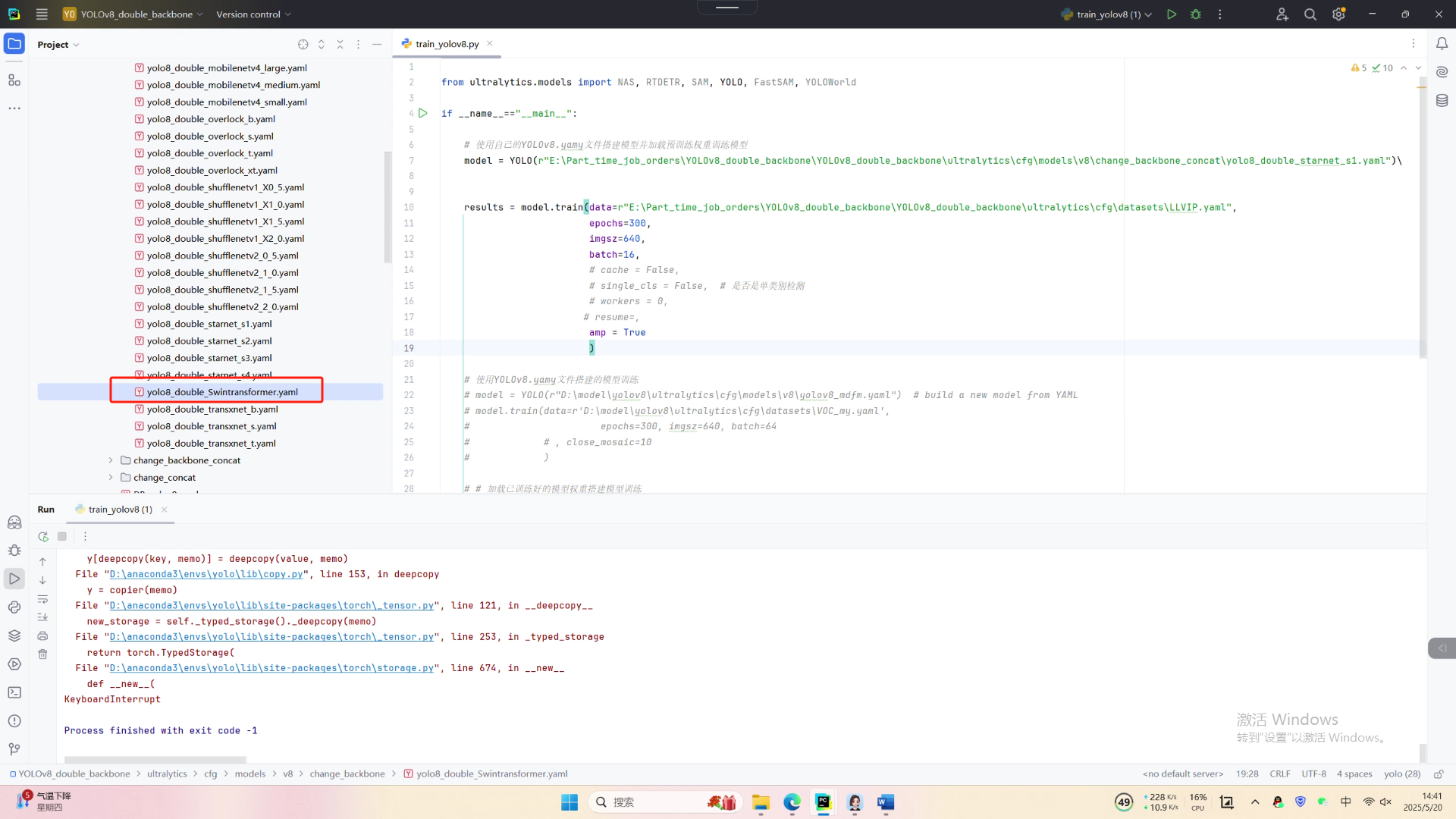
YOLOv8 的双 Backbone 架构:解锁目标检测新性能
一、开篇:为何踏上双 Backbone 探索之路
在目标检测的领域中,YOLOv8 凭借其高效与精准脱颖而出,成为众多开发者和研究者的得力工具。然而,传统的单 Backbone 架构,尽管已经在诸多场景中表现出色,但仍存在一些难以忽视的局限性。
单 Backbone 架构下,特征提取的能力存在一定瓶颈。它在捕捉细节特征与宏观语义信息时,往往难以做到完美平衡。在面对复杂场景,如拥挤的城市街道中的车辆检测,或者自然环境中多种类动物的识别时,单 Backbone 可能会因为无法同时兼顾局部细节和全局结构,导致出现误检或漏检的情况。此外,随着计算机视觉领域不断拓展应用边界,对目标检测模型在多尺度目标、不同模态数据融合等方面的要求日益提高,单 Backbone 在扩展性上的不足也逐渐凸显。
正是基于这些挑战,双 Backbone 架构成为了提升 YOLOv8 性能的一个极具潜力的方向。通过引入两个不同的主干网络,我们期望能够融合更多元化的特征信息,从而实现更强大的目标检测能力。
二、YOLOv8 单 Backbone 架构回眸
YOLOv8 的单 Backbone 架构采用了精心设计的卷积神经网络结构,旨在高效地从输入图像中提取多层次的特征图。它通过一系列精心设计的卷积模块、池化操作等,逐步对图像进行抽象和特征提取。例如,在其骨干网络中,通过不断调整卷积核的大小、步长等参数,实现对不同尺度目标的初步感知。
然而,这种单 Backbone 架构也有其内在的局限。一方面,其感受野的局限性使得在处理大场景或者远距离目标时,难以充分捕捉目标之间的关系。比如在监控大片区域时,对于远处的小目标,可能无法准确识别其类别和位置。另一方面,单 Backbone 的特征提取路径相对单一,难以在同一时间对不同语义层级的信息进行全面捕捉。这在处理包含多种类型目标,且目标之间存在复杂遮挡关系的场景时,会导致模型的判断失误。
三、双 Backbone 架构揭秘:多维度特征融合之道
双 Backbone 架构在 YOLOv8 中的实现,主要分为共享输入和双输入两种典型结构。
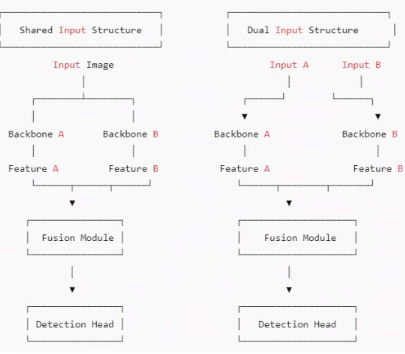
1. 共享输入的双 Backbone 结构
共享输入的双 Backbone 结构,就像是为模型开启了两扇不同视角的窗户。它允许模型在处理同一幅图像时,通过两条并行的特征提取路径,从不同的尺度和角度去理解图像内容。一条路径可以专注于提取图像中目标的浅层纹理和边缘信息,就像我们用放大镜去观察目标的细节;而另一条路径则可以深入挖掘图像的深层语义和结构关系,如同站在高处俯瞰全局。
这种结构带来的优势显而易见。它极大地增强了模型对目标的判别能力,无论是面对微小的细节差异,还是复杂的语义关联,都能有更准确的判断。同时,对于不同尺度的目标,两条路径的特征融合也使得模型能够更好地适应,不会因为目标过大或过小而出现检测偏差。而且,在训练和部署过程中,由于共享同一输入图像,参数的优化相对更加稳定,减少了模型出现不稳定训练状态的风险。
2. 双输入的双 Backbone 结构
双输入的双 Backbone 架构则更进一步,打破了传统模型仅依赖单一图像输入的限制。它允许两个 Backbone 分别处理不同来源的输入,这些输入可以是不同模态的数据,比如 RGB 图像与深度图像的结合,或者是不同时间点的图像序列。
在实际应用中,这种结构展现出了强大的适应性。在多视角融合场景中,不同摄像头采集的图像通过各自的 Backbone 处理后,能够相互补充视角盲区,让模型能够感知到更广阔的场景范围。这种结构不仅丰富了模型可利用的信息维度,还为其在多模态融合、时序建模等新兴任务中提供了广阔的发展空间。
四、双 Backbone 的多元组合及独特魅力
在 YOLOv8 的双 Backbone 架构中,不同的组合方式犹如为模型调配出不同的 “能力配方”,以适应多样化的任务需求。
1. CNN + CNN(轻量高效组合)
将两个不同的 CNN 进行组合,是一种兼顾速度与性能的策略。例如,我们可以选择一个轻量级的 CNN,如 MobileNet,它能够快速地捕捉图像中的浅层特征,就像快速扫描图像的轮廓和大致纹理。再搭配一个相对较重但语义建模能力更强的 CNN,比如 ResNet。ResNet 可以深入挖掘图像的深层语义信息,理解图像中目标的内在关系。
这种组合方式特别适用于对实时性要求较高的场景,如自动驾驶中的实时目标检测。轻量级的 CNN 可以保证模型在有限的计算资源下快速运行,而较重的 CNN 则确保了检测的准确性。通过合理的特征融合策略,将两者提取的特征进行整合,能够在不牺牲太多速度的前提下,显著提升模型对复杂背景和小目标的检测能力。
2. CNN + Transformer(语义强化组合)
Transformer 的引入为 YOLOv8 带来了全新的语义理解维度。我们都知道,CNN 擅长捕捉局部的纹理和空间结构信息,但在处理长距离依赖关系时往往力不从心。而 Transformer 则以其强大的自注意力机制,能够在全局范围内对图像中的元素进行关联和建模。
在这种组合中,我们可以让 CNN 先处理图像的低级特征,构建起目标的基本形态和局部细节。然后,将这些特征传递给 Transformer,由 Transformer 来梳理图像中各个目标之间的长距离关系,理解它们的语义关联。这种强强联合的方式,在处理复杂场景,如大型集会中的人群检测,或者密集停车场中的车辆检测时,能够极大地提升模型对目标的准确识别和定位能力,尽管计算量会有所增加,但在追求高精度的任务中,这种付出是值得的。
3. CNN + Mamba(动态感知组合)
Mamba 作为一种新兴的架构,在处理长距离依赖和动态信息方面展现出了独特的优势。与 CNN 结合时,CNN 依旧负责提取图像的静态空间结构和纹理信息,而 Mamba 则专注于捕捉图像中跨通道、跨区域甚至跨时间的动态信息。
在视频目标检测任务中,这种组合能够更好地理解目标的运动轨迹和行为模式。例如在体育赛事视频分析中,准确捕捉运动员的动作和位置变化。在遥感图像分析领域,也能更有效地分析地理目标随时间的变化情况。这种组合为 YOLOv8 赋予了更强的动态感知能力,使其在处理强调时间连续性和上下文理解的任务时,能够游刃有余。
五、迈向实践:YOLOv8 双 Backbone 代码实践指引
1. 数据集
数据集的格式如下所示,如果是共享输入(也就是输入同一张图片,那就将图片复制一份,命名为train2 val2 test2),如果是双模太数据集,那就如下所示:
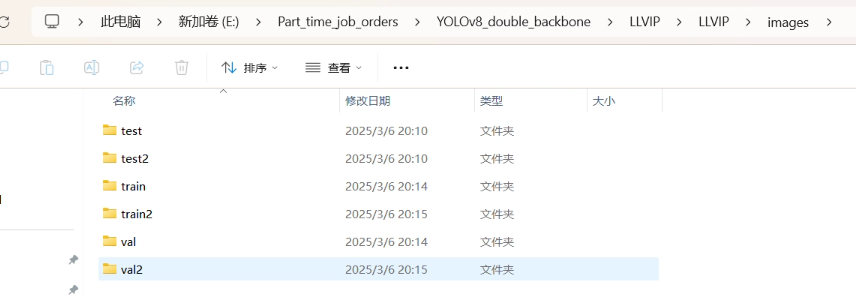
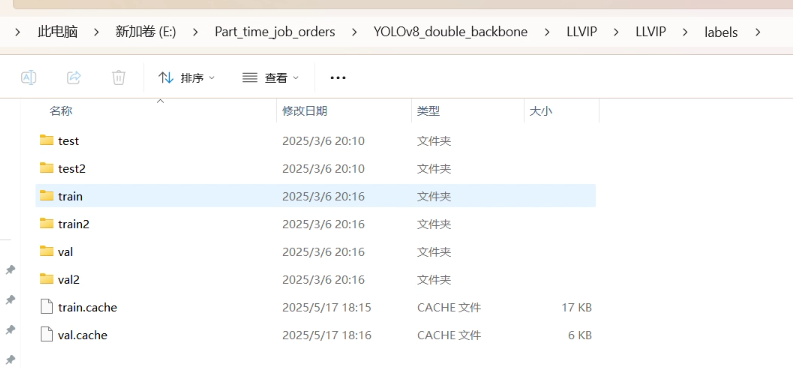
代码中的数据集的配置文件如下所示:
# Train/val/test sets as dir: path/to/imgs
path: E:/Part_time_job_orders/YOLOv8_double_backbone/LLVIP/LLVIPtrain: images/train # train visible images (relative to 'path')
train2: images/train2 # train infrared images (relative to 'path')val: images/val # val visible images (relative to 'path')
val2: images/val2 # val infrared images (relative to 'path')test: # test images (optional)
test2: # test images (optional)#image_weights: True
nc: 1# Classes
names:0: Person2. CNN + CNN(轻量高效组合)
首先看一下跑CNN+CNN组合的双backbone,这个分为两种,一个就是在在最基础的YOLO backbone+YOLO backbone的基础上改进,比如一个backbone不动,另一个对其改进,比如对C2F、sppf等。第二种就是YOLO backbone+其他的CNN backbone(ShuffleNetV1、starnet等)。比如下面两幅图,一个是YOLO backbone+YOLO backbone,一个是YOLO backbone+其他的CNN backbone
3. CNN + Transformer
CNN+Transformer组合的双backbone,这个分为两种,一个就是在在最基础的YOLO backbone+YOLO backbone的基础上改进,比如一个backbone不动,另一个对其改进,比如添加Transformer相关的模块。第二种就是YOLO backbone+其他的Transformer backbone(Swintransformer等)。比如下面两幅图,一个是YOLO backbone+YOLO backbone,一个是YOLO backbone+其他的Transformer backbone