并发编程之并发容器类
并发编程之并发容器类
Collection介绍
JDK中存储单个元素的容器类有:List、Set、Queue
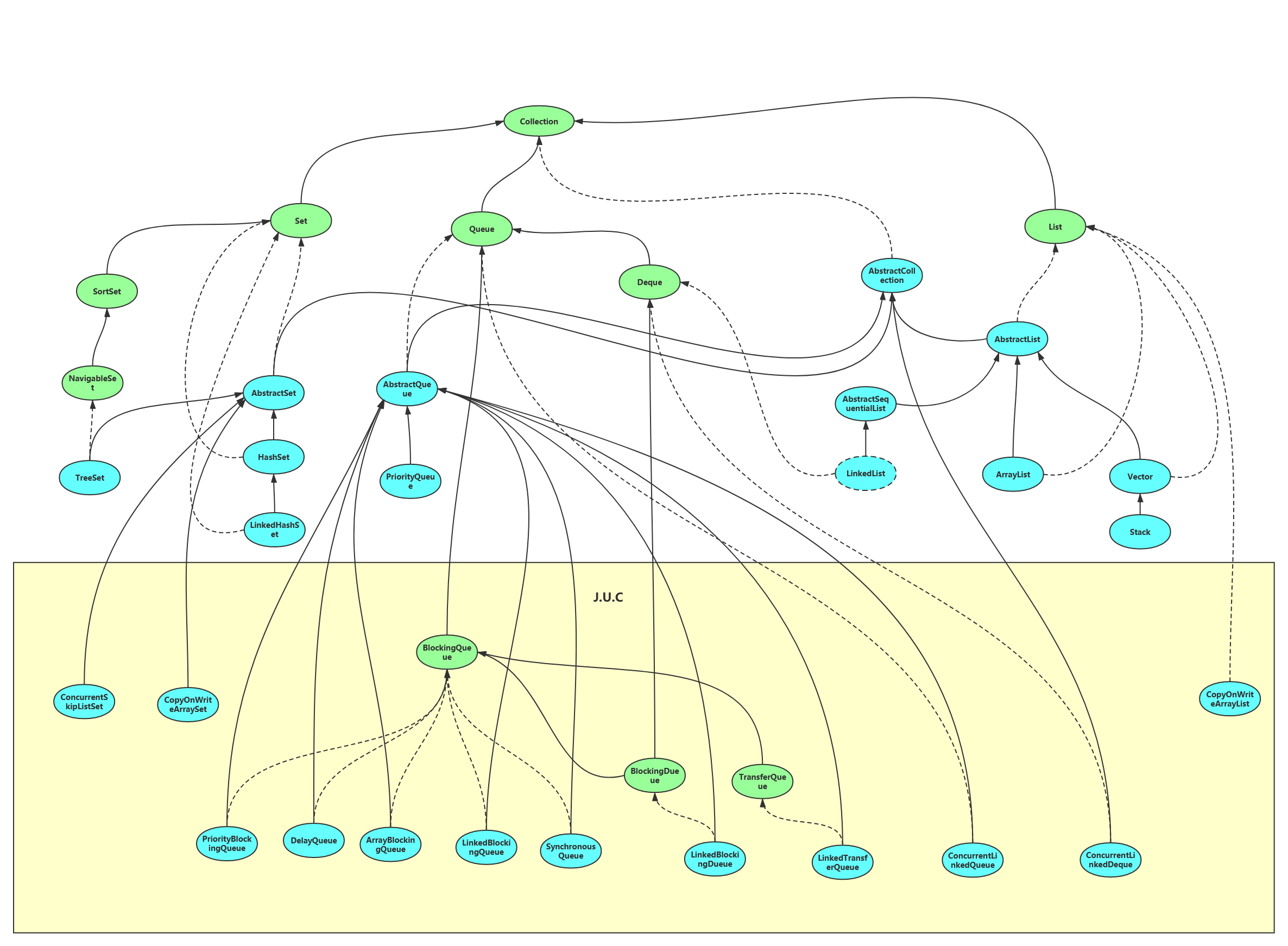
List
CopyOnWriteArrayList
CopyOnWriteArrayList容器即写时复制的容器
和ArrayList比较,优点是并发安全,缺点有两个:
1、 多了内存占用: 写数据是copy一份完整的数据,单独进行操作。占用双份内存。
2、 数据一致性: 数据写完之后,其他线程不一定是马上读取到最新内容。
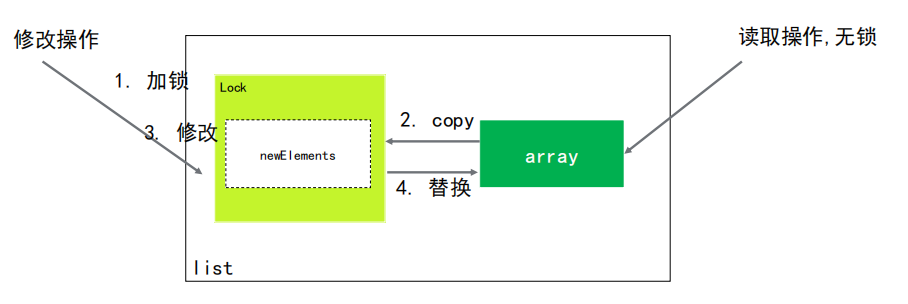
CopyOnWriteArrayList使用
public class ListDemo {public static void main(String args[]){ListDemo demo = new ListDemo();//demo.simple();demo.copyOnWrite();}public void simple(){ArrayList<String> list = new ArrayList<>();list.add("1");list.add("2");list.add("3");list.add("4");list.add("5");list.add("6");System.out.println(list);// 非线程安全,不允许边修改边遍历new Thread(()->{long s = System.currentTimeMillis();for(;System.currentTimeMillis() - s < 2000;) {list.add("99");}}).start();new Thread(()->{list.forEach((e)->{System.out.println(e);});}).start();}public void copyOnWrite(){// 线程安全CopyOnWriteArrayList<String> list = new CopyOnWriteArrayList<>();new Thread(()->{long s = System.currentTimeMillis();for(;System.currentTimeMillis() - s < 2000;) {list.add("99");}}).start();new Thread(()->{list.forEach((e)->{System.out.println(e);});/*long s = System.currentTimeMillis();for(;System.currentTimeMillis() - s < 2000;) {list.forEach((e)->{System.out.println(e);});}*/}).start();}
}
CopyOnWriteArrayList源码
/*** Creates an empty list.*创建一个空的数组*/
public CopyOnWriteArrayList() {setArray(new Object[0]);
}/*** Appends the specified element to the end of this list.** @param e element to be appended to this list* @return {@code true} (as specified by {@link Collection#add})*/
public boolean add(E e) {final ReentrantLock lock = this.lock;lock.lock();//获取锁try {Object[] elements = getArray();int len = elements.length;Object[] newElements = Arrays.copyOf(elements, len + 1);//复制一个新的数组newElements[len] = e;setArray(newElements);return true;} finally {lock.unlock();//释放锁}
}/*** Replaces the element at the specified position in this list with the* specified element.** @throws IndexOutOfBoundsException {@inheritDoc}*/public E set(int index, E element) {final ReentrantLock lock = this.lock;lock.lock();try {Object[] elements = getArray();E oldValue = get(elements, index);if (oldValue != element) {int len = elements.length;Object[] newElements = Arrays.copyOf(elements, len);newElements[index] = element;setArray(newElements);} else {// Not quite a no-op; ensures volatile write semanticssetArray(elements);}return oldValue;} finally {lock.unlock();}}public void forEach(Consumer<? super E> action) {if (action == null) throw new NullPointerException();Object[] elements = getArray();int len = elements.length;for (int i = 0; i < len; ++i) {@SuppressWarnings("unchecked") E e = (E) elements[i];action.accept(e);}}
Set
CopyOnWriteArraySet和ConcurrentSkipListSet
Set和List重要区别:不重复
| 实现 | 原理 | 特点 |
|---|---|---|
| HashSet | 基于HashMap实现 | 非线程安全 |
| CopyOnWriteArraySet | 基于CopyOnWriteArrayList实现 | 线程安全 |
| ConcurrentSkipListSet | 基于ConcurrentSkipListMap实现 | 线程安全,有序,查询快 |
CopyOnWriteArraySet和ConcurrentSkipListSet使用
public class SetDemo {public static void main(String args[]){SetDemo demo = new SetDemo();//demo.hashset();//demo.copyOnWrite();demo.concurrentSkip();}public void hashset() {// 线程不安全hashsetSet<String> set = new HashSet<>();set.add("set");set.add("set");System.out.println(set.size());set.remove("set");}public void copyOnWrite() {// 线程安全实现,写时复制CopyOnWriteArraySet<String> cowas = new CopyOnWriteArraySet<>();cowas.add("CopyOnWriteArraySet");cowas.add("CopyOnWriteArraySet");System.out.println(cowas.size());}public void concurrentSkip() {// 线程安全实现,casConcurrentSkipListSet<Integer> csls = new ConcurrentSkipListSet<>();Random random = new Random();for(int i = 0; i < 100; i++) {csls.add(random.nextInt(100));}System.out.println(csls.size()); // 为什么有时候不是100?System.out.println(csls);// 应用场合:一致性Hash算法、找一个距离x最近的数字,大于、小于// 小等于System.out.println(csls.lower(50));System.out.println(csls.floor(50));// 大等于System.out.println(csls.higher(50));System.out.println(csls.ceiling(50));// 倒序System.out.println(csls.descendingSet());// 线程安全/*new Thread(()->{long s = System.currentTimeMillis();for(;System.currentTimeMillis() - s < 2000;) {csls.add(random.nextInt(100));}}).start();new Thread(()->{csls.forEach((e)->{System.out.println(e);});}).start();*/}
}
Queue
Queue介绍
| 队列 | 描述 |
|---|---|
| ArrayBlockingQueue | 由数组构成的有界阻塞队列 |
| LinkedBlockingQueue | 由链表构成的无界面阻塞队列 |
| PriorityBlockingQueue | 支持优先等级的无解阻塞队列 |
| SynchronousQueue | 不存储元素的阻塞队列-也叫同步队列 |
| DelayQueue | 由优先等级队列构成的延时无界阻塞队列 |
| LinkedTransferQueue | 由链表组成的透传无界阻塞队列 |
| LinkedBlockingDeque | 由链表构成的双向无界阻塞队列 |
ConcurrentLinkedQueue | 一个非阻塞的基于链表的无界线程安全队列 |
Queue API
Queue –队列数据结构的实现。分为阻塞队列和非阻塞队列。下列的put、take,为阻塞队列特有方法
| 方法 | 作用 | 描述 |
|---|---|---|
| add | 添加一个元素 | 如果队列已满,则抛出一个IllegalStateException异常 |
| offer | 添加一个元素并返回true | 如果队列已满,则返回false |
put | 添加一个元素 | 如果队列满,则阻塞 |
| remove | 移除并返回队列头部的元素 | 如果队列为空,则抛出一个NoSuchElementException异常 |
| poll | 移除并返问队列头部的元素 | 如果队列为空,则返回null |
take | 移除并返回队列头部的元素 | 如果队列为空,则阻塞 |
| peek | 返回队列头部的元素 | 如果队列为空,则返回null |
| element | 返回队列头部的元素 | 如果队列为空,则抛出一个NoSuchElementException异常 |
ArrayBlockingQueue
// 指定容量大小、采用公平锁,默认是非公平锁。公平锁保证添加移除操作安装FIFO的顺序。
final ArrayBlockingQueue<String> abq = new ArrayBlockingQueue<String>(capacity, true);
LinkedBlockingQueue
public class LinkedBlockingQueueTest {public static void main(String[] args) throws Exception {LinkedBlockingQueue queue = new LinkedBlockingQueue();// 生产者扔数据queue.add("1");queue.offer("2");queue.offer("3", 2, TimeUnit.SECONDS);queue.put("2");// 消费者取数据System.out.println(queue.remove());System.out.println(queue.poll());System.out.println(queue.poll(2, TimeUnit.SECONDS));System.out.println(queue.take());}
}
PriorityBlockingQueueDemo
PriorityBlockingQueueDemo demo = new PriorityBlockingQueueDemo();
实例一
PriorityBlockingQueueDemo添加字符串,默认实现了Comparable的compareTo方法,PriorityBlockingQueueDemo使用String自带的compareTo方法进行优先级排序
public static void main(String[] args) {PriorityBlockingQueueDemo demo = new PriorityBlockingQueueDemo();demo.test1();
// demo.chooseFriend();
// demo.baiduNetdisk();}public void test1(){PriorityBlockingQueue<String> queue = new PriorityBlockingQueue<>(3);queue.put("48");queue.put("01");queue.put("12");queue.put("27");queue.put("31");for (;queue.size()>0;){try {System.out.println(queue.take());} catch (InterruptedException e) {e.printStackTrace();}}}
//结果
01
12
27
31
48
实例二
PriorityBlockingQueueDemo添加对象,使用PriorityBlockingQueueDemo构造函数中传入的Comparator比较器进行优先级排序
class BoyFriend{public int city; // 几线城市public int houseProperty; // 房产面积public int carPrice; // 车子public String name; // 名字public BoyFriend(int city, int houseProperty, int carPrice, String name) {this.city = city;this.houseProperty = houseProperty;this.carPrice = carPrice;this.name = name;}
}public void chooseFriend() {// 按照指定的排序方式进行排列男友的优先级PriorityBlockingQueue<BoyFriend> queue =new PriorityBlockingQueue<BoyFriend>(5, (BoyFriend o1, BoyFriend o2) -> {// 根据总资产,综合排序,越有钱的排在越前面int num1 = o1.houseProperty + o1.carPrice;int num2 = o2.houseProperty + o2.carPrice;if(o1.city < o2.city) {return 1;}else if(o1.city > o2.city) {return -1;} else {if (num1 > num2)return -1;else if (num1 == num2)return 0;elsereturn 1;}});queue.put(new BoyFriend(1, 80, 200000, "john"));queue.put(new BoyFriend(2, 120, 100000, "emily"));queue.put(new BoyFriend(3, 200, 0, "tom"));for (;queue.size()>0;){try {System.out.println(queue.take().name);} catch (InterruptedException e) {e.printStackTrace();}}}
实例三
public static void main(String[] args) {PriorityBlockingQueueDemo demo = new PriorityBlockingQueueDemo();
// demo.test1();
// demo.chooseFriend();demo.baiduNetdisk();}/*** 线程池实现,优先级队列模拟百度网盘下载任务*/
public void baiduNetdisk() {// 模拟百度网盘上传下载任务// 线程池中的runnalbe接口,无法通过Comparator,但是可以通过默认的Comparable接口来指定优先等级ThreadPoolExecutor threadPoolExecutor = new ThreadPoolExecutor(1, 1, 60L, TimeUnit.SECONDS,new PriorityBlockingQueue<Runnable>() );new Thread(()->{long s = System.currentTimeMillis();for(;System.currentTimeMillis() - s < 1000;) {// 下载太慢了?你的问题,充值可以解决。Task task = new Task(3, ()->{System.out.println("task");});threadPoolExecutor.execute(task);}}).start();new Thread(()->{long s = System.currentTimeMillis();for(;System.currentTimeMillis() - s < 1000;) {Task vipTask = new Task(2, ()->{System.out.println("vip task");});threadPoolExecutor.execute(vipTask);}}).start();new Thread(()->{long s = System.currentTimeMillis();for(;System.currentTimeMillis() - s < 1000;) {Task svipTask = new Task(1, ()->{System.out.println("svip task");});threadPoolExecutor.execute(svipTask);}}).start();}static class Task implements Runnable, Comparable<Task> {private final static AtomicInteger number = new AtomicInteger();private int priority;private Runnable job;private int sequence;public Task(int priority, Runnable job) {this.priority = priority;this.job = job;this.sequence = number.incrementAndGet();}@Overridepublic void run() {job.run();System.out.println("priority: "+priority+" sequence: "+sequence);System.out.println();// 为更好的观赏输出效果,停留1秒LockSupport.parkNanos(TimeUnit.SECONDS.toNanos(1));}@Overridepublic int compareTo(Task o) {//int num1 = this.priority;int num2 = o.priority;if (num1 > num2)return 1;else if (num1 == num2)return this.sequence > o.sequence ? 1 : -1;elsereturn -1;}
}
SynchronousQueue
简介
同步队列:
虽然它叫队列,但是它没有容量,只能存一个数据,这个数据出来了,其它数据才能加进去,如果还没有数据就去拿,那么就会阻塞,直到加进去数据。
非公平模式 TransferStack (以栈结构实现LIFO 后进先出,非公平的)
公平模式 TransferQueue (以队列结构实现FIFO 先进先出,公平)
一种是通过栈实现的,一种是通过队列实现的
/**
一个不存储元素的神奇队列<br/>
两个线程间的非异步化的场景
1、put时会阻塞,直到被get
2、take会阻塞,直到取到元素3、offer的元素可能会丢失
4、poll取不到元素,就返回null,如果正好有take被阻塞,可以取到
5、peek 永远只能取到null,不能让take结束阻塞*/public class SynchronousQueueDemo {public static void main(String args[]) throws InterruptedException {SynchronousQueue<String> syncQueue = new SynchronousQueue<>();new Thread(()->{try {System.out.println("begain to put...");syncQueue.put("fasdfads");System.out.println("put done...");} catch (InterruptedException e) {e.printStackTrace();}}).start();Thread.sleep(3000);Object str = syncQueue.take();System.out.println(str);
/*Object str = syncQueue.poll();System.out.println(str);Object str = syncQueue.peek();System.out.println(str);
*/new Thread(()->{try {System.out.println("begain to take...");System.out.println(syncQueue.take());System.out.println("take done...");} catch (InterruptedException e) {e.printStackTrace();}}).start();Thread.sleep(3000);syncQueue.put("put value");new Thread(()->{try {System.out.println("begin to put...");syncQueue.put("put ele...");System.out.println("put done...");} catch (InterruptedException e) {e.printStackTrace();}}).start();Thread.sleep(3000L);String ele = syncQueue.peek();System.out.println("peek " + ele);Thread.sleep(3000L);String ele1 = syncQueue.poll();System.out.println("poll:" + ele1);}
}
DelayQueue
public static void main(String[] args) {DelayQueueDemo demo = new DelayQueueDemo();demo.test();
// demo.scheduleThreadPool();}public void test() {DelayQueue<DelayQueueDemo.DelayJob> jobDelayQue = new DelayQueue<DelayQueueDemo.DelayJob>();jobDelayQue.add(new DelayJob((System.currentTimeMillis() + 5000), ()->{System.out.println("5");}));jobDelayQue.add(new DelayJob((System.currentTimeMillis() + 15000), ()->{System.out.println("15");}));jobDelayQue.add(new DelayJob((System.currentTimeMillis() + 25000), ()->{System.out.println("25");}));new Thread(()->{for(;jobDelayQue.size() > 0;) {DelayJob j = jobDelayQue.poll();if(j != null) {j.run();}else {System.out.println("null");}LockSupport.parkNanos(TimeUnit.SECONDS.toNanos(1));}}).start();}private static final AtomicInteger counter = new AtomicInteger(0);class DelayJob implements Delayed, Runnable {private long time; // 毫秒private long sequence;private Runnable task;public DelayJob(long delay, Runnable task) {this.sequence = counter.incrementAndGet();this.time = delay;this.task = task;}@Overridepublic int compareTo(Delayed o) {if(o == this) return 0;if(o instanceof DelayJob) {DelayJob other = (DelayJob) o;long diff = time - other.time;if(diff < 0) return -1;else if(diff > 0) return 1;else if(sequence < other.sequence) return -1;else return 1;}long d = getDelay(TimeUnit.NANOSECONDS) - o.getDelay(TimeUnit.NANOSECONDS);return (d == 0) ? 0 : (d < 0) ? -1 : 1;}@Overridepublic long getDelay(TimeUnit unit) {long diff = time - System.currentTimeMillis();return unit.convert(diff, TimeUnit.MILLISECONDS);}@Overridepublic void run() {task.run();System.out.println(new Date(time));}}
LinkedTransferQueue
LinkedTransferQueue是一种无界阻塞队列,底层基于单链表实现;
LinkedTransferQueue中的结点有两种类型:数据结点、请求结点;
LinkedTransferQueue基于无锁算法实现。
public class LinkedTransferQueueDemo {public static void main(String[] args) {LinkedTransferQueueDemo demo = new LinkedTransferQueueDemo();demo.test();}public void test() {LinkedTransferQueue<String> queue = new LinkedTransferQueue<String>();queue.add("1");queue.add("2");queue.add("3");new Thread(()->{try {while(true) {System.out.println(queue.take());LockSupport.parkNanos(TimeUnit.SECONDS.toNanos(3));}} catch (InterruptedException e) {e.printStackTrace();}}).start();new Thread(()->{try {queue.put("put");// 一定要等到消费者读取到值才返回queue.transfer("transfer");System.out.println("done!");} catch (InterruptedException e) {e.printStackTrace();}}).start();}
}
LinkedBlockingDeque
/*** 双端队列是一种具有队列和栈的性质的数据结构,双端队列中的元素可以从两端弹出插入。<br/>* juc下双端队列有:LinkedBlockingDeque、ArrayBlockingDeque、ConcurrentLinkedDeque三种。* 这里以LinkedBlockingDeque为例进行演示。**/
public class LinkedBlockingDequeDemo {public static void main(String[] args) {LinkedBlockingDequeDemo demo = new LinkedBlockingDequeDemo();demo.simple();}public void simple() {// 链表双端队列LinkedBlockingDeque<String> deque = new LinkedBlockingDeque<String>();deque.addLast("l");deque.addFirst("f");deque.add("a"); // 等于 addLast,建议使用带有后缀的方法以免弄混淆deque.offerFirst("");deque.offerLast("");try {deque.putFirst("");deque.putLast("");} catch (InterruptedException e) {e.printStackTrace();}System.out.println(deque);System.out.println("===========================");deque.removeFirst();System.out.println(deque);deque.removeLast();System.out.println(deque);}public void limitOutput() {LinkedBlockingDeque<String> limitOUtputDeque = new LinkedBlockingDeque<String>();// 限制输出// 可以在头尾部插入limitOUtputDeque.addFirst("f");limitOUtputDeque.addLast("l");// 只允许在尾部移除String item = limitOUtputDeque.removeLast();// 也可以限制在某一端插入,两端输出}
}
ConcurrentLinkedQueue
- ①、 非阻塞算法
ConcurrentLinkedQueue 使用的是 Michael & Scott 算法(Michael & Scott 算法的提出者是 Maged M. Michael 和 Michael L. Scott)。Michael & Scott 是无锁算法,允许多个线程并发访问队列,而无需显式的锁(通过使用 CAS 等原子操作保证线程安全),从而减少了锁竞争和上下文切换的开销。 - ②、 线程安全
该队列是线程安全的,允许多个线程同时进行插入和删除操作。所有的操作(如插入、删除和遍历)都是原子操作,不会出现线程间的竞态条件。 - ③、高性能
由于采用了非阻塞算法,ConcurrentLinkedQueue 在高并发环境下性能优越,特别适用于需要高吞吐量的场景。
public class ConcurrentLinkedQueueDemo {public static void main(String[] args) {ConcurrentLinkedQueueDemo demo = new ConcurrentLinkedQueueDemo();demo.test();}public void test() {ConcurrentLinkedQueue<String> clq = new ConcurrentLinkedQueue<String>();new Thread(()->{long s = System.currentTimeMillis();for(;System.currentTimeMillis() - s < 2000;) {// 不阻塞线程,返回结果是否操作成功boolean added = clq.add("1");}}).start();new Thread(()->{long s = System.currentTimeMillis();for(;System.currentTimeMillis() - s < 2000;) {// 不阻塞线程,返回结果是否操作成功boolean offered = clq.offer("2");}}).start();new Thread(()->{long s = System.currentTimeMillis();for(;System.currentTimeMillis() - s < 2000;) {// 空队列,获取不到元素返回nullSystem.out.println(clq.poll());// System.out.println(clq.remove());}}).start();}
}
ArrayBlockingQueue与LinkedBlockingQueue
ArrayBlockingQueue内部成员
-
Object[] items :数组,意味着连续的地址空间,可以重复使用。
-
takeIndex、putIndex:使用下标来进行控制插入、删除访问。
-
Lock lock:插入、删除操作都使用的是同一把锁
-
线程等待条件通知队列:通过同一把锁获得Condition notEmpty和Condition notFull
LinkedBlockingQueue内部维护成员
- Node head、Node last:链表
- Lock takeLock、putLock:两把锁
- 线程等待条件通知队列:分别通过两把锁获得Condition notEmpty=takeLock.newCondition();和Condition notFull =putLock.newCondition()
ArrayBlockingQueue与LinkedBlockingQueue两者差异
-
JVM GC的影响
存储的容器,一个是数组,一个是链表。
数组地址空间连续,可以重复使用,不会产生额外的对象和内存空间
链表需要通过Node对象来进行连接,删除、新增都会产出额外的对象
-
锁机制
一个很明显的区别,ArrayBlockingQueue是一把锁,LinkedBlockingQueue是两把锁
ArrayBlockingQueue,锁有公平锁和非公平锁区分,默认情况是非公平锁,如果你需要保证插入、移除操作都是FIFO,那传入true,创建公平锁
LinkedBlockingQueue,是两把锁,无法做到FIIO
应用场景
表象:一个是队列、一个是无界队列,实质上是应用场景的不同
ArrayBlockingQueue:适用于高效简单,能够知道任务的并发数量
LinkedBlockingQueue:使用于不知道任务并发数量,任务操作比较耗时的,批量场景
抽象出BlockingQueue的共性
参与角色
-
锁:lock
-
容器:数组、链表
-
通知队列:condition、用来装等待通知的线程
-
线程:插入(生产者)线程、移除(消费者)线程
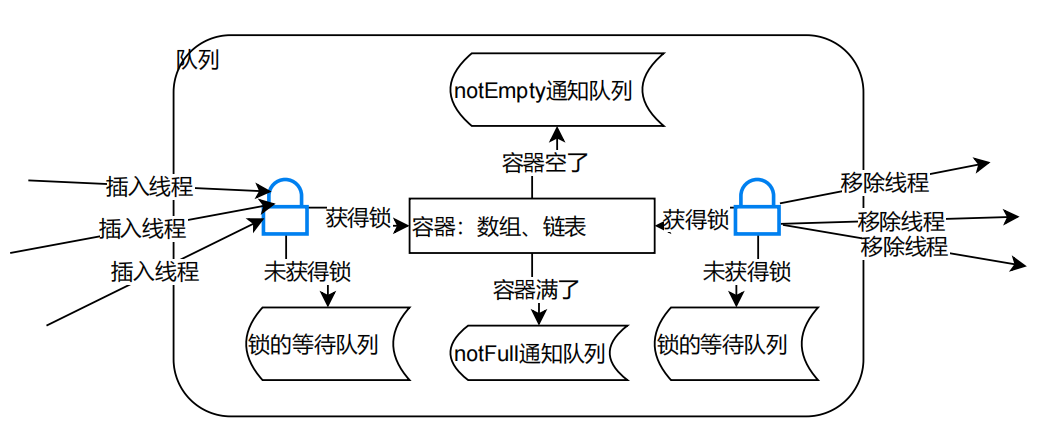
不同的Queue,几个不同的点
- 容器
- 锁
- 通知队列
不同Queue的不同行为
- 锁:一把锁、两把锁、公平锁、非公平锁之分、CAS
- 容器:FIFO、不是按照FIFO进行的呢?有限等级、延时、同步(非公平Stack LIFO)、双端队列两边都可以移除和插入
- 线程:抛出异常、返回特殊值、超时等待、阻塞、非阻塞
- 线程通知队列:容器空满问题、无同期插入移除线程互相等待
Map
Map介绍
JDK中存储两个个元素的并发容器类—Map,如图,JDK中的5个Map接口,6个常用实现类。
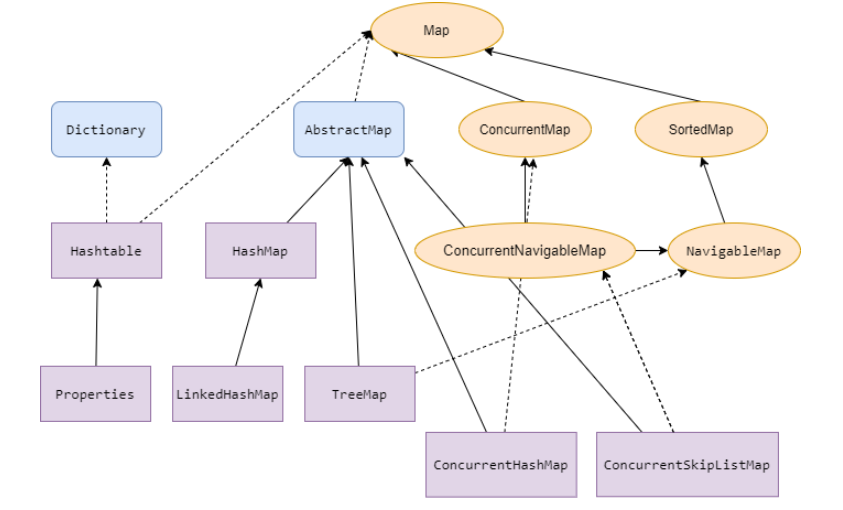
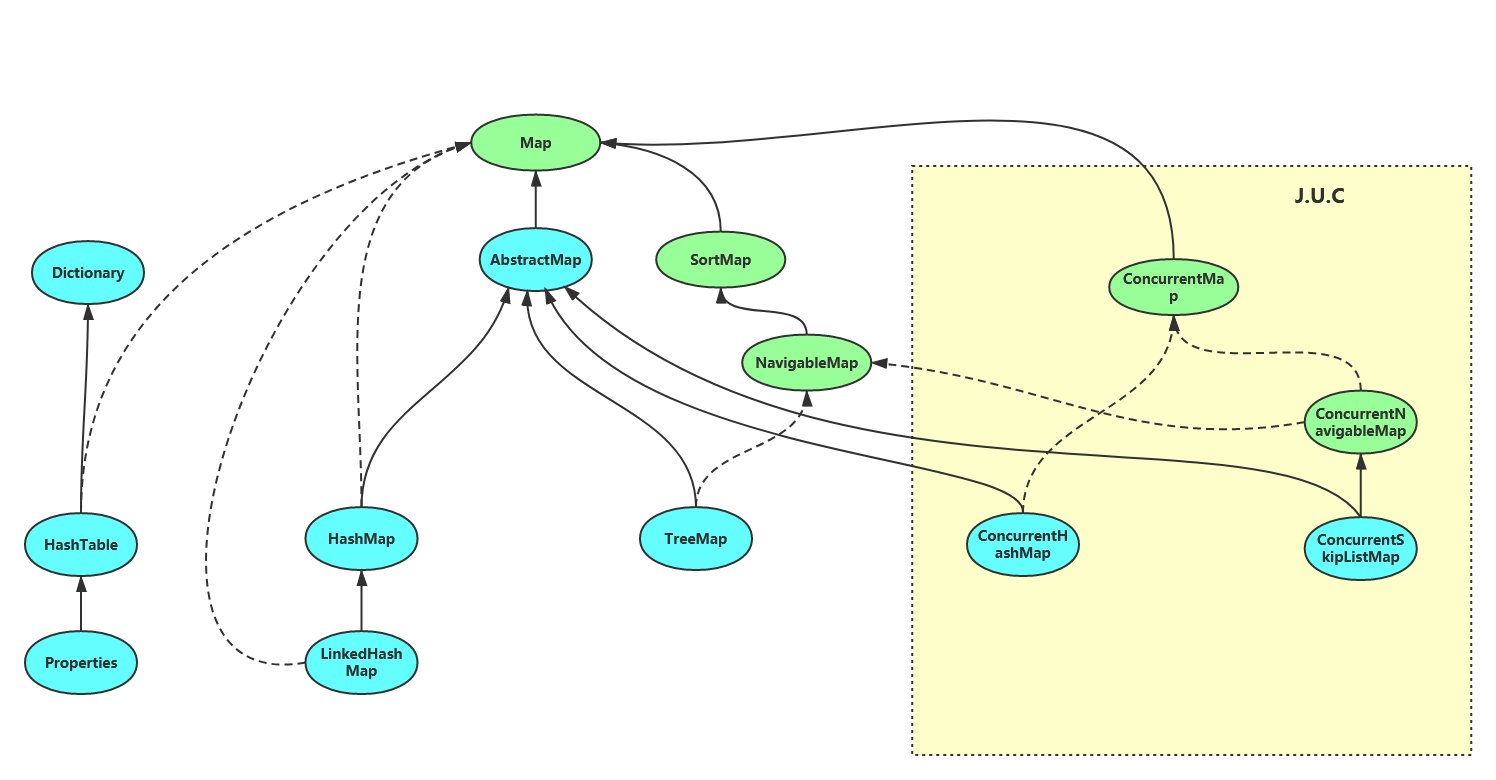
Map总结
| 6个常用Map | 有序 | 线程安全 | 描述 |
|---|---|---|---|
| HashMap | 否 | 否 | 一个高效的非线程安全的Map实现 |
| HashTable | 否 | 是 | 一个线程安全的Map实现,但是效率比较低,JDK1.6后,被ConcurrentHashMap所替代。 |
| ConcurrentHashMap | 否 | 是 | 一个高效的线程安全的Map实现,为了高效,JDK1.6、1.7、1.8版本变动比较大。比如用来实现一个自己的缓存。 |
| LinkedHashMap | 是 | 否 | 遍历时可以根据插入顺序来遍历的HashMap |
| TreeMap | 是 | 否 | 基于红黑树实现的NavigableMap接口,基于Comparable接口的key自然排序(升序),也可以通过构造函数指定Compartor,来实现自己的排序。实现一致性Hash算法的重要数据结构 |
| ConcurrentSkipListMap | 是 | 是 | 最强大的一个Map,继承了所有Map接口的基因。是一个通过跳表实现的,线程安全的有序的哈希表,适用于高并发的场景。 |
HashMap
HashMap使用
public static void main(String[] args) {HashMapDemo demo = new HashMapDemo();demo.hashmap();//demo.linkedHashmap();//demo.hashtable();
}public void hashmap() {Map<String, String> map = new HashMap<String, String>();// Collections.synchronizedMap(map); // 这是一种保证hashmap线程安全的方式// 不能包含相同的key,相同key,value被替换,// 相同的value,可以被多个不同key映射,类似给相同的value打不同的标签。map.put("1", "2");map.put("1", "2");map.put("2", "2");map.put("3", "3");System.out.println(map.get("1"));System.out.println(map.get("2"));//map.forEach(());// 并发安全问题new Thread(()->{long s = System.currentTimeMillis();for(;System.currentTimeMillis() - s < 500;) {String data = String.valueOf(System.currentTimeMillis());map.put(data, data);}}).start();new Thread(()->{Set<Entry<String, String>> entrySet = map.entrySet();entrySet.forEach((e)->{System.out.println("key: "+e.getKey()+" value: "+e.getValue());});}).start();/**//*// jdk1.8 新增功能// 当key不存在时,value才能put成功,并返回put前的value值String oldVlue = map.putIfAbsent("1", "putIfAbsent value");System.out.println("1 putIfAbsent: "+oldVlue);// 混合: 0不存在,put新值,存在时,结合老值String mv = map.merge("0", "merge value", String::concat);System.out.println("merge 0 : "+ mv);mv = map.merge("1", " merge value", (ov, nv)->ov+nv);System.out.println("merge 1 : "+ mv);// 将key为2的值取出来进行逻辑计算,比如,加法String cv = map.compute("2", (k, ov)-> ov + " compute");System.out.println("2 compute: "+cv);// compute()有空指针的风险。// key不存在时,才compute,// 在涉及到用key来计算val时才有使用价值。否则可以用putIfAbsent代替cv = map.computeIfAbsent("0", (k)-> "0 computeIfAbsent");System.out.println("0 computeIfAbsent: "+cv);// key存在时才compute()cv = map.computeIfPresent("2", (k,v)-> v+" computeIfPresent");System.out.println("2 computeIfPresent: "+cv);*/
}
HashMap思考
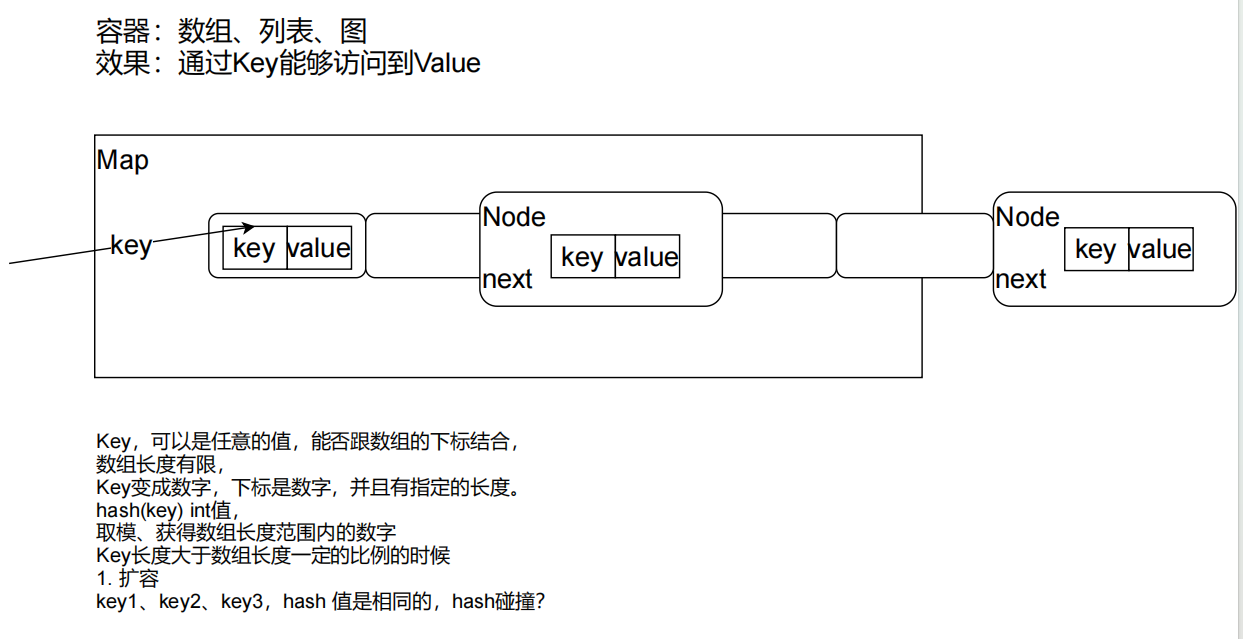
HashTable
HashTable使用
public static void main(String[] args) {HashMapDemo demo = new HashMapDemo();//demo.hashmap();//demo.linkedHashmap();demo.hashtable();
}
public void hashtable() {Hashtable<String, String> table = new Hashtable<String, String>();new Thread(()->{long s = System.currentTimeMillis();for(;System.currentTimeMillis() - s < 500;) {String data = String.valueOf(System.currentTimeMillis());table.put(data, data);}}).start();new Thread(()->{Set<Entry<String, String>> entrySet = table.entrySet();entrySet.forEach((e)->{System.out.println("key: "+e.getKey()+" value: "+e.getValue());});}).start();}
LinkedHashMap
LinkedHashMap使用
public static void main(String[] args) {HashMapDemo demo = new HashMapDemo();//demo.hashmap();demo.linkedHashmap();//demo.hashtable();
}
public void linkedHashmap() {LinkedHashMap<String, Integer> linkedMap = new LinkedHashMap<String, Integer>();linkedMap.put("3", 1);linkedMap.put("2", 1);linkedMap.put("1", 1);Set<Entry<String, Integer>> entrySet = linkedMap.entrySet();entrySet.forEach((e)->{System.out.println("key: "+e.getKey()+" value: "+e.getValue());});
}
TreeMap
使用
/*** 非线程安全的有序map:treeMap**/
public class TreeMapDemo {public static void main(String[] args) {TreeMapDemo demo = new TreeMapDemo();//demo.sortedMap();demo.navigableMap();//demo.circle();}public void sortedMap() {SortedMap<String, Integer> sortedMap = new TreeMap<String, Integer>();sortedMap = new TreeMap<String, Integer>((k1, k2)->{//System.out.println("k1: "+k1+" k2: "+k2);return k1.compareTo(k2);});sortedMap.put("key_3", 3);sortedMap.put("key_2", 2);sortedMap.put("key_5", 5);sortedMap.put("key_1", 1);sortedMap.put("key_4", 4);Set<String> keys = sortedMap.keySet();keys.forEach((k)->System.out.println(k));System.out.println();System.out.println("firstKey: "+sortedMap.firstKey());System.out.println("lastKey: "+sortedMap.lastKey());// 为遍历条目而设计,返回的是集合System.out.println();System.out.println("subMap");sortedMap.subMap("key_2", "key_4").forEach((k, v)->printEntry(k,v));System.out.println();System.out.println("tailMap");sortedMap.tailMap("key_3").forEach((k,v)->printEntry(k,v));System.out.println();System.out.println("headMap");sortedMap.headMap("key_5").forEach((k,v)->printEntry(k,v));}public void navigableMap() {NavigableMap<Integer, String> navigableMap = new TreeMap<Integer, String>();navigableMap.put(1, "one");navigableMap.put(2, "two");navigableMap.put(3, "three");navigableMap.put(4, "four");navigableMap.put(5, "five");navigableMap.put(6, "six");navigableMap.firstEntry();//navigableMap.pollFirstEntry();navigableMap.lastEntry();// 为查找定位附近的条目而设计,不返回集合// 小于3、小于等于3,即key靠近3的条目或者KeyEntry<Integer, String> entry = navigableMap.lowerEntry(3);navigableMap.floorEntry(3);navigableMap.lowerKey(3);navigableMap.floorKey(3);// 大于、大于等于4,即key靠近4的条目或者KeynavigableMap.ceilingEntry(4);navigableMap.higherEntry(4);navigableMap.ceilingKey(4);navigableMap.higherKey(4);// 如果需要遍历条目,使用返回集合方法:subMap、tailMap、headMap方法,返回结果有NavigableMap、SortedMap两种格式// 还可以指定是否包含起始、结束值。示例,从2到4,包含2不包含4的范围navigableMap.subMap(2, true, 4, false).forEach((k,v)->printEntry(k,v));// 返回倒序排列集合navigableMap.descendingMap();}public void printEntry(Object k, Object v) {System.out.println("key: "+k+" value: "+v);}}
ConcurrentHashMap
使用
public class ConcurrentHashMapDemo {public static void main(String[] args) {ConcurrentHashMapDemo demo = new ConcurrentHashMapDemo();demo.test();//demo.cache();}public void test() {Map<String, String> map = new ConcurrentHashMap<String, String>();// 不能包含相同的key,相同key,value被替换,// 相同的value,可以被多个不同key映射,类似给相同的value打不同的标签。map.put("1", "2");map.put("1", "2");map.put("2", "2");map.put("3", "3");System.out.println(map.get("1"));System.out.println(map.get("2"));// 并发安全问题new Thread(()->{long s = System.currentTimeMillis();for(;System.currentTimeMillis() - s < 500;) {String data = String.valueOf(System.currentTimeMillis());map.put(data, data);}}).start();new Thread(()->{Set<Entry<String, String>> entrySet = map.entrySet();entrySet.forEach((e)->{System.out.println("key: "+e.getKey()+" value: "+e.getValue());});}).start();/**/}
}
缓存
public class ConcurrentHashMapDemo {public static void main(String[] args) {ConcurrentHashMapDemo demo = new ConcurrentHashMapDemo();//demo.test();demo.cache();}public void cache() {// 将下面的数据缓存5秒钟MapCacheDemo mapCacheDemo = new MapCacheDemo();mapCacheDemo.add("uid_10001", "{1}", 5 * 1000);mapCacheDemo.add("uid_10002", "{2}", 5 * 1000);mapCacheDemo.add("uid_10003", "{3}", 5 * 1000);// 立马取出,值存在System.out.println("从缓存中取出值:" + mapCacheDemo.get("uid_10001"));// 5秒后再次获取LockSupport.parkNanos(TimeUnit.SECONDS.toNanos(5));System.out.println("5秒钟过后");System.out.println("从缓存中取出值:" + mapCacheDemo.get("uid_10001"));// 5秒后数据自动清除了~}
}// 用map实现一个简单的缓存功能
public class MapCacheDemo {// 使用 ConcurrentHashMap,线程安全的要求。// 使用SoftReference <Object> 作为映射值,因为软引用可以保证在抛出OutOfMemory之前,如果缺少内存,将删除引用的对象。// 在构造函数中,我创建了一个守护程序线程,每5秒扫描一次并清理过期的对象。private static final int CLEAN_UP_PERIOD_IN_SEC = 5;private final ConcurrentHashMap<String, SoftReference<CacheObject>> cache = new ConcurrentHashMap<>();public MapCacheDemo() {Thread cleanerThread = new Thread(() -> {while (!Thread.currentThread().isInterrupted()) {try {Thread.sleep(CLEAN_UP_PERIOD_IN_SEC * 1000);cache.entrySet().removeIf(entry -> Optional.ofNullable(entry.getValue()).map(SoftReference::get).map(CacheObject::isExpired).orElse(false));} catch (InterruptedException e) {Thread.currentThread().interrupt();}}});cleanerThread.setDaemon(true);cleanerThread.start();}public void add(String key, Object value, long periodInMillis) {if (key == null) {return;}if (value == null) {cache.remove(key);} else {long expiryTime = System.currentTimeMillis() + periodInMillis;cache.put(key, new SoftReference<>(new CacheObject(value, expiryTime)));}}public void remove(String key) {cache.remove(key);}public Object get(String key) {return Optional.ofNullable(cache.get(key)).map(SoftReference::get).filter(cacheObject -> !cacheObject.isExpired()).map(CacheObject::getValue).orElse(null);}public void clear() {cache.clear();}public long size() {return cache.entrySet().stream().filter(entry -> Optional.ofNullable(entry.getValue()).map(SoftReference::get).map(cacheObject -> !cacheObject.isExpired()).orElse(false)).count();}// 缓存对象valueprivate static class CacheObject {private Object value;private long expiryTime;private CacheObject(Object value, long expiryTime) {this.value = value;this.expiryTime = expiryTime;}boolean isExpired() {return System.currentTimeMillis() > expiryTime;}public Object getValue() {return value;}public void setValue(Object value) {this.value = value;}}
}
ConcurrentSkipListMap
使用
public class ConcurrentSkipListMapDemo {public static void main(String[] args) {ConcurrentSkipListMapDemo demo = new ConcurrentSkipListMapDemo();//demo.test();demo.findUnmarriedGril();}public void test() {// 最强大的一个Map,继承了所有Map接口的基因,大并发下线程安全的有序mapConcurrentSkipListMap<Integer, String> skipMap = new ConcurrentSkipListMap<Integer, String>();skipMap.put(1, "one");skipMap.put(2, "two");skipMap.put(3, "three");skipMap.put(4, "four");skipMap.put(5, "five");skipMap.put(6, "six");// 返回集合条目方法:subMap、headMap、tailMapSystem.out.println();System.out.println("tailMap");System.out.println(skipMap.tailMap(4));System.out.println(skipMap.tailMap(4, false));// 获得倒排序集合descendingMapskipMap.descendingMap();// 获得倒排序Key集合skipMap.descendingKeySet();}public void findUnmarriedGril() {ConcurrentSkipListMap<Integer, List<Persion>> skipMap = new ConcurrentSkipListMap<Integer, List<Persion>>();CountDownLatch latch = new CountDownLatch(2);new Thread(()->{Random random = new Random();for(int i = 0; i < 100000; i++) {char sex = random.nextInt(1) == 1 ? '1':'0';int age = random.nextInt(30);boolean m = random.nextInt(1) == 1 ? true : false;String name = sex == '1' ? "boy" : "gril";Persion p = new Persion(sex, age, m, name+"-"+i);List<Persion> ps = skipMap.get(age);if(ps == null) {ps = new CopyOnWriteArrayList<Persion>();skipMap.put(age, ps);}ps.add(p);}latch.countDown();}).start();new Thread(()->{Random random = new Random();for(int i = 0; i < 100000; i++) {char sex = random.nextInt(1) == 1 ? '1':'0';int age = random.nextInt(30);boolean m = random.nextInt(1) == 1 ? true : false;String name = sex == '1' ? "boy" : "gril";Persion p = new Persion(sex, age, m, name+"-"+i);List<Persion> ps = skipMap.get(age);if(ps == null) {ps = new CopyOnWriteArrayList<Persion>();skipMap.put(age, ps);}ps.add(p);}latch.countDown();}).start();try {latch.await();} catch (InterruptedException e) {e.printStackTrace();}AtomicInteger t = new AtomicInteger(0);skipMap.subMap(18, true, 25, true).forEach((k, e)->{Integer totalUnMarGirl = e.stream().map((x)->{if(x.isUnMarried() && x.isGril()) {return 1;}else {return 0;}}).reduce(0,(a,b)->a+b);t.getAndAdd(totalUnMarGirl);});System.out.println("20万人中,18-25岁间未婚女孩有 "+t.get()+" 个");}class Persion {char sex;int age;boolean married;String name;public Persion(char sex, int age, boolean married, String name) {this.sex = sex;this.age = age;this.married = married;this.name = name;}public boolean isUnMarried() {return !married;}public boolean isGril() {return sex == '0';}}
}
分布式下的负载均衡算法:一致性Hash算法
哈希指标
评估一个哈希算法的优劣,有如下指标,而一致性哈希全部满足:
- 均衡性(Balance):将关键字的哈希地址均匀地分布在地址空间中,使地址空间得到充分利用,这是设计哈希的一个基本特性。
- 单调性(Monotonicity): 单调性是指当地址空间增大时,通过哈希函数所得到的关键字的哈希地址也能映射的新的地址空间,而不是仅限于原先的地址空间。或等地址空间减少时,也是只能映射到有效的地址空间中。简单的哈希函数往往不能满足此性质。
- 分散性(Spread): 哈希经常用在分布式环境中,终端用户通过哈希函数将自己的内容存到不同的缓冲区。此时,终端有可能看不到所有的缓冲,而是只能看到其中的一部分。当终端希望通过哈希过程将内容映射到缓冲上时,由于不同终端所见的缓冲范围有可能不同,从而导致哈希的结果不一致,最终的结果是相同的内容被不同的终端映射到不同的缓冲区中。这种情况显然是应该避免的,因为它导致相同内容被存储到不同缓冲中去,降低了系统存储的效率。分散性的定义就是上述情况发生的严重程度。好的哈希算法应能够尽量避免不一致的情况发生,也就是尽量降低分散性。
- 负载(Load): 负载问题实际上是从另一个角度看待分散性问题。既然不同的终端可能将相同的内容映射到不同的缓冲区中,那么对于一个特定的缓冲区而言,也可能被不同的用户映射为不同的内容。与分散性一样,这种情况也是应当避免的,因此好的哈希算法应能够尽量降低缓冲的负荷。
一致性Hash算法介绍
在分布式系统中,数据存储和访问的均匀性、高可用性以及可扩展性一直是核心问题。一致性哈希算法(Consistent Hashing)是一种分布式算法,因其出色的分布式数据存储特性,被广泛应用于缓存、负载均衡、数据库分片等场景。主要用于解决缓存和负载均衡等问题。
产生背景
考虑这么一种场景:
我们有三台缓存服务器编号node0、node1、node2,现在有 3000 万个key,希望可以将这些个 key 均匀的缓存到三台机器上,你会想到什么方案呢?
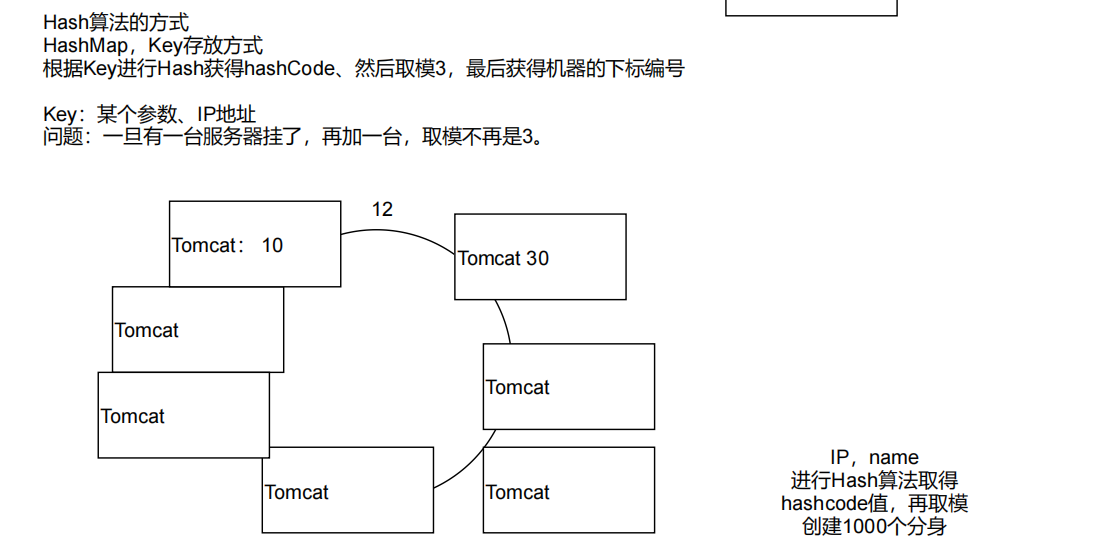
我们可能首先想到的方案是:取模算法hash(key)% N,即:对 key 进行 hash 运算后取模,N 是机器的数量;
这样,对 key 进行 hash 后的结果对 3 取模,得到的结果一定是 0、1 或者 2,正好对应服务器node0、node1、node2,存取数据直接找对应的服务器即可,简单粗暴,完全可以解决上述的问题;
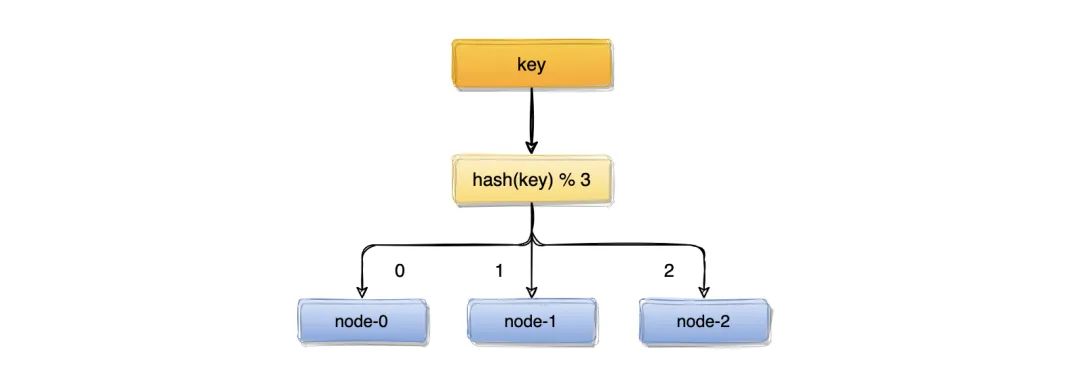
取模算法虽然使用简单,但对机器数量取模,在集群扩容和收缩时却有一定的局限性:因为在生产环境中根据业务量的大小,调整服务器数量是常有的事;
而服务器数量 N 发生变化后hash(key)% N计算的结果也会随之变化!
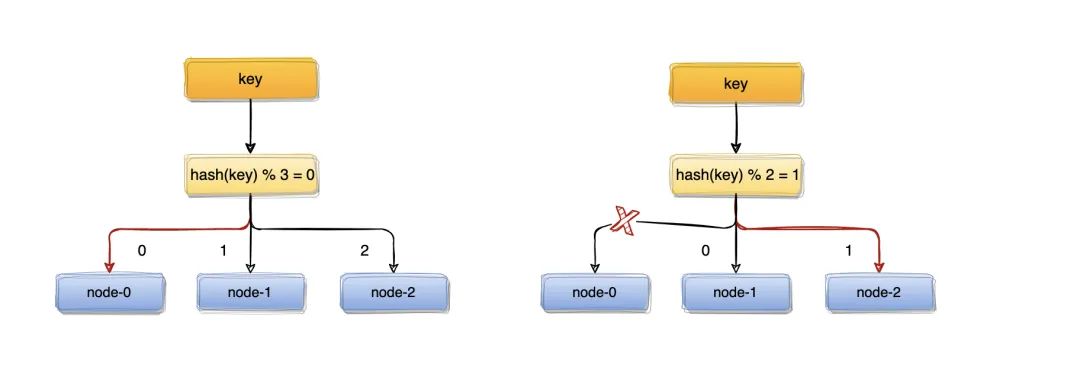
比如:一个服务器节点挂了,计算公式从hash(key)% 3变成了hash(key)% 2,结果会发生变化,此时想要访问一个 key,这个 key 的缓存位置大概率会发生改变,那么之前缓存 key 的数据也会失去作用与意义;
大量缓存在同一时间失效,造成缓存的雪崩,进而导致整个缓存系统的不可用,这基本上是不能接受的;
为了解决优化上述情况,一致性 hash 算法应运而生~
什么是一致性哈希算法
一致性哈希算法是一种用于分布式系统中的数据分片和负载均衡的算法。它将整个哈希空间划分为一个环,并且每个节点在这个环上都有一个对应的位置。当需要读写某个数据时,先将其进行哈希运算得到一个哈希值,然后根据这个哈希值在环上找到对应的节点,从而实现数据的定位。
一致性哈希算法的优点在于:当新增或删除节点时,只会影响到环上的一小部分节点,因此不会像传统的哈希算法那样造成大量的数据迁移和重新分片。同时,由于节点数较多,请求可以被更好地平均分配,从而实现了负载均衡的效果。
另外,一致性哈希算法还可以通过增加虚拟节点来解决节点不均衡的问题,从而进一步提高负载均衡的效果。
一致性哈希算法原理
一致性 hash 算法本质上也是一种取模算法;
不过,不同于上边按服务器数量取模,一致性 hash 是对固定值 2^32 取模;
1. hash 环
我们可以将这2^32个值抽象成一个圆环 ⭕️,圆环的正上方的点代表 0,顺时针排列,以此类推:1、2、3…直到2^32-1,而这个由 2 的 32 次方个点组成的圆环统称为hash环;
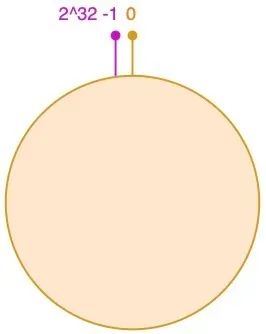
服务器映射到 hash 环
在对服务器进行映射时,使用hash(服务器ip)% 2^32,即:
使用服务器 IP 地址进行 hash 计算,用哈希后的结果对2^32取模,结果一定是一个 0 到2^32-1之间的整数;
而这个整数映射在 hash 环上的位置代表了一个服务器,依次将node0、node1、node2三个缓存服务器映射到 hash 环上;
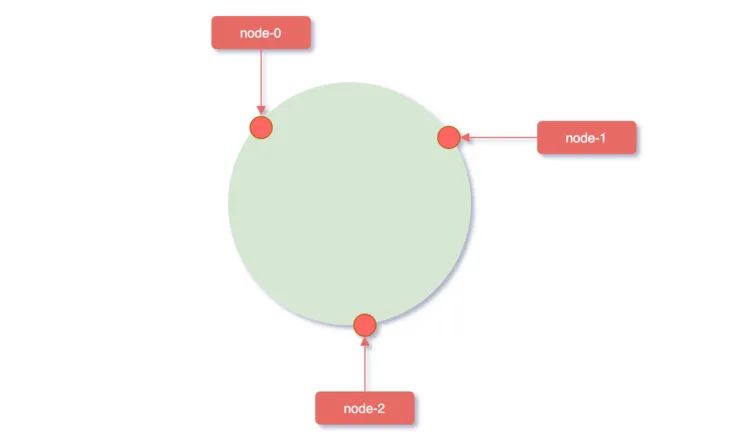
对象 key 映射到服务器
在对对应的 Key 映射到具体的服务器时,需要首先计算 Key 的 Hash 值:hash(key)% 2^32;
注:此处的 Hash 函数可以和之前计算服务器映射至 Hash 环的函数不同,只要保证取值范围和 Hash 环的范围相同即可(即:2^32);
将 Key 映射至服务器遵循下面的逻辑:
从缓存对象 key 的位置开始,沿顺时针方向遇到的第一个服务器,便是当前对象将要缓存到的服务器;
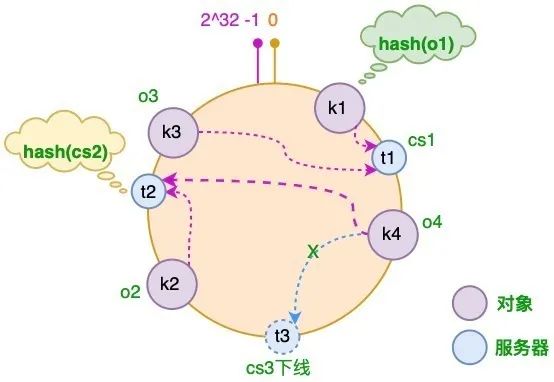
服务器扩缩容场景
服务器减少
假设 CS3 服务器出现故障导致服务下线,这时原本存储于 CS3 服务器的对象 o4,需要被重新分配至 CS2 服务器,其它对象仍存储在原有的机器上:此时受影响的数据只有 CS2 和 CS3 服务器之间的部分数据!
服务器增加
假如业务量激增,我们需要增加一台服务器 CS4,经过同样的 hash 运算,该服务器最终落于 t1 和 t2 服务器之间,具体如下图所示:
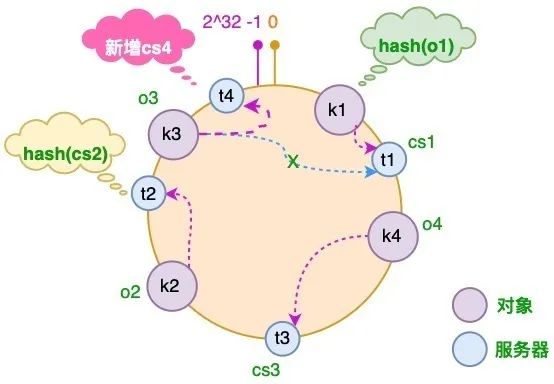
此时,只有 t1 和 t2 服务器之间的部分对象需要重新分配;
在以上示例中只有 o3 对象需要重新分配,即它被重新到 CS4 服务器;
在前面我们已经说过:如果使用简单的取模方法,当新添加服务器时可能会导致大部分缓存失效,而使用一致性哈希算法后,这种情况得到了较大的改善,因为只有少部分对象需要重新分配!
数据偏斜&服务器性能平衡问题
引出问题
在上面给出的例子中,各个服务器几乎是平均被均摊到 Hash 环上;
但是在实际场景中很难选取到一个 Hash 函数这么完美的将各个服务器散列到 Hash 环上;
此时,在服务器节点数量太少的情况下,很容易因为节点分布不均匀而造成数据倾斜问题;
如下图被缓存的对象大部分缓存在node-4服务器上,导致其他节点资源浪费,系统压力大部分集中在node-4节点上,这样的集群是非常不健康的:
同时,还有另一个问题:
在上面新增服务器 CS4 时,CS4 只分担了 CS1 服务器的负载,服务器 CS2 和 CS3 并没有因为 CS4 服务器的加入而减少负载压力;如果 CS4 服务器的性能与原有服务器的性能一致甚至可能更高,那么这种结果并不是我们所期望的;
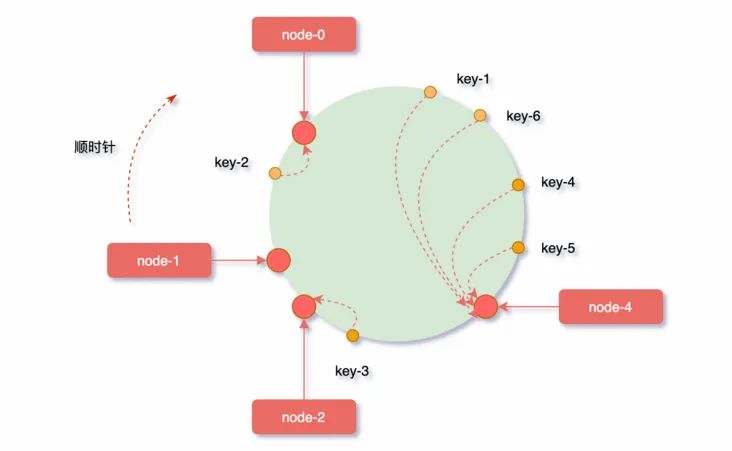
虚拟节点
针对上面的问题,我们可以通过:引入虚拟节点来解决负载不均衡的问题:
即将每台物理服务器虚拟为一组虚拟服务器,将虚拟服务器放置到哈希环上,如果要确定对象的服务器,需先确定对象的虚拟服务器,再由虚拟服务器确定物理服务器;
如下图所示:
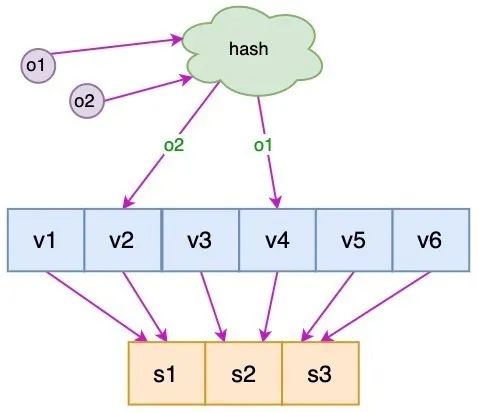
在图中:o1 和 o2 表示对象,v1 ~ v6 表示虚拟服务器,s1 ~ s3 表示实际的物理服务器;
虚拟节点的计算
虚拟节点的 hash 计算通常可以采用:对应节点的 IP 地址加数字编号后缀 hash(10.24.23.227#1) 的方式;
举个例子,node-1 节点 IP 为 10.24.23.227,正常计算node-1的 hash 值:
hash(10.24.23.227#1)% 2^32
假设我们给 node-1 设置三个虚拟节点,node-1#1、node-1#2、node-1#3,对它们进行 hash 后取模:
hash(10.24.23.227#1)% 2^32
hash(10.24.23.227#2)% 2^32
hash(10.24.23.227#3)% 2^32
注意:
- 分配的虚拟节点个数越多,映射在 hash 环上才会越趋于均匀,节点太少的话很难看出效果;
- 引入虚拟节点的同时也增加了新的问题,要做虚拟节点和真实节点间的映射,
对象key->虚拟节点->实际节点之间的转换;
使用场景
一致性 hash 在分布式系统中应该是实现负载均衡的首选算法,它的实现比较灵活,既可以在客户端实现,也可以在中间件上实现,比如日常使用较多的缓存中间件memcached和redis集群都有用到它;
memcached 的集群比较特殊,严格来说它只能算是伪集群,因为它的服务器之间不能通信,请求的分发路由完全靠客户端来的计算出缓存对象应该落在哪个服务器上,而它的路由算法用的就是一致性 hash;
还有 redis 集群中 hash 槽的概念,虽然实现不尽相同,但思想万变不离其宗,看完本篇的一致性 hash,你再去理解 redis 槽位就轻松多了;
其它的应用场景还有很多:
RPC框架Dubbo用来选择服务提供者,每个实例提供160个虚拟节点
分布式关系数据库分库分表:数据与节点的映射关系
LVS负载均衡调度器
……
一致性哈希算法广泛应用于以下场景:
分布式缓存:如Memcached、Redis等。
负载均衡:如LVS、Nginx等。
比如:NGINX中的hash算法,当每个权重为1时,每个应用有160个虚拟节点
数据库分片:如MySQL分片、MongoDB分片等。
一致性Hash算法实现
测试类
/*** Mecached、MyCat 负载均衡、一致性hash算法实现演练*/
public class Test {public static void main(String[] args) {HashSet<ServerInfo> set = new HashSet<ServerInfo>();// 准备4台机器作为服务集群set.add(new ServerInfo("192.168.1.1","9001"));set.add(new ServerInfo("192.168.1.2","9002"));set.add(new ServerInfo("192.168.1.3","9003"));set.add(new ServerInfo("192.168.1.4","9004"));// 产生一个一致性hash环ConsistentHash<ServerInfo> consistentHash = new ConsistentHash<ServerInfo>(new ConsistentHash.HashFunction(), 1000, set);// 通过请求参数获取存储的机器信息System.out.println(consistentHash.get("hello").getIp());System.out.println(consistentHash.get("world").getIp());}
}
一致性hash算法的实现类
/*** 一致性hash算法的实现*/
public class ConsistentHash<T> {// hash函数private final HashFunction hashFunction;// 产生的虚拟节点数private final int numberOfReplicas;// 一致性hash环private final SortedMap<Integer, ServerInfo> circle = new TreeMap<Integer, ServerInfo>();// 构建一致性hash环public ConsistentHash(HashFunction hashFunction, int numberOfReplicas,Collection<ServerInfo> nodes) {this.hashFunction = hashFunction;this.numberOfReplicas = numberOfReplicas;for (ServerInfo node : nodes) {add(node);}}public void add(ServerInfo node) {circle.put(hashFunction.hash(node.getIp()), node);// 将单个服务虚拟化成指定的虚拟个数,通过ip地址+1的方式for (int i = 0; i < numberOfReplicas; i++) {circle.put(hashFunction.hash(node.getIp() + i), node);}}public void remove(T node) {for (int i = 0; i < numberOfReplicas; i++) {circle.remove(hashFunction.hash(node.toString() + i));}}public ServerInfo get(Object argKey) {if (circle.isEmpty()) {return null;}// 通过对参数key进行hash算法,获得hash值int hash = hashFunction.hash(argKey);if (!circle.containsKey(hash)) {// 无法直接获得节点,则往右查找服务器的虚拟节点SortedMap<Integer, ServerInfo> tailMap = circle.tailMap(hash);// tailMap不存在,则从头开始,返回第一个key(原点),即第一个虚拟节点上。hash = tailMap.isEmpty() ? circle.firstKey() : tailMap.firstKey();}return circle.get(hash);}static class HashFunction {int hash(Object key) {// md5加密后,hashcodereturn MD5.md5(key.toString()).hashCode();}}
}
ServerInfo服务器信息类
/***/
public class ServerInfo {private String ip;// IPprivate String name;// 名称public ServerInfo(String ip, String name) {this.ip = ip;this.name = name;}public String getIp() {return ip;}public void setIp(String ip) {this.ip = ip;}public String getName() {return name;}public void setName(String name) {this.name = name;}/*** 复写toString方法,使用节点IP当做hash的KEY*/@Overridepublic String toString() {return ip;}
}
MD5加密
/***/
public class MD5 {// MD5加密。32位public static String md5(String inStr) {MessageDigest md5 = null;try {md5 = MessageDigest.getInstance("MD5");} catch (Exception e) {System.out.println(e.toString());e.printStackTrace();return "";}char[] charArray = inStr.toCharArray();byte[] byteArray = new byte[charArray.length];for (int i = 0; i < charArray.length; i++) {byteArray[i] = (byte) charArray[i];}byte[] md5Bytes = md5.digest(byteArray);StringBuffer hexValue = new StringBuffer();for (int i = 0; i < md5Bytes.length; i++) {int val = ((int) md5Bytes[i]) & 0xff;if (val < 16) {hexValue.append("0");}hexValue.append(Integer.toHexString(val));}return hexValue.toString();}public static void main(String[] args) {System.out.println(MD5.md5("admin"));}
}
参考资料
红黑树:https://www.cs.usfca.edu/~galles/visualization/RedBlack.html
探索一致性哈希算法以及在 Dubbo 负载均衡中的应用:https://devpress.csdn.net/cloud-native/6629bf1816ca5020cb596c06.html?dp_token=eyJ0eXAiOiJKV1QiLCJhbGciOiJIUzI1NiJ9.eyJpZCI6NDI3MTYzLCJleHAiOjE3MzE5MDg4NDYsImlhdCI6MTczMTMwNDA0NiwidXNlcm5hbWUiOiJxcV8yMDAyNTAzMyJ9.WVOnThiyWKUZS5RqIRaLQqCImfZWZ2MZR2fFH1HttDE&spm=1001.2101.3001.6650.5&utm_medium=distribute.pc_relevant.none-task-blog-2%7Edefault%7EBlogOpenSearchComplete%7Eactivity-5-137044405-blog-132221010.235%5Ev43%5Epc_blog_bottom_relevance_base7&depth_1-utm_source=distribute.pc_relevant.none-task-blog-2%7Edefault%7EBlogOpenSearchComplete%7Eactivity-5-137044405-blog-132221010.235%5Ev43%5Epc_blog_bottom_relevance_base7&utm_relevant_index=10
sageDigest md5 = null;
try {
md5 = MessageDigest.getInstance(“MD5”);
} catch (Exception e) {
System.out.println(e.toString());
e.printStackTrace();
return “”;
}
char[] charArray = inStr.toCharArray();
byte[] byteArray = new byte[charArray.length];
for (int i = 0; i < charArray.length; i++) {byteArray[i] = (byte) charArray[i];}byte[] md5Bytes = md5.digest(byteArray);StringBuffer hexValue = new StringBuffer();for (int i = 0; i < md5Bytes.length; i++) {int val = ((int) md5Bytes[i]) & 0xff;if (val < 16) {hexValue.append("0");}hexValue.append(Integer.toHexString(val));}return hexValue.toString();
}public static void main(String[] args) {System.out.println(MD5.md5("admin"));
}
}
## 参考资料红黑树:https://www.cs.usfca.edu/~galles/visualization/RedBlack.html探索一致性哈希算法以及在 Dubbo 负载均衡中的应用:https://devpress.csdn.net/cloud-native/6629bf1816ca5020cb596c06.html?dp_token=eyJ0eXAiOiJKV1QiLCJhbGciOiJIUzI1NiJ9.eyJpZCI6NDI3MTYzLCJleHAiOjE3MzE5MDg4NDYsImlhdCI6MTczMTMwNDA0NiwidXNlcm5hbWUiOiJxcV8yMDAyNTAzMyJ9.WVOnThiyWKUZS5RqIRaLQqCImfZWZ2MZR2fFH1HttDE&spm=1001.2101.3001.6650.5&utm_medium=distribute.pc_relevant.none-task-blog-2%7Edefault%7EBlogOpenSearchComplete%7Eactivity-5-137044405-blog-132221010.235%5Ev43%5Epc_blog_bottom_relevance_base7&depth_1-utm_source=distribute.pc_relevant.none-task-blog-2%7Edefault%7EBlogOpenSearchComplete%7Eactivity-5-137044405-blog-132221010.235%5Ev43%5Epc_blog_bottom_relevance_base7&utm_relevant_index=10