深入理解 PlaNet(Deep Planning Network):基于python从零实现
引言:基于模型的强化学习与潜在动态
基于模型的强化学习(Model-based Reinforcement Learning)旨在通过学习环境动态的模型来提高样本效率。这个模型可以用来进行规划,让智能体在不需要与真实环境进行每一次决策交互的情况下,“模拟”潜在的未来情况并选择动作。PlaNet(Deep Planning Network)是这种思路的一个杰出代表,尤其是它在紧凑的潜在空间中学习动态,通常直接从高维观测(比如图像)中学习,这一点让它脱颖而出。
PlaNet 是啥玩意儿?
PlaNet 是一个基于模型的强化学习智能体,它从经验中学习一个世界模型(world model),然后利用这个模型来规划未来的动作。它的关键创新之处在于,不是在原始观测空间(比如像素)中学习动态模型,而是在一个低维的潜在空间中学习。这使得学习模型变得更加可行,规划也更加高效。
典型的 PlaNet 架构包括:
- 学习世界模型:训练一个模型(通常是循环状态空间模型 Recurrent State-Space Model 或 RSSM),它可以根据过去的潜在状态和动作,预测未来的潜在状态、奖励,甚至重建观测。
- 在潜在空间中规划:使用学到的模型在紧凑的潜在空间中完全模拟未来的轨迹。使用一种优化算法(比如交叉熵方法 Cross-Entropy Method,CEM)来找到在规划范围内最大化预测累积奖励的动作序列。
- 执行动作:在真实环境中只执行由规划器找到的最佳计划中的第一个动作。
- 收集数据:将真实观测到的转换(观测、动作、奖励)存储在回放缓存(replay buffer)中,以持续改进世界模型。
核心思想:学习动态 & 在潜在空间中规划
与其预测每一个像素如何变化(这非常难),PlaNet 学习一个压缩表示(潜在状态 s t s_t st),这个表示捕捉了预测未来状态 s t + 1 s_{t+1} st+1 和奖励 r t r_t rt 所需的基本信息。然后规划就在这些快速可模拟的潜在动态上进行。
为啥要用 PlaNet?学习模型与规划的力量
- 高样本效率:通过利用学到的模型进行规划,PlaNet 往往能够在比无模型方法少得多的真实环境交互中学习到有效的策略,尤其是在具有高维观测的复杂任务中。
- 处理图像输入:在潜在空间中学习动态使得直接从图像构建世界模型成为可能,避免了需要手工设计状态表示的麻烦。
- 有效规划:在潜在状态上进行规划可以让智能体预见后果,并选择那些根据其学到的模型能够带来高长期奖励的动作。
PlaNet 的应用场景
PlaNet 及其后续版本(比如 DreamerV1/V2/V3)在以下领域展现出了顶尖的性能,尤其是在:
- 从像素控制:输入是图像,动作是连续的(比如 DeepMind Control Suite 基准测试)。
- 机器人仿真:从视觉输入学习复杂的操纵和运动技能。
- 样本受限领域:真实世界交互昂贵或耗时的情况。
PlaNet 的数学基础
潜在动态模型(概念性)
PlaNet 学习一个世界模型,通常结构为循环状态空间模型(Recurrent State-Space Model,RSSM),通常包括:
- 转移模型 p ( s t + 1 ∣ s t , a t ) p(s_{t+1} | s_t, a_t) p(st+1∣st,at):给定当前潜在状态 s t s_t st 和动作 a t a_t at,预测下一个潜在状态的分布。通常涉及一个确定性的循环组件 h t + 1 = f ( h t , s t , a t ) h_{t+1} = f(h_t, s_t, a_t) ht+1=f(ht,st,at) 和一个随机潜在状态 s t + 1 ∼ p ( s t + 1 ∣ h t + 1 ) s_{t+1} \sim p(s_{t+1} | h_{t+1}) st+1∼p(st+1∣ht+1)。
- 奖励模型 p ( r t ∣ s t ) p(r_t | s_t) p(rt∣st):给定潜在状态 s t s_t st,预测即时奖励的分布。
- 观测模型 p ( o t ∣ s t ) p(o_t | s_t) p(ot∣st):给定潜在状态 s t s_t st,预测(重建)观测 o t o_t ot。这对于从图像学习时锚定潜在空间至关重要。
- 编码器/表示模型 q ( s t ∣ . . . ) q(s_t | ...) q(st∣...):从观测 o t o_t ot 和可能的过去上下文 h t h_t ht 中推断潜在状态 s t s_t st。在变分方法中,这通常是后验 q ( s t ∣ h t , o t ) q(s_t | h_t, o_t) q(st∣ht,ot)。
本笔记本的简化:我们将使用基于 MLP 的更简单模型,直接在环境的向量状态上进行转移和奖励的预测,实际上把向量状态当作(部分)潜在状态,并跳过图像编码/解码。
模型训练目标
世界模型通过最大化回放缓存中存储的观测数据(观测、动作、奖励的序列)的似然度来训练。这通常是通过最小化基于变分方法的证据下界(Evidence Lower Bound,ELBO)的损失函数来实现的,通常包括:
- 重建损失:最小化预测观测 o ^ t \hat{o}_t o^t(来自 p ( o t ∣ s t ) p(o_t | s_t) p(ot∣st))和实际观测 o t o_t ot 之间的差异。
- 奖励预测损失:最小化预测奖励 r ^ t \hat{r}_t r^t(来自 p ( r t ∣ s t ) p(r_t | s_t) p(rt∣st))和实际奖励 r t r_t rt 之间的差异。
- KL 散度正则化器:惩罚推断的后验 q ( s t ∣ h t , o t ) q(s_t | h_t, o_t) q(st∣ht,ot) 和学习的先验 p ( s t ∣ h t ) p(s_t | h_t) p(st∣ht) 之间的差异,鼓励一个结构良好的潜在空间。
本笔记本的简化:我们将通过最小化均方误差(MSE)来训练我们简化的动态模型,用于预测下一个状态向量和奖励。
L m o d e l = E ( s t , a t , r t , s t + 1 ) ∼ D [ ∣ ∣ s t + 1 − s ^ t + 1 ( s t , a t ) ∣ ∣ 2 + ∣ ∣ r t − r ^ t ( s t , a t ) ∣ ∣ 2 ] L_{model} = \mathbb{E}_{(s_t, a_t, r_t, s_{t+1}) \sim \mathcal{D}} [ || s_{t+1} - \hat{s}_{t+1}(s_t, a_t) ||^2 + || r_t - \hat{r}_t(s_t, a_t) ||^2 ] Lmodel=E(st,at,rt,st+1)∼D[∣∣st+1−s^t+1(st,at)∣∣2+∣∣rt−r^t(st,at)∣∣2]
其中 s ^ t + 1 \hat{s}_{t+1} s^t+1 和 r ^ t \hat{r}_t r^t 是我们学到的模型的预测。
使用模型进行规划:交叉熵方法(CEM)
给定当前状态 s t s_t st(或其潜在表示)和学到的模型 ( p ^ ( ⋅ ∣ s , a ) , r ^ ( ⋅ , ⋅ ) ) (\hat{p}(\cdot | s, a), \hat{r}(\cdot, \cdot)) (p^(⋅∣s,a),r^(⋅,⋅)),目标是找到在规划范围 H H H 内的动作序列 a t , . . . , a t + H − 1 a_t, ..., a_{t+H-1} at,...,at+H−1,以最大化模型预测的期望累积奖励: E [ ∑ k = t t + H − 1 γ k − t r ^ k ] \mathbb{E} [ \sum_{k=t}^{t+H-1} \gamma^{k-t} \hat{r}_k ] E[∑k=tt+H−1γk−tr^k]。
CEM 是一种无导数优化算法,用于此目的:
- 初始化:定义一个初始动作序列分布(比如,高斯分布 N ( μ , Σ ) \mathcal{N}(\mu, \Sigma) N(μ,Σ),用于范围内的每一步)。
- 采样:从当前分布中采样 J J J 个候选动作序列 A j = ( a t ( j ) , . . . , a t + H − 1 ( j ) ) A_j = (a_{t}^{(j)}, ..., a_{t+H-1}^{(j)}) Aj=(at(j),...,at+H−1(j))。
- 评估:对于每个序列 A j A_j Aj,使用学到的动态模型在潜在空间中模拟轨迹,并预测总奖励 R j = ∑ k = t t + H − 1 γ k − t r ^ k ( j ) R_j = \sum_{k=t}^{t+H-1} \gamma^{k-t} \hat{r}_k^{(j)} Rj=∑k=tt+H−1γk−tr^k(j)。
- 选择:选择具有最高预测奖励 R j R_j Rj 的前 M M M(精英)动作序列。
- 重新拟合:根据精英样本更新动作序列分布的参数 ( μ , Σ ) (\mu, \Sigma) (μ,Σ)(比如,计算精英序列的均值和方差)。
- 迭代:重复步骤 2-5,固定次数。
- 输出:最终的均值 μ \mu μ 表示找到的最佳动作序列。第一个动作 a t = μ t a_t = \mu_t at=μt 将被执行。
动作选择
在时间 t t t 的真实环境中执行的动作是从 CEM 规划器找到的最佳序列中的第一个动作: a t ∗ = Planner ( s t , Model ) a_t^* = \text{Planner}(s_t, \text{Model}) at∗=Planner(st,Model)。
PlaNet 的逐步解释
- 初始化:动态模型(转移 p ^ \hat{p} p^,奖励 r ^ \hat{r} r^),回放缓存 D \mathcal{D} D(存储序列)。超参数(规划范围 H H H,CEM 参数 J , M J, M J,M,模型学习率等)。
- 循环(训练迭代/环境步骤):
a. 交互 & 收集数据:
i. 观测当前状态 s t s_t st。
ii. 使用当前模型的 CEM 规划器找到从 s t s_t st 开始的最佳动作序列 a t ∗ , . . . , a t + H − 1 ∗ a_t^*, ..., a_{t+H-1}^* at∗,...,at+H−1∗。
iii. 在真实环境中执行第一个动作 a t ∗ a_t^* at∗。
iv. 观测真实奖励 r t r_t rt 和下一个状态 s t + 1 s_{t+1} st+1。
v. 将 ( s t , a t ∗ , r t , s t + 1 ) (s_t, a_t^*, r_t, s_{t+1}) (st,at∗,rt,st+1) 存储到回放缓存 D \mathcal{D} D 中。
b. 训练世界模型:
i. 从 D \mathcal{D} D 中采样一批序列。
ii. 训练动态模型 ( p ^ , r ^ ) (\hat{p}, \hat{r}) (p^,r^),以最小化对采样序列的预测损失(比如,下一个状态和奖励的 MSE)。
c. s t ← s t + 1 s_t \leftarrow s_{t+1} st←st+1。 - 重复:直到收敛或达到最大步数。
PlaNet 的关键组成部分
世界模型(动态模型)
- 从当前状态/潜在状态和动作中学习预测未来状态(潜在或观测)和奖励。
- 基于真实经验的序列进行训练。
- 启用规划的核心组件。
回放缓存(基于序列)
- 存储转换序列 ( s t , a t , r t , s t + 1 ) (s_t, a_t, r_t, s_{t+1}) (st,at,rt,st+1) 或 ( o t , a t , r t , o t + 1 ) (o_t, a_t, r_t, o_{t+1}) (ot,at,rt,ot+1)。对于训练循环或基于序列的世界模型是必需的。
模型训练过程
- 优化世界模型参数,以根据回放缓存中的数据准确预测奖励和下一个状态。
规划器(CEM)
- 使用学到的世界模型在有限范围 H H H 内搜索最优动作序列。
- 由于其简单性和在这种情况下的有效性,CEM 是一个常见的选择。
动作执行
- 只执行计划序列中的第一个动作,在真实环境中遵循模型预测控制(Model Predictive Control)原则。
超参数
- 回放缓存大小,模型训练的批量大小。
- 模型学习率,模型架构。
- 规划范围 H H H。
- CEM 参数:迭代次数,候选数量 J J J,精英数量 M M M,初始方差。
实际示例:摆锤环境
为啥要用摆锤环境来举例呢?
正如前面提到的,PlaNet 通常使用图像输入。然而,实现必要的视觉组件(CNNs)和潜在模型(RSSMs)对于一个教学用的笔记本来说非常复杂。摆锤提供了一个标准的连续状态和动作空间,在这里,基于模型的规划的好处仍然显而易见。我们将把 PlaNet 适配为使用向量状态,学习一个直接预测下一个状态向量 s ^ t + 1 \hat{s}_{t+1} s^t+1 和奖励 r ^ t \hat{r}_t r^t 的模型。这使得我们可以专注于模型学习和 CEM 规划之间的相互作用。需要 gymnasium。
设置环境
导入库。
# 导入必要的库
import numpy as np
import matplotlib.pyplot as plt
import random
import math
from collections import namedtuple, deque
from itertools import count
from typing import List, Tuple, Dict, Optional, Callable, Any
import copy
import time# 导入 PyTorch
import torch
import torch.nn as nn
import torch.optim as optim
import torch.nn.functional as F
from torch.distributions import Normal, Independent
from torch.distributions.kl import kl_divergence# 导入 Gymnasium
try:import gymnasium as gym
except ImportError:print("Gymnasium 没找到。请使用 'pip install gymnasium' 或 'pip install gym[classic_control]' 安装")gym = None# 设置设备
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(f"使用设备:{device}")# 设置随机种子
seed = 42
random.seed(seed)
np.random.seed(seed)
torch.manual_seed(seed)
if torch.cuda.is_available():torch.cuda.manual_seed_all(seed)%matplotlib inline
使用设备:cpu
创建连续环境(Gymnasium)
实例化 Pendulum-v1。
# 实例化摆锤环境
if gym is not None:try:env = gym.make('Pendulum-v1')env.reset(seed=seed)env.action_space.seed(seed)n_observations_planet = env.observation_space.shape[0]n_actions_planet = env.action_space.shape[0]action_low_planet = env.action_space.lowaction_high_planet = env.action_space.highprint(f"摆锤环境:")print(f"状态维度:{n_observations_planet}")print(f"动作维度:{n_actions_planet}")print(f"动作下限:{action_low_planet}")print(f"动作上限:{action_high_planet}")except Exception as e:print(f"创建 Gymnasium 环境时出错:{e}")n_observations_planet = 3n_actions_planet = 1action_low_planet = np.array([-2.0])action_high_planet = np.array([2.0])env = None
else:print("Gymnasium 不可用。无法创建摆锤环境。")n_observations_planet = 3n_actions_planet = 1action_low_planet = np.array([-2.0])action_high_planet = np.array([2.0])env = None
摆锤环境:
状态维度:3
动作维度:1
动作下限:[-2.]
动作上限:[2.]
实现 PlaNet 算法
定义简化的动态模型、序列回放缓存、CEM 规划器和训练函数。
定义动态模型(简化版)
一个 MLP,接收当前状态 s t s_t st 和动作 a t a_t at,预测下一个状态 s t + 1 s_{t+1} st+1 和奖励 r t r_t rt。
class DynamicsModel(nn.Module):""" 简化的 MLP 基础动态模型,用于 PlaNet。 """def __init__(self, state_dim: int, action_dim: int, hidden_dim: int = 200):super(DynamicsModel, self).__init__()self.state_dim = state_dimself.action_dim = action_dim# 简单的 MLP 架构self.fc1 = nn.Linear(state_dim + action_dim, hidden_dim)self.fc2 = nn.Linear(hidden_dim, hidden_dim)# 输出头self.fc_next_state = nn.Linear(hidden_dim, state_dim) # 预测下一个状态self.fc_reward = nn.Linear(hidden_dim, 1) # 预测奖励def forward(self, state: torch.Tensor, action: torch.Tensor) -> Tuple[torch.Tensor, torch.Tensor]:"""预测下一个状态和奖励。参数:- state (torch.Tensor):当前状态张量。- action (torch.Tensor):动作张量。返回:- Tuple[torch.Tensor, torch.Tensor]:- 预测的下一个状态。- 预测的奖励。"""# 确保输入是 2D 的(batch_size, dim)if state.dim() == 1: state = state.unsqueeze(0)if action.dim() == 1: action = action.unsqueeze(0)x = torch.cat([state, action], dim=-1) # 将状态和动作拼接起来x = F.relu(self.fc1(x))x = F.relu(self.fc2(x))pred_next_state = self.fc_next_state(x)pred_reward = self.fc_reward(x)# 在更复杂的模型中,可能会预测分布的参数# 比如,下一个状态/奖励的均值和方差。# 这里我们直接预测均值。return pred_next_state, pred_reward
定义序列回放缓存
存储转换序列,用于训练基于序列的模型(即使是我们的简化 MLP 也从序列上下文中受益)。
# 定义一个序列转换结构
# 存储观测 (o),动作 (a),奖励 (r),下一个观测 (o_next),完成标志 (d)
SeqTransition = namedtuple('SeqTransition',('observations', 'actions', 'rewards', 'next_observations', 'dones'))class SequenceReplayBuffer:""" 存储转换序列。 """def __init__(self, capacity: int, sequence_length: int):self.capacity = capacityself.sequence_length = sequence_lengthself.buffer: List[Tuple[Any, ...]] = [] # 存储单个 (o, a, r, o_next, d) 步骤self.position = 0def push(self, obs: np.ndarray, action: np.ndarray, reward: float, next_obs: np.ndarray, done: bool) -> None:""" 将单个步骤转换添加到缓冲区中。 """# 如果需要,可以转换为 numpy 以提高存储效率,或者保持为张量transition = (obs, action, reward, next_obs, float(done)) if len(self.buffer) < self.capacity:self.buffer.append(None)self.buffer[self.position] = transitionself.position = (self.position + 1) % self.capacitydef sample(self, batch_size: int) -> Optional[SeqTransition]:""" 采样一批序列。 """if len(self.buffer) < self.sequence_length:return None # 数据不足,无法形成序列observations_batch = []actions_batch = []rewards_batch = []next_observations_batch = []dones_batch = []for _ in range(batch_size):# 随机选择一个序列的起始点start_idx = random.randint(0, len(self.buffer) - self.sequence_length)sequence = self.buffer[start_idx : start_idx + self.sequence_length]# 解压序列obs_seq, act_seq, rew_seq, next_obs_seq, done_seq = zip(*sequence)observations_batch.append(np.array(obs_seq))actions_batch.append(np.array(act_seq))rewards_batch.append(np.array(rew_seq))next_observations_batch.append(np.array(next_obs_seq))dones_batch.append(np.array(done_seq))# 将序列列表转换为张量 (batch_size, seq_len, feature_dim)obs_tensor = torch.from_numpy(np.array(observations_batch)).float().to(device)act_tensor = torch.from_numpy(np.array(actions_batch)).float().to(device)rew_tensor = torch.from_numpy(np.array(rewards_batch)).float().to(device).unsqueeze(-1) # 添加特征维度next_obs_tensor = torch.from_numpy(np.array(next_observations_batch)).float().to(device)dones_tensor = torch.from_numpy(np.array(dones_batch)).float().to(device).unsqueeze(-1) # 添加特征维度return SeqTransition(obs_tensor, act_tensor, rew_tensor, next_obs_tensor, dones_tensor)def __len__(self) -> int:return len(self.buffer)
实现 CEM 规划器
一个使用学到的动态模型进行 CEM 规划的函数。
def cem_planner(model: DynamicsModel, initial_state: torch.Tensor, horizon: int, num_candidates: int, num_elites: int, num_iterations: int,gamma: float, action_low: np.ndarray, action_high: np.ndarray,action_dim: int) -> torch.Tensor:"""使用动态模型执行交叉熵方法(CEM)规划。参数:- model:学到的 DynamicsModel。- initial_state:从哪个状态开始规划。- horizon:规划范围(步数 H)。- num_candidates:要采样的动作序列数量(J)。- num_elites:要保留的顶级序列数量(M)。- num_iterations:CEM 精炼迭代次数。- gamma:模拟奖励时使用的折扣因子。- action_low, action_high:动作空间的界限。- action_dim:动作空间的维度。返回:- torch.Tensor:找到的最佳序列中的第一个动作。"""model.eval() # 将模型设置为评估模式以进行规划# 初始化动作分布(高斯分布)# 均值初始化为零,标准差初始化为覆盖动作范围的一半action_mean = torch.zeros(horizon, action_dim, device=device)action_std_dev = torch.ones(horizon, action_dim, device=device) * (torch.from_numpy(action_high - action_low).float().to(device) / 2.0)for _ in range(num_iterations):# 从当前分布中采样候选动作序列# 形状:(num_candidates, horizon, action_dim)action_dist = Normal(action_mean, action_std_dev)candidate_actions = action_dist.sample((num_candidates,))# 将动作裁剪到界限内action_low_t = torch.from_numpy(action_low).float().to(device)action_high_t = torch.from_numpy(action_high).float().to(device)candidate_actions = torch.clamp(candidate_actions, action_low_t, action_high_t)# 使用模型评估候选序列total_rewards = torch.zeros(num_candidates, device=device)current_states = initial_state.repeat(num_candidates, 1) # 所有候选序列从初始状态开始with torch.no_grad(): # 模型回放时不需要梯度for t in range(horizon):actions_t = candidate_actions[:, t, :] # 这个时间步的动作# 使用模型预测下一个状态和奖励next_states, rewards = model(current_states, actions_t)total_rewards += (gamma ** t) * rewards.squeeze() # 累积折扣奖励current_states = next_states # 转到预测的下一个状态# 选择精英动作序列_, elite_indices = torch.topk(total_rewards, num_elites) # 获取前 M 个序列的索引elite_actions = candidate_actions[elite_indices]# 根据精英样本重新拟合动作分布action_mean = elite_actions.mean(dim=0)action_std_dev = elite_actions.std(dim=0) + 1e-6 # 加上一个 epsilon 以保证稳定性# 返回最终分布中第一个动作的均值best_first_action = action_mean[0]return best_first_action
模型训练函数
使用采样的序列训练动态模型。
def train_model(model: DynamicsModel, model_optimizer: optim.Optimizer, replay_buffer: SequenceReplayBuffer, batch_size: int, num_train_steps: int) -> float:"""训练动态模型一定步数。参数:- model:要训练的 DynamicsModel。- model_optimizer:模型的优化器。- replay_buffer:采样的回放缓存。- batch_size:每个批次的序列数量。- num_train_steps:要执行的梯度步数。返回:- float:训练步数的平均损失。"""model.train() # 将模型设置为训练模式total_loss = 0.0steps_done = 0for _ in range(num_train_steps):# 从回放缓存中采样一批序列sequence_batch = replay_buffer.sample(batch_size)if sequence_batch is None:continue # 数据不足,跳过obs_batch, act_batch, rew_batch, next_obs_batch, dones_batch = sequence_batch# obs_batch 形状:(batch_size, seq_len, state_dim)# act_batch 形状:(batch_size, seq_len, action_dim)# rew_batch 形状:(batch_size, seq_len, 1)# next_obs_batch 形状:(batch_size, seq_len, state_dim)# --- 计算模型损失 --- # 我们需要预测序列中每一步的下一个状态和奖励。# 在这里,我们简化处理,仅基于每个序列的第一步进行预测# 对于演示来说足够了。一个完整的实现会遍历整个序列# 或在模型中使用 RNN。current_states = obs_batch[:, 0, :] # 序列起始状态current_actions = act_batch[:, 0, :] # 序列起始动作target_next_states = next_obs_batch[:, 0, :] # 真实下一个状态target_rewards = rew_batch[:, 0, :] # 真实奖励# 获取模型预测pred_next_states, pred_rewards = model(current_states, current_actions)# 计算 MSE 损失state_loss = F.mse_loss(pred_next_states, target_next_states)reward_loss = F.mse_loss(pred_rewards, target_rewards)# 合并损失(如果需要,可以添加权重)loss = state_loss + reward_loss# --- 优化模型 --- model_optimizer.zero_grad()loss.backward()# 可选:梯度裁剪# torch.nn.utils.clip_grad_norm_(model.parameters(), max_norm=1.0) model_optimizer.step()total_loss += loss.item()steps_done += 1return total_loss / steps_done if steps_done > 0 else 0.0
运行 PlaNet 算法
设置超参数,初始化组件,运行主 PlaNet 循环。
超参数设置
为 PlaNet 和 CEM 定义超参数。
# PlaNet 在 Pendulum-v1 上的超参数
BUFFER_CAPACITY_PLANET = int(1e5) # 缓存存储单个步骤
SEQUENCE_LENGTH = 50 # 用于模型训练的序列长度
MODEL_BATCH_SIZE = 32 # 模型训练批次中的序列数量
MODEL_TRAIN_STEPS = 100 # 每次迭代的模型梯度步数
MODEL_LR = 1e-3 # 动态模型的学习率
HIDDEN_DIM_MODEL = 200 # 动态模型的隐藏维度# CEM 规划器超参数
PLANNING_HORIZON = 12 # 提前规划的步数(H)
CEM_CANDIDATES = 1000 # 每次 CEM 迭代采样的候选数量(J)
CEM_ELITES = 100 # 每次 CEM 迭代保留的精英数量(M)
CEM_ITERATIONS = 10 # CEM 精炼迭代次数
CEM_GAMMA = 0.99 # 规划中使用的折扣因子# 训练循环超参数
NUM_ITERATIONS_PLANET = 50 # 收集/训练迭代次数
STEPS_PER_ITERATION_PLANET = 100 # 每次迭代收集的环境步数
INITIAL_RANDOM_STEPS = 1000 # 初始随机收集的步数
初始化
初始化模型、优化器和回放缓存。
if env is None:raise RuntimeError("无法创建 Gymnasium 环境 'Pendulum-v1'。")# 初始化动态模型
dynamics_model = DynamicsModel(n_observations_planet, n_actions_planet, HIDDEN_DIM_MODEL).to(device)# 初始化模型优化器
model_optimizer = optim.Adam(dynamics_model.parameters(), lr=MODEL_LR)# 初始化回放缓存
replay_buffer = SequenceReplayBuffer(BUFFER_CAPACITY_PLANET, SEQUENCE_LENGTH)# 用于绘图的列表
planet_iteration_rewards = []
planet_iteration_model_losses = []# --- 收集初始随机数据 ---
print(f"收集 {INITIAL_RANDOM_STEPS} 个初始随机步骤...")
obs_np, _ = env.reset()
for _ in range(INITIAL_RANDOM_STEPS):action_np = env.action_space.sample()next_obs_np, reward, terminated, truncated, _ = env.step(action_np)done = terminated or truncatedreplay_buffer.push(obs_np, action_np, reward, next_obs_np, done)obs_np = next_obs_npif done:obs_np, _ = env.reset()
print("初始数据收集完成。")
收集 1000 个初始随机步骤...
初始数据收集完成。
训练循环
PlaNet 循环:使用 CEM 规划收集数据,然后训练世界模型。
print("在 Pendulum-v1 上开始 PlaNet 训练...")# --- PlaNet 训练循环 ---
total_steps_planet = 0
current_state_np, _ = env.reset()
current_state = torch.from_numpy(current_state_np).float().to(device)for iteration in range(1, NUM_ITERATIONS_PLANET + 1):# --- 1. 使用规划器收集数据 --- iteration_rewards_list = []current_episode_reward = 0.0steps_this_iter = 0while steps_this_iter < STEPS_PER_ITERATION_PLANET:# 使用 CEM 规划动作action_tensor = cem_planner(dynamics_model,current_state,horizon=PLANNING_HORIZON,num_candidates=CEM_CANDIDATES,num_elites=CEM_ELITES,num_iterations=CEM_ITERATIONS,gamma=CEM_GAMMA, # 使用规划折扣action_low=action_low_planet,action_high=action_high_planet,action_dim=n_actions_planet)action_np = action_tensor.detach().cpu().numpy()# 如果 CEM 生成的值稍微超出界限,就裁剪一下action_np_clipped = np.clip(action_np, action_low_planet, action_high_planet)# 与环境交互next_state_np, reward, terminated, truncated, _ = env.step(action_np_clipped)done = terminated or truncated# 存储经验replay_buffer.push(current_state_np, action_np_clipped, reward, next_state_np, done)current_state_np = next_state_npcurrent_state = torch.from_numpy(current_state_np).float().to(device)current_episode_reward += rewardtotal_steps_planet += 1steps_this_iter += 1if done:iteration_rewards_list.append(current_episode_reward)current_state_np, _ = env.reset()current_state = torch.from_numpy(current_state_np).float().to(device)current_episode_reward = 0.0# 检查是否达到了迭代步数限制,即使这一集提前结束if steps_this_iter >= STEPS_PER_ITERATION_PLANET:break# --- 2. 训练世界模型 --- avg_model_loss = train_model(dynamics_model, model_optimizer, replay_buffer,MODEL_BATCH_SIZE, MODEL_TRAIN_STEPS)# --- 日志记录 --- avg_iter_reward = np.mean(iteration_rewards_list) if iteration_rewards_list else np.nanplanet_iteration_rewards.append(avg_iter_reward)planet_iteration_model_losses.append(avg_model_loss)if iteration % 10 == 0:print(f"迭代 {iteration}/{NUM_ITERATIONS_PLANET} | 步数:{total_steps_planet} | 平均每集奖励:{avg_iter_reward:.2f} | 模型损失:{avg_model_loss:.6f}")print("Pendulum-v1 训练完成 (PlaNet)。")
在 Pendulum-v1 上开始 PlaNet 训练...
迭代 10/50 | 步数:1000 | 平均每集奖励:-492.32 | 模型损失:0.040212
迭代 20/50 | 步数:2000 | 平均每集奖励:-267.97 | 模型损失:0.006726
迭代 30/50 | 步数:3000 | 平均每集奖励:-519.70 | 模型损失:0.004455
迭代 40/50 | 步数:4000 | 平均每集奖励:-151.99 | 模型损失:0.003335
迭代 50/50 | 步数:5000 | 平均每集奖励:-0.64 | 模型损失:0.002298
Pendulum-v1 训练完成 (PlaNet)。
可视化学习过程
绘制每次迭代的平均每集奖励和模型训练损失。
# 绘制 PlaNet 在 Pendulum-v1 上的结果
plt.figure(figsize=(12, 4))# 每次迭代的平均每集奖励
plt.subplot(1, 2, 1)
valid_rewards_planet = [r for r in planet_iteration_rewards if not np.isnan(r)]
valid_indices_planet = [i for i, r in enumerate(planet_iteration_rewards) if not np.isnan(r)]
plt.plot(valid_indices_planet, valid_rewards_planet)
plt.title('PlaNet 摆锤:每次迭代的平均每集奖励')
plt.xlabel('迭代')
plt.ylabel('平均奖励')
plt.grid(True)
if len(valid_rewards_planet) >= 10:rewards_ma_planet = np.convolve(valid_rewards_planet, np.ones(10)/10, mode='valid')plt.plot(valid_indices_planet[9:], rewards_ma_planet, label='10 迭代移动平均', color='orange')plt.legend()# 每次迭代的模型损失
plt.subplot(1, 2, 2)
plt.plot(planet_iteration_model_losses)
plt.title('PlaNet 摆锤:每次迭代的平均模型损失')
plt.xlabel('迭代')
plt.ylabel('平均 MSE 损失 (状态+奖励)')
plt.yscale('log') # 损失通常显著下降,对数刻度有助于可视化
plt.grid(True, which='both')
if len(planet_iteration_model_losses) >= 10:mloss_ma_planet = np.convolve(planet_iteration_model_losses, np.ones(10)/10, mode='valid')plt.plot(np.arange(len(mloss_ma_planet)) + 9, mloss_ma_planet, label='10 迭代移动平均', color='orange')plt.legend()plt.tight_layout()
plt.show()
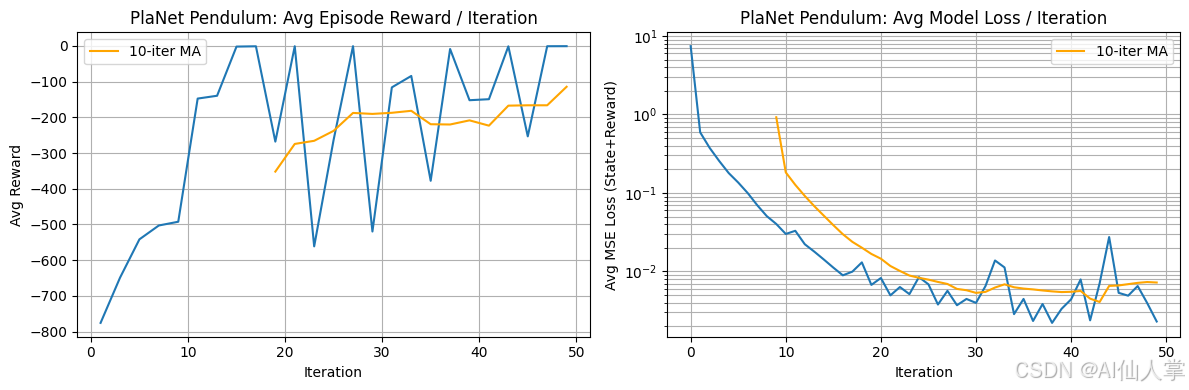
PlaNet 学习曲线分析(摆锤):
-
每次迭代的平均每集奖励(左图):
- 观察结果: 这幅图显示了一个非常快速的初始学习阶段。从非常差的表现(约 -800)开始,平均每集奖励在前 15-20 次迭代中急剧上升,接近最优范围(接近 0)。在这一陡峭的上升之后,奖励出现了显著的不稳定性,出现了较大的波动,有时接近最优表现,有时则下降到较低的奖励(-400 或更差)。10 次迭代移动平均(橙色线)捕捉到了初始学习之后的整体高水平,但平滑了这些明显的峰值和谷值。
- 解释: 初始快速提升突出了 PlaNet 的样本效率潜力。通过学习动态模型,它可以快速利用模拟经验(“规划”)找到不错的策略,相对较少地与真实环境进行交互。然而,随后的波动至关重要。它表明,尽管学到的模型足以实现初始进展,但很可能存在不准确之处。规划器(PlaNet 中的 CEM)可能会找到根据不完美模型得出的高奖励动作序列,但这些计划并不完美地转化为真实环境中的表现,导致性能下降。这种模型内计划与真实世界结果之间的差异导致了观察到的波动。
-
每次迭代的平均模型损失(右图):
- 观察结果: 这幅图显示了世界模型预测(下一个状态和奖励)的平均均方误差(MSE)损失,采用对数刻度。损失在最初的约 15 次迭代中迅速下降了好几个数量级,与奖励最快提升的时期完全对应。在这一初始下降之后,损失稳定在一个较低的平均值(约 0.01-0.02),在后续训练中有一些小的波动。
- 解释: 初始的急剧下降证实了 PlaNet 的世界模型部分能够快速有效地学习,并迅速捕捉到摆锤环境的短期动态。这种快速构建具有相当预测能力的模型的能力,使得初始策略提升如此迅速。稳定下来表明模型已经达到了一定的准确度,这可能受到动态复杂性、模型容量以及收集的数据的质量/多样性的限制。即使平均损失很低,也不保证长期预测的完美性,这对于多步规划阶段至关重要。
总体结论:
PlaNet 在摆锤任务上展示了令人印象深刻的初始样本效率,通过学习预测世界模型并利用它进行规划,快速提升了奖励。模型损失迅速收敛到较低的值,表明其具有良好的短期预测能力。然而,初始学习阶段之后奖励的显著波动表明,学到的模型中的不准确之处被多步规划过程(CEM)放大了。这导致了在模型内看起来最优的计划,但在真实环境中执行时却表现不佳或不稳定,突出了模型偏差在基于模型的强化学习中的挑战,尤其是对于需要精确长期预测的连续控制任务。
分析学到的策略(测试)
通过在环境中运行它,在每个步骤中使用规划器,来可视化 PlaNet 代理的性能。
def test_planet_agent(model: DynamicsModel, env_instance: gym.Env, num_episodes: int = 5, render: bool = False, seed_offset: int = 3000, cem_params: dict = {}) -> None:"""使用每个步骤的 CEM 规划测试训练好的 PlaNet 代理。"""if env_instance is None:print("环境不可用,无法进行测试。")returnmodel.eval() # 将模型设置为评估模式# 获取 CEM 参数或使用默认值horizon = cem_params.get('horizon', PLANNING_HORIZON)candidates = cem_params.get('candidates', CEM_CANDIDATES)elites = cem_params.get('elites', CEM_ELITES)iterations = cem_params.get('iterations', CEM_ITERATIONS)gamma = cem_params.get('gamma', CEM_GAMMA)action_dim = env_instance.action_space.shape[0]action_low = env_instance.action_space.lowaction_high = env_instance.action_space.highprint(f"\n--- 测试 PlaNet 代理 ({num_episodes} 集) ---")all_rewards = []for i in range(num_episodes):state_np, info = env_instance.reset(seed=seed + seed_offset + i)state = torch.from_numpy(state_np).float().to(device)episode_reward = 0done = Falset = 0while not done:if render:try:env_instance.render()time.sleep(0.01)except Exception as e:print(f"渲染失败:{e}。禁用渲染。")render = False# 使用 CEM 规划动作action_tensor = cem_planner(model, state, horizon, candidates, elites, iterations, gamma,action_low, action_high, action_dim)action_np = action_tensor.detach().cpu().numpy()action_np_clipped = np.clip(action_np, action_low, action_high)# 执行环境步骤next_state_np, reward, terminated, truncated, _ = env_instance.step(action_np_clipped)done = terminated or truncatedstate = torch.from_numpy(next_state_np).float().to(device)episode_reward += rewardt += 1print(f"测试集 {i+1}:奖励 = {episode_reward:.2f}, 长度 = {t}")all_rewards.append(episode_reward)if render:env_instance.close()print(f"--- 测试完成。平均奖励:{np.mean(all_rewards):.2f} ---")# 运行测试集(确保环境仍然可用)
# 传递在训练中使用的 CEM 参数(或者可能经过调整的参数)
test_cem_params = {'horizon': PLANNING_HORIZON,'candidates': CEM_CANDIDATES,'elites': CEM_ELITES,'iterations': CEM_ITERATIONS,'gamma': CEM_GAMMA
}
test_planet_agent(dynamics_model, env, num_episodes=3, render=False, cem_params=test_cem_params)
--- 测试 PlaNet 代理 (3 集) ---
测试集 1:奖励 = -1765.54, 长度 = 200
测试集 2:奖励 = -4.07, 长度 = 200
测试集 3:奖励 = -392.67, 长度 = 200
--- 测试完成。平均奖励:-720.76 ---
PlaNet 的常见挑战和扩展
挑战:模型准确性与复杂性
- 问题:从高维数据(如图像)或复杂动态中学习准确的世界模型本质上是困难的。简单的模型可能不准确,而复杂的模型(如完整的 RSSM)难以训练且计算成本高昂。
- 解决方案:
- 更好的模型架构:使用为动态建模设计的更复杂的序列模型(RSSM、Transformer)。
- 概率模型:预测下一个状态/奖励的分布可以捕捉不确定性。
- 谨慎的正则化:在变分模型中使用 KL 正则化等技术有助于结构化潜在空间。
- 关注相关信息:设计模型只预测对规划必要的内容。
挑战:累积模型误差
- 问题:在规划(模拟范围 H H H)期间,每一步的小预测误差可能会累积,导致长期预测不准确,从而可能导致计划不佳。
- 解决方案:
- 缩短规划范围 H H H:减少误差累积的可能性,但可能导致短视行为。
- 更准确的模型:提高单步预测准确性。
- 模型集成:训练多个模型并在规划期间平均它们的预测。
- 重新规划:从当前 真实 状态频繁重新规划,以纠正偏差。
挑战:规划成本
- 问题:在每个时间步执行迭代优化(如 CEM)可能计算成本很高,限制了实时应用。
解决方案:- 高效的规划器:研究更快的规划算法(例如,如果模型可微,则使用基于梯度的轨迹优化,或者优化 CEM 实现)。
- 减少 CEM 参数:减少候选数量 J J J、精英数量 M M M 或迭代次数,以换取速度。
- 不那么频繁地规划:从单个计划中执行多个动作,然后再重新规划。
- 规划摊销(策略学习):使用规划器的输出作为目标训练一个单独的策略网络(actor),有效地将规划计算蒸馏到一个快速的策略网络中(如 Dreamer 算法中所做)。
挑战:模型与现实之间的差异(仿真到现实差距)
- 问题:即使训练有素的模型也是一个近似值。完全在模型内优化的策略可能无法完美地转移到现实世界中。
- 解决方案:
- 持续更新模型:用新的真实数据持续训练模型。
- 鲁棒规划:在规划期间使用技术考虑模型不确定性。
- 系统识别:使用技术明确提高模型在相关状态空间部分的准确性。
扩展(Dreamer 系列):
- DreamerV1/V2/V3:PlaNet 的后续版本,建立在核心思想之上。它们通常使用更先进的 RSSM,在潜在空间内学习策略和价值函数,使用想象的轨迹,并且通常实现更高的样本效率和性能。
结论
PlaNet 代表了基于模型的强化学习中一个强大的范例,展示了在潜在空间中学习世界模型并利用它们进行规划的潜力。通过将模型学习与策略执行解耦,它旨在实现高样本效率,使其适用于复杂任务,尤其是那些具有高维观测(如图像)的任务。
核心循环涉及收集经验,训练潜在动态模型(预测状态和奖励),并使用像 CEM 这样的规划器,根据模型的模拟找到最优动作序列。尽管面临与模型准确性、累积误差和规划成本相关的挑战,PlaNet 的在潜在空间中规划的方法极具影响力,为后续的先进算法(如 Dreamer 系列)铺平了道路。