MapReduce-Top N程序编写与运行
我的是hadoop2.7.7 如果是其他版本 需要自己更改!!!!!!!!!
一、写MapReduce-Top N程序
先创建项目 然后配置Maven文件
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"><modelVersion>4.0.0</modelVersion><groupId>com.hadoop</groupId><artifactId>topn</artifactId><version>1.0-SNAPSHOT</version><properties><hadoop.version>2.7.7</hadoop.version><java.version>1.8</java.version></properties><dependencies><!-- Hadoop Core --><dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-common</artifactId><version>${hadoop.version}</version></dependency><dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-mapreduce-client-core</artifactId><version>${hadoop.version}</version></dependency><dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-client</artifactId><version>${hadoop.version}</version></dependency></dependencies><build><plugins><plugin><groupId>org.apache.maven.plugins</groupId><artifactId>maven-compiler-plugin</artifactId><version>3.8.1</version><configuration><source>${java.version}</source><target>${java.version}</target></configuration></plugin><plugin><groupId>org.apache.maven.plugins</groupId><artifactId>maven-shade-plugin</artifactId><version>3.2.4</version><executions><execution><phase>package</phase><goals><goal>shade</goal></goals><configuration><filters><filter><artifact>*:*</artifact><excludes><exclude>META-INF/*.SF</exclude><exclude>META-INF/*.DSA</exclude><exclude>META-INF/*.RSA</exclude></excludes></filter></filters><transformers><transformer implementation="org.apache.maven.plugins.shade.resource.ManifestResourceTransformer"><mainClass>com.hadoop.topn.TopNDriver</mainClass></transformer></transformers></configuration></execution></executions></plugin></plugins></build>
</project>然后先点右边的maven 更新配置 先卸载clean,再点install进行更新依赖
先把src/main/java/下的org/example包删了,重新创建包 为com/hadoop/topn,不删原始包也可以 代码中要改了 然后再创建三个类,分别为:TopNReducer、TopNMapper、TopNDriver.
package com.hadoop.topn;import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;import java.io.IOException;
import java.util.TreeMap;public class TopNReducer extends Reducer<Text, IntWritable, Text, IntWritable> {private final TreeMap<Integer, String> topRecords = new TreeMap<>();private int N;@Overrideprotected void setup(Context context) {N = context.getConfiguration().getInt("top.n", 10);}@Overridepublic void reduce(Text key, Iterable<IntWritable> values, Context context)throws IOException, InterruptedException {for (IntWritable value : values) {topRecords.put(value.get(), key.toString());if (topRecords.size() > N) {topRecords.remove(topRecords.firstKey());}}}@Overrideprotected void cleanup(Context context)throws IOException, InterruptedException {// 按降序输出结果for (Integer value : topRecords.descendingKeySet()) {context.write(new Text(topRecords.get(value)), new IntWritable(value));}}
}package com.hadoop.topn;import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;import java.io.IOException;
import java.util.TreeMap;public class TopNMapper extends Mapper<LongWritable, Text, Text, IntWritable> {private final TreeMap<Integer, String> topRecords = new TreeMap<>();private int N;@Overrideprotected void setup(Context context) {N = context.getConfiguration().getInt("top.n", 10);}@Overridepublic void map(LongWritable key, Text value, Context context)throws IOException, InterruptedException {String[] parts = value.toString().split("\\s+");if (parts.length >= 2) {try {String recordKey = parts[0];int recordValue = Integer.parseInt(parts[1]);topRecords.put(recordValue, recordKey);if (topRecords.size() > N) {topRecords.remove(topRecords.firstKey());}} catch (NumberFormatException e) {// 忽略格式不正确的行}}}@Overrideprotected void cleanup(Context context)throws IOException, InterruptedException {for (Integer value : topRecords.keySet()) {context.write(new Text(topRecords.get(value)), new IntWritable(value));}}
}package com.hadoop.topn;import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;public class TopNDriver {public static void main(String[] args) throws Exception {if (args.length != 3) {System.err.println("Usage: TopNDriver <input path> <output path> <N>");System.exit(-1);}Configuration conf = new Configuration();conf.setInt("top.n", Integer.parseInt(args[2]));Job job = Job.getInstance(conf, "Top N");job.setJarByClass(TopNDriver.class);job.setMapperClass(TopNMapper.class);job.setReducerClass(TopNReducer.class);job.setOutputKeyClass(Text.class);job.setOutputValueClass(IntWritable.class);FileInputFormat.addInputPath(job, new Path(args[0]));FileOutputFormat.setOutputPath(job, new Path(args[1]));System.exit(job.waitForCompletion(true) ? 0 : 1);}
}如果代码报红 就这样刷新
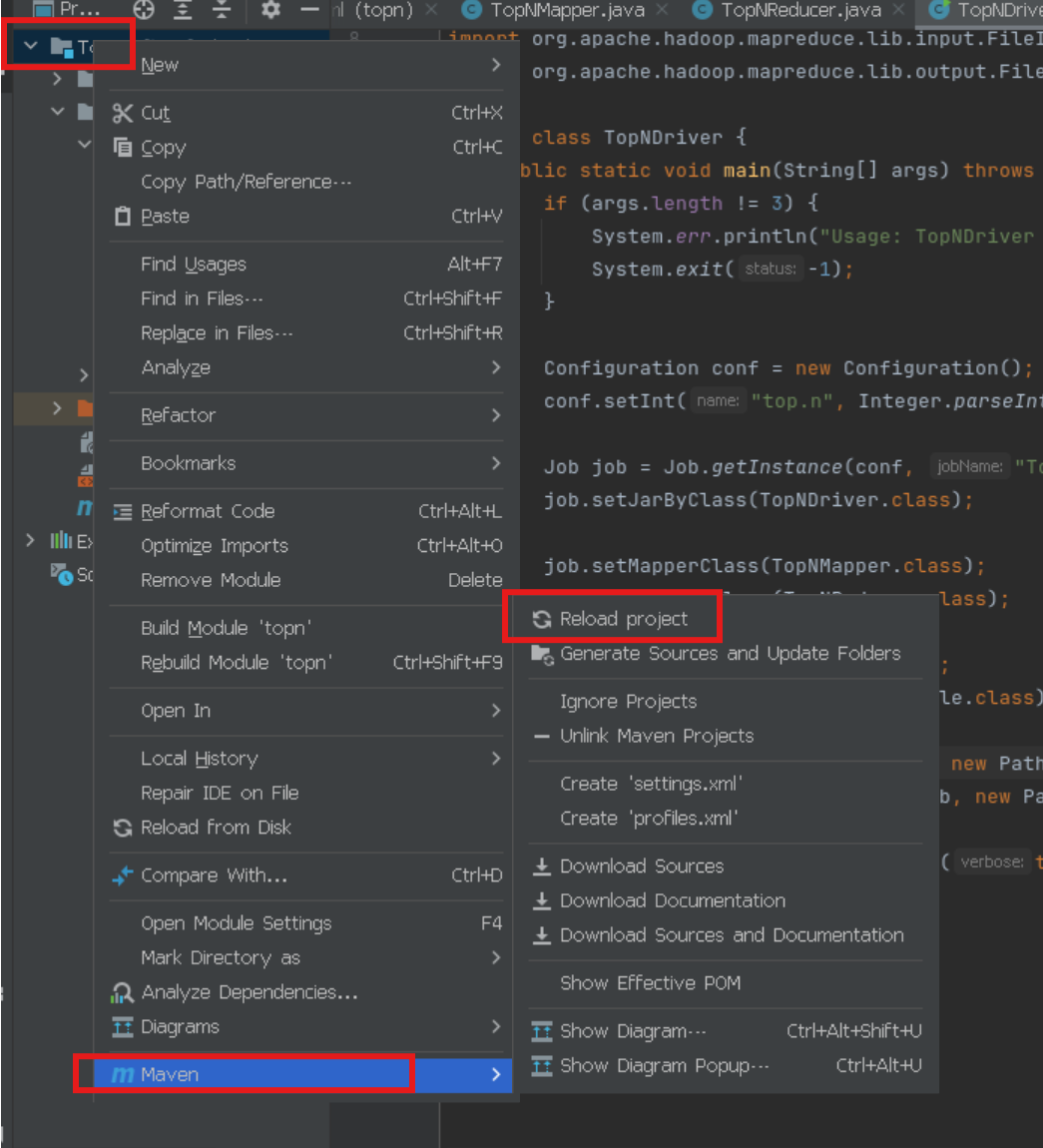
二、运行MapReduce作业
准备输入数据
创建一个输入文件 input.txt,内容格式如下:
item1 100
item2 200
item3 150
item4 300
item5 250
item6 180
item7 220
item8 190
item9 210
item10 230
item11 170
item12 240
将输入文件上传到HDFS
前提是要启动hadoop集群
hadoop fs -mkdir -p /user/yourusername/input
hadoop fs -put input.txt /user/yourusername/input编译打包项目
在项目根目录执行(自动打包):
mvn clean package也可以手动打包(如果自动打包不行 就手动打包)
导航到 target/classes 目录
cd /HadoopJavaCode/Top_N/Top_N/target/classes
#手动创建JAR文件
jar cvf /HadoopJavaCode/Top_N/Top_N/target/topn-manual-1.0-SNAPSHOT.jar com/
验证手动打包的 JAR 文件
jar tf /HadoopJavaCode/Top_N/Top_N/target/topn-manual-1.0-SNAPSHOT.jar看到类似以下内容为打包成功:
com/hadoop/topn/TopNDriver.class
com/hadoop/topn/TopNMapper.class
com/hadoop/topn/TopNReducer.class
在运行作业之前,确保输出路径 /user/yourusername/output 不存在。如果路径已存在,可以手动删除:
hadoop fs -rm -r /user/yourusername/output运行手动打包的 JAR 文件(如果是自动打包的,把目录和jar包进行修改)
hadoop jar /HadoopJavaCode/Top_N/Top_N/target/topn-manual-1.0-SNAPSHOT.jar com.hadoop.topn.TopNDriver /user/yourusername/input /user/yourusername/output 5查看运行结果
hadoop fs -cat /user/yourusername/output/part-r-00000 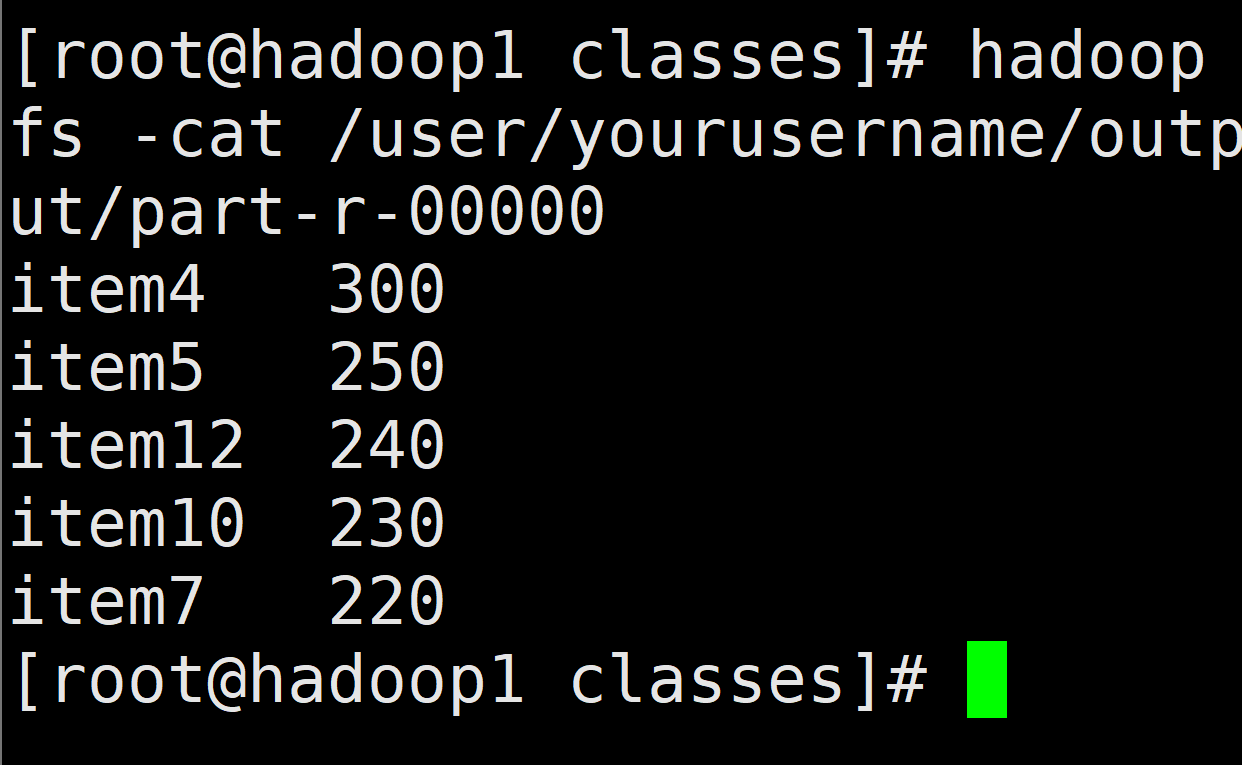
这样就运行成功啦