黑马点评相关知识总结
黑马点评的项目总结
主要就黑马点评项目里面的一些比较重要部分的一次总结,方便以后做复习。
基于Session实现短信登录
短信验证码登录
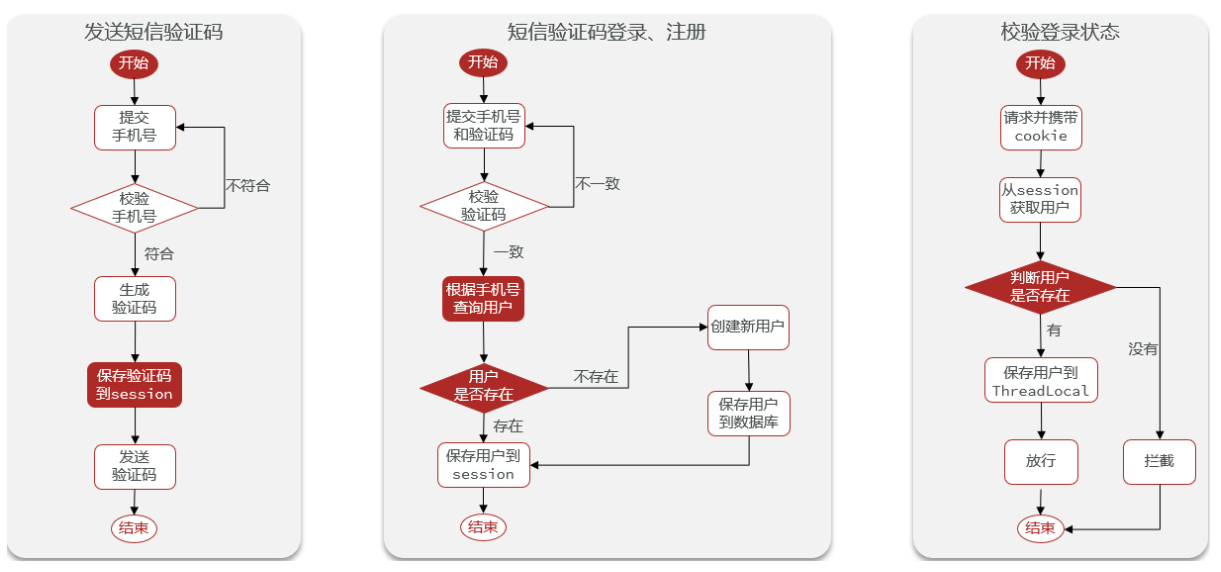
这部分使用常规的session来存储用户的登录状态,其中短信发送采取逻辑形式,并不配置云服务验证码功能。
/*** 发送验证码*/@Overridepublic Result sendCode(String phone, HttpSession session) {// 1、判断手机号是否合法if (RegexUtils.isPhoneInvalid(phone)) {return Result.fail("手机号格式不正确");}// 2、手机号合法,生成验证码,并保存到Session中String code = RandomUtil.randomNumbers(6);session.setAttribute(SystemConstants.VERIFY_CODE, code);// 3、发送验证码log.info("验证码:{}", code);return Result.ok();}/*** 用户登录*/@Overridepublic Result login(LoginFormDTO loginForm, HttpSession session) {String phone = loginForm.getPhone();String code = loginForm.getCode();// 1、判断手机号是否合法if (RegexUtils.isPhoneInvalid(phone)) {return Result.fail("手机号格式不正确");}// 2、判断验证码是否正确String sessionCode = (String) session.getAttribute(LOGIN_CODE);if (code == null || !code.equals(sessionCode)) {return Result.fail("验证码不正确");}// 3、判断手机号是否是已存在的用户User user = this.getOne(new LambdaQueryWrapper<User>().eq(User::getPassword, phone));if (Objects.isNull(user)) {// 用户不存在,需要注册user = createUserWithPhone(phone);}// 4、保存用户信息到Session中,便于后面逻辑的判断(比如登录判断、随时取用户信息,减少对数据库的查询)session.setAttribute(LOGIN_USER, user); // userreturn Result.ok();}/*** 根据手机号创建用户*/private User createUserWithPhone(String phone) {User user = new User();user.setPhone(phone);user.setNickName(SystemConstants.USER_NICK_NAME_PREFIX + RandomUtil.randomString(10));this.save(user);return user;}
登录拦截器配置
在本项目中,一些功能需要进行登录才能够使用,一些功能则可以直接访问。本项目采用拦截器的形式对有无用户登录进行判断,并及时将信息存储到Threadlocal里面
public class LoginInterceptor implements HandlerInterceptor {/*** 前置拦截器,用于判断用户是否登录*/@Overridepublic boolean preHandle(HttpServletRequest request, HttpServletResponse response, Object handler) throws Exception {HttpSession session = request.getSession();// 1、判断用户是否存在User user = (User) session.getAttribute(LOGIN_USER);if (Objects.isNull(user)){// 用户不存在,直接拦截response.setStatus(HttpStatus.HTTP_UNAUTHORIZED);return false;}// 2、用户存在,则将用户信息保存到ThreadLocal中,方便后续逻辑处理// 比如:方便获取和使用用户信息,session获取用户信息是具有侵入性的UserHolder.saveUser(user);return true;}
}
同时需要配置相应拦截的url
@Configuration
public class WebMvcConfig implements WebMvcConfigurer {@Overridepublic void addInterceptors(InterceptorRegistry registry) {// 添加登录拦截器registry.addInterceptor(new LoginInterceptor())// 设置放行请求.excludePathPatterns("/user/code","/user/login","/blog/hot","/shop/**","/shop-type/**","/upload/**","/voucher/**");}
}
数据脱敏
对返回用户信息中的敏感字段进行去除
@Data
public class UserDTO {private Long id;private String nickName;private String icon;
}
使用这个DTO替换上面的User实体类即可
Session引发的问题
- 由于不同的Tomcat并不共享session信息,当请求切换到不同的服务器时导致信息丢失问题(例子:nginx做复杂均衡)
- 同时存储的在服务端session很多的时候导致需要的内存变多
常见解决方案(session共享)
这里采用redis来实现共享功能
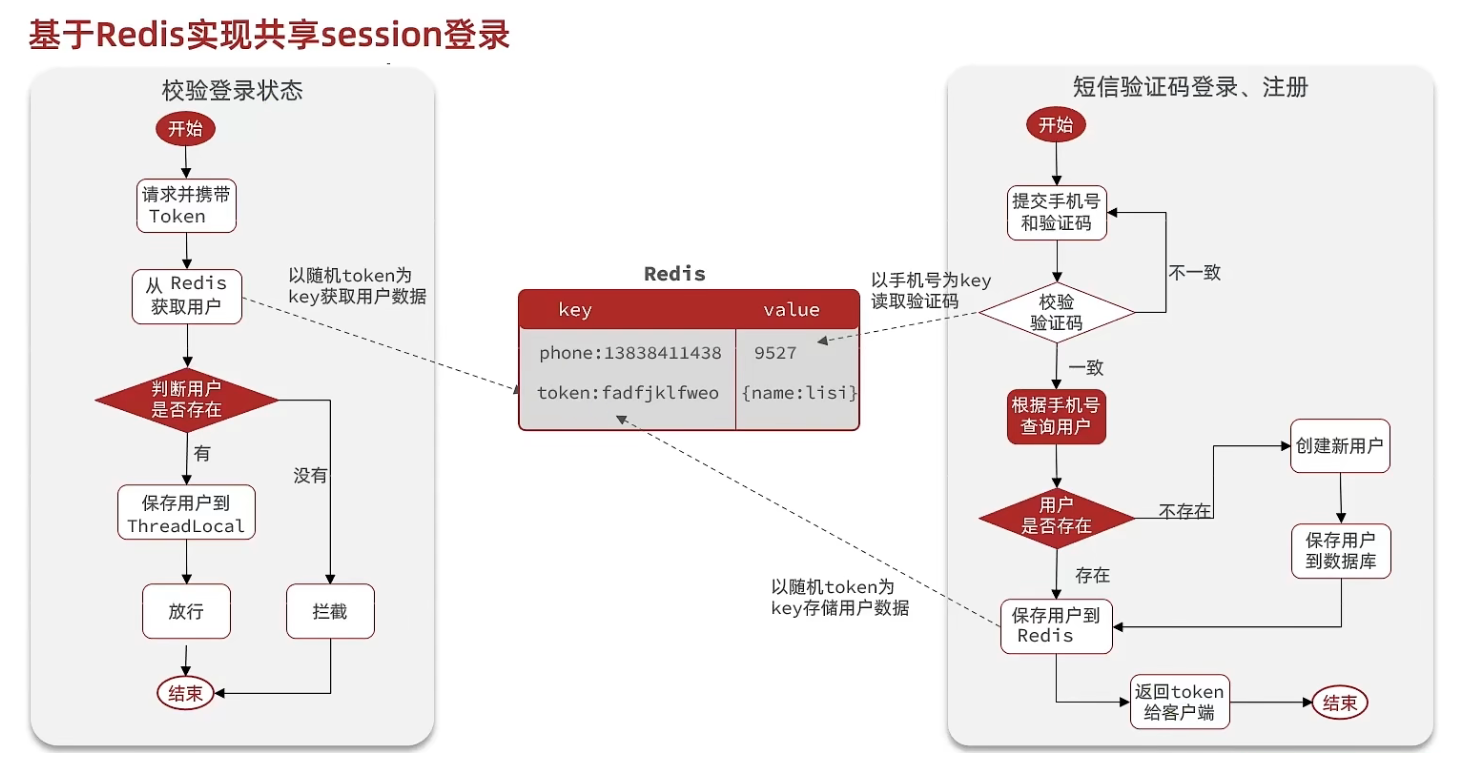
/*** 发送验证码** @param phone* @param session* @return*/@Overridepublic Result sendCode(String phone, HttpSession session) {if(RegexUtils.isPhoneInvalid(phone)){//手机号格式错误return Result.fail("手机号格式错误");}String code = RandomUtil.randomNumbers(6);// 保存到session//session.setAttribute("code", code);stringRedisTemplate.opsForValue().set(LOGIN_CODE_KEY + phone, code, LOGIN_CODE_TTL, TimeUnit.MINUTES);System.out.println("code = " + code);return Result.ok();}/*** 登录功能*/@Overridepublic Result login(LoginFormDTO loginForm, HttpSession session) {String phone = loginForm.getPhone();if (RegexUtils.isPhoneInvalid(phone)) {// 1. 校验手机号return Result.fail("手机号格式错误");}// 校验验证码String code = loginForm.getCode();String cacheCode = stringRedisTemplate.opsForValue().get(LOGIN_CODE_KEY + phone);if(cacheCode == null || !cacheCode.equals(code)){return Result.fail("验证码错误");}// 查询User user = this.query().eq("phone", phone).one();if(user == null){// 不存在则创建user = createUserWithPhone(phone);}// 保存用户信息到session//session.setAttribute("user", BeanUtil.copyProperties(user, UserDTO.class));// 保存到redis中String token = UUID.randomUUID().toString();UserDTO userDTO = BeanUtil.copyProperties(user, UserDTO.class);// 将对象中字段全部转成string类型,StringRedisTemplate只能存字符串类型的数据Map<String, Object> userMap = BeanUtil.beanToMap(userDTO,new HashMap<>(), CopyOptions.create().setIgnoreNullValue(true).setFieldValueEditor((fieldName,fieldValue) ->String.valueOf(fieldValue)));String tokenKey = LOGIN_USER_KEY + token;stringRedisTemplate.opsForHash().putAll(tokenKey, userMap);stringRedisTemplate.expire(tokenKey, LOGIN_USER_TTL, TimeUnit.MINUTES);return Result.ok(token);}
配置刷新token有效期的拦截器
用户在访问页面的时候,就应该刷新token的有效期。这个时候拦截登录信息的拦截器显得不够。这个时候需要设置另外一个拦截器,只要在登录状态(查redis的共享session查到)访问页面就及时刷新token的到期时间。
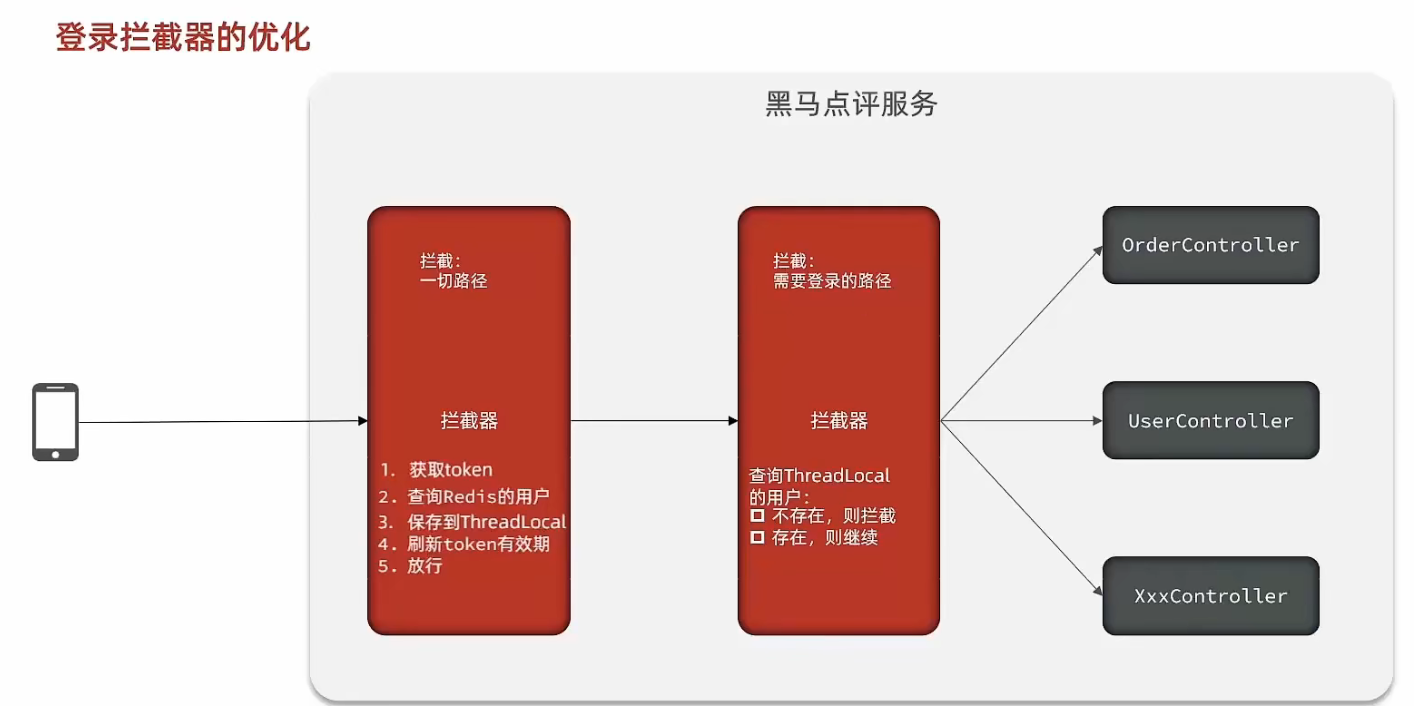
登录拦截器
/*** 在执行Controller之前进行拦截,判断用户是否登录* @param request* @param response* @param handler* @return* @throws Exception*/@Overridepublic boolean preHandle(HttpServletRequest request, HttpServletResponse response, Object handler) throws Exception {if(UserHolder.getUser() == null){response.setStatus(401);return false;}return true;}
刷新token拦截器
public class RefreshTokenInterceptor implements HandlerInterceptor {private StringRedisTemplate stringRedisTemplate;public RefreshTokenInterceptor(StringRedisTemplate stringRedisTemplate) {this.stringRedisTemplate = stringRedisTemplate;}@Overridepublic boolean preHandle(HttpServletRequest request, HttpServletResponse response, Object handler) throws Exception {String token = request.getHeader("authorization");// 判断请求头是否为空if(StrUtil.isBlank(token)){return true;}Map<Object, Object> entries = stringRedisTemplate.opsForHash().entries(LOGIN_USER_KEY + token);if(entries.isEmpty()){response.setStatus(401);return true;}// 将redis中的用户信息转换为UserDTOUserDTO userDTO = BeanUtil.fillBeanWithMap(entries, new UserDTO(), false);// 将用户信息保存到ThreadLocal中UserHolder.saveUser(userDTO);// 刷新stringRedisTemplate.expire(LOGIN_USER_KEY + token, LOGIN_USER_TTL, TimeUnit.MINUTES);return true;}/*** 在请求处理完成后执行删除* @param request* @param response* @param handler* @param ex* @throws Exception*/@Overridepublic void afterCompletion(HttpServletRequest request, HttpServletResponse response, Object handler, Exception ex) throws Exception {UserHolder.removeUser();}
}
同时在SpringMVC中注册,配置相应的实行顺序。
缓存应用
使用缓存能够大大的提高读写性能,其中数据只做临时存放。
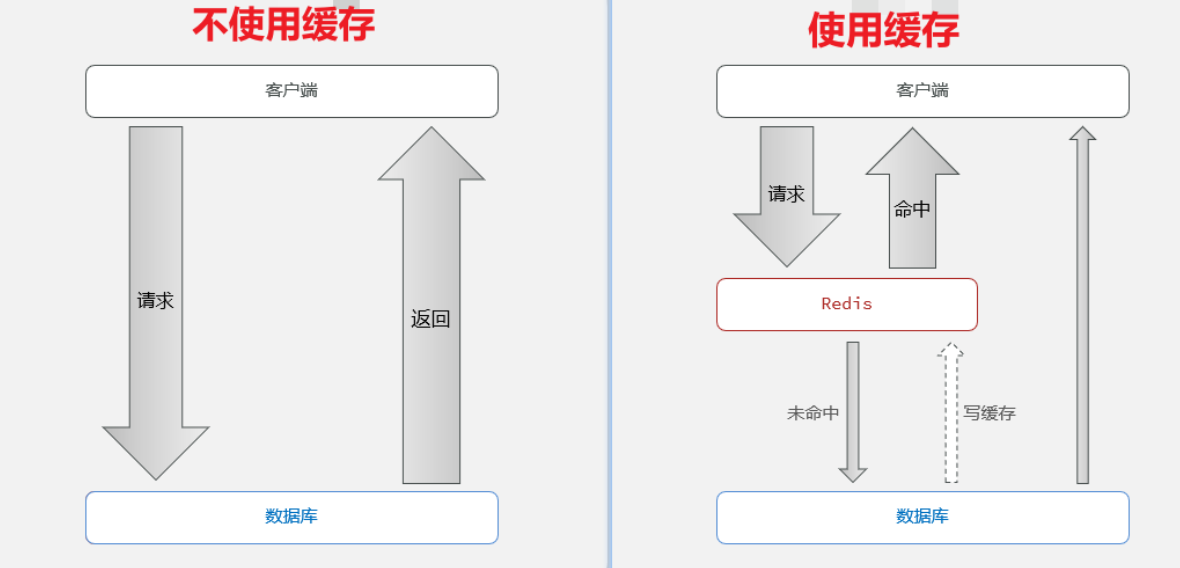
缓存商铺信息
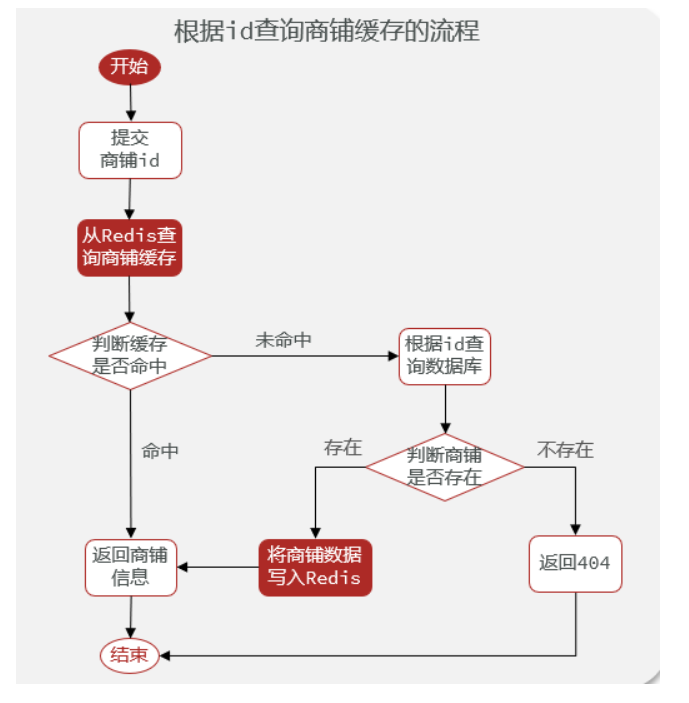 ****
****
/*** 根据id查询商铺数据** @param id* @return*/
@Override
public Result queryById(Long id) {String key = CACHE_SHOP_KEY + id;// 1、从Redis中查询店铺数据String shopJson = stringRedisTemplate.opsForValue().get(key);Shop shop = null;// 2、判断缓存是否命中if (StrUtil.isNotBlank(shopJson)) {// 2.1 缓存命中,直接返回店铺数据shop = JSONUtil.toBean(shopJson, Shop.class);return Result.ok(shop);}// 2.2 缓存未命中,从数据库中查询店铺数据shop = this.getById(id);// 4、判断数据库是否存在店铺数据if (Objects.isNull(shop)) {// 4.1 数据库中不存在,返回失败信息return Result.fail("店铺不存在");}// 4.2 数据库中存在,写入Redis,并返回店铺数据stringRedisTemplate.opsForValue().set(key, JSONUtil.toJsonStr(shop));return Result.ok(shop);
}
数据一致性问题
缓存的使用会带来,redis中的数据与数据中的数据不同步,为了同步需要采用相应的更新策略。
- 常见策略
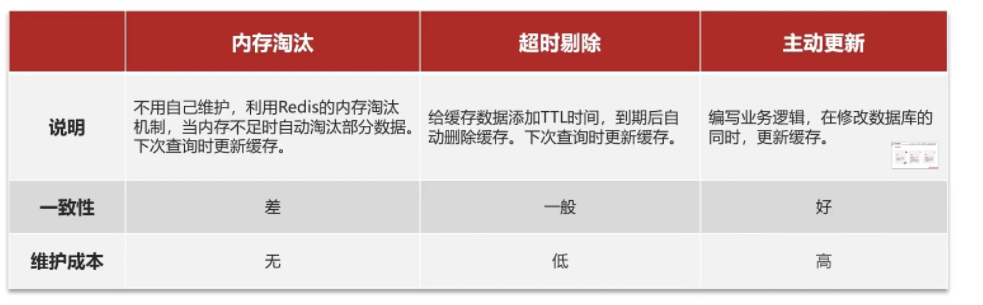
- 超时剔除:即手动设置TTL,到期后redis自动进行删除缓存
- 主动更新:手动编码的方式对缓存进行更新,修改数据库的同时修改缓存。
- 双写方案:缓存调用者在更新完数据库后在更新缓存
- 读取(Read):当需要读取数据时,首先检查缓存是否存在该数据。如果缓存中存在,直接返回缓存中的数据。如果缓存中不存在,则从底层数据存储(如数据库)中获取数据,并将数据存储到缓存中,以便以后的读取操作可以更快地访问该数据。
- 写入(Write):当进行数据写入操作时,首先更新底层数据存储中的数据。然后,根据具体情况,可以选择直接更新缓存中的数据(使缓存与底层数据存储保持同步),或者是简单地将缓存中与修改数据相关的条目标记为无效状态(缓存失效),以便下一次读取时重新加载最新数据
- 使用双写方案注意事项
- 删除缓存还是更新缓存
- 删除缓存(√) :更新数据时更新数据库并删除缓存,查询时在更新缓存,无效写操作较少
- 先操作缓存还是先操作数据库?
- 先操作缓存:先删除缓存,在更新数据库(不推荐)
- 原因:在更新数据库时,由于数据库写操作耗时大,可能出现期间有其他线程来读缓存,这个时候缓存实际被删了,会出现缓存穿透 (发生的概率大)
- 先操作数据库:先更新数据库,在删除缓存(推荐)
- 当一个线程查询缓存未命中时,他在查询数据后,要将数据写入缓存。另一个线程去更新数据库,并删除缓存。这个时候写入的缓存会出现脏数据的问题。但实际上查询数据库与写入缓存的速度明显大于数据库更新加删除缓存。这个事件发生的概率低。
- 删除缓存(√) :更新数据时更新数据库并删除缓存,查询时在更新缓存,无效写操作较少
- 删除缓存还是更新缓存
- 双写方案:缓存调用者在更新完数据库后在更新缓存
缓存主动更新策略的实现
/*** 根据id查询商铺数据(查询时,重建缓存)** @param id* @return*/
@Override
public Result queryById(Long id) {String key = CACHE_SHOP_KEY + id;// 1、从Redis中查询店铺数据String shopJson = stringRedisTemplate.opsForValue().get(key);Shop shop = null;// 2、判断缓存是否命中if (StrUtil.isNotBlank(shopJson)) {// 2.1 缓存命中,直接返回店铺数据shop = JSONUtil.toBean(shopJson, Shop.class);return Result.ok(shop);}// 2.2 缓存未命中,从数据库中查询店铺数据shop = this.getById(id);// 4、判断数据库是否存在店铺数据if (Objects.isNull(shop)) {// 4.1 数据库中不存在,返回失败信息return Result.fail("店铺不存在");}// 4.2 数据库中存在,重建缓存,并返回店铺数据stringRedisTemplate.opsForValue().set(key, JSONUtil.toJsonStr(shop), CACHE_SHOP_TTL, TimeUnit.MINUTES);return Result.ok(shop);
}/*** 更新商铺数据(更新时,更新数据库,删除缓存)** @param shop* @return*/
@Transactional
@Override
public Result updateShop(Shop shop) {// 1、更新数据库中的店铺数据boolean flag = this.updateById(shop);if (!flag){// 缓存更新失败,抛出异常,事务回滚throw new RuntimeException("数据库更新失败");}// 2、删除缓存f = stringRedisTemplate.delete(CACHE_SHOP_KEY + shop.getId());if (!f){// 缓存删除失败,抛出异常,事务回滚throw new RuntimeException("缓存删除失败");}return Result.ok();
}缓存穿透、缓存雪崩、缓存击穿解决方案参考另一篇博客
优惠券秒杀
全局唯一ID
-
单纯使用数据库自增ID存在的问题
- ID规律性太明显了
- 数据量大时,进行分表后ID不能相同,需要保证唯一性
-
分布式ID的实现方式:
-
UUID
-
Redis自增
-
数据库自增
-
snowflake算法(雪花算法)
-
全局ID生成器(自定义)

ID的组成部分:符号位:1bit,永远为0
时间戳:31bit,以秒为单位,可以使用69年
序列号:32bit,秒内的计数器,支持每秒产生2^32个不同ID
@Component
public class RedisIdWorker {/*** 开始时间戳*/private static final long BEGIN_TIMESTAMP = 1640995200L;/*** 序列号的位数*/private static final int COUNT_BITS = 32;private StringRedisTemplate stringRedisTemplate;public RedisIdWorker(StringRedisTemplate stringRedisTemplate) {this.stringRedisTemplate = stringRedisTemplate;}public long nextId(String keyPrefix) {// 1.生成时间戳LocalDateTime now = LocalDateTime.now();long nowSecond = now.toEpochSecond(ZoneOffset.UTC);long timestamp = nowSecond - BEGIN_TIMESTAMP;// 2.生成序列号,需要总体自增// 2.1.获取当前日期,精确到天String date = now.format(DateTimeFormatter.ofPattern("yyyy:MM:dd"));// 2.2.自增长long count = stringRedisTemplate.opsForValue().increment("icr:" + keyPrefix + ":" + date);// 3.拼接并返回return timestamp << COUNT_BITS | count;}
}
优惠券秒杀
解决库存超卖问题
由于多线程情况下,会导致多个线程都查询库存充足,同时进行扣减造成超卖现象。
超卖常见解决方案
- 悲观锁 认为线程安全问题一定会发生,因此操作数据库之前都需要先获取锁,确保线程串行执行。常见的悲观锁有:
synchronized、lock - 乐观锁,认为线程安全问题不一定发生,因此不加锁,只会在更新数据库的时候去判断有没有其它线程对数据进行修改,如果没有修改则认为是安全的,直接更新数据库中的数据即可,如果修改了则说明不安全,直接抛异常或者等待重试。常见的实现方式有:版本号法、CAS操作
- 应用场景
- 悲观锁:写入操作较多和冲突频发的场景适合
- 乐观锁:适合读取操作多、冲突较少的场景
拓展CAS
乐观锁解决超卖问题
实现方式一:版本号法
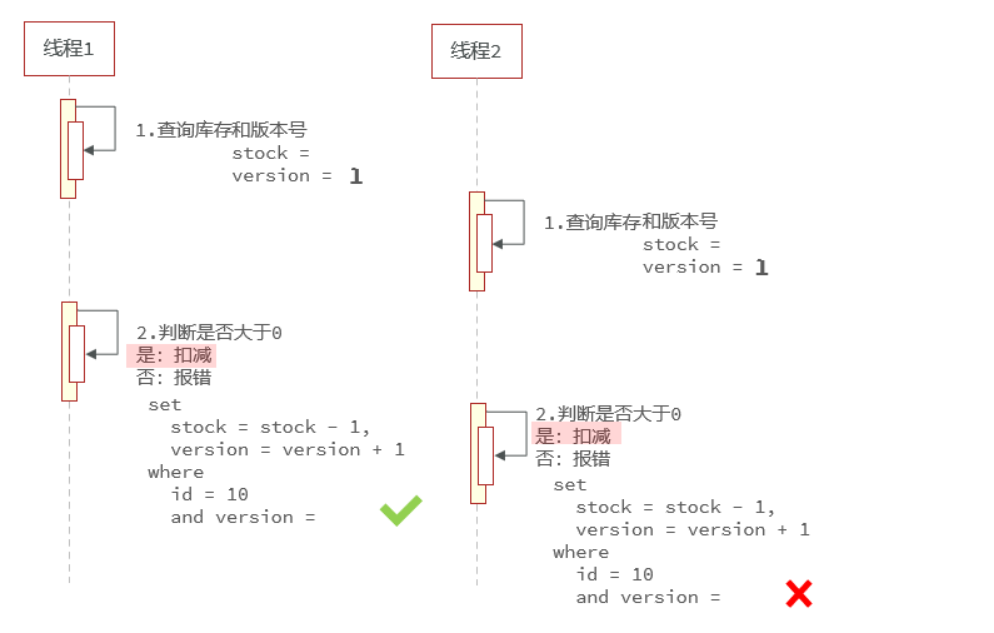
这种方式需要为表中新增一个字段version,在执行库存扣减操作时将版本号加一并对比当前此时的版本与之前查到的版本是否相同。
实现方式二:CAS法
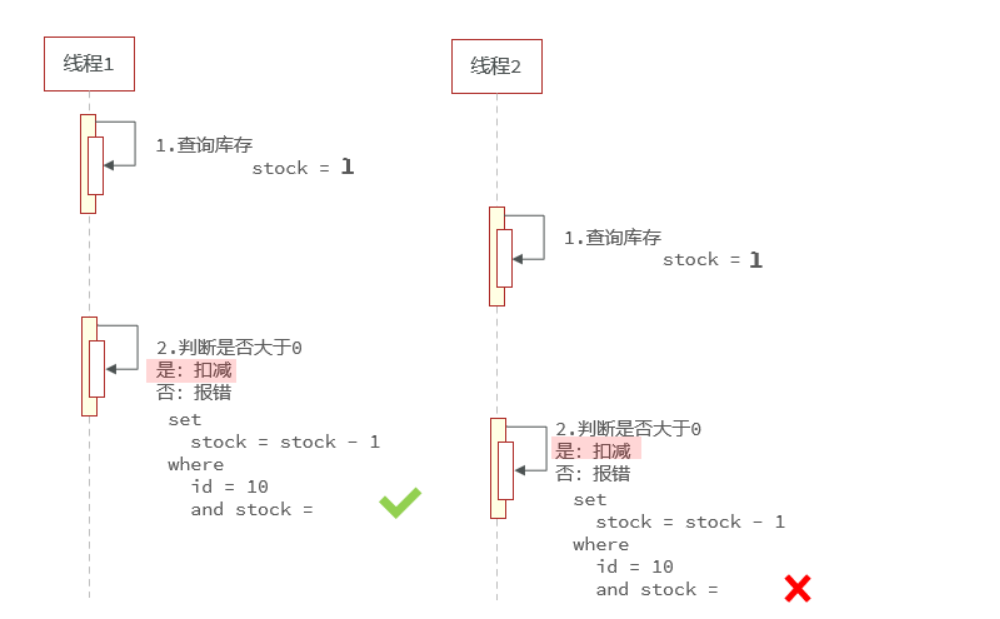
这种方式与之前的版本号方式类似。
悲观锁解决超卖问题
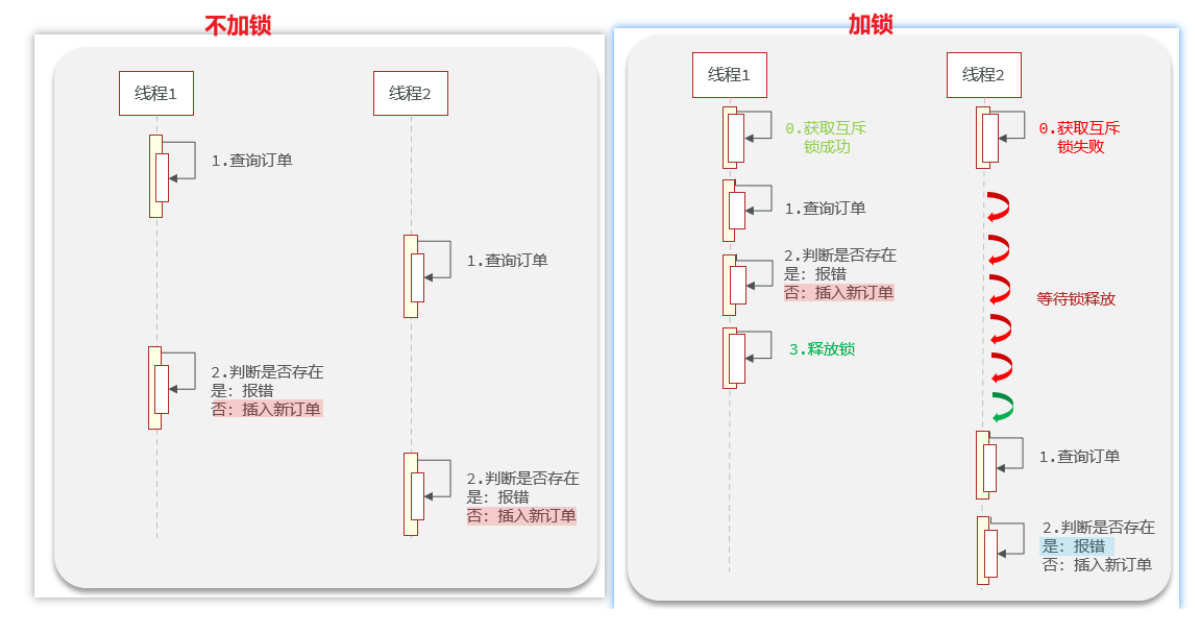
实现细节:
- 锁的范围要缩小。尽量不要选择锁方法
- 锁的值要不变。所以不能锁引用对象,这里选择转化为String对象后,使用
intern()方法从常量池中寻找与当前字符串一直的字符对象。 - 需要锁住整个事务而不是事务的代码。因为锁事务内的代码还是会导致其他线程进入事务,如果事务未提交,锁释放,仍然存在超卖问题。
- Spring的注解想要事务生效,必须使用动态代理。Service中一个方法中调用另一个方法,另一个方法使用了事务,此时会导致
@Transactional失效,所以我们需要创建一个代理对象,使用代理对象来调用方法。
[事务失效参考文章](spring 事务失效的 12 种场景_spring 截获duplicatekeyexception 不抛异常-CSDN博客)
集群下一人一单超卖问题
synchronized是本地锁,对应着每一个JVM,同时不能进行跨JVM进行上锁。所以在分布式情况下这种锁失效。
分布式锁
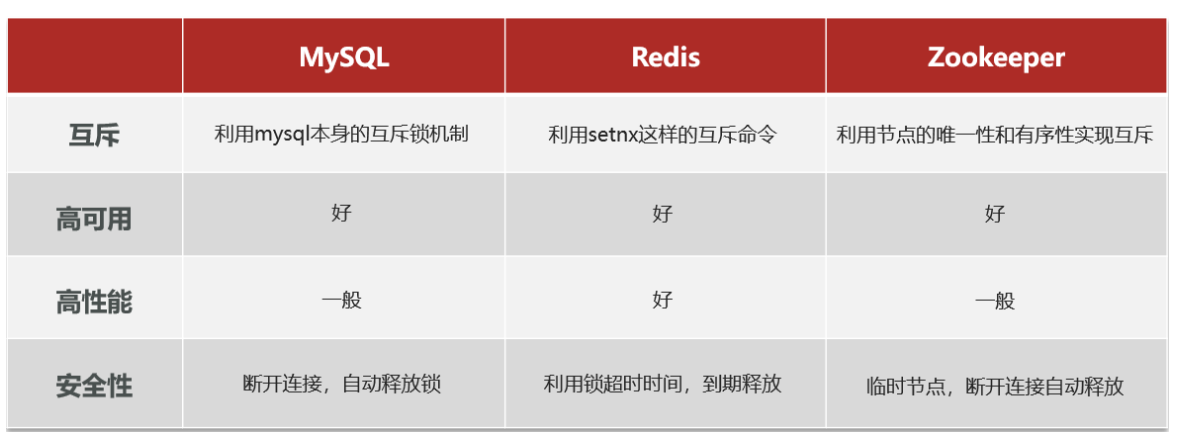
本项目采用redis来实现分布式锁
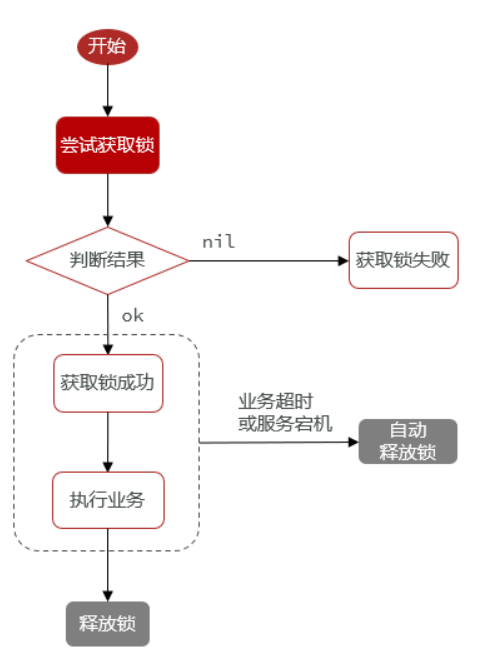
public class SimpleRedisLock implements Lock {/*** RedisTemplate*/private StringRedisTemplate stringRedisTemplate;/*** 锁的名称*/private String name;public SimpleRedisLock(StringRedisTemplate stringRedisTemplate, String name) {this.stringRedisTemplate = stringRedisTemplate;this.name = name;}/*** 获取锁** @param timeoutSec 超时时间* @return*/@Overridepublic boolean tryLock(long timeoutSec) {String id = Thread.currentThread().getId() + "";// SET lock:name id EX timeoutSec NXBoolean result = stringRedisTemplate.opsForValue().setIfAbsent("lock:" + name, id, timeoutSec, TimeUnit.SECONDS);return Boolean.TRUE.equals(result);}/*** 释放锁*/@Overridepublic void unlock() {stringRedisTemplate.delete("lock:" + name);}
}
分布式锁优化
问题:持有锁的线程在锁的内部出现了阻塞,导致他的锁自动释放,这时其他线程,线程2来尝试获得锁,就拿到了这把锁,然后线程2在持有锁执行过程中,线程1反应过来,继续执行,而线程1执行过程中,走到了删除锁逻辑,此时就会把本应该属于线程2的锁进行删除,这就是误删别人锁的情况。
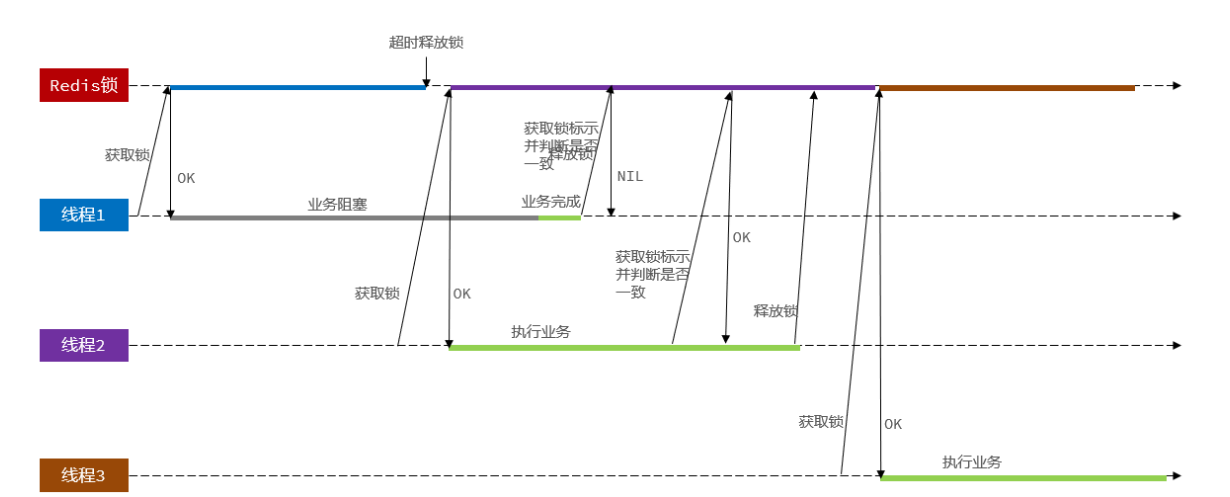
解决方案
在释放锁时需要判断锁是否时自己的。
/*** 获取锁** @param timeoutSec 超时时间* @return*/@Overridepublic boolean tryLock(long timeoutSec) {String threadId = ID_PREFIX + Thread.currentThread().getId() + "";// SET lock:name id EX timeoutSec NXBoolean result = stringRedisTemplate.opsForValue().setIfAbsent(KEY_PREFIX + name, threadId, timeoutSec, TimeUnit.SECONDS);return Boolean.TRUE.equals(result);}/*** 释放锁*/@Overridepublic void unlock() {// 判断 锁的线程标识 是否与 当前线程一致String currentThreadFlag = ID_PREFIX + Thread.currentThread().getId();String redisThreadFlag = stringRedisTemplate.opsForValue().get(KEY_PREFIX + name);if (currentThreadFlag != null || currentThreadFlag.equals(redisThreadFlag)) {// 一致,说明当前的锁就是当前线程的锁,可以直接释放stringRedisTemplate.delete(KEY_PREFIX + name);}// 不一致,不能释放}
分布式锁的原子性问题
线程1现在持有锁之后,在执行业务逻辑过程中,他正准备删除锁,而且已经走到了条件判断的过程中,比如他已经拿到了当前这把锁确实是属于他自己的,正准备删除锁,但是此时他的锁到期了,那么此时线程2进来,但是线程1他会接着往后执行,当他卡顿结束后,他直接就会执行删除锁那行代码,相当于条件判断并没有起到作用,这就是删锁时的原子性问题,之所以有这个问题,是因为线程1的拿锁,比锁,删锁,实际上并不是原子性的
Lua脚本解决多条命令原子性问题
因为redis是单线程执行的(早期是这样的)
此时的执行释放锁的流程:
- 获得锁的线程标识
- 判断当前前程与标识是否一致
- 如果一直则释放锁
- 如果不一致则删除锁
这样就把这些操作变成一气呵成的原子操作
-- 这里的 KEYS[1] 就是锁的key,这里的ARGV[1] 就是当前线程标示
-- 获取锁中的标示,判断是否与当前线程标示一致
if (redis.call('GET', KEYS[1]) == ARGV[1]) then-- 一致,则删除锁return redis.call('DEL', KEYS[1])
end
-- 不一致,则直接返回
return 0
java中调用代码
private static final DefaultRedisScript<Long> UNLOCK_SCRIPT;static {UNLOCK_SCRIPT = new DefaultRedisScript<>();UNLOCK_SCRIPT.setLocation(new ClassPathResource("unlock.lua"));UNLOCK_SCRIPT.setResultType(Long.class);}public void unlock() {// 调用lua脚本stringRedisTemplate.execute(UNLOCK_SCRIPT,Collections.singletonList(KEY_PREFIX + name),ID_PREFIX + Thread.currentThread().getId());
}
分布式锁redission
基于setnx简单实现的分布式锁存在如下问题

为了进行优化,使用市面上成熟的框架redisson.
详细了解参考其他的博客
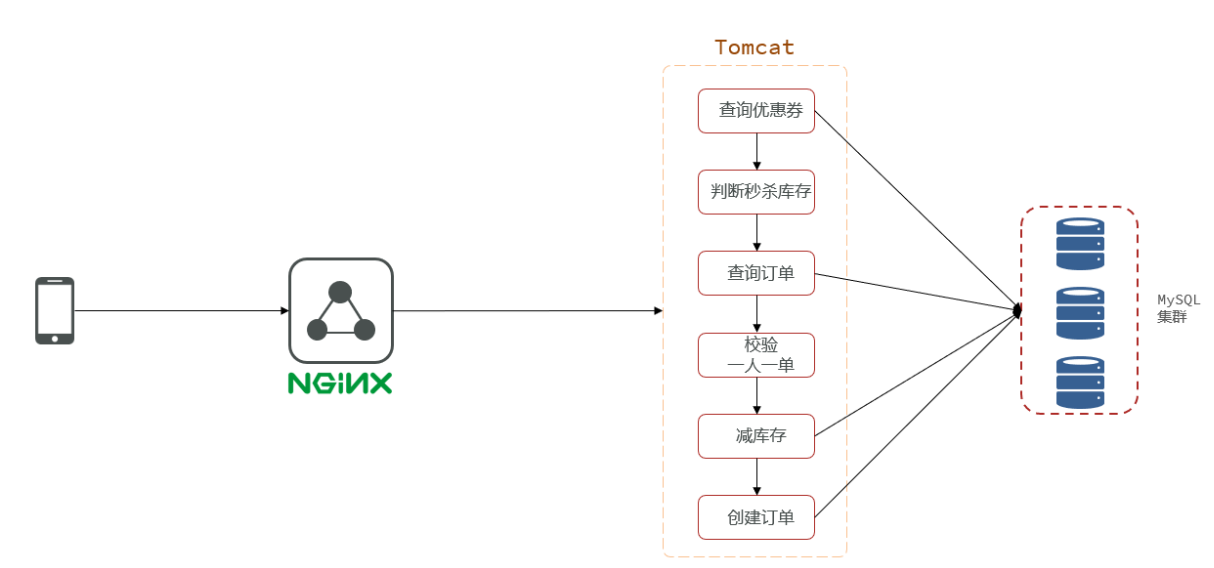
异步秒杀
在这种流程下,各个流程之间是同步执行,在时间上面消耗较大
优化方案:
把耗时较短的逻辑判断放在redis中实现,如判断库存、校验一人一单操作。
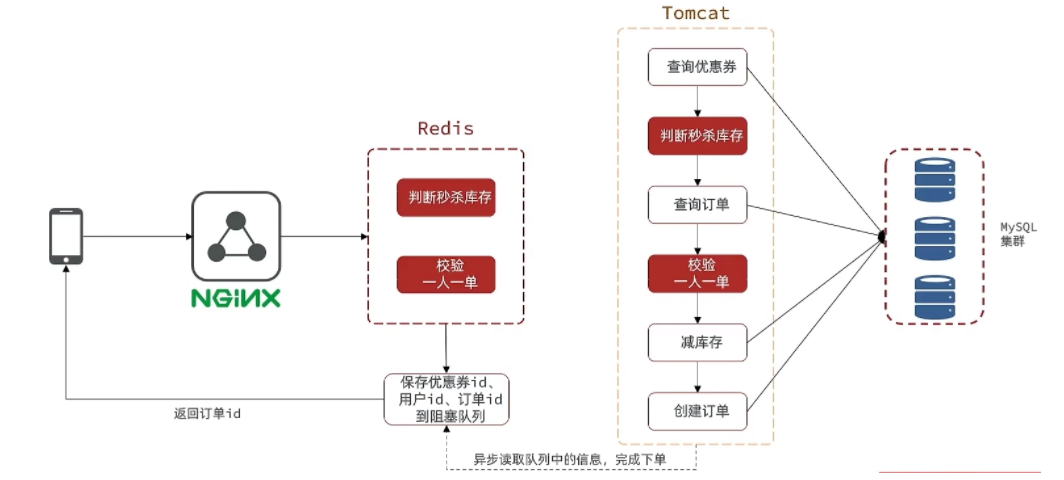
现在整体的思路就是:在用户下单后,只需要判断库存和是否一人一单即可,为了保证原子操作,同样使用lua脚本实现这方面的逻辑。只要符合就可以下单,之后将一些优惠券id、用户id、订单id放入阻塞队列中,然后交给异步线程实现数据库中的操作。
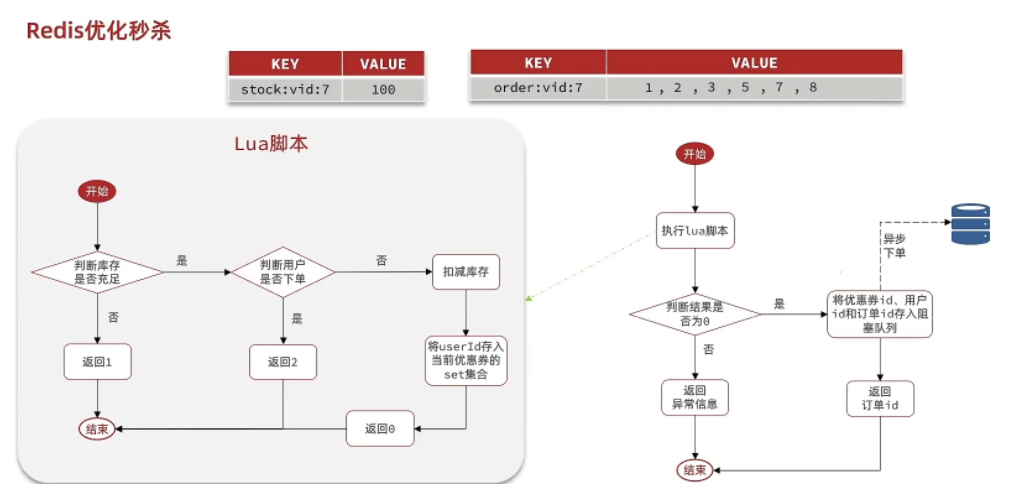
lua代码
-- 优惠券id
local voucherId = ARGV[1];
-- 用户id
local userId = ARGV[2];-- 库存的key
local stockKey = 'seckill:stock:' .. voucherId;
-- 订单key
local orderKey = 'seckill:order:' .. voucherId;-- 判断库存是否充足 get stockKey > 0 ?
local stock = redis.call('GET', stockKey);
if (tonumber(stock) <= 0) then-- 库存不足,返回1return 1;
end-- 库存充足,判断用户是否已经下过单 SISMEMBER orderKey userId
if (redis.call('SISMEMBER', orderKey, userId) == 1) then-- 用户已下单,返回2return 2;
end-- 库存充足,没有下过单,扣库存、下单
redis.call('INCRBY', stockKey, -1);
redis.call('SADD', orderKey, userId);
-- 返回0,标识下单成功
return 0;
java代码
@Service
public class VoucherOrderServiceImpl extends ServiceImpl<VoucherOrderMapper, VoucherOrder> implements IVoucherOrderService {@Resourceprivate ISeckillVoucherService seckillVoucherService;@Resourceprivate RedisIdWorker redisIdWorker;@Resourceprivate StringRedisTemplate stringRedisTemplate;@Resourceprivate RedissonClient redissonClient;/*** 当前类初始化完毕就立马执行该方法*/@PostConstructprivate void init() {// 执行线程任务SECKILL_ORDER_EXECUTOR.submit(new VoucherOrderHandler());}/*** 存储订单的阻塞队列*/private BlockingQueue<VoucherOrder> orderTasks = new ArrayBlockingQueue<>(1024 * 1024);/*** 线程池*/private static final ExecutorService SECKILL_ORDER_EXECUTOR = Executors.newSingleThreadExecutor();/*** 线程任务: 不断从阻塞队列中获取订单*/private class VoucherOrderHandler implements Runnable {@Overridepublic void run() {while (true) {// 从阻塞队列中获取订单信息,并创建订单try {VoucherOrder voucherOrder = orderTasks.take();handleVoucherOrder(voucherOrder);} catch (Exception e) {log.error("处理订单异常", e);}}}}/*** 创建订单** @param voucherOrder*/private void handleVoucherOrder(VoucherOrder voucherOrder) {Long userId = voucherOrder.getUserId();RLock lock = redissonClient.getLock(RedisConstants.LOCK_ORDER_KEY + userId);boolean isLock = lock.tryLock();if (!isLock) {// 索取锁失败,重试或者直接抛异常(这个业务是一人一单,所以直接返回失败信息)log.error("一人只能下一单");return;}try {// 创建订单(使用代理对象调用,是为了确保事务生效)proxy.createVoucherOrder(voucherOrder);} finally {lock.unlock();}}/*** 加载 判断秒杀券库存是否充足 并且 判断用户是否已下单 的Lua脚本*/private static final DefaultRedisScript<Long> SECKILL_SCRIPT;static {SECKILL_SCRIPT = new DefaultRedisScript<>();SECKILL_SCRIPT.setLocation(new ClassPathResource("lua/seckill.lua"));SECKILL_SCRIPT.setResultType(Long.class);}/*** VoucherOrderServiceImpl类的代理对象* 将代理对象的作用域进行提升,方面子线程取用*/private IVoucherOrderService proxy;/*** 抢购秒杀券** @param voucherId* @return*/@Transactional@Overridepublic Result seckillVoucher(Long voucherId) {// 1、执行Lua脚本,判断用户是否具有秒杀资格Long result = null;try {result = stringRedisTemplate.execute(SECKILL_SCRIPT,Collections.emptyList(),voucherId.toString(),ThreadLocalUtls.getUser().getId().toString());} catch (Exception e) {log.error("Lua脚本执行失败");throw new RuntimeException(e);}if (result != null && !result.equals(0L)) {// result为1表示库存不足,result为2表示用户已下单int r = result.intValue();return Result.fail(r == 2 ? "不能重复下单" : "库存不足");}// 2、result为0,用户具有秒杀资格,将订单保存到阻塞队列中,实现异步下单long orderId = redisIdWorker.nextId(SECKILL_VOUCHER_ORDER);// 创建订单VoucherOrder voucherOrder = new VoucherOrder();voucherOrder.setId(orderId);voucherOrder.setUserId(ThreadLocalUtls.getUser().getId());voucherOrder.setVoucherId(voucherId);// 将订单保存到阻塞队列中orderTasks.add(voucherOrder);// 索取锁成功,创建代理对象,使用代理对象调用第三方事务方法, 防止事务失效IVoucherOrderService proxy = (IVoucherOrderService) AopContext.currentProxy();this.proxy = proxy;return Result.ok();}/*** 创建订单** @param voucherOrder* @return*/@Transactional@Overridepublic void createVoucherOrder(VoucherOrder voucherOrder) {Long userId = voucherOrder.getUserId();Long voucherId = voucherOrder.getVoucherId();// 1、判断当前用户是否是第一单int count = this.count(new LambdaQueryWrapper<VoucherOrder>().eq(VoucherOrder::getUserId, userId));if (count >= 1) {// 当前用户不是第一单log.error("当前用户不是第一单");return;}// 2、用户是第一单,可以下单,秒杀券库存数量减一boolean flag = seckillVoucherService.update(new LambdaUpdateWrapper<SeckillVoucher>().eq(SeckillVoucher::getVoucherId, voucherId).gt(SeckillVoucher::getStock, 0).setSql("stock = stock -1"));if (!flag) {throw new RuntimeException("秒杀券扣减失败");}// 3、将订单保存到数据库flag = this.save(voucherOrder);if (!flag) {throw new RuntimeException("创建秒杀券订单失败");}}
}
消息队列优化
前面我们使用 Java 自带的阻塞队列 BlockingQueue 实现消息队列,这种方式存在以下几个严重的弊端:
- 信息可靠性没有保障,BlockingQueue 的消息是存储在内存中的,无法进行持久化,一旦程序宕机或者发生异常,会直接导致消息丢失
- 消息容量有限,BlockingQueue 的容量有限,无法进行有效扩容,一旦达到最大容量限制,就会抛出OOM异常
可以使用成熟的消息队列,如RabbitMQ、Kafka等。
相关资料:
RabbitMQ超详细学习笔记(章节清晰+通俗易懂
实现黑马点评中将消息队列由Redis实现换为RabbitMQ实现
SortedSet实现点赞排行榜
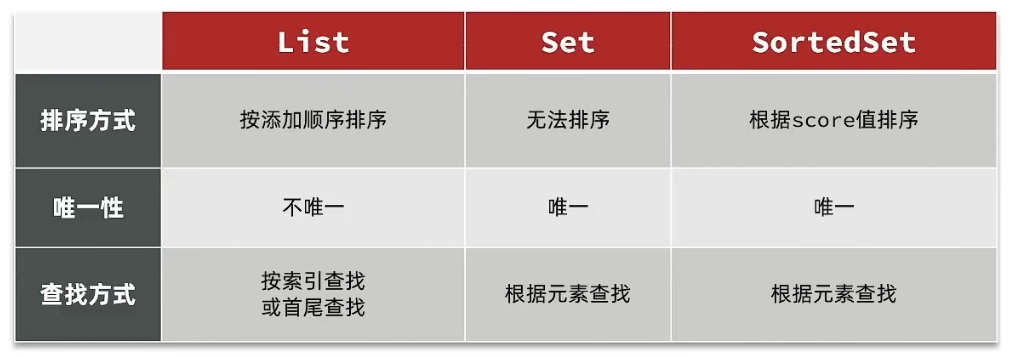
相较于Set集合,SortedList有以下不同之处:
- 对于Set集合我们可以使用 isMember方法判断用户是否存在,对于SortedList我们可以使用ZSCORE方法判断用户是否存在
- Set集合没有提供范围查询,无法获排行榜前几名的数据,SortedList可以使用ZRANGE方法实现范围查询
@Service
public class BlogServiceImpl extends ServiceImpl<BlogMapper, Blog> implements IBlogService {@Resourceprivate IUserService userService;@Resourceprivate StringRedisTemplate stringRedisTemplate;/*** 根据id查询博客** @param id* @return*/@Overridepublic Result queryBlogById(Long id) {// 查询博客信息Blog blog = this.getById(id);if (Objects.isNull(blog)) {return Result.fail("笔记不存在");}// 查询blog相关的用户信息queryUserByBlog(blog);// 判断当前用户是否点赞该博客isBlogLiked(blog);return Result.ok(blog);}/*** 判断当前用户是否点赞该博客*/private void isBlogLiked(Blog blog) {UserDTO user = ThreadLocalUtls.getUser();if (Objects.isNull(user)){// 当前用户未登录,无需查询点赞return;}Long userId = user.getId();String key = BLOG_LIKED_KEY + blog.getId();Double score = stringRedisTemplate.opsForZSet().score(key, userId.toString());blog.setIsLike(Objects.nonNull(score));}/*** 查询热门博客** @param current* @return*/@Overridepublic Result queryHotBlog(Integer current) {// 根据用户查询Page<Blog> page = this.query().orderByDesc("liked").page(new Page<>(current, SystemConstants.MAX_PAGE_SIZE));// 获取当前页数据List<Blog> records = page.getRecords();// 查询用户records.forEach(blog -> {this.queryUserByBlog(blog);this.isBlogLiked(blog);});return Result.ok(records);}/*** 点赞** @param id* @return*/@Overridepublic Result likeBlog(Long id) {// 1、判断用户是否点赞Long userId = ThreadLocalUtls.getUser().getId();String key = BLOG_LIKED_KEY + id;// zscore key valueDouble score = stringRedisTemplate.opsForZSet().score(key, userId.toString());boolean result;if (score == null) {// 1.1 用户未点赞,点赞数+1result = this.update(new LambdaUpdateWrapper<Blog>().eq(Blog::getId, id).setSql("liked = liked + 1"));if (result) {// 数据库更新成功,更新缓存 zadd key value scorestringRedisTemplate.opsForZSet().add(key, userId.toString(), System.currentTimeMillis());}} else {// 1.2 用户已点赞,点赞数-1result = this.update(new LambdaUpdateWrapper<Blog>().eq(Blog::getId, id).setSql("liked = liked - 1"));if (result) {// 数据更新成功,更新缓存 zrem key valuestringRedisTemplate.opsForZSet().remove(key, userId.toString());}}return Result.ok();}/*** 查询所有点赞博客的用户** @param id* @return*/@Overridepublic Result queryBlogLikes(Long id) {// 查询Top5的点赞用户 zrange key 0 4Long userId = ThreadLocalUtls.getUser().getId();String key = BLOG_LIKED_KEY + id;Set<String> top5 = stringRedisTemplate.opsForZSet().range(key, 0, 4);if (top5 == null || top5.isEmpty()) {return Result.ok(Collections.emptyList());}List<Long> ids = top5.stream().map(Long::valueOf).collect(Collectors.toList());List<UserDTO> userDTOList = userService.luserService.list(new LambdaQueryWrapper<User>().in(User::getId, ids).last("order by field (id," + idStr + ")")).stream().map(user -> BeanUtil.copyProperties(user, UserDTO.class)).collect(Collectors.toList());return Result.ok(userDTOList);}/*** 查询博客相关用户信息** @param blog*/private void queryUserByBlog(Blog blog) {Long userId = blog.getUserId();User user = userService.getById(userId);blog.setName(user.getNickName());blog.setIcon(user.getIcon());}
}
Feed流关注推送
关注推送也叫做Feed流,直译为投喂。为用户持续的提供“沉浸式”的体验,通过无限下拉刷新获取新的信息。Feed流是一种基于用户个性化需求和兴趣的信息流推送方式,常见于社交媒体、新闻应用、音乐应用等互联网平台。Feed流通过算法和用户行为数据分析,动态地将用户感兴趣的内容以流式方式呈现在用户的界面上。

Feed流产品有两种常见模式:
Timeline:不做内容筛选,简单的按照内容发布时间排序,常用于好友或关注。例如朋友圈
- 优点:信息全面,不会有缺失。并且实现也相对简单
- 缺点:信息噪音较多,用户不一定感兴趣,内容获取效率低
智能排序:利用智能算法屏蔽掉违规的、用户不感兴趣的内容。推送用户感兴趣信息来吸引用户
- 优点:投喂用户感兴趣信息,用户粘度很高,容易沉迷
- 缺点:如果算法不精准,可能起到反作用
本例中的个人页面,是基于关注的好友来做Feed流,因此采用Timeline的模式。该模式的实现方案有三种:
我们本次针对好友的操作,采用的就是Timeline的方式,只需要拿到我们关注用户的信息,然后按照时间排序即可
,因此采用Timeline的模式。该模式的实现方案有三种:
- 拉模式,也叫做读扩散。在拉模式中,终端用户或应用程序主动发送请求来获取最新的数据流。
- 优点:节约空间,可以减少不必要的数据传输,只需要获取自己感兴趣的数据
- 缺点:延迟较高,当用户读取数据时才去关注的人里边去读取数据
- 推模式,也叫做写扩散。在推模式中,数据提供方主动将最新的数据推送给终端用户或应用程序
- 优点:数据延迟低,不用临时拉取
- 缺点:内存耗费大,假设一个大V写信息,很多人关注他, 就会写很多份数据到粉丝那边去
- 推拉结合,也叫做读写混合,兼具推和拉两种模式的优点。在推拉结合模式中,数据提供方会主动将最新的数据推送给终端用户或应用程序,同时也支持用户通过拉取的方式来获取数据。
基于模式实现关注推送功能
索引漂移现象,也就是查询的时候数据也在更新,基于索引的方式,会出现这种问题导致,数据重复
滚动分页
SortedSet可以按照Score排序,我们每次选择上一次查到的分数,来进行滚动查询
/*** 关注推送页面的笔记分页** @param max* @param offset* @return*/@Overridepublic Result queryBlogOfFollow(Long max, Integer offset) {// 1、查询收件箱Long userId = ThreadLocalUtls.getUser().getId();String key = FEED_KEY + userId;// ZREVRANGEBYSCORE key Max Min LIMIT offset countSet<ZSetOperations.TypedTuple<String>> typedTuples = stringRedisTemplate.opsForZSet().reverseRangeByScoreWithScores(key, 0, max, offset, 2);// 2、判断收件箱中是否有数据if (typedTuples == null || typedTuples.isEmpty()) {return Result.ok();}// 3、收件箱中有数据,则解析数据: blogId、minTime(时间戳)、offsetList<Long> ids = new ArrayList<>(typedTuples.size());long minTime = 0; // 记录当前最小值int os = 1; // 偏移量offset,用来计数for (ZSetOperations.TypedTuple<String> tuple : typedTuples) { // 5 4 4 2 2// 获取idids.add(Long.valueOf(tuple.getValue()));// 获取分数(时间戳)long time = tuple.getScore().longValue();if (time == minTime) {// 当前时间等于最小时间,偏移量+1os++;} else {// 当前时间不等于最小时间,重置minTime = time;os = 1;}}// 4、根据id查询blog(使用in查询的数据是默认按照id升序排序的,这里需要使用我们自己指定的顺序排序)String idStr = StrUtil.join(",", ids);List<Blog> blogs = this.list(new LambdaQueryWrapper<Blog>().in(Blog::getId, ids).last("ORDER BY FIELD(id," + idStr + ")"));// 设置blog相关的用户数据,是否被点赞等属性值for (Blog blog : blogs) {// 查询blog有关的用户queryUserByBlog(blog);// 查询blog是否被点赞isBlogLiked(blog);}// 5、封装并返回ScrollResult scrollResult = new ScrollResult();scrollResult.setList(blogs);scrollResult.setOffset(os);scrollResult.setMinTime(minTime);return Result.ok(scrollResult);}
用户签到
采用位图的方式来记录一个月中每一天的签到情况,当天签到了就标记为1,在redis中有BitMap来实现这个功能
BitMap的操作命令有:
-
SETBIT:向指定位置(offset)存入一个0或1
-
GETBIT :获取指定位置(offset)的bit值
-
BITCOUNT :统计BitMap中值为1的bit位的数量
-
BITFIELD :操作(查询、修改、自增)BitMap中bit数组中的指定位置(offset)的值
-
BITFIELD_RO :获取BitMap中bit数组,并以十进制形式返回
-
BITOP :将多个BitMap的结果做位运算(与 、或、异或)
-
BITPOS :查找bit数组中指定范围内第一个0或1出现的位置
/*** 用户签到** @return*/@Overridepublic Result sign() {// 获取当前登录用户Long userId = ThreadLocalUtls.getUser().getId();// 获取日期LocalDateTime now = LocalDateTime.now();// 拼接keyString keySuffix = now.format(DateTimeFormatter.ofPattern(":yyyyMM"));String key = USER_SIGN_KEY + userId + keySuffix;// 获取今天是本月的第几天int dayOfMonth = now.getDayOfMonth();// 写入Redis SETBIT key offset 1stringRedisTemplate.opsForValue().setBit(key, dayOfMonth - 1, true);return Result.ok();}