python学习打卡day31
DAY 31 文件的规范拆分和写法
今日的示例代码包含2个部分
- notebook文件夹内的ipynb文件,介绍下今天的思路
- 项目文件夹中其他部分:拆分后的信贷项目
知识点回顾
- 规范的文件命名
- 规范的文件夹管理
- 机器学习项目的拆分
- 编码格式和类型注解
作业:尝试针对之前的心脏病项目ipynb,将他按照今天的示例项目整理成规范的形式,思考下哪些部分可以未来复用。
preprocessing.py
import pandas as pd
import seaborn as sns
import numpy as np
from typing import Tuple, Dict
from sklearn.preprocessing import StandardScaler, MinMaxScaler
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier # 随机森林分类器
from sklearn.metrics import make_scorer, accuracy_score, precision_score, recall_score, f1_score # 用于评估分类器性能的指标
from sklearn.metrics import classification_report, confusion_matrix # 用于生成分类报告和混淆矩阵
import warnings # 用于忽略警告信息
import osdef load_data(file_path: str) -> pd.DataFrame:"""加载数据文件Args:file_path: 数据文件路径Returns:加载的数据框"""return pd.read_csv(file_path)def encode_categorical_features(data: pd.DataFrame) -> Tuple[pd.DataFrame, Dict]:"""对分类特征进行编码Args:data: 原始数据框Returns:编码后的数据框和编码映射字典"""discrete_features = ['sex', 'cp', 'fbs', 'restecg', 'exang', 'slope', 'thal']continuous_features = ['age', 'trestbps', 'chol', 'thalach', 'oldpeak']data_encoded = data.copy()# Purpose 独热编码data_encoded = pd.get_dummies(data, columns=discrete_features)return data_encodeddef normalization(data: pd.DataFrame) -> Tuple[pd.DataFrame, Dict]:"""对连续特征进行归一化Args:data: 连续数据框Returns:归一化后的数据"""continuous_features = ['age', 'trestbps', 'chol', 'thalach', 'oldpeak']data_scaled = data.copy()min_max_scaler = MinMaxScaler()data_scaled[continuous_features] = min_max_scaler.fit_transform(data_scaled[continuous_features])return data_scaledif __name__ == "__main__":# 测试代码file_path = r"C:\Users\zwj\Desktop\python\Python60DaysChallenge-main\1\text\day31\data\raw\heart.csv"if not os.path.exists(file_path):print(f"文件不存在,请检查路径:{file_path}")else:data = load_data(file_path)data_encoded = encode_categorical_features(data)data_clean = normalization(data_encoded)print("数据预处理完成!")train.py
# -*- coding: utf-8 -*-import sys
import os
sys.path.append(os.path.dirname(os.path.dirname(os.path.abspath(__file__))))from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import classification_report, confusion_matrix
import time
import joblib # 用于保存模型
from typing import Tuple # 用于类型注解from data.preprocessing import load_data, encode_categorical_features, normalizationdef prepare_data() -> Tuple:"""准备训练数据Returns:训练集和测试集的特征和标签"""# 加载和预处理数据data = load_data(r"C:\Users\zwj\Desktop\python\Python60DaysChallenge-main\1\text\day31\data\raw\heart.csv")data_encoded = encode_categorical_features(data)data_scaled = normalization(data_encoded)# 分离特征和标签X = data_scaled.drop(['target'], axis=1)y = data_scaled['target']# 划分训练集和测试集X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)return X_train, X_test, y_train, y_testdef train_model(X_train, y_train, model_params=None) -> RandomForestClassifier:"""训练随机森林模型Args:X_train: 训练特征y_train: 训练标签model_params: 模型参数字典Returns:训练好的模型"""if model_params is None:model_params = {'random_state': 42}model = RandomForestClassifier(**model_params)model.fit(X_train, y_train)return modeldef evaluate_model(model, X_test, y_test) -> None:"""评估模型性能Args:model: 训练好的模型X_test: 测试特征y_test: 测试标签"""y_pred = model.predict(X_test)print("\n分类报告:")print(classification_report(y_test, y_pred))print("\n混淆矩阵:")print(confusion_matrix(y_test, y_pred))def save_model(model, model_path: str) -> None:"""保存模型Args:model: 训练好的模型model_path: 模型保存路径"""os.makedirs(os.path.dirname(model_path), exist_ok=True)joblib.dump(model, model_path)print(f"\n模型已保存至: {model_path}")if __name__ == "__main__":# 准备数据X_train, X_test, y_train, y_test = prepare_data()# 记录开始时间start_time = time.time()# 训练模型model = train_model(X_train, y_train)# 记录结束时间end_time = time.time()print(f"\n训练耗时: {end_time - start_time:.4f} 秒")# 评估模型evaluate_model(model, X_test, y_test)# 保存模型save_model(model, "models/random_forest_model.joblib") plots.py
import matplotlib.pyplot as plt
import seaborn as sns
import shap
import numpy as np
from typing import Any
import sys
import os
sys.path.append(os.path.dirname(os.path.dirname(os.path.abspath(__file__))))from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import classification_report, confusion_matrix
import time
import joblib # 用于保存模型
from typing import Tuple # 用于类型注解
from data.preprocessing import load_data, encode_categorical_features, normalization
def plot_feature_importance_shap(model: Any, X_test, save_path: str = None) -> None:"""绘制SHAP特征重要性图Args:model: 训练好的模型X_test: 测试数据save_path: 图片保存路径"""# 初始化SHAP解释器explainer = shap.TreeExplainer(model)shap_values = explainer.shap_values(X_test)# 绘制特征重要性条形图plt.figure(figsize=(12, 8))shap.summary_plot(shap_values[:, :, 0], X_test, plot_type="bar", show=False)plt.title("SHAP特征重要性")if save_path:plt.savefig(save_path)print(f"特征重要性图已保存至: {save_path}")plt.show()def plot_confusion_matrix(y_true, y_pred, save_path: str = None) -> None:"""绘制混淆矩阵热力图Args:y_true: 真实标签y_pred: 预测标签save_path: 图片保存路径"""plt.figure(figsize=(8, 6))cm = confusion_matrix(y_true, y_pred)sns.heatmap(cm, annot=True, fmt='d', cmap='Blues')plt.title('混淆矩阵')plt.ylabel('真实标签')plt.xlabel('预测标签')if save_path:plt.savefig(save_path)print(f"混淆矩阵图已保存至: {save_path}")plt.show()def set_plot_style():"""设置绘图样式"""#plt.style.use('seaborn')sns.set() # 使用 seaborn 的样式plt.rcParams['font.sans-serif'] = ['SimHei']plt.rcParams['axes.unicode_minus'] = Falseif __name__ == "__main__":# 设置绘图样式set_plot_style()# 准备数据和模型from sklearn.datasets import load_irisfrom sklearn.ensemble import RandomForestClassifierfrom sklearn.model_selection import train_test_splitdata = load_data(r"C:\Users\zwj\Desktop\python\Python60DaysChallenge-main\1\text\day31\data\raw\heart.csv")data_encoded = encode_categorical_features(data)data_scaled = normalization(data_encoded)# 分离特征和标签X = data_scaled.drop(['target'], axis=1)y = data_scaled['target']# 划分训练集和测试集X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)# 训练模型model = RandomForestClassifier(random_state=42)model.fit(X_train, y_train)plot_feature_importance_shap(model, X_test)# 这里可以添加测试代码print("可视化模块加载成功!") 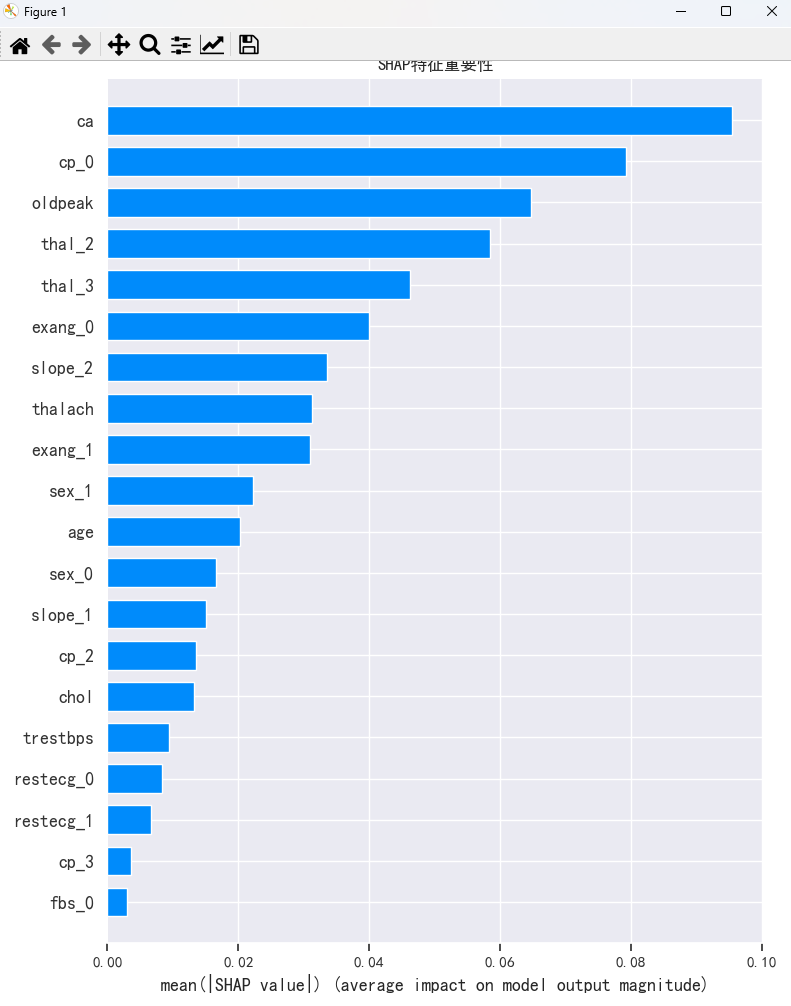
@浙大疏锦行