目标检测DN-DETR(2022)详细解读
文章目录
- gt labels 和gt boxes加噪
- query的构造
- attention mask
- IS(InStability)指标
在DAB-Detr的基础上,进一步分析了Detr收敛速度慢的原因:二分图匹配的不稳定性(也就是说它的目标在频繁地切换,特别是在训练的早期),导致早期训练阶段的优化目标不一致(一个query通常在不同的时间段与不同的对象匹配,这使得优化变得模糊和不稳定)
解决方法:除了匈牙利损失外,提出了全新的去噪训练来解决二分图匹配不稳定的问题。从而有效降低了双方图匹配的难度,并加快了收敛速度。去噪任务仅在训练时需要,而推理时是去掉的,并不会给最终模型的实际应用带来负担,该方法具有通用性,只需添加几十行代码,就能轻松插入任何类似 DETR 的方法中,从而实现显著的改进。
先理解Decoder在做什么:
可以按照DAB-DETR把它看作一个四维的bounding box(检测框):$( x , y , w , h ) ,在每一层 d e c o d e r 中都会去预测相对偏移量 ( Δ x , Δ y , Δ w , Δ h ) 并去更新检测框,得到一个更加精确的检测框预测 ,在每一层decoder中都会去预测相对偏移量( Δ x , Δ y , Δ w , Δ h )并去更新检测框,得到一个更加精确的检测框预测 ,在每一层decoder中都会去预测相对偏移量(Δx,Δy,Δw,Δh)并去更新检测框,得到一个更加精确的检测框预测( x^, , y^, , w^, , h^, ) $ = $( x , y , w , h ) $ + ( Δ x , Δ y , Δ w , Δ h ),并传到下一层中。
我们可以把decoder看成在学习两个东西:
- good anchors(anchor位置)$( x , y , w , h ) $
- relative offset(相对偏移)(Δx,Δy,Δw,Δh)
decoder queries可以看成是anchor位置的学习,而不稳定的匹配会导致不稳定的anchor,从而使得相对偏移的学习变得困难。因此,直接在 DETR 训练时引入去噪任务作为训练捷径,使相对偏移学习起来更容易,因为去噪任务跳过了匹配过程直接进行学习。
如果我们把query像上述一样看作四维坐标,可以通过在真实框附近添加一个微小的扰动作为噪声,因此一个带噪声的查询query可以被看作是一个“good anchor”,它附近肯定有一个相应的gt Box。这样DN-DETR架构去噪训练有一个明确的优化目标——预测原始的box,这从本质上避免了匈牙利匹配带来的模糊性。总的来说DN任务就是:输入是通过对 gt 加噪而获得,输出是为了去重构原来的 gt。
除了上面对position位置加噪,DN作者同时对content任务部分进行了加噪,比如将原来的gt label(标签类别)替换为其他的label作为输入,输出则是为了去重构原来的 gt label。
gt labels 和gt boxes加噪
gt labels 加噪:
以一定概率随机把gt label翻转为其余的任何一个label。由于 gt label 是一个数字,因此当然不能是将这个数字改为另一个数字就完事了。我们可以参考 query 的 position 部分,它是一个 embedding 向量,所以在这里我们也可以把加噪的 label 编码为 embedding 向量。根据 1 个整型数值到 embedding 矩阵中去“查表”从而得到对应的向量。于是,需要在模型中设置一个 embedding matrix,来对加噪的 gt label 进行编码得到对应的 Class Label Embedding。
这么一来,原来做匈牙利匹配任务的那部分 query 的 content 部分也需要改造下,让它的值初始化为 ‘non-object’,这个值应当不小于类别数 num_classes,因为做去噪任务的 query 的 content 部分是由真实的 gt label 而来,其值域会是 [0,num_classes−1] 。当然了,要记得将这个 non-object class 也通过 embedding matrix 去编码,从而得到对应的 embedding 向量。
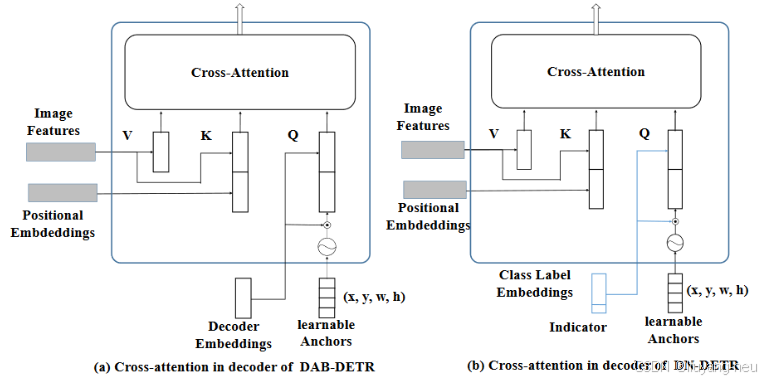
另外,考虑到对原始 DETR 的匈牙利匹配任务的友好性,作者还在 Class Label Embedding部分拼接(concat)了指示向量 indicator,用以区别 query 到底是做去噪任务还是匹配任务。果查询属于去噪部分,则指示器为 1,否则为 0。
gt boxes 加噪:
DN-DETR 承袭了 DAB-DETR,position 部分就是 4d anchor box:x、y、w、h (对于以下内容,默认这 4 个分量都归一化到 [0,1] )。自然地,要做的就是对这 4 个分量都加上细微的“扰动”。总的来说,这部分的加噪可以概括为:中心点位移 & 尺度缩放。
中心点位移:在中心点(x,y)处添加一个随机噪声(∆x ,∆y),并保证|∆x | < λ 1 w 2 \frac{λ_1w}{2} 2λ1w和|∆y | < λ 1 h 2 \frac{λ_1h}{2} 2λ1h,其中 λ 1 λ_1 λ1∈( 0 , 1),使得被噪声污染的box中心(x+∆x ,y+∆y)仍位于gt box之中。
尺度缩放:对宽度和高度在[(1 − λ 2 λ_2 λ2)w, (1 + λ 2 λ_2 λ2w] 和 [(1 − λ 2 λ_2 λ2)h, (1 + λ 2 λ_2 λ2)h]中进行随机抽样,其中 λ 2 λ_2 λ2∈( 0 , 1),宽高会缩放至原来的 0~2 倍。
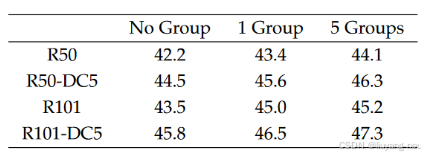
对于以上两个扰动参数不同值所带来的效果,作者也做了实验进行探索
设置dn group加噪组的个数:
为了更充分地利用 DN 任务去提升模型的学习效率,我们可以让模型对于每个 gt 在不同程度的噪声下都拥有“纠错”能力,从而使模型更明确 query & gt 的对应关系,也就是更能知道什么样的 query 该负责预测哪个 gt。基于此,作者设置了 dn groups,即多个去噪组,每个 gt 在每组都会由一个噪声 query(noised label & noised box) 负责去预测。
query的构造
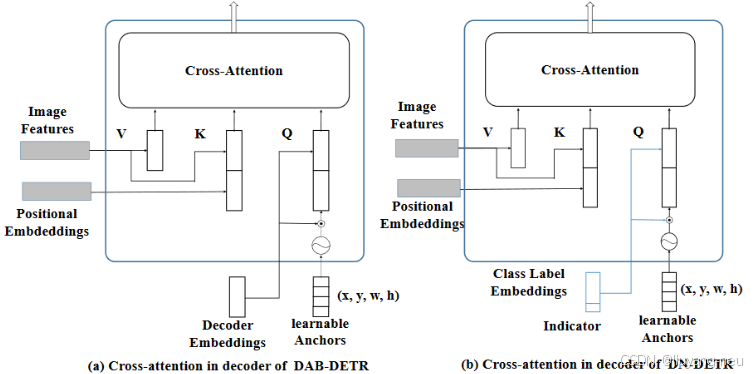
首先,将原本的Decoder Embeding变为了Class Label Embeding,这里的改变只是变个名字罢了,方便我们理解。
随后假设 batch size=3,image0中有9个target,image1中有1个target,image2中有2个target,总计12个target。设置加入噪声的group组为5组,设置类别噪声比例为0.2,x,y,w,h噪声比例为0.4。即12个target,5组,那么有12X5=60个真实框,0.2作为比例或阈值,比如取60X0.2=12个target加入类别噪声,即将其真实类别替换为其他类别,这个比例可以随便取。0.4则是box的xy偏移比例与wh的缩放比例。
接着我们取3个batch中最大的target的数量,在这里为9,由于group=5,所有5X9=45,构造噪声query的结构为【3,45,256】,这里注意256的最后一维为indicator标识,值为1,代表噪声。沿用DAB-DETR的匹配query构造方式为【3,300,256】,此时256最后一维indicator=0。
最后将其cat起来,得到class label embeding为【3,345,256】。
同理构造learnable Anchor为【3,345,4】随后送入Decoder进行计算。如上图所示。
attention mask
DN 任务的噪声 queries 是会和匈牙利匹配任务的 queries 拼接起来一起喂到 transformer 中的,在 transformer 中,它们会经过 attention 交互(你看看我,我看看你),这样问题就大了!因为噪声 queries 可是通过 gt “稍微”改造而来,那么它们其实是包含着大量 gt 信息的,如果匈牙利匹配任务的 queries 看到了它们,那就会“偷懒”,导致学习效果大打折扣,所以需要有针对性的进行mask处理。
如上所述,匈牙利匹配任务的 queries 肯定不能看到 DN 任务的 queries;其次,不同 dn group 的 queries 也不能相互看到,因为每个 gt 在每组都会由一个噪声 quer负责去预测,其他queries都不会有自己gt的信息。
总的来说,attention mask 的设计归纳为:
- 匈牙利匹配任务的 queries 不能看到 DN任务的 queries
- DN 任务中,不同组的 queries 不能相互看到
- 其它情况均可见
假设一张训练图片中有M 个目标,施加P 个版本的噪声(p个group)后,就会得到P 组带噪目标,共M × P 个新的带噪目标。假设原始一张图片有N个查询,新的带噪目标会作为额外的查询与原始查询拼接到一起,于是形成M × P + N 个查询。原始查询就是DAB-DETR中的300个查询。
DN-DETR将与带噪目标相关的部分称为去噪部分,将与原始查询相关的部分称为匹配部分。
图中,P = 2 , M = 3 , N = 5 ;匹配部分表示N 个原始查询;灰色部分表示对应查询不可访问,彩色部分表示可以访问。
外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传
noised labes, noised boxes & attention mask 做为 DN 大法的“三剑客”,作者对它们的 KPI 完成情况也进行了发布:

总结下来,DAB-DETR和DN-DETR仅训练时有差别,相较于DAB-DETR的差别是:
(1) 解码器嵌入被换成了类别标签嵌入+指示项。嵌入部分由nn.Embedding初始化,匹配部分按未知类取最后一个特征,去噪部分按噪声类别取对应索引的特征。指示项为0表示匹配部分,为1表示去噪部分。
(2) 输入查询的数量从N 变成了M × P + N 。M × P 是该图片中M 个真实目标被施加了P 个版本的噪声后得到的锚框和标签。
(3) 为了避免通信带来的问题,引入了注意力掩码。
(4) 与原始查询拼接在一起的去噪查询也会经解码器输出框和标签预测。为实现去噪,对于框使用l1 loss和GIOU loss,对于标签使用Focal loss,三个loss合并称为重构损失(reconstruction loss)。
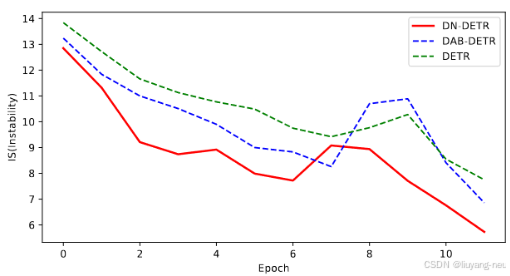
IS(InStability)指标
设计了一个指标IS(Instability)通过比较相邻epoch之间匹配的不一致性来衡量匹配的不稳定性,如下图所示。这表明DN-DETR能有效提高匹配的稳定性。