基于Resnet-34的树叶分类(李沐深度学习基础竞赛)
目录
一,数据集介绍
1.1 数据集下载
1.2 数据集介绍
二,Resnet-34介绍
三,模型训练
四,模型预测
五,测试结果
5.1 测试集结果
5.2 预测结果
5.3 总结
一,数据集介绍
1.1 数据集下载
本数据集下载至沐神的Kaggle竞赛:
Classify Leaves | KaggleTrain models to predict the plant species![]() https://www.kaggle.com/competitions/classify-leaves/data
https://www.kaggle.com/competitions/classify-leaves/data
1.2 数据集介绍
该数据集包含18000张训练集图片和8000张测试集图片,分别以.csv文件给出来

该数据集一共包含176个类别的树叶种类
二,Resnet-34介绍
ResNet-34 是何恺明等人于 2015 年提出的残差神经网络(ResNet)家族成员,因含 34 层可学习卷积层得名,通过引入残差块(含残差连接)解决深度网络梯度消失 / 爆炸和退化问题,其基础残差块由 2 个 3×3 卷积层构成,输入输出通道一致时直接相加,不一致时通过 1×1 卷积投影调整维度;网络结构包括输入层、5 个阶段的卷积层(含下采样和残差块堆叠)、全局平均池化层和全连接分类层,具有支持更深网络训练、计算效率较高等特点,在 ImageNet 等图像分类任务中表现优异,常作为基准模型或用于特征提取,为后续深层网络发展奠定了基础。
Resnet介绍请看:基于CNN的猫狗识别(自定义Resnet-18模型)-CSDN博客
三,模型训练
# 导入数据处理库
import pandas as pd
# 导入操作系统相关库
import os
# 导入PyTorch核心库
import torch
# 导入PyTorch神经网络模块
import torch.nn as nn
# 导入优化器模块
import torch.optim as optim
# 导入学习率调度器模块
from torch.optim import lr_scheduler
# 导入数据集和数据加载相关模块
from torch.utils.data import Dataset, DataLoader, random_split
# 导入计算机视觉相关工具(如图像变换、预训练模型)
from torchvision import transforms, models
# 导入绘图库
import matplotlib.pyplot as plt
# 导入数值计算库
import numpy as np
# 导入图像处理库
from PIL import Image# --------------------------- 基础配置 ---------------------------
# 设置 matplotlib 显示中文字体
plt.rcParams['font.sans-serif'] = ['SimHei']
# 解决 matplotlib 负号显示问题
plt.rcParams['axes.unicode_minus'] = False
# 允许PyTorch重复加载动态链接库(解决Windows下的潜在冲突)
os.environ['KMP_DUPLICATE_LIB_OK'] = 'TRUE'# --------------------------- 数据预处理 ---------------------------
# 定义训练集数据增强和归一化流程
train_transform = transforms.Compose([transforms.Resize((256, 256)), # 将图像Resize到256x256尺寸transforms.RandomRotation(45), # 随机旋转图像(角度范围±45度)transforms.RandomHorizontalFlip(), # 随机水平翻转图像(概率50%)transforms.RandomVerticalFlip(), # 随机垂直翻转图像(概率50%)transforms.ToTensor(), # 将PIL图像转换为PyTorch张量(数值范围[0,1])transforms.Normalize( # 对图像进行标准化(减去均值,除以标准差)mean=[0.7589, 0.7788, 0.7598], # 图像各通道均值std=[0.2477, 0.2347, 0.2630] # 图像各通道标准差)
])# 定义验证集数据预处理流程(仅调整尺寸、转换张量和标准化,无数据增强)
val_transform = transforms.Compose([transforms.Resize((224, 224)), # 将图像Resize到224x224尺寸(适配ResNet输入要求)transforms.ToTensor(), # 转换为PyTorch张量transforms.Normalize( # 标准化,参数与训练集一致mean=[0.7589, 0.7788, 0.7598],std=[0.2477, 0.2347, 0.2630])
])# --------------------------- 自定义数据集 ---------------------------
# 定义树叶数据集类,继承PyTorch的Dataset类
class LeafDataset(Dataset):def __init__(self, csv_file, root_dir, transform=None):# 读取包含图像路径和标签的CSV文件self.data_frame = pd.read_csv(csv_file)# 图像文件根目录self.root_dir = root_dir# 数据预处理变换(如Resize、归一化等)self.transform = transform# 获取所有唯一的标签类别并排序self.classes = sorted(self.data_frame['label'].unique())# 创建标签到索引的映射字典(用于模型输出转换)self.class_to_idx = {cls: i for i, cls in enumerate(self.classes)}def __len__(self):# 返回数据集样本总数return len(self.data_frame)def __getitem__(self, idx):# 处理输入索引(支持Tensor类型索引)if torch.is_tensor(idx):idx = idx.tolist()# 从DataFrame中获取当前样本的图像名称(第一列)img_name = self.data_frame.iloc[idx, 0]# 移除图像名称中的"images/"前缀(如果存在,确保路径正确拼接)img_name = img_name.replace("images/", "")# 拼接图像的完整路径(根目录 + 图像名称)full_path = os.path.join(self.root_dir, img_name)# 读取图像并转换为RGB格式(处理可能的灰度图像)image = Image.open(full_path).convert('RGB')# 获取当前样本的标签(第二列)label = self.data_frame.iloc[idx, 1]# 将标签转换为索引(通过class_to_idx字典)label_idx = self.class_to_idx[label]# 对图像应用预处理变换(如Resize、归一化等)image = self.transform(image)# 返回处理后的图像张量和标签索引return image, label_idx# --------------------------- 定义ResNet-34模型 ---------------------------
# 创建ResNet-34模型的函数,支持加载预训练权重
def create_resnet_model(pretrained=True):# 根据pretrained参数选择是否加载ImageNet预训练权重weights = models.ResNet34_Weights.IMAGENET1K_V1 if pretrained else None# 实例化ResNet-34模型,传入预训练权重model = models.resnet34(weights=weights)# 获取原模型全连接层的输入特征数in_features = model.fc.in_features# 修改全连接层,适配当前任务的类别数(176类)model.fc = nn.Linear(in_features, 176)# 返回自定义后的模型return model# --------------------------- 训练和验证函数 ---------------------------
# 训练和验证模型的函数
def train_model(model, train_loader, val_loader, criterion, optimizer, scheduler, epochs, device):# 记录最佳验证准确率best_val_acc = 0.0# 存储训练历史(损失和准确率)的字典history = {'train_loss': [], 'train_acc': [], 'val_loss': [], 'val_acc': []}for epoch in range(epochs):# --------------------------- 训练阶段 ---------------------------# 设置模型为训练模式(启用Dropout、BatchNorm等训练相关操作)model.train()# 初始化训练损失、正确预测数、样本总数train_loss = 0.0train_correct = 0train_total = 0# 遍历训练数据加载器for inputs, labels in train_loader:# 将输入和标签移动到指定设备(CPU或GPU)inputs, labels = inputs.to(device), labels.to(device)# 清空优化器的梯度缓存optimizer.zero_grad()# 前向传播:模型预测outputs = model(inputs)# 计算损失(交叉熵损失)loss = criterion(outputs, labels)# 反向传播:计算梯度loss.backward()# 优化器更新参数optimizer.step()# 累加训练损失(乘以batch大小,得到总损失)train_loss += loss.item() * inputs.size(0)# 获取预测结果(概率最大的类别索引)_, predicted = outputs.max(1)# 累加样本总数和正确预测数train_total += labels.size(0)train_correct += predicted.eq(labels).sum().item()# 计算平均训练损失和准确率train_loss /= len(train_loader.dataset)train_acc = 100.0 * train_correct / train_total# --------------------------- 验证阶段 ---------------------------# 设置模型为评估模式(禁用Dropout、BatchNorm等训练操作)model.eval()# 初始化验证损失、正确预测数、样本总数val_loss = 0.0val_correct = 0val_total = 0# 禁用梯度计算(节省内存和计算资源)with torch.no_grad():for inputs, labels in val_loader:inputs, labels = inputs.to(device), labels.to(device)outputs = model(inputs)loss = criterion(outputs, labels)val_loss += loss.item() * inputs.size(0)_, predicted = outputs.max(1)val_total += labels.size(0)val_correct += predicted.eq(labels).sum().item()# 计算平均验证损失和准确率val_loss /= len(val_loader.dataset)val_acc = 100.0 * val_correct / val_total# --------------------------- 学习率调整 ---------------------------# 根据验证损失调整学习率(ReduceLROnPlateau策略)scheduler.step(val_loss)# --------------------------- 保存最佳模型 ---------------------------# 如果当前验证准确率高于历史最佳,保存模型参数if val_acc > best_val_acc:best_val_acc = val_acctorch.save(model.state_dict(), 'ClassifyLeaves_model.pth')print(f'保存最佳模型: 验证准确率 = {val_acc:.2f}%')# --------------------------- 记录训练历史 ---------------------------# 将当前epoch的损失和准确率存入history字典history['train_loss'].append(train_loss)history['train_acc'].append(train_acc)history['val_loss'].append(val_loss)history['val_acc'].append(val_acc)# --------------------------- 打印训练日志 ---------------------------print(f'Epoch {epoch + 1}/{epochs}')print(f'Train Loss: {train_loss:.4f} | Train Acc: {train_acc:.2f}%')print(f'Val Loss: {val_loss:.4f} | Val Acc: {val_acc:.2f}%')print('-' * 50)# 返回训练好的模型和训练历史return model, history# --------------------------- 主程序入口 ---------------------------
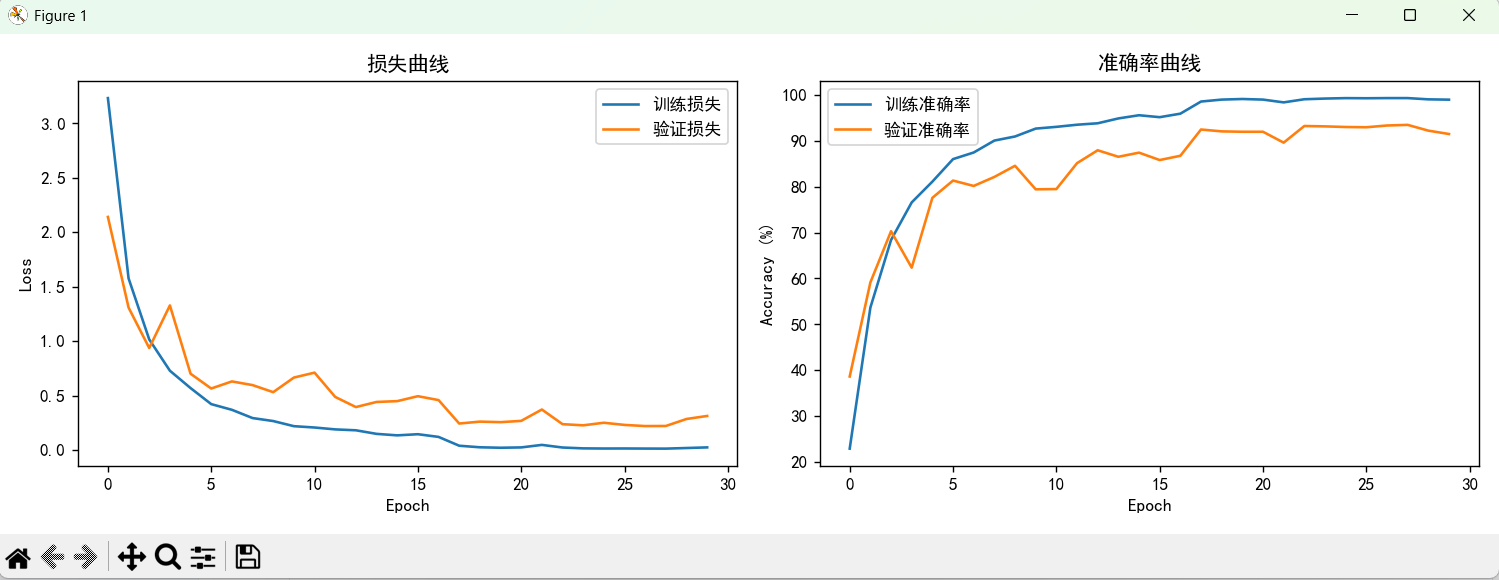
if __name__ == '__main__':# --------------------------- 数据加载配置 ---------------------------# 训练数据CSV文件路径(包含图像名称和标签)csv_file = r"C:\Users\10532\Desktop\Study\Test\Data\classify-leaves\LeavesTrain.csv"# 图像文件根目录image_directory = r"C:\Users\10532\Desktop\Study\Test\Data\classify-leaves\images"# 创建完整数据集(包含所有样本,应用训练集预处理)full_dataset = LeafDataset(csv_file, image_directory, transform=train_transform)# 划分训练集和验证集(8:2比例)train_size = int(0.8 * len(full_dataset))val_size = len(full_dataset) - train_sizetrain_subset, val_subset = random_split(full_dataset, [train_size, val_size])# 为验证集单独设置预处理变换(使用val_transform)val_subset.dataset.transform = val_transform# --------------------------- 创建数据加载器 ---------------------------# 训练数据加载器(设置批量大小、是否打乱、线程数等)train_loader = DataLoader(train_subset, # 训练子集batch_size=32, # 批量大小为32shuffle=True, # 训练时打乱数据顺序num_workers=4, # 使用4个线程加载数据pin_memory=torch.cuda.is_available() # 如果有GPU,启用锁页内存加速数据传输)# 验证数据加载器(不打乱数据,其他配置与训练集一致)val_loader = DataLoader(val_subset,batch_size=32,shuffle=False,num_workers=4,pin_memory=torch.cuda.is_available())# 打印数据加载信息print(f"成功加载 {len(full_dataset)} 个样本")print(f"训练集大小: {len(train_subset)}, 验证集大小: {len(val_subset)}")print(f"类别数量: {len(full_dataset.classes)}")# --------------------------- 初始化设备和模型 ---------------------------# 自动检测是否有GPU可用,设置计算设备device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")# 创建ResNet-34模型,加载预训练权重,并移动到指定设备model = create_resnet_model(pretrained=True).to(device)# --------------------------- 定义损失函数和优化器 ---------------------------# 交叉熵损失函数(适用于多分类任务)criterion = nn.CrossEntropyLoss()# Adam优化器(学习率0.001)optimizer = optim.Adam(model.parameters(), lr=0.001)# 学习率调度器(根据验证损失降低学习率)scheduler = lr_scheduler.ReduceLROnPlateau(optimizer, mode='min', patience=3, factor=0.5)# --------------------------- 开始训练 ---------------------------print("开始训练ResNet-34模型...")# 调用训练函数,返回训练好的模型和训练历史model, history = train_model(model=model,train_loader=train_loader,val_loader=val_loader,criterion=criterion,optimizer=optimizer,scheduler=scheduler,epochs=30, # 训练30个epochdevice=device)# --------------------------- 结果可视化 ---------------------------# 创建绘图窗口plt.figure(figsize=(12, 4))# 绘制损失曲线子图(左)plt.subplot(1, 2, 1)plt.plot(history['train_loss'], label='训练损失')plt.plot(history['val_loss'], label='验证损失')plt.legend() # 显示图例plt.title('损失曲线') # 设置子图标题plt.xlabel('Epoch') # 设置x轴标签plt.ylabel('Loss') # 设置y轴标签# 绘制准确率曲线子图(右)plt.subplot(1, 2, 2)plt.plot(history['train_acc'], label='训练准确率')plt.plot(history['val_acc'], label='验证准确率')plt.legend()plt.title('准确率曲线')plt.xlabel('Epoch')plt.ylabel('Accuracy (%)')plt.tight_layout() # 自动调整子图间距plt.show() # 显示图像# 打印最佳验证集准确率print(f"最佳验证集准确率: {max(history['val_acc']):.2f}%") 代码构建了一个基于 ResNet-34 的树叶分类模型训练框架,涵盖数据处理、模型构建、训练优化及结果分析全流程。首先,通过自定义数据集类LeafDataset读取训练数据,分离图像路径与标签并构建类别索引映射,同时对训练集和验证集应用差异化预处理:训练集采用 Resize、随机旋转、翻转等数据增强策略提升泛化能力,验证集仅保留 Resize、标准化以确保数据一致性。模型基于 ResNet-34 架构,加载 ImageNet 预训练权重并修改全连接层适配 176 类分类任务,采用交叉熵损失函数与 Adam 优化器,搭配学习率动态调整策略(ReduceLROnPlateau)以避免过拟合。训练过程中实时记录损失与准确率,自动保存验证准确率最高的模型参数,并通过 Matplotlib 可视化训练历史曲线,直观呈现模型收敛趋势。
四,模型预测
# 导入数据处理库
import pandas as pd
# 导入操作系统相关库
import os
# 导入PyTorch核心库
import torch
# 导入PyTorch神经网络模块
import torch.nn as nn
# 导入数据集和数据加载相关模块
from torch.utils.data import Dataset, DataLoader
# 导入计算机视觉相关工具(如图像变换、预训练模型)
from torchvision import transforms, models
# 导入图像处理库
from PIL import Image# --------------------------- 基础配置 ---------------------------
# 允许PyTorch重复加载动态链接库(解决Windows下的潜在冲突)
os.environ['KMP_DUPLICATE_LIB_OK'] = 'TRUE'# --------------------------- 数据预处理 ---------------------------
# 定义测试集数据预处理流程(调整尺寸、转换张量、标准化,无数据增强)
test_transform = transforms.Compose([transforms.Resize((224, 224)), # 将图像Resize到224x224尺寸(适配ResNet输入要求)transforms.ToTensor(), # 将PIL图像转换为PyTorch张量(数值范围[0,1])transforms.Normalize( # 对图像进行标准化(减去均值,除以标准差)mean=[0.7589, 0.7788, 0.7598], # 图像各通道均值(需与训练集一致)std=[0.2477, 0.2347, 0.2630] # 图像各通道标准差(需与训练集一致))
])# --------------------------- 自定义数据集 ---------------------------
# 定义测试数据集类,继承PyTorch的Dataset类
class TestDataset(Dataset):def __init__(self, csv_file, root_dir, transform=None):# 读取测试数据CSV文件(第一列为图像名称,第二列留空)self.data_frame = pd.read_csv(csv_file)# 图像文件根目录self.root_dir = root_dir# 数据预处理变换(如Resize、归一化等)self.transform = transform# 检查图像文件是否存在(自定义方法,用于提前发现缺失文件)self.check_image_files()def __len__(self):# 返回测试数据集样本总数return len(self.data_frame)def __getitem__(self, idx):# 处理输入索引(支持Tensor类型索引)if torch.is_tensor(idx):idx = idx.tolist()# 从DataFrame中获取当前样本的图像名称(第一列)img_name = self.data_frame.iloc[idx, 0]# 移除图像名称中的"images/"前缀(如果存在,确保路径正确拼接)img_name = img_name.replace("images/", "")# 拼接图像的完整路径(根目录 + 图像名称)full_path = os.path.join(self.root_dir, img_name)# 尝试读取图像,若失败则返回空白图像并打印错误信息try:image = Image.open(full_path).convert('RGB') # 转换为RGB格式except Exception as e:print(f"Error loading image {full_path}: {str(e)}")# 返回224x224的白色空白图像作为替代image = Image.new('RGB', (224, 224), color='white')# 对图像应用预处理变换(如Resize、归一化等)if self.transform:image = self.transform(image)# 返回处理后的图像张量和原始图像名称(不含"images/"前缀)return image, img_namedef check_image_files(self):# 检查所有图像文件是否存在,记录缺失的文件名missing_files = []for idx in range(len(self.data_frame)):img_name = self.data_frame.iloc[idx, 0]img_name = img_name.replace("images/", "") # 移除前缀full_path = os.path.join(self.root_dir, img_name) # 完整路径if not os.path.exists(full_path):missing_files.append(img_name) # 记录缺失文件# 打印缺失文件警告(最多显示前10个)if missing_files:print(f"警告: 找不到 {len(missing_files)} 个图像文件")for file in missing_files[:10]:print(f" - {file}")if len(missing_files) > 10:print(f" - ... 和其他 {len(missing_files) - 10} 个文件")# --------------------------- 定义ResNet-34模型 ---------------------------
# 创建ResNet-34模型的函数(支持加载预训练权重或随机初始化)
def create_resnet_model(weights=None):# 实例化ResNet-34模型,传入权重参数(None表示随机初始化)model = models.resnet34(weights=weights)# 获取原模型全连接层的输入特征数in_features = model.fc.in_features# 修改全连接层,适配当前任务的类别数(176类,需与训练时一致)model.fc = nn.Linear(in_features, 176)# 返回自定义后的模型return model# --------------------------- 预测函数 ---------------------------
# 对测试集进行预测的函数
def predict(model, test_loader, device, class_to_idx):# 设置模型为评估模式(禁用Dropout、BatchNorm等训练操作)model.eval()# 初始化预测结果列表和图像名称列表predictions = []image_names = []# 禁用梯度计算(节省内存和计算资源)with torch.no_grad():# 遍历测试数据加载器for inputs, img_names in test_loader:# 将输入数据移动到指定设备(CPU或GPU)inputs = inputs.to(device)# 前向传播:模型预测outputs = model(inputs)# 获取预测结果(概率最大的类别索引)_, predicted = torch.max(outputs, 1)# 将预测索引转换为类别名称(通过反向映射字典)idx_to_class = {v: k for k, v in class_to_idx.items()}predicted_classes = [idx_to_class[idx.item()] for idx in predicted]# 累加预测结果和图像名称predictions.extend(predicted_classes)image_names.extend(img_names)# 返回图像名称列表和预测标签列表return image_names, predictions# --------------------------- 保存结果到CSV ---------------------------
# 将预测结果保存到CSV文件的函数
def save_predictions_to_csv(image_names, predictions, csv_path):# 在图像名称前添加"images/"前缀(符合输出要求)prefixed_image_names = [f"images/{name}" for name in image_names]# 创建DataFrame,结构为:image列(带前缀)、label列(预测标签)result_df = pd.DataFrame({'image': prefixed_image_names,'label': predictions})# 保存为CSV文件,不包含索引列result_df.to_csv(csv_path, index=False)# 打印保存成功信息print(f"预测结果已保存到 {csv_path}")# --------------------------- 主程序入口 ---------------------------
if __name__ == '__main__':# --------------------------- 数据加载配置 ---------------------------# 测试数据CSV文件路径(第一列为图像名称,第二列留空)test_csv_file = r"C:\Users\10532\Desktop\Study\Test\Data\classify-leaves\LeavesTest.csv"# 图像文件根目录image_directory = r"C:\Users\10532\Desktop\Study\Test\Data\classify-leaves\images"# 输出CSV文件路径output_csv = "submission.csv"# 从训练数据中获取类别映射(需与训练时一致)train_csv_file = r"C:\Users\10532\Desktop\Study\Test\Data\classify-leaves\LeavesTrain.csv"train_df = pd.read_csv(train_csv_file) # 读取训练数据CSVclasses = sorted(train_df['label'].unique()) # 获取所有唯一标签并排序class_to_idx = {cls: i for i, cls in enumerate(classes)} # 创建标签到索引的映射# --------------------------- 创建测试数据集和数据加载器 ---------------------------# 实例化测试数据集类,应用测试集预处理变换test_dataset = TestDataset(test_csv_file, image_directory, transform=test_transform)# 创建测试数据加载器(设置批量大小、线程数等)test_loader = DataLoader(test_dataset, # 测试数据集batch_size=32, # 批量大小为32shuffle=False, # 测试时不打乱数据顺序num_workers=4, # 使用4个线程加载数据pin_memory=torch.cuda.is_available() # 如果有GPU,启用锁页内存加速数据传输)# 打印测试数据加载成功信息print(f"成功加载 {len(test_dataset)} 个测试样本")# --------------------------- 初始化设备和模型 ---------------------------# 自动检测是否有GPU可用,设置计算设备device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")# 创建ResNet-34模型(不加载预训练权重,使用训练好的参数)model = create_resnet_model(weights=None).to(device)# 加载训练好的模型参数model_path = 'ClassifyLeaves_model.pth'model.load_state_dict(torch.load(model_path, map_location=device)) # map_location确保兼容不同设备print(f"已加载模型: {model_path}")# --------------------------- 进行预测 ---------------------------# 打印提示信息print("开始预测...")# 调用预测函数,获取图像名称和预测标签image_names, predictions = predict(model, test_loader, device, class_to_idx)# --------------------------- 保存预测结果 ---------------------------# 调用保存函数,将结果写入CSV文件save_predictions_to_csv(image_names, predictions, output_csv) 测试代码围绕训练好的 ResNet-34 模型构建推理流程,实现从测试数据加载到预测结果输出的自动化。通过自定义TestDataset类读取测试集 CSV 文件,自动移除图像名称中的固定前缀并拼接完整路径,同时集成文件存在性检查功能(check_image_files),提前捕获缺失文件并输出警告列表,增强鲁棒性。图像加载过程包含异常处理逻辑,若文件读取失败则返回固定尺寸的空白图像,避免单个样本问题导致程序中断。预处理流程与训练阶段的验证集完全一致,确保输入数据格式统一。
模型加载阶段通过create_resnet_model函数实例化 ResNet-34 架构,加载训练保存的参数文件并适配当前设备(CPU/GPU)。预测函数predict采用批量推理模式,禁用梯度计算以提升效率,通过反向映射字典将模型输出的类别索引转换为具体标签名称。结果处理环节为图像名称添加 “images/” 前缀,生成符合要求的 CSV 文件(第一列为带前缀的图像名,第二列为预测标签)
五,测试结果
5.1 测试集结果

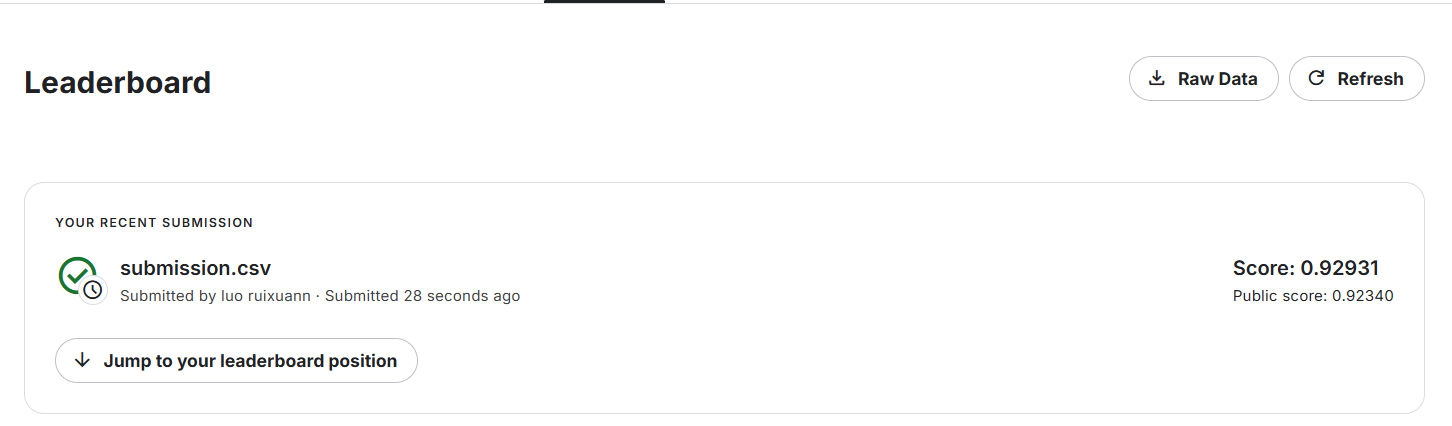
5.2 预测结果
上传至kaggle比赛,准确度大概是92.9%
5.3 总结
本次使用的Resnet-34实测其实和Resnet-18跑出来的结果和准确度是大差不差的,要实现更高的准确度,数据层面,训练集可增加颜色抖动、随机裁剪等增强策略,引入加权采样或 Focal Loss 应对类别不平衡,测试集可添加置信度输出或 Top-K 预测提升结果可靠性;模型训练方面,可集成混合精度训练加速计算,加入早停机制避免过拟合,采用余弦退火等学习率调度策略优化收敛过程,同时补充精确率、召回率等评估指标及混淆矩阵可视化以全面分析性能。