词向量(Word Embedding)深度解析
一、核心概念
词向量是自然语言处理(NLP)中的基础技术,通过将单词或短语映射到低维实数向量空间,实现文本的数值化表示。其核心价值在于:
- 语义编码:语义相近的词在向量空间中距离更近(如“猫”与“狗”)。
- 数学可操作性:支持向量运算(如“国王-男人+女人≈女王”)。
- 上下文感知:动态模型(如BERT)可生成上下文相关的向量。
二、主流模型对比
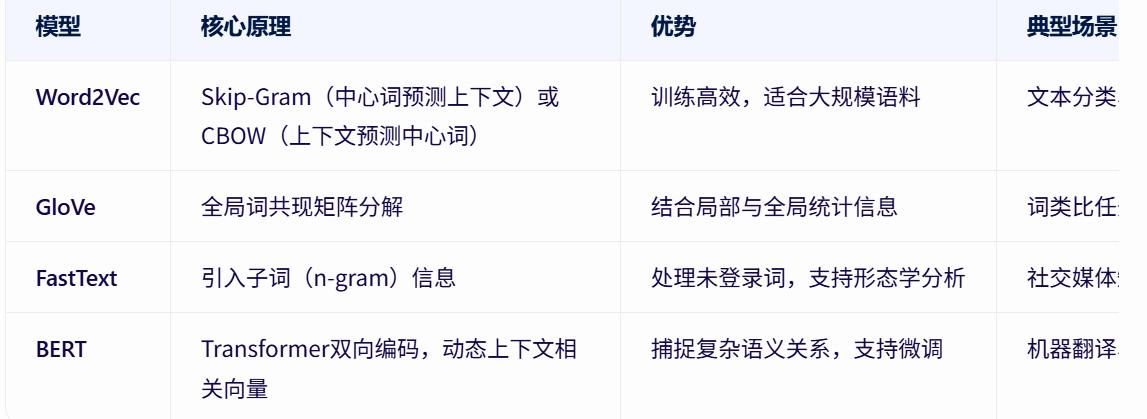
| 模型 | 核心原理 | 优势 | 典型场景 |
|---|---|---|---|
| Word2Vec | Skip-Gram(中心词预测上下文)或CBOW(上下文预测中心词) | 训练高效,适合大规模语料 | 文本分类、推荐系统 |
| GloVe | 全局词共现矩阵分解 | 结合局部与全局统计信息 | 词类比任务、语义相似度计算 |
| FastText | 引入子词(n-gram)信息 | 处理未登录词,支持形态学分析 | 社交媒体短文本、低资源语言 |
| BERT | Transformer双向编码,动态上下文相关向量 | 捕捉复杂语义关系,支持微调 | 机器翻译、问答系统、情感分析 |
三、训练流程与关键参数
- 数据准备
- 清洗与分词:使用Jieba、HanLP等工具处理文本,构建词汇表。
- 构建语料库:如维基百科、新闻数据(需数十GB以上)。
- 模型选择
- 静态向量:Word2Vec、GloVe(适合简单任务)。
- 动态向量:BERT、ELMo(需上下文感知时选用)。
- 参数调优
- 向量维度:通常100-300维(维度越高,表达能力越强,但计算成本增加)。
- 窗口大小:控制上下文范围(如Word2Vec默认窗口为5)。
- 负采样:优化训练效率,减少计算量(如设置负样本数为5-20)。
- 训练与评估
- 训练工具:Gensim(Word2Vec/FastText)、TensorFlow/PyTorch(自定义模型)。
- 评估方法:词类比任务(如“国王-男人+女人=?”)、语义相似度计算。
四、典型应用场景
- 文本分类
- 流程:文本→词向量矩阵→分类器(如SVM、CNN)。
- 案例:情感分析(正面/负面评价分类)。
- 机器翻译
- 原理:通过词向量对齐源语言与目标语言语义空间。
- 工具:使用预训练多语言BERT模型(如mBERT)。
- 信息检索
- 方法:计算查询词与文档向量的余弦相似度。
- 优化:结合TF-IDF加权词向量。
- 语义相似度计算
- 应用:推荐系统(计算用户兴趣与物品描述的相似度)。
- 工具:使用Sentence-BERT生成句子向量。
五、技术演进趋势
- 从静态到动态:从Word2Vec的固定向量到BERT的上下文相关向量。
- 多模态融合:结合图像、语音等多模态数据训练跨模态词向量。
- 轻量化部署:通过知识蒸馏(如DistilBERT)压缩模型,适应移动端场景。
六、工具与资源推荐
- 预训练模型:Hugging Face Transformers库(提供BERT、GPT等模型)。
- 训练框架:Gensim(快速实现Word2Vec/FastText)、TensorFlow/PyTorch(灵活定制)。
- 数据集:维基百科语料库、Common Crawl(PB级网络文本)。
总结:词向量通过将文本转换为数值向量,为NLP任务提供了统一的输入表示。从静态模型到动态模型,词向量技术不断演进,适应了更复杂的语言场景。选择模型时需综合考虑任务需求、计算资源和数据规模。