印度语言指令驱动的无人机导航!UAV-VLN:端到端视觉语言导航助力无人机自主飞行

- 作者:Pranav Saxena, Nishant Raghuvanshi and Neena Goveas
- 单位:比尔拉理工学院(戈瓦校区)
- 论文标题:UAV-VLN: End-to-End Vision Language guided Navigation for UAVs
- 论文链接:https://arxiv.org/pdf/2504.21432
主要贡献
- 提出了UAV-VLN,这是一个针对无人机(UAV)的端到端视觉语言导航(VLN)框架,能够在复杂的真实世界环境中解释和执行自由形式的自然语言指令,填补了无人机视觉语言导航领域的研究空白。
- 构建了一个包含1000多个空中导航指令提示及其对应子计划的新颖数据集,专门用于训练和评估适用于3D无人机环境的大型语言模型。
- 证明了该方法能够泛化到未见环境和指令,在室内外环境中均实现了稳健的零样本导航性能。
研究背景
- 无人机(UAV)在室内和室外环境中承担着越来越多的任务,如包裹递送、空中监视和搜索救援等,这些任务要求无人机能够在动态、以人类为中心的环境中导航,同时与静态物体和移动主体进行交互。
- 传统的无人机导航方法依赖于预定义的飞行路径或基于GPS的航点,难以应对动态环境、不确定性和信息不完整的挑战。
- 视觉语言导航(VLN)为无人机导航提供了新的方向,使无人机能够通过视觉输入将高级自然语言指令转化为复杂的导航任务,但以往的VLN方法主要针对在结构化二维环境中运行的轮式或腿式机器人,对无人机的适用性有限。
研究方法
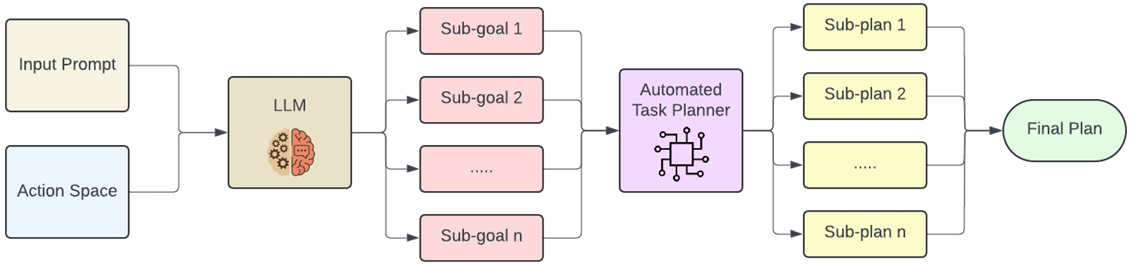
问题定义
- 任务目标:给定一个自由形式的自然语言指令 I I I 和无人机从机载RGB相机捕获的视觉观测流 V = { v 1 , v 2 , … , v T } V = \{v_1, v_2, \dots, v_T\} V={v1,v2,…,vT},目标是预测一个控制指令序列 A = { a 1 , a 2 , … , a T } A = \{a_1, a_2, \dots, a_T\} A={a1,a2,…,aT},引导无人机从起始位置到达指令中描述的目标位置或目标状态,同时安全地穿越环境。
- 关键挑战:
- 语义解析:从非结构化语言中提取可操作的目标和空间线索。
- 视觉定位:在动态、无结构的环境中,将语言引用的对象和区域与无人机的视觉视野对齐。
- 轨迹规划:在三维空间中生成可行、安全且符合指令的飞行路径。
- 泛化能力:在新环境中保持鲁棒性,对新的指令和视觉场景具有最小的重新训练需求。
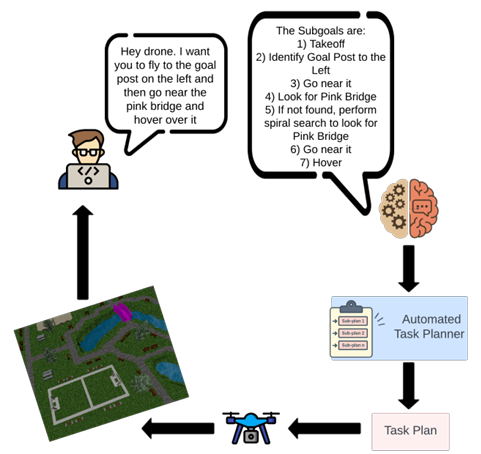
自然语言Prompt
- 核心目标:准确理解和执行自然语言指令。
- 问题:通用的预训练大型语言模型(如ChatGPT或Gemini)在无人机导航任务中可能会出现误解或错误分类动作,且依赖云端基础设施可能导致延迟或可用性问题。
- 解决方案:采用基于领域特定数据集的微调方法。作者定制了一个无人机指令数据集,并在该数据集上微调了TinyLlama-1.1B模型,使其更好地理解无人机特定的术语、空间指令和安全关键细节。
- 输入:
- 输入提示:用户提供的高级自然语言指令。
- 动作空间:无人机可以执行的所有有效离散动作集合。
- 输出:微调后的LLM生成一系列中间子目标,每个子目标对应一个可执行的无人机动作。
自动化任务规划器
- 功能:将LLM分解的高级子目标进一步转换为具体的行动计划,以便无人机在物理环境中执行。
- 实现:
- 利用无人机的离散动作空间,结合当前状态和环境上下文,为每个子目标生成有效且高效的子计划。
- 将这些子计划组合成一个连贯的最终执行计划,确保无人机安全且最优地完成任务。
- 技术实现:使用Robot Operating System 2(ROS 2)实现控制流程,提供模块化、实时能力和与无人机飞行堆栈的稳健集成。

视觉输入
- 目标:结合语言理解分析视觉输入,确定无人机的目标位置。
- 挑战:无人机不仅要准确感知环境,还要根据自然语言指令对感知结果进行语义定位。
- 解决方案:采用开放词汇对象检测器Grounding DINO,利用文本查询的语义丰富性定位视觉输入中的相关实体。
- 输入:指令和微调后的TinyLlama-1.1B模型处理后的文本。
- 输出:目标对象或区域的描述符,用于在相机流中定位目标。
- 功能:
- 解释指令以识别目标对象或地标。
- 使用Grounding DINO在相机流中定位这些目标。
- 根据无人机与检测到的实体之间的空间关系生成基于语义的子目标。
终止条件
- 重要性:准确判断何时终止导航任务与执行路径本身同等重要。过早或过晚终止可能导致无人机悬停、漂移或错过目标位置。
- 终止逻辑:
- 目标对象检测:使用Grounding DINO确认当前视野中是否存在指令中指定的目标对象或地标。
- 接近度检查:使用预定义的空间阈值验证无人机是否在目标的可接受范围内。
- 指令满足:验证从指令中派生的子目标是否已成功执行。
- 实现:终止逻辑集成在ROS 2控制堆栈中,确保任务结束时无人机状态的安全处理,并为未来扩展(如用户发起的停止信号或任务失败时的动态重新规划)提供支持。
实验
实验设置
- 硬件:在配备Nvidia GTX 1650 GPU的笔记本电脑上运行,模拟真实无人机配备的计算能力。
- 模拟器:使用Gazebo Garden与ROS 2进行仿真,无人机配备Pixhawk飞行控制器和底部安装的单目相机。
- 评估指标:使用成功完成任务的比例(Success Rate, SR)和路径效率(Success Rate Weighted by Inverse Path Length, SPL)进行评估。
评估场景
实验在四个不同场景中进行,每个场景包含15个不同的导航任务:
- 仓库
- 公园
- 房屋社区
- 办公室
基线方法
- DEPS:使用LLM进行中间推理,通过描述环境、解释子目标、规划候选动作并选择可行计划。
- VLMNav:使用Gemini 2.0 Flash作为零样本和端到端的语言条件导航策略。
实验结果

- UAV-VLN在所有场景中的表现均优于基线方法,显示出更高的成功完成任务的比例和路径效率。
- 例如,在“公园”场景中,UAV-VLN的成功率达到93.33%,路径效率为0.0792,而DEPS的成功率为86.67%,路径效率为0.0733;VLMNav的成功率为73.33%,路径效率为0.0755。
消融研究
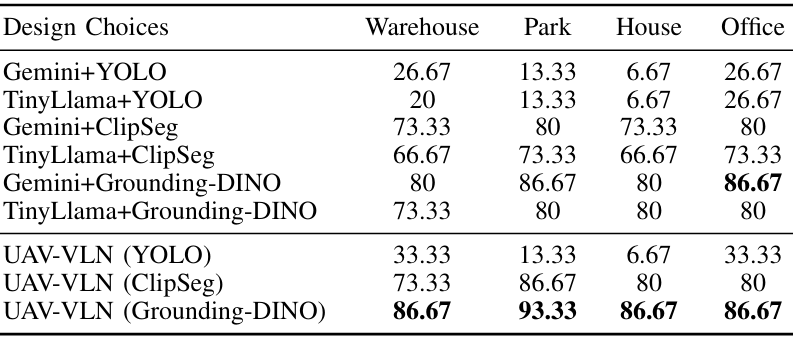
- 不同LLM和视觉模型的组合:实验结果表明,使用开放词汇模型(如CLIPSeg和Grounding DINO)比封闭词汇模型(如YOLO)表现更好,能够更好地泛化到不同场景。
- 微调的重要性:微调后的TinyLlama-1.1B模型在所有场景中均优于未微调的模型,强调了针对无人机任务定制语言模型的重要性。
结论与未来工作
- UAV-VLN通过结合微调的大型语言模型的语义推理能力和开放词汇视觉定位,显著提高了指令遵循准确性和路径效率,能够在复杂动态环境中实现稳健的导航。
- 未来工作计划将导航历史和轻量级语义映射纳入系统,帮助无人机进行全局推理,避免冗余探索并规划更高效的路径,使UAV-VLN系统更接近于在具有挑战性的开放世界环境中实现真正可扩展和终身导航的目标。
