含了大量的参考 SQL,即自然语言问题与对应的 SQL 语句示例。这些语句主要是让大模型学习如何在有背景知识的情况下学会写SQL语句。这些叫做黄金语句,Golden statement,这些语句给的越多,大模型学习的越好,他能够回答的问题越有不会出错。正常情况下准备5000-10000个这样的SQL语句就可以了。
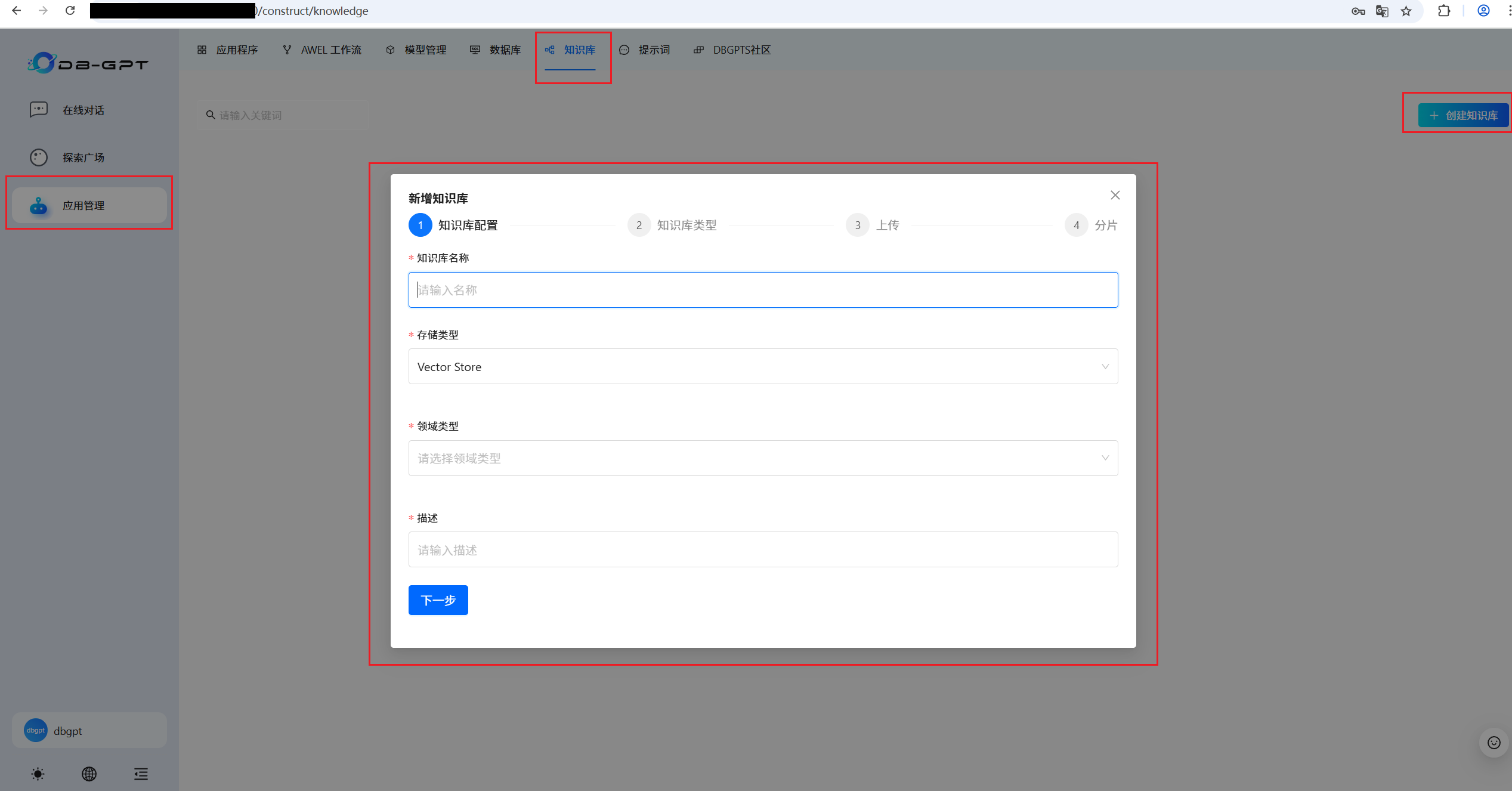
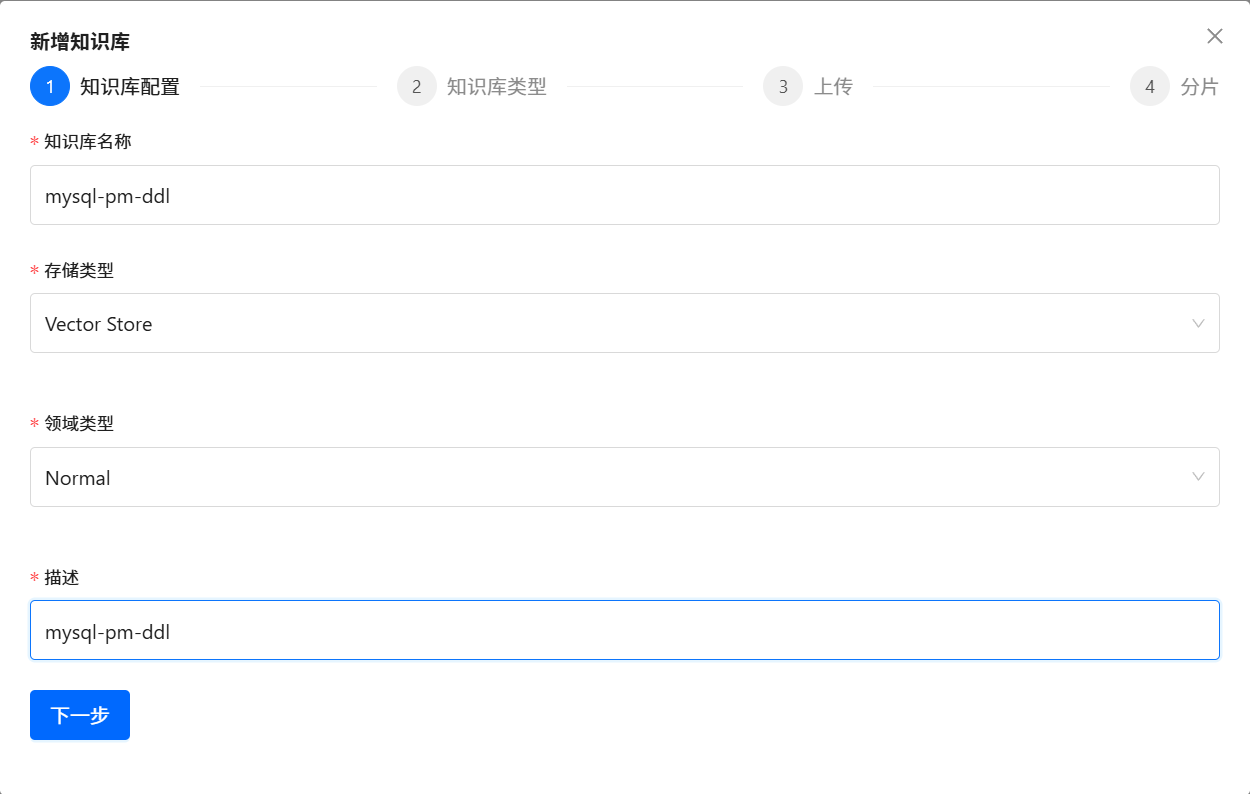
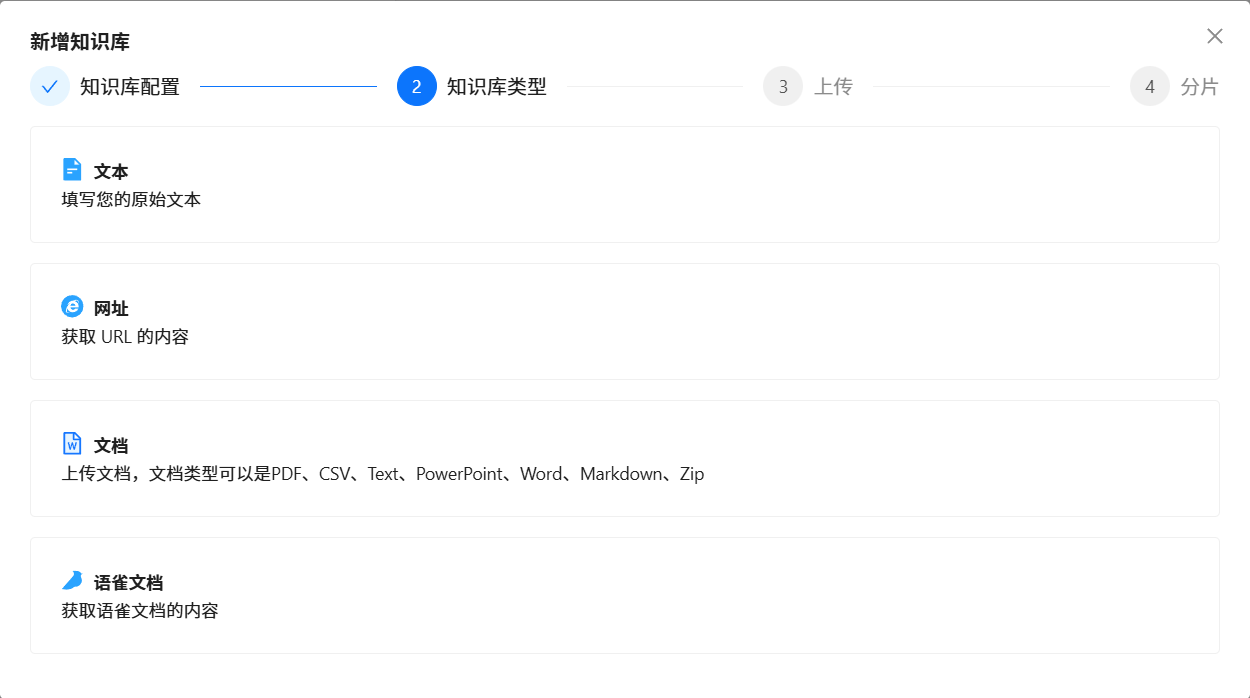
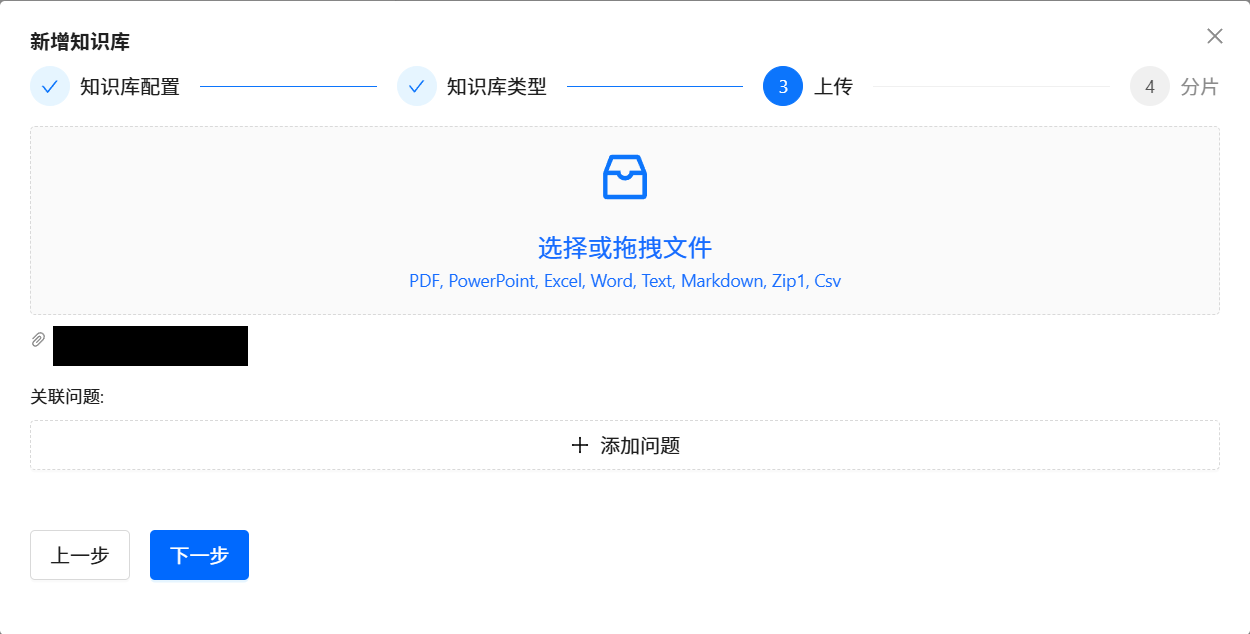
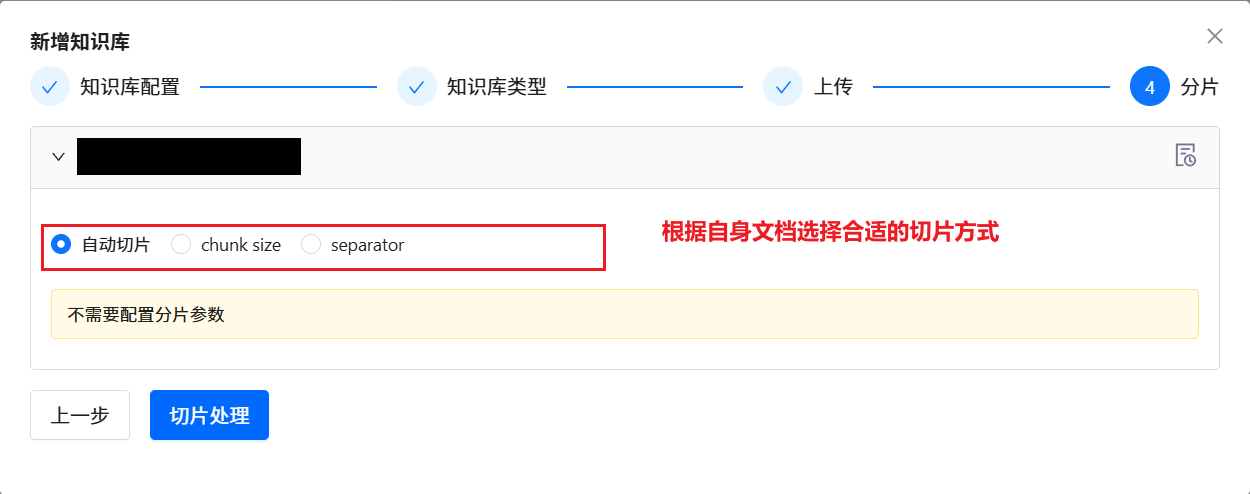
按照上面步骤,依次为每个单独的数据源,维护该单独数据源对应的三个独立的 DDL 知识库 、DB Description 知识库 和 Q->SQL 知识库。
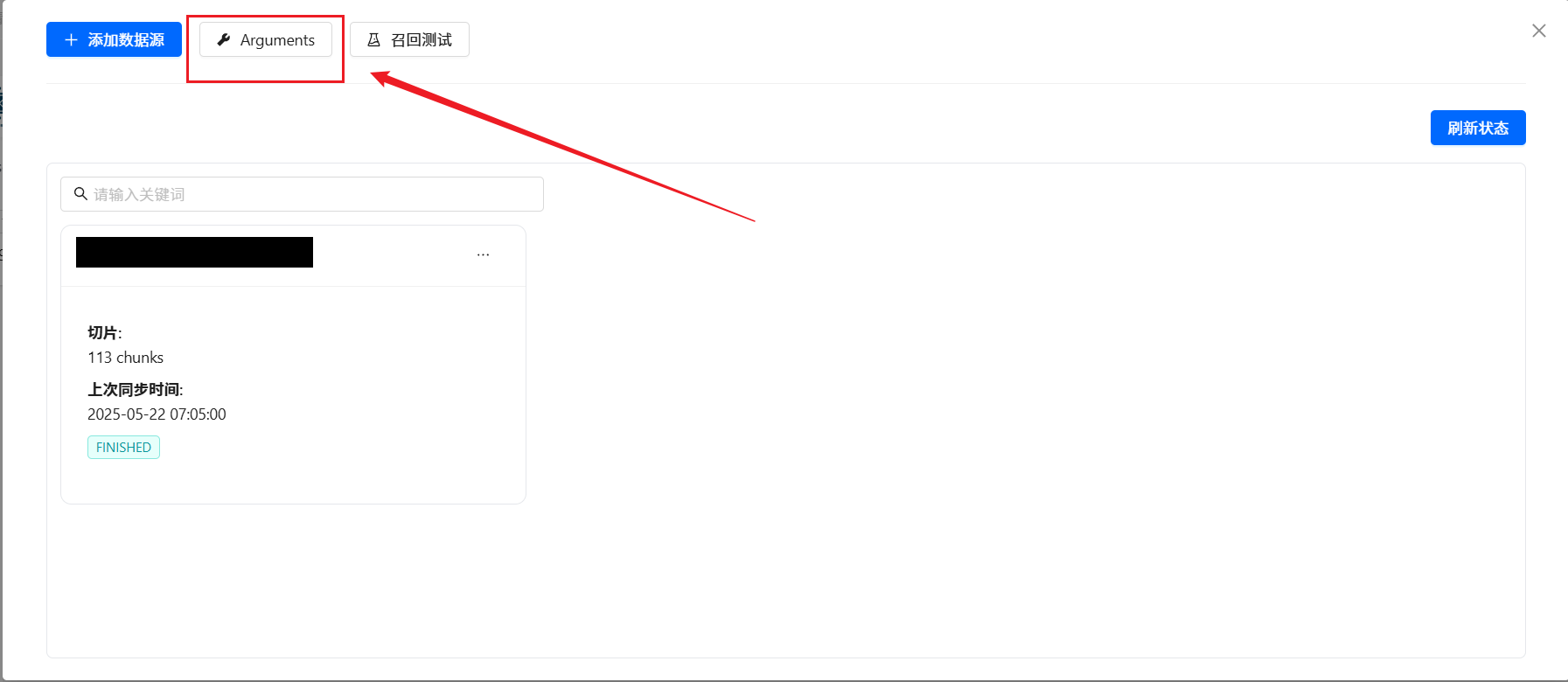
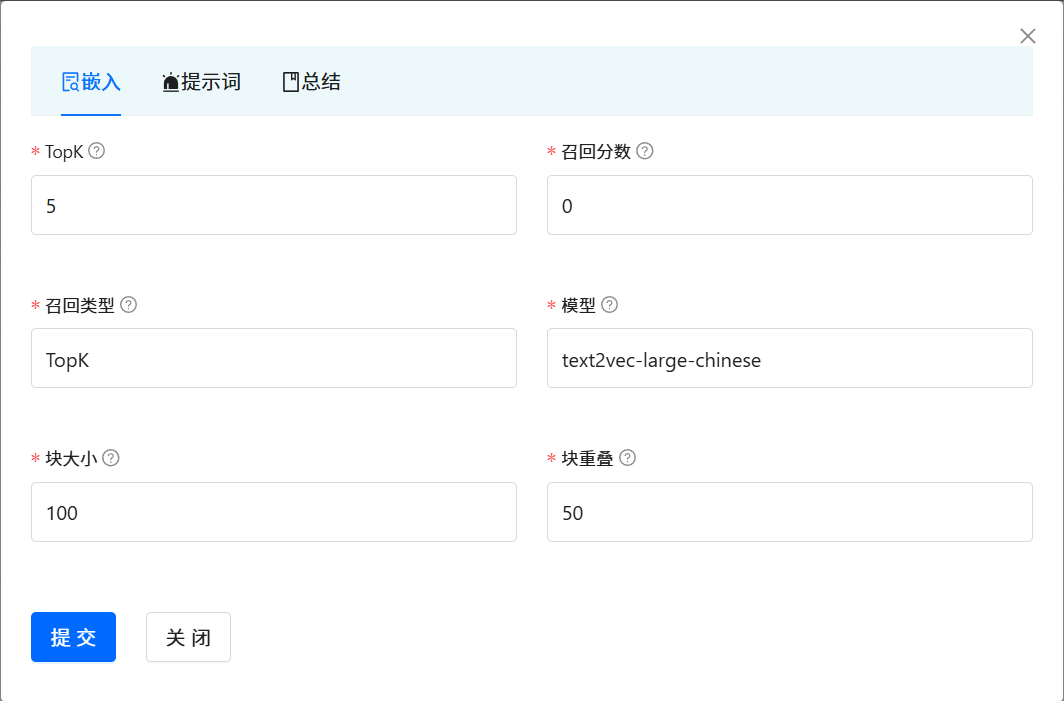
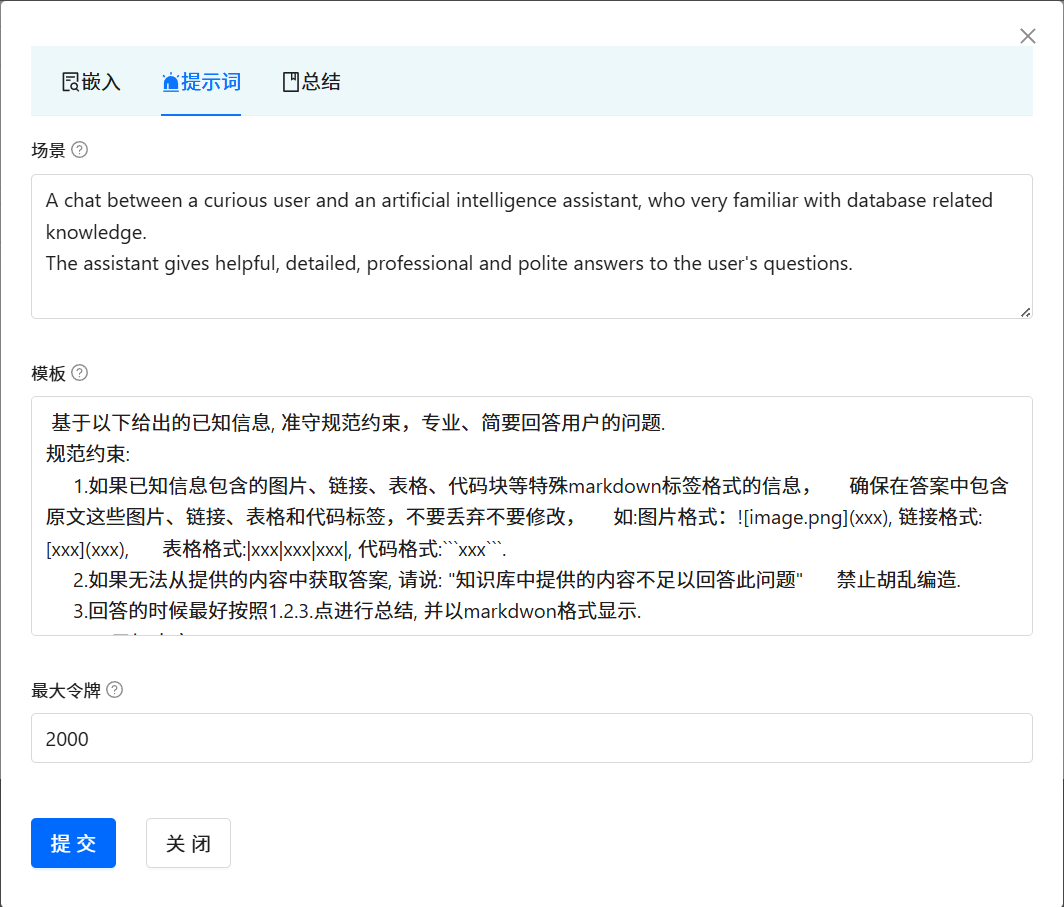
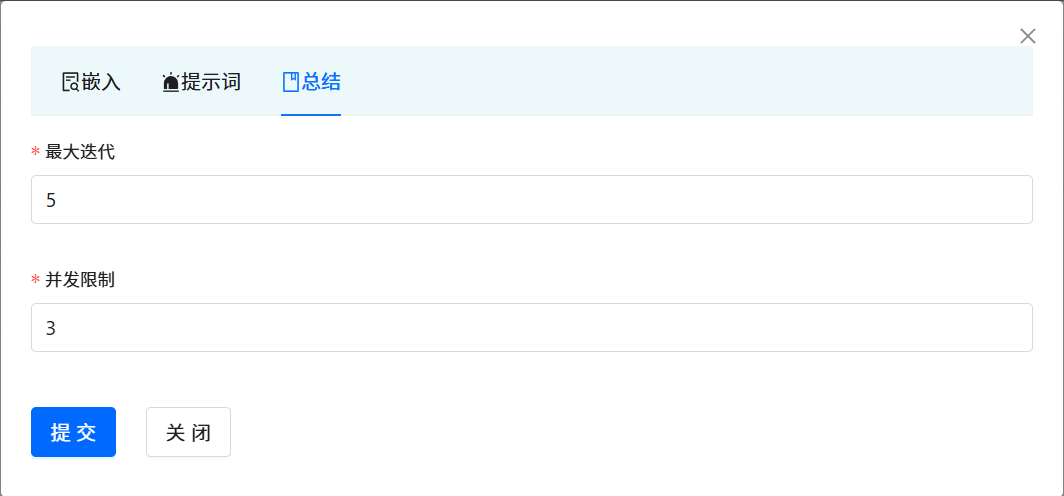
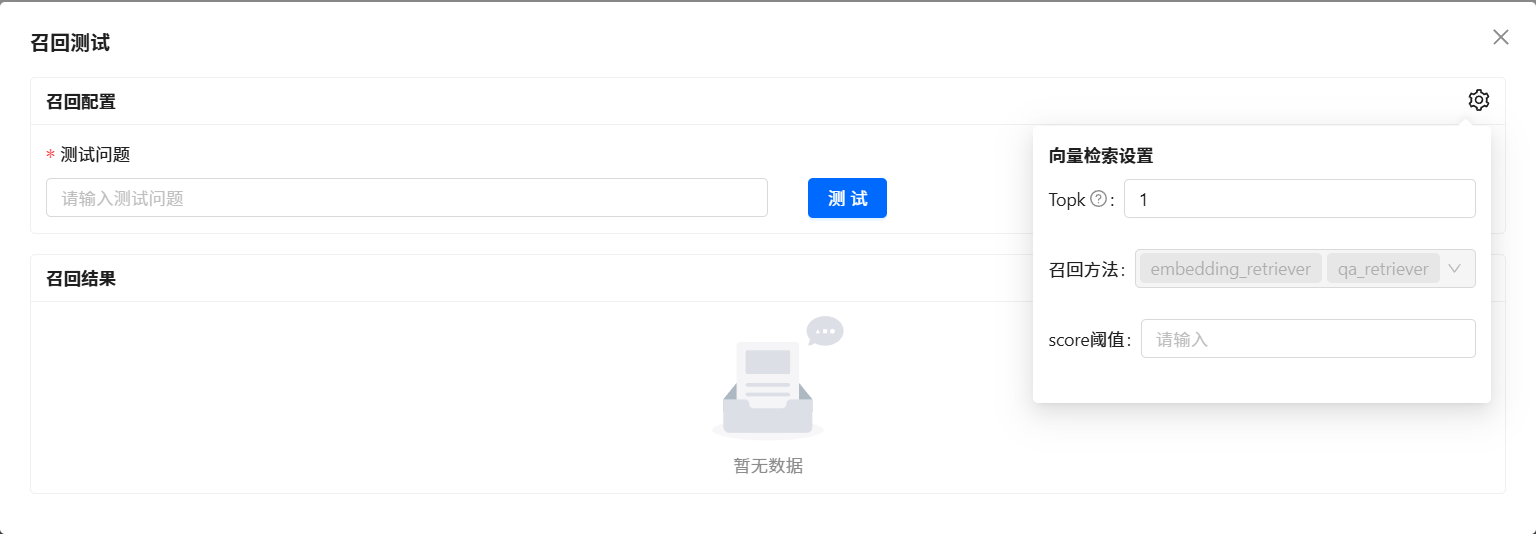
每一个知识库空间支持参数定制,包括向量检索的相关参数和知识问答提示的参数。 点击对应的知识库空间, 会弹出对话框。 点击 Arguments 按钮。即可进入到调参界面。

3.4 提示词
根据自身需要创建维护完善提示词。
3.5 应用程序
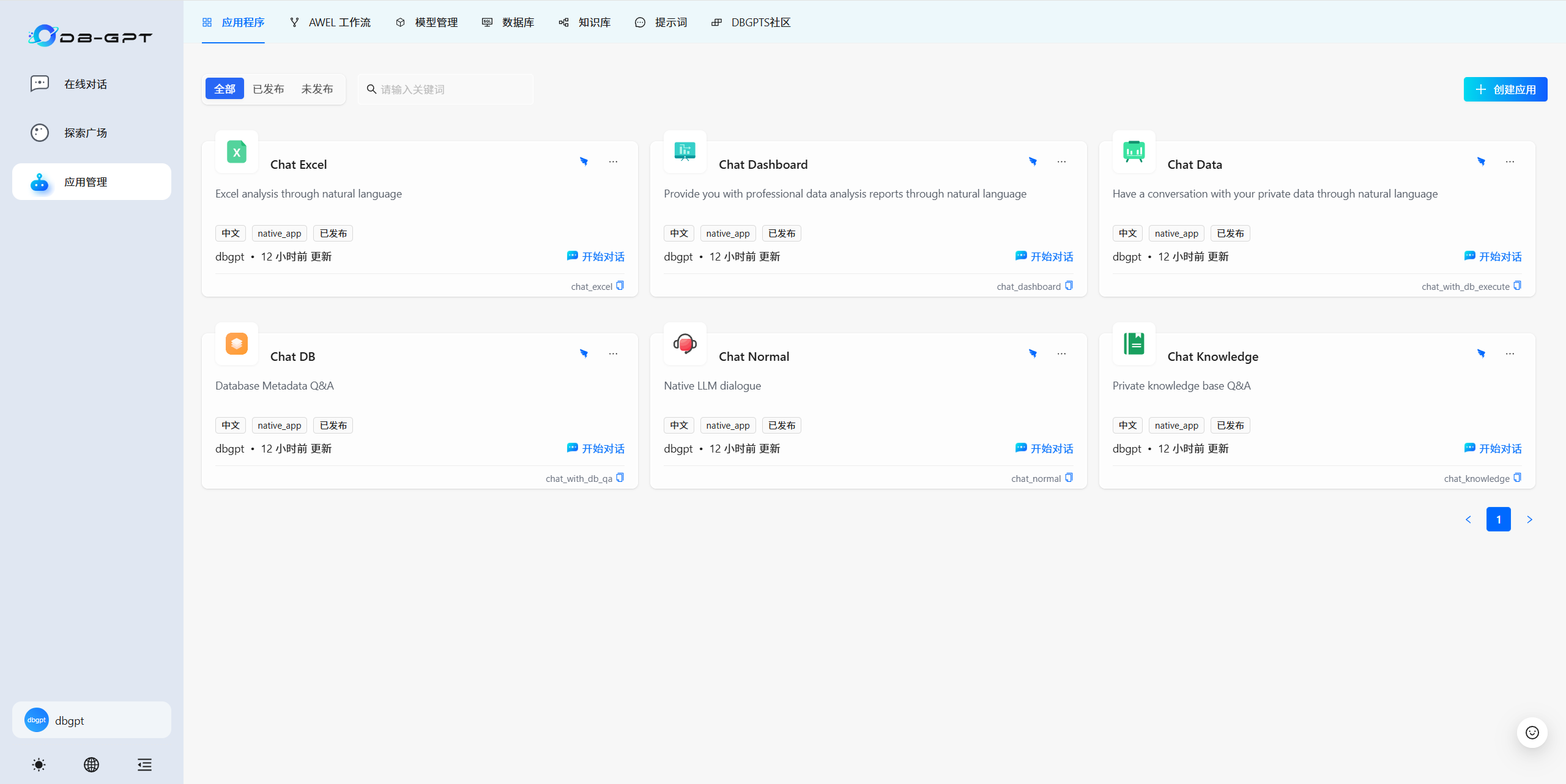
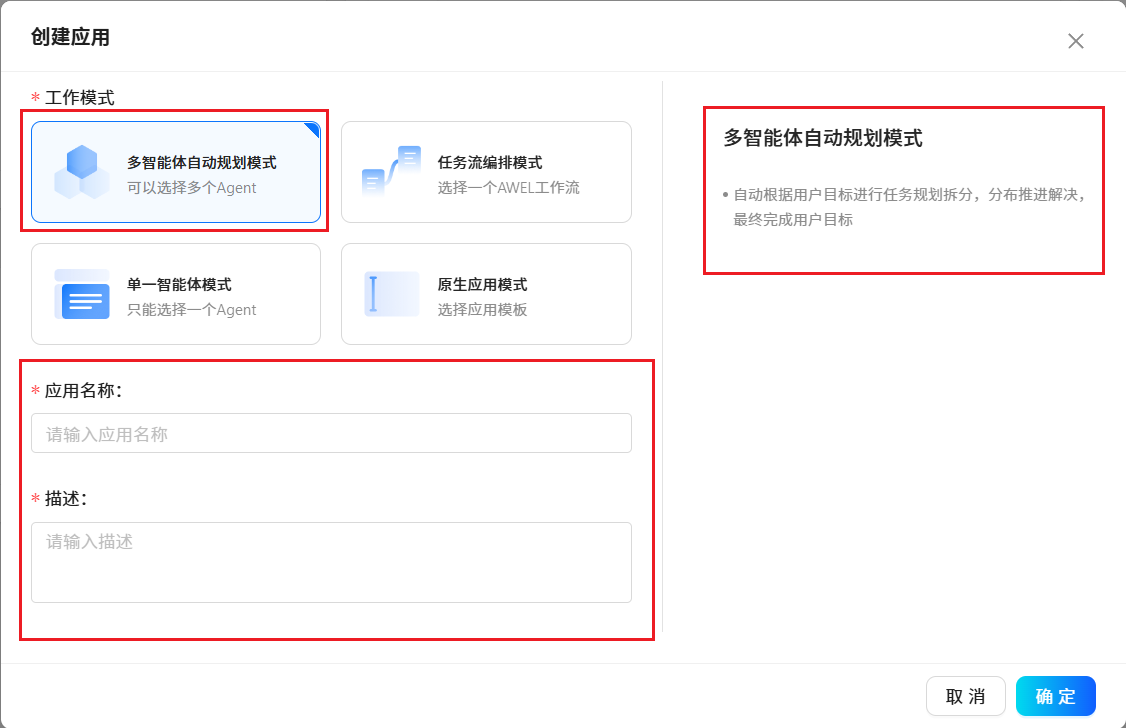
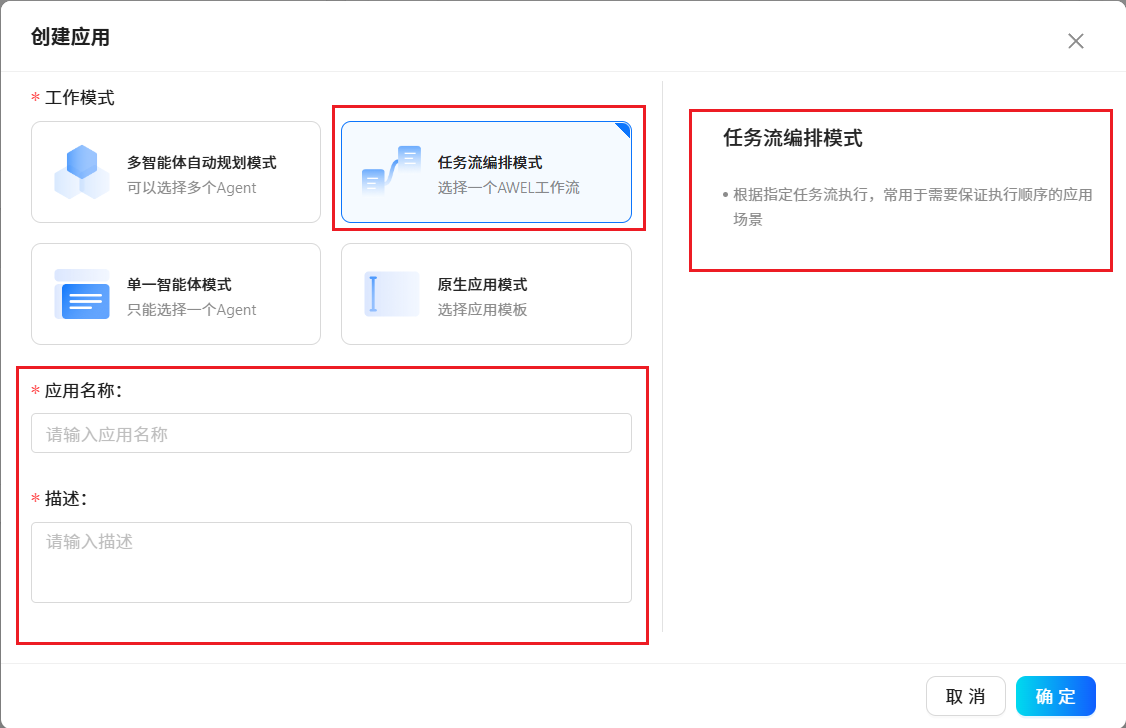
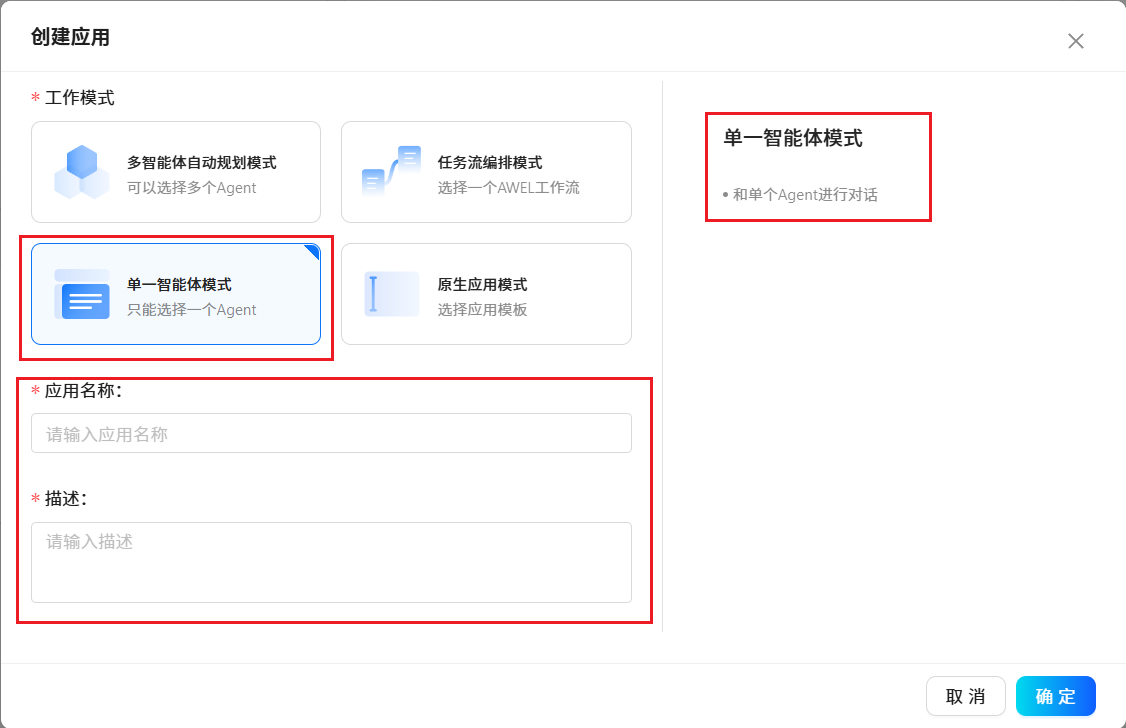
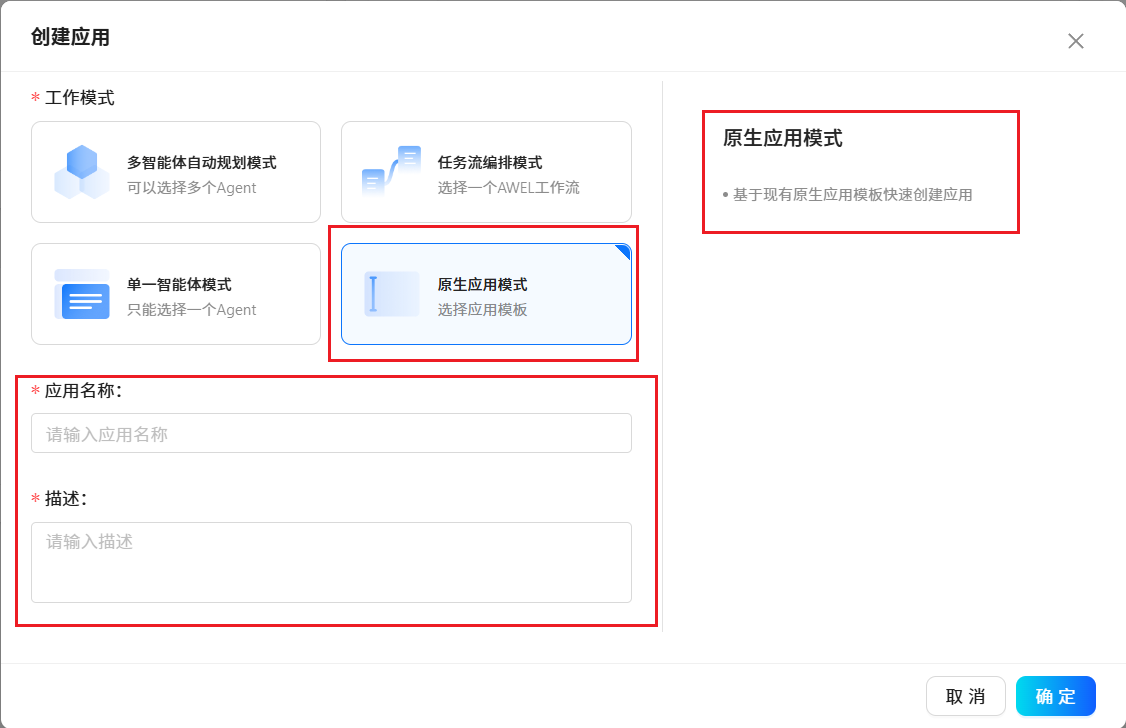
根据提示使用预置好的应用程序模板或创建属于自己个性化的应用程序。
3.6 AWEL 工作流
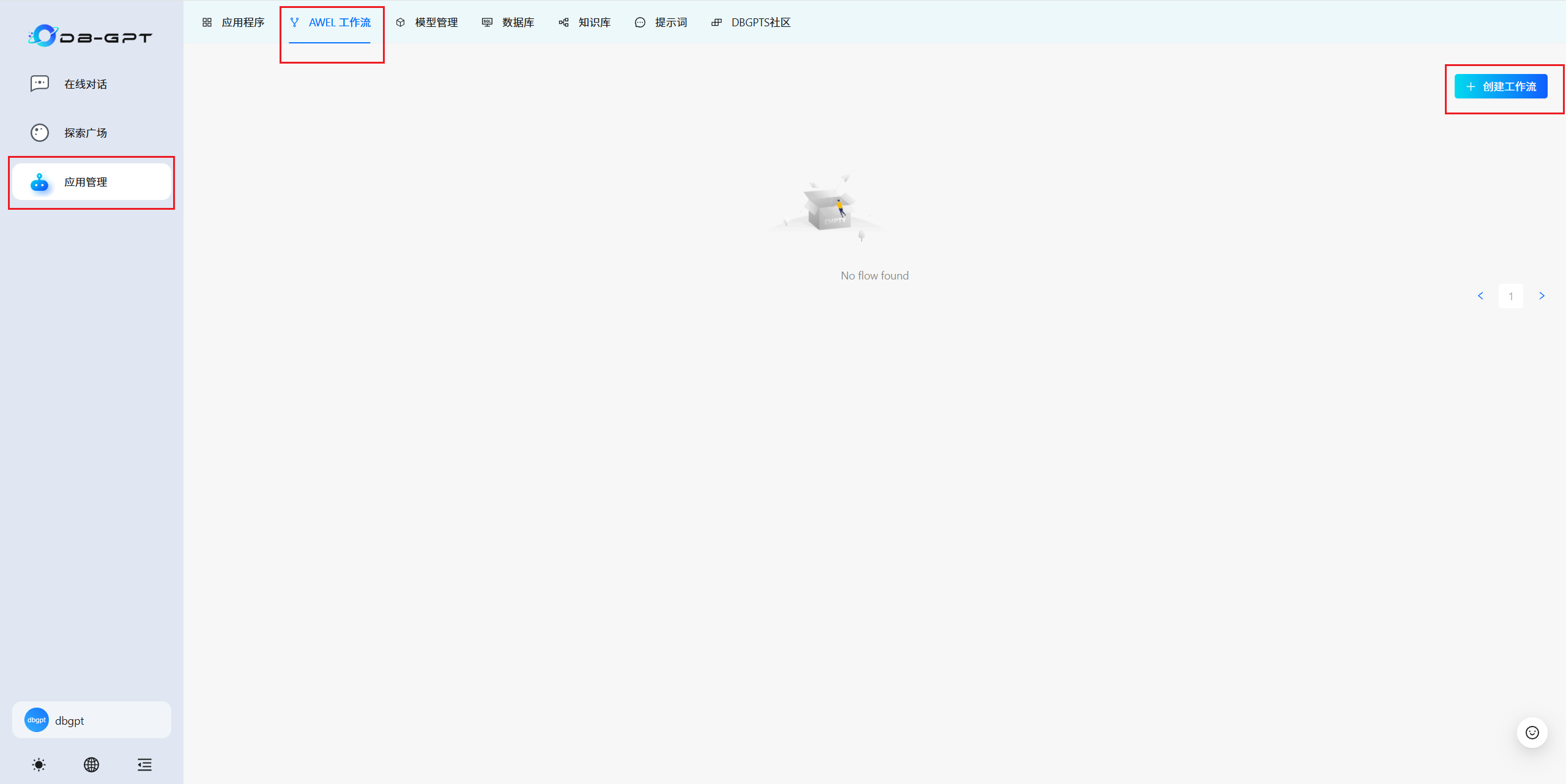
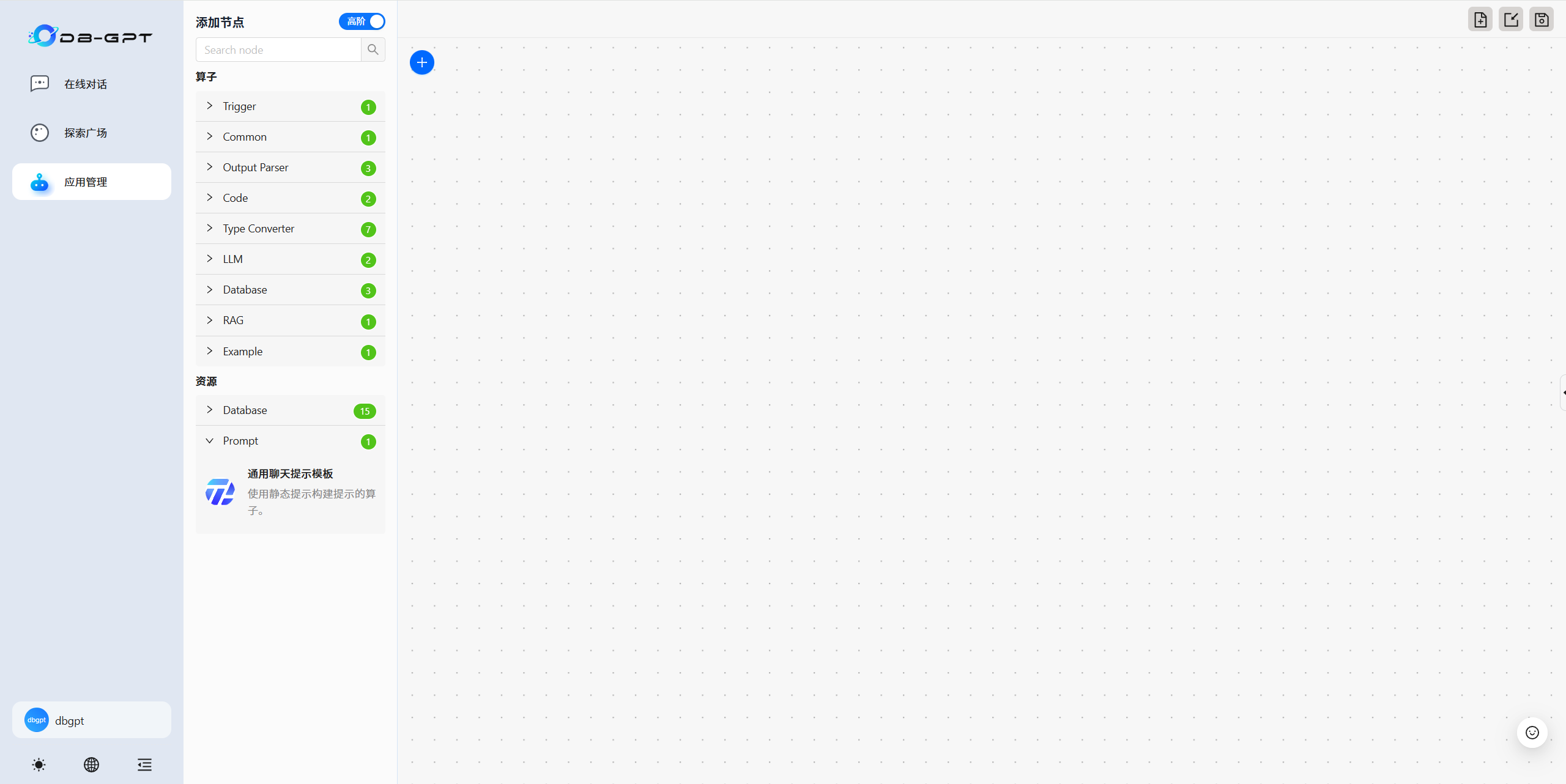
根据提示创建属于自己个性化的工作流。
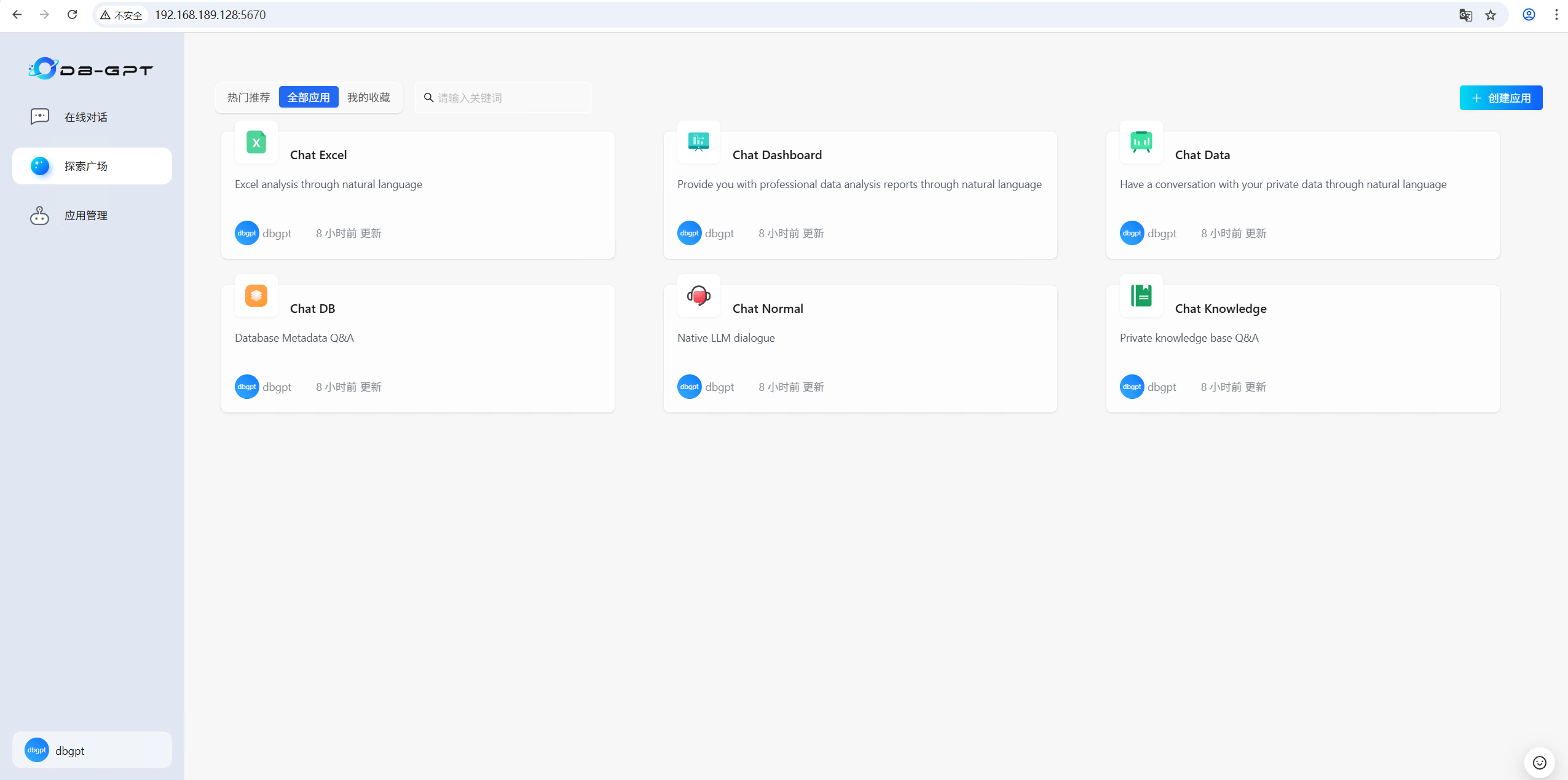
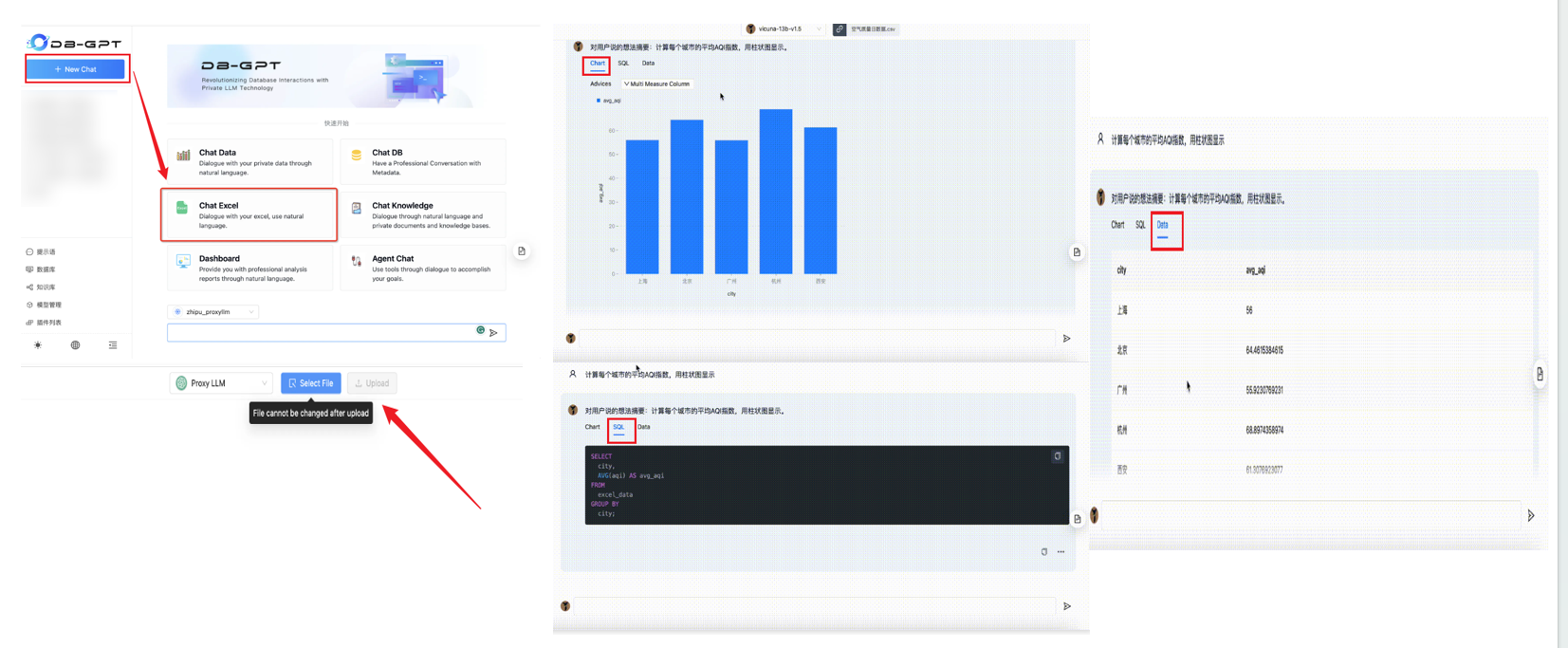
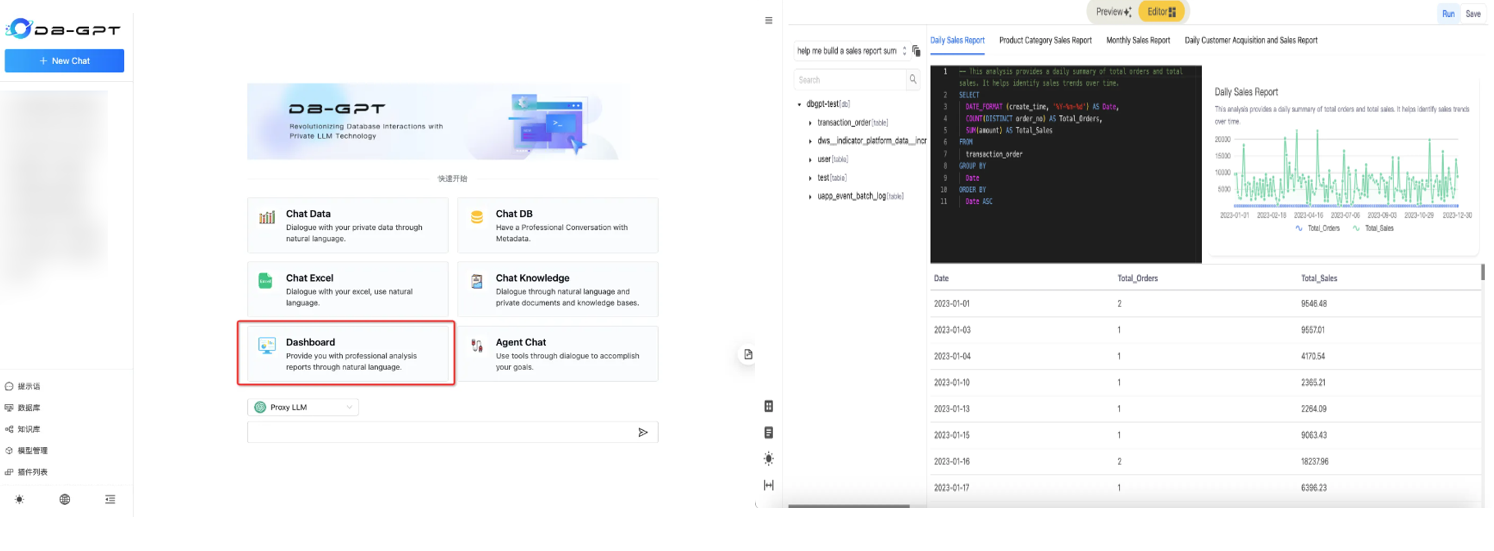
3.7 选择对话模式开始对话
Excel对话(Chat Excel)是指可以通过自然语言对话的方式,实现Excel数据的解读与分析。注意Excel文件格式转换为.csv格式 。
对话仪表板(Chat Dashboard)可以通过自然语言进行智能的报表生成与分析。
数据对话(Chat Data)是通过自然语言与数据进行对话,目前主要是结构化与半结构化数据的对话,可以辅助做数据分析与洞察。
数据库对话(Chat DB)是打造专业的数据库专家,定位是 LLM As DBA ,可以通过与数据库对话完成数据库性能分析、优化等工作。
标准对话(Chat Normal)是用来本地LLM对话。
知识库对话(Chat Knowledge)是用来基于指定知识库进行RAG的 Q&A 问答。
选择对话模式后,就可以开始对话。
--------------------------------------
没有自由的秩序和没有秩序的自由,同样具有破坏性。

————————————————
版权声明:本文为博主原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。
原文链接:https://mp.csdn.net/mp_blog/creation/editor/148136773