VoiceFixer语音修复介绍与使用
一.简介
VoiceFixer 是一款基于深度学习的通用语音修复工具,主要用于恢复严重退化的语音信号,支持降噪、消除回声、提升音质等功能。
二.核心功能
1.语音修复与增强
VoiceFixer 采用端到端的神经网络模型,能够处理多种语音退化问题,包括:
降噪:有效抑制背景噪音、环境干扰等。
消除回声:去除录音中的混响和回声效应。
分辨率提升:将低采样率(2kHz 至 44.1kHz)的语音信号恢复至 44.1kHz 高保真音质。
剪切失真修复:修正因信号过载导致的剪切失真(阈值范围 0.1 至 1.0)。
音质增强:提升语音清晰度和自然度,尤其适用于老旧录音或低质量录音的修复。
2.多模式处理
提供三种运行模式,适用于不同场景:
模式 0:原生模型,默认推荐,适合大多数常规情况。
模式 1:增加预处理模块,去除高频段噪声,适用于特定场景(如含高频干扰的录音)。
模式 2:训练模式,在极重度退化的实际语音中可能有较好表现。
3.技术特性
神经声码器技术:基于 44.1kHz 通用说话人无关神经声码器,生成高保真语音。
多任务学习:同时处理噪声、混响、低分辨率等多种退化类型,无需单独调用不同工具。
端到端处理:无需复杂预处理或后处理步骤,直接输入受损语音即可输出修复结果。
三.适用场景
历史录音修复:恢复老旧磁带、广播等录音中的语音,提升清晰度。
会议与通信:改善电话会议、网络通话中的音质,消除背景噪音和回声。
语音识别预处理:优化语音数据质量,提高语音识别系统的准确率。
音频后期制作:修复录音室中的意外损伤,增强人声或乐器音质。
学术研究:作为语音处理工具,用于声学分析、语音合成等领域的数据预处理。
四.优势与特点
智能化与高效性
无需复杂参数调整,模型自动处理多种退化问题,且在现代计算机上运行速度快。
开源与灵活性
代码完全开源,支持用户自由修改和扩展,适合研究与开发。
多平台支持
提供命令行、Python API、桌面应用等多种使用方式,兼容 Windows、Mac 等系统。
成果显著
实际测试显示,VoiceFixer 在改善音频质量方面效果明显,尤其在处理复杂多重退化时表现优异。
五.项目主页
https://github.com/haoheliu/voicefixer
六.安装与使用
1.首先,通过 pip 安装 voicefixer:
pip install git+https://github.com/haoheliu/voicefixer.git
2.关更多帮助程序信息,请运行:
voicefixer -h
3.使用
更改模式(默认模式为 0):
voicefixer --infile /path/to/input.wav --outfile /path/to/output.wav --mode 1
Run all modes: 运行所有模式:
# output file saved to `/path/to/output-modeX.wav`.
voicefixer --infile /path/to/input.wav --outfile /path/to/output.wav --mode all
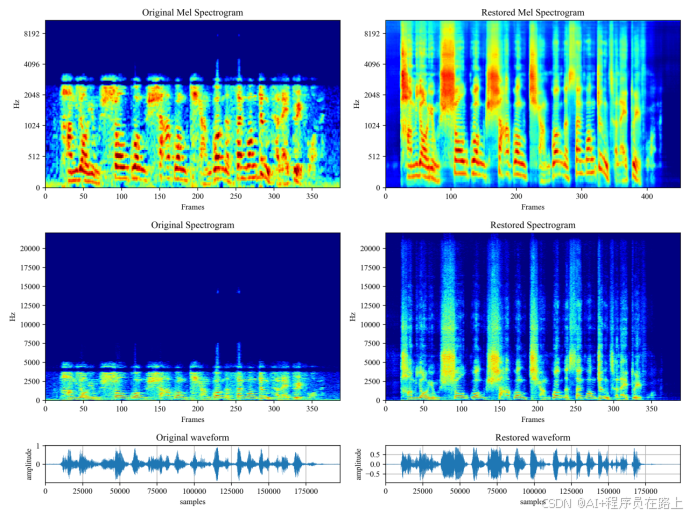
七.声音处理后频谱对比